
一、背景
实时数据仓库是近年来数据技术领域内的一大发展潮流。构建一个能够实现高吞吐量写入与更新、端到端全链路实时处理以及低延迟、高并发的实时数据仓库,一直是众多企业面临的重大挑战。随着B站游戏业务的快速发展,对数据的实时应用需求也日益增加。单点式实时指标计算模式已难以支撑日益复杂的实时业务需求,因此,构建一个稳定、高效的实时数据仓库变得迫在眉睫。
建设实时数仓的主要原因包括:
- 游戏业务对数据实时性的需求愈发迫切,需要实时数据来辅助决策制定;
- 实时数据建设缺乏统一规范,导致数据可用性不足,难以形成完整的数仓体系,造成资源的极大浪费;
- 离线数仓与实时链路相互独立,难以统一对外服务
如今,Hologre实时数仓体系已建设完成,它全面支持了运营、广告、算法等多元化业务场景的实时化需求,成为B站游戏数据应用的重要基石。本文将主要介绍我们在架构选型、方案设计、技术细节等方面的探索。
二、架构选型
离线数仓搭建的方法论比较明确,各类数据模型构建方式也比较成熟,数据流转可通过定时层间调度实现;但对于实时数仓的搭建,目前还没有一个明确的方法体系,各大厂商也采取了不同的方案架构,尤其是近年来各类优秀的OLAP (Online Analytical Processing) 数据库如StarRocks、Hologres快速发展,给实时数仓方案提供了更为丰富的选型,从众多方案中设计出符合B站游戏业务的实时架构,也就成为了我们首先考虑的方面。
1. Lambda还是Kappa?
Lambda架构是一种最经典的数据处理架构,通过Hive构建离线数仓,再利用Kafka、Hbase、Redis、Clickhouse等组件构建实时数仓,既可以满足跑批的需求,也可以进行流式计算。但是也有一个弊端,就是流和批分为两套技术栈,运维也要维护两套系统架构,维护成本非常高。
Kappa架构的出现,给行业带来了不一样的思路,即完全通过实时进行数据处理,实现全流程实时化构建,也是对流批一体式架构的一种探索。但只有实时链路,难以解决数据质量问题,时常需要离线链路对实时链路进行修正和丰富,而且依赖消息中间件支撑海量数据的回刷是成本极高且不稳定的架构。
考虑到B站游戏已经有了完善的离线数仓架构,选用Lambda架构是一种可靠且实际的做法,但是如何解决传统Lambda架构所带来的离线实时割裂化和高运维成本仍是个亟待解决的问题。
2. StarRocks还是Hologres?
为解决上述问题,我们考虑选取一种OLAP引擎来优化传统的Lambda架构,StarRocks与Hologres这两个近年来飞速发展的组件就成为了我们关注的重点。
首先是StarRocks,它采用了全面向量化引擎,并配备全新设计的 CBO优化器,使其查询速度(尤其是多表关联查询)远超同类产品。用其进行应用层的构建可使效率得到极大的提升,业内也有利用其强大的物化视图及视图能力分层构建实时数仓的案例,但对于大数据量的实时构建,通过物化视图进行驱动会对性能产生巨大的消耗,并不是当前的最优架构。
于是,我们将目光转向了Hologres,一款阿里自主研发的OLAP引擎,在经过深度调研后,其以下几个功能点吸引了我们的注意:
a.全链路事件驱动
Hologres内部表支持更新事件的Binlog透出能力,可替代kafka等消息中间件实现数仓各层级之间的数据传递,从而能够实现数仓层次间全链路实时开发。
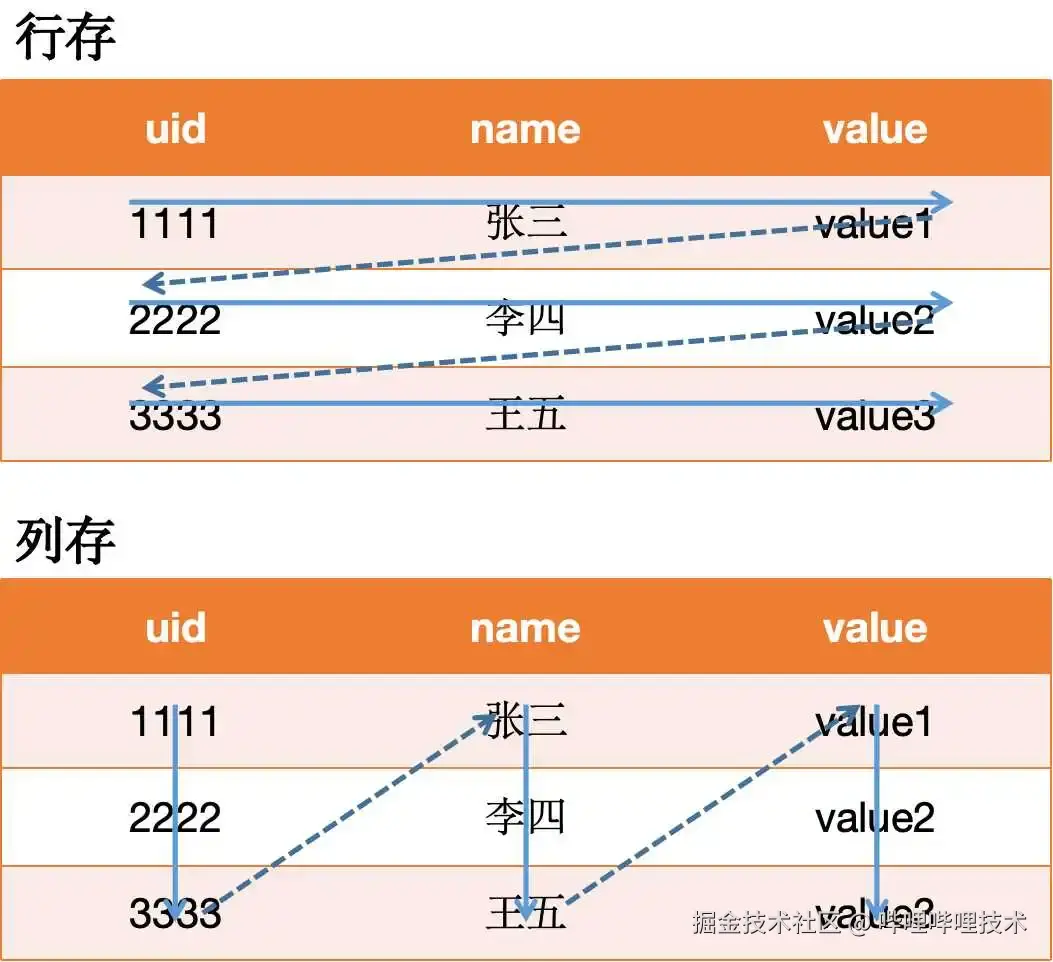
b.行列共存
Hologres同时支持行存格式和列存格式,能支持多样化的应用场景。
c.局部更新能力
局部更新能力使Flink多表join场景简化,可通过流式处理分段更新表字段,对于大宽表构建场景提供了强大支持。
d.MaxCompute查询加速
Hologres与MaxCompute底层数据相互打通,可无缝衔接,且通过Hologres外表可直接加速离线表的查询,可替代presto等组件的使用。
三、数仓架构
在架构中引入了Hologres后,我们对传统的Lambda架构进行了优化,将原先所需的消息中间件、缓存、Hbase等组件进行整合,统一使用Hologres+Flink进行实时数据的全链路构建,不仅大大降低了运维成本,也实现了存储层面的流批一体化设计,实现了离线-实时数据间的无缝衔接,全面推进了离线指标的实时化。
下图是我们现行的实时数仓架构:
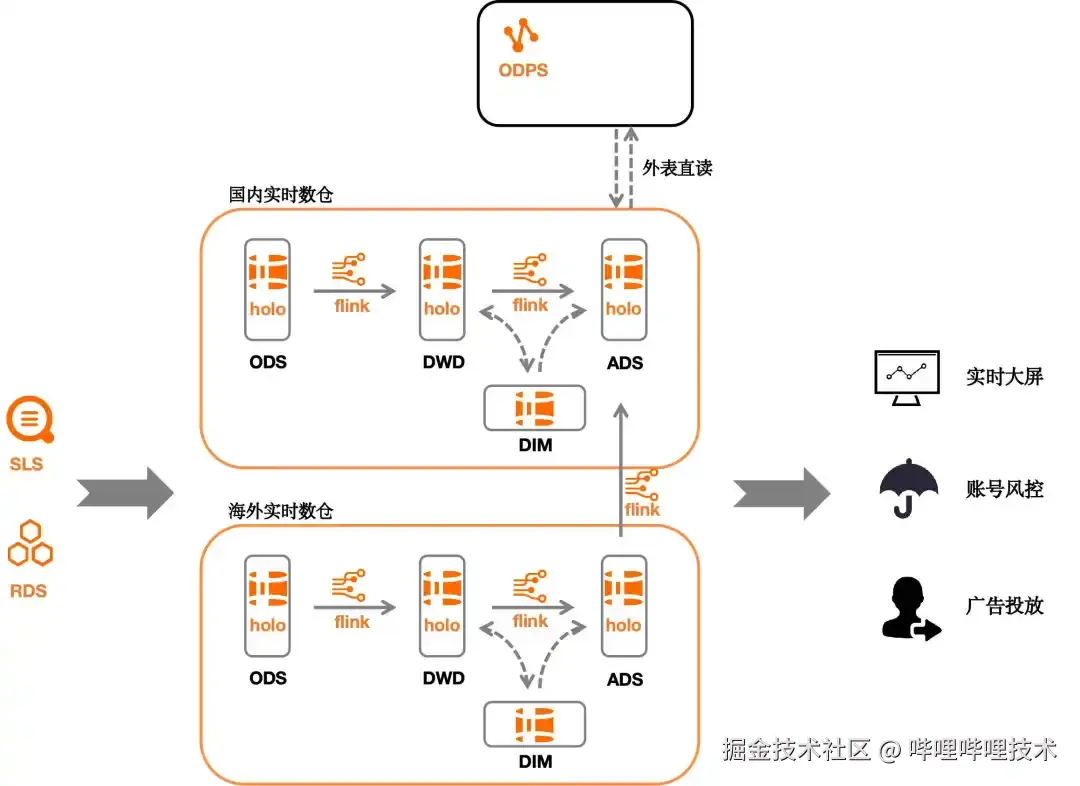
数据从SLS (Log Service)、RDS (Relational Database Service) 等组件流入Hologres,通过Flink读取holo表的增量binlog进行层间数据模型构建,同时实现实时全量维表的自更新,最终数据流入应用层服务于实时运营、风控、广告等方向。
传统的实时数仓往往会面临离线与实时数据的数据孤岛问题,实时数据与离线数据很难做到相互结合,这是不同组件间的底层数据存储模式不同带来的痛点。Hologres与MaxCompute底层数据相互打通,数据可以通过直读模式进行结合,针对这一特性,我们对离线指标所需的所有明细层都进行了实时化构建,使其可以满足秒级的实时明细查询,并可通过直读模式与离线表直接进行join计算,实现了大部分的离线指标实时化。
B站游戏有着全球化部署的策略,我们在国内海外分别部署了Hologres实时数仓,以满足对全球游戏数据的实时观测,通过将计算好的指标回传国内,实现国内-海外数据的一站式查询。
四、分层构建
为了方便之后与离线数仓对接,我们在层级结构上仿照了离线数据的搭建模式,将实时数据也分为了ODS原始层、DWD明细层、DIM维表层、以及ADS应用层等层级,对数据逐层清洗落盘,使每个实时中间层都可进行数据查询,并可与离线相关层进行关联。下文将介绍我们对各个层级的设计思路。
4.1 数据接入
该层主要是通过Flink清洗SLS中的数据流至ODS原始层,并承担简单的解析工作,以减轻下游DWD明细层数据处理压力。
这里主要面临的问题是存储成本方面的,设计初期为实现效率最大化的数据流入,引入了stage接入层,并采用了行存格式。行存格式的数据无法进行高效的数据压缩,单独一个Stage层保留三天数据就已超过1.5TB。为了解决该问题,采用了以下方式:
-
行存改列存,在保障满足吞吐要求的情况下,拥有更高的压缩比
-
砍掉Stage层,在ODS层保留源数据格式src_message,并进行共有字段的拆解
-
缩减binlog TTL (Time To Live),binlog是无压缩存储,会占用大量的空间,每日有六成增量来自binlog存储。
4.2 DIM层构建
实时维表在实时数仓中扮演着非常重要的角色,它负责了各个事件间的数据交互,用点查维表代替各流间的join操作,能大幅减少数据时延,提升数据准确性。
各维表的数据量很大,其中用户维表有几亿条数据,设备维表有几十亿条数据,要实现如此大量维表数据的实时更细和高QPS点查,对系统的整体设计带来了很大的考验。
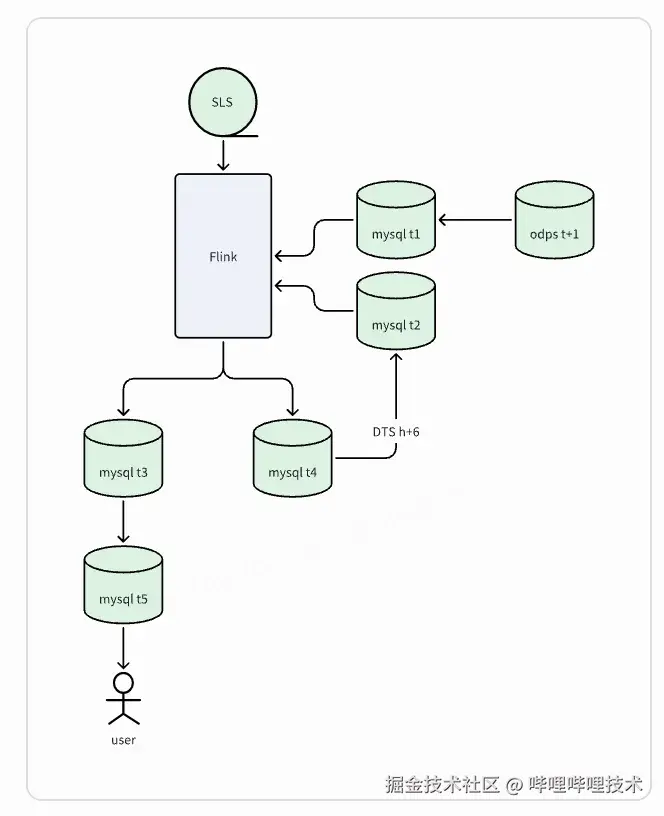
在实时体系构建初期,我们使用了MySQL作为维表数据的载体,它带来了以下痛点:
- 用户维表分为OB (Open Bata) 前表、OB后表,且由于数据量大,在MySQL中分成了几十张子表,维护困难
- 实时链路复杂,涉及离线表、实时表、实时6h表等各种表间的组合,排查问题时困难
- 计算过程中会将维表存于内存中,需要占用大量的内存资源,曾尝试过将维表置于redis中,但也会占用大量存储,成本较高
- 维表字段只有基本的uid、udid等字段,可支持的指标有限
原实时维表架构:
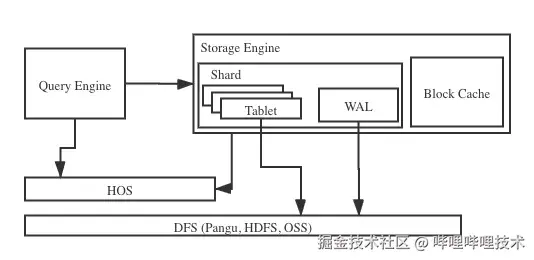
Hologres的行存表底层采用的LSM(Log-Structured Merge)结构,其底层采用了多分片结构,一个分片又由多个tablet组成,这些tablet会共享一个日志(Write-Ahead Log,WAL)。得益与LSM结构,所有新数据都是以append-only的形式写入,数据先写到tablet所在的内存表 (MemTable),积累到一定规模后再写入到文件中。与传统数据库的B+-tree数据结构相比,LSM减少了随机IO,大幅的提高了写的性能。下图展示了Hologres的一个分片的基本架构:
我们利用Hologres的行存表构建了全新的实时维表,将全量的用户、设备、订单等信息记录在维表中,通过对明细层的处理实时更新维表字段。原先冗余、繁复的维表架构被取代,实现了维表底层存储上的统一,同时我们根据日常的使用场景为维表设置了各类分布键、聚簇键,使其点查效率最大化。它带来了一系列的好处:
- LSM结构的行存表带来了写入即可查的时效性及高QPS的点查能力,无需再将维表存于内存中,即用即取
- 维表维护链路简化,不需要再维护多个不同ttl的维表,同一维表可实现自更新
- 丰富了维表字段,可支持更多样化的指标需求
下图是我们实时维表的更新模式:
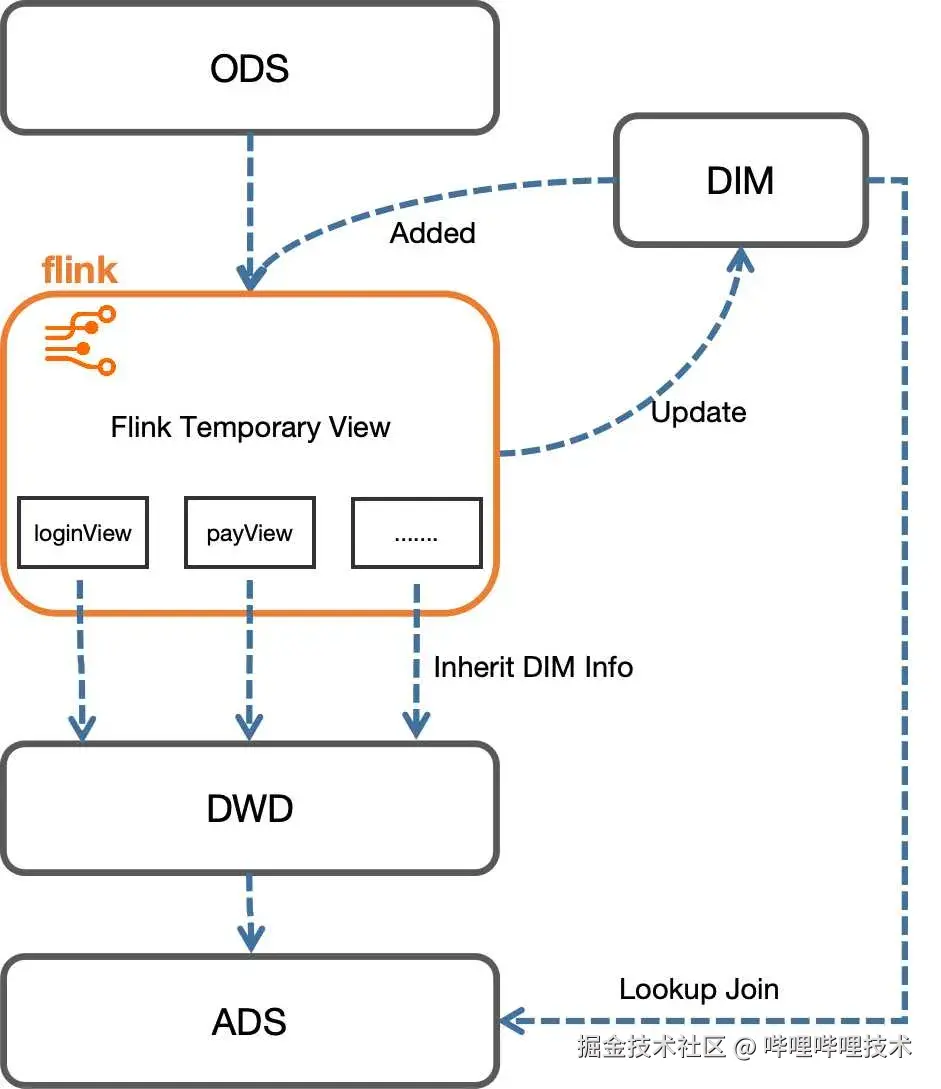
实时维表在初次启动时,会通过历史离线数据进行初始化操作,后续会依靠Flink程序进行实时更新。数据从ODS层流入,在Flink程序中进行各事件的拆分,然后与维表进行关联,将最新的维表信息补充进事件信息中。然后各事件明细层中的维表信息又会反哺给实时维表,使维表始终保持最新状态。各明细层最终会带着继承的最新维表信息进入下游,进行进一步的指标计算。在指标计算过程中,若有其他维表信息的需求,则可直接对维表进行lookup join,取出相应字段进行计算。
1.多流join带来的数据冗余及数据延迟问题
在探索初期,我们为了让明细层获取更多的维表信息,曾用多流join进行补充多种维表字段。这样做可以使下游在使用数据表时更为方便,但是却带来了巨大的维护成本,多流join会导致数据延迟更新,还会使数据在明细层发生冗余。最终我们放弃了这种做法,在每一类明细表中仅保留与其相关的维表信息,如登录明细表会保留首末次登录相关的信息。经过优化后,整体的架构显得简洁明了,响应延迟也从分钟级提升至了秒级。
2.QPS峰值问题
QPS (Queries-per-second) 也是我们重点优化的能力之一。这一问题在使用初期并没有暴露出来,但在重刷数据时,我们发现lookup join算子峰值流量为4000QPS,并随着多个并行度逐渐空跑,数据倾斜的问题也逐渐显露,QPS逐渐下降至200~300,这与Hologres的理论性能相去甚远。经过排查发现,Flink查询Hologres维表时,默认采用同步方式,这极大的限制了点查性能。通过将点查维表方式从同步改为异步,同时增大批处理size的方式,成功将lookup join算子流量提升至30000+QPS,数据倾斜发生时单一并行度也能达到13000+QPS。
经过多轮优化后,目前实时维表支撑了几十亿级别维表的秒级更新操作,保障了实时指标的准确输出。
4.3 DWD层构建
DWD明细层是实时数仓重要的中间层,向上承接了ODS层的数据细化与维表更新,向下负责了指标的计算,它直接决定了数据的准确性及计算链路的复杂度。
我们在设计dwd层时重点关注了它与离线明细的交互性。我们目标是打通实时、离线间的数据孤岛问题,所以在字段设计期间,我们就充分参考了离线数仓的数据模型。
- 在离线明细层拆分逻辑基础上又额外补充了一些字段信息,保障数据一致性及实时场景的全覆盖
- 保留了实时维表的关键信息,计算指标时可省去很多join操作,降低集群压力
MaxCompute与Hologres已在底层无缝打通,我们依据其特性构建了多场景明细层应用方式。
1.实时报表展示
我们在实时明细层中增加了大量维表字段,对于各类新增、留存、回流等指标,可不用再join维表直接进行单表聚合统计得出。
对于一些累计指标,我们在Hologres中构建了ODPS外表以获取其保存的离线数据,再与当日实时数据结合,将T+1产出的指标变为实时产出,极大的提高了运营效率。
2.实时信息拉取
对于一些特殊的离线场景,我们需要进行大数据量的离线计算,同时又希望获取到最新的实时用户信息,而不是T-1的数据。
针对这种情况,我们在ODPS中构建了Hologres实时外表,利用其实时直读能力,用离线引擎读取实时信息进行大数据量的复杂计算。使其可以充分利用MaxCompute的多级分区过滤和算子下推来优化查询速度。
明细层的实时化构建,打破了传统数仓中离线、实时数据孤岛化的壁垒,使指标计算可在实时-离线中任意切换,全面推进了离线指标实时化的进程。
4.4 ADS层构建与重写策略
ADS层是实时指标的重要输出窗口,其易用性、准确性、及其响应速度是我们优先考虑的方面,为了平衡各方面的性能,我们采用了大宽表+行列共存的模式进行构建。
1.指标碎片化问题
实时数仓的指标层,往往会面临指标碎片化的问题,即单独的一两个指标就占用一张实时表,随着指标数的增多,实时表的数量会越来越多,给下游取数带来很大的不便。
因此,在应用层的构建上,我们充分利用Hologres的局部更新能力,构建指标大宽表,将大多数实时指标计算维度规范化,统一写入一张实时指标宽表中,解决业务增长带来的指标碎片化问题。
- 支持多聚合维度、多统计维度指标扩展
- 国内、海外指标层合表,统一对外提供服务
- 宽表构建,降低下游取数难度
2.指标复杂聚合问题
在实时数仓应用之前,我们采用MySQL作为应用层的载体,MySQL可以赋予指标较高的点查性能,但是对于复杂的指标关联聚合就显的比较吃力,往往会带来使用体验上的下降。
通过将Hologres底表设置成行列共存,数据查询时,优化器会根据SQL,解析出对应的执行计划,执行引擎会根据执行计划判断走行存还是列存,大大提升了应用层的查询效率。
行列共存的数据在底层存储时会存储两份,一份按照行存格式存储,一份按照列存格式存储,因此会带来更多的存储开销。但对于使用方来说,行列共存意味着更灵活的使用方式,使一张表同时拥有行列和列存的能力,既支持高性能的基于PK点查,又支持OLAP分析。
3.高乱序数据重写策略
在Flink流式语义中,当数据正常流入时,watermark会正常推进,少量低乱序数据也可通过各类延迟策略进行解决,保障指标的正常输出。但是当多并行度数据重刷时,数据会处于高乱序状态,此时watermark的推进就会异常,导致中间状态数据缺失。常见的有在使用CUMULATE窗口按分钟计算累加指标时,若进行数据重刷,则会因数据乱序导致中间状态缺失,只会更新最新时间点的数据,中间时间点的数据出现计算异常。同时,常用的延迟策略,table.exec.emit.allow-lateness参数在CUMULATE窗口中也还未被支持,给这类数据的修复带来了很大的麻烦。
针对以上情况,我们开发了与CUMULATE窗口配套的保障程序,其利用实时明细层进行数据补全计算,再刷写入指标层,可在2~5分钟内修复中间缺失状态。在刷写过程中,我们先将指标写入临时表中作为中转,再刷写入结果表,用于防止长时间的写入操作引起的锁表问题,导致写入ads报表的Flink程序失败。
五、现状与展望
通过将Hologres引入架构,我们对经典Lambda架构进行了全面的优化升级,避免了Lambda架构中众多组件带来的高运维成本,同时实现了存储层面的流批一体,使离线与实时数据可以无缝交互。目前,Hologres实时数仓已全面应用于B站游戏的各类数据应用场景,涉及报表展示、运营分析、算法风控、广告投放等各个领域,服务于数百款游戏的实时取数需求,全面推进了数据分析的实时化。
下一步我们将针对以下方面进行建设:
1.完善实时指标建设
原来点到点式的实时指标计算方式面临着开发周期冗长的问题,而实时数仓的指标开发方式,可从任意数据切面进行接入,能大大提高数据的复用性,使我们可以完成更加复杂多样的指标建设,逐步实现离线指标的全面实时化。
2.扩展实时明细层应用
通过与MaxCompute的存储直连,我们已实现了DWD明细层的秒级入库更新,这相比传统离线数仓明细层的T+1更新有了质的飞跃,在应用层方面也将赋予业务更大实时化空间,推进对实时明细层的应用将是我们下一步的重点工作。
3.研发数据实时解析
实时数仓目前主要针对的是运营数据,针对研发数据的相关解析还主要是通过离线方式。可依托已有经验,对重点游戏建立研发数据实时仓库,推进研发数据分析的实时化进程。
-End-
作者丨指尖

评论记录:
回复评论: