

本来应该写 LeakCanary 源码阅读 系列的第四篇文章,第四篇文章主要是介绍它是怎么处理 HPROF 内存快照文件,但是直接阅读源码可能大多数时候都是懵逼的,所以本篇文章我决定先详细介绍一下 HPROF 文件结构,磨刀不误砍柴工嘛。
Android 的 HPROF 文件也是满足基本的 Java HPROF 文件结构的,只是自己增加了几种特有的 Record。我们先通过下面一张大图描述一下它的结构,后面再详细解释下。
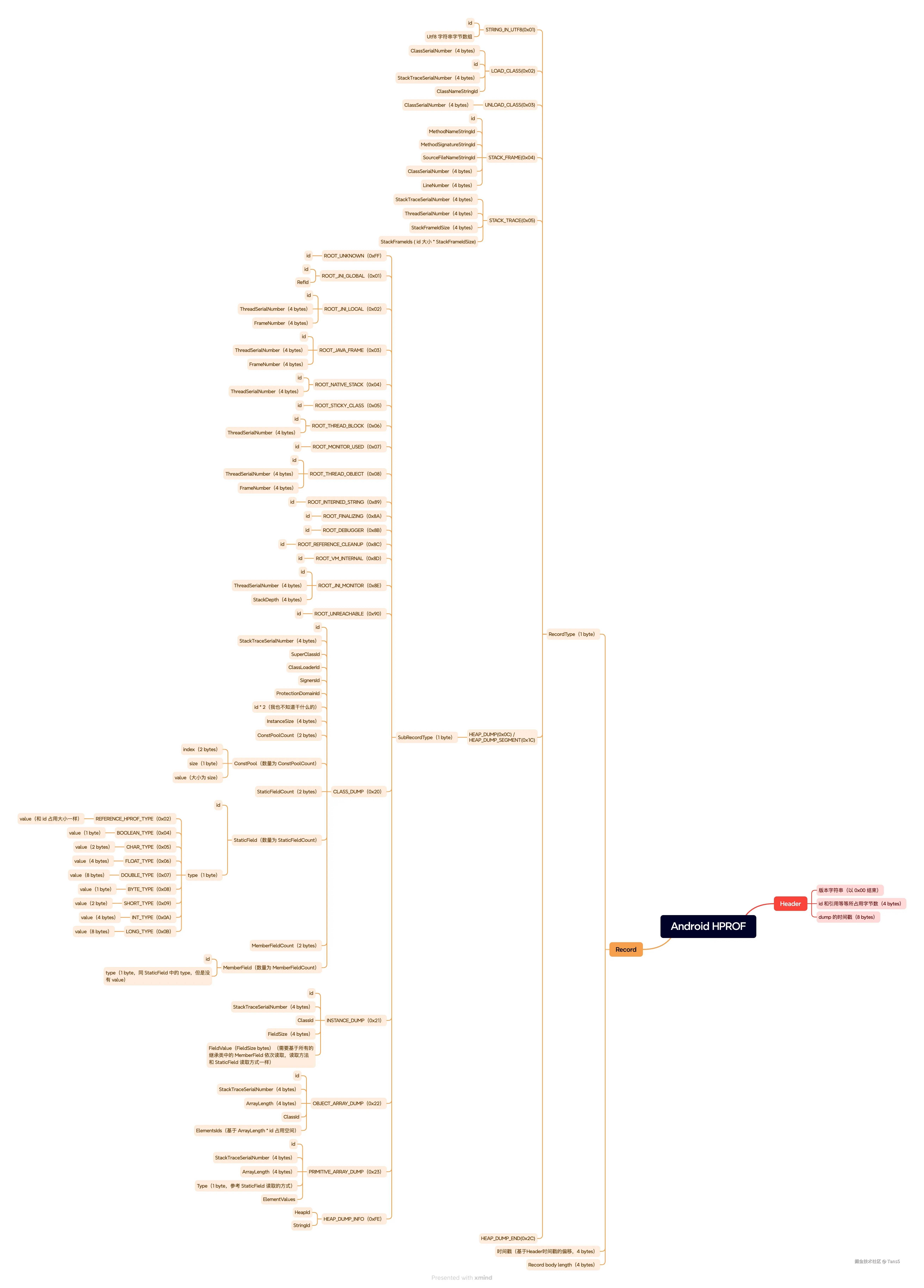
根据上面的图我们可以看到 HPROF 分为两个部分,一个是 Header 和 Recorder,其中 Header 是非常简单的,其中 Recorder 就非常复杂了,我们所需要的所有信息也都保存在 Recorder 中,我上面的图也是根据我看 LeakCanary 的源码总结的,并不是适配了所有的 Java HPROF 的 Record,但是 Android 肯定全部都适用的,如果还有一些特殊的 Record 类型,你可以去查查别的资料,但是基础的格式类型都是满足上面图表中的描述的。
0 Header
0.0 版本字符串
版本的字符串以 0x00 结束,前面的都是用来描述版本的字符串字节数组。具体版本参考我以下的代码:
Kotlin 代码解读复制代码/**
* Supported hprof versions
*/
enum class HprofVersion(val versionString: String) {
JDK1_2_BETA3("JAVA PROFILE 1.0"),
JDK1_2_BETA4("JAVA PROFILE 1.0.1"),
JDK_6("JAVA PROFILE 1.0.2"),
ANDROID("JAVA PROFILE 1.0.3")
}
Android 的版本固定为 JAVA PROFILE 1.0.3。
0.1 各种 ID 和引用所占的字节数(4 bytes)
这是用来描述当前的 HPROF 文件中的 ID 和引用类型所占的字节数,通常都是 4 个字节,我上面的大图中没有描述字节数的地方都是根据这个值来判断字节数。
0.2 Dump 的时间戳(8 bytes)
1 Record
1.0 RecordType(1 byte)
也就是不同的 Record 的类型标识,后面我会详细讲解重要的 Record。
1.1 时间戳(4 bytes)
也就是当前 Record Dump 时的时间戳,他是基于 Header 中的时间戳的偏移量,所以它只占 4 个字节。
1.2 RecordBodyLength(4 bytes)
后续 Record 的内容所占的字节数。
1.3 RecordBody
Record 的详细内容,长度为上面读取到的 RecordBodyLength。
2 Record 的类型
2.0 STRING_IN_UTF8(0x01)
也就是保存各种字符串的 Record,像类名,方法名,变量名等等,其中用到的字符串都保存在这里,每个字符串都有一个 ID 标识,使用到的地方都通过这个 ID 来描述,通过 ID 就能够找到对应的 String 了,它也占用了大量的存储空间。
2.0.0 ID
2.0.1 Utf8 字符串字节数组
2.1 LOAD_CLASS(0x02)
已经加载了的 Class。
2.1.0 ClassSerialNumber(4 bytes)
Class 对应的序列号,大多数其他地方用到 Class 的地方都是用序列号来表示的。
2.1.1 ID
通过这个 ID 能够找到 Class 对应的实例对象。
2.1.2 StackTraceSerialNumber(4 bytes)
对应的栈的序列号,遗憾的是 Android 固定为 -1,也就是不支持。
2.1.3 ClassNameStringId
Class 的名字对应的 StringId。
2.2 UNLOAD_CLASS(0x03)
还未加载的 Class。
2.2.0 ClassSerialNumber(4 bytes)
2.3 STACK_FRAME(0x04)
也就是描述一个线程方法栈中的一个栈帧,很遗憾的是 Android 也不支持这个,其他的 JVM 虚拟机支持,这对分析问题也有很大的帮助。
2.3.0 ID
通过该 ID 能够找到对应的引用实例。
2.3.1 MethodNameStringId
方法名 StringId。
2.3.2 MethodSignatureStringId
2.3.3 SourceFileNameStringId
源码文件名 StringId。
2.3.4 ClassSerialNumber(4 bytes)
对应 Class 名的 StringId。
2.3.5 LineNumber(4 bytes)
对应源码行。
2.4 STACK_TRACE(0x05)
线程的栈信息,Android 不支持。
2.4.0 StackTraceSerialNumber(4 bytes)
栈对应的序列号。
2.4.1 ThreadSerialNumber(4 bytes)
线程序列号。
2.4.2 StackFrameIdSize(4 bytes)
栈帧数量。
2.4.3 StackFrameIds
栈帧对应的 ID,根据 StackFrameIdSize 值和 Header 中定义的 ID 的长度依次去读取,然后再根据值查找对应的 STACK_FRAME,就能够分析出对应线程的栈信息。
2.5 HEAP_DUMP(0x0C) / HEAP_DUMP_SEGMENT(0x1C)
堆信息,这也是我们分析内存问题时最重要的部分,也是解析过程中最复杂的部分,HEAP_DUMP 和 HEAP_DUMP_SEGMENT 的解析方式都是一样,其中 Android 中是 HEAP_DUMP_SEGMENT,其他 JVM 虚拟机是 HEAP_DUMP。一个 HEAP_DUMP_SEGMENT 的 Record 其中可能包含多个子 SubRecord,所以我们需要去循环读取,直到读取完毕。每个子 SubRecord 中开始的一个字节是子 SubRecord 的类型。我们关注的子类型可以大致分为两类 GC Root (子类型以 ROOT 开头) 和 Instance(子类型以 DUMP 结尾),后面我在介绍他们的 SubRecord。
2.6 HEAP_DUMP_END(0x2C)
标记 Record 读取完毕,它没有 Body 内容。
3 HEAP_DUMP / HEAP_DUMP_SEGMENT 的子类型
3.0 GCRoot
看最上面的大图,以 ROOT 开始的 SubRecord 都是属于 GCRoot,可以看到 GCRoot 的类型非常多,比网络上流传的八股文中的 GCRoot 类型多多了,你也可以用其中的一些去考考八股文面试官试试🐶,有很多我也不清楚具体是干什么的,你可以自行再去找找其他的资料,我也不列举所有的 GCRoot 分析了,如果是读取方法直接看我上面的大图就好了。我就列举 ROOT_THREAD_OBJECT 和 ROOT_JAVA_FRAME 两个例子。
3.0.0 ROOT_JAVA_FRAME(0x03)
表示线程的单个 GCRoot 对应的帧。
3.0.0.0 ID
通过这个 ID 能够查询到当前的栈帧对应的 Instance。
3.0.0.1 ThreadSerialNumber(4 bytes)
对应线程序列号。
3.0.0.2 FrameNumber(4 bytes)
帧序列号。
3.0.1 ROOT_THREAD_OBJECT(0x08)
表示线程对象的 GCRoot,通过它可以找到对应的线程实例,进而获取详细的线程信息。
3.0.1.0 ID
通过这个值能够查询到对应的 Java 中的 Thread 的实例,能够获取到详细的线程信息。
3.0.1.1 ThreadSerialNumber(4 bytes)
对应的线程序列号,通过它就可以在 ROOT_JAVA_FRAME 中查询到当前线程所对应的栈帧信息。
3.0.1.2 FrameNumber(4 bytes)
3.1 Instance
中文翻译叫实例吧,其中实例包括 Java Class 对象的实例,普通对象,对象数组和 Java 基本变量数组(就是 Java 中八种基本变量对应的数组,八股文都背烂了)。
3.1.0 CLASS_DUMP(0x20)
CLASS_DUMP 应该是最复杂的 Record 了。
3.1.0.1 StackTraceSerialNumber(4 bytes)
3.1.0.2 SuperClassId
父类对应的 Class 的 ID。
3.1.0.3 ClassLoaderId
对应加载的 ClassLoader 的实例的 ID。
3.1.0.4 SignersId
3.1.0.5 ProtectionDomainId
3.1.0.6 id * 2(我也不知道干什么的)
3.1.0.7 InstanceSize(4 bytes)
当前实例占用的内存,也就是 SallowSize,不计算引用对应的实例占用的内存;如果计算引用对应的实例所占用的内存就是 RetainedSize。
3.1.0.8 ConstPoolCount(2 bytes)
编译时常量数量。
3.1.0.9 ConstPool(数量为 ConstPoolCount)
这里需要根据 ConstPoolCount 数量去循环读取每一个常量的值。常量的数据结构如下:
3.1.0.9.0 Index(2 bytes)
3.1.0.9.1 Size(1 byte)
3.1.0.9.2 Value(大小为 Size)
3.1.0.10 StaticFieldCount(2 bytes)
静态 Field 的数量。
3.1.0.11 StaticField(数量为 StaticFieldCount)
静态 Field,需要根据 StaticFieldCount 的数量去循环读取静态 Field,具体的结构如下:
3.1.0.11.0 ID
通过这个去 STRING_IN_UTF8 中查询对应的 Field 的名字。
3.1.0.11.1 Type(1 byte)
也就是对应的 Field 的类型,因为静态的 Field 已经随 Class 对象已经初始化了,所以它的值就直接顺序读就好了。类型和所占用的空间参考下面:
REFERENCE_HPROF_TYPE(引用,和 id 占用大小一样),BOOLEAN_TYPE(1 byte),CHAR_TYPE(2 bytes),FLOAT_TYPE(4 bytes),DOUBLE_TYPE(8 bytes),BYTE_TYPE(1 byte),SHORT_TYPE(2 bytes),INT_TYPE(4 bytes)和 LONG_TYPE(8 bytes)。
除了 8 种基本类型以外,其他的都是引用,引用都指向一个 Instance。
3.1.0.12 MemberFieldCount(2 bytes)
成员 Field 的数量。
3.1.0.13 MemberField
成员 Field,需要根据 MemberFieldCount 的数量去循环读取成员 Field,和读取静态 Field 类似,不过它只有 Type 而没有 Value,这也很好理解 Class 实例当然没有初始化成员的 Field,而需要等到对应 new 了后才有,当我们需要读取普通 Instance 中的成员 Field 的值的时候就需要 MemberField 了。
3.1.1 INSTANCE_DUMP(0x21)
普通实例对象。
3.1.1.0 ID
3.1.1.1 StackTraceSerialNumber(4 bytes)
3.1.1.2 ClassId
3.1.1.3 FieldSize(4 bytes)
对应的成员 Field 所占用的字节数。
3.1.1.4 FieldValue(FieldSize bytes)
要解析实例的成员 Field 的值相对有一点点麻烦,首先我们要遍历当前实例对应的 Class 的所有父 Class,然后根据 CLASS_DUMP 中的 MemeberField 去依次读取 Field 中的值,读取的方式和读静态 Field 中的值一样。我们把需要读的 Class 排序一下:当前实例的 Class 排第一个,然后 Object 的 Class 排最后一个(因为 Object 是所有类的 SuperClass)。
3.1.2 OBJECT_ARRAY_DUMP(0x22)
对象数组。
3.1.2.0 ID
3.1.2.1 StackTraceSerialNumber(4 bytes)
3.1.2.2 ArrayLength(4 bytes)
数组长度。
3.1.2.3 ClassId
对应的 Class 的 ID。
3.1.2.4 ElementsIds(基于 ArrayLength * id 占用空间)
根据 ArrayLength 和 ID 占用的空间去循环读取对应实例的 ID,然后再 Instance 中去查询就能够获取到对应的 Instance。如果是空的话对应引用的值为 0。
3.1.3 PRIMITIVE_ARRAY_DUMP(0x23)
基本类型数组。
3.1.3.0 ID
3.1.3.1 StackTraceSerialNumber(4 bytes)
3.1.3.2 ArrayLength(4 bytes)
3.1.3.3 Type(1 byte,参考 StaticField 读取的方式)
3.1.3.4 ElementValues
根据 Type 确定基本类型和对应的值的长度,参考静态 Field 中读取值的过程,然后根据 ArrayLength 循环读取就好了。
到这里如何解析 HPROF 文件就讲解完了,后面再介绍一下我自己如何解析线程栈和 LeakCanary 是如何发现泄漏的对象的 GCRoot 的路径的。
解析线程栈
前面其实我已经讲到一点了,这里再总结性地讲一下。首先找到所有的 ROOT_THREAD_OBJECT,它表示线程的 GCRoot,通过它的 ID 值可以查询到对应的 Java Thread 的实例,通过这个实例可以读取很多线程的信息。例如你想要知道线程的名字,就需要读取 name 成员 Field 的值,它是一个指向 String 实例的引用(如何读取成员 Field 的值,前面有介绍),通过引用查找到对应的 String 实例,然后再拿到对应的 value 的成员 Field,它也是一个引用,它指向一个字节数组的实例,找到这个字节数组实例后再以 Utf-8 的编码解析出来就得到了线程的名字。其他的线程信息也是通过类似的方法去解析,这里就不再介绍了。
再继续查找线程栈对应的栈帧所对应的各种实例,在 ROOT_THREAD_OBJECT 中有 ThreadSerialNumber 这个参数,表示线程的序列号,同时 ROOT_JAVA_FRAME 中也有 ThreadSerialNumber 参数,这样也就是 ROOT_THREAD_OBJECT 和 ROOT_JAVA_FRAME 对应上了,这样就能够找到线程对应的栈帧,通过 ROOT_JAVA_FRAME 的 ID 再去实例中查找就能够获取到对应的实例。
我给一个我自己解析主线程的日志:
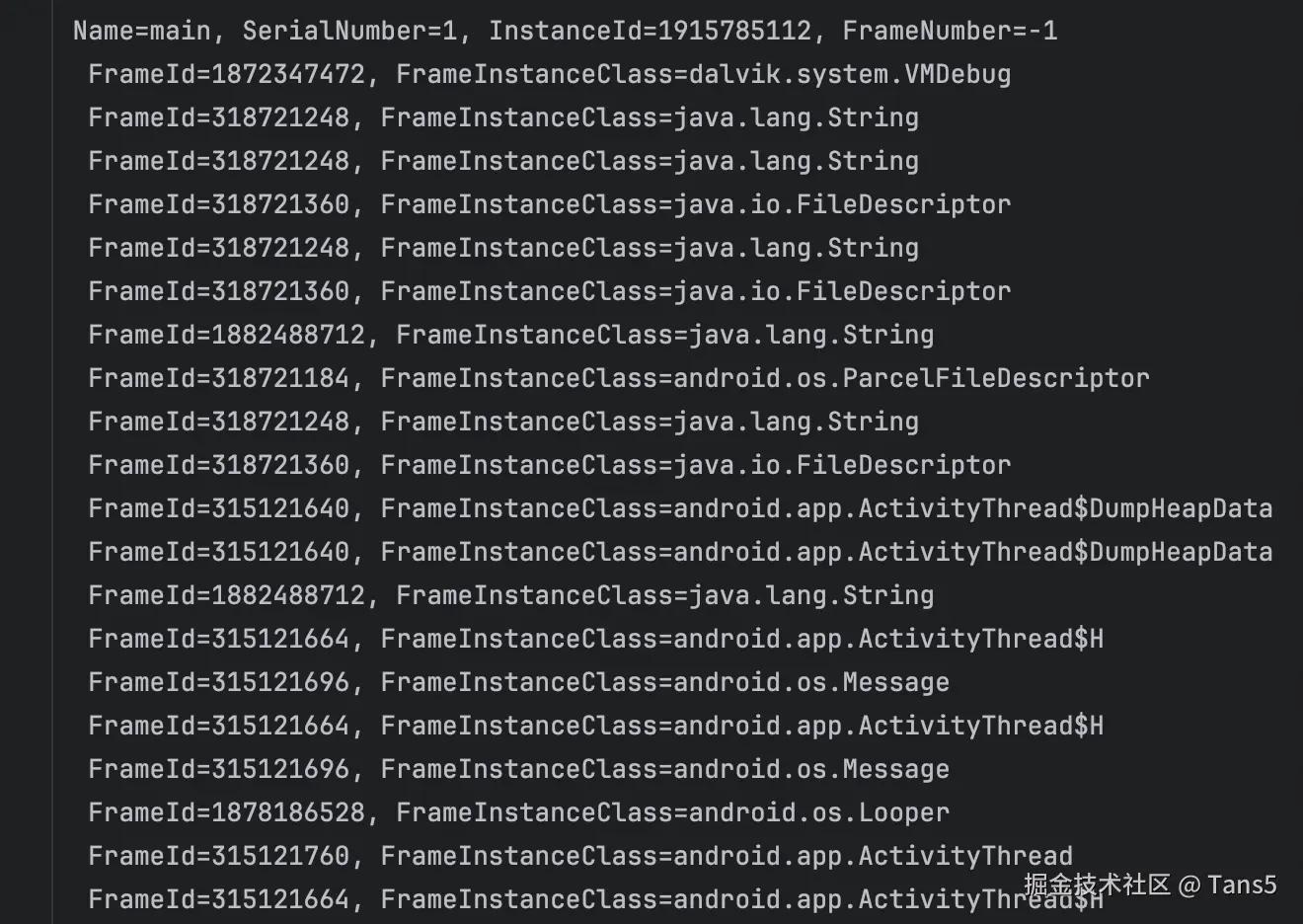
LeakCanary 如何发现泄漏对象 GCRoot 的路径
在前面文章中有介绍 LeakCanary 如何监控泄漏的 Android 组件。这里再回忆下:首先 LeakCanary 会监控 Android 各种组件销毁的生命周期,例如 Activity 的 onDestory() 生命周期回调后,就表示对应的 Activity 实例就应该被回收了。那如何判断对应的实例是否被回收呢?它是通过自定义的 WeakReference 和ReferenceQueue 来监控对象是否被回收,自定义的 WeakReference 的实现类是 leakcanary.KeyedWeakReference。当对象被回收后会被添加到 ReferenceQueue 中,如果没有被回收那么就不会在 ReferenceQueue,同时 WeakReference 中引用的对象也会存在。当出现泄漏后,就去 Dump 内存,成功就能够获取到内存快照 HPROF 文件。这时就需要去解析 HPROF 文件,解析完成后,去查找所有的 leakcanary.KeyedWeakReference 实例,然后再去拿到他们引用的真实的对象。这些对象就是泄漏的对象,到这里虽然拿到了泄漏的对象,但是还无法定位他们泄漏的 GCRoot 路径。要定位泄漏的路径,就需要从所有的 GCRoot 出发依次遍历寻找,上面已经讲过了 ROOT 开头的 Record 都是 GCRoot。从 GCRoot 找到对应的实例,然后解析实例的 Field,如果是引用类型就继续查找,这样就构建了一个完整的从 GCRoot 出发的引用树。当引用的节点中有我们泄漏的对象时,我们就找到了一条泄漏的路径,一直循环直到找到所有的泄漏对象或者便利完全部的 GCRoot 的引用。到这里还差一步,就是一个泄漏对象到 GCRoot 可能有多条路径,需要只保留最近到达 GCRoot 的一条路径。
最后
我自己也仿照 LeakCanary 写了一个解析 HPROF 文件的 demo,感兴趣的可以看看,当了解了 HPROF 文件的结构后对 JVM 的内存管理也有一个新的认识,如果有线上内存问题的时候,也可以自己搜集用户的 HPROF 文件,当然这个文件非常大,那这个时候就需要裁剪操作,比如我只想要当前应用包名的对象的内存占用信息,我就可以裁剪掉我不需要的实例信息,还可以裁剪掉 GCRoot,再优化一下我没有用到的 String。裁剪后的文件就可以上传到服务器。当然我也可以不裁剪,我直接在用户手机上分析问题,将分析的结果上报服务器也行。无论用哪种方法都需要对 HPROF 文件有所了解,我自己也没有在手机上处理分析过 HPROF 文件,感觉这个会有挑战性,也挺有意思。
评论记录:
回复评论: