
1 业务背景
DMP(数据管理平台)为广告部门提供B站用户数据的管理。主要功能包括用户标签收集存储,标签市场建设,人群包圈选,人群画像分析,人群/特征定向几大功能模块。
其中人群包圈选和人群画像分析是两大核心功能。对设计,性能,扩展性,可维护性都有比较高的要求。也是本文中要讨论的ClickHouse技术的应用场景。在实践中,我们利用ClickHouse的bitmap相关功能,实现了人群包的实时预估和计算,也实现了人群包画像的分钟级计算。
下面先简单介绍下人群包圈选和人群画像两个功能。
1.1 人群圈选
所谓人群圈选,就是由用户根据标签指定一系列规则,然后通过这个规则把满足条件的人群圈选出来。假设我们用户有”性别”,“年龄”,“地域”三个维度的标签,那么圈选规则就可以是”性别男,年龄>30,北京地区”。该系统需要根据圈选规则实时输出满足条件的人数和人群包。
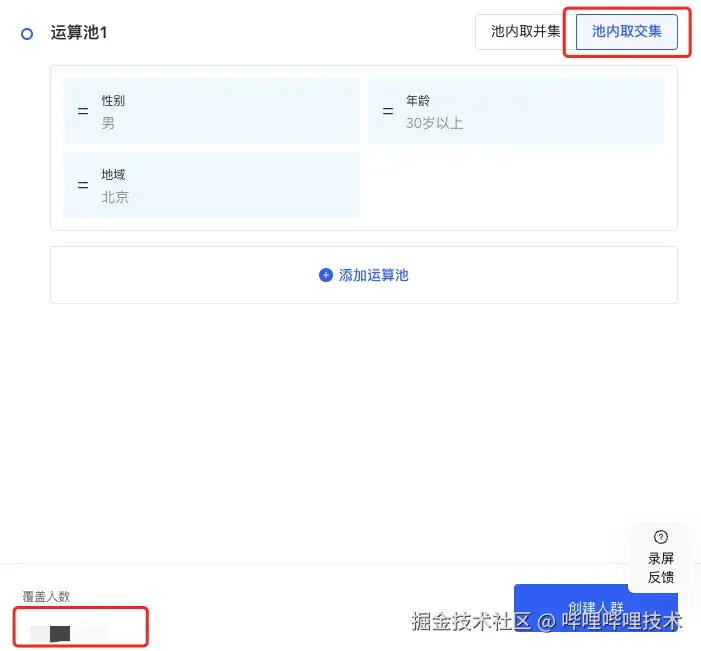
如上图所示,用户使用了性别,年龄,地域三个标签取了交集,在下方实时显示了对应的覆盖人数。
这里的技术难点在于
- 用户的圈选的规则非常灵活,可能涉及数十种标签或人群包的交并运算,并且要求实时显示计算结果。商业DMP中现有大约数百种标签,hive表中原始数据量PB级,如果采用直接查hive表的方式,显然是无法满足性能要求的。
- 人群包数量多,目前日新增数百个人群包,加上需要刷新的旧人群包,每天需要计算上万个人群包。
因此基于以上需求,需要设计一种高效灵活,可扩展的人群圈选手段。
1.2 人群画像
用户打好人群包之后,可以对人群包中的用户特征分析,如查看用户的年龄,性别,地域分布,兴趣爱好,up主关注,互动等等。例如下图所示:

计算用户画像的基本原理是需要用人群包中的用户id与每一个需要洞察的标签值所对应的用户id取交集,求出交集的人数后,计算该标签值在人群包中的百分比或TGI。例如:标签值"男"占比XX%, 标签值"女"占比XX% 。人群画像的技术难点有:
- 人群包人数多,从数万到亿。
- 计算量大,目前画像包含数十个维度,每日按人群包X维度计算百分比和tgi排名,涉及数亿次bitmap交并运算。
最早的DMP使用离线hive sql进行画像计算,平均一个包画像要等待2个小时,引入ClickHouse Bitmap技术后,画像时间降到了分钟级。
2 基于bitmap的人群圈选
2.1 bitmap基本原理及其在人群圈选中的应用
bitmap是一种数据结构,可以用来表示一系列正整数的集合。底层是一系列连续的二进制bit位,每个bit位有一个索引序号,依次用1,2,3,4,5...自然数编号。每个bit位有两种状态,0或1。如果bit位为0表示这一位对应的索引序号的数字不在集合里,相反,如果bit位为1,表示对应的索引序号的数字在集合中。例如bitmap内容是01101,其中第2,3,5位(从左到右)是1,则该bitmap代表整数集合{2,3,5}。
B站用户id是一个64位正整数,从1开始编号,无限增加。根据前面的描述,可以用bitmap来代表一系列id的集合。也就是说每个人群包的id集合都可以用一个bitmap来表示。
我们可以在逻辑上给每个标签值创建一个bitmap,表示所有具有该标签属性的人群。这样人群包的圈选就等价于多个标签bitmap的交并差运算。以前面提到的规则”性别男,年龄>30,北京地区”为例,人群圈选过程如下:

如图所示,系统预先分别给男,>30岁,北京地区建立三个bitmap索引,如果相应索引位的id在集合中,则把对应位置的bit位设置为1。根据人群圈选规则,对三个bitmap进行AND位运算,得到最终bitmap结果,也就是最终的人群包中包含{2,5,7,9}四个id。
以上就是基于bitmap圈选人群包的基本原理,在具体应用中,还解决了很多工程上的问题,例如:
-
支持可扩展的,任意维度的标签圈选。目前支持标签数量>300种,总数据量>1PB
-
打通离线数仓与ClickHouse之间的数据流,实现数仓到ClickHouse和ClickHouse到数仓的双向数据格式转换和传输,以及标签元数据管理机制。
-
一个包含亿级别的bitmap大小有数百MB,如果只存储在单个bitmap中会导致计算效率下降,因此需要对bitmap的存储方式进行优化。
-
开发相比原始ClickHouse sql更易于使用的DSL,通过DSL提高系统的易用性,扩展性和执行效率。
2.2 实践中遇到的bitmap相关问题
在具体实践中,我们发现bitmap可以很好的解决离散标签值的计算,对于亿级的人群计算通常可以在5秒内完成。可以满足大多数人群计算需求。但是仍然存在一些明显的问题。
id不连续导致的性能问题
ClickHouse中使用Roaring Bitmap存储bitmap数据,而在Roaring Bitmap内部,数据存储在不同类型的container中,不同类型的container具有不同的空间成本和计算时间复杂度。Roaring Bitmap内的数据存储为哪种类型的container是由数据特性决定的,其中一个重要特性就是数据的连续性。分布稀疏的数据连续性低,在Roaring Bitmap中消耗的空间成本和计算时间复杂度都会更高(有关Roaring Bitmap的内部存储结构及其对计算存储性能的影响在此不做详细论述,有兴趣的读者可参见文章基于改进字典的大数据多维分析加速实践中的第4章节)。
B站用户的id是整型数据,我们在实践中发现,id的分布非常稀疏,连续性低,这就造成bitmap体积膨胀,无法达到最佳性能,尤其是在计算画像时,需要对数百万的bitmap进行交并运算,bitmap体积过大,对磁盘IO和CPU都有很大的压力。因此如何采用合适的方法让bitmap中的id尽量连续分布,是我们的一个主要优化方向。
对于非离散标签圈选支持受限
DMP的标签中大部分都是离散标签查询,每个标签值对应一个bitmap。所谓离散标签值是指枚举类的标签值,例如性别,年龄,地域,关注的up主都属于此类。对于这种标签,每个标签值对应的id聚合成bitmap后写入ClickHouse是比较自然的选择,ClickHouse对此类标签的交并查询支持也很好。
但是在业务需求中,还存在一些非离散的指标查询,例如:“找出最近一个月某个广告单元曝光次数大于N次的人“,”找出最近一个月某稿件播放时长大于N分钟的人“。这些查询的特点是需要在一定时间范围内对某个实体的相关指标进行聚合,以广告曝光次数为例,对应的hive sql大概如下所示:
sql 代码解读复制代码SELECT
id
FROM (SELECT id, unit_id FROM ad_event_table WHERE
event='show' -- 曝光
AND unit_id IN (11111, 22222) -- 单元id列表
AND log_date >= '${yyyyMMdd, -360d}' -- 近一年
GROUP BY unit_id, id -- 按id + unit_id聚合
HAVING COUNT(1) > N -- 找出每个单元曝光次数大于N次的id ) t0
GROUP BY id -- 所有单元曝光次数>N的id进行去重
如果直接执行一个这样一个hive sql,涉及的广告曝光底表近一年的数据可能有数百G之多,至少要几分钟才会获得结果,显然是无法满足dmp人数实时预估的要求的。
如果把一年的明细数据导入ClickHouse,在ClickHouse中做类似的查询并把id实时聚合成bitmap,同样面临数据量大,无法满足秒级人数预估的要求。作为一个折中的办法,DMP中对于类似的查询规定了一系列固定的时间窗口,如近30天,60天,90天,180天等等,事先通过离线任务按照固定的时间窗口对每个指标进行预聚合,把每个固定时间窗口内满足某个指标的人事先聚合成bitmap写入ClickHouse,用户圈人的时候只能对固定的几个时间窗口内的指标进行圈选。还是以上面单元近一年曝光为例,ClickHouse中的查询如下:
sql 代码解读复制代码SELECT groupBitmapOr(uid_index) AS `uid_index` -- id bitmap
FROM tag_index_table
WHERE (tag_name='ad_show') -- 广告曝光
AND (log_date='${yyyyMMdd}') -- 每天更新全量数据
AND (tag_value IN ('360D-11111','360D-22222')) -- 事先聚合好360天的单元曝光,把范围查询变成几个固定时间区间的点查
AND (metric>=N) -- 曝光指标 > N
上述查询是把采用预聚合的方法把标签值(单元id)+时间(天数)+指标值(metric)进行聚合,可以把范围查询近似成点查,满足实时计算的需求,通常也可以在秒级返回结果。但是这种方案仍然有以下问题:
- 预聚合数据量大,多个时间窗口存在数据冗余,某些标签要处理每天都要处理近一年的数据,有数百G到TB级,并且30,60,90等不同时间窗口存在重叠,有数据冗余。
- 标签值x指标值造成标签数据膨胀。指标值(metric)为非离散数据, 如曝光次数,播放时长,指标值可能在0到数千之间分布,假设某个广告单元有1000个指标值,那仅这一个广告单元就会有1000个bitmap(每个bitmap对应一个指标值),这就造成表中的数据行数很多,索引变大,增加了内存和缓存的开销。
- 圈选方式不灵活。预处理的时间窗口只能处理一些典型的查询,还有很多客户就是要求实时圈选任意日期范围内的指标,对于这部分需求clikhouse无法满足,只能采用spark离线计算。系统就分成了ClickHouse实时计算和spark离线计算两个部分,增加了系统的复杂度和开发成本。
基于以上原因,我们也需要寻找一种更高效,更灵活的非离散指标标签圈选方案。
3 ClickHouse字典服务
ClickHouse字典服务是B站ClickHouse团队针对多个需要在ClickHouse中用Roaring Bitmap做交并补计算的场景而设计开发的一套字典映射服务。关于ClickHouse字典服务的架构及实现,本文不做详细介绍,感兴趣的读者可参见文章基于改进字典的大数据多维分析加速实践中的4.3章节,本文下一章节主要阐述该服务在DMP场景下的应用姿势及效果。
4 ClickHouse字典服务在DMP中的应用
4.1 应用姿势
首先,使用ClickHouse字典服务对于DMP场景有以下两个好处:
- 字典服务的id是按顺序分配的,可以让id集中到更小的空间里,对于bitmap来说,id越集中,所生成的bitmap体积越小,运算效率越高。
- 标签圈选不再局限于整数类型的id,通过字典服务把任意字符串映射成一个整数,比如设备号,buvid等等,为将来的产品功能扩充提供了更大的可能性。
加入字典服务后,整个数据流程如下:
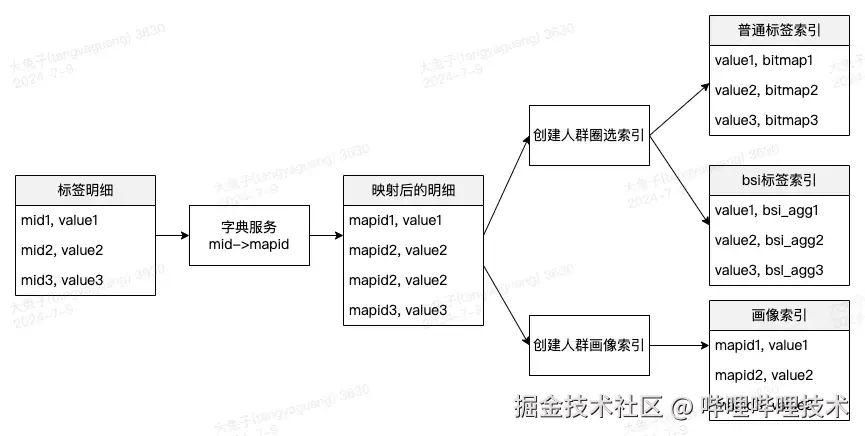
如图所示,在原始的id明细表调用字典服务做一次id映射,然后把映射后的id聚合成bitmap。具体还做了以下优化:
-
为了提高效率,减少线上压力,字典服务每天导出一张离线hive表,业务方先关联hive表获取映射id,如果离线hive表中不存在,则通过RPC实时调用字典服务。字典初始化之后,离线表的映射率通常在90%以上,可以极大的减少线上服务的实时压力。
-
优化了ClickHouse中不同shard中id的分片算法,每个id是一个64位整数,给定N个分片,则取个id的高48位(17~64位)对N取模,模数相同的id属于通一个bitmap分片。之所以采用这种方法分片,是考虑到ClickHouse bitmap存储的特点,让低16位连续的id尽量处于同一个分片中,因为bitmap中连续的bit位越多,可以采用压缩算法减少体积,提高计算效率。经过测试,在同等条件下,这种优化的分片方式比id直接对分片数N取模,要节省30%的存储,计算速度快一倍以上。
4.2 优化效果
引入ClickHouse字典服务后,我们在存储成本、写入性能、查询性能等方面均取得了显著收益,具体如下文所述。
存储成本收益
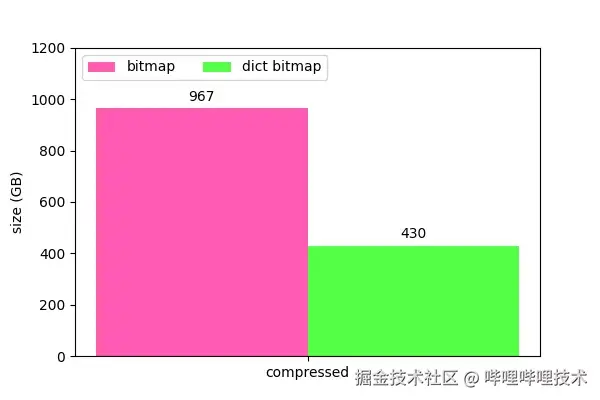
存储空间上,对于千万到上亿级别的bitmap,体积减少了约4.5倍,对于万级别的小bitmap减少约1.4倍,平均减少3倍左右。bitmap越大,收益越大。
整体存储空间收益如下图所示:
查询性能收益
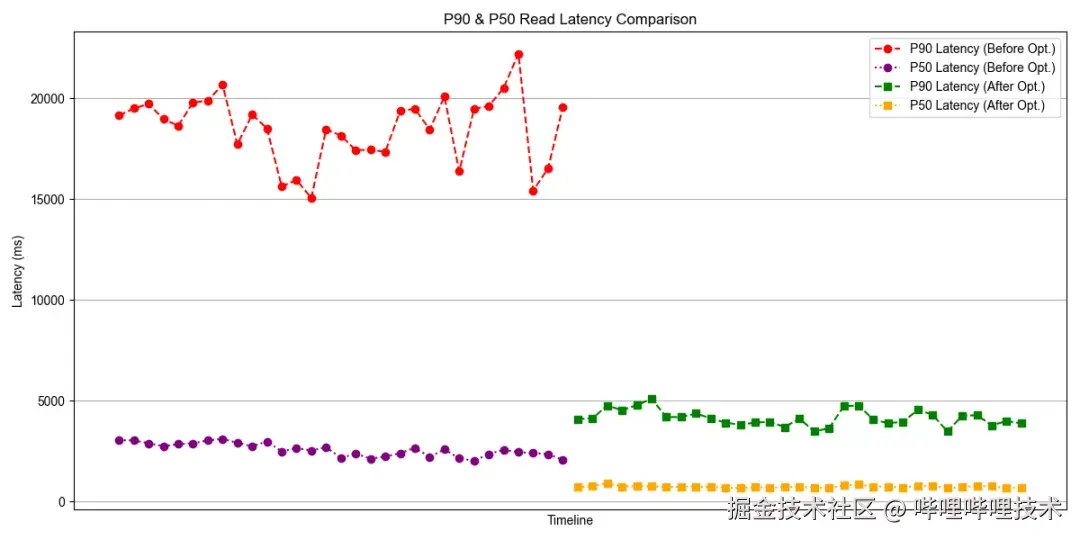
对于查询延迟较高的人群画像计算,引入ClickHouse字典服务后查询性能大幅提升,end2end查询延迟由之前的20分钟提升到3分钟,提升了6.7倍。
从ClickHouse引擎侧观察,DMP场景整体查询P50,P90延迟优化效果如下图所示:
写入性能收益
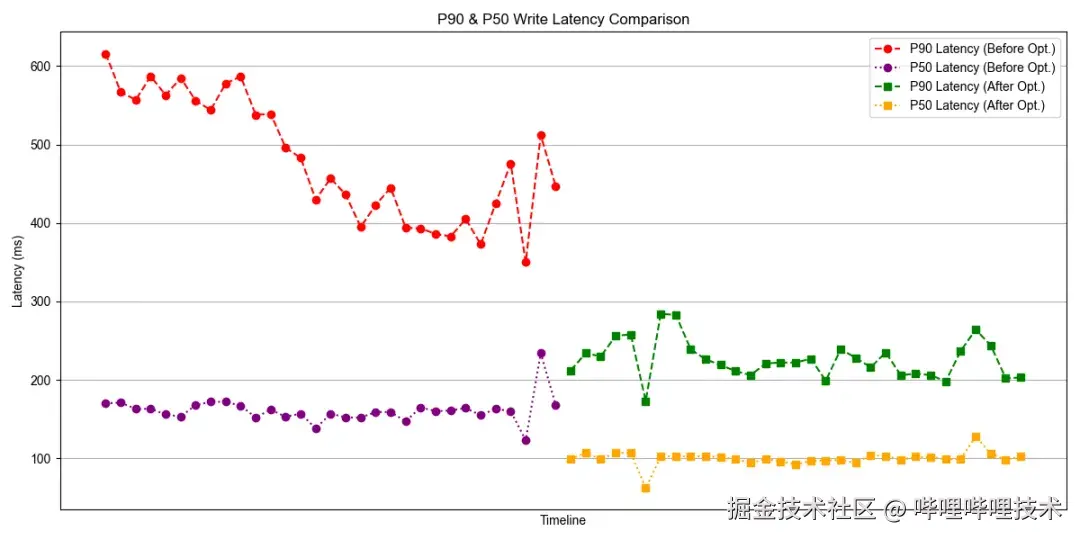
在写入方面,p90写入延迟降低了2x+,p50写入延迟降低了1.5x。
整体写入P50,P90延迟优化效果如下图所示:
5 BSI原理简介及其在ClickHouse中的功能实现
5.1 BSI原理简介
BSI(Bit-slice index)的数据结构由一组bitmap组成,其中每个bitmap用于表示二进制整型metric在对应比特位上取值为1的实体id集合。
下图展示了将5个实体id及其对应的整型metric value转换成BSI表示形式后的效果:
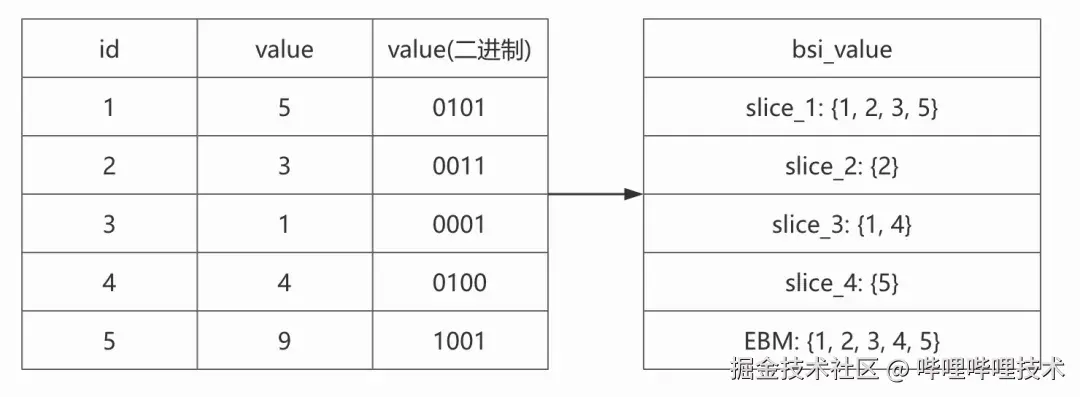
从上图的转换中,我们可以总结出BSI数据结构的以下特征:
- BSI的slice个数由最大整型值的二进制位数决定
- 每个slice都是一个bitmap
- 每个slice对应一个比特位:slice_i 存储第i个比特位上取值为1的metric value对应的所有实体id的集合
如上文所述,bitmap适用于离散值标签的人群圈选计算场景,而BSI则更适合针对连续值指标的人群圈选计算场景。除此之外,BSI也适合用于人群圈选完成之后的人群效果指标分析场景(比如,计算某个指定人群包的平均曝光次数)。
5.2 BSI在ClickHouse中的功能实现
BSI数据类型
在ClickHouse中,我们将BSI封装成一个新的数据类型,用户可以根据自己的需求定义BSI类型字段并配合ClickHouse中的aggregating mergetree引擎建表,建表示例如下:
less 代码解读复制代码CREATE TABLE test.bsi
( `log_date` Date,
...
`ck_bucket` UInt32,
`bsi_agg` AggregateFunction(bsi_merge_agg, BSI)
)
ENGINE = AggregatingMergeTree
PARTITION BY log_date
ORDER BY ck_bucket
TTL ...
具体实现上,BSI本质上就是Bitmap Array,所以我们并没有重新实现一个独立的数据类型,而是基于ClickHouse内部的自定义数据类型注册机制,将Bitmap Array类型注册为一个新的BSI数据类型。
除了各个比特位对应的slice bitmaps之外,BSI类型数据中还存储了一个existence bitmap(EBM),用于表示所有metric取值非空(not null)的实体id集合。EBM可用于加速某些BSI计算,并且对于某些BSI functions而言EBM是必需的。
BSI Functions
我们在ClickHouse中实现了许多BSI Functions,包括:
- 用于从明细数据构建BSI的bsi_build
- 用于对单个BSI进行过滤,求和等操作的bsi_filter, bsi_sum, bsi_range, bsi_lt, bsi_gt, bsi_topk, etc
- 用于对BSI数据列做聚合的bsi_add_agg, bsi_merge_agg, etc
关于各个BSI Function的功能细节这里不做详细阐述,有兴趣的读者可参见引用[2]。
由于BSI Functions的底层实现上依赖于Roaring Bitmap的交并补计算,所以对组成BSI的Roaring Bitmap做ClickHouse字典服务映射也能够大幅提升BSI Functions的计算性能。
6 BSI+字典服务方案在DMP场景的 落地及效果
6.1 落地姿势
针对DMP场景下连续值指标圈选困难的问题,我们基于连续值指标的明细数据构建出连续值指标的BSI数据,然后导入到ClickHouse中通过BSI Functions即可对连续值指标进行任意时间范围内的圈选,解决了原来只能预聚合固定时间窗口的查询限制。
下图是写入与查询BSI数据的整体流程:
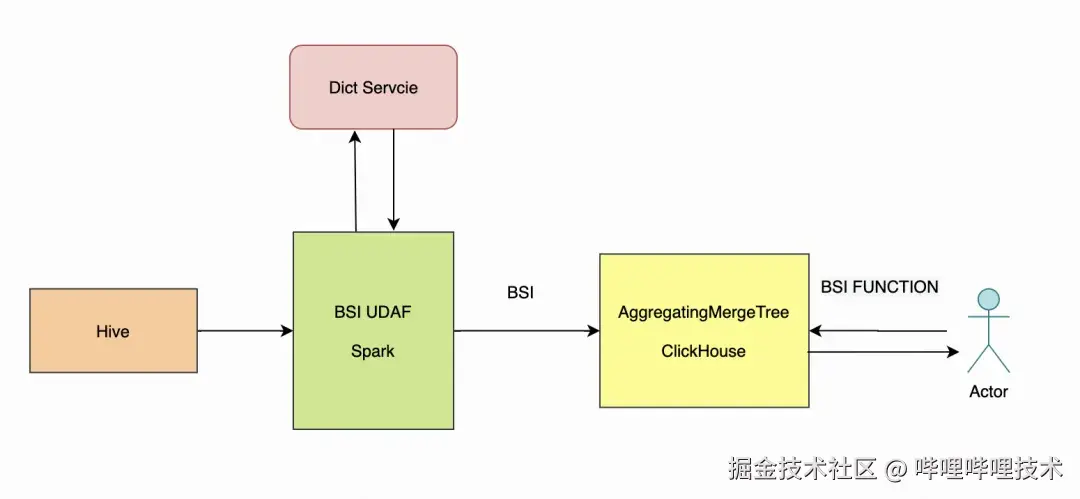
BSI数据写入
我们的明细数据存储在离线数仓Hive表中,利用Spark程序将Hive上的明细数据转换成BSI(bitmap array)结构后写入到ClickHouse表中。其中,Spark数据同步程序会调用生成BSI数据的UDAF将明细数据组装成为BSI,同时会调用ClickHouse字典服务进行字典映射转换,从而降低BSI的存储成本和查询延迟。
以上文提及的广告曝光查询为例,使用BSI后,数仓开发在进行数据处理时不再需要按照标签值(单元id)+时间(时间窗口天数)+指标值(metric)进行聚合,每天只需要处理当天的增量日志即可,把当天增量的单元曝光聚合成一个BSI即可。
BSI数据查询
上述BSI写入ClickHouse后,业务方就可以通过bsi相关的函数在ClickHouse中实时查询,以广告曝光为例,一个典型的表结构和查询语句如下所示:
sql 代码解读复制代码CREATE TABLE tag_bitmap_bsi
(
`tag_name` String,
`tag_value` String,
`log_date` Date,
`sp_bucket` UInt32,
`sk_bucket` UInt32,
`ck_bucket` UInt32,
`bsi_agg` AggregateFunction(bsi_merge_agg, BSI)
)
ENGINE = ReplicatedAggregatingMergeTree(...)
PARTITION BY (toYYYYMMDD(log_date), tag_name)
ORDER BY (sp_bucket, tag_value, ck_bucket)
TTL ...
SELECT groupBitmapOr(bsi_ge(bsi_agg, N)) AS `uid_index` -- 180天内曝光次数>N次的id组成的bitmap
FROM
(
SELECT bsi_add_agg(bsi_agg) AS `bsi_agg`
FROM
(
SELECT tag_value, bsi_merge_aggMerge(bsi_agg) AS `bsi_agg` -- 一天之内的指标合并(去重)
FROM
tag_bitmap_index_mapped_bsi
WHERE (tag_name = 'ad_show') AND (log_date > '${yyyyMMdd}' - INTERVAL 180 DAY -- 近180天 ) AND (tag_value IN ('11111', '22222'))
GROUP BY tag_value, log_date
)
GROUP BY
tag_value -- 最终累加出180天内所有的指标
)
6.2 落地过程遇到的问题及其解决方案
在将BSI落地到,我们遇到了以下问题:
- 在Spark数据同步程序中生成的单个BSI过大,导致spark中的一个row对象过大,在Kyro Serializer做序列化的过程中出现buffer overflow的问题。
- 写入到ClickHouse各个分片的BSI里的bitmap数据分布稀疏,影响BSI查询性能。
- 写入到ClickHouse单个分片的BSI的基数过大(即包含的实体id过多),导致单分片BSI的查询性能较低。
- ClickHouse中由于分批写入导致存储的BSI个数过大,影响BSI的查询性能。
为了解决上述问题,我们做了以下设计与优化:
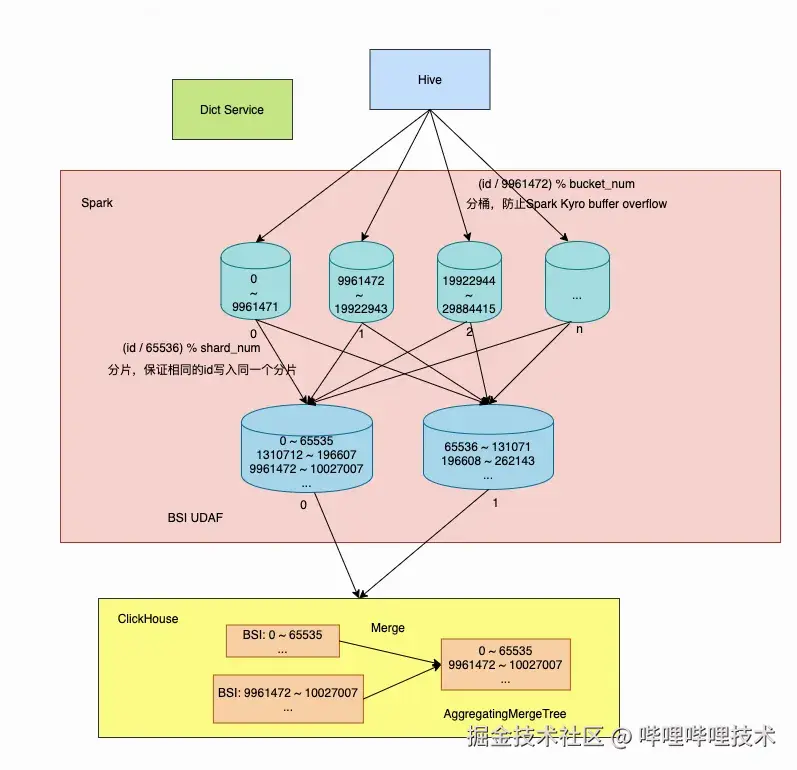
-
在Spark数据同步程序中对明细数据做分桶处理,以避免单条BSI记录过大导致Kryo Serializer的buffer overflow问题。
-
在Spark数据同步程序中引入ClickHouse字典服务,对分布稀疏的实体id做字典映射,提高BSI内数据的连续性,从而提升BSI查询性能。
-
使用实体id的高48位做sharding,让实体id高48位相同的数据都写入到相同的ClickHouse分片中,降低单个分片中BSI的基数,同时进一步提高BSI内数据的连续性,从而提升BSI查询性能。
-
使用AggregatingMergeTree作为表引擎,分批写入的小BSI数据异步聚合成更大的BSI数据,减少ClickHouse中的BSI记录个数,从而提升BSI查询性能。
6.3 落地效果与收益
产品功能增强
引入BSI后,DMP在产品功能上得到以下增强与优化:
-
实现了任意日期的指标人群圈选,不再局限于几个固定的时间窗口,扩展了业务的应用场景。
-
去除了部分通过spark sql离线计算流程,把所有人群包相关的计算统一到ClickHouse里,简化了系统设计。
-
对于广告曝光,稿件播放这种数据量大标签时间范围从30天提升到一年,提升了产品的能力。
整体场景查询性能
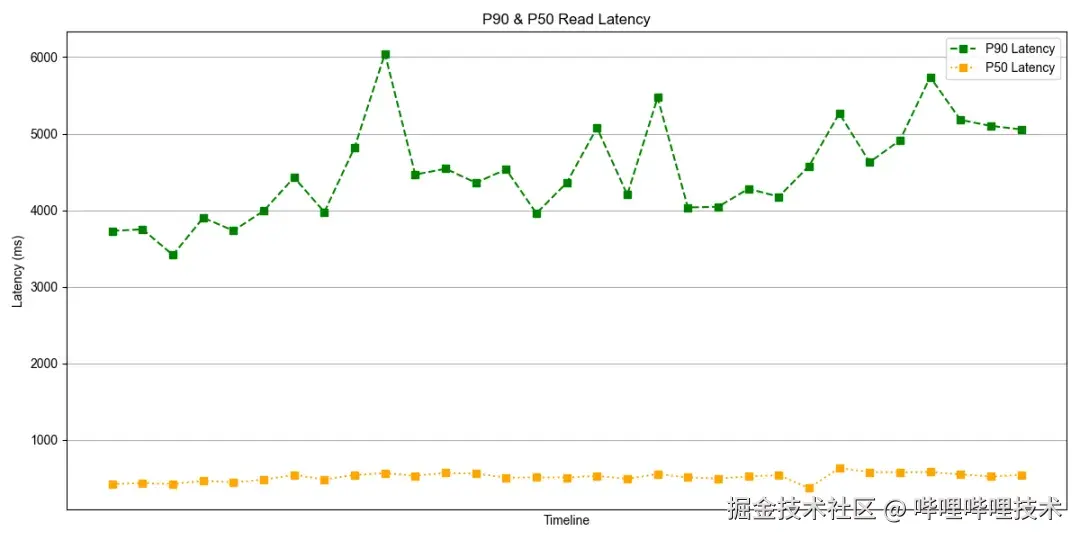
受益于BSI和字典服务对查询性能和存储成本的优化,生产业务在使用BSI+字典服务的方案后,将之前30天~90天的时间范围圈选扩大到了一年,目前整体的p50查询延迟可以保证在500ms左右,p90查询延迟可以保证在5s左右。
存储成本收益
相较于通过预聚合不同时间范围的bitmap数据来支持任意日期范围的人群圈选,BSI+字典服务的方案在存储成本上具有显著优势,以下是一个支持5天内任意日期范围圈选场景下,预聚合bitmap方案和BSI方案的存储成本对比:
| 方案 | 行数 | 大小(压缩前) | 大小(压缩后) |
|---|---|---|---|
| 预聚合bitmap | 663 | 40732860 | 38043990 |
| BSI+字典服务 | 5 | 1790465 | 1753776 |
可以看到,BSI+字典服务的方案与预聚合Bitmap方案的存储比约为1:21。
查询性能收益
相较于原Bitmap方案,BSI+字典服务的方案在查询性能方面也有明显优势。下图为一个90天范围内圈选场景,原Bitmap方案和BSI方案的查询延迟对比:
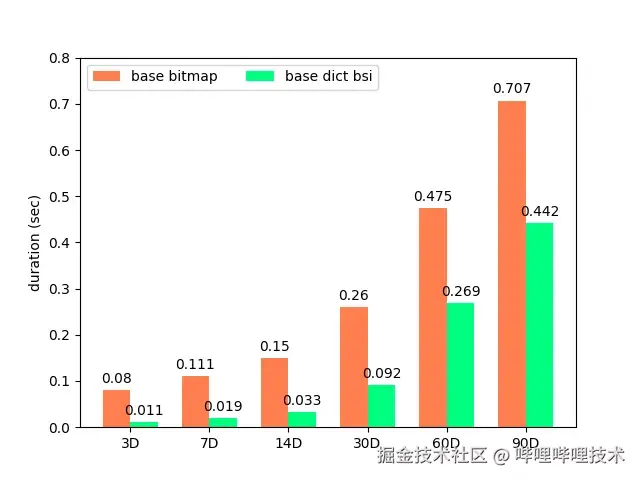
7 总结与展望
本文重点介绍了DMP场景的业务需求及实践过程中遇到的问题,并详细阐述了我们如何利用ClickHouse字典服务和BSI技术优化增强DMP产品功能,提升整体查询性能,降低资源成本。
目前BSI+字典服务方案已经在B站商业化DMP场景完成落地上线,未来我们将重点在以下方向完善增强我们的产品功能:
-
工程化BSI+字典服务方案的数据接入流程,为用户提供更为便利的接入体验,让BSI+字典服务方案赋能更多商业化业务场景。
-
探索BSI+字典服务的实时链路建设,在低成本低查询延迟的前提下,为用户提供更高的end2end数据时效性。
-
得益于字典对人群圈选性能的提升,商业化业务正在尝试扩展人群圈选的业务范围,例如投放端定向人数预估,预计24年Q4可以落地。
-
商业化DMP中尝试BSI的更多应用场景,例如用于多维度广告相关指标人群的画像分析。
引用
-
BSI Introduction From Hologres(*www.alibabacloud.com/help/en/hol…
-
BSI Function Introduction From Hologres(*www.alibabacloud.com/help/en/hol…
-End-
作者丨大兔子、王智博、douNaiK1ng
评论记录:
回复评论: