
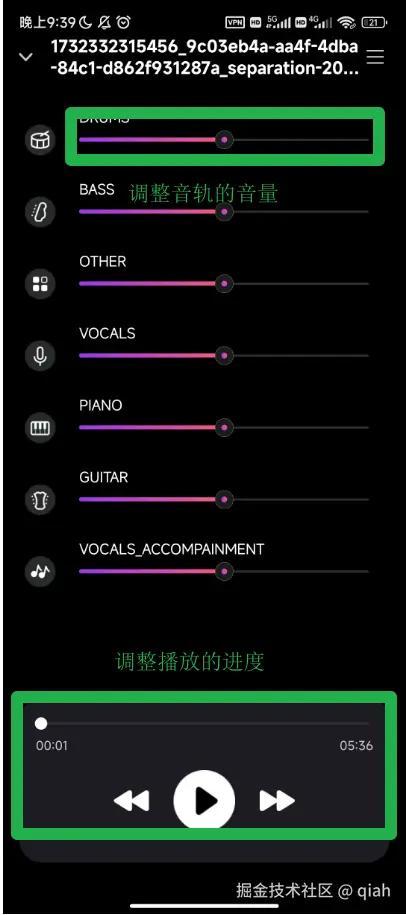
应用场景
在公司项目中,有一个功能是音轨分离。用户可以上传一首歌曲到后端服务器,系统会将这首歌曲拆分成多个音轨,例如人声、钢琴、吉他、贝斯等,最多可以拆分成8个音轨。这些音轨会被保存为独立的音频文件,以便用户在前端进行进一步的操作和编辑。
问题:
最初,我们尝试使用 MediaPlayer 来实现多音轨播放。每个音轨对应一个 MediaPlayer 实例,通过调用 start 方法来播放音频。然而,这种方法存在明显的同步问题:
同步问题:尽管我们在代码中尽量保证每个 MediaPlayer 的 start 方法在同一时间被调用,但由于系统调度和内部实现的差异,实际播放时间并不完全一致。这种不同步现象在七八个音轨播放时尤为明显,严重影响了用户体验。
尝试硬解码音频后播放
为了解决上述问题,决定参试开发一个音频播放器,利用 MediaCodec 进行硬件解码,获取原始的 PCM 数据,然后将不同音轨的 PCM 数据混合在一起,最后通过 AudioTrack 进行播放。这种方法不仅能够保证音轨之间的同步性。
关键技术点
-
MediaCodec 解码:使用
MediaCodec进行硬件加速解码,获取原始的 PCM 数据。 -
音频混音:将多个音轨的 PCM 数据混合在一起,支持独立调整每个音轨的音量。
此处需要格外注意,不同采样率与声道数的不可以直接相加,需要做转换
-
AudioTrack 播放:通过
AudioTrack将混合后的 PCM 数据实时播放。
关键代码实现
在播放音乐时,多线程是必要的,以确保各个任务能够并行处理,避免阻塞主线程。为了更好地管理和协调这些线程,我们采用了Kotlin协程
队列: BlockQueue
为了在不同的协程之间进行通信,我们使用了一个阻塞队列 BlockQueue。
kotlin 代码解读复制代码class BlockQueue<T>(val capacity: Int = 4) {
private var channel = Channel(capacity)
suspend fun produce(item: T) {
channel.send(item)
}
suspend fun consume(): T {
return channel.receive()
}
fun init() {
channel.close()
channel = Channel(capacity)
}
}
解码音频 : Decoder
初始化: 配置解码器配置,配置音频提取器
audioInfo 用于存储音频文件的元信息,如采样率和声道数。
scala 代码解读复制代码init {
extractor.setDataSource(filePath)
var type = ""
// 选择找到的第一条音频轨道
for (i in 0 until extractor.trackCount) {
val format = extractor.getTrackFormat(i)
val mime = format.getString(MediaFormat.KEY_MIME)
if (mime != null && mime.startsWith("audio/")) {
trackIndex = i
type = mime
extractor.selectTrack(trackIndex)
break
}
}
if (trackIndex < 0) {
throw IllegalStateException("extractor not found audio track")
}
val format = extractor.getTrackFormat(trackIndex)
// audioInfo 会把一些采样率,声道数之类的存放
audioInfo = AudioInfo.createInfo(filePath, format)
// 小心别写错成endcoer
decoder = MediaCodec.createDecoderByType(type)
decoder.configure(format, null, null, 0)
}
strart() :启动解码器
需要注意的点有
- 解码的流程是使用常规的同步流程,
MediaCodec提供了异步回调机制,这些回调默认在主线程上执行,但如果在主线程上处理可能会导致应用程序卡顿,如果在主线程用会堵塞的队列,会直接把APP卡死 - 而如果在回调中手动切换到IO线程以避免阻塞,这虽然可以防止主线程被占用,但由于线程切换带来的开销,可能会导致数据不是按照其到达的顺序被处理和存储到队列中,从而破坏了数据的顺序性和完整性
- 解码后得到的数据保存到一个ByteBuffer中,而我们播放的pcm是16位的pcm,这意味着每个采样点由两个字节表示。然而,当我们将多个音频流混合(即同时播放)时,直接将这些byte相加会引入不必要的噪音。
kotlin 代码解读复制代码// 启动解码器,并调用 startInner 方法开始解码和播放流程
fun start() {
decoder.start()
startInner()
}
// startInner 方法启动两个协程:
// 一个用于从音频文件中读取数据并将其送入解码器
// 另一个用于从解码器中获取解码后的数据并将其放入队列中
private fun startInner() {
runExtractor()
runDecoder()
}
private fun runExtractor() =
scope.launchIO {
while (isActive) {
val index = decoder.dequeueInputBuffer(0)
if (index > 0) {
val inputBuffer = decoder.getInputBuffer(index) ?: ByteBuffer.allocate(0)
val sampleSize = extractor.readSampleData(inputBuffer, 0)
if (sampleSize < 0) {
decoder.queueInputBuffer(index, 0, 0, 0, MediaCodec.BUFFER_FLAG_END_OF_STREAM)
} else {
decoder.queueInputBuffer(index, 0, sampleSize, extractor.sampleTime, 0)
extractor.advance()
}
}
}
}
private fun runDecoder() =
scope.launchIO {
val info = BufferInfo()
while (isActive) {
val index = decoder.dequeueOutputBuffer(info, 0)
if (index > 0) {
val byteBuffer = decoder.getOutputBuffer(index) ?: ByteBuffer.allocate(0)
// ShortsInfo.createShortsInfo(byteBuffer, info)
// 会把一个betyBuffer转换成一个ShortArray
// 因为播放的音频是16位pcm,不转换成short直接相加就不对了
queue.produce(ShortsInfo.createShortsInfo(byteBuffer, info))
decoder.releaseOutputBuffer(index, false)
}
}
}
从解码器中提取数据:consume()
kotlin 代码解读复制代码suspend fun consume(): ShortsInfo = queue.consume()
调整播放进度:seekTo
kotlin 代码解读复制代码suspend fun seekTo(timeUs: Long) {
extractorJob?.cancelAndJoin()
decodeJob?.cancelAndJoin()
queue.init()
decoder.flush()
extractor.seekTo(timeUs, MediaExtractor.SEEK_TO_CLOSEST_SYNC)
startInner()
}
-
定位到目标时间点: 如果只有一个音频轨道,可以通过调用
extractor.seekTo(timeUs, MediaExtractor.SEEK_TO_CLOSEST_SYNC)方法,将MediaExtractor的读取位置移动到目标时间最近的一个同步帧。这样可以确保下一次从音频文件中读取的数据是从目标时间点开始的。 -
读取并解码数据: 当
MediaExtractor的位置调整到目标时间点后,从音频文件中读取的数据送入解码器的协程会在下一次运行时获取到目标时间点之后的数据,并将其送入解码器进行解码。 -
提取解码后的数据: 从解码器中取出数据的协程, 稍后从解码器中获取到的数据也都是目标时间点之后的数据。这样可以确保所有输出的数据都是从目标时间点的。
-
播放音频: 最后,将解码后的音频数据通过
AudioTrack播放,即可实现从目标进度开始播放音频。
如下所示
现在extractor的位置指向03数据快,已经把01,02送到mediaCodec中的输入缓冲区。
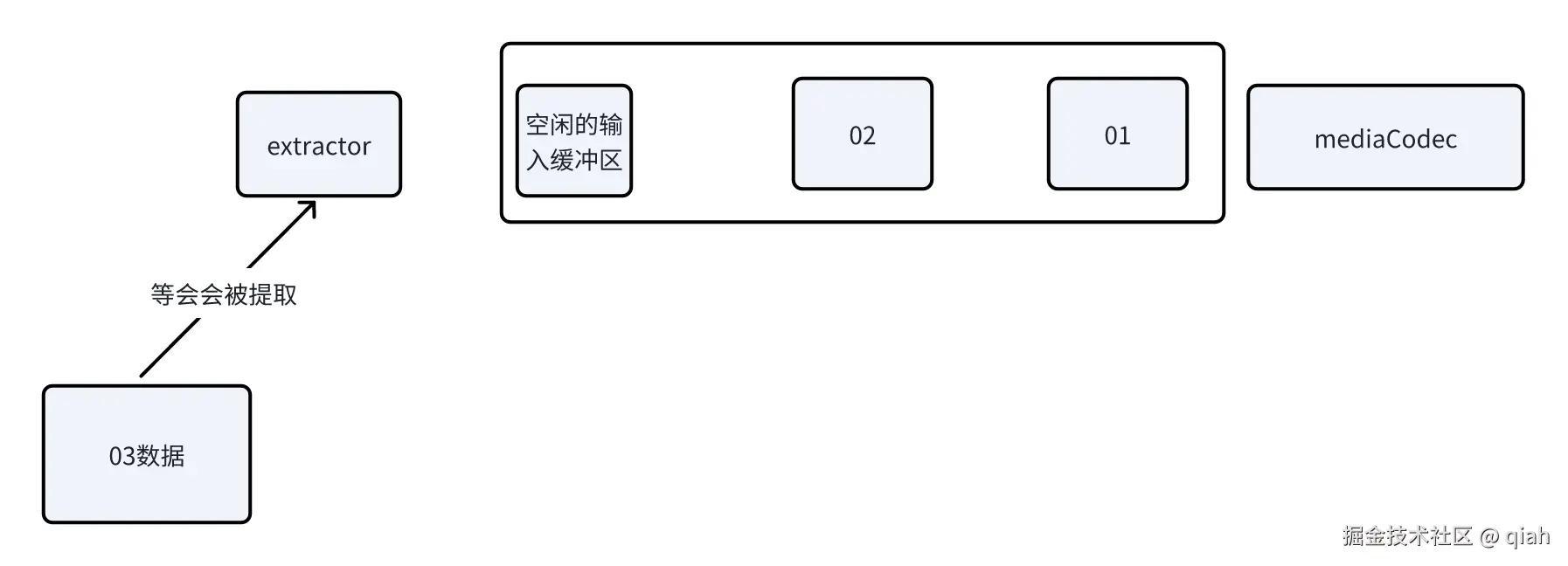
按照原本的流程,mediaCodec将会吧01,02,与即将入队的03缓冲区按顺序解码,送入到输出缓冲区,假设一个输入缓冲区的数据用一个输出缓冲区可以存放
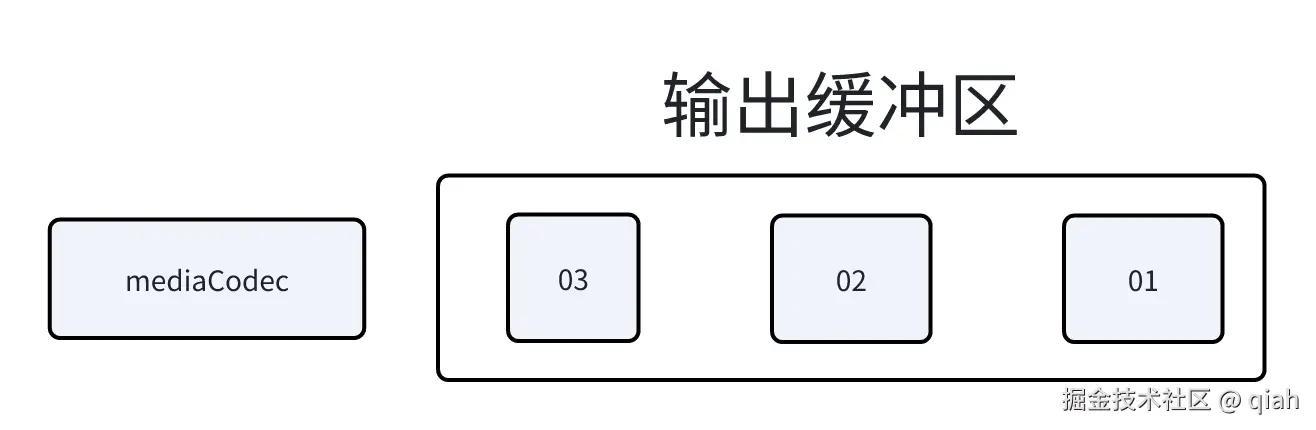
这些缓冲区会被取出转换成16位后存到另一个队列,然后被播放
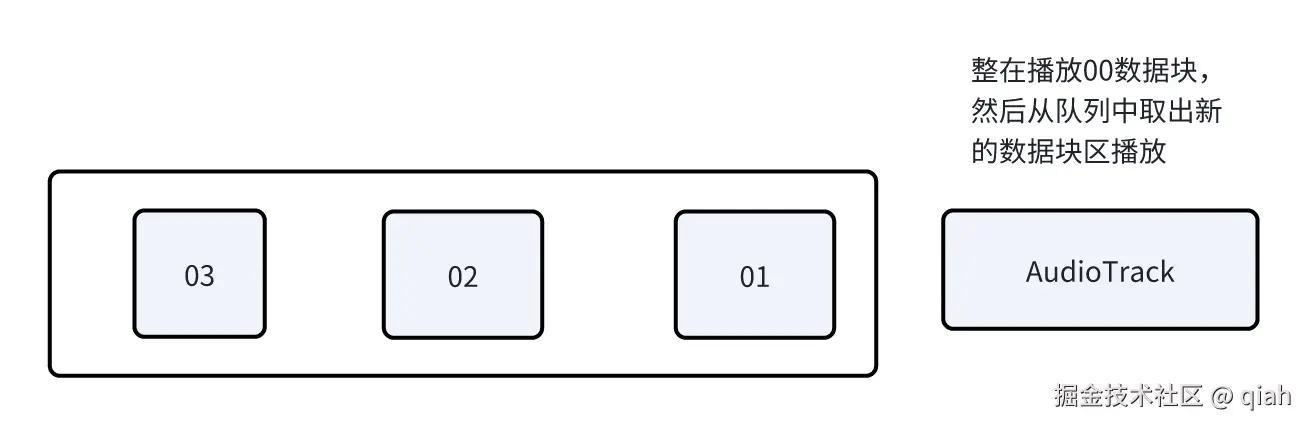
如果说只有一个音轨这么播放是可以的,按照我们的分析,如果原本是要按照00,01,02,03的顺序播放
在从03中读取数据的时候我们让mediaExtractor下次不要读03数据块了。下次从100开始读
那么就会按照00,01,02, 100,101...的顺序开始播放
但是在多轨道一起播放的情况下,因为不同的线程运行的进度不一定完全一样,目前的extractor指向的数据块其实是不一样的,可能会有先后的差距,快的马上要去拿03数据块,慢的要去拿02数据块
其次medieCodec的输入与输出缓存区队列也不一致, 有的将会按照,
00,01,02,100,101...播放
有的是按照
00,01,100,101...播放
出现了播放的进度不同步的问题。
所以要把mediaCodec的输入输出缓冲区清空
这些数据都不要了
lua 代码解读复制代码 decoder.flush()
但在这个之前,我们首先要先把 往mediaCodec送数据的协程 关了。
kotlin 代码解读复制代码 extractorJob?.cancelAndJoin()
private fun runExtractor() =
scope.launchIO {
// 为什么会被取消就是因为,死循环是根据isActive来判断是否执行的
while (isActive) {
val index = decoder.dequeueInputBuffer(0)
if (index > 0) {
val inputBuffer = decoder.getInputBuffer(index) ?: ByteBuffer.allocate(0)
val sampleSize = extractor.readSampleData(inputBuffer, 0)
if (sampleSize < 0) {
decoder.queueInputBuffer(index, 0, 0, 0, MediaCodec.BUFFER_FLAG_END_OF_STREAM)
} else {
decoder.queueInputBuffer(index, 0, sampleSize, extractor.sampleTime, 0)
extractor.advance()
}
}
}
}
好了mediaCodec的缓冲区不会影响我们播放同步了
要注意decoder有一个输出缓冲区,里面的数据是解码后等待被拿去播放的数据
他们也同样数量不一样,会影响播放的同步。
同样在清空之前要关闭从mediaCodec中拿出解码后的数据送入输出队列的协程
markdown 代码解读复制代码 decodeJob?.cancelAndJoin()
然后清空队列
arduino 代码解读复制代码 queue.clear()
kotlin 代码解读复制代码fun clear() {
while (channel.tryReceive().getOrNull() != null) {}
}
由于为了避免多个线程同时操控输出队列导致顺序不对破坏同步。
从解码器 输出队列取出后混音播放的线程在混音和调整进度的位置加了互斥锁
kotlin 代码解读复制代码suspend fun seekTo(timeUs: Long) {
mutex.lock()
// 调用diecoder门的seekTo
mutex.unlock()
}
private suspend fun startInner() {
map.values.forEach { it.decoder.start() }
while (true) {
mutex.lock()
// 从解码器中取出数据后混音
mutex.unlock()
}
}
通过上述步骤,可以确保在调整播放进度时,所有轨道的数据都能从目标时间点开始同步播放,避免因数据不一致导致的播放不同步问题。
处理原始PCM: AudioCovert
先讲一下为什么有这个类
这个类是负责混音的AudioMix与负责解码的Decoder对接的桥梁
面临问题有两个
-
缓冲区大小不一致:
- 不同的解码器输出的缓冲区大小可能不同,例如有的缓冲区大小为 256 字节,有的为 1024 字节。直接将这些缓冲区的数据相加会导致数据对齐问题,进而影响同步。
-
PCM 格式不一致:
- 不同的音频轨道可能具有不同的采样率(如 44100 Hz 和 48000 Hz)和不同的声道数(如单声道和立体声)。直接将这些不同格式的 PCM 数据相加会导致播放进度不统一,甚至产生严重的音频质量问题。
AudioConvert 类的主要职责是将不同格式的 PCM 数据转换为统一的大小与格式的pom数据,
具体的说期望的·AudioCovertt·实现
-
缓冲区对齐:
- 将不同大小的缓冲区数据,填充到一个统一大小的缓冲区。例如,将 4个256 字节的缓冲区的数据添加在一起变成 1024 字节,或者将 1024 字节的缓冲区的数据切分到到 256 字节。这样可以确保所有数据在混音前具有相同的长度。
-
采样率转换(未实现):
- 使用重采样技术将不同采样率的 PCM 数据转换为统一的采样率。例如,将 44100 Hz 的数据转换为 48000 Hz,或者反之。这一步骤确保了所有音频数据在时间轴上的对齐。
-
声道数匹配(未实现):
- 将不同声道数的 PCM 数据转换为统一的声道数。例如,将单声道数据转换为立体声,或者将立体声数据转换为单声道。这一步骤确保了所有音频数据在声道上的对齐。
但是因为我需要的场景并不需要对采样率和声道数的转换,都是播放 44.1khz 2声道的音频,故2,3为未实现
kotlin 代码解读复制代码class AudioCovert(
val decoder: Decoder,
val bufferSize: Int,
) {
private var cache: ShortsInfo? = null
private val shortsInfo = ShortsInfo(ShortArray(0))
fun clearCache() {
cache = null
}
suspend fun getBuffer(): ShortsInfo {
shortsInfo.flags = 0
shortsInfo.sampleTime = 0
val shorts = ShortArray(bufferSize) { getNext(shortsInfo) }
return ShortsInfo(shorts, 0, bufferSize, 0L, shortsInfo.flags)
}
private suspend fun getNext(info: ShortsInfo): Short {
val bufferInfo = cache ?: decoder.consume().also { cache = it }
info.flags = info.flags or bufferInfo.flags
if (bufferInfo.size == 0) {
cache = null
return getNext(info)
}
val result = bufferInfo.shorts[bufferInfo.offset]
bufferInfo.offset++
bufferInfo.size--
return result
}
}
混合音频AudioMix
添加音频: addAudioSource
会维持一个map记录AuidoCovert的id和AudioCovert
每次addAudioSource就是创建一个对象后记录到map中
kotlin 代码解读复制代码
private val map = ArrayMap<Int, AudioCovert>()
fun addAudioSource(path: String): Int {
map[++cnt] = AudioCovert(Decoder(scope, path), BUFFER_SIZE)
return cnt
}
启动:start
混音还需要注意的一个点是,原先的数据是short 但是多个轨道后相加很有可能就会溢出,溢出后会导入杂音
这就是混音算法的应用场景了,混音算法可以让混合后的音频不要溢出,或者规定了溢出发生的时候做什么
我这里没有用正常的混音算法,原本打算后面由调用方配置的,
只是简单的调用tanh把值约束在-1f与1f之间,又不是粗暴的裁剪,又可以听出多道一样的音轨的时候的与单独一道音轨的音量区别
kotlin 代码解读复制代码fun start() {
scope.launchIO {
startInner()
}
}
// TODO 不同音轨的声道数和采样率可能不同直接相加pcm数据,时间对不上,需转换
private suspend fun startInner() {
map.values.forEach { it.decoder.start() }
while (true) {
mutex.lock()
mix()
mutex.unlock()
}
}
private suspend fun mix() {
val shortMap = ArrayMap<Int, ShortsInfo>()
for ((id, decoder) in map.entries) {
shortMap[id] = decoder.getBuffer()
}
val firstInfo = shortMap.values.iterator().next()
val length = firstInfo.size
val floats = FloatArray(length)
shortMap.values.forEach { info ->
floats.addShortInfo(info)
}
for (i in floats.indices) {
// TODO 这个混音逻辑不行 后续做成可以由用户配置的
floats[i] = tanh(floats[i])
}
queue.produce(FloatsInfo(floats, 0, length, firstInfo.sampleTime, firstInfo.flags))
}
private fun FloatArray.addShortInfo(info: ShortsInfo) {
val offset = info.offset
for (i in offset until offset + info.size) {
this[i - offset] += info.shorts[i] / MAX_SHORT_F
}
}
SyncPlayer
没什么好说的,创建一个Audiotrack播放音乐
创建一个AudioMix混合音频数据
其他的addDataSource seekTo也只是封装了AudioMix的方法
kotlin 代码解读复制代码fun start() {
audioTrack = initAudioTrack()
mix.start()
audioTrack.play()
scope.launchIO {
startInner()
}
}
private suspend fun startInner() {
while (true) {
val bytesInfo = mix.queue.consume()
if (bytesInfo.flags == 4) {
audioTrack.stop()
break
}
audioTrack.write(bytesInfo.floats, bytesInfo.offset, bytesInfo.size, AudioTrack.WRITE_BLOCKING)
}
}
项目地址
源码如下:media分支
最后面对的问题:
这个播放器还有很多待完成的功能:
例如说播放,暂停,回复,释放资源
还有兼容不同采样率或者声道数的音乐
修正混音算法
但是更大的问题在于项目开启了太多的线程cpu占比过高,在播放多首歌曲的时候,在有些设备上出现性能不够的问题
例如在播放20首音频的时候
我的手机(天机8100)出现了明显的播放卡顿现象
而我的平板(骁龙865)则是 还可以正常播放
后面打算去优化一下写法,然后在native层编写转码和播放的功能,或许表现会好点,用硬解码播放的分支可能不会再更新了。
评论记录:
回复评论: