
一、搜索二维矩阵
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。
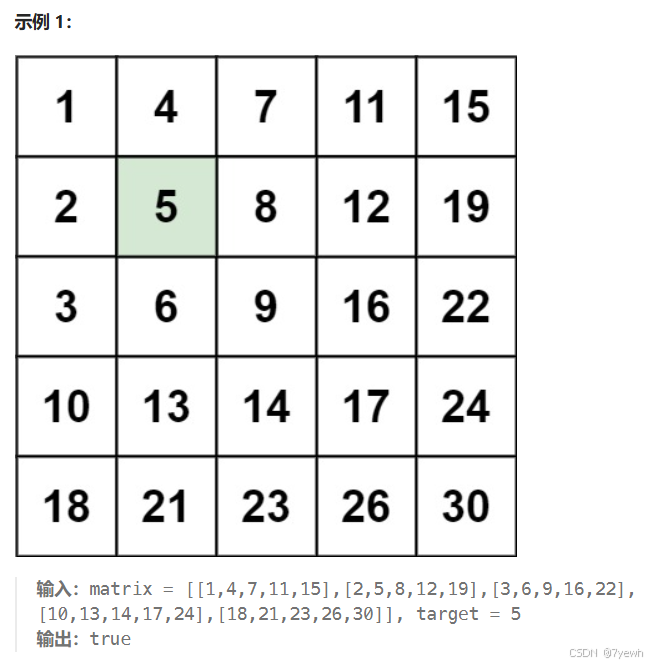
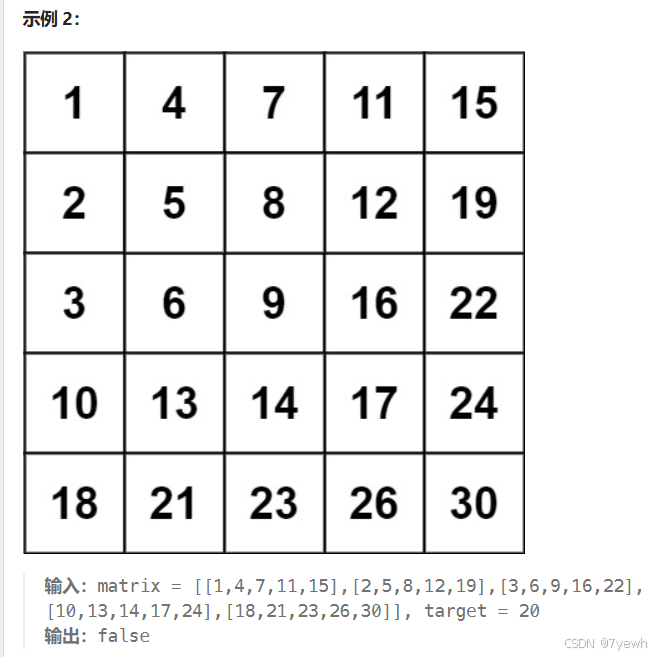
可以使用 从右上角开始搜索 的方法来有效地找到目标值。
- 选择起始位置: 从矩阵的右上角开始。假设我们当前的位置是
matrix[0][n-1],其中n是列数。 - 逐步搜索:
- 如果当前元素等于目标值,返回
true。 - 如果当前元素大于目标值,说明目标值可能出现在当前元素的左边,因此我们向左移动一列。
- 如果当前元素小于目标值,说明目标值可能出现在当前元素的下方,因此我们向下移动一行。
- 如果当前元素等于目标值,返回
- 结束条件: 如果超出了矩阵的边界,说明没有找到目标值,返回
false。
- class Solution {
- public:
- bool searchMatrix(vector
int >>& matrix, int target) { - if (matrix.empty() || matrix[0].empty()) return false;
-
- int m = matrix.size(); // 行数
- int n = matrix[0].size(); // 列数
-
- // 从右上角开始
- int row = 0;
- int col = n - 1;
-
- while (row < m && col >= 0) {
- if (matrix[row][col] == target) {
- return true; // 找到目标值
- } else if (matrix[row][col] > target) {
- col--; // 当前元素大于目标值,向左移动
- } else {
- row++; // 当前元素小于目标值,向下移动
- }
- }
-
- return false; // 没有找到目标值
- }
- };
- 初始位置:从矩阵的右上角
matrix[0][n-1]开始。 - 移动规则:
- 如果当前元素等于目标值,则返回
true。 - 如果当前元素大于目标值,则移动到左边一列。
- 如果当前元素小于目标值,则移动到下方一行。
- 如果当前元素等于目标值,则返回
- 边界条件:当行数或列数超出范围时,结束搜索。
二、岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。

-
DFS 遍历:从每个尚未访问的陆地单元格开始,使用 DFS 遍历其所有相邻的陆地单元格,将它们标记为已访问。每次发现一个新的未被访问的陆地,就说明发现了一个新的岛屿。
-
标记访问:为了避免重复计算同一个岛屿,需要在遍历过程中将已经访问过的陆地标记为水('0'),这样就不会再次访问到它。
-
岛屿计数:每当我们从一个未访问的陆地开始 DFS 时,岛屿数加一。
- 对于每一个格子,如果它是陆地 ('1') 且未被访问,则从该格子开始进行 DFS,将与之相连的所有陆地格子标记为已访问,并将岛屿数量加一。
- 遍历所有格子,最终得到岛屿的数量。
- 对于一个陆地格子('1'),递归地向上下左右四个方向扩展,找到与它相连的所有陆地并将其标记为水('0')。
- 这样做的目的是确保每个岛屿的陆地只被计数一次。
- class Solution {
- public:
- void dfs(vector
char >>& grid, int i, int j) { - // 边界条件:如果当前格子越界或已经是水('0'),则返回
- if (i < 0 || i >= grid.size() || j < 0 || j >= grid[0].size() || grid[i][j] == '0') {
- return;
- }
-
- // 将当前陆地格子标记为水,表示已访问
- grid[i][j] = '0';
-
- // 递归四个方向
- dfs(grid, i + 1, j); // 向下
- dfs(grid, i - 1, j); // 向上
- dfs(grid, i, j + 1); // 向右
- dfs(grid, i, j - 1); // 向左
- }
-
- int numIslands(vector
char >>& grid) { - if (grid.empty()) return 0;
-
- int numIslands = 0;
-
- // 遍历整个网格
- for (int i = 0; i < grid.size(); ++i) {
- for (int j = 0; j < grid[0].size(); ++j) {
- // 找到一个未访问的陆地,启动 DFS
- if (grid[i][j] == '1') {
- numIslands++; // 发现新的岛屿
- dfs(grid, i, j); // 使用 DFS 标记整个岛屿
- }
- }
- }
-
- return numIslands;
- }
- };
-
DFS 函数:
dfs用来递归访问与当前格子相连的所有陆地格子,并将它们标记为水('0')。- 参数
i, j表示当前正在处理的格子坐标。 - 在函数内部,首先检查是否越界或是否已经是水('0'),如果是则直接返回。
- 然后标记当前格子为水,并递归检查四个方向(上下左右)。
- 参数
-
主函数:
numIslands遍历整个二维网格,发现每个未访问的陆地时,调用dfs来标记所有相连的陆地,从而确保每个岛屿只计算一次。 -
边界条件:如果网格为空,直接返回
0。
三、腐烂的橙子
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
- 值
0代表空单元格; - 值
1代表新鲜橘子; - 值
2代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1 。

- class Solution {
- public:
- int orangesRotting(vector
int >>& grid) { - int m = grid.size();
- int n = grid[0].size();
-
- // 记录腐烂的橘子的位置
- queue
int, int>> rotten; - int freshCount = 0; // 记录新鲜橘子的数量
-
- // 初始化队列和新鲜橘子数量
- for (int i = 0; i < m; ++i) {
- for (int j = 0; j < n; ++j) {
- if (grid[i][j] == 2) {
- rotten.push({i, j});
- } else if (grid[i][j] == 1) {
- freshCount++;
- }
- }
- }
-
- // 如果没有新鲜橘子,直接返回 0
- if (freshCount == 0) return 0;
-
- // 四个方向
- vector
int, int>> directions = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}}; -
- int minutes = 0;
-
- // 开始 BFS
- while (!rotten.empty()) {
- int size = rotten.size();
- bool rottedThisRound = false; // 记录这一轮是否有橘子腐烂
-
- for (int i = 0; i < size; ++i) {
- auto [x, y] = rotten.front();
- rotten.pop();
-
- // 四个方向扩展
- for (auto& dir : directions) {
- int nx = x + dir.first;
- int ny = y + dir.second;
-
- // 如果新位置在网格内且是新鲜橘子
- if (nx >= 0 && nx < m && ny >= 0 && ny < n && grid[nx][ny] == 1) {
- grid[nx][ny] = 2; // 将新鲜橘子腐烂
- rotten.push({nx, ny}); // 加入队列
- freshCount--; // 减少新鲜橘子的数量
- rottedThisRound = true;
- }
- }
- }
-
- // 如果这一轮有橘子腐烂,时间增加
- if (rottedThisRound) {
- minutes++;
- }
- }
-
- // 如果还有新鲜橘子,返回 -1
- return freshCount == 0 ? minutes : -1;
- }
- };
- 初始化:
- 我们先遍历网格,找到所有腐烂的橘子,并将其加入队列。同时,我们统计新鲜橘子的数量。
- BFS 过程:
- 我们从腐烂的橘子开始,逐层扩展,检查每个腐烂橘子周围的四个方向。
- 如果发现相邻位置是新鲜橘子(值为
1),我们就把它变成腐烂的橘子(值改为2),并将其加入队列,继续扩展。 - 每次扩展都意味着时间增加一分钟。
- 结束条件:
- 如果在 BFS 完成后还有新鲜橘子(
freshCount > 0),说明不能完全腐烂所有橘子,返回-1。 - 否则,返回所需的分钟数。
- 如果在 BFS 完成后还有新鲜橘子(
四、课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。

- class Solution {
- public:
- bool canFinish(int numCourses, vector
int >>& prerequisites) { - vector<int> indegree(numCourses, 0); // 记录每个课程的入度
- vector
int>> graph(numCourses); // 邻接表表示图 -
- // 构建图和入度数组
- for (const auto& prereq : prerequisites) {
- int course = prereq[0]; // 需要学习的课程
- int pre = prereq[1]; // 先修课程
- graph[pre].push_back(course); // 将 course 加入 pre 的邻接表
- indegree[course]++; // course 的入度加 1
- }
-
- // 使用队列存储入度为 0 的课程
- queue<int> q;
- for (int i = 0; i < numCourses; ++i) {
- if (indegree[i] == 0) {
- q.push(i); // 将入度为 0 的课程加入队列
- }
- }
-
- int count = 0; // 记录已修课程的数量
- while (!q.empty()) {
- int course = q.front();
- q.pop();
- count++;
-
- // 对当前课程的所有后续课程(即它的邻接课程)进行处理
- for (int nextCourse : graph[course]) {
- indegree[nextCourse]--; // 当前课程修完,减去下一个课程的入度
- if (indegree[nextCourse] == 0) {
- q.push(nextCourse); // 如果下一个课程的入度为 0,加入队列
- }
- }
- }
-
- // 如果修完的课程数量等于总课程数,则可以完成所有课程
- return count == numCourses;
- }
- };
- 构建图和入度数组:
- 我们首先创建一个
graph数组来存储图的邻接表,并创建一个indegree数组来记录每个课程的入度(即每个课程有多少先修课程)。 - 然后,我们根据
prerequisites数组来构建图,并更新每个课程的入度。
- 我们首先创建一个
- 拓扑排序:
- 我们初始化一个队列
q,将所有入度为 0 的课程加入队列。 - 逐个从队列中取出课程,修完后,将它的邻接课程的入度减 1。如果某个邻接课程的入度变为 0,则将它加入队列。
- 我们初始化一个队列
- 判断是否完成所有课程:
- 最后,我们检查已修的课程数量
count是否等于总课程数numCourses。如果相等,说明没有环路,返回true;否则,返回false。
- 最后,我们检查已修的课程数量
五、实现 Trie (前缀树)
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。

- class Trie {
- private:
- struct TrieNode {
- unordered_map<char, TrieNode*> children;
- bool isWord;
-
- TrieNode() : isWord(false) {}
- };
-
- TrieNode* root;
-
- public:
- // 构造函数,初始化 Trie 树
- Trie() {
- root = new TrieNode();
- }
-
- // 向 Trie 插入一个字符串
- void insert(string word) {
- TrieNode* node = root;
- for (char c : word) {
- // 如果当前字符的子节点不存在,则创建一个新的节点
- if (node->children.find(c) == node->children.end()) {
- node->children[c] = new TrieNode();
- }
- node = node->children[c];
- }
- // 标记字符串结束的节点
- node->isWord = true;
- }
-
- // 查找字符串是否存在于 Trie 中
- bool search(string word) {
- TrieNode* node = root;
- for (char c : word) {
- if (node->children.find(c) == node->children.end()) {
- return false; // 如果有字符没有找到对应节点,返回 false
- }
- node = node->children[c];
- }
- // 如果到达字符串结尾并且是一个完整的单词,返回 true
- return node->isWord;
- }
-
- // 检查是否有任何单词以 prefix 为前缀
- bool startsWith(string prefix) {
- TrieNode* node = root;
- for (char c : prefix) {
- if (node->children.find(c) == node->children.end()) {
- return false; // 如果有字符没有找到对应节点,返回 false
- }
- node = node->children[c];
- }
- // 如果遍历完整个前缀,说明 Trie 中有以 prefix 为前缀的单词
- return true;
- }
- };
-
- /**
- * Your Trie object will be instantiated and called as such:
- * Trie* obj = new Trie();
- * obj->insert(word);
- * bool param_2 = obj->search(word);
- * bool param_3 = obj->startsWith(prefix);
- */
-
TrieNode 结构体:每个
TrieNode代表一个树节点,包含:children:一个哈希表,键是字符,值是指向子节点的指针。这个哈希表用于存储当前节点的所有子节点。isWord:一个布尔值,标记当前节点是否为一个单词的结束。
-
Trie 构造函数:创建一个空的根节点
root。 -
insert(word):
- 从根节点开始,逐个字符遍历
word。 - 如果某个字符的子节点不存在,则创建一个新的子节点。
- 最后,将最后一个字符的
isWord标记为true,表示这是一个完整的单词。
- 从根节点开始,逐个字符遍历
-
search(word):
- 从根节点开始,逐个字符遍历
word。 - 如果在任何字符位置找不到对应的子节点,则返回
false。 - 如果遍历结束并且当前节点的
isWord为true,说明找到了该单词,返回true。
- 从根节点开始,逐个字符遍历
-
startsWith(prefix):
- 从根节点开始,逐个字符遍历
prefix。 - 如果在某个字符位置找不到对应的子节点,则返回
false。 - 如果能够遍历完前缀的所有字符,说明存在以该前缀为开始的单词,返回
true。
- 从根节点开始,逐个字符遍历

 微信名片
微信名片

评论记录:
回复评论: