
探秘国产显卡:性能角逐背后的隐藏王者是谁?
近年来,随着人工智能、大数据、云计算等新兴技术的快速发展,高性能GPU芯片需求迎来井喷式增长。在全球GPU市场竞争格局中,AMD和NVIDIA持续领跑。但伴随中国科技力量的飞跃及国际环境的变迁,推动国产GPU的发展已成为一股不可忽视的重要趋势。
在政策扶持、资本涌入及市场需求激增的多重驱动下,国产GPU产业迅速崛起,国内厂商正奋力追赶国际领先企业。鉴于AI训练与推理任务对算力的需求持续攀升,国产显卡逐渐成为行业关注的热点。
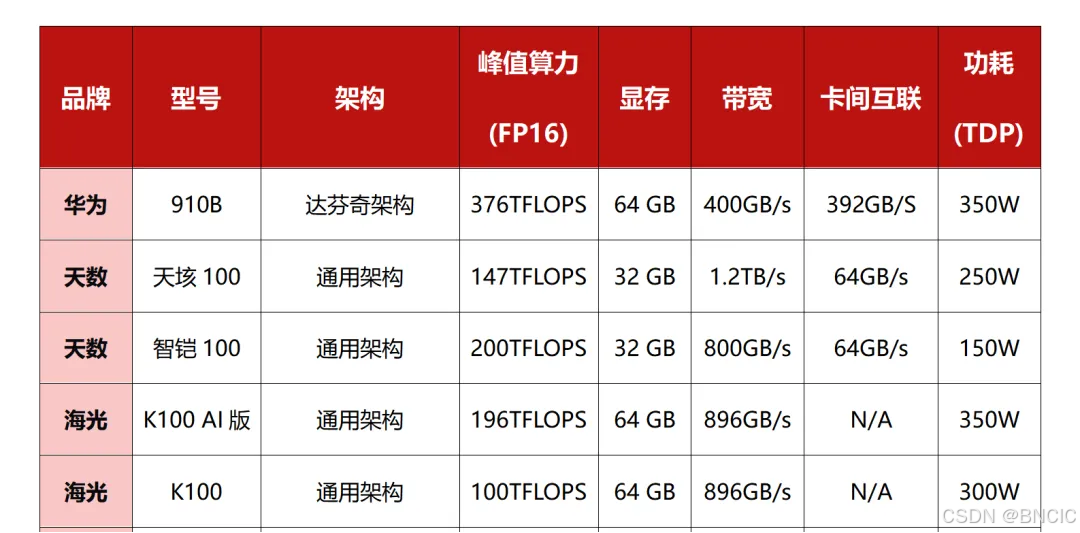
本文将对华为昇腾910B、天数天垓100、天数智铠100、海光K100 AI版、海光K100、寒武纪MLU590等一系列主流国产显卡进行深入对比,着重剖析其架构设计、算力、显存带宽、功耗等关键性能指标,揭示各款显卡的独特优势和技术亮点。
一、产品对比
二、架构设计与算力分析
华为昇腾910B
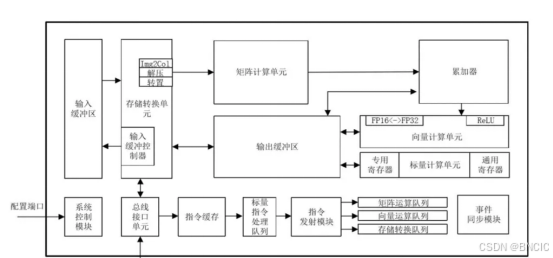
华为昇腾910B是一款基于华为自研达芬奇架构的高性能AI处理器,专为数据中心设计,适用于深度学习、机器学习及大规模数据处理场景。采用7nm工艺制程,该芯片在FP16浮点运算中提供高达376 TFLOPS的峰值算力,与英伟达A100相媲美,同时保持350W的低功耗,展现出卓越的能效比。昇腾910B支持大容量HBM高速内存,具备高达400GB/s的带宽,并兼容多种AI框架,包括华为自研的MindSpore。通过同百度在自动驾驶领域的合作,优化算法性能提升2倍以上,功耗降低80%。此外,该芯片还广泛应用于AI一体机和行业智能化解决方案,如能源、金融、交通等,为本地化大模型部署和行业智能升级提供强有力支持。然而,昇腾系列的良品率仍需进一步提高,避免对大规模部署项目产生影响。
天数天垓100
天垓100是天数智芯推出的一款基于自研通用架构的AI训练加速卡,专注于深度学习训练和多卡协作计算。其峰值算力为147 TFLOPS(FP16/BF16),支持FP32、INT8等多种数据精度,能够灵活适配多种算法。尽管显存带宽为64GB/s相对逊色,但其1.2TB/s的卡间互联带宽在分布式训练任务中展现出绝对优势。天垓100兼容CUDA生态和主流深度学习框架,支持x86和ARM架构,具备灵活的编程能力和高效的软件栈,能够帮助客户低成本、快速实现系统迁移。作为一款性价比出色的训练加速卡,天垓100适用于AI训练、多卡协作及分布式计算等场景。
天数智铠100
智铠100是天数智芯推出的一款专注于推理任务的通用GPU加速卡,基于通用架构设计,提供200 TFLOPS的推理算力,同时保持150W的超低功耗,展现出极高的能效比,特别适合安防、金融等对低功耗部署有严格要求的行业。智铠100支持FP32、FP16、INT8等多种精度推理,兼容CUDA生态和主流深度学习框架,具备灵活的编程能力和高性能函数库。其完善的软件栈工具支持X86和ARM架构,集成多种调试和优化工具,为人工智能应用的开发和部署提供了高效支持。智铠100以高性价比和广泛的行业适配性,成为推理任务中出色的选择。
海光K100 AI版
海光K100 AI版是一款基于通用架构设计的AI加速卡,拥有196 TFLOPS的峰值算力、64GB显存和896GB/s的显存带宽,特别适合显存密集型训练任务和高性能计算领域。其功耗为350W,支持飞桨框架ROCm版,能够在海光CPU与其专用的DCU(Deep Computing Unit)加速器上高效运行模型训练与预测任务。尽管其计算性能相比英伟达A100和H100略显不足,但通过硬件和软件架构优化,尤其在大模型的场景化落地方面展现了强劲的应用能力。
海光K100
海光K100拥有100 TFLOPS的峰值算力、64GB显存和896GB/s的显存带宽,在FP16性能上与K100AI版有较大差异,采用双精度计算单元,定位于需要高精度计算的通用任务场景。相比之下,K100 AI版则侧重单精度计算,在FP16和INT8算力上表现更优,适合AI任务。K100的设计更加通用,适用于高精度科学计算,而K100 AI版通过优化AI计算单元,在深度学习和人工智能任务中具备更高的效率。
寒武纪MLU590
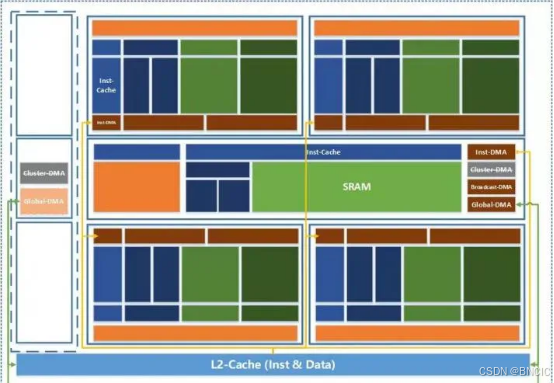
寒武纪MLU590是一款基于灵活的MLUv02扩展架构设计的高性能AI加速芯片,支持云端和端侧应用,具备314 TFLOPS(FP16)的峰值算力、80GB显存和高达2TB/s的带宽。在分布式计算和大规模模型训练任务中表现尤为突出。其架构具有端云一体的可扩展性,以TP(Tensor Processor)和MTP(Multi Tensor Processor)作为最小扩展单元:TP适用于单个IPU核心,适合低功耗的端侧应用;MTP则由多个IPU核心组成的Cluster,面向高性能的云端任务,可通过单机多卡或多机多卡的MLU-Link集群实现并行加速,满足云端AI计算和分布式任务的多样化需求。MLU590的设计在性能、灵活性和扩展性之间达到了良好平衡,是AI训练和推理的重要选择。
三、显存与带宽分析
显存和带宽是影响AI加速器性能的关键因素,尤其是在大规模模型训练和推理任务中至关重要。以下是各显卡的详细表现:
从显存和带宽的对比来看,寒武纪 MLU590 凭借 80GB 显存和 2TB/s 的超高带宽在大规模模型训练和数据吞吐方面表现突出;海光 K100 系列以 64GB 显存和 896GB/s 带宽在显存密集型任务中展现强劲实力;天数智铠100 和天垓100 虽显存为 32GB,但带宽分别达到 800GB/s 和 64GB/s,适合中型模型和推理应用;华为 910B 则以 64GB 显存和 392GB/s 带宽,结合其强大算力,适合深度学习等场景。
四、功耗
从功耗表现来看,各显卡在能效设计上各有侧重。华为昇腾 910B、海光 K100 AI版、寒武纪 MLU590 均采用 350W 的高功耗设计,聚焦于高性能计算和大规模AI训练任务;海光 K100 标准版功耗稍低,为 300W,适合对算力和能效均有需求的场景。天数天垓100以 250W 的功耗实现较优的算力与能效平衡,而智铠100功耗仅为 150W,是推理任务和低功耗应用的理想选择,特别适合对能效要求较高的行业应用。
总结
国产显卡于AI领域迅猛发展,各具鲜明特色。华为昇腾910B以其卓越的算力与广泛的应用场景展现出强大潜力;天数天垓100与智铠100在训练和推理任务中表现稳定;海光K100系列和寒武纪MLU590在算力、显存与扩展性方面各展所长,各具竞争优势。
从整体格局来看,这些国产显卡通过持续对架构进行深度优化,精心打磨每一项技术细节,并在能效设计上不断推陈出新,已经能够在多元化的 AI 应用场景中纵横驰骋,游刃有余地应对各种复杂挑战,充分彰显出强劲的市场竞争力。它们不仅是国产科技力量崛起的重要标志,更是北方算网构建强大信创资源池和重保资源池的坚实基石,北方算网积极与各大国产 GPU 厂商构建起紧密且深入的合作关系,全力投入到可信算力资源池的建设之中。
本文提及的相关参数及图片来源与网络,如有侵权请告知删除。
评论记录:
回复评论: