
DeepSeek
一、前言
最近DeepSeek非常火,DeepSeekV3在数学、编码能力已经超越GPT-4o和claude这种最强模型,在推理模型DeepSeek-R1在多项任务测试中都与OpenAi最强大的o1模型表现几乎一样,甚至优化后的DeepSeek-R1-32B模型也和OpenAi-o1mini表现差不多,作为一个爱好AI领域的人,我想将自己整理到的关于DeepSeek方面的一些内容分享给大家,想了解DeepSeek的可以看看。
1.1深度求索(DeepSeek)简介
深度求索(DeepSeek)成立于2023年,是一家专注实现AGI(通用人工智能)的中国人工智能公司,核心团队由前网易伏羲实验室负责人领衔,汇聚顶尖AI科学家与工程师。公司聚焦大模型技术研发与创新,致力于通过通用人工智能技术推动社会生产力跃迁。
1.2技术优势
• 自主研发的MoE架构大模型DeepSeek-R1,在数学推理、代码生成等复杂场景表现卓越
• 推出开源代码模型DeepSeek-Coder系列,长期占据Hugging Face代码模型榜单前列
• 创新性提出"全域注意力"机制,显著提升模型效率与性能
1.3核心产品
- 企业级大模型解决方案:提供垂直领域模型定制与私有化部署
- 开发者生态:开放API接口及开源模型矩阵(包括7B/33B/67B等参数版本)
- 智能体平台:支持低代码构建行业专属AI应用
二、DeepSeek性能对比
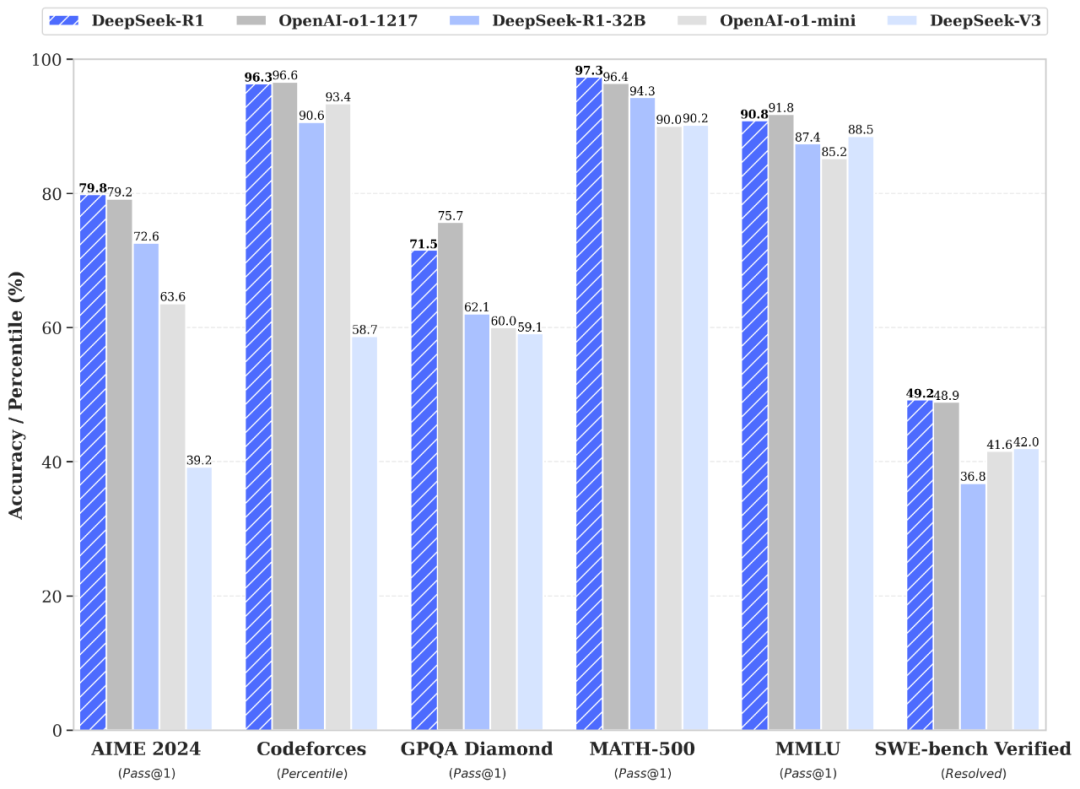
2.1 DeepSeek-R1与OpenAi-o1性能对比
性能对齐 OpenAI-o1 正式版,DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。
2.2 DeepSeek-V3与其它指令模型性能对比
DeepSeek-V3是一款拥有6710亿参数的专家混合(MoE)模型,激活370亿参数,基于14.8T token的预训练数据。生成速度方面相比V2.5提升了3倍,从 20TPS 提升至惊人的 60TPS。实测回复速度极快。DeepSeek-V3不仅开源了原生FP8权重,还提供了BF16转换脚本,方便社区适配和应用。SGLang、LMDeploy、TensorRT-LLM等工具已支持V3模型推理,进一步降低了用户的使用门槛。
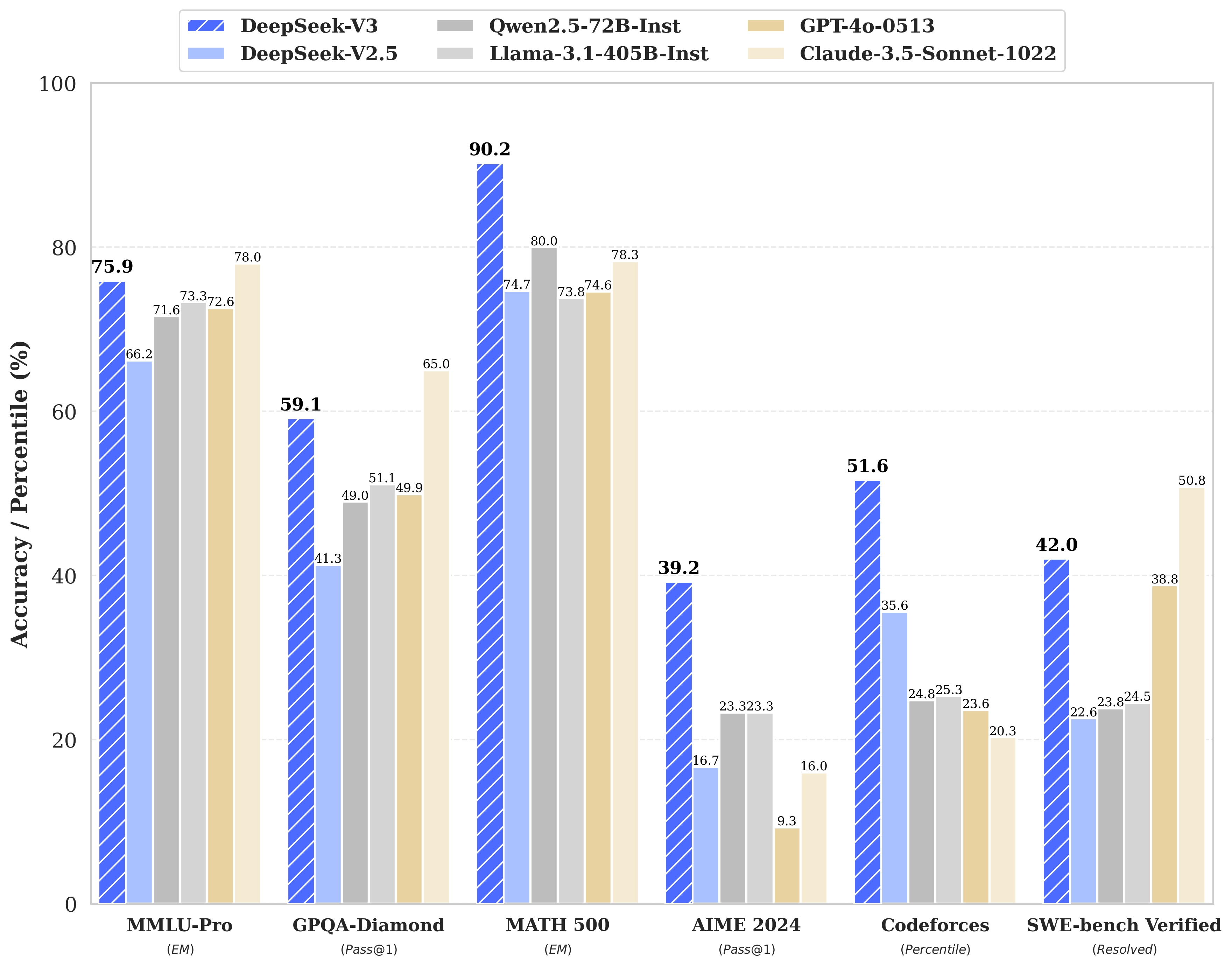
DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲。生成速度提升至 3 倍,通过算法和工程上的创新,DeepSeek-V3 的生成吐字速度从 20 TPS 大幅提高至 60 TPS,相比 V2.5 模型实现了 3 倍的提升,为用户带来更加迅速流畅的使用体验。这一模型的发布不仅标志着DeepSeek在 AGI(人工通用智能) 探索道路上的又一里程碑,也再次证明了其在开源AI领域的领先地位。
三、技术细节和创新
3.1、DeepSeek技术架构核心
3.1.1. 模型架构创新
- 混合专家系统(MoE)
- 采用细粒度专家拆分(如16-64个专家),配合动态路由算法,实现计算效率与模型性能的平衡
- 基于硬件特性的负载均衡优化,提升GPU利用率30%+
- DeepSeek-R1架构
- 创新性长上下文处理模块,支持128K+上下文窗口,通过位置编码改进与注意力机制优化,实现长文本理解RAG准确率提升40%
- 动态稀疏注意力机制,在保持性能前提下降低长文本处理显存占用60%
3.1.2. 训练基础设施
- 自研训练框架DS-Train
- 支持万卡级集群高效并行训练,实现90%+的线性加速比
- 混合精度训练优化,结合梯度压缩与通信优化,训练效率提升50%
- 数据工程体系
- 多阶段数据筛选Pipeline:基于质量评分、去重、毒性检测的多层过滤系统
- 创新课程学习策略,动态调整数据配比,提升训练效率20%
3.2、关键技术突破
3.2.1 效率革命
- DeepSeek-V2模型
- 同等效果下训练成本仅为GPT-4的1/8,推理成本降低70%
- 首创参数隐式扩展技术,通过146B激活参数实现千亿级模型效果
- 高效注意力机制
- FlashAttention-3定制优化版,单卡处理速度提升2.1倍
- 基于硬件特性的算子融合技术,降低显存峰值30%
3.2.2 AGI核心能力
- Infra-AGI框架
- 自主知识进化系统:实现模型参数的持续在线更新
- 多智能体协作架构,支持动态任务分解与结果合成
- 认知架构创新
- 引入神经符号系统,结合传统符号推理与神经网络优势
- 基于世界模型的预测性学习机制,提升因果推理能力
3.3 应用层创新
3.3.1 智能体系统**
- DeepSeek-Agent Framework
- 支持多模态输入的任务自动分解与工具调用
- 首创「反思-修正」闭环机制,任务完成率提升65%
- 企业级解决方案
- 行业知识即时注入技术,支持私有化部署的分钟级领域适配
- 安全护栏系统:实现实时内容过滤与合规性检查
3.3.2 多模态突破
- DeepSeek-Vision
- 视觉-语言联合建模架构,跨模态对齐效率提升3倍
- 支持复杂图表解析与视觉推理,科学文献理解准确率达89%
3.4 技术生态布局
- 搜索增强架构
- 实时搜索引擎直连技术,响应延迟<200ms
- 混合检索策略结合稠密/稀疏向量检索,召回率提升35%
- 开发者生态
- 模型即服务(MaaS)平台:支持API调用、微调、部署全流程
- 开源社区计划:逐步开放训练框架与工具链
3.5 核心优势对比
class="table-box">| 维度 | DeepSeek优势 | 行业基准 |
|---|---|---|
| 训练效率 | 千卡集群利用率>92% | 行业平均70-80% |
| 长文本处理 | 128K上下文准确率98.7% | 主流模型~85% |
| 多模态推理 | ScienceQA准确率89.2% | SOTA 83.5% |
| 能效比 | 每token能耗降低76% | 传统架构基准 |


评论记录:
回复评论: