
中文技术领域中经常有一些词被翻译得奇奇怪怪,而八股文式的传播方式又会加深这种误解,“双亲委派模式”便是其中的一个。其误解的地方在于两点:
-
英文中叫作"Parent Delegation Model",它强调的是parent-first的委派加载模式。它是"parent",不是"parents",因此不存在双亲的概念。中文翻译成“双亲”,的确容易造成误解。这就好比,我们叫"parent class"不会叫它“双亲类”,而是叫它“父类”。因此这里叫作“父委派模式”更合理些,或者大胆一点,就叫”先父模式“。
-
我翻遍了"The Java Language Specification"和"The Java Virtual Machine Specification"这两个规范文件,通篇没有找到"parent-first"的表述。这也就表明,我们奉为圭臬的"Parent Delegation Model"并非是Java语言和JVM的规范要求。实际上JVMS中只规定了类加载可以委派其他class loader来完成,但并没有要求两个class loader之间的关系。
When the Java Virtual Machine asks a class loader L to locate a binary representation for a class or interface called N, L loads the class or interface C denoted by N. L may load C directly, by locating a binary representation and asking the Java Virtual Machine to derive and create C from the binary representation. Alternatively, L may load C indirectly, by delegating to another class loader which loads C directly or indirectly.
所以理论上你可以委派给父亲,也可以委派给兄弟和儿子。当然现实也确实如此,譬如Apache Tomcat中的类加载模式就和"parent-fisrt"刚好相反。而我们面试中喜欢问的这种只是JDK的默认选择,它并非Java语言的严格规范。不同类加载模式有着不同的用途和优缺点,这里有一篇实践性的文章可作参考。所以当我们知道一个概念的时候,不仅要知道它的含义,更要知道它的适用范围。
说起类加载,大家脑中浮现的肯定是各种源码、各种流程,但这种描述方式容易让人陷入云里雾里的细节。对大多数人来说,宏观地理解一个概念远比了解概念的细节要重要。但宏观描述是一件很难的事,这让我想起过往的经历,小时候我的语文不好,每次写作文都憋不到要求的字数。唯独有一次,我写了好多字,写到手都酸了还是被老师批评,因为那次的要求是缩写。可见,想要理解精髓并宏观地概括出来并不容易。
当Android Studio将编写的Java代码编译成DEX文件时,类的信息便以如下方式组织起来。DEX文件在开发者和最终运行中间承担着信息传达的作用,就好比货物的运输环节。因此它的文件格式自然不是拍脑袋出来的结果,而是经过合理设计有着特定目标的产物。简单来说就是在不降低Java代码信息量的前提下尽量压缩文件大小,譬如其中大量采用的LEB128编码格式。
LEB128 ("Little-Endian Base 128") is a variable-length encoding for arbitrary signed or unsigned integer quantities.
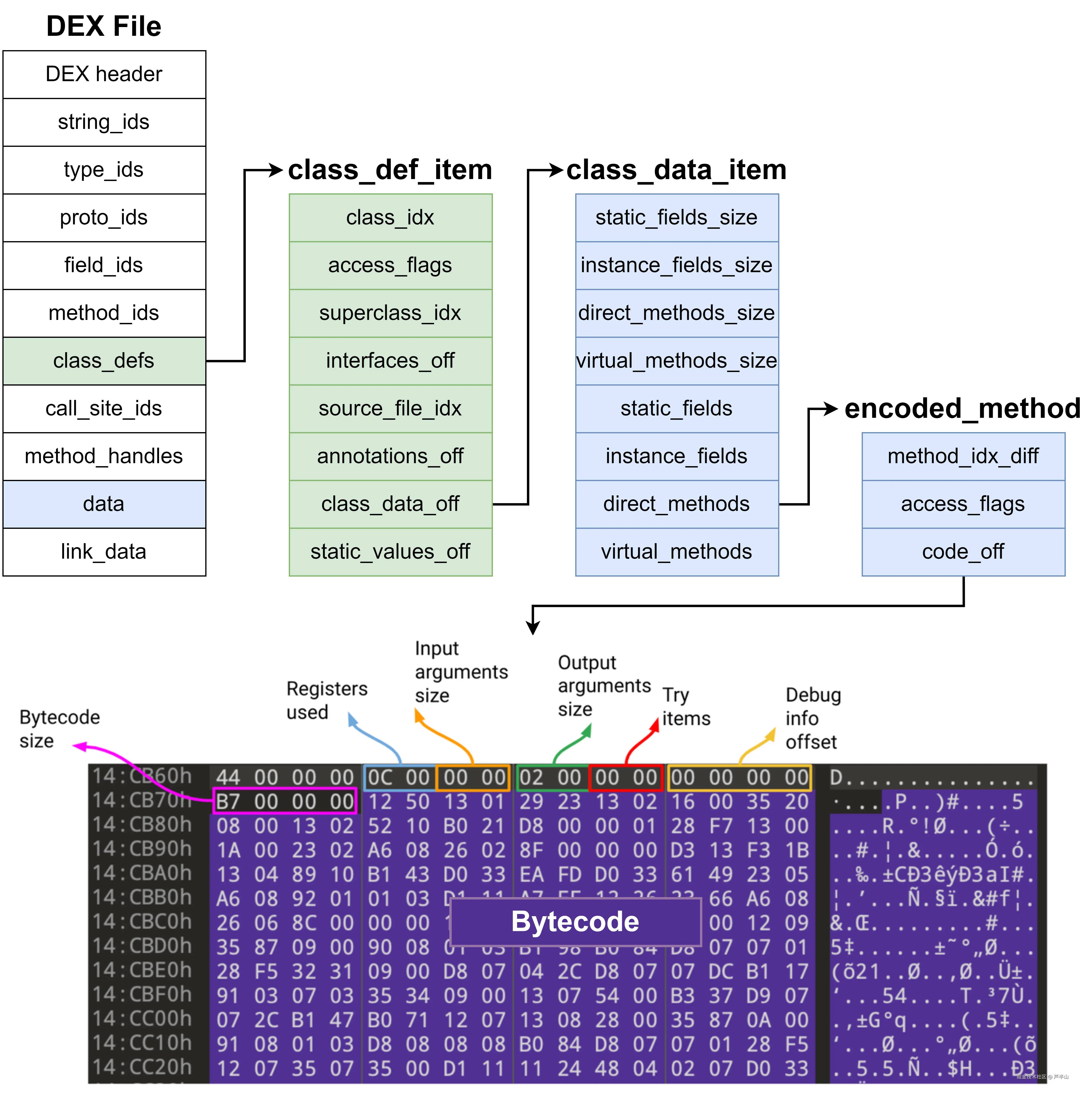
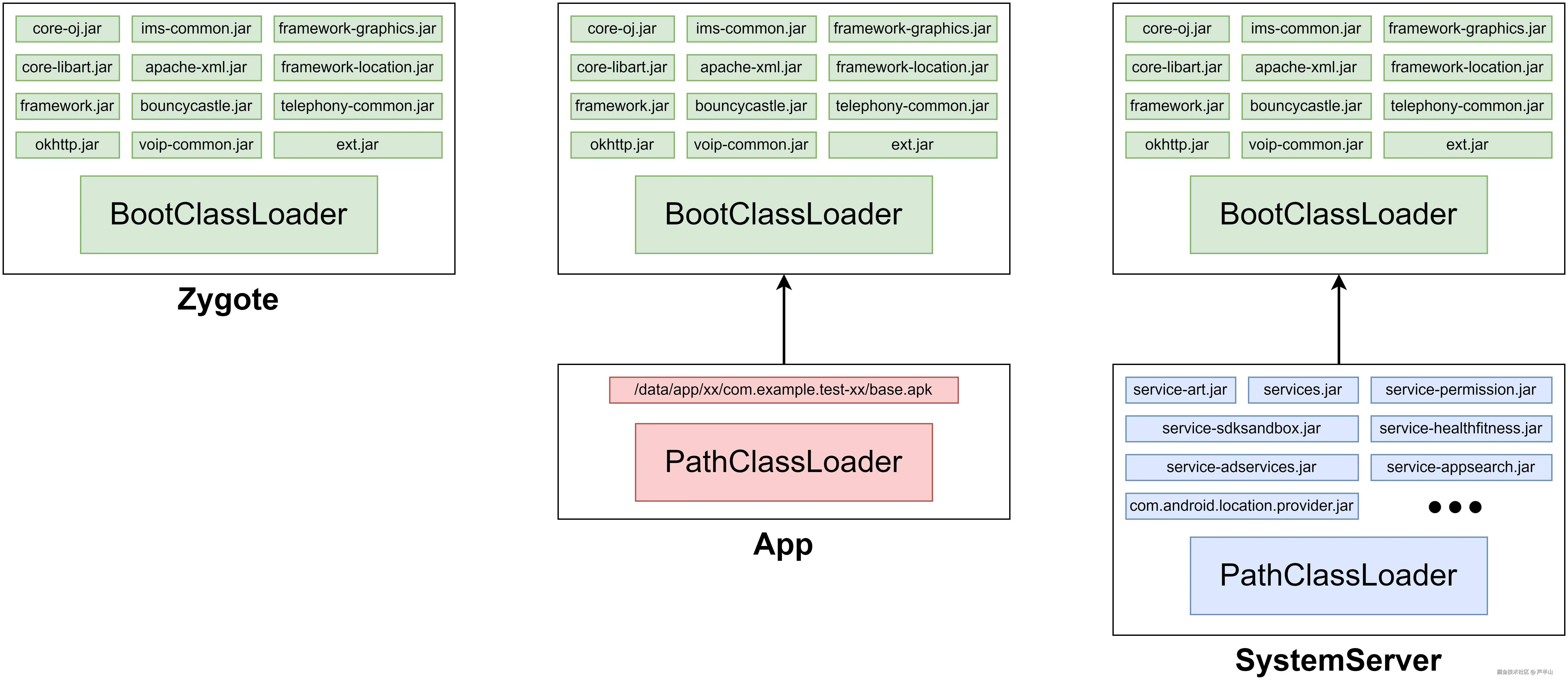
而所谓的“类加载”,其实就是将类在DEX中的信息转换成运行时的结构,一方面为了运行速度,另一方面是因为有些信息只存在于运行时,譬如引用字段的值,它必须等对象创建后才能给你相应的地址。而不同ClassLoader的主要区别,就在于绑定的DEX文件不同。以下是三个不同进程的ClassLoader。Zygote中只有BootClassLoader(它也有一个类型为PathClassLoader的sysem loader,但是默认条件下没绑定任何DEX文件,除非在虚拟机启动时通过-classpath或-cp来指定路径,因此还是BootClassLoader承担了所有),其绑定的DEX文件是系统最核心的库,譬如core-oj.jar,oj这里代表OpenJDK,它里面有java.lang.Object、java.lang.Class这种最基本的类。需要注意的是,不管是jar还是apk,它们都只是文件的打包方式,其背后仍是DEX文件。App中多了一个PathClassLoader,它绑定的是App自己的DEX文件。SystemServer中的PathClassLoader绑定的则是service相关的DEX文件,因为它最核心的作用就是管理系统服务。
目前为止我们仍然徘徊在类加载的门外,其内部错综复杂的景观尚未出现。下面我们就开始阐述这个过程,但相比于LoadClass、DefineClass、FindClass、ResolveClass、LinkClass、InitializeClass这些名词,我更愿意揭示名词背后的故事。名词可以变来变去,但背后做的事情说到底就是那些。
第一步 按图索骥
当我们想要加载一个类时,第一步先去查看它是否已经存在。既然涉及到查找,那么就有两个问题:1.用什么查?2.在哪里查?对于类而言,它的全名是独一无二的(在同一个ClassLoader中),因此可以用于查找。另外在虚拟机内部,每个ClassLoader都会关联一个ClassTable,顾名思义,它就是用来存放已加载类的。其内部采用HashSet的数据结构,元素是uint32_t的值,也即art::mirror::Class的指针。由于Java堆中的数据需要按8字节对齐,因此类指针的低3位一定是0,这3位拿来存储hash值的低3位可以加速HashSet的查找速度,尤其在HashSet中碰撞几率较高的时候。
尽管类加载采用先父的模式,但查找类是否已经加载却是相反的顺序,即先找子ClassLoader中是否有已加载的类,再找父ClassLoader中是否有已加载的类。这样安排是因为已加载的类并不影响类加载的层级关系,同时在递归写法上更为简便。
第二步 开疆拓土
当系统中找不到这个类时,我们就需要自己加载。而加载的第一步,就是根据运行时类的结构来开辟空间,这样后续的加载过程才能有地方来填入数据。
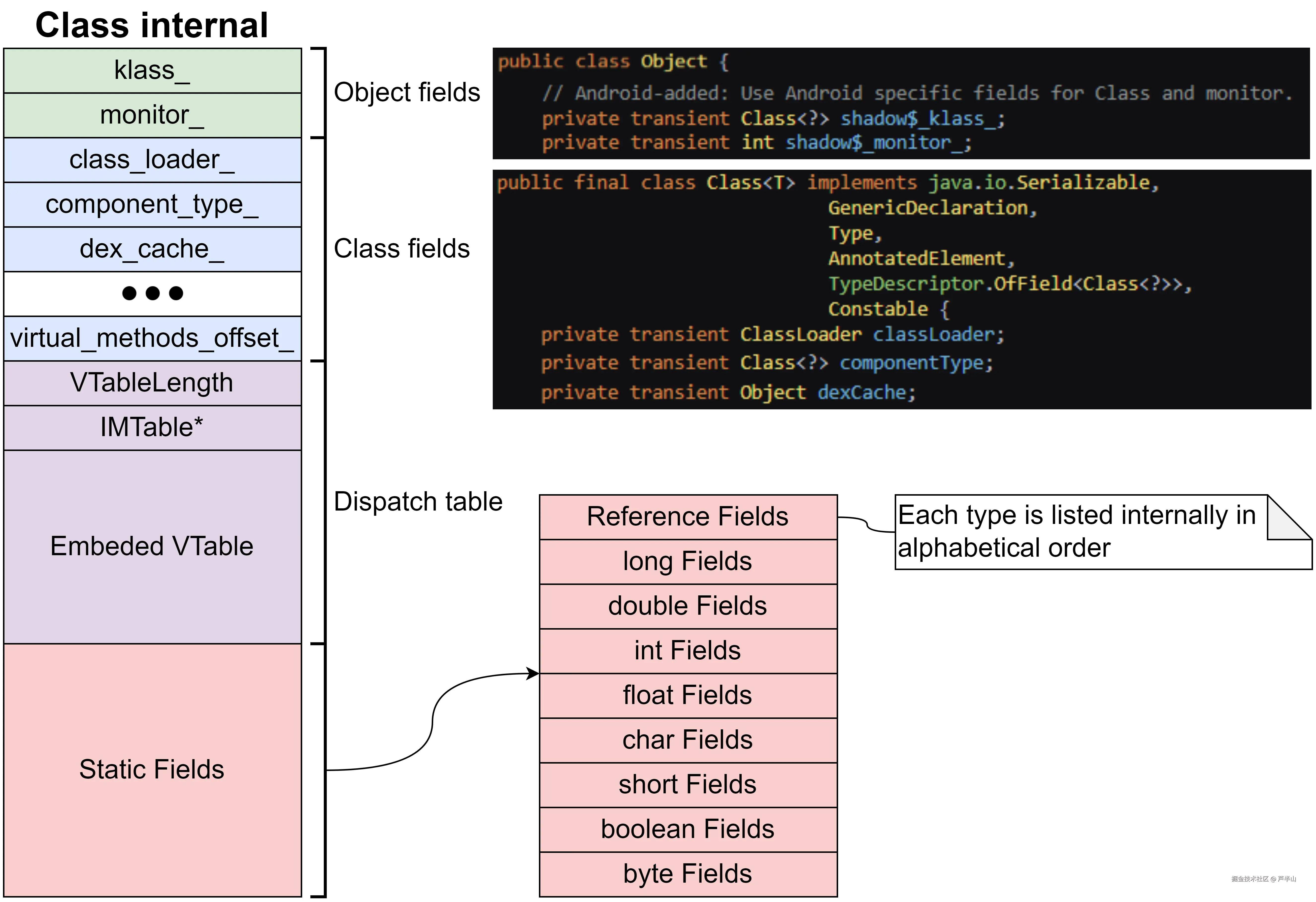
从上图可以看出,一个类的数据分为了四个部分。最头部是Object的字段,因为Class继承于Object。其后跟的是Class的字段,它里面包含类的基本数据,譬如classLoader和dexCache。这两部分的数据是所有类都具备的。第三部分包含IMTable(Interface Method Table)和VTable(Virtual Table),它们在调用接口方法和虚方法时能够保证多态的正确执行。第四部分则是每个具体类的静态字段,静态字段序并没有按照定义的先后来排序,而是先分类,再按照字段名称的字母顺序来排列。
在类加载的初期阶段,第三部分(Dispatch Table)的大小还无法确定,因为它需要解析类的层级,了解这个类有什么父类、实现了哪些接口;另外还需要对方法进行链接,让系统在多态环境中知道哪些方法用子类的,哪些方法用父类的,以及分别到哪里去寻找最终实现。因此,此时开辟的类空间并不包含"Dispatch Table"的大小。等到后续加载过程确定了"Dispatch Table"的大小后,再将原来类中的数据拷贝到新创建的类(包含"Dispatch Table"大小)。这也就意味着类加载过程中会对同一个类创建两次,且第一次创建的类会在加载结束后成为垃圾。
第三步 攘外必先安内
空间开辟出来以后,就需要往里面填充数据了。这个过程可以分为两个阶段,先是安内,再是攘外。怎么理解这句话呢?让我们回到Java语言的基本特性上来。作为面向对象的语言,多态是它最重要的特性。所谓安内,指的是不考虑多态,不考虑类的层级关系,单就眼前的这个类去填充数据;而所谓攘外,便是结合了父类、接口、多态的语言特性所做的数据填充。
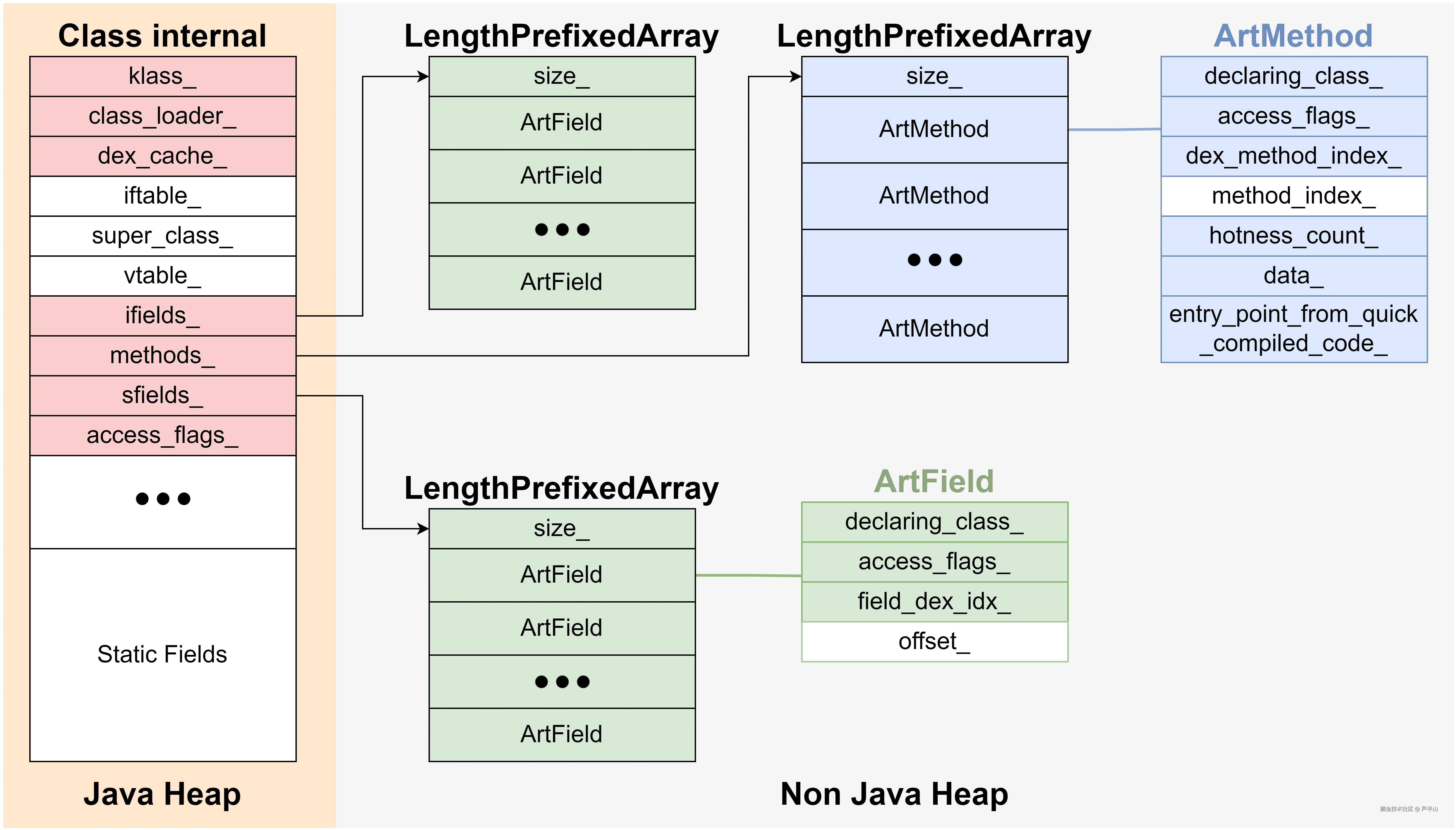
上图标注颜色的部分是不考虑多态时填充的数据,其中最为核心的是字段和方法的填充。ifields_表示instance fields,sfields_表示static fields。它们是一个64bit的指针值,各自指向一个元素为ArtField的数组。同理,methods_指向一个元素为ArtMethod的数组。此时的类仿佛一个孤岛,这些数据全部来自于自己,与父类无关,与接口也无关。用ArtMethod这样的数据结构来描述一个方法尚且可以理解,可是为什么字段也需要ArtField这样的结构呢?难道它不是直接存在类(静态字段)和对象(实例字段)中的么?这是因为类和对象中存的只是字段的值,而字段的属性依然需要额外的结构,譬如access_flags_和field_dex_idx_(通过它可以去DexFile中找到字段的名称)。
存储ArtField和ArtMethod的数组是在这个阶段根据DEX里的信息动态创建的,其创建的位置位于Linear Alloc区域,并不属于Java Heap,因此这块空间并不计入Heap的内存统计。关于哪些内存计入Heap统计,其实有个简单的判别方式:只有通过Java可以访问到的内存才会分配在Heap中(VTable是一种特殊情况),像ArtField和ArtMethod这种无法在Java层访问的数据,自然不应该放在Heap中。
上图留白的部分指的是之后阶段才会填充的数据。iftable_(interface table)和super_class_需要父类和接口的信息,vtable_不仅需要父类和接口的信息,还需要方法链接来确定具体实现的位置,而static fields则属于运行时的数据,其初始化的值将留到加载的最后阶段才填入。ArtField的offset_字段表示该字段在类中的偏移,它需要在字段链接后才能确定。而ArtMethod的method_index_字段则是用于运行时寻找具体实现的索引,它需要在方法链接后才能确定。这里提了几次“链接”,那么它到底是什么含义呢?简言之,链接就是将孤立的各个部分串接起来,并固定最终的位置的过程(可以类比到动态库的链接)。这一块具体的阐述将放在第五步。
第四步 认祖归宗
当属于自己的数据加载完毕后,接下来便要寻找父类和接口了。根据DEX里的信息,类可以顺利找到自己的父类和接口,但在设置super_class_这样的字段之前,会有递归的加载逻辑来保证父类已被解析(解析指的是完成了大部分的加载,但未初始化)。同理对接口们也有一样的解析过程。因此这个阶段结束后,该类层级关系树状结构上所有的父类和关联的接口都将被解析。
第五步 穿针引线
接下来我们将来到整个加载过程中最为复杂的一步,它可以分为“方法链接”和“字段链接”两个部分。之所以复杂,是因为要考虑的情况众多,譬如不仅要考虑普通类,还要考虑抽象类和接口;不仅要考虑虚方法,还要考虑default方法和miranda方法;不仅要考虑自身的接口,还要考虑父类的接口(interfaces of super class)和接口的父接口(super interfaces)。总是,迷雾缭绕。
首先来介绍虚拟机视角下方法的分类,大体上可以分为三个类别:
-
Direct Methods:private、static以及constructor的方法属于Direct Methods,之所以称为"Direct",是因为调用它们时不用经历多态的派发。譬如我们调用一个private方法肯定不会找到它的父类里去。这里对final的方法多提一句,虽然它也不可覆写(Override),但DEX文件生成时依然会将它当作Virtual Method来对待,原因是final只禁止了子类覆写它,但并没有限制它不能覆写父类,因此它仍然可能成为多态派发寻找的对象。
-
Copied Methods:default和miranda方法属于Copied Methods。Default方法是Java 8引入的新特性,在此之前接口中只能有abstract方法,default方法可以允许接口提供一个默认的实现。Miranda这个名称来自美国宪法中的Miranda Rule,它要求执法人员在对被拘留者进行拘留和审讯时必须给予Miranda Warning。Miranda Warning包含多个内容,譬如人们常说的”你有权保持沉默“,”如果你无力聘请律师,我们将为你指定一名律师“等。在Java语言中,abstract类在implement接口时可以只实现部分方法,而那些未实现的方法将会由虚拟机动态生成,并命名为miranda method。这两类方法之所以被称为"Copied",是因为它们都是从接口中拷贝而来(拷贝接口方法到类中)。不过程序员碰到他们的几率很小,但因为它们而给虚拟机增加的复杂度却成倍上升,因此下面的讨论不会带入它们。
-
Virtual Methods:剩下的方法都可以被归入Virtual Methods,之所以称为"Virtual",是因为它们并非运行时调用的真实方法,运行时调用需要经历多态的派发方能找到最终的方法。
下面来介绍“方法链接”。在多态的派发中,对父类方法的覆写和对接口方法的覆写处理并不相同,原因是一个类只能继承一个父类,但却可以实现多个接口。这种语义的差别决定了派发方式的不同。因此”方法链接“的主要工作也分为两块,分别是建立接口方法的派发机制和普通虚方法的派发机制。
接口方法的派发机制依赖IfTable(Interface Table)和IMT(Interface Method Table),关于它们的介绍可以参考我之前的一篇文章。因此这里要去创建IfTable和IMT。
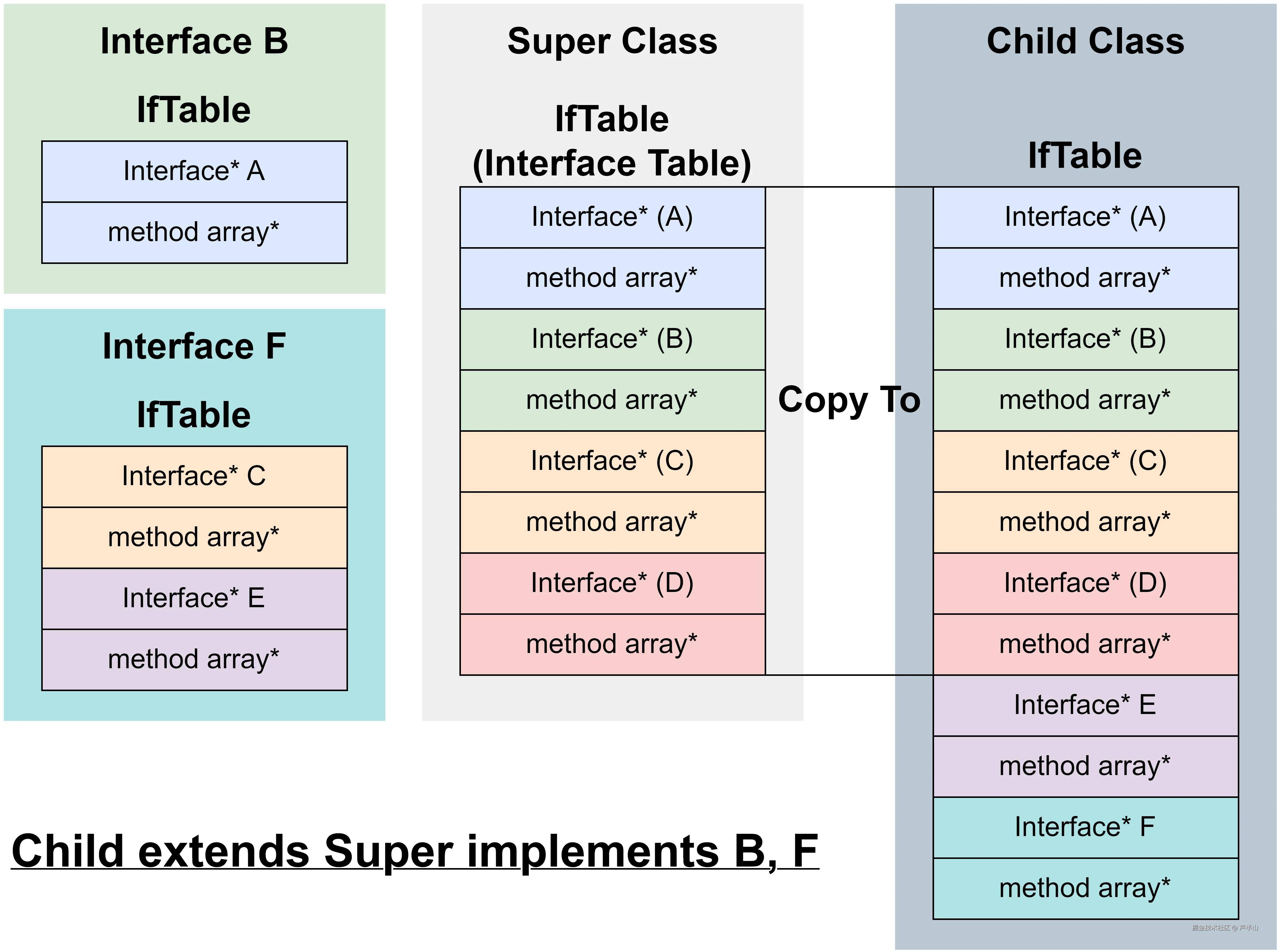
对于一个新加载的类来说,父类的IfTable可以作为它的母版。相较于父类,它会引入一些新的接口:实现的接口以及接口的父接口。我们以上图来做个例子,Parent类的IfTable有A、B、C、D四个接口,Child implement了B和F。由于B在Parent中已经存在,因此不必再加入IfTable;F的父接口为C和E,C在Parent中也存在,因此最终Child中新增的接口为E和F。
此时创建的IfTable中,method array并没有更新,因为它里面要存放接口方法的最终实现,所以需要等到vtable建立(会确定所有虚方法的最终实现)完成后才能更新。同理IMT也要等待VTable创建完成。
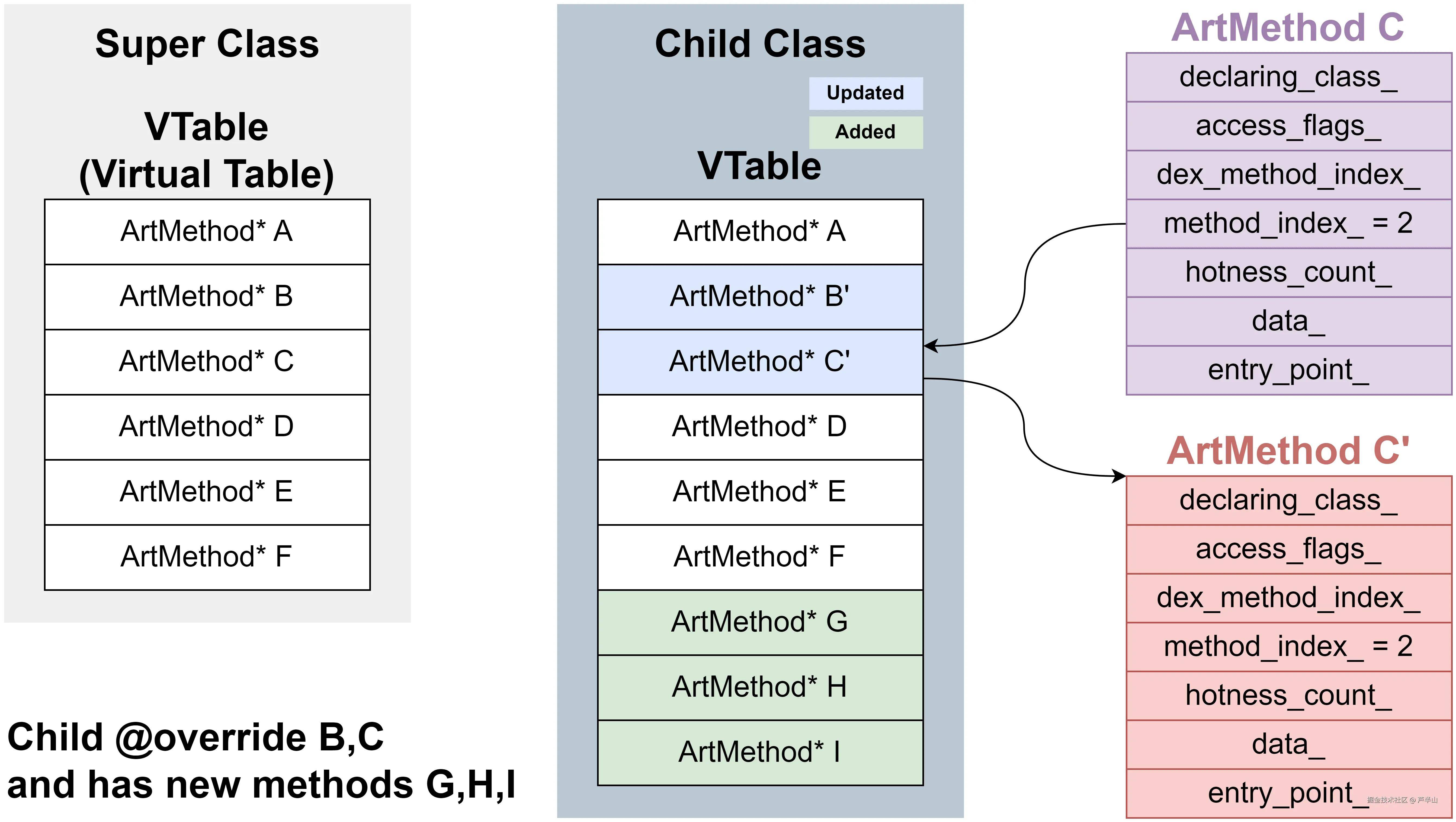
VTable创建时依然选择父类的VTable作为母版,它会遍历自己的所有虚方法,如果能在父类的VTable找到同签名的方法,那么就会更新相应的slot;否则将它添加到VTable的尾端。以上图为例,Child类覆写了B和C两个方法,因此会将B和C的slot更新为B'和C',新增的方法G、H、I添加到尾部。当我们以object.C()的方式调用Parent类的C方法时,虚拟机会根据C方法的method_index_去object所属的类中寻找最终实现。如果object属于Child Class,那么找到的最终实现将会是C',因此最终调用的方法也是C',而非C。
等VTable创建完成后,便会根据VTable里的信息来更新IfTable的method array,同时创建IMT。IMT是一个长度为43的数组,其中的元素为ArtMethod*,看起来和VTable的结构一样。不过VTable最后会被内嵌到Class中成为Embedded VTable,而IMT只会将数组的指针保存在Class中。为什么两种结构一样、用途也类似的数组会采取不同的形式呢?
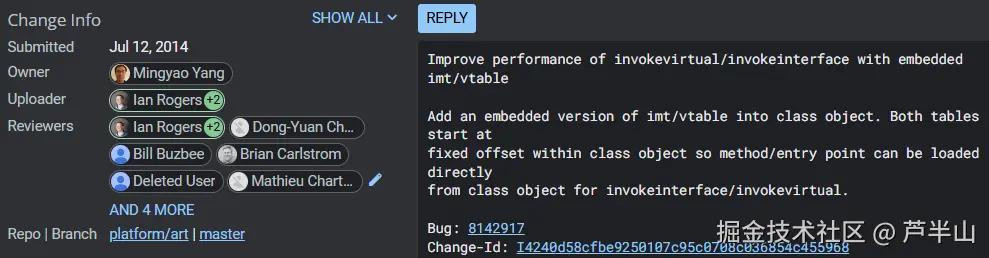
其实在早期的ART版本(2014-2016)中,VTable和IMT都设计成embedded的形式,引入的改动如上。原因也很简单,embeded的方式可以减少一次指针load的操作,对性能有好处。
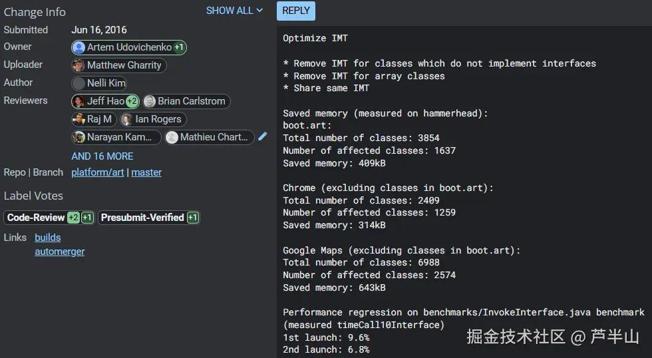
但后来三星的一个工程师发现IMT有挺大的概率可以被复用(子类复用父类的IMT),并提交了上面的改动。在复用的情况里,子类不用创建新的IMT,而只用将父类IMT的指针存入自己的Class中。这样一来对内存会有较大的好处,但同时性能相比embedded方式也会有些牺牲(6~9%)。
介绍完“方法链接”后,再来介绍“字段链接”。
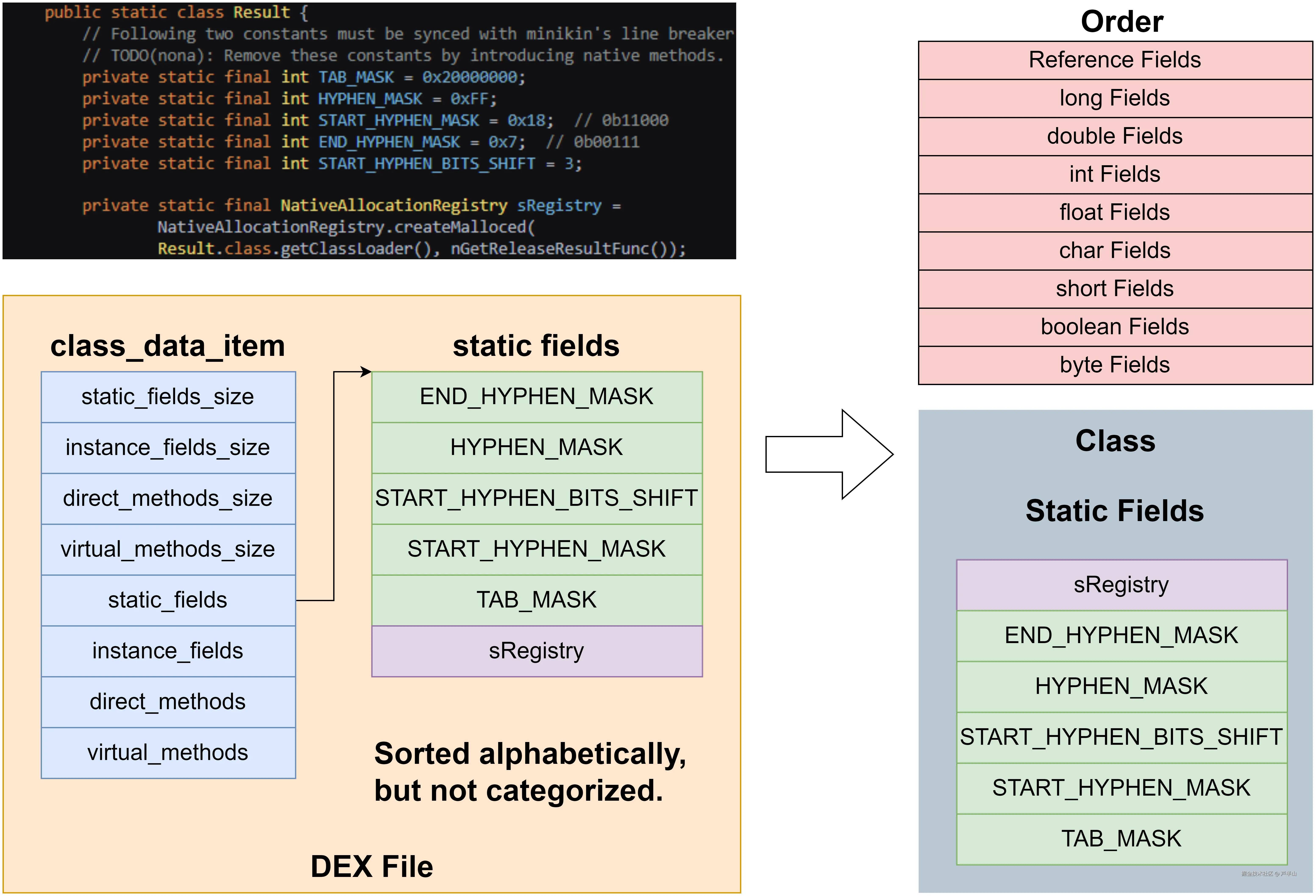
这个过程会对静态字段进行重新排序。原始的Java文件中,字段按照先后顺序排序;当它编译成DEX文件后,字段便按照字母顺序排序;当类加载起来后,字段便先按照类型进行分类,再在每个类别中按照字母顺序排列。我们以上图为例,sRegistry按照字母顺序在DEX文件中本来排在最后面,但加载进来后由于是引用类型便排在最前面。将引用字段放在最前面,会方便GC的遍历。等到排序完成后,便会将每个字段的位置写入ArtField的offset_字段。
另外还记得第二步我们提到的这句话么?当上述所有过程都结束后,便会创建一个新类,它的大小包含VTable和IMT指针。之后对原有类进行拷贝,同时将VTable存成embedded格式。
等到后续加载过程确定了"Dispatch Table"的大小后,再将原来类中的数据拷贝到新创建的类(包含"Dispatch Table"大小)。
第六步 蓄势待发
万里长征来到最后一步,此时类的状态叫作“已解析,但未初始化”,类的静态字段尚未填入,同时静态代码块也没有运行。因此,这最后一步就是给子弹上膛。在填入静态字段之前,虚拟机会对类进行验证,这个Verify的过程很多书籍都会将它归到LinkClass阶段,但ART把它放到了InitializeClass阶段。所以还是那句话,要跳过名词的表象,看到事物的本质。验证,顾名思义就是看加载的类是否合法,只有合法的类才能按照Java的语义正确执行。此外,验证完之后会递归地对父类及接口进行初始化。
静态字段的填入需要从DEX文件中读取初始值,但这里只针对基本类型。至于引用类型的初始值,则要放到
至此,一个类就被加载完毕了。
谈谈PreloadClasses
众所周知,Zygote里有个PreloadClasses的环节用于加载系统中重要的类。但其实这个环节的作用如今已经大大衰减,或者说被Boot Images给大部分取代了。
系统在编译时会根据BOOTCLASSPATH(也即BootClassLoader绑定的那些DEX文件)生成所谓的Boot Images。
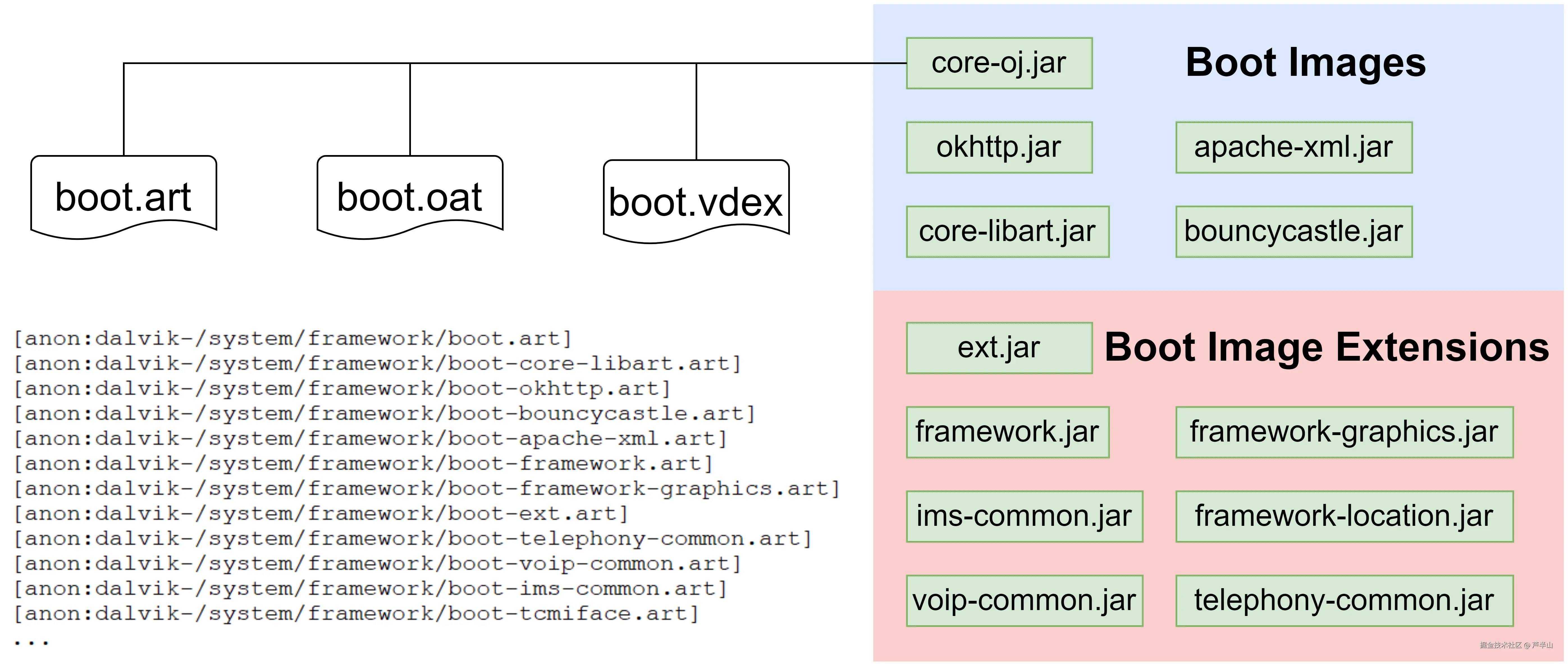
逻辑上Boot Image可以分为两块,一块是最核心的DEX文件编译出来的东西,跟随com.android.artAPEX模块发布;一块是手机厂家改动比较多的地方(我们常说的framework),通常随系统更新而更新。不过大多数的讨论中我们不用分的这么细,统称为"Boot Images"就好。
现如今Boot Images的生成也采用PGO(Profile-Guided-Optimization)的方式,而默认情况下它采用的profile文件则位于frameworks/base/config/boot-image-profile.txt。这里面包含两块内容,一块是值得被AOT优化的方法名,一块是值得固化在Image里从而减少启动时类加载的类名。大多数人在讨论PGO(譬如Baseline Profile)时经常关注了前者,而忽略了后者。细看boot-image-profile.txt这个文件里的内容,我们会发现其中的类名和frameworks/base/config/preloaded-classes(标注哪些类会被Zygote preload,它由art/build/boot/preloaded-classes和frameworks/base/boot/preloaded-classes两个文件合并而来)中的类名基本重合,这也就意味着Boot Images会提前加载本该在Zygote中加载的类,并将它们固化在image文件(.art文件)中。这样一来,Zygote启动时只需要加载image文件,就可以省掉绝大多数的类加载工作,从而减少手机的启动时间。
我原本以为Boot Images只会解析这些类,而把类的初始化留给Zygote,但细看源码后发现Boot Images也会干初始化的活,除了一种情况:当类名尾部有$NoPreloadHolder字符时,表明该类不希望被提前初始化。这么看来,Zygote的PreloadClasses环节重要性就下降了很多。
(本文分析基于Android 15)
评论记录:
回复评论: