
11 月 30 日,Rust China Tour 武汉站在武汉恺德光谷城际酒店举行。本次活动汇聚了来自 Databend、GreptimeDB、华中科技大学的多位 Rust 技术专家和研究者,共同探讨 Rust 语言在前沿技术中的创新应用。Databend 数据库研发工程师张祖前在活动中带来主题演讲《云原生数仓 Databend 的 Rust 开发实践》,重点探讨 Databend 的设计与开发过程,为何选择 Rust 进行开发,以及在使用 Rust 开发过程中的心得与经验。

Databend 是一个使用 Rust 研发,基于对象存储设计的新一代的云原生数据仓库产品。它实现了真正的存储与计算分离架构,能够提供高性能、低成本、按需按量使用等能力,兼容 MySQL、ClickHouse 协议,提供了极速弹性扩展能力+强分布式,致力于解决大数据分析成本和复杂问题。
Databend 在设计之初就全面拥抱云原生理念,将存储和计算完全解耦,将对象存储作为存储层,使用云对象存储来持久化存储数据,支持如 S3、Azure Blob、MiniIO、HDFS 等 20 多种对象存储协议。
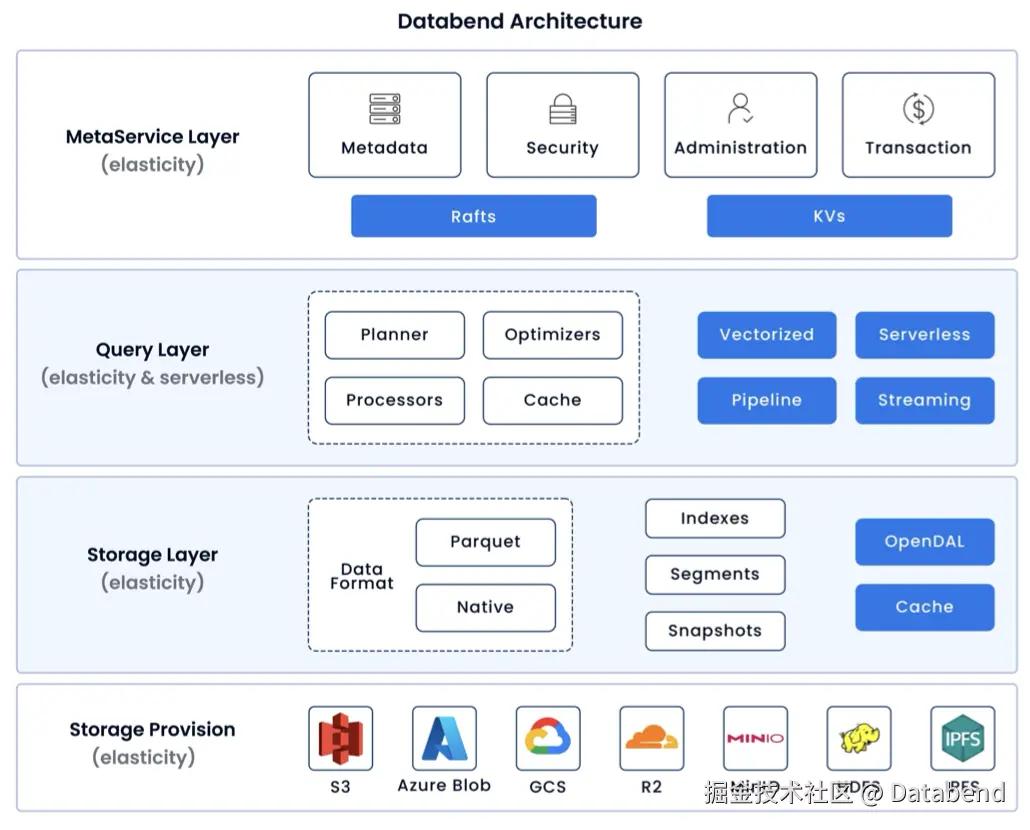
在 Databend 的架构中,计算节点是完全无状态的,每个计算节点都可以独立拓展或回收。这种无状态的设计大大简化了故障恢复的流程,增强了系统的响应速度。为了提升查询性能,Databend 使用了列式存储格式,并通过高效的元数据管理系统实现数据的快速定位和访问。元数据管理(Meta Service)采用了 Raft 共识协议进行分布式应用,可以实现多租户隔离和资源分配。
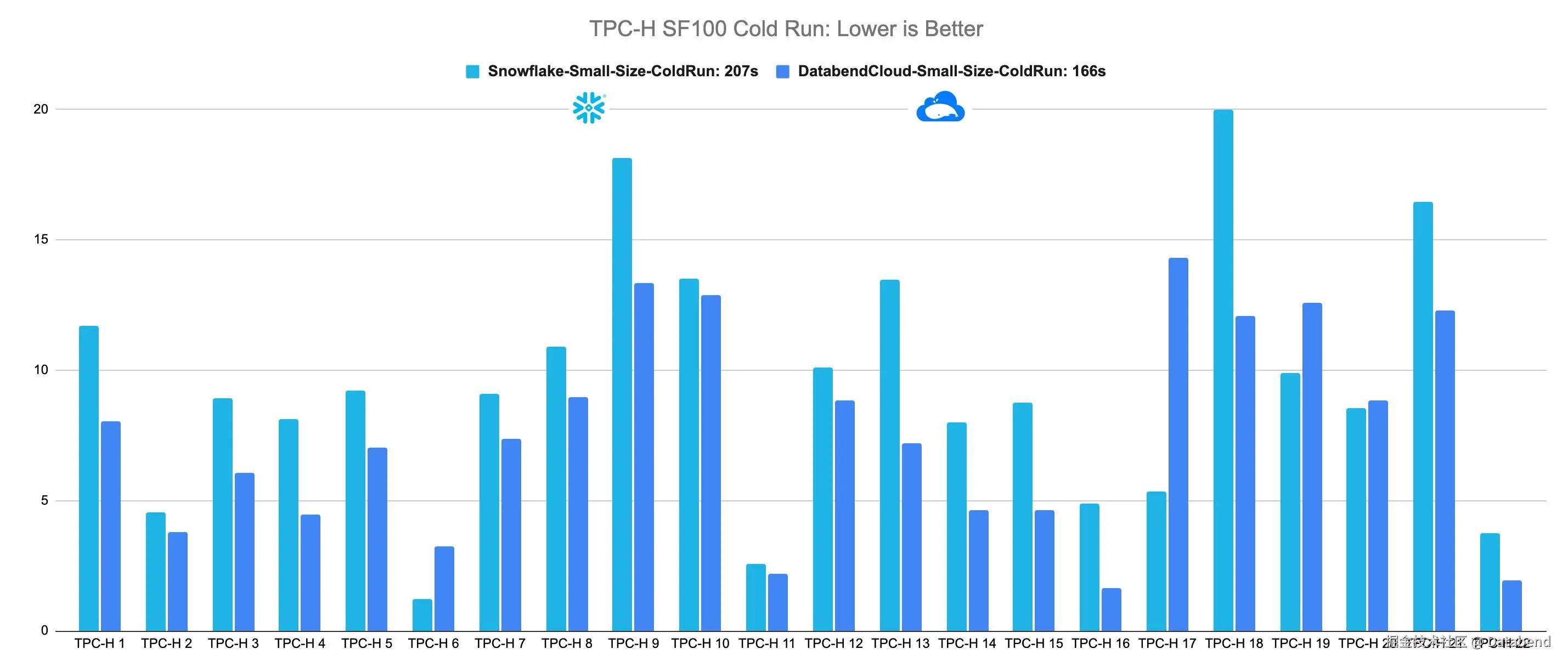
Databend 在多个性能测试中表现优异,其中在 TPC-H 的基准测试中,在相同规格下,Databend 的性能比 Snowflake 高出约1.3 倍,但成本只有 Snowflake 的一半。
目前,Databend 向用户提供两种主要产品形式,一种是 Databend Cloud,一种是私有化部署。
Databend Cloud 是以开源项目 Databend 作为核心,提供一站式 SaaS 服务,支持国内外多个公有云部署,用户可以根据自身实际情况自由选择。
在私有化部署方面,Databend 提供了社区版和企业版两个版本。其中,社区版是完全开源的,开源用户可以自行部署,企业版主要针对企业级用户,提供了更多高级功能,比如用户自定义函数,清理历史数据等等,还可以享受企业级专属支持服务。
为什么选择 Rust 作为开发语言?
Databend 早期的开发成员,之前大部分是 ClickHouse、TiDB、Oceanbase、MySQL 等项目的开发者,主要技术栈是 C++ 和 Go。Databend CEO 张雁飞在创立 Databend 前,也用 Go 实现过一个向量化的计算引擎原型(VectorSQL)。但在实际测试过程中,我们发现 Go 语言不能满足数据库对高性能的需求,因为垃圾回收等问题,它在高性能方面有一些欠缺。这个时候,我们发现了 Rust ,它的所有权与借用、生命周期模型,保证了内存安全性,无需依赖垃圾回收。同时,Rust 的编译时检查能够保证线程安全,避免了空指针缓冲,缓冲区溢出等问题,极大地减少了运行时崩溃的可能性。相比之下, C++ 需要开发者手动管理内存,容易引发内存泄露或者一些未定义的行为。
得益于零成本抽象,Rust 的高级功能,如泛型、模式匹配等,不会引入运行时开销。通过在编译时检查,Rust 可以避免数据竞争的问题,实现类型安全的高效并发模型,并且能够原生支持异步。相比于 C++ , Rust 的工具链可以使开发过程更加高效。
综上所述,相对于 C++ 和 Go,Rust 能够在安全性、性能、开发体验之间实现平衡,特别适合如 Databend 这种高性能数仓的场景。它既能满足对底层性能的极致需求,又可以通过内存安全和并发模型来减少开发难度和潜在的问题。这种独特的优势使得 Rust 成为构建云原生高性能系统的理想语言。现在很多开发 Serverless DB 的厂商,都在使用 Rust 作为内核开发语言,用 Go 实现业务代码。
Rust 开发过程中的高性能实践
Dispatch

Rust Trait 是一种对于类型行为的抽象,类似于 Java 的 interface( 接口)。在系统调用一个 Trait 的时候,因为可能有多个不同的实例实现了 Trait,我们需要知道到底是哪个实例和具体的类型。这主要分成两种分派方式:静态分派和动态分派。
静态分派(Static Dispatch)在编译的时候就能够确定调用的具体实现(如上图左),它没有运行时开销,在编译的时候通过单态化,可以为每种具体的类型生成专门的代码。Rust 可以通过泛型和特征约束的方式来实现这种静态分派。
它的优点是性能高,函数调用在编译的时候就已经确定了具体的类型和方法,避免了运行时的开销。同时,Rust 允许编译器进行一些优化,Rust 的类型系统在编译的时候要验证所有特征约束,以保证类型的行为符合预期,但它也有一个缺点——代码膨胀。在编译的时候,它需要为每一种具体的类型生成代码方法,所以会导致编译过程中生成的代码量膨胀,可能会拖慢编译的速度,并且会增加最终生成的二进制文件的体积。所以,相对于动态分派(Dynamic Dispatch),静态分派的灵活性比较低。
动态分派用于一些隐藏不必要的类型信息,从而能够提高封装性,并且能够简化实现。这意味着它只有在运行的时候,才能够确定方法调用的具体实现。程序必须通过虚表 vtable,来查找类型信息。这样的话,它虽然提高了灵活性,但也带来了额外的运行时开销。
这两种分派有各自的优缺点,有不同的使用场景。假如对性能敏感的部分,如数据库在做 Function 计算的时候,我们更推荐静态分派的方法;当需要扩展性或者多态性支持的时候,更推荐使用动态分派。
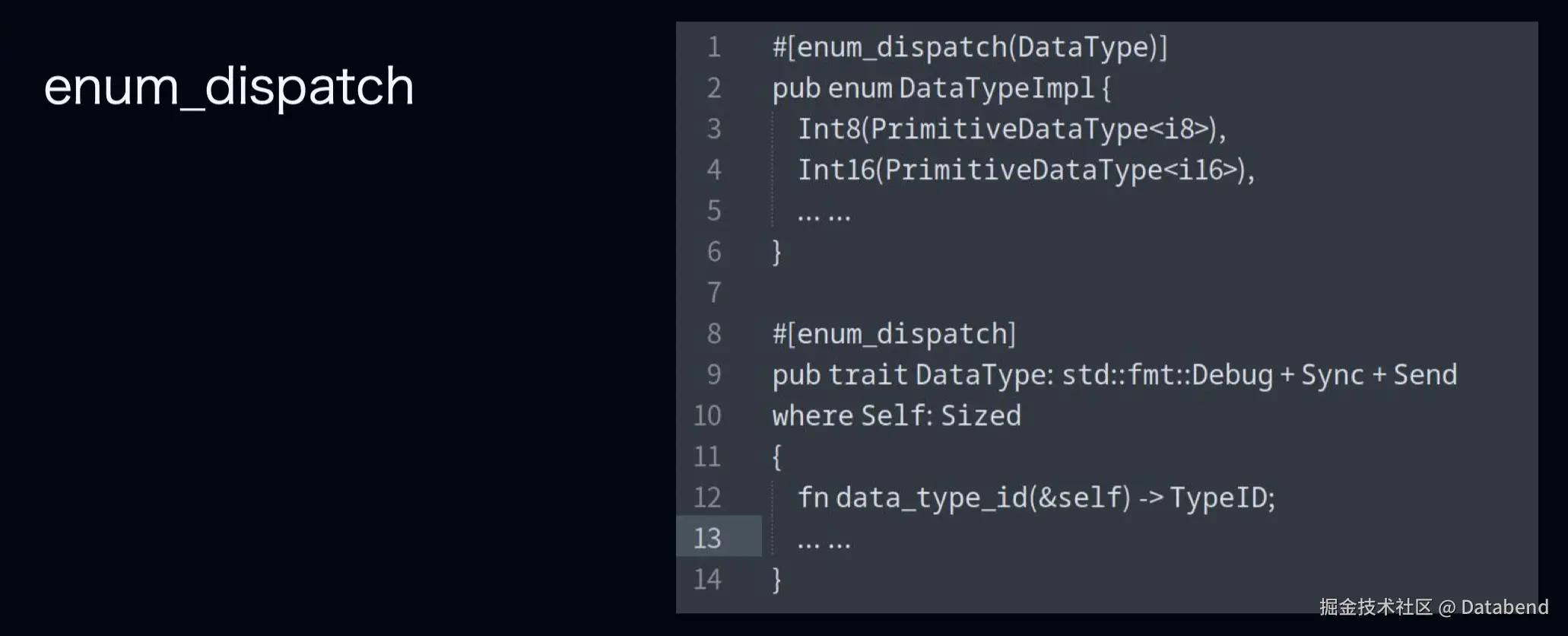
除此之外,还有一种方法叫 enum_dispatch,它是一个宏,用于优化动态分派的特征访问,通过把 Trait 对象转换成具体的复合类型,在编译器为枚举的各个变体实现特定的代码,来实现 Trait 方法的代理。这样做它会避免运行时的分派,同时又可以具备动态分配那样的灵活性。它事实上是一种语法糖,本质上还是一种静态分派。
延迟初始化(Lazy Initialization)
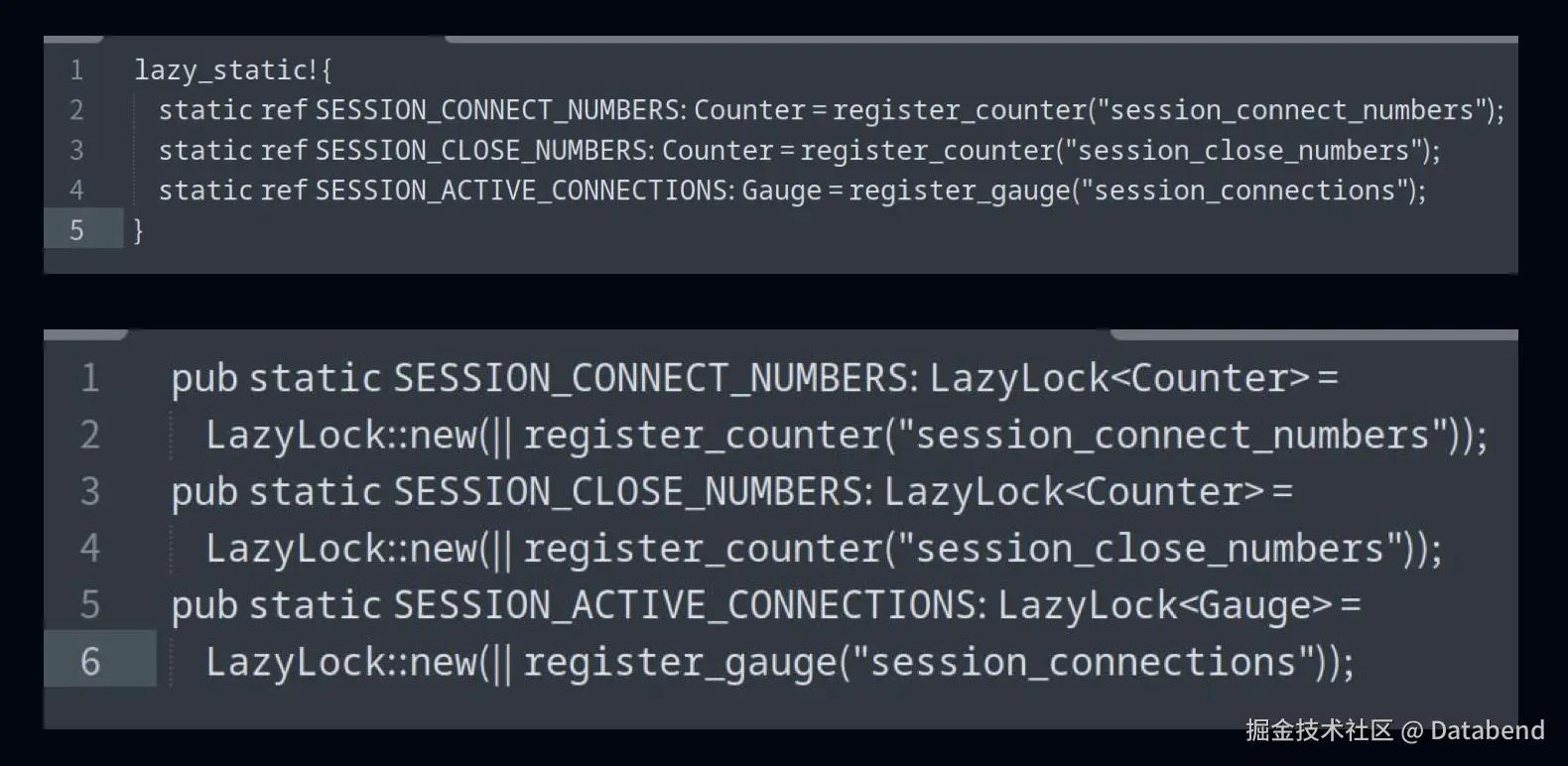
Rust v1.8 之后提供了稳定的 Lazy lock 的方法,用这种方法,静态数据的值只有在第一次线程安全访问的时候才会进行初始化,从而避免了不必要的提前计算或者资源占用。
静态求值
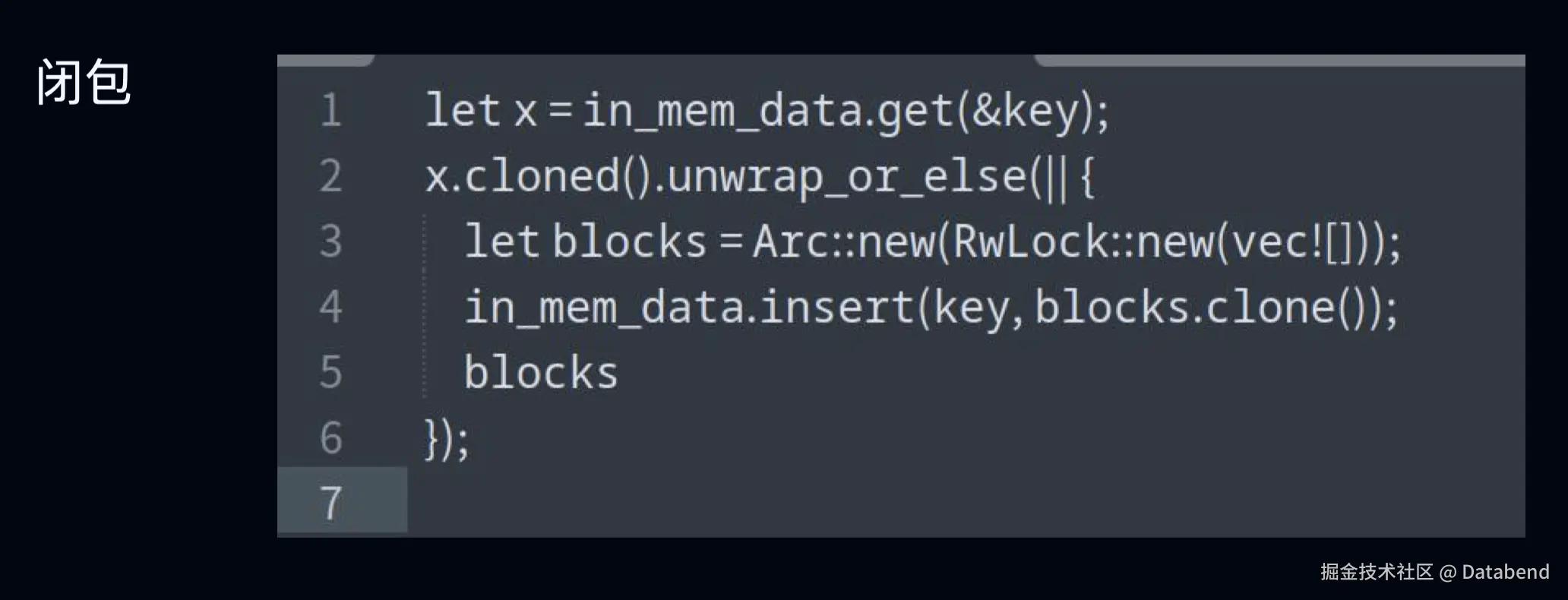
静态求值是静态计算表达式的值。我们可以让 Rust 使用闭包来实现这一点,只有在真正需要的时候才会进行计算,能够避免不必要的计算,我们在使用 Result 或者 Option 的时候,可以用它提供的一些系统标准库的方法,比如类似 unwrap_or_else 来实现。
内联
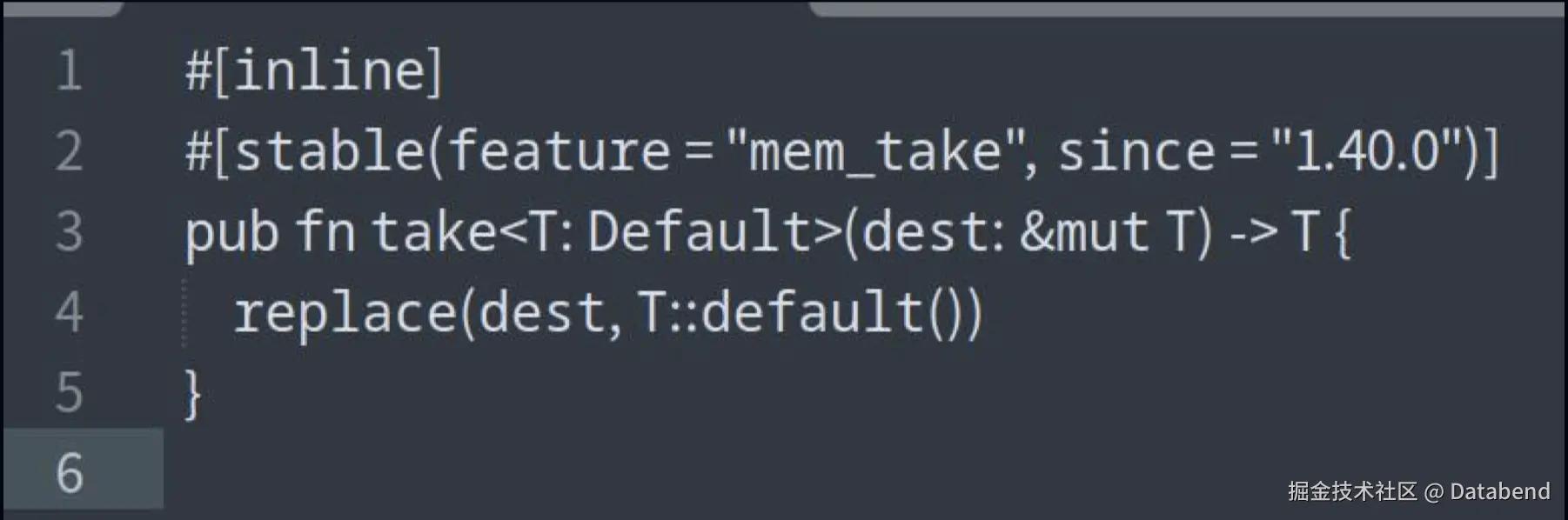
当 Rust 调用一个函数的时候,它通常会有以下的开销:
首先是创建栈帧,每次函数调用都会为该函数分配一个栈帧。在执行函数调用的时候,需要跳转指令,程序需要跳转到函数的代码位置,执行完成之后,再跳回到原调用的地方,这样很明显会有一些开销。
inline是一个优化的提示,它允许编译器将函数调用直接替换为函数体,从而减少函数调用的开销。一个函数调用另外一个函数,如果另外一个函数加了一个 inline 的优化提示,那么编译器会可能地在编译的时候,把这个函数体替换到调用的地方,这样的话就不需要再去创建栈帧或者跳转指令。
对于内联,我们建议对性能敏感的公共 API 或者跨crate实现,使用的一些关键路径的函数可以添加内联。一般来说,泛型函数通常会隐式内联,非必要的话不需要去添加。Rust 编译器其实已经足够智能,在编译的时候如果能做内联,它就会给函数做内联。
内联的优点的是减少函数的开销,提高性能。尤其对于一些比较小的调用频繁的函数。但需要注意的是,内联并不总是有益的,特别是对于一些较大的函数,它和静态分派一样,可能会导致代码膨胀,影响编译速度和二进制文件的大小。
内存管理
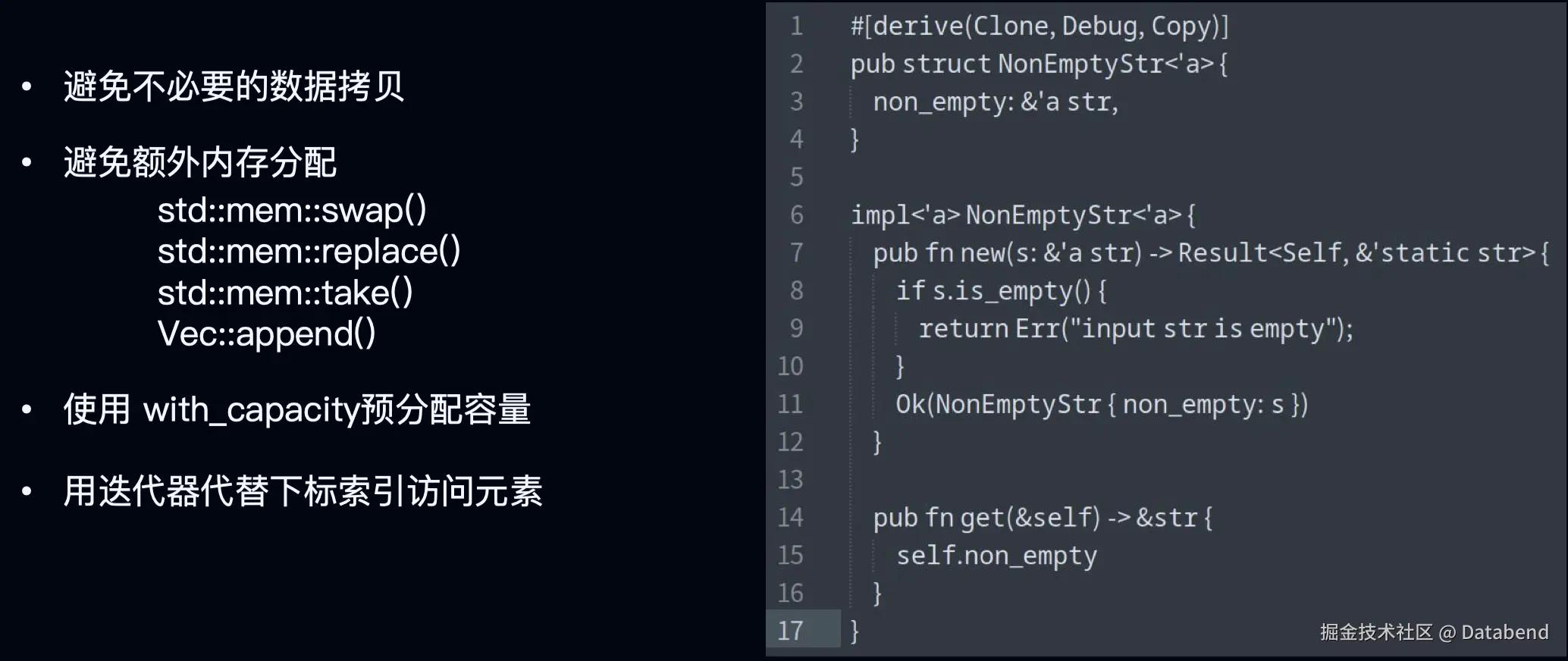
我们需要避免不必要的内存拷贝。比如上图右侧的例子中用了传递引用来避免数据的复制。同时我们还可以用一些系统库里提供的方法,来避免额外的内存分配:
-
swap 可以交换两个值的位置,而没有额外的内存开销;
-
replace 可以给一个指定的变量替换成一个新值,同时返回变量原来的值;
-
take 会把指定的变量替换成默认值,同时返回原来的值;
-
append 通过移动数据,来避免不必要的内存复制。
同时,我们在声明对象的时候,可以用 with_capatity 的方法来预分配容量,避免动态扩展的时候频繁的内存分配。另外,我们建议用迭代器来替代下标索引,来访问元素,避免运行时它需要做边界检查来提升性能。
使用并发
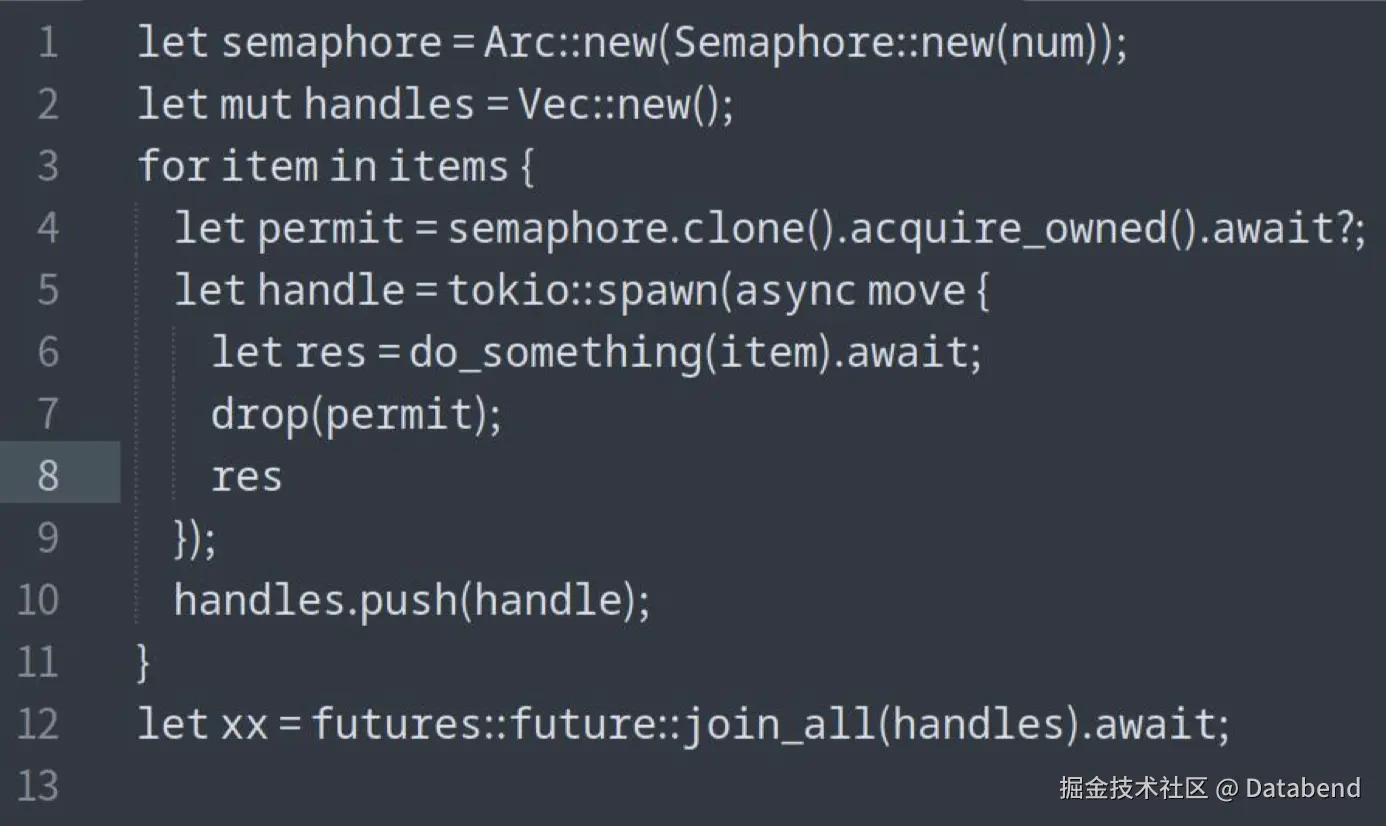
在一些 IO 密集型的场景,从对象存储里读数据,可以使用并发的方式来提高效率。Databend 的归并排序算法原来用常规方法,我们会首先把数据分段做并行排序,再归并起来,用小顶堆或败者树的方法做最终排序。最终的归并排序算法是单线程的,在一些场景下性能非常不理想,databend采用了 merge path 方法,把归并排序过程并行化。需要注意的是我们可以用信号量来限制并发的数量,避免并发过多。
SIMD
SIMD 就是单指令多数据,是 CPU 的一个优化指令,它能够在一个单个核心里实现并行处理。比如 CPU 里有一些特殊的寄存器——宽寄存器,比如一个 256 位的寄存器,可以容纳 16 个 16 位的整数。比如加法,一次指令可以一次性做 4 组数据的加法操作,相对于标量方法只能做一次,很显然会大大提升性能。
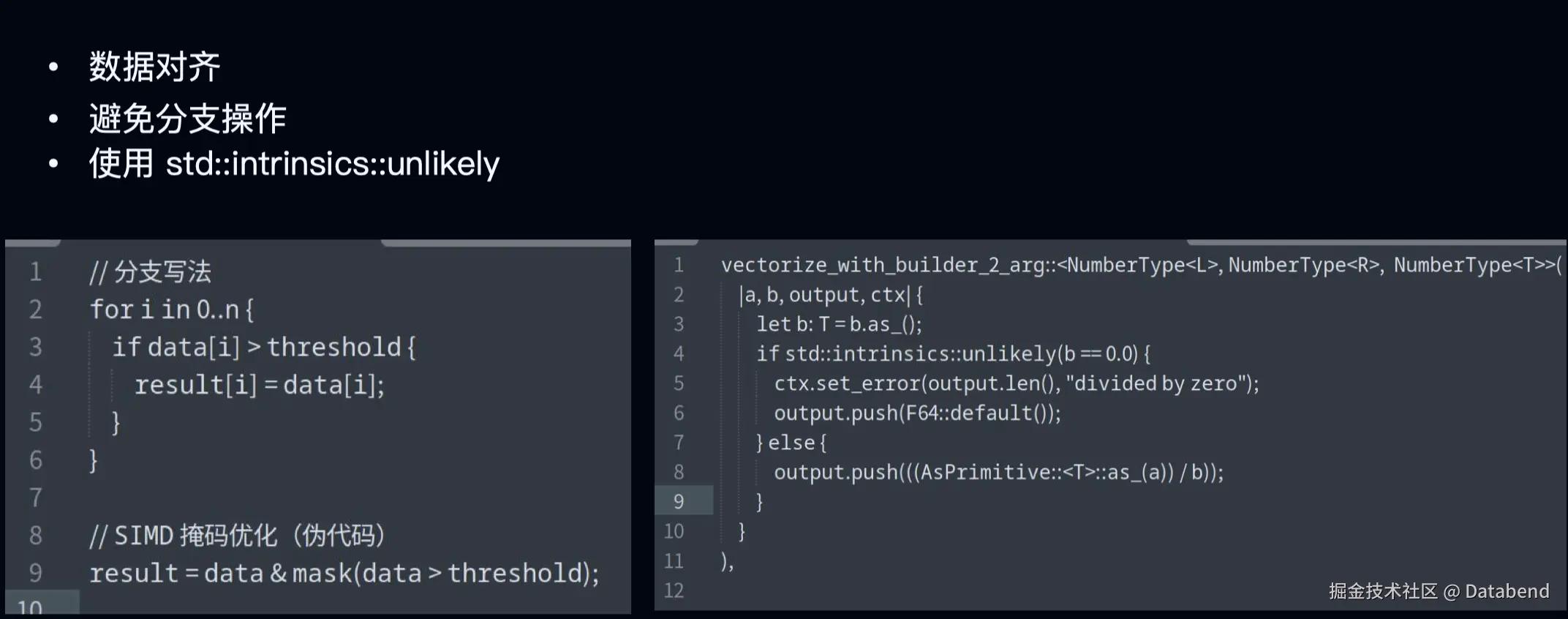
Rust 实现了自动向量化,开发者需要注意尽量编写对 SIMD 友好的代码。首先是数据对齐,我们需要保证数据结构的内存对齐,避免因内存对齐问题而影响 SIMD 的性能。然后要避免分支操作,干扰 CPU 的流水线,降低 SIMD 效率。
上图左下角的例子就是一个分支的写法,我们可以用位运算的方式,把它转换成一个 SIMD 友好的代码。如果实在没有办法避免分支操作,我们还可以用系统库里面的 unlikely方法,来帮助编译器优化分支逻辑,减少一些不太可能执行的代码路径对性能的影响。上图右侧是 Databend 里实现除法的方法,这需要去判断除数是否为 0 。如果是无法避免的,就用 unlikely 的方法减少分支预测,来提高 SIMD 的效率性能。
Unsafe
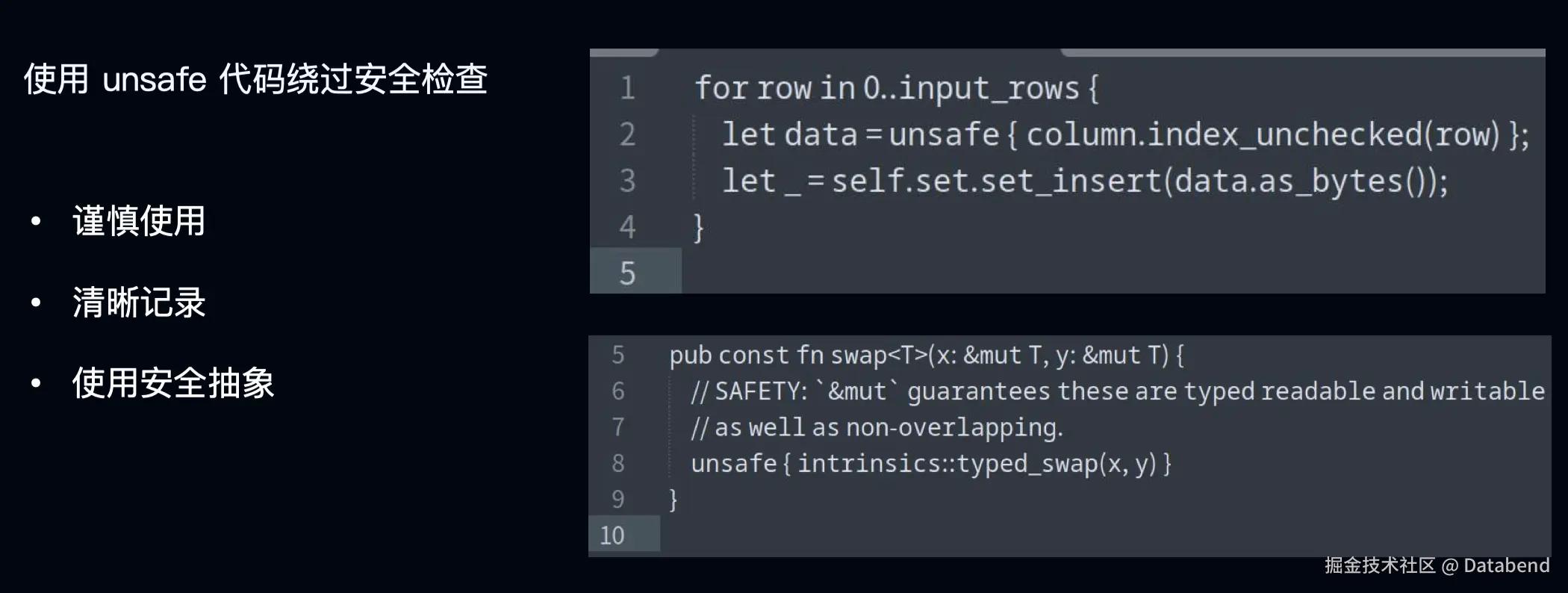
在 Rust 里 Unsafe 的关键字允许绕过编译器的安全检查,来实现更高效的底层操作。如果在关键路径中使用 Unsafe 代码,可以提升性能,但需要确保操作的安全性。非必要还是不建议使用 Unsafe,如果使用尽量将 Unsafe 局限在局部范围内,避免对整个代码库产生影响。
比如上图中为了提高性能,我们用了一个 index_unchecked 的方法,在获取元数据的时候,就不会做边界检查。但事实上我们需要在外部保证 column 不会有问题,我们要能够保证它是 safe 的才去使用它。然后你需要在代码中加一些注释,清晰地记录你使用 Unsafe 的原因以及需要保证的条件,帮助其他开发者理解维护代码。
我们建议使用安全抽象,把 Unsafe 的代码封装在安全接口里,最大限度减少暴露 Unsafe 的部分。比如右下角引用的是系统标准库里的 swap 的方法,它对外提供的是一个 safe 的方法,内部是 unsafe 的代码。
性能剖析
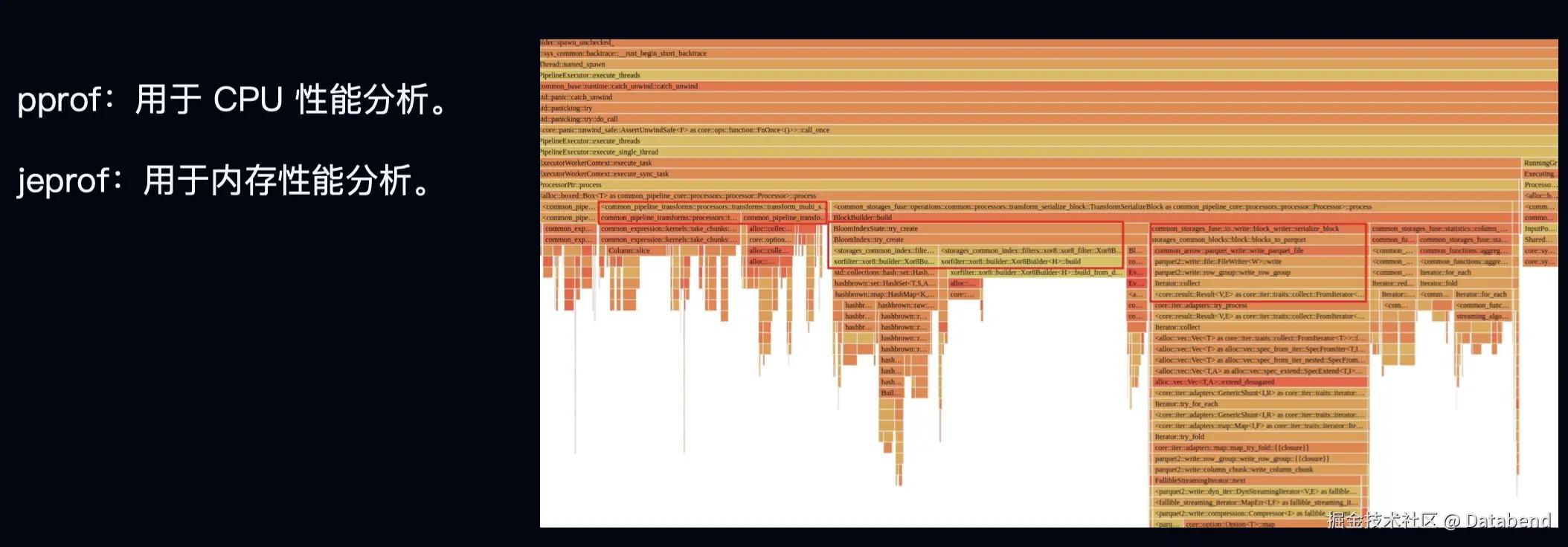
性能剖析的工具和方法有很多,这里主要介绍两种:pprof 和 jeprof。主要用在 CPU 性能分析和内存性能分析里。Databend 集成了这些代码库,可以用库提供的能力来分析我们的代码。 上图右侧是执行了一个 Databend 里面一个 recluster 的操作,运行 pprof 分析,就得到个火焰图。从这个火焰图可以清晰地看到这个操作,这个 SQL ,到底在哪一部分。我们可以针对性地做一些性能优化。
社区共创之路

目前,Databend 在 GitHub 上已经有约 8000 个 star,拥有 200 位 contributors,其中有 40% 多是来自于公司外部的社区成员。社区的活跃让 Databend 的功能不断完善,用户群体也在持续扩大。
除了 Databend 之外,我们还有 Apache OpenDAL,它是一个开放的数据访问层,允许用户以统一的方式轻松有效地从各种存储服务中检索数据。现在,OpenDAL 已经从 Apache 孵化器毕业,应用在多家数据库厂商和企业中。此外,还有Openraft 项目,一个由 Rust 编写的高级 raft 共识协议,用在 Databend 的 Meta Service 层里;Askbend,一个使用 Rust 编写的知识问答系统,可以根据 Markdown 文件创建一个基于 SQL 的知识库,以及 Opensrv,jsonb 等项目。
早在 2021年时,Databend 就制定了一个 Rust 培养计划。我们联合知数堂举办了多期 Rust 公开课,吸引了一大批 Rust 爱好者参与到 Rust 生态里。相关资料在 GitHub 里找到,相关视频资料也可以在 B 站的 Databend 官方号上看到。我们还成立了 「Data Infra 研究社」,邀请内部和外部的朋友们来分享数据库或云原生技术的相关话题。此外,从 2022 年开始至今,我们还参与到ospp的开源之夏项目,吸引在校学生和优秀开发者参与 Databend 的生态创建中。
Databend 从项目创立的第一天起就坚持开源,不论你是 Rust、数据库新手,还是数据库老兵,都欢迎参与到 Databend 的开源项目里。在 Databend GitHub 的 issue 里面有一个 good first issue,新手友好问题,对于刚接触 Rust 或者数据库的朋友们,可以通过这种新手友好问题,尝试参与到 Databend 的开发过程中。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn/
💻 Wechat:Databend
✨ GitHub:github.com/databendlab…
评论记录:
回复评论: