
论文arXiv地址:arxiv.org/abs/2412.10…
文章导读
动画在影视工业中是相当重要的一个领域。尽管当前先进的视频生成模型比如Sora、可灵或智谱清影在生成三次元视频上取得了成功,他们在处理动画视频时却缺乏同样的效果。此外,由于独特的艺术风格、打破物理规则以及夸张的动作,评估动画视频生成结果也是一个巨大的挑战。
在我们的工作中,我们提出了一个专为动漫视频生成设计的综合系统AniSora,包括数据飞轮、可控的生成模型和一个评估基准。在数据飞轮提供了10M以上高质量数据的支持下,生成模型加入了一个时空掩码模块来实现关键的动画制作功能比如图生视频、视频插帧和局部图像引导动画。我们收集了一个包含了948个不同的动画视频的评估基准。基于VBench指标和人工双盲测试都证明了生成视频在人物和动作上的一致性,取得了在动画视频生成领域行业领先的结果。
业务上,我们的视频生成模型赋能了动态漫内容制作,已经有超过10部自有IP作品运用了AI动态漫能力。相比于人工制作需要专业人员和较长工期,AI动态漫实现了低成本、低门槛、高效率的剧集内容制作,并在多个平台突破千万播放。
概述
我们提出的专为动漫视频生成设计的整套系统AniSora如图1所示。首先,我们的数据处理飞轮提供了超过1000多万个高质量的文本-视频对,构成我们工作的基础。其次,我们开发了一个适用于动画视频生成的统一扩散框架。我们的框架利用时空掩码来支持一系列任务,包括图生视频、视频插帧和局部图像引导动画。通过集成这些功能,我们的系统可以在若干关键帧之间创建平滑的过渡并实现在特定区域的可动控制,例如精确地控制不同角色说话。这为专业动画创作者提供了更高效的创作过程。
此外,我们还提出了一个专门为动画视频评估设计的基准数据集。与主要关注自然景观或现实世界人类动作的现有评估数据集不同,我们的数据集满足了动画视频评估的独特要求。为了实现这一目标,我们收集了横跨多个类别的948个动画视频,并且手动优化与之关联的文本提示词。
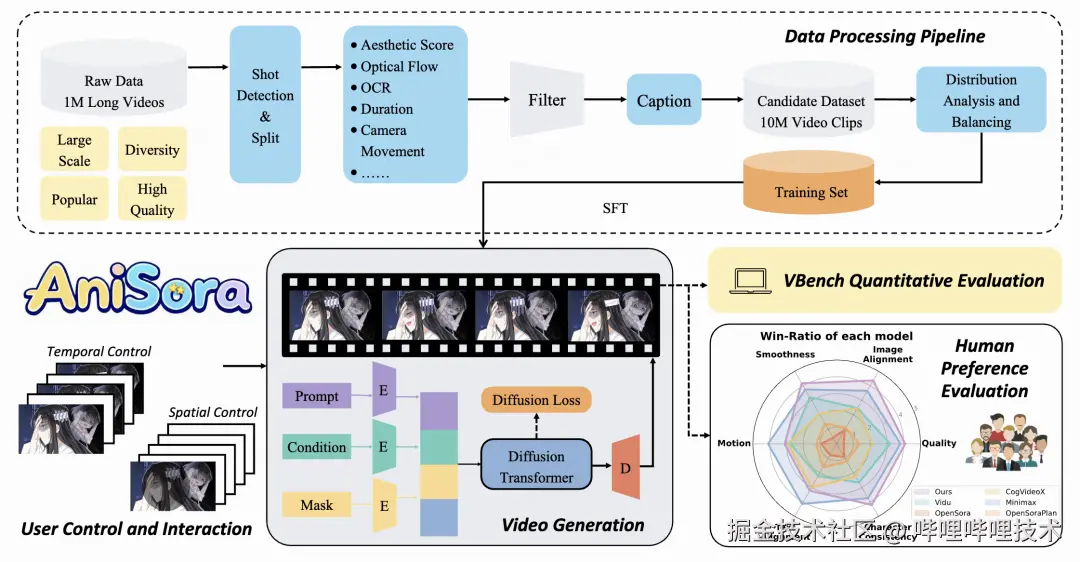
**图1 AniSora整套系统概述**
数据集
我们观察到高质量的文本-视频对是视频生成的基石,这点也被最近的研究所证明。据此我们构建了自己的动画数据集,我们将在本节中对动画数据集构建和评估基准进行详细描述。
动画数据集构建:我们构造了一个数据飞轮从100万个原始动画视频中获得高质量的文本-视频对。首先,我们使用场景检测[1]将原始动画视频分割成片段。然后,对于每个视频片段,我们从四个维度构造了过滤规则:文本覆盖区域、光流得分、美学得分和帧数。过滤规则是通过在模型训练中的观察逐步建立起来的。详细地说,文本覆盖区域得分(通过CRAFT算法[2]得到)可以丢弃掉那些有类似片尾字幕的文本覆盖的片段。光流得分(通过RAFT算法[3]得到)可以防止那些有静止图像或快速闪回场景的片段。美学得分[4]用于保存具有高艺术质量的片段。此外,我们还根据帧数保留持续时间在2s-20s之间的视频片段。在上述四个步骤之后,大约10%的片段(超过1000万段)可以进入训练步骤。此外,我们根据观察到的表现调整特定训练数据的比例(如说话和运动幅度),一些更高质量的片段最终将从训练集中筛选出来,以进一步提高模型性能。
基准数据集构建: 为了直接比较我们的模型和其他最近研究的生成视频,我们手动构建了一个基准动漫数据集。我们收集了948个动画视频片段并标记了不同的动作,如说话、走路、跑步、吃饭、打斗等。其中有857个2D片段和91个3D片段。这些动作标签是从人工注释的100多的常见动作中总结出来的。每个标签包含10-30个视频片段。相应的文本提示词首先由Qwen-VL2[5]生成,然后手动校正以确保文本-视频对齐。
方法
在本节中,我们将展示一种使用扩散transformer(Dit)架构生成动画视频的有效方法,如图2所示。第一小节概述了基础的Dit模型。在第二小节,我们引入了时空掩码模块,该模块扩展了Dit模型,在统一的框架内实现了关键的动画制作功能,比如图生视频、视频插帧和局部图像引导动画。这些增强功能对专业动画制作至关重要。最后,第三小节详细介绍了在动画数据集上采用的有监督微调策略。
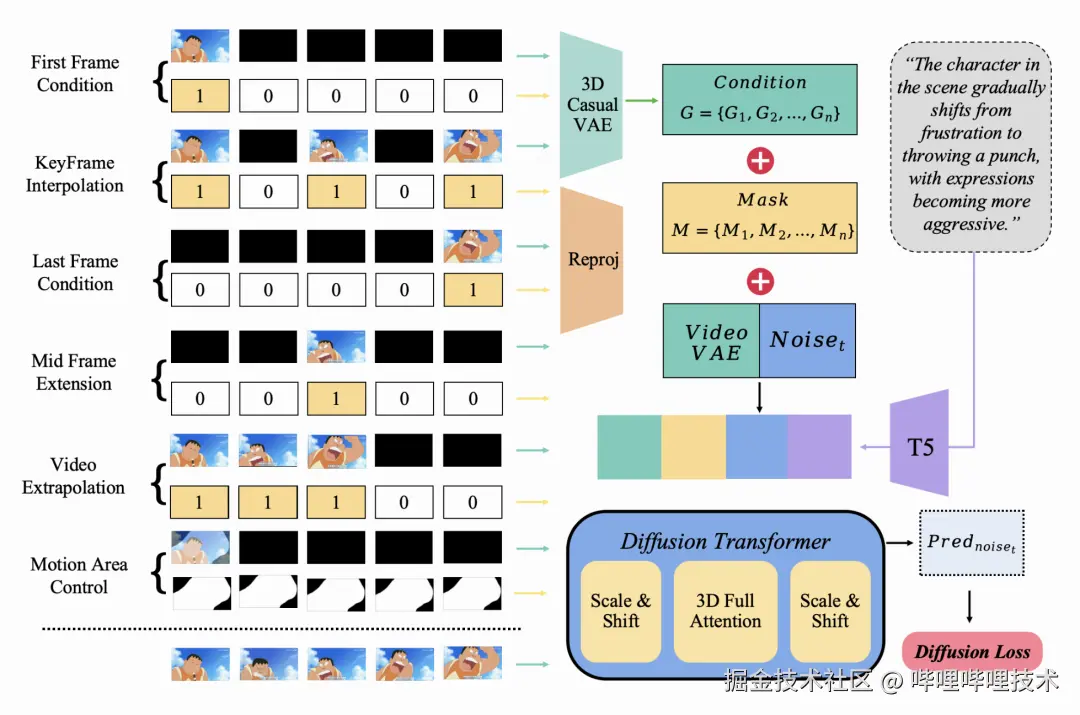
**图2 时空掩码的扩散transformer框架图**
1.基于Dit架构的视频生成模型

2. 时空条件模型
关键帧插帧 通过生成中间帧来创建在关键帧之间的平滑过渡。这是专业动画制作的一个重要阶段,也是艺术家最劳动密集型的任务之一。我们将这一概念扩展到以放置一个或者多个任意帧到视频序列里的任何位置为条件的视频生成。
运动控制 作为我们框架内的一项技术,解决了基于文本控制的局限性,并实现了对运动区域的精确控制。这种方法增强了艺术家对视频内容的控制,使他们能够表达自己创造力的同时大大减少了工作量。
2.1 带掩码的扩散transformer模型

2.2 运动区域控制

3. 有监督的微调
我们使用了一个在3500万个不同的视频片段上预训练的权重初始化我们的模型。随后,我们在自建的动画训练数据集执行全参数监督微调(SFT),使模型专门适用于动画任务。
从弱到强 我们的视频生成模型采用从弱到强的训练策略,以逐步提高其在不同分辨率和帧率下的学习能力。最初,模型在8fps的480P视频上训练3轮,使其能够以较低的帧率捕捉基本的时空动态。在此之后,在16fps的480P视频上进行额外1.9轮的训练,使其能够优化时间一致性并适应更高的帧率。最后,在16fps的720P视频上进行了2.3轮的微调,利用之前学习到的特征生成高分辨率、时序连贯的视频输出。此外,我们使用了前文”数据集“章节提到的更加严格的过滤,生成了100万超高质量数据集用于最后阶段的微调,显著提高了高分辨率视频质量。
删除生成的字幕 我们的训练数据中存在大量带有字幕和平台水印的视频,导致模型在输出中偶尔会产生此类伪影。为了缓解这个问题,我们专门构造了一个完全没有字幕和水印的视频数据集进行了有监督的微调。这个数据集由79万个视频视频片段组成,是通过按比例裁剪含字幕的视频和挑选干净无字幕的视频构建的。然后对模型进行全参数微调。在5500轮迭代后,我们观察到模型在生成结果里有效地消除了字幕和水印,并且不损害整体性能。
时域多分辨率训练 鉴于高质量动画数据的稀缺性,我们采用混合训练策略,使用不同持续时间的视频片段来最大限度地提高数据利用率。具体而言,我们采用可变长度训练方法,训练视频持续时间为2至8秒。该策略使我们的模型能够生成可变长度在2至8秒的720p视频片段。
多任务学习 与现实世界中具有物理一致性的运动模式相比,不同作品的动画风格和动作动态会有很大差异。数据集之间的这种领域差距通常会导致从具有不同艺术风格的引导帧生成的视频存在实质性的质量差异。因此,我们加入了图像生成,形成多任务训练框架来提高模型对多样艺术风格的泛化性。
掩码策略 在训练过程中,我们以50%的均匀采样概率随机打开首帧、尾帧和其他帧的掩码。该策略使模型具备处理任意引导条件的能力,使其能够执行比如视频过渡、首帧续写和任意帧引导等任务。我们在2.1小节中做了详细讨论。
实验结果
针对我们提出的系统以及评估基准,我们采用了自动化评测和人工评测两种方式。
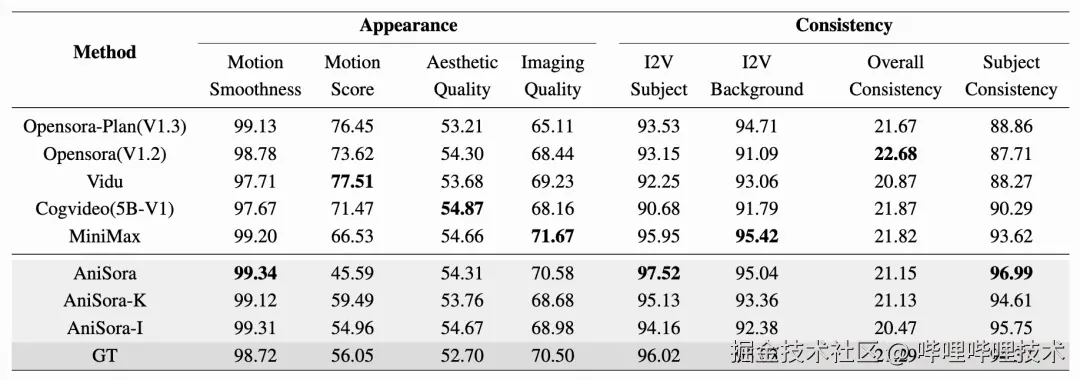
自动化评测的指标采取了VBench[9]中的多个维度,例如运动平滑度、美学质量、成像质量、主体一致性、图生视频主体一致性、图生视频背景一致性和整体一致性等。整体一致性评估的是文本-视频的一致性。此外,我们还使用了一个运动幅度模型来评估生成的视频片段的运动得分。我们将这8个指标对我们的方法以及其他6个近期的前沿工作进行了评估,如表1所示。我们观察到我们的方法在主体一致性和运动平滑度上表现良好,并且在除了运动分数以外的其他5个指标上表现接近。这些主要是因为我们对生成质量与运动幅度之间的平衡进行了全面评估,并发现大多数大幅度运动的生成结果都会有失真和不自然的片段。
表1 与其他方法的自动化评测结果比较
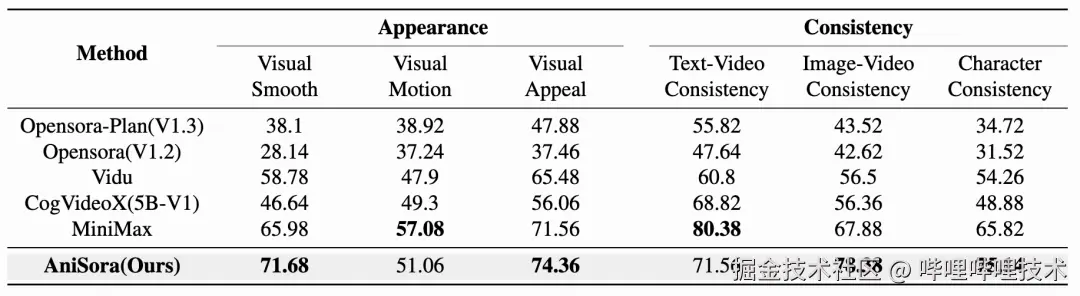
我们也在6个直观维度上进行了人工双盲评估,包括视觉平滑度、视觉动作、视觉吸引度、文本-视频一致性、图像-文本一致性和主角一致性。我们观察到Anisora在大多数维度上都超越了其他方法。
表2 人工评估分数
我们针对运动区域控制也进行了量化评估。评估基准的构建基于我们提出的基准数据集,对每一个初始帧采用显著性分割和连通域检测获取每个实例的包围框,然后从中挑选高质量的运动区域掩码,总共有200个样本。评估指标为运动掩码精度,即生成的视频运动像素在掩码区域内的占比。评估结果如表3所示,其验证了我们方法控制可动区域的有效性。
表3 运动区域控制评估

此外,我们分析发现在我们的数据集中2D的样本占大多数,但是3D动画的生成质量各指标持续领先2D。这可能是因为3D动画也是基于物理引擎如UE等渲染的,遵循一致的物理规则,和基于真实世界数据的预训练模型更为接近,可以更好地在微调时知识迁移。
我们也在一个具有独特艺术风格的漫画上对多任务训练(混合图像和视频)进行了消融实验,发现即使训练时只有少量的该特定风格图像数据的加入,以该独特风格的引导图生成的视频结果也能在稳定性和视觉质量上有显著的提升。
demo

更多结果以及完整提示词和视频可点此链接
pwz4yo5eenw.feishu.cn/docx/XN9Ydi…
业务场景
在视频内容火热的当下,用户对于视频内容的接受程度远高于漫画图片内容,动态漫作为漫画和动画之间的一个衍生品类也获得了大量用户的青睐。对于传统的漫画行业来说,动态漫是一个破局与革新的重要手段,但传统的动态漫制作需要一定的制作成本和较长时间周期,对于平台来说大批量的生产动态漫内容会承担较大的风险。而通过自研AI的生成能力,实现低成本、批量的动态漫内容的制作,对于拥有大量漫画版权资源的业务方来说是一个低风险且高收益的全新内容方向,并且通过动态漫的投放可持续扩大漫画IP的影响力,实现漫画&动态漫内容双赢。
具体来说,我们基于自研的动画视频生成技术,搭建了动态漫生成平台,只需要给到一段对应漫画图片的动态描述和漫画图片中角色对话的台词及情绪,就可以在3-5分钟内获得由漫画图片生成的动态视频及符合漫画角色音色和情绪的配音。为了方便运营同学使用,我们还增加了一些额外的配置,如利用掩码控制动态区域、快捷prompt、调整动态幅度、控制生成视频时长等,适配更具体的应用场景。
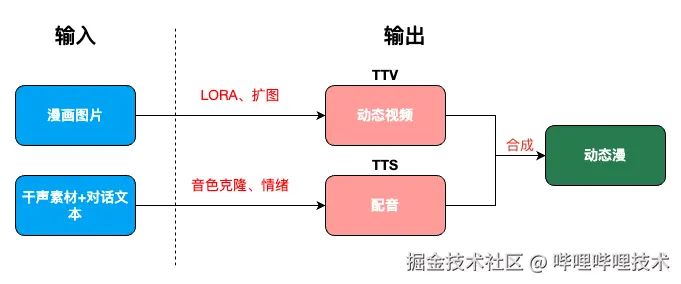
**动态漫生产流程图**
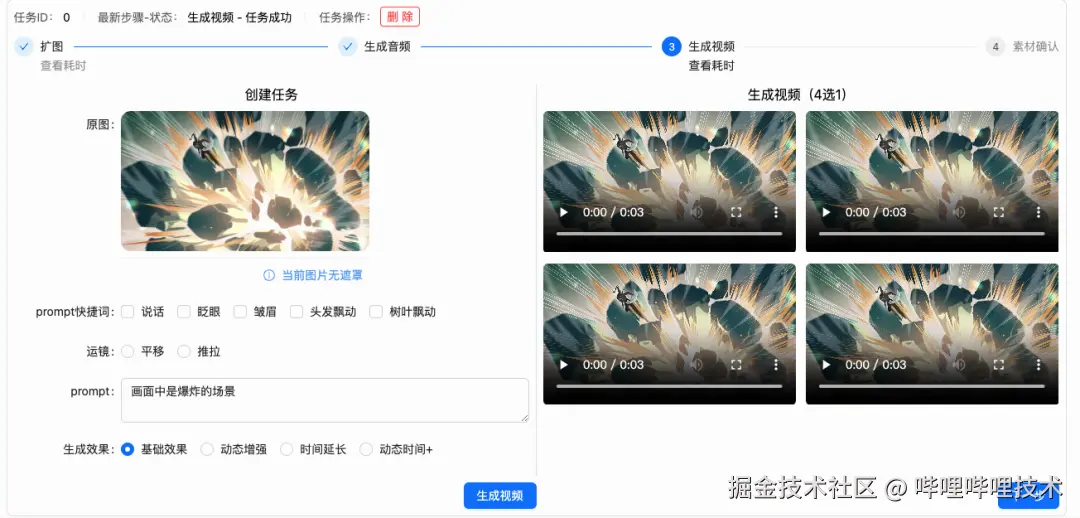
**动态漫生成平台示例图**
传统动态漫的制作需要专业的动效师进行动态效果制作,而动态效果制作占据了大量的时间、金钱成本。据数据统计,传统动态漫制作成本可至1000~10000元/分钟,而制作周期根据制作团队的人数安排需要几天到几周不等;AI动态漫的优势则在于极大程度的降低了创作成本,且去除了动效制作的能力门槛。一个会剪辑包装的运营制作1分钟的动态漫内容通常可以在1天内完成,综合考虑资源及人力成本来看,AI动态漫制作成本有数量级的降低。
截至12月,已经有超过10部自有IP作品运用了AI动态漫能力,实现了低成本且高效的动态漫剧集内容制作,并在各平台收获数千万播放。
此外,动态漫项目也在WAIC、QCon等会议参展,累计接待用户近6K+,受到了广泛好评。
未来规划
在本文中,我们提出了一个统一的框架AniSora模型,为克服动画视频生成中的挑战提供了解决方案。我们不仅在基准数据集上验证了方法的有效性,也以低成本、高效率支持动态漫内容制作,在多个平台突破千万播放。
尽管如此,目前的动画生成仍会存在一些瑕疵和畸变的问题。未来,我们计划开发一个全面的自动评分系统,专门用于动画视频评估,从而使评估更贴近主观感知。同时,我们计划扩展当前的模型架构,将多模态引导纳入其中实现更加精确的生成控制,包括相机运动、轨迹、动作和音频等。此外,为解决高质量动画数据有限的问题,我们还将采用强化学习技术,在有限的数据上进一步优化模型性能。
参考文献
[1] Breakthrough. Pyscenedetect. github.com/Breakthroug…, 2024. 3
[2] Youngmin Baek, Bado Lee, Dongyoon Han, Sangdoo Yun, and Hwalsuk Lee. Character region awareness for text detection. In CVPR, 2019. 3
[3] princeton vl. Raft. github.com/princeton-v…, 2020. 3
[4] christophschuhmann. improved-aesthetic-predictor. github.com/hristophsch…, 2022. 3
[5] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024. 3, 7
[6] William Peebles and Saining Xie. Scalable diffusion models with transformers. In ICCV, 2023. 1, 4
[7] Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072, 2024. 1, 3, 4, 6
[8] Taehun Kim, Kunhee Kim, Joonyeong Lee, Dongmin Cha, et al. Revisiting image pyramid structure for high resolution salient object detection. In ACCV, 2022. 5
[9] Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, et al. Vbench: Comprehensive benchmark suite for video generative models. In CVPR, 2024. 1, 3, 5
-End-
作者丨das、高树、HarryJ、星宇XY、森琦

评论记录:
回复评论: