class="hljs-ln-code"> class="hljs-ln-line">定义 SharedBottomMultiTaskModel 类 继承自 nn.Module: class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="3"> class="hljs-ln-code"> class="hljs-ln-line"> 定义 __init__ 方法 参数 (self, 输入维度, 隐藏层1大小, 隐藏层2大小, 隐藏层3大小, 输出任务1维度, 输出任务2维度): class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="4"> class="hljs-ln-code"> class="hljs-ln-line"> 初始化共享底部的三层全连接层 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="5"> class="hljs-ln-code"> class="hljs-ln-line"> 初始化任务1的三层全连接层 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="6"> class="hljs-ln-code"> class="hljs-ln-line"> 初始化任务2的三层全连接层 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="7"> class="hljs-ln-code"> class="hljs-ln-line"> class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="8"> class="hljs-ln-code"> class="hljs-ln-line"> 定义 forward 方法 参数 (self, 输入数据): class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="9"> class="hljs-ln-code"> class="hljs-ln-line"> 计算输入数据通过共享底部后的输出 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="10"> class="hljs-ln-code"> class="hljs-ln-line"> 从共享底部输出分别计算任务1和任务2的结果 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="11"> class="hljs-ln-code"> class="hljs-ln-line"> 返回任务1和任务2的结果 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="12"> class="hljs-ln-code"> class="hljs-ln-line"> class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="13"> class="hljs-ln-code"> class="hljs-ln-line">生成虚拟样本数据: class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="14"> class="hljs-ln-code"> class="hljs-ln-line"> 创建训练集和测试集 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="15"> class="hljs-ln-code"> class="hljs-ln-line"> class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="16"> class="hljs-ln-code"> class="hljs-ln-line">实例化模型对象 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="17"> class="hljs-ln-code"> class="hljs-ln-line">定义损失函数和优化器 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="18"> class="hljs-ln-code"> class="hljs-ln-line">训练循环: class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="19"> class="hljs-ln-code"> class="hljs-ln-line"> 前向传播: 获取预测值 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="20"> class="hljs-ln-code"> class="hljs-ln-line"> 计算每个任务的损失 class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="21"> class="hljs-ln-code"> class="hljs-ln-line"> 反向传播和优化 class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}" onclick="hljs.signin(event)">
PyTorch版本:
算法逻辑
- 导入必要的库。
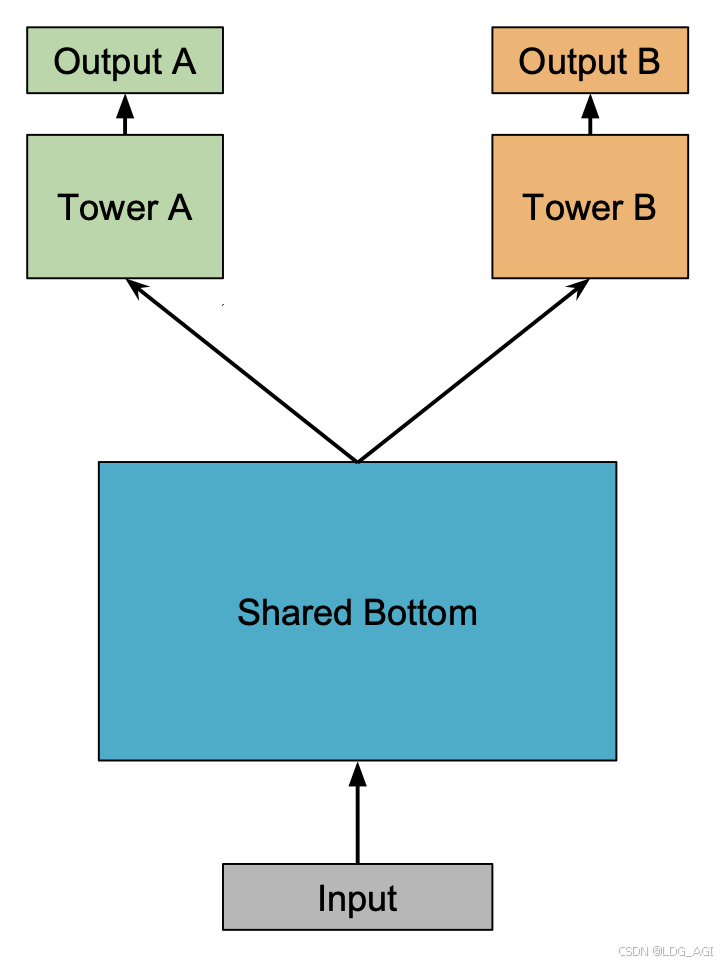
- 定义一个类来表示共享底部和特定任务头部的模型结构。
- 在初始化方法中定义共享底部和两个独立的任务头部网络层。
- 实现前向传播函数,处理输入数据通过共享底部后分发到不同的任务头部。
- 生成虚拟样本数据。
- 定义损失函数和优化器。
- 编写训练循环。
- 进行模型预测。
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="1"> class="hljs-ln-code"> class="hljs-ln-line">import torch
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="2"> class="hljs-ln-code"> class="hljs-ln-line">import torch.nn as nn
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="3"> class="hljs-ln-code"> class="hljs-ln-line">import torch.optim as optim
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="4"> class="hljs-ln-code"> class="hljs-ln-line">from torch.utils.data import DataLoader, TensorDataset
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="5"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="6"> class="hljs-ln-code"> class="hljs-ln-line">class SharedBottomMultiTaskModel(nn.Module):
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="7"> class="hljs-ln-code"> class="hljs-ln-line"> def __init__(self, input_dim, hidden1_dim, hidden2_dim, hidden3_dim, output_task1_dim, output_task2_dim):
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="8"> class="hljs-ln-code"> class="hljs-ln-line"> super(SharedBottomMultiTaskModel, self).__init__()
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="9"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="10"> class="hljs-ln-code"> class="hljs-ln-line"> self.shared_bottom = nn.Sequential(
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="11"> class="hljs-ln-code"> class="hljs-ln-line"> nn.Linear(input_dim, hidden1_dim),
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="12"> class="hljs-ln-code"> class="hljs-ln-line"> nn.ReLU(),
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="13"> class="hljs-ln-code"> class="hljs-ln-line"> nn.Linear(hidden1_dim, hidden2_dim),
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="14"> class="hljs-ln-code"> class="hljs-ln-line"> nn.ReLU(),
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="15"> class="hljs-ln-code"> class="hljs-ln-line"> nn.Linear(hidden2_dim, hidden3_dim),
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="16"> class="hljs-ln-code"> class="hljs-ln-line"> nn.ReLU()
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="17"> class="hljs-ln-code"> class="hljs-ln-line"> )
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="18"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="19"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="20"> class="hljs-ln-code"> class="hljs-ln-line"> self.task1_head = nn.Sequential(
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="21"> class="hljs-ln-code"> class="hljs-ln-line"> nn.Linear(hidden3_dim, hidden2_dim),
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="22"> class="hljs-ln-code"> class="hljs-ln-line"> nn.ReLU(),
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="23"> class="hljs-ln-code"> class="hljs-ln-line"> nn.Linear(hidden2_dim, output_task1_dim)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="24"> class="hljs-ln-code"> class="hljs-ln-line"> )
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="25"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="26"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="27"> class="hljs-ln-code"> class="hljs-ln-line"> self.task2_head = nn.Sequential(
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="28"> class="hljs-ln-code"> class="hljs-ln-line"> nn.Linear(hidden3_dim, hidden2_dim),
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="29"> class="hljs-ln-code"> class="hljs-ln-line"> nn.ReLU(),
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="30"> class="hljs-ln-code"> class="hljs-ln-line"> nn.Linear(hidden2_dim, output_task2_dim)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="31"> class="hljs-ln-code"> class="hljs-ln-line"> )
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="32"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="33"> class="hljs-ln-code"> class="hljs-ln-line"> def forward(self, x):
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="34"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="35"> class="hljs-ln-code"> class="hljs-ln-line"> shared_output = self.shared_bottom(x)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="36"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="37"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="38"> class="hljs-ln-code"> class="hljs-ln-line"> task1_output = self.task1_head(shared_output)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="39"> class="hljs-ln-code"> class="hljs-ln-line"> task2_output = self.task2_head(shared_output)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="40"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="41"> class="hljs-ln-code"> class="hljs-ln-line"> return task1_output, task2_output
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="42"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="43"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="44"> class="hljs-ln-code"> class="hljs-ln-line">torch.manual_seed(42)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="45"> class="hljs-ln-code"> class="hljs-ln-line">input_dim = 10
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="46"> class="hljs-ln-code"> class="hljs-ln-line">task1_dim = 3
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="47"> class="hljs-ln-code"> class="hljs-ln-line">task2_dim = 2
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="48"> class="hljs-ln-code"> class="hljs-ln-line">num_samples = 1000
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="49"> class="hljs-ln-code"> class="hljs-ln-line">X_train = torch.randn(num_samples, input_dim)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="50"> class="hljs-ln-code"> class="hljs-ln-line">y_train_task1 = torch.randn(num_samples, task1_dim)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="51"> class="hljs-ln-code"> class="hljs-ln-line">y_train_task2 = torch.randn(num_samples, task2_dim)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="52"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="53"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="54"> class="hljs-ln-code"> class="hljs-ln-line">train_dataset = TensorDataset(X_train, y_train_task1, y_train_task2)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="55"> class="hljs-ln-code"> class="hljs-ln-line">train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="56"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="57"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="58"> class="hljs-ln-code"> class="hljs-ln-line">model = SharedBottomMultiTaskModel(input_dim, 64, 32, 16, task1_dim, task2_dim)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="59"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="60"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="61"> class="hljs-ln-code"> class="hljs-ln-line">criterion_task1 = nn.MSELoss()
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="62"> class="hljs-ln-code"> class="hljs-ln-line">criterion_task2 = nn.MSELoss()
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="63"> class="hljs-ln-code"> class="hljs-ln-line">optimizer = optim.Adam(model.parameters(), lr=0.001)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="64"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="65"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="66"> class="hljs-ln-code"> class="hljs-ln-line">num_epochs = 10
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="67"> class="hljs-ln-code"> class="hljs-ln-line">for epoch in range(num_epochs):
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="68"> class="hljs-ln-code"> class="hljs-ln-line"> model.train()
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="69"> class="hljs-ln-code"> class="hljs-ln-line"> running_loss = 0.0
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="70"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="71"> class="hljs-ln-code"> class="hljs-ln-line"> for batch_idx, (X_batch, y_task1_batch, y_task2_batch) in enumerate(train_loader):
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="72"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="73"> class="hljs-ln-code"> class="hljs-ln-line"> outputs_task1, outputs_task2 = model(X_batch)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="74"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="75"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="76"> class="hljs-ln-code"> class="hljs-ln-line"> loss_task1 = criterion_task1(outputs_task1, y_task1_batch)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="77"> class="hljs-ln-code"> class="hljs-ln-line"> loss_task2 = criterion_task2(outputs_task2, y_task2_batch)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="78"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="79"> class="hljs-ln-code"> class="hljs-ln-line"> total_loss = loss_task1 + loss_task2
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="80"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="81"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="82"> class="hljs-ln-code"> class="hljs-ln-line"> optimizer.zero_grad()
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="83"> class="hljs-ln-code"> class="hljs-ln-line"> total_loss.backward()
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="84"> class="hljs-ln-code"> class="hljs-ln-line"> optimizer.step()
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="85"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="86"> class="hljs-ln-code"> class="hljs-ln-line"> running_loss += total_loss.item()
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="87"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="88"> class="hljs-ln-code"> class="hljs-ln-line"> print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="89"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="90"> class="hljs-ln-code"> class="hljs-ln-line">
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="91"> class="hljs-ln-code"> class="hljs-ln-line">model.eval()
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="92"> class="hljs-ln-code"> class="hljs-ln-line">with torch.no_grad():
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="93"> class="hljs-ln-code"> class="hljs-ln-line"> test_input = torch.randn(1, input_dim)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="94"> class="hljs-ln-code"> class="hljs-ln-line"> pred_task1, pred_task2 = model(test_input)
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="95"> class="hljs-ln-code"> class="hljs-ln-line">
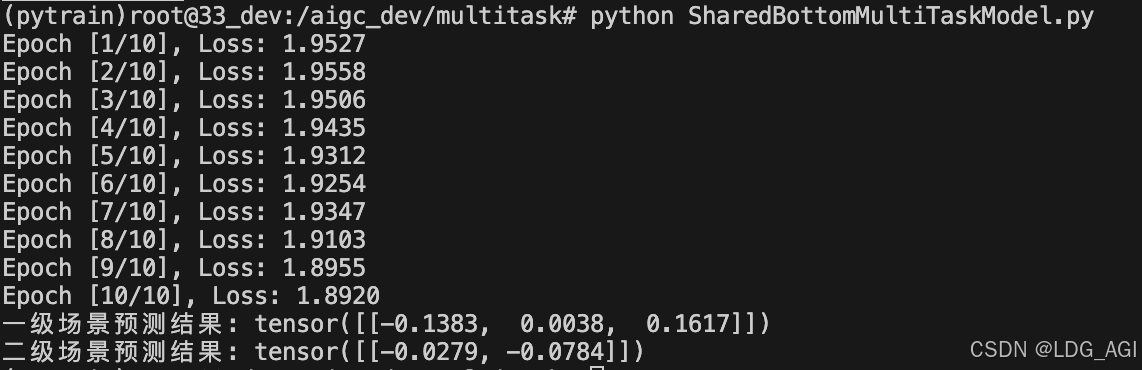
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="96"> class="hljs-ln-code"> class="hljs-ln-line"> print(f'任务1预测结果: {pred_task1}')
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="97"> class="hljs-ln-code"> class="hljs-ln-line"> print(f'任务2预测结果: {pred_task2}')
三、总结
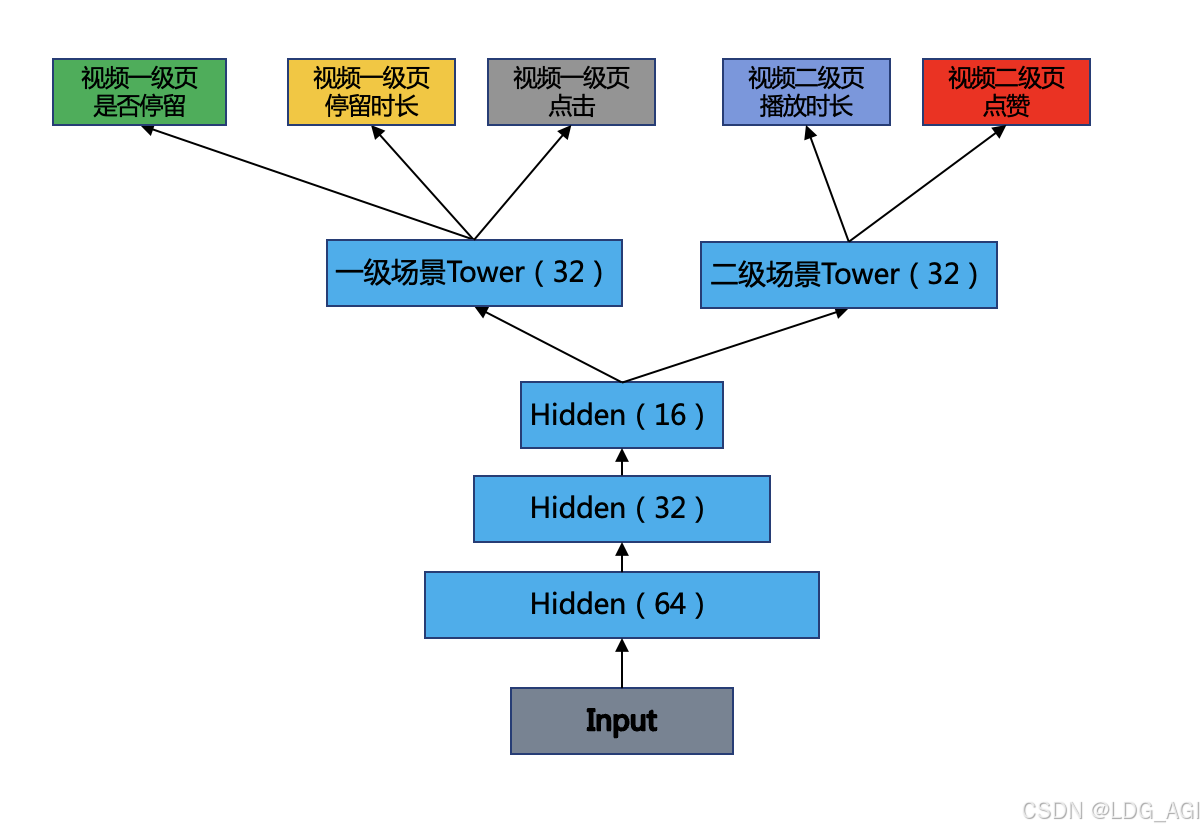
本文从技术原理、技术优缺点方面对推荐系统深度学习多任务多目标“Shared-Bottom Multi-task Model”算法进行讲解,该模型使用深度学习模型对多个任务场景多个目标的业务问题进行建模,使得用户在多个场景连续性行为可以被学习,在现实推荐系统业务中是比较基础的方法,后面本专栏还会陆续介绍MoE、MMoE等多任务多目标算法,期待您的关注和支持。
如果您还有时间,欢迎阅读本专栏的其他文章:
【深度学习】多目标融合算法(一):样本Loss加权(Sample Loss Reweight)
【深度学习】多目标融合算法(二):底部共享多任务模型(Shared-Bottom Multi-task Model)
id="blogVoteBox" style="width:400px;margin:auto;margin-top:12px" class="blog-vote-box"> class="vote-box csdn-vote" style="opacity: 1;">
class="pos-box pt0" style="height: 222px; visibility: visible;">

评论记录:
回复评论: