
在当今科技飞速发展的时代,人工智能(Artificial Intelligence,简称 AI)已然成为推动社会进步的核心力量。从智能语音助手到自动驾驶,从医疗诊断到金融风险预测,AI 的应用无处不在,深刻地改变着我们的生活和工作方式。随着 AI 技术的不断演进,各种 AI 模型如雨后春笋般涌现,它们在不同的领域展现出独特的能力。而在这众多的模型中,DeepSeek 以其卓越的性能和独特的优势,成为了 AI 领域中一颗耀眼的明星。本文将深入探讨 DeepSeek 的显著优点,并详细介绍如何借助蓝耘智算平台搭建 DeepSeek R1 模型,让更多的人能够体验到这一强大工具的魅力。
一、DeepSeek:AI 领域的璀璨明珠
1.1 DeepSeek卓越性能
-
语言生成:DeepSeek 在语言生成方面表现出色,尤其是在中文语境下,其优势更加明显。它能够生成自然流畅、语义准确的文本,无论是日常对话、文案创作还是学术写作,都能轻松应对。在多轮对话中,DeepSeek 能够准确理解上下文的含义,保持对话的连贯性,给出贴合语境的回答,让人感觉仿佛是在与一位真实的对话者交流。例如,在撰写一篇关于人工智能发展趋势的文章时,DeepSeek 能够迅速组织语言,提供丰富的观点和论据,生成高质量的文章内容。
-
逻辑推理:面对复杂的逻辑推理任务,DeepSeek 毫不逊色。无论是数学问题的求解,还是复杂的逻辑分析,它都能凭借强大的算法和丰富的训练数据,进行清晰、准确的推理。例如,在解决一道复杂的数学证明题时,DeepSeek 能够逐步分析问题,给出详细的推理过程和准确的答案,帮助用户更好地理解问题的本质。
-
计算效率:DeepSeek 的模型设计经过精心优化,在保证高性能的同时,对计算资源的消耗较低。这使得它可以在各种环境中高效部署,无论是小型企业的服务器,还是个人电脑,都能轻松运行。与其他一些对计算资源要求较高的模型相比,DeepSeek 大大降低了使用门槛,让更多的人能够享受到 AI 技术带来的便利。
1.2 Deepseek成本优势
以 DeepSeek-V3 为例,它拥有庞大的 671 亿参数量和 37 亿激活参数,预训练 token 量高达 14.8 万亿,但令人惊讶的是,其训练成本却仅为同类模型 GPT-4o 的二十分之一。如此低廉的训练成本,使得企业和开发者在大规模应用时,无需承担高昂的费用,能够更经济高效地利用资源。这对于推动 AI 技术的普及和应用具有重要意义,让更多的人能够参与到 AI 的创新和发展中来。
1.3 Deepseek广泛应用

-
智能客服:在智能客服领域,DeepSeek 能够快速准确地响应客户的咨询,理解客户的问题,并提供满意的解决方案。它可以 24 小时不间断工作,大大提高了客户服务的效率和质量,提升了客户满意度。例如,当客户询问产品的使用方法或售后服务时,DeepSeek 能够迅速给出详细的解答,让客户感受到便捷和贴心的服务。
-
内容创作:对于内容创作者来说,DeepSeek 是一个强大的助手。它可以提供创意灵感、生成大纲甚至具体内容,帮助创作者提高创作效率和质量。无论是小说、诗歌、广告文案还是新闻报道,DeepSeek 都能为创作者提供有价值的参考。例如,当创作者在构思一个故事时,DeepSeek 可以提供一些情节线索和人物设定的建议,帮助创作者打开思路。
-
教育辅助:在教育领域,DeepSeek 可以帮助学生答疑解惑,辅助教师备课。它可以作为一个智能学习伙伴,为学生提供个性化的学习指导,帮助学生更好地理解和掌握知识。同时,教师也可以利用 DeepSeek 生成教学资料、设计教学方案,提高教学质量。例如,当学生在学习数学、物理等学科时遇到难题,DeepSeek 可以提供详细的解题思路和步骤,帮助学生解决问题。
-
数据分析:在数据分析领域,DeepSeek 能够从海量的数据中挖掘有价值的信息,为企业的决策提供有力的支持。它可以进行数据清洗、特征提取、模型训练等工作,帮助企业更好地理解市场趋势和客户需求。例如,在市场调研中,DeepSeek 可以分析消费者的购买行为和偏好,为企业的产品研发和营销策略提供参考。
1.4 Deepseek开源共享
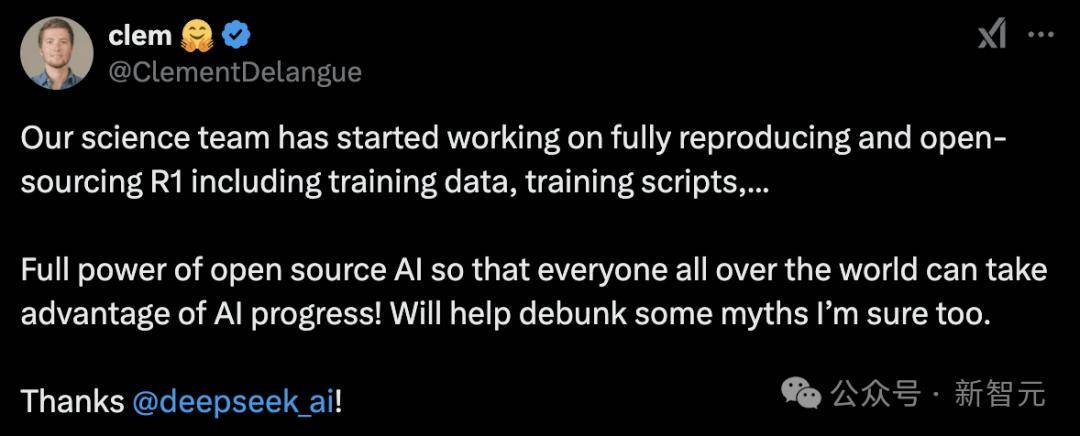
DeepSeek 完全开源且支持免费商用和衍生开发,这一开放的策略吸引了全球众多开发者的参与。开源不仅提高了模型的透明度,还促进了全球开发者之间的协作与改进。开发者们可以根据自己的需求对 DeepSeek 进行定制和优化,基于 DeepSeek 的创新应用不断涌现,进一步推动了 AI 技术的发展。
二、DeepSeek 与其他 AI 模型的对比
2.1 中文语境
在中文语境下,DeepSeek GPT-4在语言生成能力方面表现出色,生成的文本自然流畅,且多轮对话具有较强的连贯性,整体语言生成能力优异。然而,与DeepSeek在多模态融合下的独特语言生成优势相比,其在纯文本生成能力方面略逊一筹。逻辑推理方面,DeepSeek GPT-4能够准确推理复杂的数学和逻辑问题,且推理过程清晰,堪称行业标杆;而DeepSeek在逻辑推理的表现较为一般,更多专注于多模态任务。
2.2 计算效率
在计算效率方面,DeepSeek GPT-4对计算资源的消耗较低,适合在资源有限的环境中部署;相比之下,Google Gemini的计算资源需求较高,部署成本较为昂贵。DeepSeek的计算资源需求会根据任务不同有所变化,但在多模态任务中需要的资源较大。
2.3 训练成本
从训练成本来看,以DeepSeek-V3为例,训练成本仅为GPT-4的二十分之一,显示出较高的性价比;而Google Gemini的训练成本则较为昂贵,具体费用取决于模型版本。
2.4 应用场景
在应用场景上,DeepSeek GPT-4广泛应用于智能客服、内容创作、教育辅助和数据分析等企业级应用中,具备明显优势。Google Gemini则主要专注于多模态任务,如图像描述和视频分析等。
关于开源与专有性,DeepSeek完全开源,支持免费商用和衍生开发;而部分Google Gemini的新模型采用了专有模式,限制了开发者的自由使用和深度开发。部分核心技术也具有较强的专有性,尤其在多模态相关领域。
通过以上对比可以看出,DeepSeek 在性能、成本、应用和开源等方面都具有独特的优势,尤其是在中文语境和企业级应用场景中表现突出。不同的 AI 模型各有所长,用户在选择时应根据自己的需求、预算和应用场景等因素进行综合考虑,选择最适合自己的 AI 工具。
三、蓝耘智算平台:DeepSeek 的最佳搭档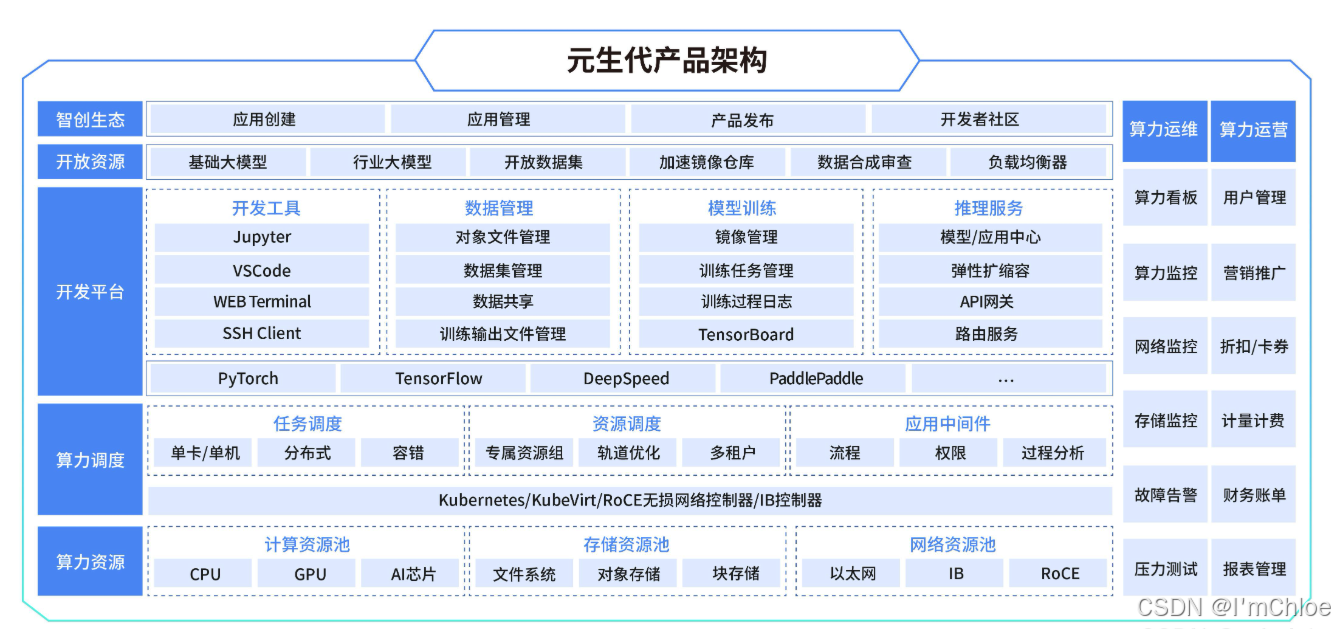
蓝耘 GPU 智算云平台是依托 Kubernetes 搭建的现代化云平台,它具备行业领先的灵活基础设施和大规模 GPU 算力资源。该平台为用户提供开放、高性能且性价比高的算力云服务,全方位助力 AI 客户开展模型构建、训练和推理的全业务流程,同时也为教科研客户加速科研创新。蓝耘智算平台的运算速度比传统云服务提供商快 35 倍,成本却降低了 30%,为用户提供了高效、经济的计算解决方案。
在大模型训练场景下,蓝耘算力云平台将运行环境、模型以及训练框架统一打包至容器中,借助定制化的 Kubernetes 容器编排工具,实现容器的调度、管理与扩展。这一举措有效解决了开发环境设置、运维和管理等方面的问题,算法工程师能够运用统一的环境模板进行开发,避免了初期繁杂的开发环境搭建,以及在新环境中管理新算力资源的困扰,为用户提供了便捷的、开箱即用的大模型训练与推理平台。
此外,蓝耘 GPU 智算云平台针对大模型训练中常见的容器进程死机、大规模分布式训练中 GPU 驱动丢失、GPU 硬件损坏、计算节点宕机等难题,进行了定制化设计,具备自动化调度能力和强大的自愈能力。这些特点大幅提升了开发和训练效率,提高了整体资源利用率,为用户提供了稳定、可靠的计算环境。
四、为何选择蓝耘智算平台搭建 DeepSeek
在使用 DeepSeek 时,我们可能会遇到一些问题,如服务器繁忙报错等,这会影响我们的使用体验。如果选择本地部署,不仅会占用大量的内存(最小的模型就需要 1GB),对显卡的要求也比较高,而且下载的本地模型在调用时可能不够智能,有时会出现答非所问的情况。而蓝耘智算平台则为我们提供了一个更好的解决方案。使用联网状态的 DeepSeek R1 模型,相较于离线的模型更加智能,能够为我们提供更准确、更及时的服务。同时,蓝耘智算平台的高性能和高可靠性也能够保证 DeepSeek 的稳定运行,让我们能够更加高效地使用这一强大的工具。
五、使用蓝耘 GPU 智算云平台搭建 DeepSeek R1 模型并成功调用的教程
5.1 注册与登录
打开蓝耘智算平台的注册链接:https://cloud.lanyun.net//#/registerPage?promoterCode=0131,填写相关信息完成注册。
注册成功后,点击已有账号,输入账号密码进行登录。
5.2 选择模型
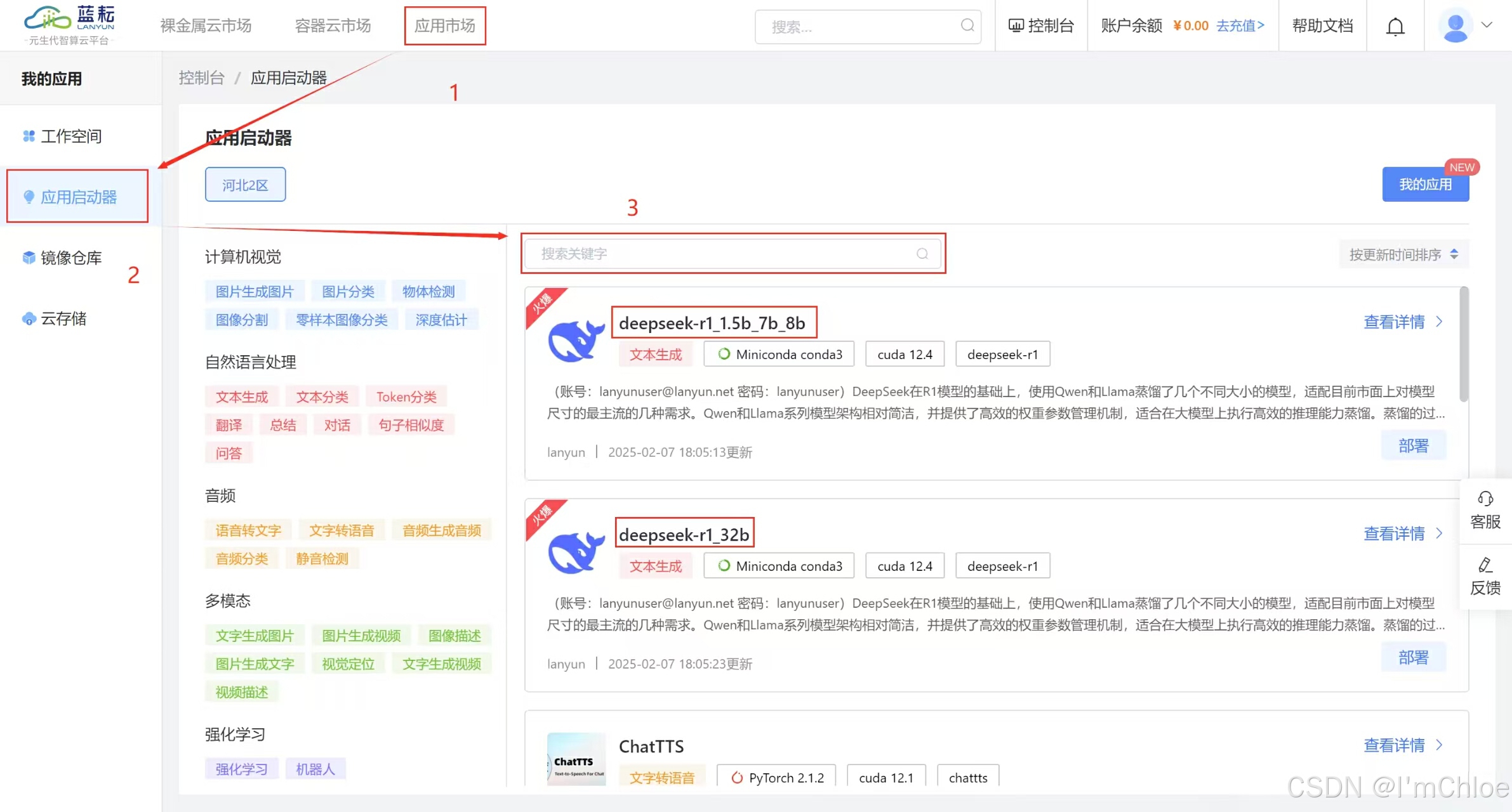
登录后,点击左上角的应用市场,在众多的 AI 大模型中找到 DeepSeek R1 模型。为了更清晰地展示,我们选择使用 deepseek-r1_1.5b_7b_8b 这个模型。
点击进入模型详情页面,可以查看模型的相关介绍,包括如何使用以及如何进行部署等信息。DeepSeek 在 R1 模型的基础上,使用 Qwen 和 Llama 蒸馏了几个不同大小的模型,适配目前市面上对模型尺寸的最主流的几种需求。Qwen 和 Llama 系列模型架构相对简洁,并提供了高效的权重参数管理机制,适合在大模型上执行高效的推理能力蒸馏。蒸馏的过程中不需要对模型架构进行复杂修改,减少了开发成本 【 默认账号: [email protected] 密码:lanyunuser】
5.3 部署模型
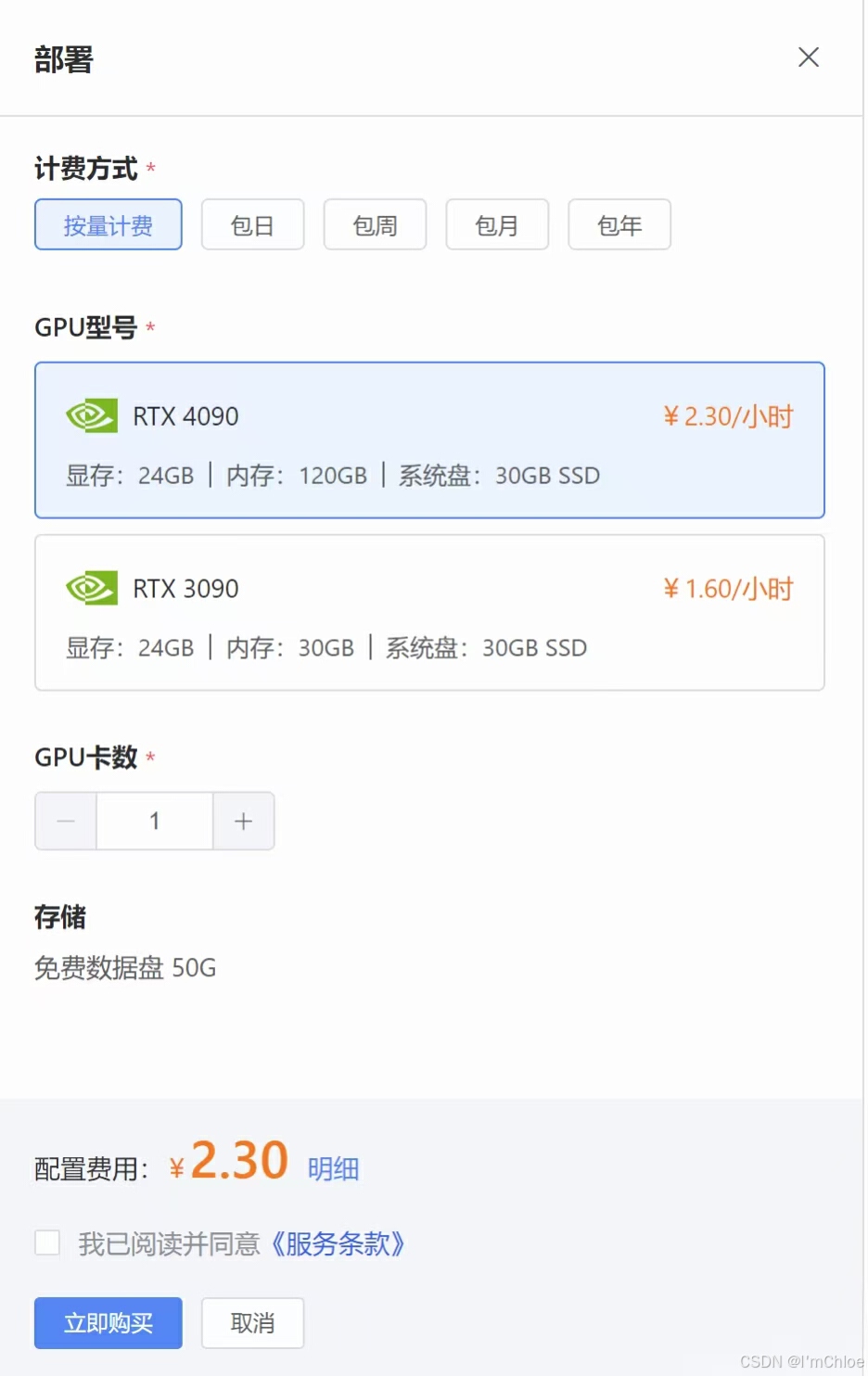
点击右上角的部署按钮,弹出配置表格。
选择按量付费的方式,根据实际使用情况付费,更加灵活经济。
GPU 的型号选择 RTX 4090 ,显存为 24GB ,内存为 120GB ,系统盘为 30GB SSD。如果是一般需求,GPU 卡数选择 1 即可;如果有大规模需求,可以根据实际情况增加显卡数量。
点击购买,完成模型部署的配置。如果弹出提示,直接点击确定即可,然后会跳转到调用界面。
5.4 使用模型
等待几分钟,模型创建完成后,点击快速启动应用,进入 DeepSeek R1 模型的使用可视化界面。
输入默认账号:[email protected] ,密码:lanyunuser 进行登录操作。
登录后,即可使用 DeepSeek R1 大模型。下面我们进行一些与机器学习相关的测试:
测试一:生成机器学习算法代码
询问:请帮我写出支持向量机(SVM)算法的 Python 代码以及详细的注释。
DeepSeek 思考过程:用户需要支持向量机算法的 Python 代码和注释。SVM 是一种常用的监督学习算法,可用于分类和回归问题。核心思想是找到一个超平面,将不同类别的数据点尽可能分开。我要先导入必要的库,定义数据结构,然后实现 SVM 算法的核心逻辑,包括数据预处理、模型训练和预测等步骤。在注释中详细说明每一步的作用,帮助用户理解算法原理。
以下是生成的代码:
pythonimport numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建SVM分类器
clf = SVC(kernel='linear') # 使用线性核函数
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
评论记录:
回复评论: