
代码随想录算法训练营第三天 | 链表part01
链表基础
类型
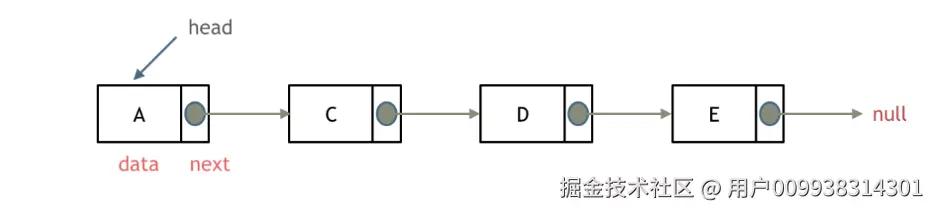
单链表
链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链表的入口节点称为链表的头结点也就是head。
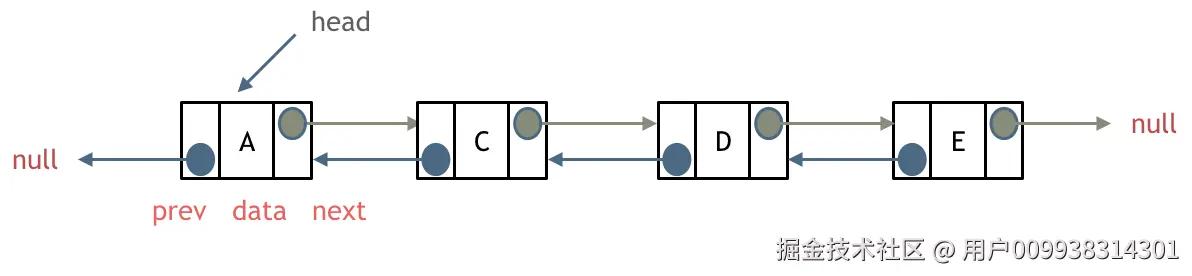
双链表
单链表中的指针域只能指向节点的下一个节点。
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表 既可以向前查询也可以向后查询。
如图所示: 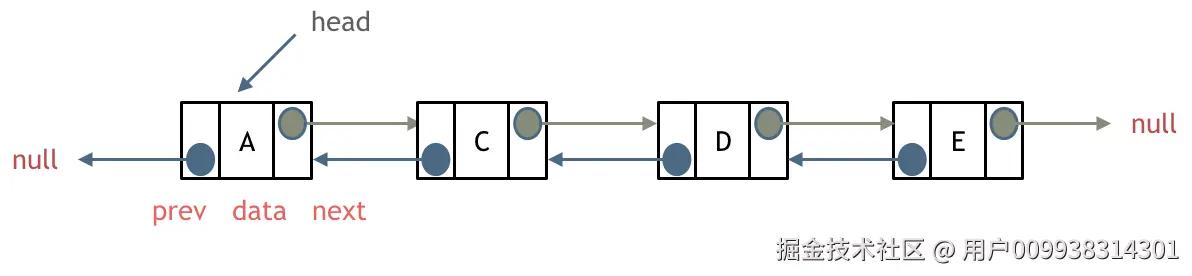
循环链表
循环链表,顾名思义,就是链表首尾相连。
循环链表可以用来解决约瑟夫环问题。
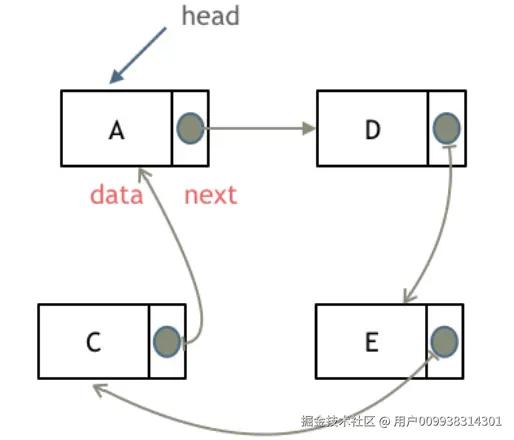
存储方式
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
如图所示:
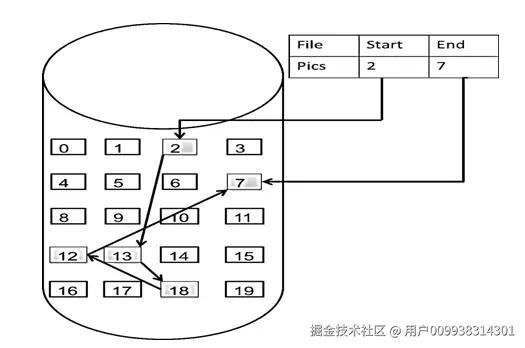
这个链表起始节点为2, 终止节点为7, 各个节点分布在内存的不同地址空间上,通过指针串联在一起。
定义
python 代码解读复制代码class ListNode:
def __init__(self, val, next=None):
self.val = val
self.next = next
操作
删除节点
删除D节点,如图所示:
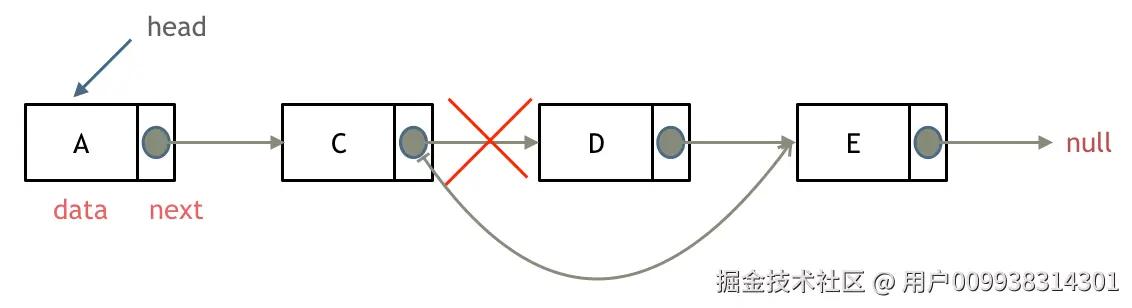
只要将C节点的next指针 指向E节点就可以了。
那有同学说了,D节点不是依然存留在内存里么?只不过是没有在这个链表里而已。
是这样的,所以在C++里最好是再手动释放这个D节点,释放这块内存。
其他语言例如Java、Python,就有自己的内存回收机制,就不用自己手动释放了。
添加节点
如图所示:
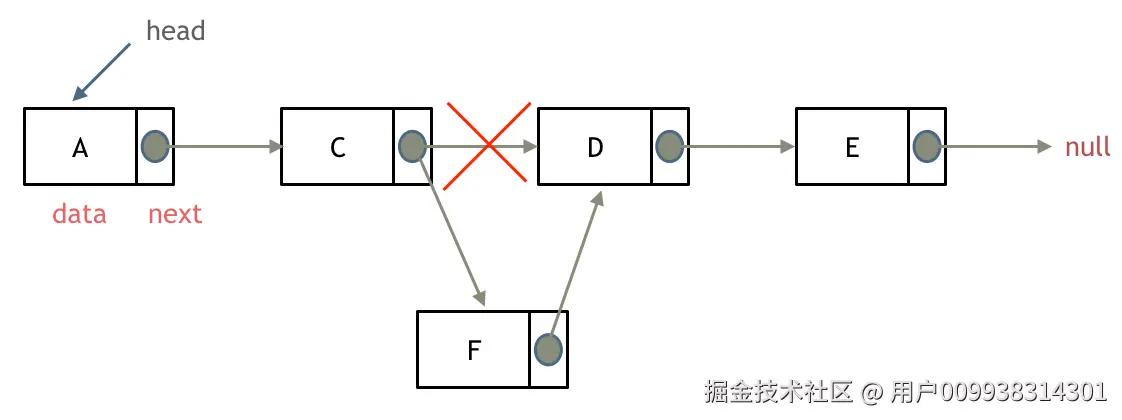
可以看出链表的增添和删除都是O(1) 操作,也不会影响到其他节点。
但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是O(n)。
性能分析
再把链表的特性和数组的特性进行一个对比,如图所示:
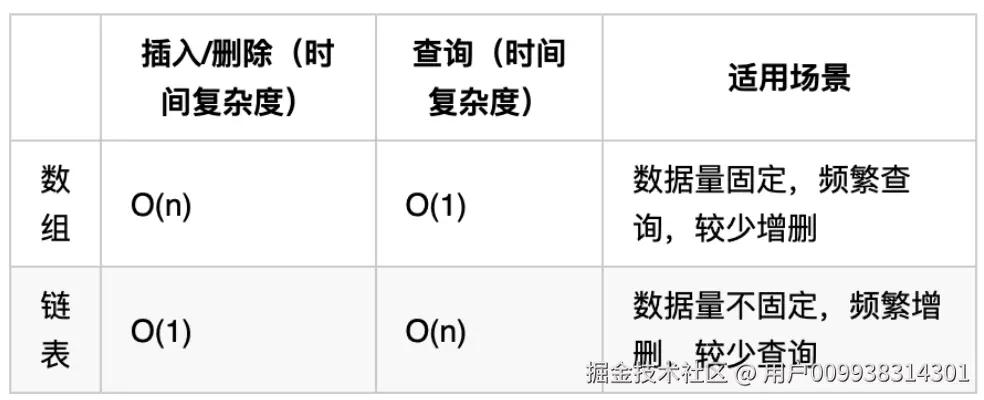
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。
203 移除链表元素
从一个链表里面删除指定的元素,这个看起来很简单,写起来就需要动点脑子了。
首先我们需要假设一种情况,删的如果是第一个元素该怎么办?
为了直接去掉这种情况,我们让第一个节点变成第二个节点,也就是加入一个虚拟的头节点。
python 代码解读复制代码# 有了虚拟的头节点
# 我们就可以直接进行删除操作
# 遇到val,那么next = next.next
# 没有遇到val,那么就正常往后遍历
def removeElements(self,head,val):
dummy_head = ListNode(next = head)
current = dummy_head
while current.next:
if current.next.val == val:
current.next = current.next.next
else :
current = current.next
return dummy_head.next
707 设计链表

单链表实现
一共就是定义5个方法,首尾添加两个,指定添加一个,指定删除一个,得到data一个。
如果使用单链表,那么我们依旧采用虚拟的头节点。
首添加:只需要让dummy_head.next = 添加的节点就行了
尾添加:需要一直遍历到最后一个,直到current.next == NULL 的时候,current.next = 添加的节点
指定添加:可以对每次遍历加一个count,count对应于index
指定删除:同上,只需要断开后接上下一个就ok
得到data:同上,输出data
python 代码解读复制代码# 手写一下,首先添加节点的时候需要注意的是添加了一个节点,所以我们需要定义一个节点类,这个类里有一个初始化方法,里面有2个属性,node和val。
class LinkNode:
def __init__(self,val=0,next=None):
self.val = val
self.next = next
class MyLinkedList(object):
def __init__(self):
# 初始化的时候我们需要设置一个虚拟节点 只要是新加入的节点都必须进行初始化
self.dummy_head = LinkNode()
self.size = 0
def get(self, index):
# 首先对index进行判断
if index < 0 or index >= self.size:
return -1
current = self.dummy_head.next
for i in range(index):
current = current.next
return current.val
def addAtHead(self, val):
self.dummy_head.next = LinkNode(val,self.dummy_head.next)
self.size += 1
def addAtTail(self, val):
current = self.dummy_head
while current.next:
current = current.next
current.next = LinkNode(val)
self.size += 1
def addAtIndex(self, index, val):
if index < 0 or index > self.size:
return -1
current = self.dummy_head
for i in range(index):
current = current.next
current.next = LinkNode(val,current.next)
self.size += 1
def deleteAtIndex(self, index):
if index < 0 or index >= self.size:
return -1
current = self.dummy_head
for i in range(index):
current = current.next
current.next = current.next.next
self.size -= 1
单链表的差不多了,其实说白了就是添加节点的时候都需要明白添加的是一个节点
双链表实现
双链表法其实做这种题会相对简单。
但是代码写起来会很复杂。其运用的思想就是看index和size//2的关系,从而决定是用前驱还是用后继。
因为有首尾节点,如果Index 定义指针cur指向头节点,指定pre指向cur的前一个 然后while(cur) ,用一个temp来存储cur的后一个指针,然后cur的后一个指针指向pre,pre指向cur,cur指向temp。 其实和双指针法一样,就是把双指针法中的循环写在了一起。 完整代码如下:
class ListNode:
def __init__(self, val=0, prev=None, next=None):
self.val = val
self.prev = prev
self.next = next
class MyLinkedList:
def __init__(self):
self.head = None
self.tail = None
self.size = 0
def get(self, index):
if index < 0 or index >= self.size:
return -1
if index < self.size // 2:
current = self.head
for i in range(index):
current = current.next
else:
current = self.tail
for i in range(self.size - index - 1):
current = current.prev
return current.val
def addAtHead(self, val) :
new_node = ListNode(val, None, self.head)
if self.head:
self.head.prev = new_node
else:
self.tail = new_node
self.head = new_node
self.size += 1
def addAtTail(self, val):
new_node = ListNode(val, self.tail, None)
if self.tail:
self.tail.next = new_node
else:
self.head = new_node
self.tail = new_node
self.size += 1
def addAtIndex(self, index, val):
if index < 0 or index > self.size:
return
if index == 0:
self.addAtHead(val)
elif index == self.size:
self.addAtTail(val)
else:
if index < self.size // 2:
current = self.head
for i in range(index - 1):
current = current.next
else:
current = self.tail
for i in range(self.size - index):
current = current.prev
new_node = ListNode(val, current, current.next)
current.next.prev = new_node
current.next = new_node
self.size += 1
def deleteAtIndex(self, index):
if index < 0 or index >= self.size:
return
if index == 0:
self.head = self.head.next
if self.head:
self.head.prev = None
else:
self.tail = None
elif index == self.size - 1:
self.tail = self.tail.prev
if self.tail:
self.tail.next = None
else:
self.head = None
else:
if index < self.size // 2:
current = self.head
for i in range(index):
current = current.next
else:
current = self.tail
for i in range(self.size - index - 1):
current = current.prev
current.prev.next = current.next
current.next.prev = current.prev
self.size -= 1
# Your MyLinkedList object will be instantiated and called as such:
# obj = MyLinkedList()
# param_1 = obj.get(index)
# obj.addAtHead(val)
# obj.addAtTail(val)
# obj.addAtIndex(index,val)
# obj.deleteAtIndex(index)
206 反转链表
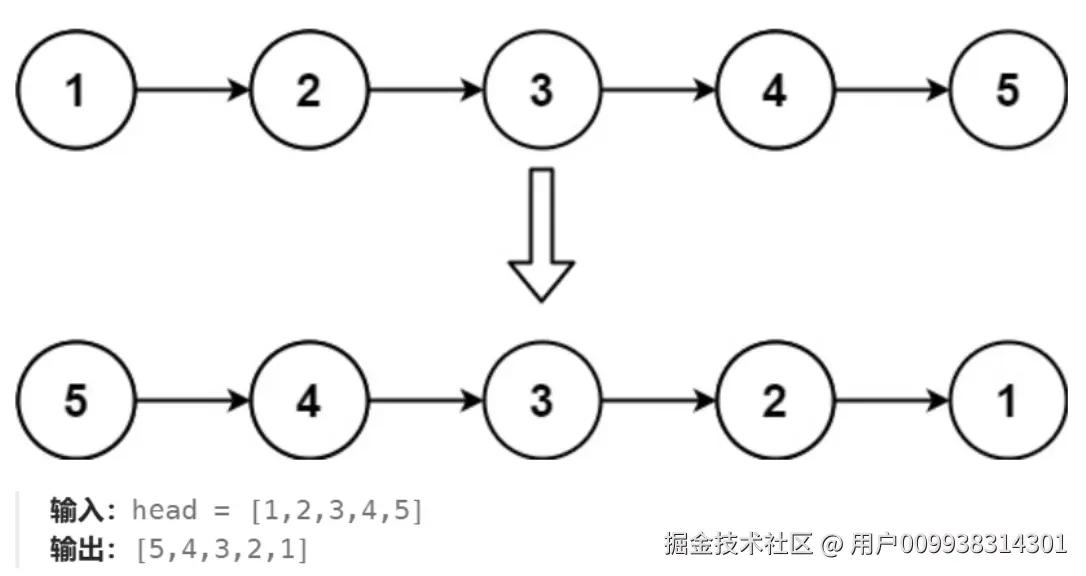
双指针法
while(cur):
temp = cur.next
cur.next = pre
pre = cur
cur = temp
return pre
# 因为pre指向新链表的头节点,cur指向的是Null
递归法
def reverse(cur,pre):
temp = cur.next
cur.next = pre
reverse(temp.cur)
class Solution:
def reverseList(self, head):
return self.reverse(head, None)
def reverse(self, cur, pre):
if cur == None:
return pre
temp = cur.next
cur.next = pre
return self.reverse(temp, cur)
评论记录:
回复评论: