
从 0 开始搞定 RAG 应用(三)路由
上一篇文章 从 0 开始搞定 RAG 应用(第二篇)query translation 查询转换 主要介绍 RAG 中重要的用户 query 的各种方式和代码实现,目的就是为了提供检索的准确性。
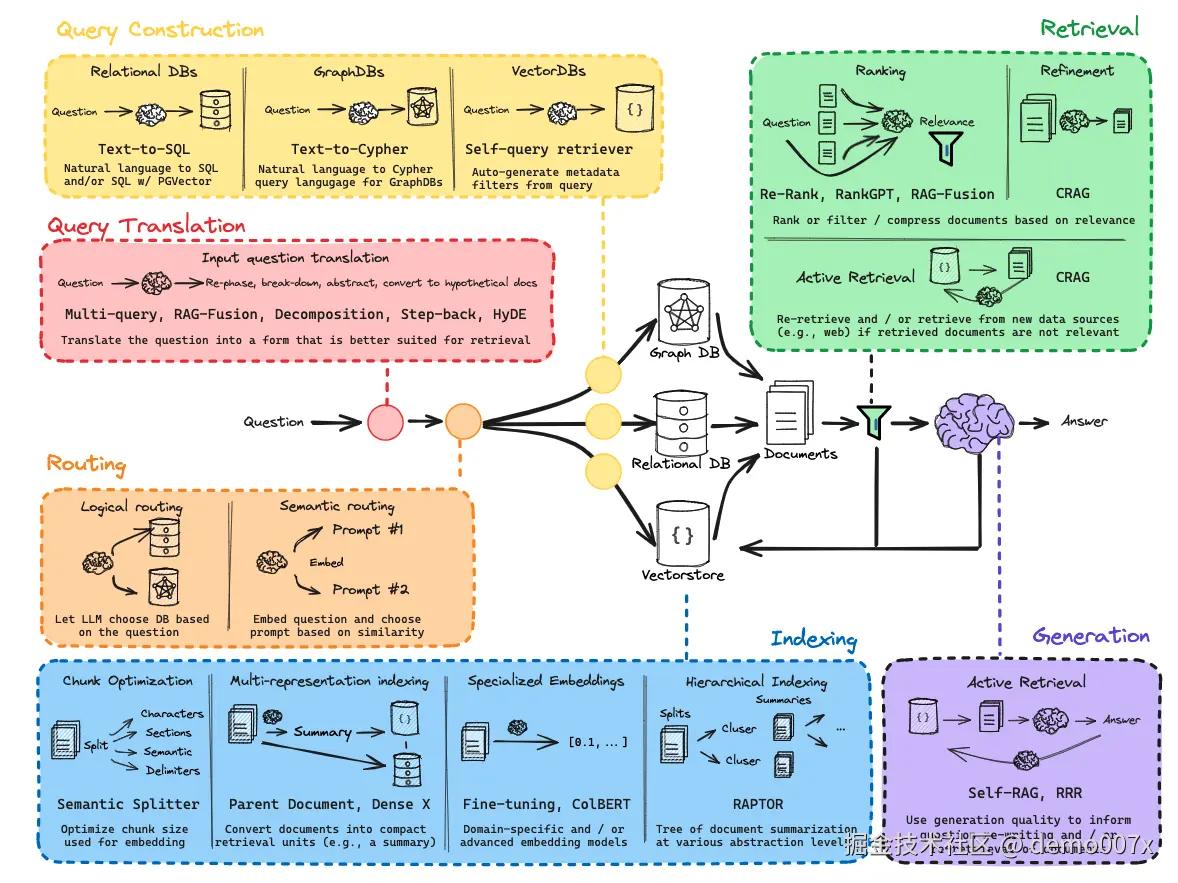
路由对于我们来说是很熟悉的了。在 RAG 中的路由主要的作用是让 LLM 分析用户 query 的语义,从而帮助我们的应用正确的选择要查找的数据源(向量库、Relation DB等)。
环境配置
安装依赖项
代码解读复制代码pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
langSmith 环境配置(选择安装)
lua 代码解读复制代码 import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] = 'your-api-key'
如果你是用 openAI 作为 LLM,那么你需要在环境变量中设置 OPENAI_API_KEY
css 代码解读复制代码 os.environ['OPENAI_API_KEY'] =
我这里是用 azure 的服务,所以这里我的代码是这样子的,你可以根据自己的情况进行修改
python 代码解读复制代码 import os
import dotenv
# 加载.env 文件
dotenv.load_dotenv(".env")
逻辑语义路由
使用函数调用进行路由区分
我们现看代码,然后一步步解释代码的作用:
导入需要的 python 包:
python 代码解读复制代码 from typing import Literal
import bs4
import os
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import AzureChatOpenAI, AzureOpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import AzureChatOpenAI
定义数据模型
ini 代码解读复制代码 # 定义数据模型
class RouteQuery(BaseModel):
"""
将用户查询路由到最相关的数据源。
鉴于用户提出的问题,请选择最相关的数据源来回答他们的问题。
"""
datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field(
...,
description="Given a user question choose which datasource would be most relevant for answering their question",
)
# LLM function call
# 初始化 LLM, LLM 的配置会自动获取环境变量中的值。
llm = AzureChatOpenAI(
azure_deployment=os.getenv("AZURE_DEPLOYMENT_NAME_GPT35"),
temperature=0
)
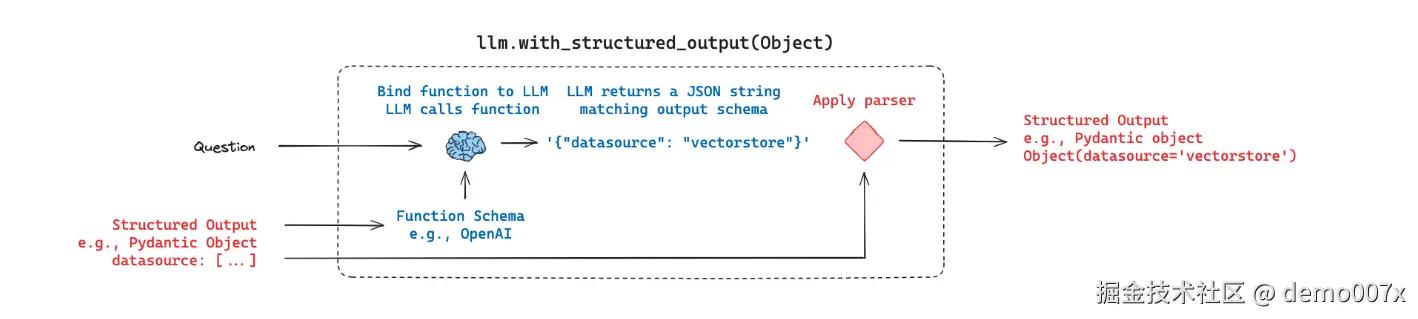
structured_llm = llm.with_structured_output(RouteQuery)
# Prompt
system = """You are an expert at routing a user question to the appropriate data source.
Based on the programming language the question is referring to, route it to the relevant data source."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
# 定义路由器
router = prompt | structured_llm
上面的代码中,我们提供了函数 RouteQuery 的作用是让 LLM 可以从语义上识别到我们的问题与定义的 datasource 的关系, LLM 语义分析后是用 function call 返回结果。
css 代码解读复制代码 datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field(
...,
description="Given a user question choose which datasource would be most relevant for answering their question",
)
这里面的 description 很重要,他是 prompt,会要求 LLM 怎么做,确保返回的数据是我们已经定义好的(如果 LLM 返回的结果是随意的,那么我们根本无法做任何事情)。
ini 代码解读复制代码 question = """
Go语言为什么值得学习?
"""
result = router.invoke({"question": question})
result
我们体格问题,观察 router 返回的信息
ini 代码解读复制代码 RouteQuery(datasource='golang_docs')
一旦我们有了这个,定义一个使用 result.datasource 的分支就很简单了。
更多 routeing 的文档可以查看 langchain 文档
示例
我从掘金的上面选了三篇文章,一篇关于 golang,一篇是 rust,一篇是 python;
python 代码解读复制代码 from langchain_core.runnables import RunnableLambda
docs_url = ("https://juejin.cn/post/7366149991159955466",
"https://juejin.cn/post/7280104452399841332", "https://juejin.cn/post/7281444255120769039")
def choose_route(result)->str:
"""根据结果的数据源选择适当的链。"""
if "python_docs" in result.datasource.lower():
return docs_url[0]
elif "js_docs" in result.datasource.lower():
return docs_url[1]
else:
return docs_url[2]
full_chain = router | RunnableLambda(choose_route)
full_chain.invoke({"question": question})
rust 代码解读复制代码 'https://juejin.cn/post/7281444255120769039'
上面的代码主要是将用户的 query从语义上分析,然后返回一个合适话题的文档链接(实际应用中可以基于此扩展,这里只是 demo)。
然后我们就可以结合第一篇文章中的示例进行 RAG。
RAG 实现
我们把检索这块的代码封装为一个函数:
ini 代码解读复制代码 from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.vectorstores import VectorStoreRetriever
from langchain_core.output_parsers import StrOutputParser
def get_retrieval(web_url: str) -> VectorStoreRetriever:
loader = WebBaseLoader(
web_paths=(web_url,),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("article", "article-title")
)
),
)
# 文档加载器加载文档
docs = loader.load()
# 文档拆分器
# from_tiktoken_encoder 使用tiktoken编码器的文本分割器来计长度。
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50
)
# 文档拆分
splits = text_splitter.split_documents(docs)
# 实例化 embedding 模型 AzureOpenAIEmbeddings
embeddings = AzureOpenAIEmbeddings(
model=os.environ.get("AZURE_EMBEDDING_TEXT_MODEL")
)
# 构建向量索引
vectorstore = FAISS.from_documents(
documents=splits,
embedding=embeddings
)
return vectorstore.as_retriever()
提问回答:prompt + 检索 + llm
ini 代码解读复制代码 from operator import itemgetter
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
web_url = full_chain.invoke({"question": question})
retrieval = get_retrieval(web_url)
question = "Go语言为什么值得学习"
# retrieval.invoke(question)
end_chain = (
{"context": retrieval | format_docs, "question": RunnablePassthrough()}
# {"context": retrieval}
| prompt
| llm
| StrOutputParser()
)
# question = "Go语言为什么值得学习?"
end_chain.invoke(question)
上面的代码我们已经看到过好多遍了。
- 将
url指定的网络加载并解析
- 使用
embedding model进行向量化+保存 - 回答:prompt + 检索 + llm
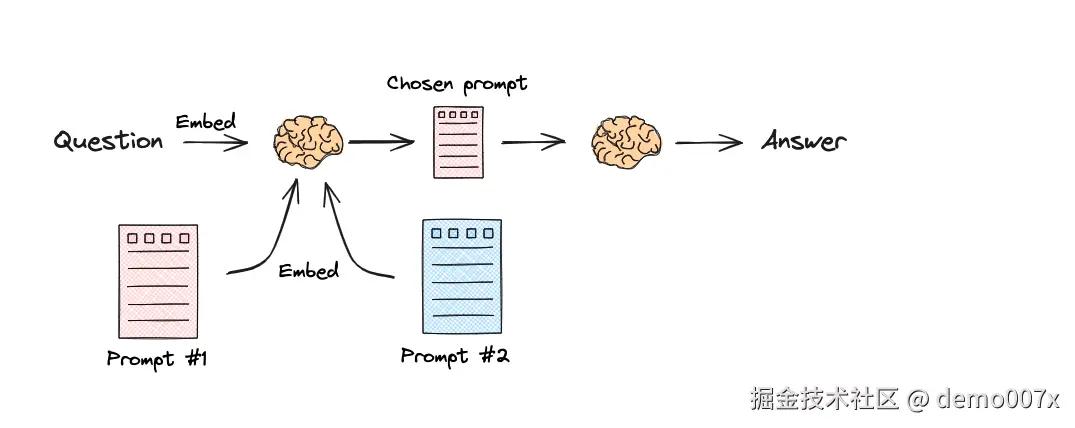
语义路由
路由允许创建非确定性链,其中上一步的输出定义下一步。路由有助于为与 LLM 的交互提供结构和一致性。
有两种方式执行路由:
- 有条件地返回可运行对象
RunnableLambda(推荐) - 使用
RunnableBranch。
示例
ini 代码解读复制代码 from langchain.utils.math import cosine_similarity
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_openai import AzureChatOpenAI, AzureOpenAIEmbeddings
# 定义一个物理老师的 prompts
physics_template = """You are a very smart physics professor. \
You are great at answering questions about physics in a concise and easy to understand manner. \
When you don't know the answer to a question you admit that you don't know.
Here is a question:
{query}"""
# 定义一个数学老师的 prompt
math_template = """You are a very good mathematician. You are great at answering math questions. \
You are so good because you are able to break down hard problems into their component parts, \
answer the component parts, and then put them together to answer the broader question.
Here is a question:
{query}"""
# 实例化 embedding 模型 AzureOpenAIEmbeddings
embeddings = AzureOpenAIEmbeddings(
model=os.environ.get("AZURE_EMBEDDING_TEXT_MODEL")
)
llm = AzureChatOpenAI(
azure_deployment=os.getenv("AZURE_DEPLOYMENT_NAME_GPT35"),
temperature=0
)
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates)
# 路由选择 prompt
def prompt_router(input):
# 向量化问题
query_embedding = embeddings.embed_query(input["query"])
# 比较相似性, 这里是公式计算,并没有是用到 LLM 相关
similarity = cosine_similarity([query_embedding], prompt_embeddings)[0]
most_similar = prompt_templates[similarity.argmax()]
# 选择 prompt
print("Using MATH" if most_similar == math_template else "Using PHYSICS")
return PromptTemplate.from_template(most_similar)
chain = (
{"query": RunnablePassthrough()}
| RunnableLambda(prompt_router)
| llm
| StrOutputParser()
)
print(chain.invoke("什么是黑洞"))
上面的代码是一个语义路由的示例,首先定义两个 prompt,一个是关于 physics,另一个mathematician,然后将 prompt 和 query 计算相似性,从而选定需要提交给 LLM 的 prompt。最后让 LLM 结合给定的 prompt 和 query 来回答问题。
基于查询构造的元数据路由
检索中最重要的步骤之一是将文本输入转换为正确的搜索和过滤参数。从非结构化输入中提取结构化参数的过程就是我们所说的查询结构化。

许多向量存储包含元数据字段。这使得我们可以基于元数据对特定块进行过滤。
例如,假设您有一个向量存储,其中包含不同类型的文档,例如技术文档和非技术文档。
假设我们已经创建了一个向量库:
- 允许我们在每个文档的“内容”和“标题”上执行非结构化搜索
- 并且对“查看次数”、“发布日期”和“长度”进行范围过滤。
我们希望将自然语言转换为结构化搜索查询。我们可以为结构化搜索定义查询模式。
示例
下面我们定义一个结构化的数据类
python 代码解读复制代码 import datetime
from typing import Literal, Optional, Tuple
from langchain_core.pydantic_v1 import BaseModel, Field
class TutorialSearch(BaseModel):
"""搜索数据库中与相关的视频数据。"""
content_search: str = Field(
...,
description="Similarity search query applied to video transcripts.",
)
title_search: str = Field(
...,
description=(
"Alternate version of the content search query to apply to video titles. "
"Should be succinct and only include key words that could be in a video "
"title."
),
)
min_view_count: Optional[int] = Field(
None,
description="Minimum view count filter, inclusive. Only use if explicitly specified.",
)
max_view_count: Optional[int] = Field(
None,
description="Maximum view count filter, exclusive. Only use if explicitly specified.",
)
earliest_publish_date: Optional[datetime.date] = Field(
None,
description="Earliest publish date filter, inclusive. Only use if explicitly specified.",
)
latest_publish_date: Optional[datetime.date] = Field(
None,
description="Latest publish date filter, exclusive. Only use if explicitly specified.",
)
min_length_sec: Optional[int] = Field(
None,
description="Minimum video length in seconds, inclusive. Only use if explicitly specified.",
)
max_length_sec: Optional[int] = Field(
None,
description="Maximum video length in seconds, exclusive. Only use if explicitly specified.",
)
def pretty_print(self) -> None:
for field in self.__fields__:
if getattr(self, field) is not None and getattr(self, field) != getattr(
self.__fields__[field], "default", None
):
print(f"{field}: {getattr(self, field)}")
现在,我们提示LLM生成查询。
ini 代码解读复制代码 from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Given a question, return a database query optimized to retrieve the most relevant results.
If there are acronyms or words you are not familiar with, do not try to rephrase them. answer in chinese"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = AzureChatOpenAI(
azure_deployment=os.getenv("AZURE_DEPLOYMENT_NAME_GPT4"),
temperature=0
)
structured_llm = llm.with_structured_output(TutorialSearch)
query_analyzer = prompt | structured_llm
question = "RAG优化技巧有哪些?"
query_analyzer.invoke({"question": question}).pretty_print()
content_search: RAG优化技巧
title_search: RAG优化
输出示例:
yaml 代码解读复制代码 query_analyzer.invoke(
{"question": "videos on chat langchain published in 2023"}
).pretty_print()
# 输出结构化结果
content_search: chat langchain
title_search: langchain
earliest_publish_date: 2023-01-01
yaml 代码解读复制代码 query_analyzer.invoke(
{"question": "videos that are focused on the topic of chat langchain that are published before 2024"}
).pretty_print()
# 输出结构化结果
content_search: chat langchain
title_search: chat langchain
latest_publish_date: 2024-01-01
yaml 代码解读复制代码 query_analyzer.invoke(
{
"question": "how to use multi-modal models in an agent, only videos under 5 minutes"
}
).pretty_print()
# 输出结构化结果
content_search: how to use multi-modal models in an agent
title_search: multi-modal models agent
max_length_sec: 300
从上面的示例可以看到,我们可以将用户的一个 query 转换为一个结构化的数据。这样我们可以使用结构化的数据进行数据库的查询逻辑。
总结
想要构建一个比较灵活的、功能强大的、可复用的 RAG 应用, 路由的能力是很重要的,它可以动态规划要查询的数据源,从而保证结果的正确性。
- 逻辑语义路由
- 查询构造路由
这两种策略可以分别是用在不同的场景,同时也可以赋予 Agent 更大的能力。
相关文章
需要源码的评论区回复: 如果对你有帮助,点赞?+收藏。关注下篇文章
评论记录:
回复评论: