
随着大语言模型(LLM)在各个领域的应用快速普及,越来越多开发者想要尝试在本地运行这些模型。然而,这些模型对计算机硬件的要求极高,特别是在显存(VRAM)和推理速度方面。那么,如何评估你的设备是否合适?本文将帮助你了解模型的存储需求、推理平台选择和不同硬件的实际表现,助力你找到最适合的配置。
不废话,先上结论:
绝大多数电脑 (包括笔记本) 几乎可以跑 AI 模型,但是使用不同 AI 模型,不同平台,不同机器推理速度差异会很大。
如果你想要跑一个勉强可玩的 LLM (比如 Llamma3.2 1B 模型),至少需要:
- 内存至少 16 GB
- CPU 至少是 4核 (非硬性要求,只是为了保证 1 秒大概能生成 5 个字的速度) 及以上
- CPU 至少 4GB 的显卡 (可选,如果不想用 llamma.cpp 跑模型)
- 优先推荐 vLLM 平台 (使用 GPU) 上跑模型,来获取最快的推理速度。

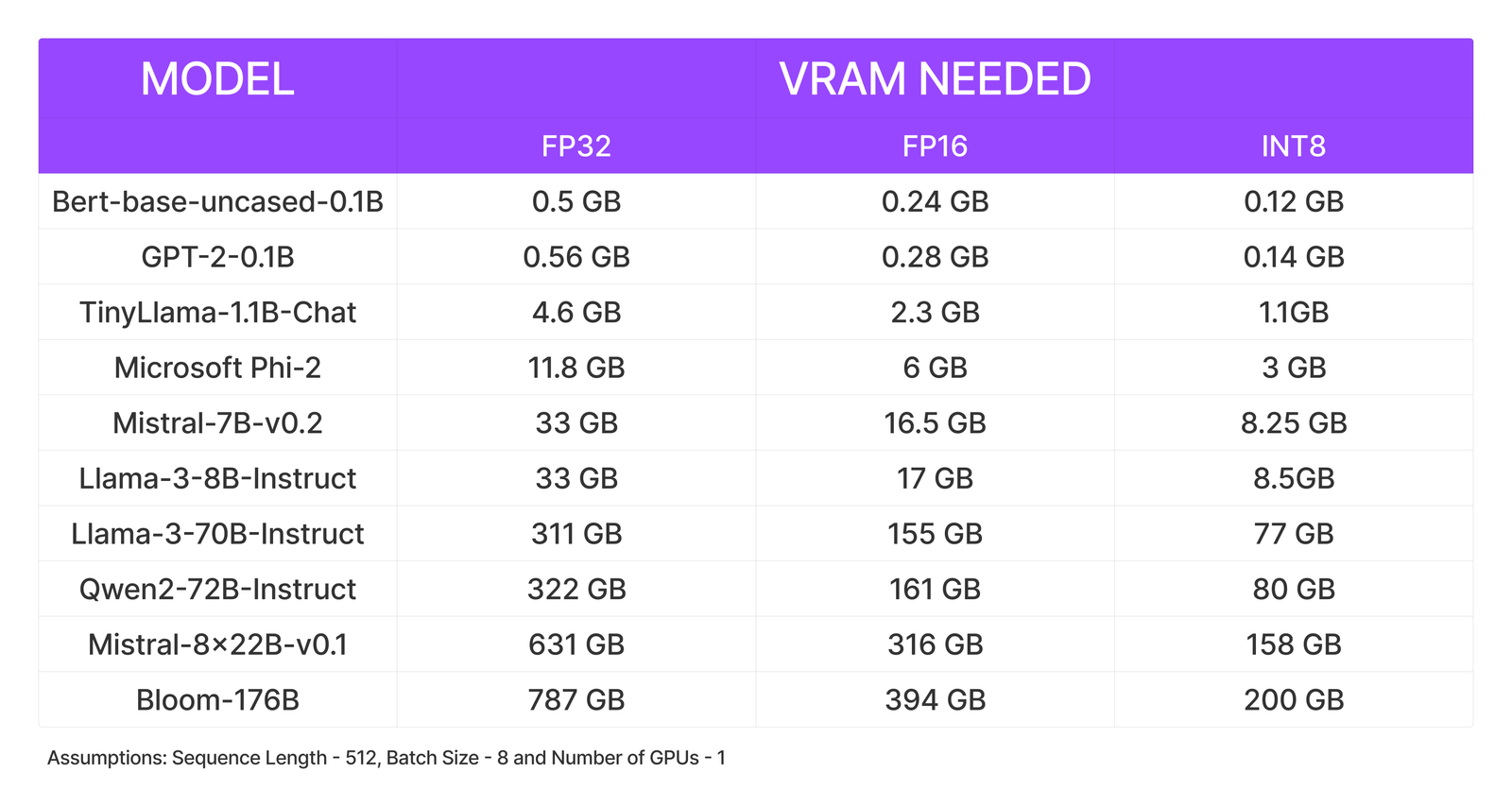
一、模型参数和存储需求计算
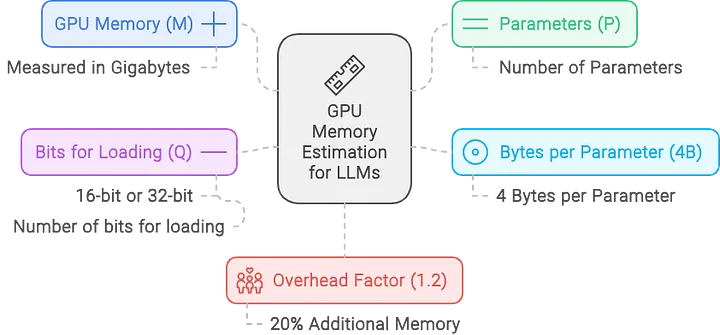
要高效运行大语言模型,我们首先需要了解模型的 参数量 和 比特量化(Bit Quantization)。模型的显存需求(VRAM)可以通过以下公式计算:
$$
M=\frac{P \times 4B}{32 / Q} \times 1.2
$$
class="table-box">| 符号 | 含义 |
|---|---|
| M M M | 显存大小需求,单位:GB |
| P P P | 模型的参数量(Billion = 10 亿) |
| Q Q Q | 量化位宽(如 16-bit、8-bit、4-bit) ,每个参数占用的存储 |
| 4 B 4B 4B | 4 个字节 (原始模型用 32-bit 参数量化,占 4 个字节存储) |
| 1.2 1.2 1.2 | 20% 的额外开销,用于加载辅助数据 |

评论记录:
回复评论: