


【个人主页】Francek Chen
【人生格言】征途漫漫,惟有奋斗!
【热门专栏】大数据技术基础 | 数据仓库与数据挖掘 | Python机器学习
前言
在 2024 年的这一年中,我沉浸在创作的海洋中,感受着技术与文字交织带来的无限魅力。每一次敲击键盘,都是对知识的提炼与分享,每一次点击发布,都是与世界的又一次深刻对话。回顾这一年的历程,心中充满了成长的喜悦与收获的满足。
从最初对技术的懵懂探索,到如今能够自信地在大数据领域发声,我经历了无数次的挑战与突破。在这过程中,我不仅加深了对技术的理解,更学会了如何以更加清晰、独特的笔触,将复杂的技术概念转化为易于理解的语言,与广大读者共享这份知识的盛宴。
在过去的一年里,我经历了许多的挑战和成长,本文主要是回顾我的个人成长历程,以及在创作和日常生活方面的突破,分享我是如何平衡个人生活与博客创作的经验。
一、个人成长与盘点
我是一名数据科学与大数据技术专业的大四学生,专注于学习大数据分析和机器学习相关的知识。一开始,大一大二期间,认为学习基本的计算机编程语言(C语言、Java和Python等基础课)是一段很枯燥的过程,但是到了大三,进一步学习了大数据技术的相关专业课,方才明白这些编程语言的重要性,让我对专业课有了更充分的学习动力,产生了浓厚的兴趣并开始了博客的创作。
(一)机缘与开端
在信息技术日新月异的时代,不知不觉的加入 CSDN 已有三年时间了,我于 2022 年 4 月与 CSDN 不期而遇,这仿佛是命运巧妙的安排,为我打开了通往广阔技术世界的大门。当时,我正站在学习生涯的十字路口,对未来的发展充满迷茫与憧憬。在一次偶然的机会中,学长向我推荐了几个 IT 社区平台,其中就包括 CSDN——中国最大的程序员创作平台。怀揣着对未知的好奇与对技术的渴望,我毫不犹豫地注册了 CSDN 的账号。初入这个平台,我被其丰富的技术资源、活跃的交流氛围所深深吸引。在这里,不仅有资深专家分享的前沿技术动态,也有同行们探讨的实战经验心得。我仿佛找到了一片技术的沃土,渴望在这里汲取养分,茁壮成长。
直到 2023 年下半年,在学校开始了大数据专业相关课程的学习,由此才开始萌生了创作的想法,然后于 11 月 28 日发布了人生中第一篇博客《大数据技术概述》,接下来就一直围绕着大数据主题、结合所学的课程进行创作。后来,学习人工智能和机器学习相关的知识和内容,拓宽自己的知识面,提升个人能力。通过写博客来记录学习的过程,也可以巩固知识,与大家分享。随着时间的推移,我逐渐深入了解了 CSDN 的方方面面。从最初的浏览帖子、学习他人经验,到后来的主动参与讨论、分享自己的见解,我逐渐融入了这个大家庭。在这个过程中,我不仅拓宽了技术视野,也结识了许多志同道合的朋友。我们共同学习、共同进步,一起为技术的梦想而努力奋斗。
回首这一年,我深感庆幸与感激。庆幸自己能够遇到 CSDN 这样优秀的平台,感激它为我提供的学习机会与交流空间。我相信,在未来的日子里,我会继续在这个平台上发光发热,为技术事业贡献自己的力量。

(二)收获与分享
在过去的一年里,我全身心地投入到创作之中,不仅是为了分享我的知识和经验,更是为了与广大读者共同成长。经过不懈的努力,我收获了众多粉丝的关注和支持,这对我来说是莫大的鼓励和肯定。在此,我想与大家分享一些我认为比较好的专栏以及我最喜欢的三篇文章,希望能为大家的学习之路提供一些帮助和启发。
1、我认为比较好的专栏有:
- 大数据技术基础:这个专栏涵盖了大数据技术的方方面面,从Hadoop、Spark到HBase等核心组件的安装配置到实验实践,我都进行了详细的介绍和解读。通过一系列的实验,读者可以深入了解大数据技术的底层原理和实际应用,为未来的大数据分析和挖掘打下坚实基础。
- Spark编程基础:Spark作为大数据处理领域的明星框架,其强大的数据处理能力和灵活的编程模型深受开发者喜爱。在这个专栏中,我不仅介绍了Spark的基本概念和架构,还通过丰富的实例代码展示了如何使用Spark进行数据处理和分析。无论是初学者还是有一定经验的开发者,都能在这里找到适合自己的学习内容。
- 数据仓库与数据挖掘:数据仓库和数据挖掘是大数据分析中不可或缺的。在这个专栏中,我深入探讨了数据仓库的构建和管理、数据挖掘的方法和技巧等关键内容。通过实际案例的分析和解读,读者可以更加直观地理解数据仓库和数据挖掘在大数据分析中的重要作用。
- Python机器学习:Python作为机器学习领域的首选编程语言,其简洁的语法和强大的库支持使得机器学习模型的构建和训练变得更加容易。在这个专栏中,我不仅介绍了Python机器学习的基础知识和常用算法,还通过实例代码展示了如何使用Python进行机器学习模型的构建和评估。对于想要学习机器学习的读者来说,这是一个不可多得的学习资源。
欢迎大家前来订阅,共同学习。嘿嘿?
2、我最喜欢的三篇文章是:
- 大数据存储技术(1)—— Hadoop简介及安装配置:这篇文章是我对Hadoop技术的全面介绍和安装配置的详细指导。Hadoop作为大数据存储和处理领域的基石,其重要性不言而喻。在这篇文章中,我不仅介绍了Hadoop的基本概念和发展历史,还详细讲解了Hadoop的安装配置步骤和注意事项。通过这篇文章的学习,读者可以快速上手Hadoop技术,为后续的大数据处理和分析打下坚实基础。
- 【大数据分析&深度学习】在Hadoop上实现分布式深度学习:这篇文章是我对Hadoop与深度学习结合应用的探索和实践。随着大数据和人工智能技术的不断发展,分布式深度学习已经成为了一个热门的研究方向。在这篇文章中,我不仅介绍了Hadoop和深度学习的基本概念和原理,还详细讲解了如何在Hadoop上实现分布式深度学习模型的构建和训练。通过这篇文章的学习,读者可以更加深入地了解Hadoop与深度学习技术的结合应用和未来发展趋势。
- 【智能大数据分析 | 实验四】Spark实验:Spark Streaming:这篇文章是我对Spark Streaming技术的实验实践和心得分享。Spark Streaming作为Spark框架中的实时数据处理组件,其强大的数据处理能力和灵活的编程模型深受开发者喜爱。在这篇文章中,我不仅介绍了Spark Streaming的基本概念和工作原理,还通过实际案例展示了如何使用Spark Streaming进行实时数据处理和分析。通过这篇文章的学习,读者可以深入了解Spark Streaming技术的实际应用和编程技巧。
其中,实验部分代码如下:
package spark.streaming.test;
import scala.Tuple2;
import com.google.common.collect.Lists;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.StorageLevels;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import java.util.Iterator;
import java.util.regex.Pattern;
public class SparkStreaming {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws InterruptedException {
if (args.length < 2) {
System.err.println("Usage: JavaNetworkWordCount " );System.exit(1);
}
SparkConf sparkConf = new SparkConf().setAppName("JavaNetworkWordCount");
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(1));
JavaReceiverInputDStream<String> lines = ssc.socketTextStream(
args[0], Integer.parseInt(args[1]), StorageLevels.MEMORY_AND_DISK_SER);
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String x){
return Lists.newArrayList(SPACE.split(x));
}
});
JavaPairDStream<String, Integer> wordCounts = words.mapToPair(
new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
wordCounts.print();
ssc.start();
ssc.awaitTermination();
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
二、年度创作历程回顾
(一)创作历程概览
回望 2024,我的创作之旅如同一幅丰富多彩的画卷,缓缓展开在眼前。从最初的摸索与尝试,到如今的熟练与自信,每一步都凝聚着我的心血与汗水。起初,我对创作充满了好奇与憧憬,却也面临着无数的挑战与困难。我不断地学习、实践,试图找到属于自己的创作风格与表达方式。在这个过程中,我经历了无数次的失败与挫折,但正是这些经历,让我更加坚定了创作的信念,也让我更加珍惜每一次的成功与收获。随着时间的推移,我的创作逐渐走向成熟。我开始尝试不同的题材与风格,不断挑战自己的创作极限。每一次的创作,都是一次全新的探索与发现,让我更加深入地理解了创作的魅力与价值。
这段时间里,我经历了许多,感受到了成长的喜悦。在日常学习的繁忙中,我依然坚持创作的信念,将技术和经验分享给大家。但无论是繁忙还是减缓,每次打开创作的心扉,都是一次新鲜的体验。这一年来,是技术之路的探索,是表达能力的锻炼,更是自我的成长。每一篇博客都是一次对知识和经验的总结,也是对自己成长的见证。或许在技术领域取得了一些进步,或许在写作中找到了更加独特的风格,这一切都是在不断尝试和努力中实现的。



经过这 2024 一年的创作时间,我得到了许多宝贵的收获。截至目前我创作了 263 篇文章,收获了 15319 位粉丝,获得了 596889 次总访问量、10959 次点赞、3223 次评论、8825 次收藏以及我最喜欢的创作者身份认证大数据领域优质创作者。从新星创作者到优质创作者,从 5k 粉丝到 1w 粉丝,从综合热榜第十六到综合热榜第二,创作者周榜排名不断上升,都是一点一滴、不断积累的结果,这让我感到非常欣慰和鼓舞。
在创作的道路上,我也结识了许多志同道合的朋友与伙伴。我们相互鼓励、相互支持,共同分享着创作的喜悦与成就。这些珍贵的友谊与回忆,成为了我创作历程中不可或缺的一部分。他们不仅给予了我许多宝贵的建议和支持,还让我看到了更广阔的技术世界。在加入 CSDN 这个圈子慢慢的也是认识了很多创作者:AIGC领域优质创作者小ᶻ☡꙳ᵃⁱᵍᶜ꙳,全栈领域优质创作者景天科技苑,博客专家小虚竹、征途黯然.、韩楚风等等。
如今,我的创作已经取得了一定的成果与影响。但我深知,这只是一个新的起点,未来的路还很长。我将继续秉持初心,坚持创作,用更多的优秀作品,回馈那些一直支持我、关注我的朋友们。感谢这段创作历程,让我成长、让我收获。我相信,在未来的日子里,我会继续书写属于自己的创作传奇,为 CSDN 创作平台增添更多的色彩与美好。
(二)荣誉与成就
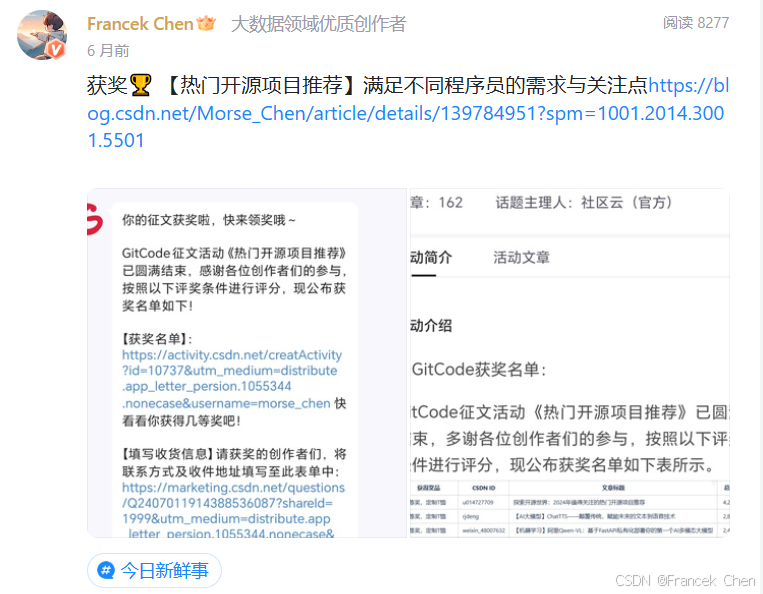
2024 年度,我参加了不少 CSDN 官方举办的创作者活动,例如,GitCode 征文活动《热门开源项目推荐》和 1024 程序员节征文活动。与此同时,也参加了其它相关平台的创作者活动,并获得了相关荣誉,例如,阿里云乘风者计划·专家博主和华为云·云享专家。


三、博客创作日常
创作文章,这一行为已经悄然融入了我的学习生活,成为不可或缺的一部分。在繁重的学业与自我提升的双重压力下,我始终坚守着创作博客的这片阵地,视之为一种习惯,一种对知识的沉淀与分享。CSDN,这个技术交流的广阔平台,早已成为我学习旅程中的重要伙伴,陪伴我共同成长。
每天,当灵感涌现之时,我便会打开 CSDN 的编辑器,开始我的博客创作。我深知,在有限的时间和精力下,坚持创作并非易事,但正是这份坚持,让我得以系统地整理所学知识,形成自己的理解体系。每一篇文章的诞生,都是对某个技术点或学习方法的深度剖析,它们如同一块块拼图,逐渐构建起我个人的知识图谱。
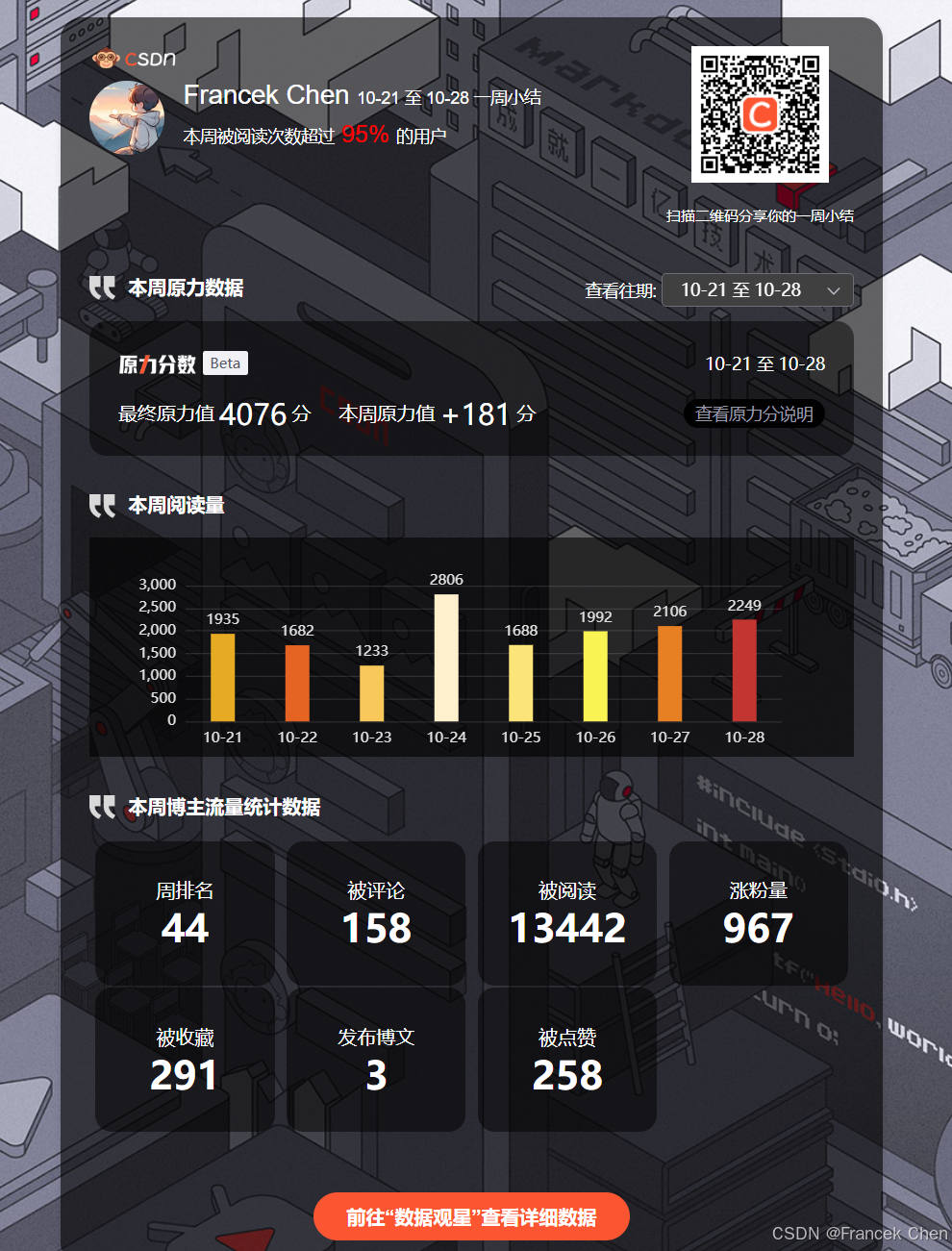
写博客的习惯,不仅让我能够随时回顾自己的学习历程,查漏补缺,更在无形中促使我不断提升自我。每当翻阅过去的文章,我都能清晰地看到自己的成长轨迹,那些曾经的困惑与不解,如今已化为解决问题的利器。这种成就感,无疑是对我持续创作的最大动力。更重要的是,博客创作让我学会了如何将理论与实践相结合,将创作中的经验和教训转化为实际工作中的智慧。无论是面对复杂的项目任务,还是解决突如其来的技术难题,我都能够迅速调动起博客中积累的知识与经验,找到最优解。这种能力,无疑为我的学习与工作增添了强大的助力。
展望未来,我将继续秉承记录与分享的精神,将博客创作进行到底。我相信,通过不断的积累与实践,我能够在这个充满挑战与机遇的技术世界里,走得更远、更稳。CSDN,这个见证我成长的地方,也将继续成为我学习旅程中最坚实的后盾。

四、个人业余生活爱好
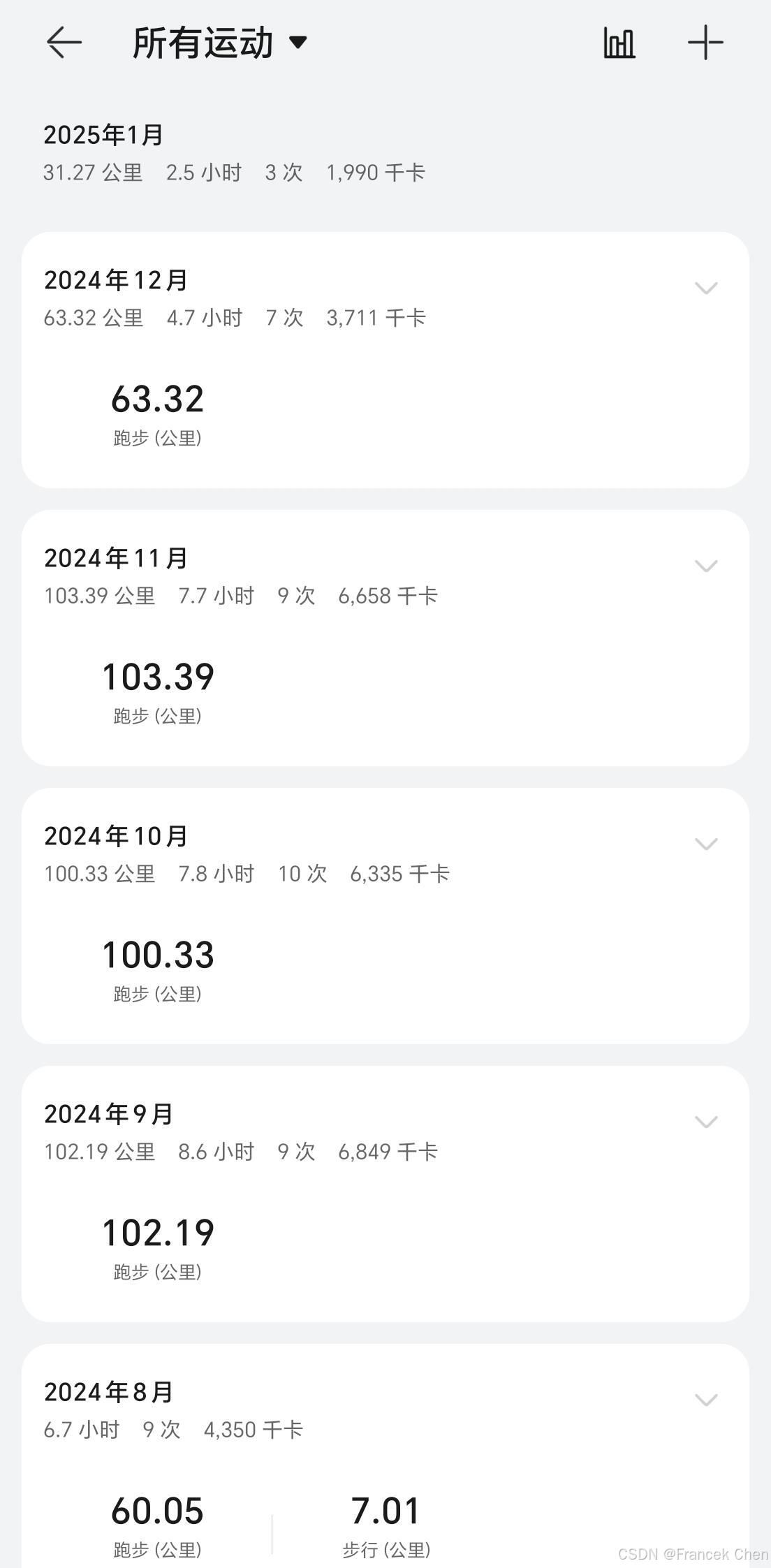
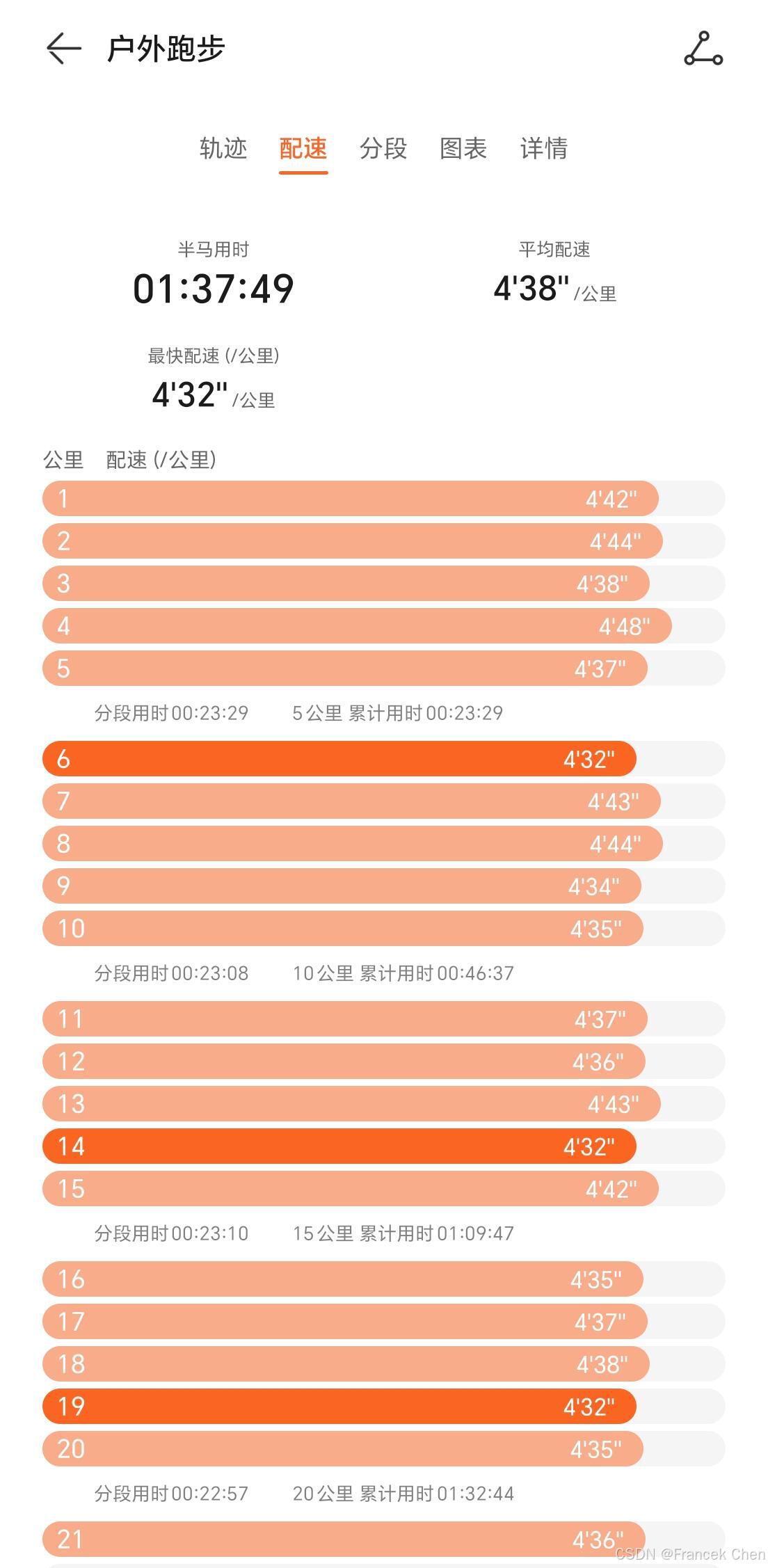
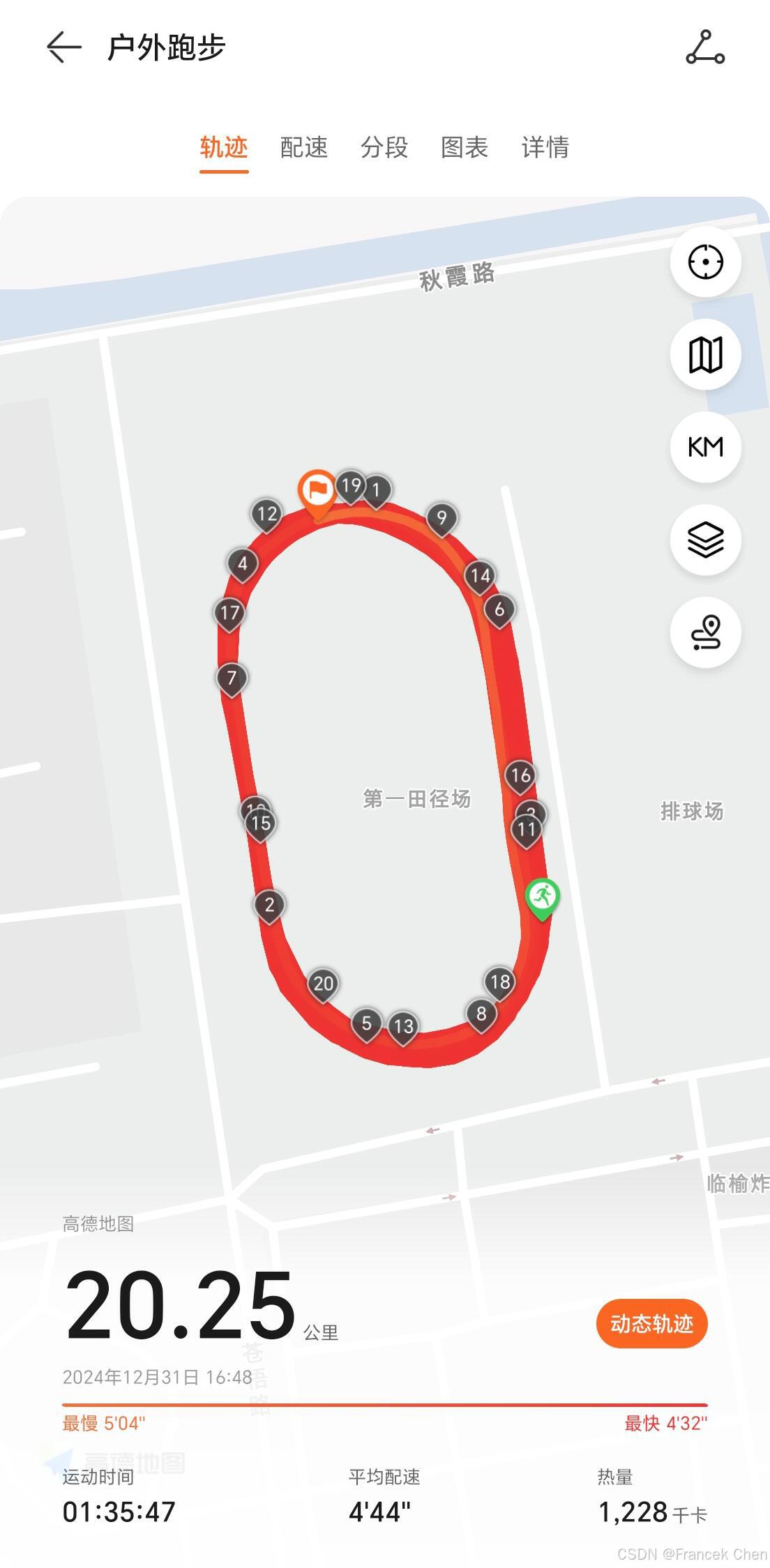
热爱运动的我,总是喜欢在业余时间通过跑步锻炼身体,增强体质,良好的身体素质才是程序员之本。当觉得自己劳累疲倦,想要放弃之时,始终会想起大正的一句话:“没有白练的!”。这也是我不断前进、进步的动力。加油,2025!
五、未来憧憬
1. 职业规划
在未来的职业道路上,我怀揣着对大数据分析的无限热情与憧憬,立志成为该领域的佼佼者。我深知,技术的深度与广度是职业发展的基石,因此,我将不遗余力地深化自己的技术能力,拓宽领域知识,以期在大数据分析的相关工作与研究中,贡献自己的力量,实现个人价值与社会价值的双重飞跃。
2. 创作规划
在 CSDN 的创作旅程中,我深刻体会到了自我提升的喜悦与挑战并存的滋味。面对创作中的不足,如词穷、技术深度不够等问题,我已制定了明确的改进计划。首先,我将加大阅读专业技术书籍的力度,不仅限于大数据分析领域,还将涉猎相关学科的前沿知识,以拓宽知识面的深度和广度。其次,我将通过不断的写作实践,沉淀技术功底,提升文章质量,力求每一篇作品都能为读者带来实质性的收获。
同时,我也将积极寻求与行业内专家的交流与合作,汲取他们的宝贵经验,为自己的创作注入新的灵感与动力。我相信,通过不懈的努力与坚持,我能够不断提升自己的创作水平,向更高的平台迈进。让我们一起加油,共同见证彼此的成长与蜕变!


 微信名片
微信名片

评论记录:
回复评论: