
线性回归
线性回归(Linear Regression)是机器学习中最基础且广泛应用的监督学习算法之一,主要用于预测连续型的目标变量。它假设输入特征和输出之间存在线性关系,并试图找到一条最佳拟合直线来描述这种关系。
线性回归的工作原理
-
模型假设
线性回归模型假设目标变量 y 和特征向量 X=[x1,x2,…,xn]之间的关系可以通过一个线性方程来表示:y=β0+β1x1+β2x2+…+βnxn+ϵ,这里,βi是模型参数(也称为权重或系数),β0是截距项,而 ϵ表示误差项,代表了所有未被模型解释的因素。 -
最小二乘法
为了确定这些参数值,最常用的方法是最小二乘法(Ordinary Least Squares, OLS)。该方法通过最小化预测值与实际观测值之间的差异平方和来求解最优参数:
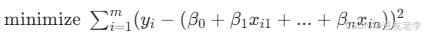
其中 m 是训练样本的数量。 -
解决过拟合问题
当特征过多时,可能会导致模型过拟合训练数据。为了解决这个问题,可以使用正则化技术,如岭回归(Ridge Regression)和Lasso回归(Lasso Regression),它们分别引入了L2范数和L1范数惩罚项来限制参数的大小。
线性回归的应用场景
- 房价预测:根据房屋的面积、房间数量等特征预测其价格。
- 销售额预测:基于广告支出、促销活动等因素预测产品的销售量。
- 经济分析:研究收入、教育水平等对消费行为的影响。
实现线性回归
在Python中,scikit-learn 提供了一个非常方便的方式来实现线性回归。下面是一个简单的例子:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_boston()
X = boston.data
y = boston.target
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
请注意,load_boston 数据集由于一些原因已被移除或标记为过时,因此你可能需要寻找其他替代的数据集来进行实验,比如sklearn.datasets.load_diabetes()或者从外部资源下载适合的数据集。
线性回归的优点和局限性
优点
- 简单易懂,计算效率高。
- 结果具有良好的可解释性,容易理解各个特征对预测结果的影响。
局限性
- 对非线性关系建模能力有限。
- 对异常值敏感。
- 假设特征之间相互独立,但在现实世界中这往往不成立。
总的来说,线性回归是理解和应用机器学习的一个很好的起点,尽管它的假设较为简单,但它仍然是许多复杂模型的基础,并且在很多实际应用中表现良好。
多元线性回归
1、基本概念
线性回归是机器学习中有监督机器学习下的一种算法。 回归问题主要关注的是因变量(需要预测的值,可以是一个也可以是多个)和一个或多个数值型的自变量(预测变量)之间的关系。
需要预测的值:即目标变量,target,y,连续值预测变量。
影响目标变量的因素: X 1 X_1 X1… X n X_n Xn,可以是连续值也可以是离散值。
因变量和自变量之间的关系:即模型,model,是我们要求解的。
1.1、连续值

1.2、离散值
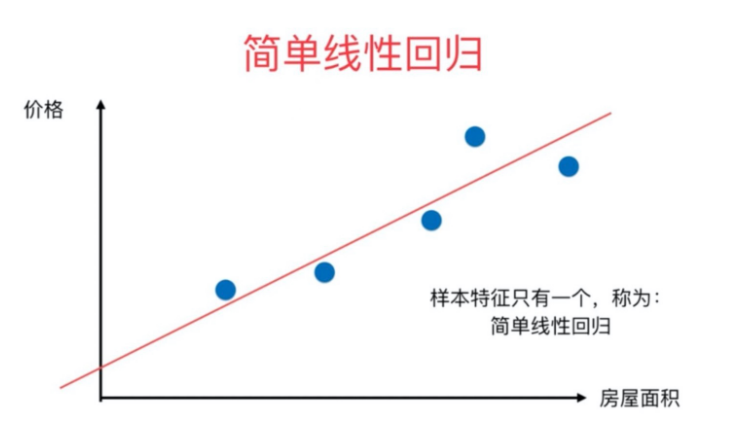
1.3、简单线性回归
前面提到过,算法说白了就是公式,简单线性回归属于一个算法,它所对应的公式。
y = w x + b y = wx + b y=wx+b
这个公式中,y 是目标变量即未来要预测的值,x 是影响 y 的因素,w,b 是公式上的参数即要求的模型。其实 b 就是咱们的截距,w 就是斜率嘛! 所以很明显如果模型求出来了,未来影响 y 值的未知数就是一个 x 值,也可以说影响 y 值 的因素只有一个,所以这是就叫简单线性回归的原因。
同时可以发现从 x 到 y 的计算,x 只是一次方,所以这是算法叫线性回归的原因。 其实,大家上小学时就已经会解这种一元一次方程了。为什么那个时候不叫人工智能算法呢?因为人工智能算法要求的是最优解!
1.4、最优解
Actual value:真实值,一般使用 y 表示。
Predicted value:预测值,是把已知的 x 带入到公式里面和猜出来的参数 w,b 计算得到的,一般使用 y ^ \hat{y} y^ 表示。
Error:误差,预测值和真实值的差距,一般使用 ε \varepsilon ε 表示。
最优解:尽可能的找到一个模型使得整体的误差最小,整体的误差通常叫做损失 Loss。
Loss:整体的误差,Loss 通过损失函数 Loss function 计算得到。
1.5、多元线性回归
现实生活中,往往影响结果 y 的因素不止一个,这时 x 就从一个变成了 n 个, x 1 x_1 x1… x n x_n xn 同时简单线性回归的公式也就不在适用了。多元线性回归公式如下:
y ^ = w 1 x 1 + w 2 x 2 + … … + w n x n + b \hat{y} = w_1x_1 + w_2x_2 + …… + w_nx_n + b y^=w1x1+w2x2+……+wnxn+b
b是截距,也可以使用 w 0 w_0 w0来表示
y ^ = w 1 x 1 + w 2 x 2 + … … + w n x n + w 0 \hat{y} = w_1x_1 + w_2x_2 + …… + w_nx_n + w_0 y^=w1x1+w2x2+……+wnxn+w0
y ^ = w 1 x 1 + w 2 x 2 + … … + w n x n + w 0 ∗ 1 \hat{y} = w_1x_1 + w_2x_2 + …… + w_nx_n + w_0 * 1 y^=w1x1+w2x2+……+wnxn+w0∗1
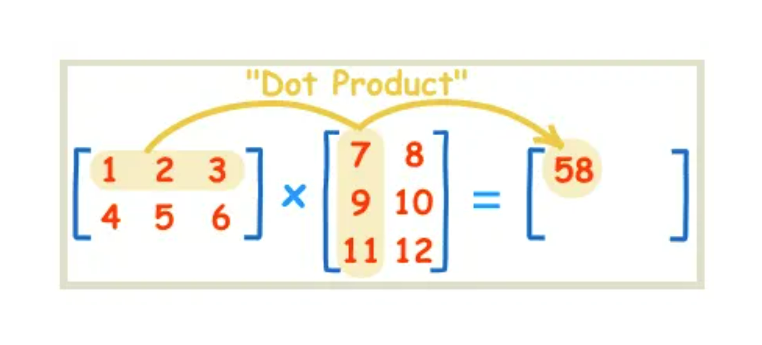
使用向量来表示, X ⃗ \vec{X} X表示所有的变量,是一维向量; W ⃗ \vec{W} W表示所有的系数(包含 w 0 w_0 w0),是一维向量,根据向量乘法规律,可以这么写:
y ^ = W T X \hat{y} = W^TX y^=WTX【默认情况下,向量都是列向量】
2、正规方程
2.1、最小二乘法矩阵表示
最小二乘法可以将误差方程转化为有确定解的代数方程组(其方程式数目正好等于未知数的个数),从而可求解出这些未知参数。这个有确定解的代数方程组称为最小二乘法估计的正规方程。公式如下:
θ = ( X T X ) − 1 X T y \theta = (X^TX)^{-1}X^Ty θ=(XTX)−1XTy 或者 W = ( X T X ) − 1 X T y W = (X^TX)^{-1}X^Ty W=(XTX)−1XTy ,其中的 W 、 θ W、\theta W、θ 即使方程的解!
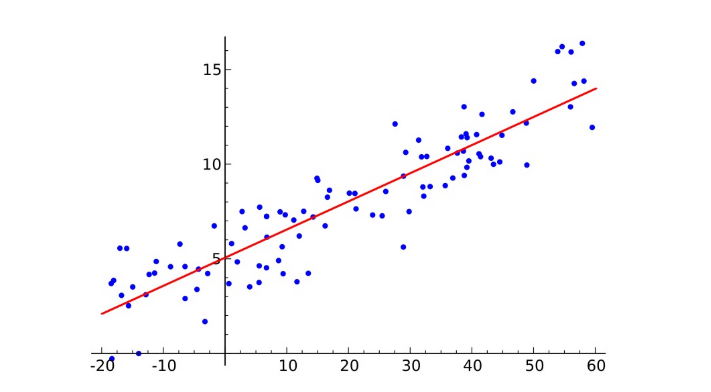
公式是如何推导的?
最小二乘法公式如下:
J ( θ ) = 1 2 ∑ i = 0 n ( h θ ( x i ) − y i ) 2 J(\theta) = \frac{1}{2}\sum\limits_{i = 0}^n(h_{\theta}(x_i) - y_i)^2 J(θ)=21i=0∑n(hθ(xi)−yi)2
使用矩阵表示:
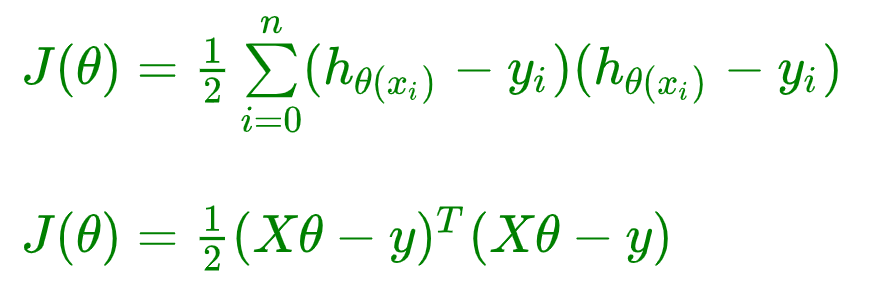
之所以要使用转置T,是因为,矩阵运算规律是:矩阵A的一行乘以矩阵B的一列!
2.2、多元一次方程举例
1、二元一次方程
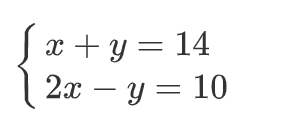
2、三元一次方程
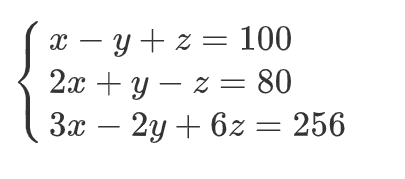
3、八元一次方程
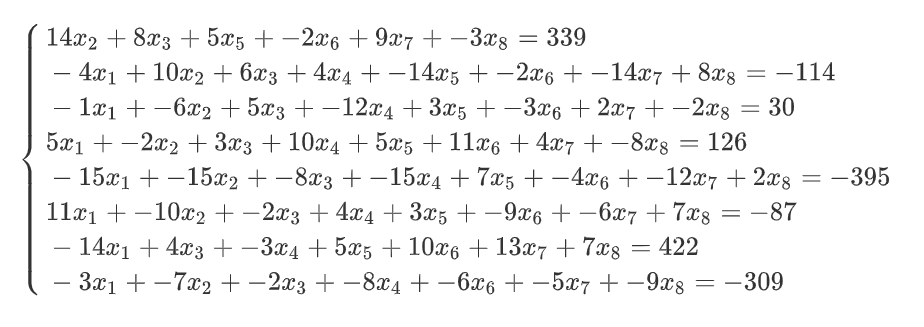
# 上面八元一次方程对应的X数据
X = np.array([[ 0 ,14 , 8 , 0 , 5, -2, 9, -3],
[ -4 , 10 , 6 , 4 ,-14 , -2 ,-14 , 8],
[ -1 , -6 , 5 ,-12 , 3 , -3 , 2 , -2],
[ 5 , -2 , 3 , 10 , 5 , 11 , 4 ,-8],
[-15 ,-15 ,-8 ,-15 , 7 , -4, -12 , 2],
[ 11 ,-10 , -2 , 4 , 3 , -9 , -6 , 7],
[-14 , 0 , 4 , -3 , 5 , 10 , 13 , 7],
[ -3 , -7 , -2 , -8 , 0 , -6 , -5 , -9]])
# 对应的y
y = np.array([ 339 ,-114 , 30 , 126, -395 , -87 , 422, -309])
display(X,y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.3、矩阵转置公式与求导公式:
转置公式如下:
- ( m A ) T = m A T (mA)^T = mA^T (mA)T=mAT,其中m是常数
- ( A + B ) T = A T + B T (A + B)^T = A^T + B^T (A+B)T=AT+BT
- ( A B ) T = B T A T (AB)^T = B^TA^T (AB)T=BTAT
- ( A T ) T = A (A^T)^T = A (AT)T=A
求导公式如下:

2.4、推导正规方程 θ \theta θ 的解:
- 矩阵乘法公式展开
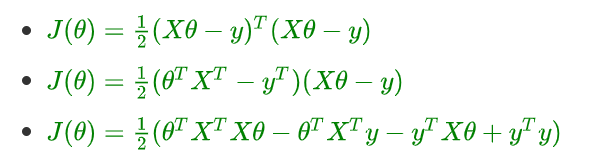
- 进行求导(注意X、y是已知量, θ \theta θ 是未知数):
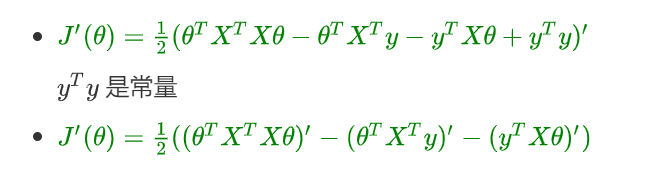
根据2.3、矩阵转置公式与求导公式可知
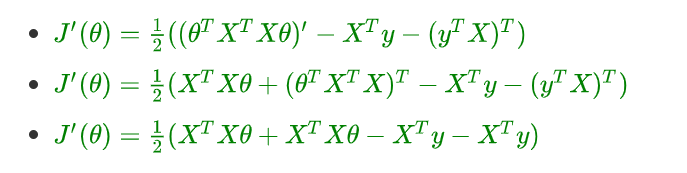
- 根据上面求导公式进行运算:

- 令导数 J ′ ( θ ) = 0 : J'(\theta) = 0: J′(θ)=0:
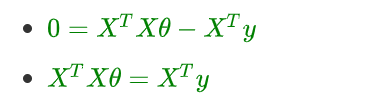
- 矩阵没有除法,使用逆矩阵进行转化:
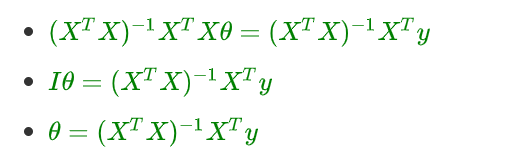
到此为止,公式推导出来了~
2.5、凸函数判定
判定损失函数是凸函数的好处在于我们可能很肯定的知道我们求得的极值即最优解,一定是全局最优解。
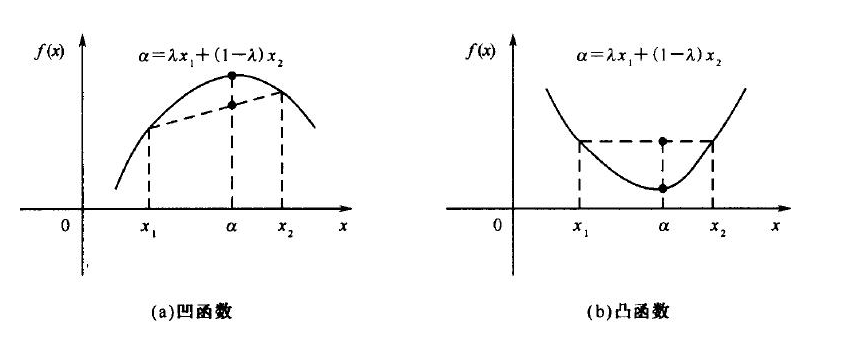
如果是非凸函数,那就不一定可以获取全局最优解~
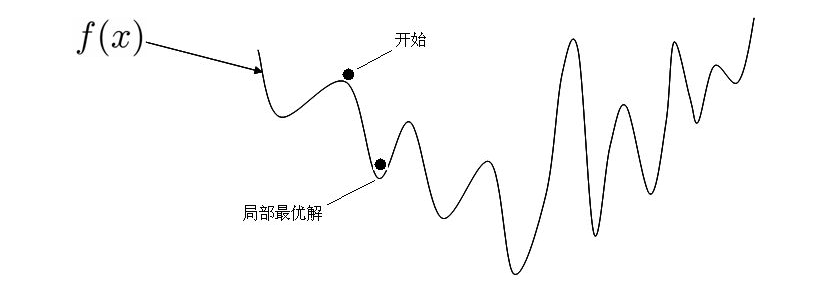
来一个更加立体的效果图:
判定凸函数的方式: 判定凸函数的方式非常多,其中一个方法是看黑塞矩阵是否是半正定的。
黑塞矩阵(hessian matrix)是由目标函数在点 X 处的二阶偏导数组成的对称矩阵。
对于我们的式子来说就是在导函数的基础上再次对θ来求偏导,结果就是 X T X X^TX XTX。所谓正定就是 X T X X^TX XTX 的特征值全为正数,半正定就是 X T X X^TX XTX 的特征值大于等于 0, 就是半正定。
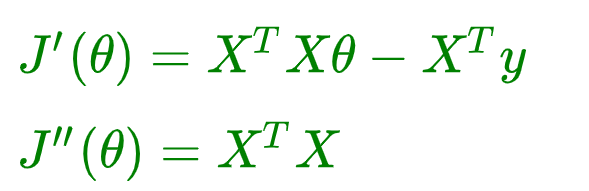
这里我们对 J ( θ ) J(\theta) J(θ) 损失函数求二阶导数的黑塞矩阵是 X T X X^TX XTX ,得到的一定是半正定的,自己和自己做点乘嘛!
这里不用数学推导证明这一点。在机器学习中往往损失函数都是凸函数,到深度学习中损失函数往往是非凸函数,即找到的解未必是全局最优,只要模型堪用就好!机器学习特点是:不强调模型 100% 正确,只要是有价值的,堪用的,就Okay!

3、线性回归算法推导
3.1、深入理解回归
回归简单来说就是“回归平均值”(regression to the mean)。但是这里的 mean 并不是把 历史数据直接当成未来的预测值,而是会把期望值当作预测值。 追根溯源回归这个词是一个叫高尔顿的人发明的,他通过大量观察数据发现:父亲比较高,儿子也比较高;父亲比较矮,那么儿子也比较矮!正所谓“龙生龙凤生凤老鼠的儿子会打洞”!但是会存在一定偏差~
父亲是 1.98,儿子肯定很高,但有可能不会达到1.98
父亲是 1.69,儿子肯定不高,但是有可能比 1.69 高
大自然让我们回归到一定的区间之内,这就是大自然神奇的力量。
高尔顿是谁?达尔文的表弟,这下可以相信他说的十有八九是对的了吧!
人类社会很多事情都被大自然这种神奇的力量只配置:身高、体重、智商、相貌……
这种神秘的力量就叫正态分布。大数学家高斯,深入研究了正态分布,最终推导出了线性回归的原理:最小二乘法!
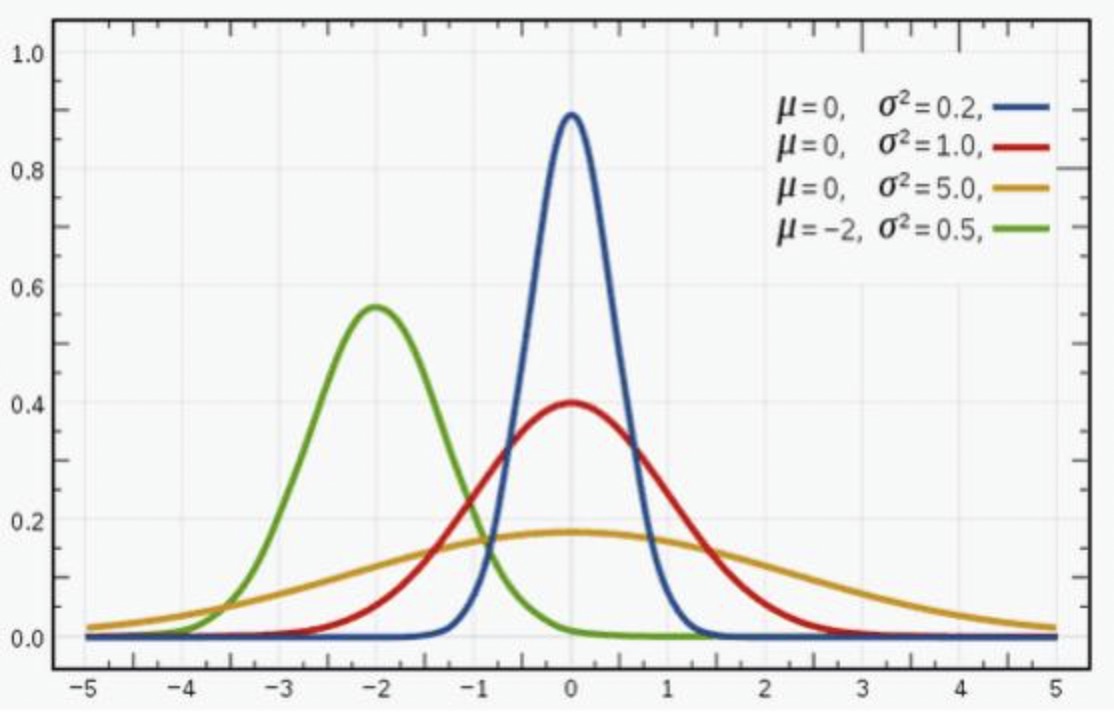
接下来,我们跟着高斯的足迹继续向下走~
3.2、误差分析
误差 ε i \varepsilon_i εi 等于第 i 个样本实际的值 y i y_i yi 减去预测的值 y ^ \hat{y} y^ ,公式可以表达为如下:
ε i = ∣ y i − y ^ ∣ \varepsilon_i = |y_i - \hat{y}| εi=∣yi−y^∣
ε i = ∣ y i − W T x i ∣ \varepsilon_i = |y_i - W^Tx_i| εi=∣yi−WTxi∣
假定所有的样本的误差都是独立的,有上下的震荡,震荡认为是随机变量,足够多的随机变量叠加之后形成的分布,它服从的就是正态分布,因为它是正常状态下的分布,也就是高斯分布!均值是某一个值,方差是某一个值。 方差我们先不管,均值我们总有办法让它去等于零 0 的,因为我们这里是有截距b, 所有误差我们就可以认为是独立分布的,1<=i<=n,服从均值为 0,方差为某定值的高斯分布。机器学习中我们假设误差符合均值为0,方差为定值的正态分布!!!
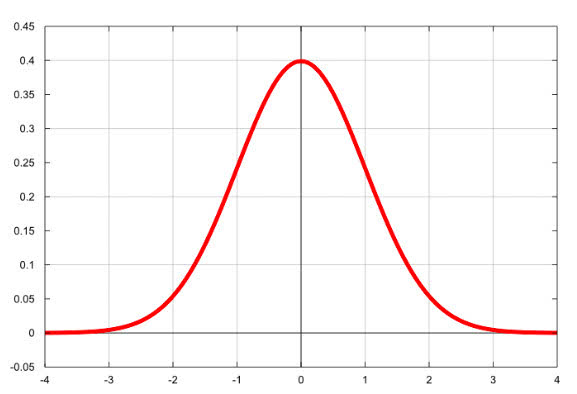
3.3、最大似然估计
最大似然估计(maximum likelihood estimation, MLE)一种重要而普遍的求估计量的方法。最大似然估计明确地使用概率模型,其目标是寻找能够以较高概率产生观察数据的系统发生树。最大似然估计是一类完全基于统计的系统发生树重建方法的代表。
是不是,有点看不懂,太学术了,我们举例说明~
假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的比例也不知。我们想知道罐中白球和黑球的比例,但我们不能把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球再放回罐中。这个过程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,有七十次是白球,请问罐中白球所占的比例最有可能是多少?

请告诉我答案!
很多小伙伴,甚至不用算,凭感觉,就能给出答案:70%!
下面是详细推导过程:
-
最大似然估计,计算
-
白球概率是p,黑球是1-p(罐子中非黑即白)
-
罐子中取一个请问是白球的概率是多少?
p p p
-
罐子中取两个球,两个球都是白色,概率是多少?
p 2 p^2 p2
-
罐子中取5个球都是白色,概率是多少?
p 5 p^5 p5
-
罐子中取10个球,9个是白色,一个是黑色,概率是多少呢?

- C 10 1 = C 10 1 C_{10}^1 = C_{10}^1 C101=C101 这个两个排列组合公式是相等的~
- C 10 9 p 9 ( 1 − p ) = C 10 1 p 9 ( 1 − p ) C_{10}^9p^9(1-p) = C_{10}^1p^9(1-p) C109p9(1−p)=C101p9(1−p)
-
罐子取100个球,70次是白球,30次是黑球,概率是多少?
-
P = C 100 30 p 70 ( 1 − p ) 30 P = C_{100}^{30}p^{70}(1-p)^{30} P=C10030p70(1−p)30
-
最大似然估计,什么时候P最大呢?
C 100 30 C_{100}^{30} C10030是常量,可以去掉!
p > 0,1- p > 0,所以上面概率想要求最大值,那么求导数即可!
-
P ′ = 70 ∗ p 69 ∗ ( 1 − p ) 30 + p 70 ∗ 30 ∗ ( 1 − p ) 29 ∗ ( − 1 ) P' = 70*p^{69}*(1-p)^{30} + p^{70}*30*(1-p)^{29}*(-1) P′=70∗p69∗(1−p)30+p70∗30∗(1−p)29∗(−1)
令导数为0:
-
0 = 70 ∗ p 69 ∗ ( 1 − p ) 30 + p 70 ∗ 30 ∗ ( 1 − p ) 29 ∗ ( − 1 ) 0 = 70*p^{69}*(1-p)^{30} +p^{70}*30*(1-p)^{29}*(-1) 0=70∗p69∗(1−p)30+p70∗30∗(1−p)29∗(−1)
公式化简:
-
0 = 70 ∗ ( 1 − p ) − p ∗ 30 0 = 70*(1-p) - p*30 0=70∗(1−p)−p∗30
-
0 = 70 − 100 ∗ p 0 = 70 - 100*p 0=70−100∗p
-
p = 70%
3.4、高斯分布-概率密度函数
最常见的连续概率分布是正态分布,也叫高斯分布,而这正是我们所需要的,其概率密度函数如下:
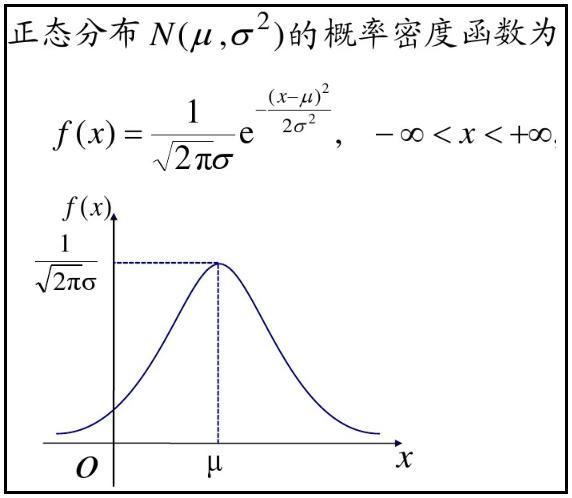
公式如下:
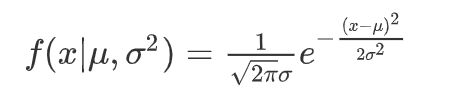
随着参数μ和σ变化,概率分布也产生变化。 下面重要的步骤来了,我们要把一组数据误差出现的总似然,也就是一组数据之所以对应误差出现的整体可能性表达出来了,因为数据的误差我们假设服从一个高斯分布,并且通过截距项来平移整体分布的位置从而使得μ=0,所以样本的误差我们可以表达其概率密度函数的值如下:
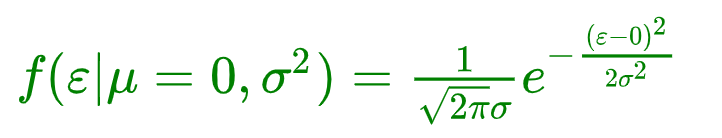
简化如下:
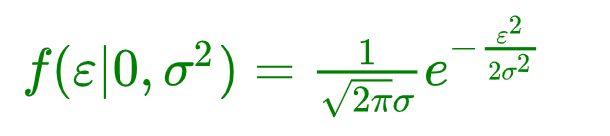
3.5、误差总似然
和前面黑球白球问题类似,也是一个累乘问题~
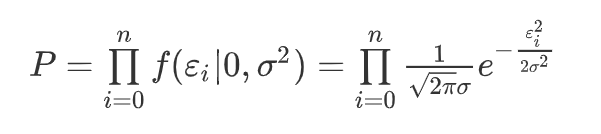
根据前面公式 ε i = ∣ y i − W T x i ∣ \varepsilon_i = |y_i - W^Tx_i| εi=∣yi−WTxi∣可以推导出来如下公式:
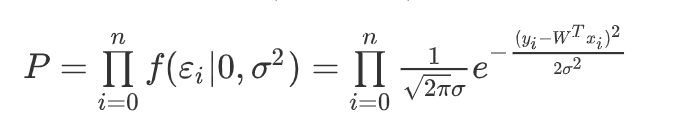
公式中的未知变量就是 W T W^T WT,即方程的系数,系数包含截距~如果,把上面当成一个方程,就是概率P关于W的方程!其余符号,都是常量!
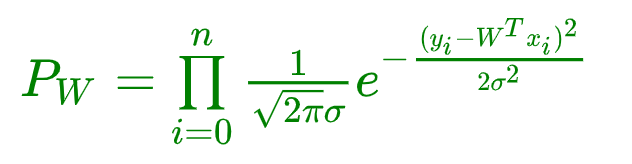
现在问题,就变换成了,求最大似然问题了!不过,等等~
累乘的最大似然,求解是非常麻烦的!
接下来,我们通过,求对数把累乘问题,转变为累加问题(加法问题,无论多复杂,都难不倒我了!)
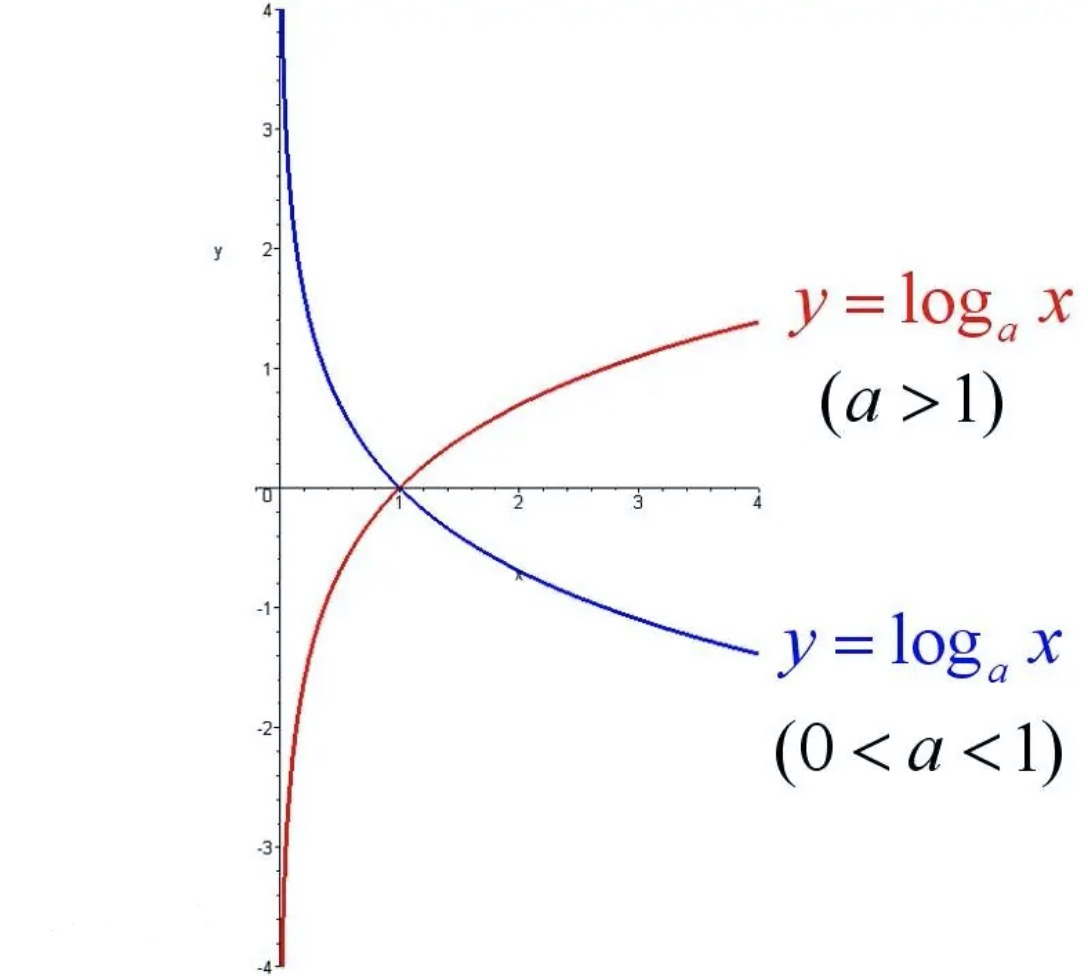
3.6、最小二乘法MSE
P W = ∏ i = 0 n 1 2 π σ e − ( y i − W T x i ) 2 2 σ 2 P_W = \prod\limits_{i = 0}^{n}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i - W^Tx_i)^2}{2\sigma^2}} PW=i=0∏n2πσ1e−2σ2(yi−WTxi)2
根据对数,单调性,对上面公式求自然底数e的对数,效果不变~
l o g e ( P W ) = l o g e ( ∏ i = 0 n 1 2 π σ e − ( y i − W T x i ) 2 2 σ 2 ) log_e(P_W) = log_e(\prod\limits_{i = 0}^{n}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i - W^Tx_i)^2}{2\sigma^2}}) loge(PW)=loge(i=0∏n2πσ1e−2σ2(yi−WTxi)2)
接下来 log 函数继续为你带来惊喜,数学上连乘是个大麻烦,即使交给计算机去求解它也得哭出声来。惊喜是:
- l o g a ( X Y ) = l o g a X + l o g a Y log_a(XY) = log_aX + log_aY loga(XY)=logaX+logaY
- l o g a X Y = l o g a X − l o g a Y log_a\frac{X}{Y} = log_aX - log_aY logaYX=logaX−logaY
- l o g a X n = n ∗ l o g a X log_aX^n = n*log_aX logaXn=n∗logaX
- l o g a ( X 1 X 2 … … X n ) = l o g a X 1 + l o g a X 2 + … … + l o g a X n log_a(X_1X_2……X_n) = log_aX_1 + log_aX_2 + …… + log_aX_n loga(X1X2……Xn)=logaX1+logaX2+……+logaXn
- l o g x x n = n ( n ∈ R ) log_xx^n = n(n\in R) logxxn=n(n∈R)
- l o g a 1 X = − l o g a X log_a\frac{1}{X} = -log_aX logaX1=−logaX
- l o g a N y x = y x l o g a N log_a\sqrt[x]{N^y} = \frac{y}{x}log_aN logaxNy=xylogaN
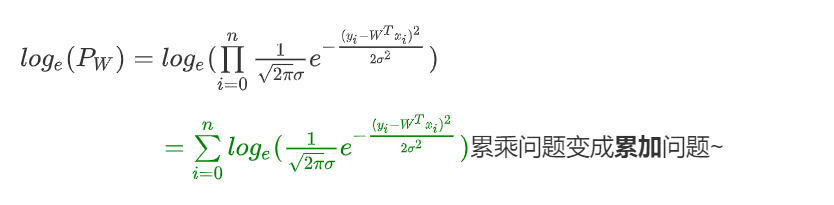
乘风破浪,继续推导—>
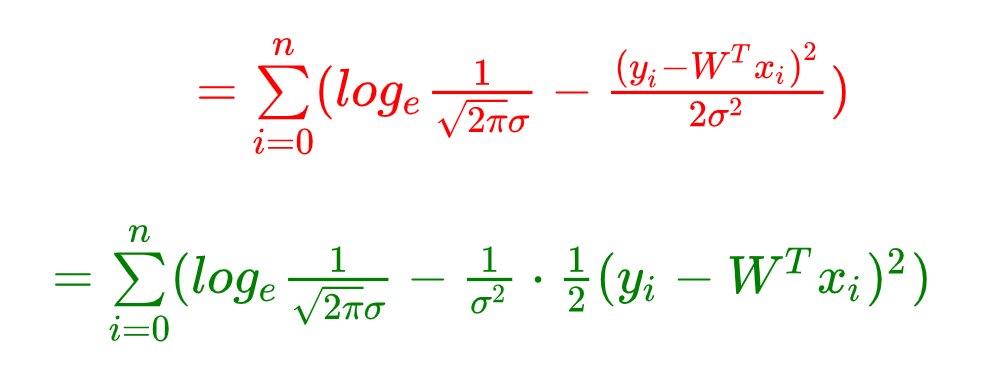
上面公式是最大似然求对数后的变形,其中 π 、 σ \pi、\sigma π、σ都是常量,而 ( y i − W T x i ) 2 (y_i - W^Tx_i)^2 (yi−WTxi)2肯定大于零!上面求最大值问题,即可转变为如下求最小值问题:
L ( W ) = 1 2 ∑ i = 0 n ( y ( i ) − W T x ( i ) ) 2 L(W) = \frac{1}{2}\sum\limits_{i = 0}^n(y^{(i)} - W^Tx^{(i)})^2 L(W)=21i=0∑n(y(i)−WTx(i))2 L代表Loss,表示损失函数,损失函数越小,那么上面最大似然就越大~
有的书本上公式,也可以这样写,用 J ( θ ) J(\theta) J(θ)表示一个意思, θ \theta θ 的角色就是W:
J ( θ ) = 1 2 ∑ i = 1 n ( y ( i ) − θ T x ( i ) ) 2 = 1 2 ∑ i = 1 n ( θ T x ( i ) − y ( i ) ) 2 J(\theta) = \frac{1}{2}\sum\limits_{i = 1}^n(y^{(i)} - \theta^Tx^{(i)})^2 = \frac{1}{2}\sum\limits_{i = 1}^n(\theta^Tx^{(i)} - y^{(i)})^2 J(θ)=21i=1∑n(y(i)−θTx(i))2=21i=1∑n(θTx(i)−y(i))2
进一步提取:
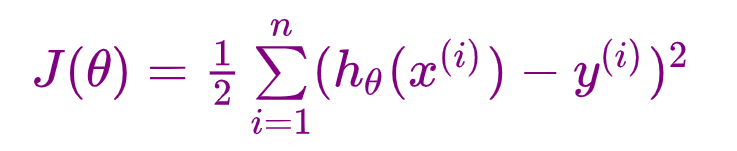
其中:
y ^ = h θ ( X ) = X θ \hat{y} = h_{\theta}(X) =X \theta y^=hθ(X)=Xθ 表示全部数据,是矩阵,X表示多个数据,进行矩阵乘法时,放在前面
y ^ i = h θ ( x ( i ) ) = θ T x ( i ) \hat{y}_i = h_{\theta}(x^{(i)}) = \theta^Tx^{(i)} y^i=hθ(x(i))=θTx(i) 表示第i个数据,是向量,所以进行乘法时,其中一方需要转置
因为最大似然公式中有个负号,所以最大总似然变成了最小化负号后面的部分。 到这里,我们就已经推导出来了 MSE 损失函数 J ( θ ) J(\theta) J(θ),从公式我们也可以看出来 MSE 名字的来 历,mean squared error,上式也叫做最小二乘法!
3.7、归纳总结升华
这种最小二乘法估计,其实我们就可以认为,假定了误差服从正太分布,认为样本误差的出现是随机的,独立的,使用最大似然估计思想,利用损失函数最小化 MSE 就能求出最优解!所以反过来说,如果我们的数据误差不是互相独立的,或者不是随机出现的,那么就不适合去假设为正太分布,就不能去用正太分布的概率密度函数带入到总似然的函数中,故而就不能用 MSE 作为损失函数去求解最优解了!所以,最小二乘法不是万能的~
还有譬如假设误差服从泊松分布,或其他分布那就得用其他分布的概率密度函数去推导出损失函数了。
所以有时我们也可以把线性回归看成是广义线性回归。比如,逻辑回归,泊松回归都属于广义线性回归的一种,这里我们线性回归可以说是最小二乘线性回归。
4、线性回归实战
4.1、使用正规方程进行求解
4.1.1、简单线性回归
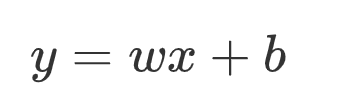
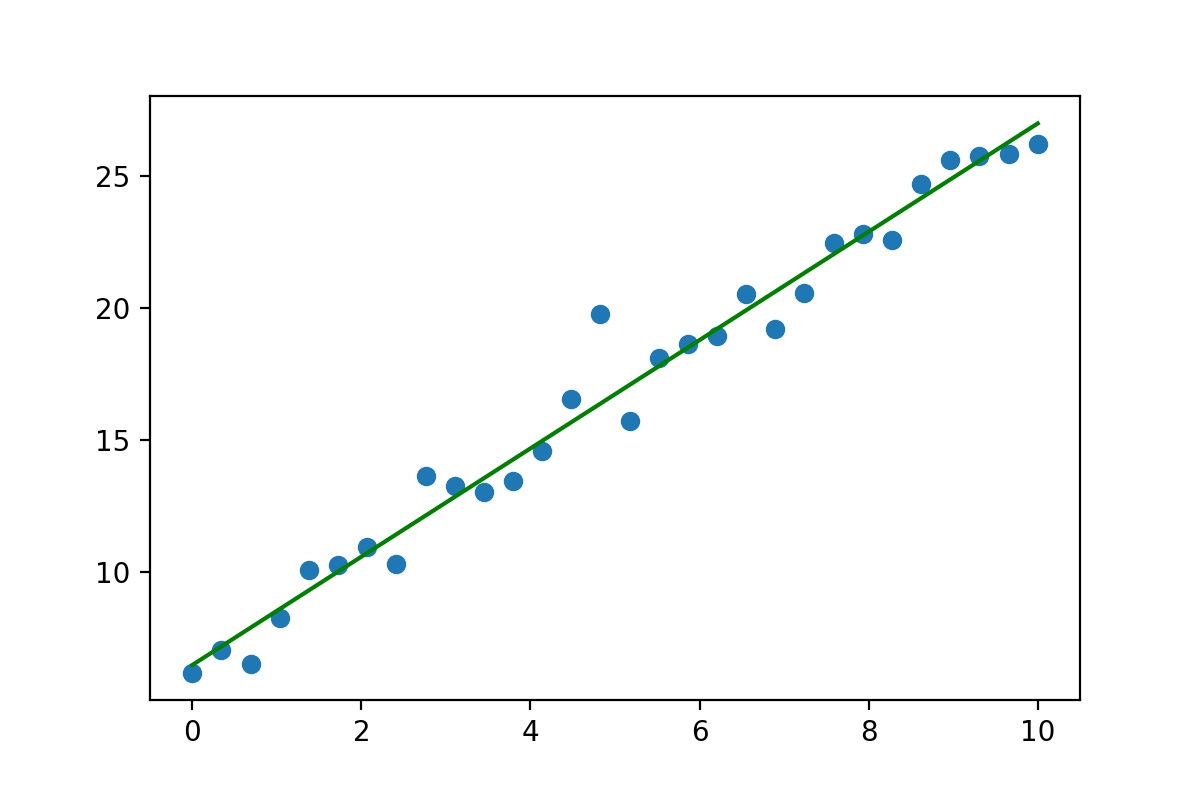
一元一次方程,在机器学习中一元表示一个特征,b表示截距,y表示目标值。
import numpy as np
import matplotlib.pyplot as plt
# 转化成矩阵
X = np.linspace(0,10,num = 30).reshape(-1,1)
# 斜率和截距,随机生成
w = np.random.randint(1,5,size = 1)
b = np.random.randint(1,10,size = 1)
# 根据一元一次方程计算目标值y,并加上“噪声”,数据有上下波动~
y = X * w + b + np.random.randn(30,1)
plt.scatter(X,y)
# 重新构造X,b截距,相当于系数w0,前面统一乘以1
X = np.concatenate([X,np.full(shape = (30,1),fill_value= 1)],axis = 1)
# 正规方程求解
θ = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y).round(2)
print('一元一次方程真实的斜率和截距是:',w, b)
print('通过正规方程求解的斜率和截距是:',θ)
# 根据求解的斜率和截距绘制线性回归线型图
plt.plot(X[:,0],X.dot(θ),color = 'green')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
效果如下(random.randn是随机生成正太分布数据,所以每次执行图形会有所不同):
4.1.2、多元线性回归
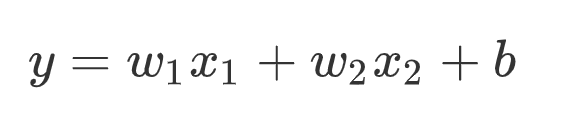
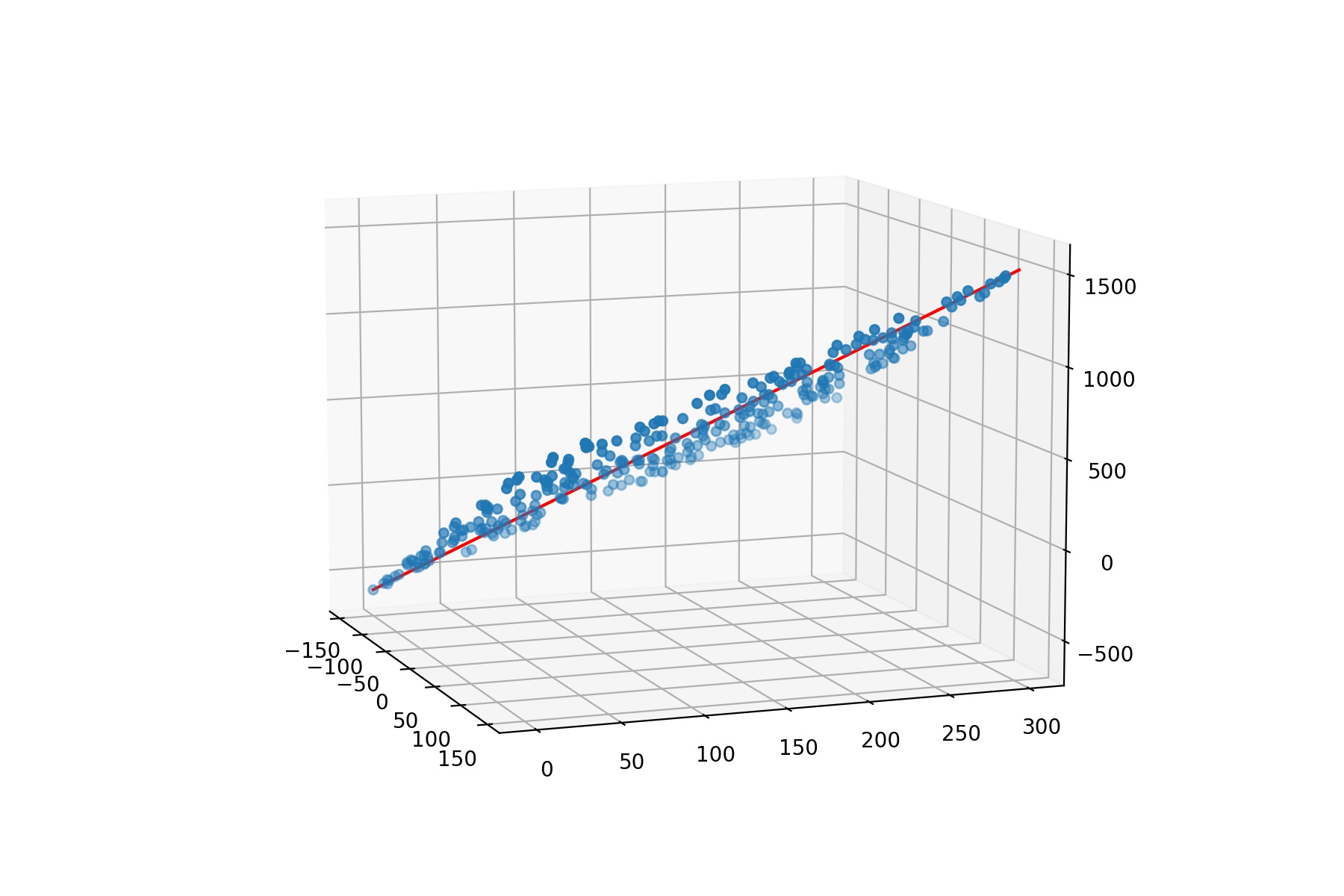
二元一次方程, x 1 、 x 2 x_1、x_2 x1、x2 相当于两个特征,b是方程截距
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d.axes3d import Axes3D # 绘制三维图像
# 转化成矩阵
x1 = np.random.randint(-150,150,size = (300,1))
x2 = np.random.randint(0,300,size = (300,1))
# 斜率和截距,随机生成
w = np.random.randint(1,5,size = 2)
b = np.random.randint(1,10,size = 1)
# 根据二元一次方程计算目标值y,并加上“噪声”,数据有上下波动~
y = x1 * w[0] + x2 * w[1] + b + np.random.randn(300,1)
fig = plt.figure(figsize=(9,6))
ax = Axes3D(fig)
ax.scatter(x1,x2,y) # 三维散点图
ax.view_init(elev=10, azim=-20) # 调整视角
# 重新构造X,将x1、x2以及截距b,相当于系数w0,前面统一乘以1进行数据合并
X = np.concatenate([x1,x2,np.full(shape = (300,1),fill_value=1)],axis = 1)
w = np.concatenate([w,b])
# 正规方程求解
θ = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y).round(2)
print('二元一次方程真实的斜率和截距是:',w)
print('通过正规方程求解的斜率和截距是:',θ.reshape(-1))
# # 根据求解的斜率和截距绘制线性回归线型图
x = np.linspace(-150,150,100)
y = np.linspace(0,300,100)
z = x * θ[0] + y * θ[1] + θ[2]
ax.plot(x,y,z ,color = 'red')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
效果如下:
4.2、机器学习库scikit-learn
4.2.1、scikit-learn简介

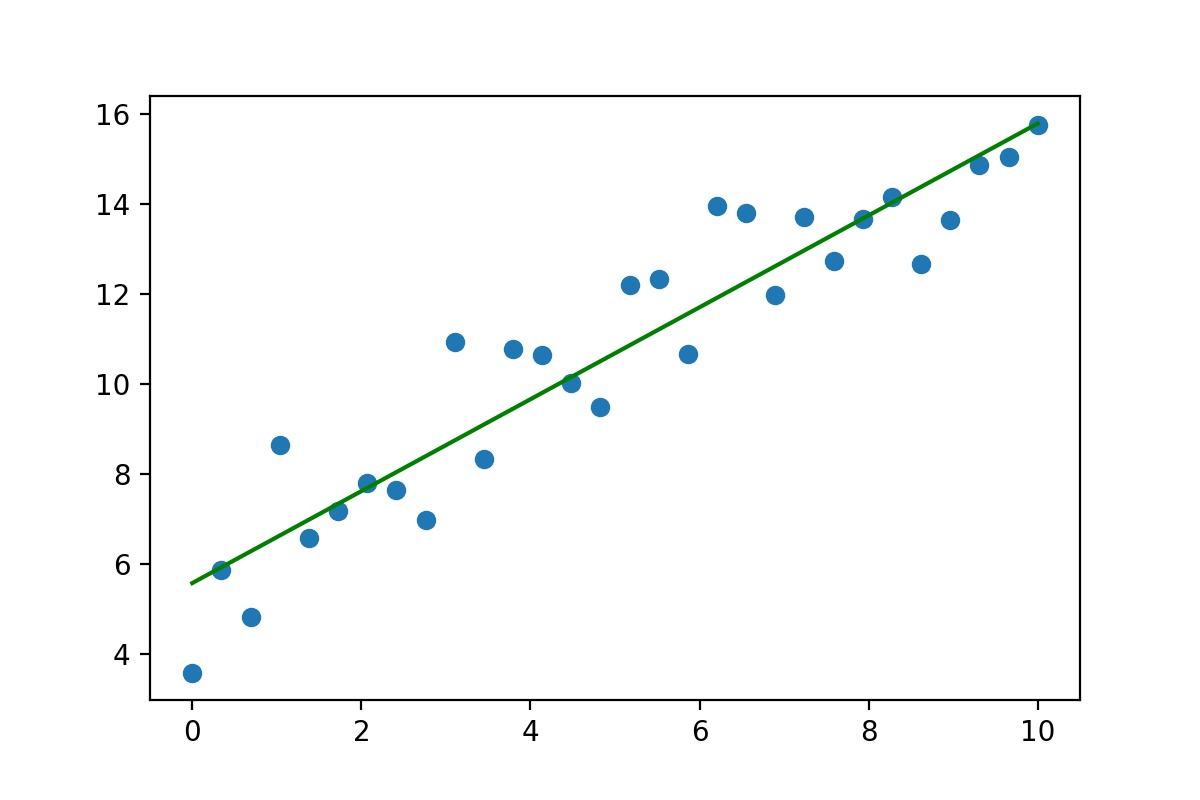
4.2.2、scikit-learn实现简单线性回归
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
# 转化成矩阵
X = np.linspace(0,10,num = 30).reshape(-1,1)
# 斜率和截距,随机生成
w = np.random.randint(1,5,size = 1)
b = np.random.randint(1,10,size = 1)
# 根据一元一次方程计算目标值y,并加上“噪声”,数据有上下波动~
y = X * w + b + np.random.randn(30,1)
plt.scatter(X,y)
# 使用scikit-learn中的线性回归求解
model = LinearRegression()
model.fit(X,y)
w_ = model.coef_
b_ = model.intercept_
print('一元一次方程真实的斜率和截距是:',w, b)
print('通过scikit-learn求解的斜率和截距是:',w_,b_)
plt.plot(X,X.dot(w_) + b_,color = 'green')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
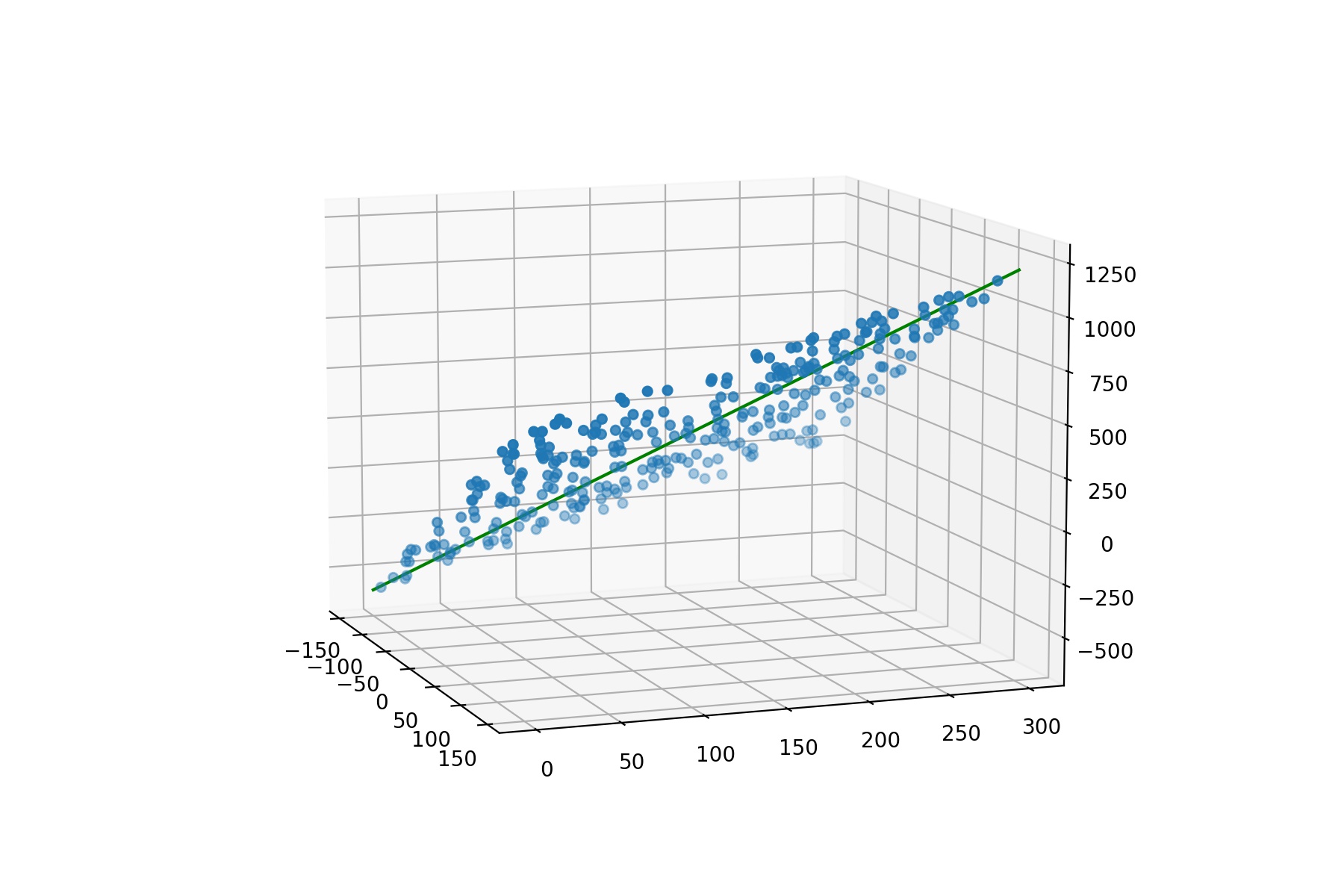
4.2.3、scikit-learn实现多元线性回归
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d.axes3d import Axes3D
# 转化成矩阵
x1 = np.random.randint(-150,150,size = (300,1))
x2 = np.random.randint(0,300,size = (300,1))
# 斜率和截距,随机生成
w = np.random.randint(1,5,size = 2)
b = np.random.randint(1,10,size = 1)
# 根据二元一次方程计算目标值y,并加上“噪声”,数据有上下波动~
y = x1 * w[0] + x2 * w[1] + b + np.random.randn(300,1)
fig = plt.figure(figsize=(9,6))
ax = Axes3D(fig)
ax.scatter(x1,x2,y) # 三维散点图
ax.view_init(elev=10, azim=-20) # 调整视角
# 重新构造X,将x1、x2以及截距b,相当于系数w0,前面统一乘以1进行数据合并
X = np.concatenate([x1,x2],axis = 1)
# 使用scikit-learn中的线性回归求解
model = LinearRegression()
model.fit(X,y)
w_ = model.coef_.reshape(-1)
b_ = model.intercept_
print('二元一次方程真实的斜率和截距是:',w,b)
print('通过scikit-learn求解的斜率和截距是:',w_,b_)
# # 根据求解的斜率和截距绘制线性回归线型图
x = np.linspace(-150,150,100)
y = np.linspace(0,300,100)
z = x * w_[0] + y * w_[1] + b_
ax.plot(x,y,z ,color = 'green')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
4.3 房价预测
- 数据加载
- 数据介绍
- 数据拆分
- 数据建模
- 数据预测
- 数据评估
4.3.1 导包
from sklearn.linear_model import LinearRegression
from sklearn import datasets
from sklearn.model_selection import train_test_split
- 1
- 2
- 3
import warnings
warnings.filterwarnings('ignore')
- 1
- 2
4.3.2 数据加载
波士顿房价【数据类型无所谓:癌症、糖尿病、身高】
data = datasets.load_boston()
data
- 1
- 2
{'data': array([[6.3200e-03, 1.8000e+01, 2.3100e+00, ..., 1.5300e+01, 3.9690e+02,
4.9800e+00],
[2.7310e-02, 0.0000e+00, 7.0700e+00, ..., 1.7800e+01, 3.9690e+02,
9.1400e+00],
[2.7290e-02, 0.0000e+00, 7.0700e+00, ..., 1.7800e+01, 3.9283e+02,
4.0300e+00],
...,
[6.0760e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02,
5.6400e+00],
[1.0959e-01, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9345e+02,
6.4800e+00],
[4.7410e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02,
7.8800e+00]]),
'target': array([24. , 21.6, 34.7, 33.4, 36.2, 28.7, 22.9, 27.1, 16.5, 18.9, 15. ,
18.9, 21.7, 20.4, 18.2, 19.9, 23.1, 17.5, 20.2, 18.2, 13.6, 19.6,
15.2, 14.5, 15.6, 13.9, 16.6, 14.8, 18.4, 21. , 12.7, 14.5, 13.2,
13.1, 13.5, 18.9, 20. , 21. , 24.7, 30.8, 34.9, 26.6, 25.3, 24.7,
21.2, 19.3, 20. , 16.6, 14.4, 19.4, 19.7, 20.5, 25. , 23.4, 18.9,
35.4, 24.7, 31.6, 23.3, 19.6, 18.7, 16. , 22.2, 25. , 33. , 23.5,
19.4, 22. , 17.4, 20.9, 24.2, 21.7, 22.8, 23.4, 24.1, 21.4, 20. ,
20.8, 21.2, 20.3, 28. , 23.9, 24.8, 22.9, 23.9, 26.6, 22.5, 22.2,
23.6, 28.7, 22.6, 22. , 22.9, 25. , 20.6, 28.4, 21.4, 38.7, 43.8,
33.2, 27.5, 26.5, 18.6, 19.3, 20.1, 19.5, 19.5, 20.4, 19.8, 19.4,
21.7, 22.8, 18.8, 18.7, 18.5, 18.3, 21.2, 19.2, 20.4, 19.3, 22. ,
20.3, 20.5, 17.3, 18.8, 21.4, 15.7, 16.2, 18. , 14.3, 19.2, 19.6,
23. , 18.4, 15.6, 18.1, 17.4, 17.1, 13.3, 17.8, 14. , 14.4, 13.4,
15.6, 11.8, 13.8, 15.6, 14.6, 17.8, 15.4, 21.5, 19.6, 15.3, 19.4,
17. , 15.6, 13.1, 41.3, 24.3, 23.3, 27. , 50. , 50. , 50. , 22.7,
25. , 50. , 23.8, 23.8, 22.3, 17.4, 19.1, 23.1, 23.6, 22.6, 29.4,
23.2, 24.6, 29.9, 37.2, 39.8, 36.2, 37.9, 32.5, 26.4, 29.6, 50. ,
32. , 29.8, 34.9, 37. , 30.5, 36.4, 31.1, 29.1, 50. , 33.3, 30.3,
34.6, 34.9, 32.9, 24.1, 42.3, 48.5, 50. , 22.6, 24.4, 22.5, 24.4,
20. , 21.7, 19.3, 22.4, 28.1, 23.7, 25. , 23.3, 28.7, 21.5, 23. ,
26.7, 21.7, 27.5, 30.1, 44.8, 50. , 37.6, 31.6, 46.7, 31.5, 24.3,
31.7, 41.7, 48.3, 29. , 24. , 25.1, 31.5, 23.7, 23.3, 22. , 20.1,
22.2, 23.7, 17.6, 18.5, 24.3, 20.5, 24.5, 26.2, 24.4, 24.8, 29.6,
42.8, 21.9, 20.9, 44. , 50. , 36. , 30.1, 33.8, 43.1, 48.8, 31. ,
36.5, 22.8, 30.7, 50. , 43.5, 20.7, 21.1, 25.2, 24.4, 35.2, 32.4,
32. , 33.2, 33.1, 29.1, 35.1, 45.4, 35.4, 46. , 50. , 32.2, 22. ,
20.1, 23.2, 22.3, 24.8, 28.5, 37.3, 27.9, 23.9, 21.7, 28.6, 27.1,
20.3, 22.5, 29. , 24.8, 22. , 26.4, 33.1, 36.1, 28.4, 33.4, 28.2,
22.8, 20.3, 16.1, 22.1, 19.4, 21.6, 23.8, 16.2, 17.8, 19.8, 23.1,
21. , 23.8, 23.1, 20.4, 18.5, 25. , 24.6, 23. , 22.2, 19.3, 22.6,
19.8, 17.1, 19.4, 22.2, 20.7, 21.1, 19.5, 18.5, 20.6, 19. , 18.7,
32.7, 16.5, 23.9, 31.2, 17.5, 17.2, 23.1, 24.5, 26.6, 22.9, 24.1,
18.6, 30.1, 18.2, 20.6, 17.8, 21.7, 22.7, 22.6, 25. , 19.9, 20.8,
16.8, 21.9, 27.5, 21.9, 23.1, 50. , 50. , 50. , 50. , 50. , 13.8,
13.8, 15. , 13.9, 13.3, 13.1, 10.2, 10.4, 10.9, 11.3, 12.3, 8.8,
7.2, 10.5, 7.4, 10.2, 11.5, 15.1, 23.2, 9.7, 13.8, 12.7, 13.1,
12.5, 8.5, 5. , 6.3, 5.6, 7.2, 12.1, 8.3, 8.5, 5. , 11.9,
27.9, 17.2, 27.5, 15. , 17.2, 17.9, 16.3, 7. , 7.2, 7.5, 10.4,
8.8, 8.4, 16.7, 14.2, 20.8, 13.4, 11.7, 8.3, 10.2, 10.9, 11. ,
9.5, 14.5, 14.1, 16.1, 14.3, 11.7, 13.4, 9.6, 8.7, 8.4, 12.8,
10.5, 17.1, 18.4, 15.4, 10.8, 11.8, 14.9, 12.6, 14.1, 13. , 13.4,
15.2, 16.1, 17.8, 14.9, 14.1, 12.7, 13.5, 14.9, 20. , 16.4, 17.7,
19.5, 20.2, 21.4, 19.9, 19. , 19.1, 19.1, 20.1, 19.9, 19.6, 23.2,
29.8, 13.8, 13.3, 16.7, 12. , 14.6, 21.4, 23. , 23.7, 25. , 21.8,
20.6, 21.2, 19.1, 20.6, 15.2, 7. , 8.1, 13.6, 20.1, 21.8, 24.5,
23.1, 19.7, 18.3, 21.2, 17.5, 16.8, 22.4, 20.6, 23.9, 22. , 11.9]),
'feature_names': array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
4.3.3 提取数据
X = data['data'] # 特征,影响房价的指标
y = data['target'] # 房价
display(X.shape,y.shape,X[:5],y[:5])
- 1
- 2
- 3
(506, 13)
(506,)
array([[6.3200e-03, 1.8000e+01, 2.3100e+00, 0.0000e+00, 5.3800e-01,
6.5750e+00, 6.5200e+01, 4.0900e+00, 1.0000e+00, 2.9600e+02,
1.5300e+01, 3.9690e+02, 4.9800e+00],
[2.7310e-02, 0.0000e+00, 7.0700e+00, 0.0000e+00, 4.6900e-01,
6.4210e+00, 7.8900e+01, 4.9671e+00, 2.0000e+00, 2.4200e+02,
1.7800e+01, 3.9690e+02, 9.1400e+00],
[2.7290e-02, 0.0000e+00, 7.0700e+00, 0.0000e+00, 4.6900e-01,
7.1850e+00, 6.1100e+01, 4.9671e+00, 2.0000e+00, 2.4200e+02,
1.7800e+01, 3.9283e+02, 4.0300e+00],
[3.2370e-02, 0.0000e+00, 2.1800e+00, 0.0000e+00, 4.5800e-01,
6.9980e+00, 4.5800e+01, 6.0622e+00, 3.0000e+00, 2.2200e+02,
1.8700e+01, 3.9463e+02, 2.9400e+00],
[6.9050e-02, 0.0000e+00, 2.1800e+00, 0.0000e+00, 4.5800e-01,
7.1470e+00, 5.4200e+01, 6.0622e+00, 3.0000e+00, 2.2200e+02,
1.8700e+01, 3.9690e+02, 5.3300e+00]])
array([24. , 21.6, 34.7, 33.4, 36.2])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4.3.4 拆分数据
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 50)
display(X_train.shape,X_test.shape)
- 1
- 2
(456, 13)
(50, 13)
- 1
- 2
4.3.5 建模和预测
model = LinearRegression(fit_intercept=True)# 正规方程,封装好了
model.fit(X_train,y_train)# 训练,建模
- 1
- 2
LinearRegression()
- 1
y_ = model.predict(X_test) # 保留的50个样本
display('算法预测的房价值:',y_.round(1))
display('真实房价是多少:',y_test)
- 1
- 2
- 3
- 4
'算法预测的房价值:'
array([25.1, 20.7, 27.3, 15.2, 14.8, 21.7, 24.9, 32.8, 27.1, 41.5, 22.8,
11.3, 29.6, 22.2, 27. , 8.3, 24.2, 16.9, 37.8, 26.8, 28.8, 15.7,
20.5, 20.5, 17.5, 17.2, 38.3, 19.2, 22.7, 17. , 18.3, 20.3, 20.6,
40.4, 13.4, 25.8, 25.7, 11.6, 18.5, 11.7, 34.5, 16.5, 31.8, 35.1,
24.2, 18.5, 37.1, 18. , 18.8, 40.7])
'真实房价是多少:'
array([19.4, 20.5, 24.5, 17.2, 15.4, 16.1, 22.9, 33.1, 22.3, 48.5, 23.2,
6.3, 23. , 21.1, 23.2, 7.2, 22.2, 17.5, 21.9, 23.9, 28.6, 15.6,
19.9, 21.8, 14.9, 17.2, 44.8, 18.2, 23.1, 18.6, 16.1, 13.8, 24.5,
50. , 9.5, 50. , 22.2, 12.7, 12.1, 12. , 39.8, 20.6, 29. , 35.1,
23.4, 20.8, 44. , 13.9, 20.1, 48.8])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.3.6 模型评估
model.score(X_test,y_test)
- 1
0.7390814955259399
- 1
# 不是死记硬背,根据数据提取 规律,方程,并不是所有的数据,都吻合
model.score(X_train,y_train)
- 1
- 2
0.7398774710790202
- 1
from sklearn.metrics import mean_squared_error # 均方误差
- 1
# 均方误差,越小越好!
mean_squared_error(y_test,y_)
- 1
- 2
31.198469141420972
- 1
# 模型非常好,预测非常准,完全一样!
# y_test == y_ 根据这个公式进行计算,结果是:0
((y_test - y_)**2).mean()
- 1
- 2
- 3
31.198469141420972
- 1
模型上线,模型部署
评论记录:
回复评论: