
作者:裘文成(翊韬)
问题背景
在当今数字化时代,日志数据已成为企业 IT 运营和业务分析的关键资源。然而,随着业务规模的扩大和系统复杂度的提升,日志数据的体量呈现爆发式增长,给日志采集和处理系统带来了巨大挑战。最近,我们遇到了一个典型案例,充分体现了当前日志服务采集在高负载场景下面临的困境,以下为客户现状:
- 海量日志与正则采集:客户的某项业务产生了数量巨大的多行日志,并且需要通过正则表达式进行日志解析。这种复杂的采集模式本身就对系统资源提出了较高要求。
- 关键业务影响:这些日志数据和客户的核心业务分析任务直接相关。过高的采集延迟会影响数据分析的准确性。
- 采集性能瓶颈:客户根据 iLogtail 启动参数配置文档【1】对 iLogtail 的线程数等进行了调整,在压测时采集速度依然只有 90M/s,但实际压测时的日志生成速度在 200M/s,远超采集速度。这导致了日志采集出现近 1 小时的延迟。
- 业务需求升级:客户计划进一步增加压测量,预计写入流量将达到 300MB/s。这将进一步加剧采集延迟问题。
- 业务负载高:客户的业务已经占据了大部分的 CPU 资源,比较困难继续为 iLogtail 提供更多的资源。
技术难点
在收到客户反馈后,我们立即着手分析问题并制定优化策略。通过获取客户的测试日志样本并进行深入测试,我们发现了以下关键技术难点:
-
性能瓶颈
- 挑战: 即使在优化的测试环境中,我们也无法达到客户期望的 300MB/s 处理速度。
- 数据: 采用 16 线程并行处理,最高吞吐量仅为约 270MB/s。
- 影响: 无法满足客户的性能需求,可能导致日志处理延迟和数据分析滞后。
-
资源消耗与业务冲突
- 挑战: 为接近目标性能,iLogtail 需要占用大量系统资源。
- 数据: 需要 16 个线程才能达到 270MB/s 的处理速度。
- 影响: 高强度的资源占用严重影响服务器上的其他业务进程,可能导致整体系统性能下降。
-
线程扩展效益递减
- 挑战: 简单增加处理线程数量并不能线性提升性能,达到一定线程数后,性能增益呈现边际递减趋势。
- 影响: 表明仅依靠增加硬件资源难以实现质的突破,需要从算法层面进行优化。
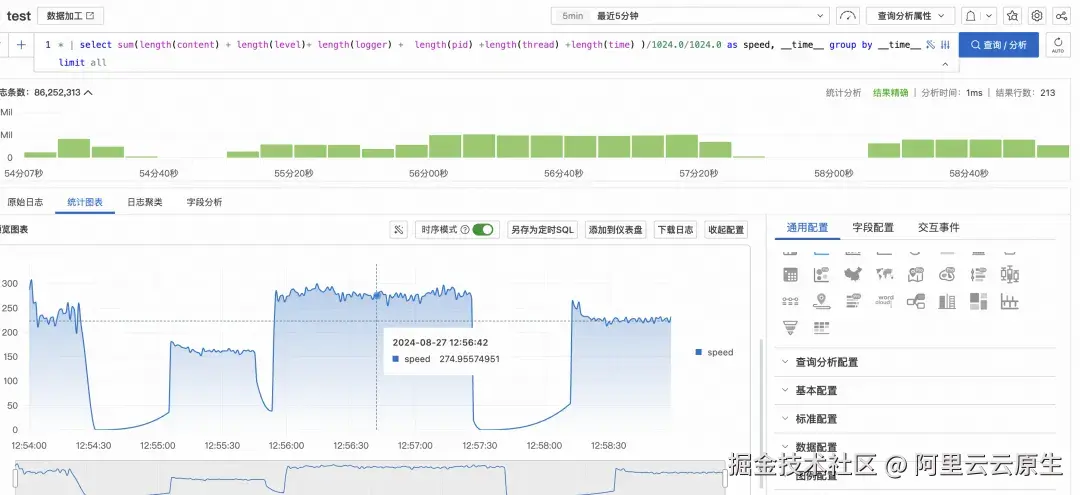
优化过程与成果
怕看官们等不及,在深入技术细节之前,让我们先一睹为快,直观呈现这次优化的成果:
- 性能质的飞跃:成功将采集速率提升至超过 300MB/s,完全满足客户需求。
- 资源利用大幅优化:在保持高性能的同时,将所需线程数从16减少到8,显著降低了 CPU 占用。
- 创新解决方案:针对资源受限的场景,我们推出了 IngestProcessor 方案。使用这种方案,iLogtail 仅需 1 个线程就能实现 320MB/s 的采集速度,为客户提供了极致的资源效率选择。
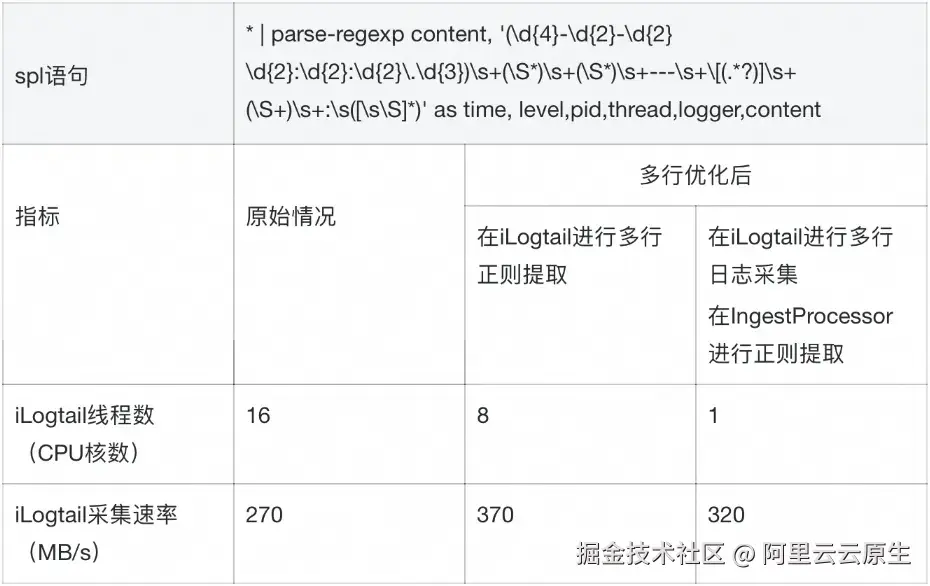
本文分析和测试,皆在以下硬件环境进行测试
硬件环境
- 计算资源:阿里云 ECS 实例(规格:ecs.c5.8xlarge)
- 存储资源:PL3 规格的 ESSD 云盘
-
- 为避免磁盘 I/O 出现瓶颈,在高日志量的输出和采集场景,我们推荐使用 PL3 规格的 ESSD 云盘。本文将基于该规格的 ESSD 云盘进行性能分析,详情可参考 ESSD 云盘官方文档【2】
多行日志采集性能提升
初步观察
为深入了解性能瓶颈,我们首先将注意力放在多行日志的处理性能上。
- 客户的日志主要是多行格式。
- 多行日志采集步骤在日志正则处理之前,可能对整体性能产生重大影响。
在深入研究多行日志采集性能时,我们观察到了一个令人震惊的现象。尽管预期多行日志处理会对性能产生一定影响,但实际测试结果却远远超出了我们的初步估计。在统一的单线程环境下,我们记录到以下数据:
- 单行日志采集速度:425MB/s
- 多行日志采集速度:98MB/s
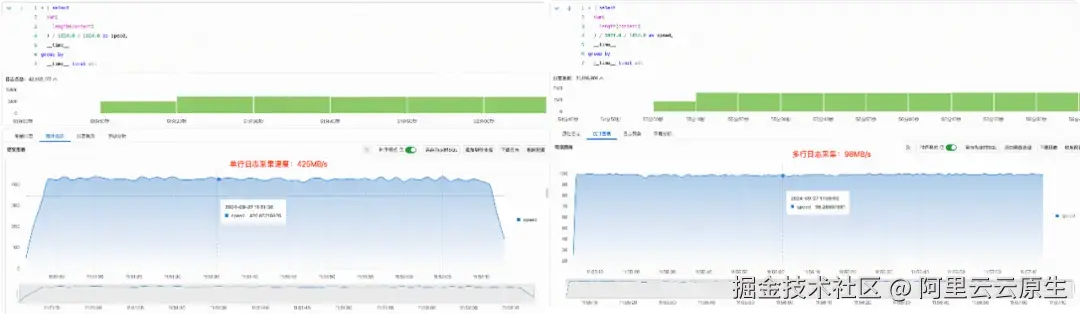
这近乎 80% 的性能下降不仅令人惊讶,更引发了我们对多行采集算法实现的深度思考:
- 性能差距:从 425MB/s 骤降至 98MB/s,这种程度的性能退化远远超出了我们对多行处理的初始预期。
- 异常性:如此巨大的差异明显超出了正常的多行处理开销,显然存在一个重大的性能瓶颈。
- 算法效率质疑:这一现象使我们不得不重新审视当前多行采集算法的实现效率。可能存在某些未优化的操作或不必要的重复计算。
iLogtail 多行日志处理原理
iLogtail 的多行日志合并功能基于特定的日志格式将分散的多行数据聚合为完整事件。其工作流程如下:
- 用户配置行首正则表达式。
- iLogtail 对每行日志开头应用此正则。
- 若某行不匹配,iLogtail 继续等待直至找到匹配的行首。
举个例子,假设我们有如下的日志格式,通常我们会配置行首正则为 \d+-\d+-\d+\s\d+:\d+:\d+.\d+\s.*,iLogtail 会拿着这个正则对每行进行匹配,将这些单行日志合并成一个完整的多行日志。
php 代码解读复制代码2024-03-15 14:23:45.678 ERROR 987654 --- [TaskExecutor-1] c.e.d.s.TaskScheduler : Failed to process task due to unexpected exception
java.lang.NullPointerException: Cannot invoke "com.example.data.model.Task.getPriority()" because "task" is null
at com.example.data.processor.TaskProcessor.processTask(TaskProcessor.java:123)
at com.example.data.scheduler.TaskScheduler.lambda$scheduleTask$1(TaskScheduler.java:89)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.IllegalArgumentException: Task ID cannot be null or empty
at com.example.data.validator.TaskValidator.validateTask(TaskValidator.java:45)
at com.example.data.processor.TaskProcessor.processTask(TaskProcessor.java:115)
... 4 common frames omitted
性能瓶颈分析
深入 iLogtail 的实现机制,我们发现性能瓶颈的关键在于其正则匹配方法。
iLogtail 使用 boost::regex_match 函数进行全量匹配,这在处理大规模日志时会产生显著的性能开销。
arduino 代码解读复制代码bool BoostRegexMatch(const char* buffer, size_t size, const boost::regex& reg, string& exception) {
// ...
if (boost::regex_match(buffer, buffer + size, reg))
return true;
// ...
}
对于之前提到的日志示例,正则表达式会对第一行的全部 253 个字符进行匹配,这在处理大量日志时会导致性能下降。
为了量化这一性能问题,我编写了测试代码进行实验,目的是观察随着与行首正则无关的日志长度增加(即 .* 匹配的部分),boost::regex_match 的执行时间如何变化。
c 代码解读复制代码static void BM_Regex_Match(int batchSize) {
std::string buffer = "2024-07-19 15:02:16.055 INFO ";
std::string regStr = "\\d+-\\d+-\\d+\\s\\d+:\\d+:\\d+\\.\\d+\\s.*";
boost::regex reg(regStr);
std::ofstream outFile("BM_Regex_Match.txt", std::ios::trunc);
outFile.close();
for (int i = 0; i < 1000; i++) {
std::ofstream outFile("BM_Regex_Match.txt", std::ios::app);
buffer += "a";
int count = 0;
uint64_t durationTime = 0;
for (int j = 0; j < batchSize; j++) {
count++;
uint64_t startTime = GetCurrentTimeInMicroSeconds();
if (!boost::regex_match(buffer, reg)) {
std::cout << "error" << std::endl;
}
durationTime += GetCurrentTimeInMicroSeconds() - startTime;
}
outFile << i << '\t' << "durationTime: " << durationTime << std::endl;
outFile << i << '\t' << "process: " << formatSize(buffer.size() * (uint64_t)count * 1000000 / durationTime)
<< "/s" << std::endl;
outFile.close();
}
}
int main(int argc, char** argv) {
logtail::Logger::Instance().InitGlobalLoggers();
std::cout << "BM_Regex_Match" << std::endl;
BM_Regex_Match(10000);
return 0;
}
通过这个实验,可以观察到一个关键现象:
- 随着与行首正则无关的日志长度增加(即 .* 匹配的那部分日志),boost::regex_match 的执行时间也呈线性增长。
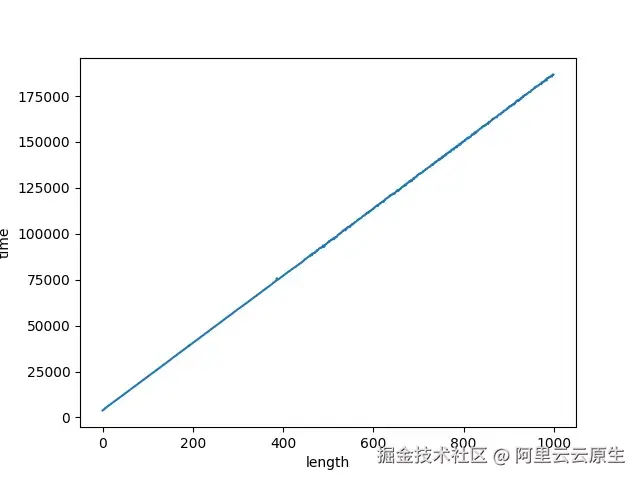
基于实验结果,我们可以得出以下结论:
- 全量匹配的低效性:boost::regex_match 对整行进行匹配,即使只有行首部分是关键的。
- 资源浪费:匹配时间与日志行长度呈线性关系,大部分匹配时间花在了与实际分割逻辑无关的内容上(.* 匹配的部分),这在处理大量长行日志时会导致严重的性能下降。
性能优化
基于性能瓶颈分析,我们确定了关键的优化方向:实现部分匹配。这种方法只对日志行首进行匹配,而不是整行,有望显著提高处理效率。
为了避免重复造轮子,在调研后,我们发现 Boost 库提供了一个替代方案:boost::regex_search 函数,通过适当配置,这个函数能够精确满足我们的需求。以下是优化后的代码实现:
arduino 代码解读复制代码bool BoostRegexSearch(const char* buffer, size_t size, const boost::regex& reg, string& exception) {
// ...
if (boost::regex_search(buffer, buffer + size, what, reg, boost::match_continuous)) {
return true;
}
// ...
}
关键改进点:
-
使用 boost::regex_search 替代 boost::regex_match。
-
添加 boost::match_continuous 标志,确保只匹配前缀,如果字符串的开头子串满足正则表达式,就会返回成功。
这种实现方式允许我们精确控制匹配过程,只关注日志行首,这正是多行日志处理所需要的。
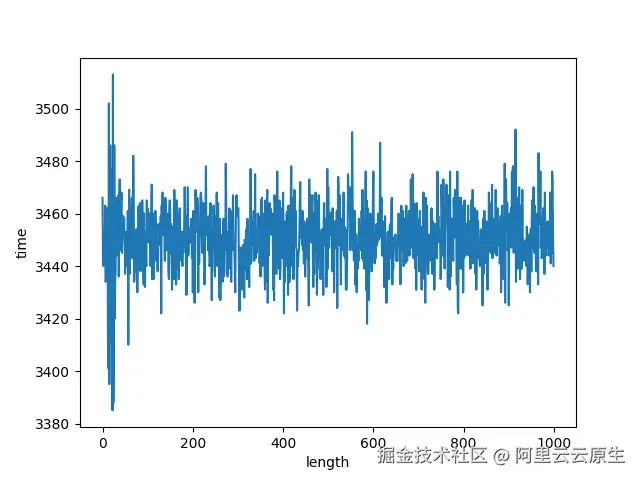
为了量化这一优化的效果,和 boost::regex_match 一样,我也对 boost::regex_search 根据日志长度进行了测试。可以发现,新方案的执行时间基本保持稳定,不受日志长度影响。
优化后的多行算法,实际采集效果
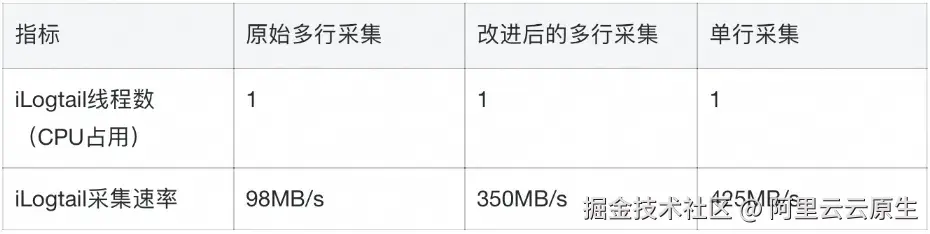
我们对使用优化后多行算法的 iLogtail,进行了多行日志采集,以下是测试的详细结果:
-
多行采集性能飞跃
- 优化后的多行采集速度从 98MB/s 提升到 350MB/s
- 性能提升幅度:257%(约 3.57 倍)
-
接近单行采集性能
- 优化后的多行采集速度(350MB/s)已接近单行采集(425MB/s)
相对于单行采集的性能比:82.35%
- 资源利用效率
- 在保持单线程的情况下实现显著性能提升
- 体现了算法优化在提高资源利用效率方面的巨大潜力
用户体验优化
在 iLogtail 的已有实现中,用户配置的行首正则表达式通常包含 .*后缀。这是由于之前的匹配机制会匹配整行内容,为了让客户不改动采集配置,只需要升级 iLogtail 版本 2.1 及以上,就能享受到该多行采集性能优化,我们设计了一个以下兼容性策略:
- 正则表达式解析:
- 在处理用户配置时,iLogtail 会自动分析正则表达式。
- 如果检测.*后缀的存在,iLogtail 动态调整正则表达式,移除.*后缀。
正则匹配双方案
改进多行日志性能后的多行正则匹配采集
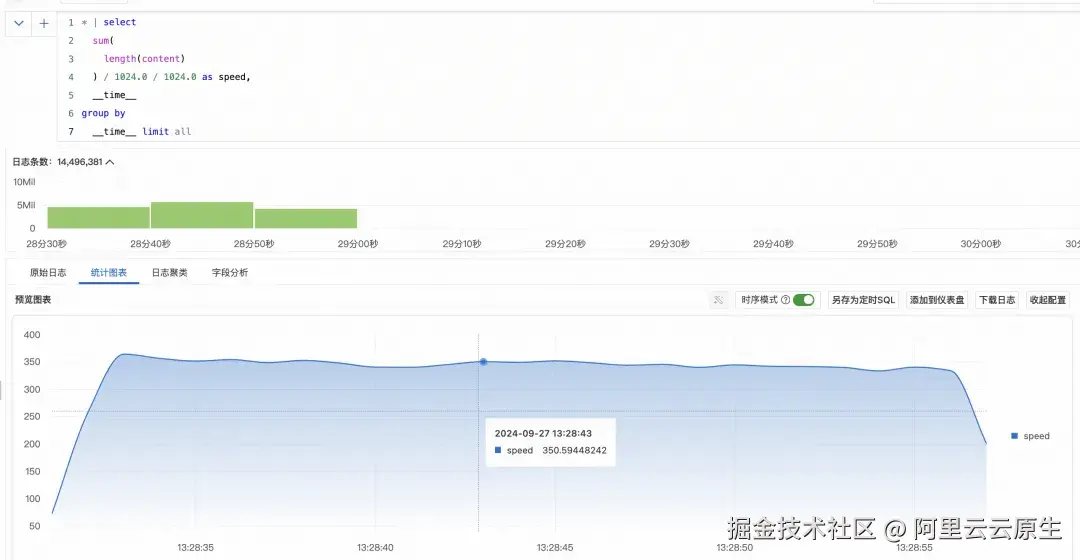
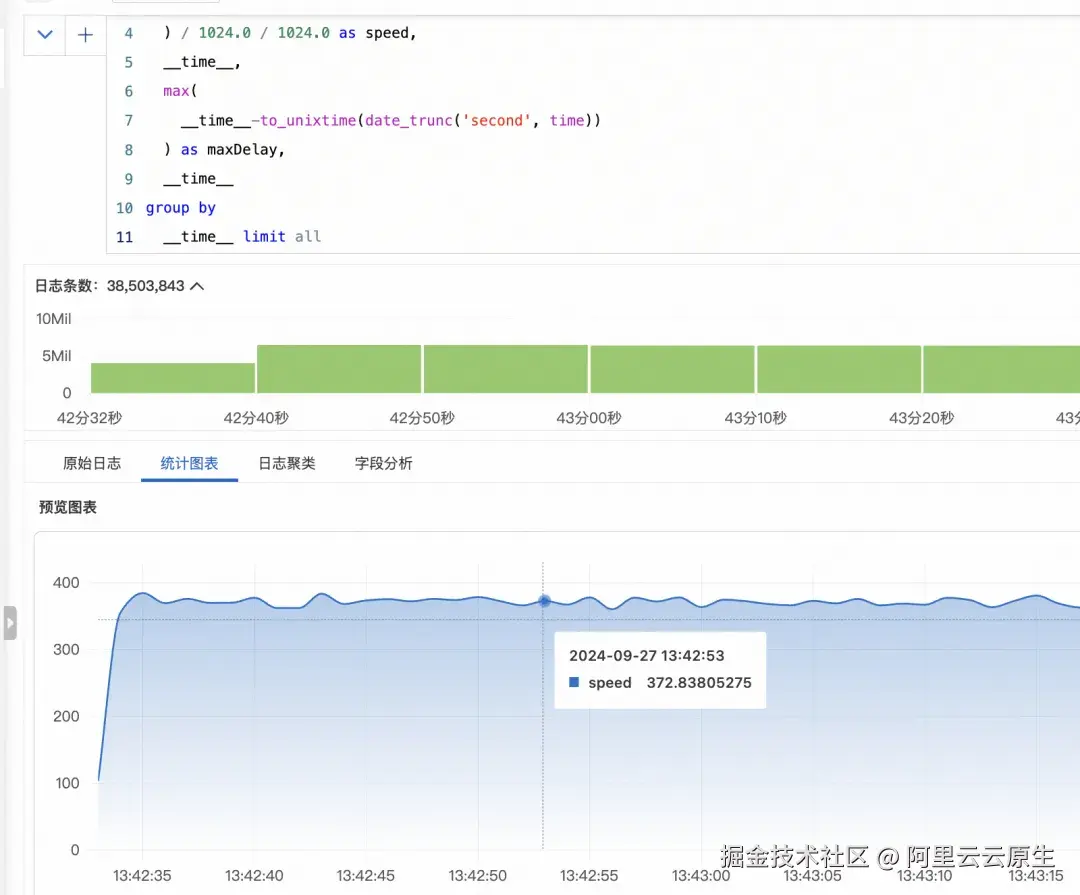
在优化多行日志采集性能后,我们进一步探讨了将改进后的多行采集与正则提取相结合的效果。下面详细分析了这种组合方案的性能表现及其实际应用价值。在 8 线程下, iLogtail 的多行日志采集性能已经可以到 370MB/s,已经足够满足客户的采集速度需求。

-
采集速率提升
- 优化后的采集速率从 270MB/s 提升到 370MB/s
- 性能提升幅度:37%
-
资源利用优化
- 线程数从 16 减少到 8,减少了 50%
- 在减少一半 CPU 资源的同时,仍然实现了显著的性能提升
-
正则提取的限制
- 由于正则提取需要对日志进行全量匹配,多行采集的部分优化手段在此无法应用
本地资源紧张 - 快速迁移 IngestProcessor
尽管我们成功地在 8 线程下实现了 iLogtail 对多行日志的采集和正则提取,但这种方法仍然面临着一些挑战:
- 高资源需求:需要占用 8 个 CPU 核心,对机器资源造成显著压力。
- 客户端限制:并非所有客户都有能力或意愿增加机器资源。
- 可扩展性问题:随着业务压力增加,客户端资源可能成为瓶颈。
为了应对这些挑战,阿里云日志服务推出了一个创新的解决方案:写入处理器(IngestProcessor)。这种方法不仅有效解决了资源限制问题,还大幅提高了处理效率。
-
工作原理
- 数据流:通过 iLogtail 采集的日志数据首先经过 IngestProcessor。
- 处理位置:数据处理过程在日志服务中完成,而非客户端。
- 资源优化:这种方法显著减少了客户端资源占用,释放计算能力。
-
注意事项
-
IngestProcessor不支持日志聚合(将多个日志合并为一个)。
-
该功能需要额外计费。详细信息请参考阿里云官方文档:help.aliyun.com/zh/sls/user…
-
IngestProcessor 不仅可以解决资源限制问题,还提供了丰富的数据处理能力:
- 字段提取:从原始日志字段中通过正则表达式、Key-Value 格式、JSON 等解析方式提取出新的字段。
- 扩展字段:为原始日志添加新的字段。
- 丢弃字段:删除原始日志的部分字段。
- 数据脱敏:将原始日志的敏感信息进行脱敏处理。
- 数据过滤:丢弃原始日志的部分数据。

由于 IngestProcessor 使用的 SPL 语法和 iLogtail 使用的 SPL 语法一致,因此我们可以直接把 iLogtail 使用的 SPL 语句复制到 IngestProcessor 上,实现快速迁移。
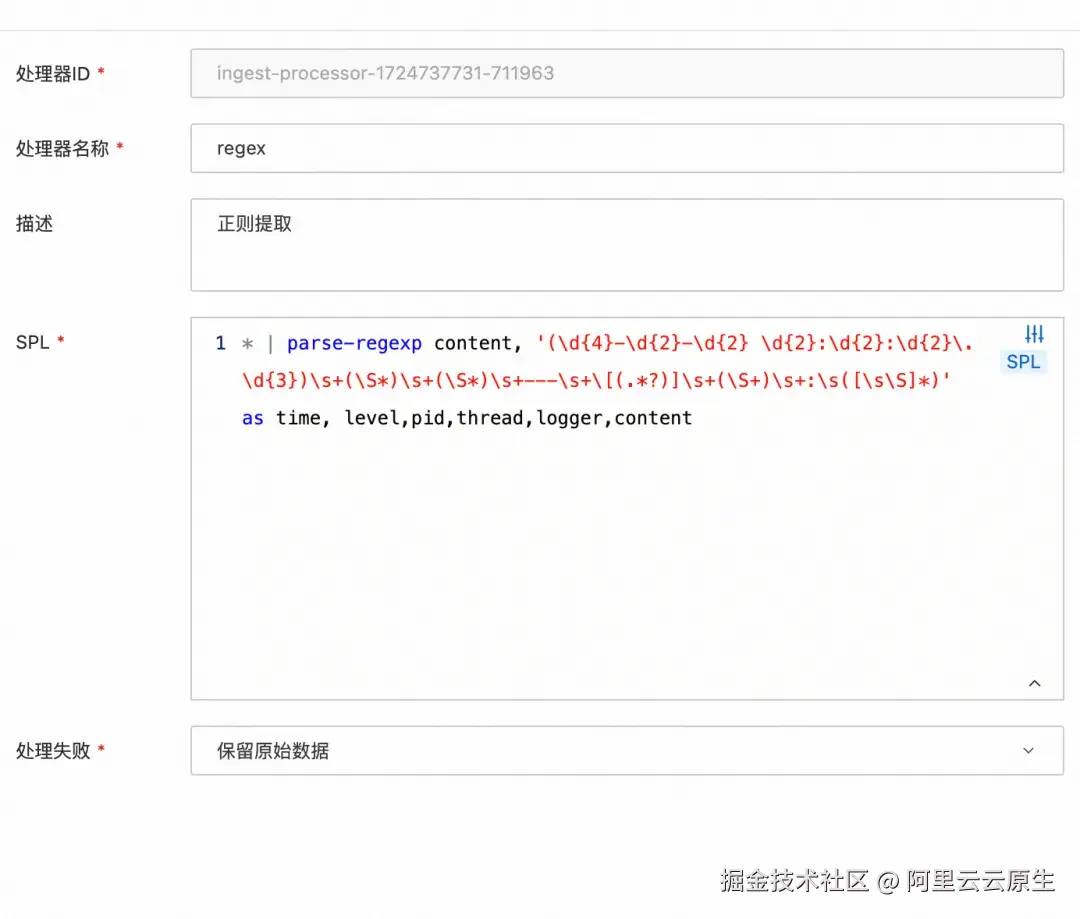
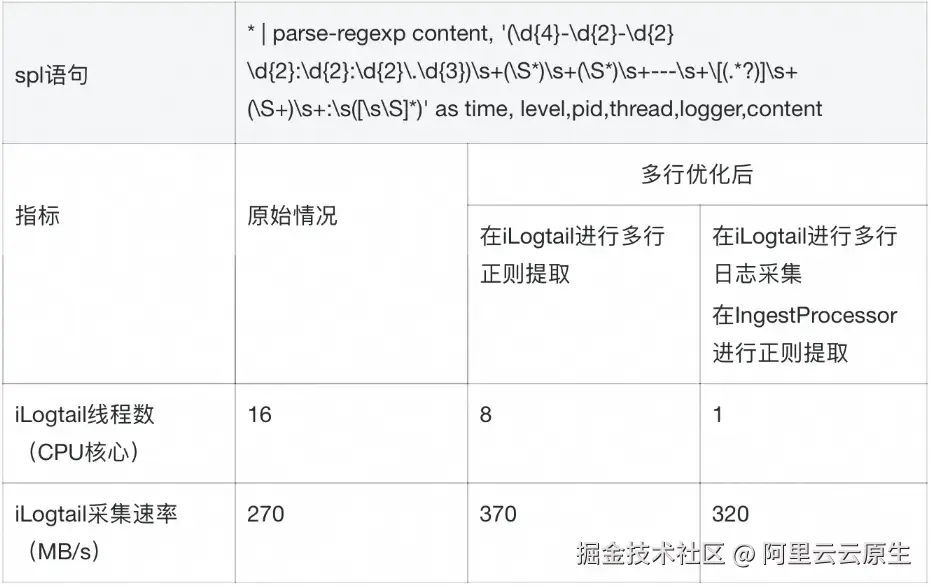
我们在 10 个 shard 的环境下进行了详细的性能测试。以下是使用的 SPL 语句和测试结果:
-
资源利用效率:
- IngestProcessor 方案将客户端 CPU 占用从 16 核心降至 1 核心,减少了 93.75% 。
- 同时保持了 320MB/s 的高采集速率,与不解析正则时的多行采集极限速率接近。
-
性能平衡:
- 虽然采集速率略有下降,但资源占用的大幅减少使得整体效率显著提升。
- 对于资源受限的环境,这种轻微的速度降低是完全可以接受的。
-
可扩展性:
- 通过将处理负载转移到云端,客户端获得了更大的扩展空间。
- 这种方案为处理更大规模的日志数据提供了可能性。
实际应用价值
- 成本效益:客户可以通过评估硬件资源成本和 IngestProcessor 使用成本,灵活选择适合自己的方案,降低了总体拥有成本。
- 灵活部署:使客户能在资源受限的环境中部署高级日志处理功能。
- 快速迁移:与 iLogtail 使用相同的 SPL 语法,便于现有用户快速采用新方案。
结论
通过这次全面的性能测试和优化,我们可以得出以下结论:
- 高效性:优化后的 iLogtail 能够在 8 线程下稳定地处理 300MB/s 的多行日志数据并进行正则提取,展现了卓越的性能。
- 灵活的计算迁移方案:在传统的基于 iLogtail 进行日志采集和处理的方案外,结合 iLogtail 的高效采集和 IngestProcessor 的强大处理能力,我们实现了一个既高效又灵活的日志处理方案,能够在 1 线程下稳定地处理 300MB/s 的多行日志数据并进行正则提取。这种组合能够满足各种复杂的日志处理需求,而不会对客户端性能造成额外负担。
注意事项:正则提取的性能还受到正则表达式本身复杂度的影响。如果正则表达式设计得过于复杂,或者包含大量的回溯操作,可能会导致匹配效率显著下降,尤其是在处理大规模数据时。因此,在编写正则表达式时,应尽量优化其结构,避免不必要的嵌套和冗余匹配。
相关链接:
【1】iLogtail 启动参数配置文档:
【2】ESSD 云盘官方文档:
评论记录:
回复评论: