
作为一名工作接近5年的PNC算法攻城狮,由于一致在做传统算法,对模型训练一直没有深入了解,随着最近大模型的兴起,各大头部公司都在布局自动驾驶大模型的开发,深感前途渺茫,是时候学习一下大模型的基本原理了,就从这篇transformer开始吧。
以下是原文,强推大家去看原文,英文水平有限,翻译不对的地方请大佬指出!
https://jalammar.github.io/illustrated-transformer/jalammar.github.io/illustrated-transformer/
概览
把transformer看成一个黑盒,以翻译文本为例,一个输入经过黑盒转换成特定的期望。

打开黑盒,里面是一个encoders 和 decoders
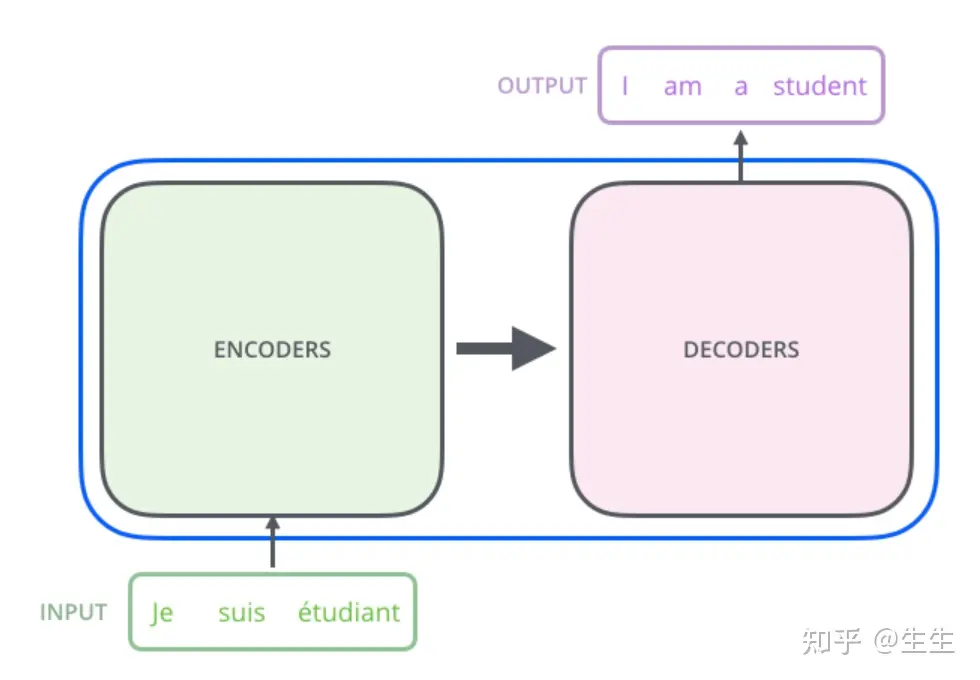
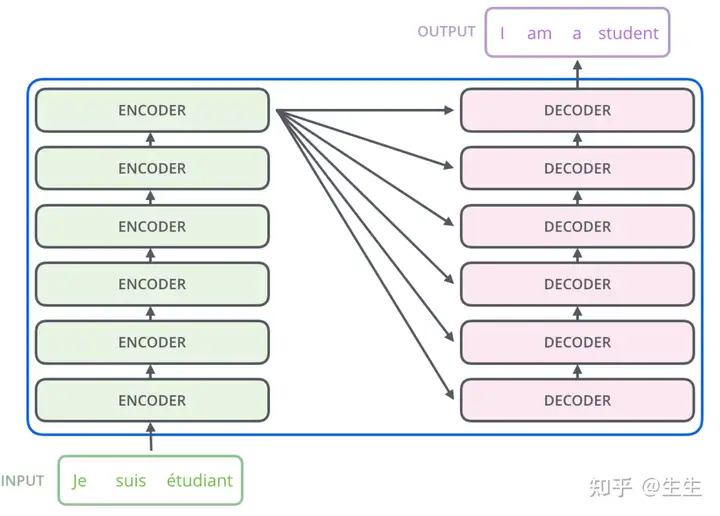
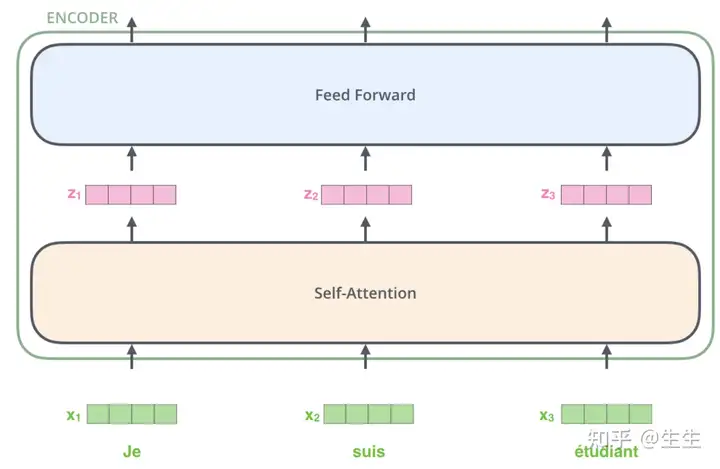
encoders是由多个encoder组成,decoders由多个decode组成,论文中是6个,如下图
encoder由两部分组成,self_attention 和 feed forward neural network
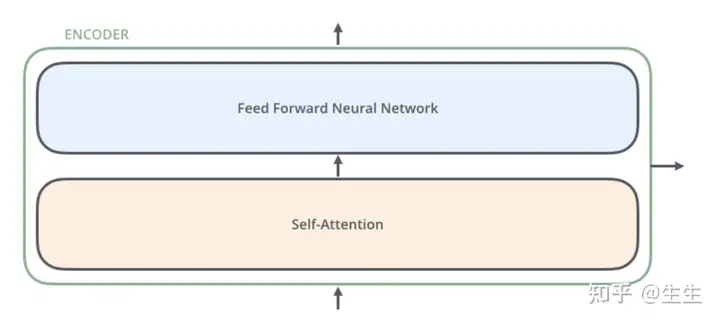
编码器的输入首先流经自注意力层——该层可帮助编码器在编码特定单词时查看输入句子中的其他单词。我们将在后面的文章中更详细地介绍自注意力。
自注意力层的输出被馈送到前馈神经网络。完全相同的前馈网络独立应用于每个位置。
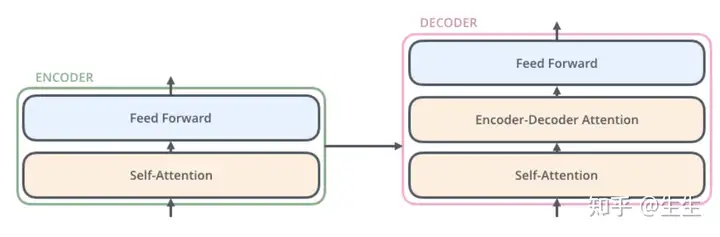
解码器也具有这两个层,但它们之间加了一个注意力层,可帮助解码器关注输入句子的相关部分(类似于注意力在 seq2seq 模型中的作用)。
引入张量
张量是通用的多维数组,它可以包含标量、向量、矩阵甚至更高维度的数据 。
1. 张量的定义
张量是多维数组的泛化,具体来说:
- 标量(Scalar) 是零维张量,如一个数值 5。
- 向量(Vector) 是一维张量,如 [1, 2, 3]。
- 矩阵(Matrix) 是二维张量,如 [[1, 2], [3, 4]]。
- 高维张量 是三维及以上的张量,如 [[[1], [2]], [[3], [4]]]。
2. 张量的属性
每个张量都有以下几个主要属性:
- 维度(Rank):张量的维度数,即轴的数量。
- 形状(Shape):张量在每个维度上的大小。例如,一个形状为 (3, 4) 的张量是一个 3x4 的矩阵。
- 数据类型(Data Type):张量中元素的数据类型,如 float32, int32 等。
3. 张量的操作
张量支持多种操作,包括但不限于:
- 数学运算:加法、减法、乘法、除法等。
- 线性代数操作:矩阵乘法、矩阵转置等。
- 张量变形:重塑(reshape)、展平(flatten)等。
- 切片和索引:提取子张量。
4. 深度学习中的张量
在深度学习中,张量是用于表示和处理数据的主要数据结构。以下是一些常见的应用:
- 输入数据:图像、文本、音频等输入数据通常表示为张量。例如,彩色图像可以表示为一个形状为 (height, width, channels) 的三维张量。
- 权重和偏置:神经网络的权重和偏置通常也是张量。
- 中间计算结果:前向传播和反向传播过程中,各层之间的中间结果也是张量。
5. 张量库
有许多深度学习库和框架提供了对张量的支持和操作,包括:
- TensorFlow:一个用于大规模机器学习的开源框架,由谷歌开发。它的名字就来源于“张量流”。
- PyTorch:一个流行的深度学习框架,由 Facebook 开发,广泛用于研究和生产中。
- NumPy:尽管主要是一个科学计算库,但它也提供了多维数组(即张量)支持,是许多深度学习库的基础。
现在我们已经了解了模型的主要组成部分,让我们开始研究各种向量/张量,以及它们如何在这些组件之间流动,从而将经过训练的模型的输入转化为输出。
与一般 NLP 应用中的情况一样,我们首先使用嵌入算法将每个输入词转化为向量。

嵌入仅发生在最底层的编码器中。所有编码器的共同抽象是它们接收一个向量列表,每个向量的大小为 512 – 在底层编码器中,这将是单词嵌入,但在其他编码器中,它将是直接位于下方的编码器的输出。此列表的大小是我们可以设置的超参数 – 基本上它将是我们训练数据集中最长句子的长度。
将单词嵌入到我们的输入序列中后,每个单词都会流经编码器的两层中的每一层。
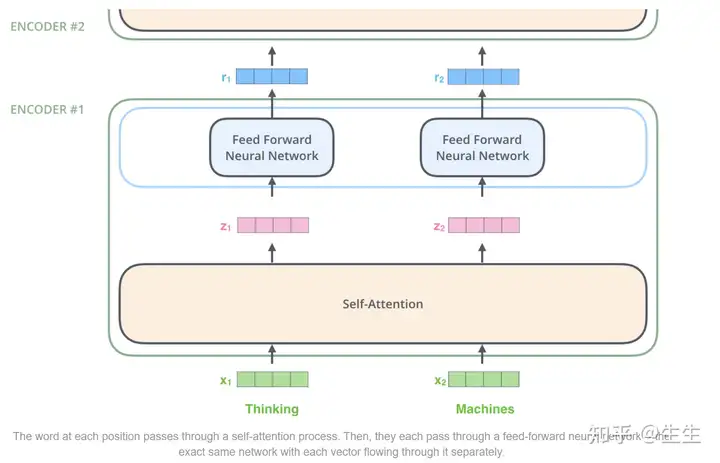
在这里,我们开始看到 Transformer 的一个关键属性,即每个位置上的单词在编码器中都流经自己的路径。在自注意力层中,这些路径之间存在依赖关系。然而,前馈层没有这些依赖关系,因此在流经前馈层时,各种路径可以并行执行。
接下来,我们将示例切换为较短的句子,并查看编码器的每个子层中发生的情况。
Encodeing
正如我们已经提到的,编码器接收一个向量作为输入。它通过将这些向量传递到“自我注意”层,然后传递到前馈神经网络,然后将输出向上发送到下一个编码器。
Self -Attention 直观理解
不要被我随意使用“自注意力”这个词所欺骗,好像这是一个每个人都应该熟悉的概念。我个人在阅读《注意力就是你所需要的一切》这篇论文之前从未接触过这个概念。让我们提炼一下它的工作原理。
假设以下句子是我们要翻译的输入句子:
“动物没有过马路,因为它太累了”这句话中的“它”指的是什么?它是指街道还是动物?这对人类来说是一个简单的问题,但对算法来说却不那么简单, 当模型处理单词“它”时,自注意力允许它将“它”与“动物”联系起来。
当模型处理每个单词(输入序列中的每个位置)时,自注意力允许它查看输入序列中的其他位置以寻找有助于更好地编码该单词的线索。
如果您熟悉 RNN,请考虑如何通过保持隐藏状态让 RNN 将其已处理的先前单词/向量的表示与当前正在处理的单词/向量结合起来。自注意力是 Transformer 用于将对其他相关单词的“理解”融入我们当前正在处理的单词的方法。
Self -Attention in Detail
让我们首先看看如何使用向量计算自注意力,然后再看看它是如何实际实现的——使用矩阵。
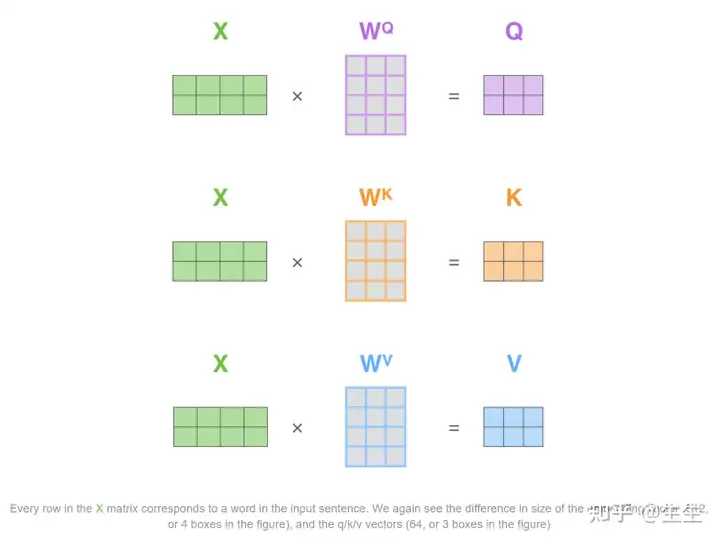
计算自注意力的第一步是从每个编码器的输入向量(在本例中是每个单词的嵌入)创建三个向量。因此,对于每个单词,我们创建一个查询向量、一个键向量和一个值向量。这些向量是通过乘以我们在训练过程中训练的三个矩阵而创建的。
请注意,这些新向量的维度小于输入(embedding)向量。它们的维数为 64,而嵌入和编码器输入/输出向量的维数为 512。它们不必更小,这是一种架构选择,可以使多头注意力的计算(大部分)保持恒定。
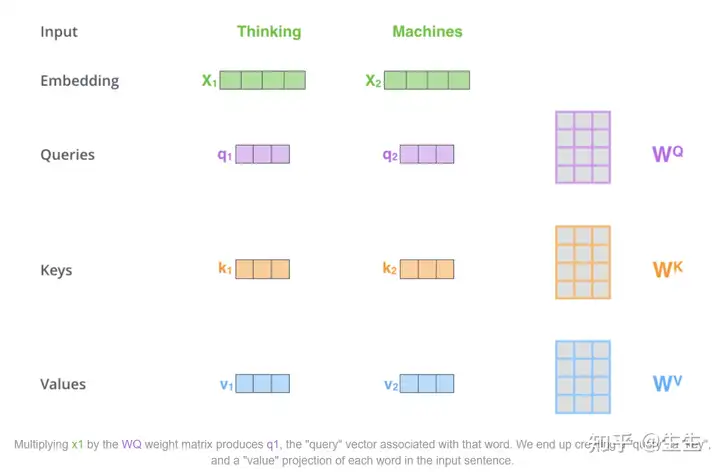
什么是“查询”、“键”和“值”向量?
它们是用于计算和思考注意力的抽象概念。继续阅读下面的注意力计算方法,您将了解每个向量所起的作用。
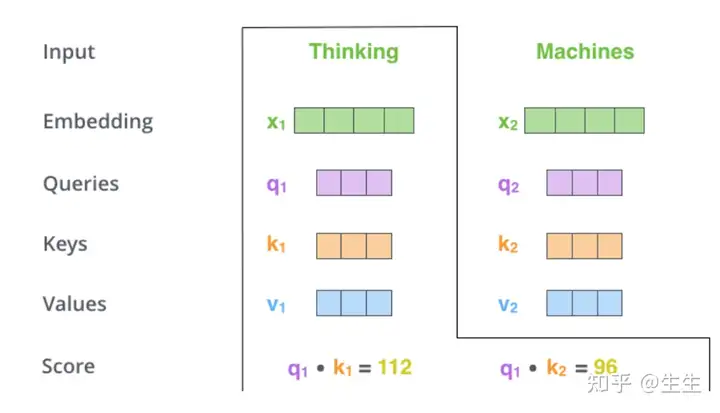
计算自我注意力的第二步是计算分数。假设我们正在计算此示例中第一个单词“Thinking”的自我注意力。我们需要根据这个词对输入句子的每个单词进行评分。分数决定了在某个位置对单词进行编码时对输入句子其他部分的关注程度。
分数是通过对查询向量与我们正在评分的相应单词的键向量进行点积来计算的。因此,如果我们正在处理位置 #1 中的单词的自我注意力,则第一个分数将是 q1 和 k1 的点积。第二个分数将是 q1A 和 k2 的点积。
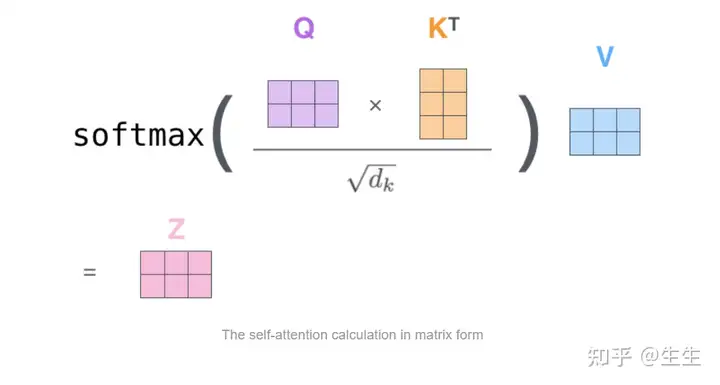
第三步和第四步是将分数除以 8(论文中使用的关键向量维度的平方根 - 64。这会导致更稳定的梯度。这里可能还有其他可能的值,但这是默认值),然后将结果传递给 softmax 运算。Softmax 对分数进行归一化,使它们都为正数并加起来为 1。
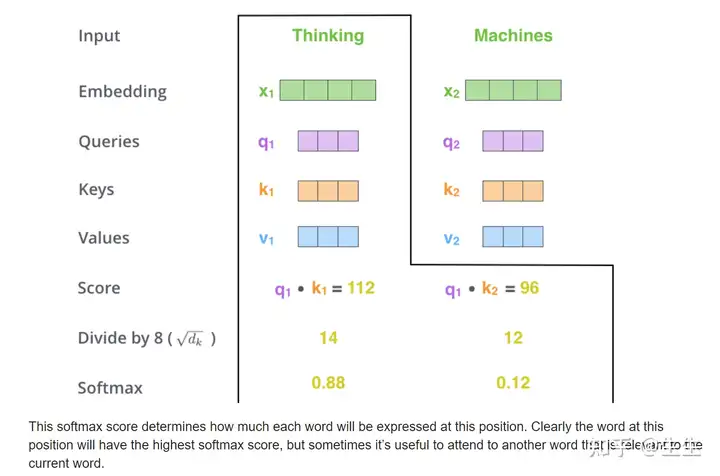
第五步是将每个值向量乘以 softmax 分数(准备将它们相加)。这里的直观理解是保持我们想要关注的单词的值不变,并淹没不相关的单词(例如,将它们乘以 0.001 等小数字)。
第六步是将加权值向量相加。这会在此位置(对于第一个单词)产生自注意力层的输出。
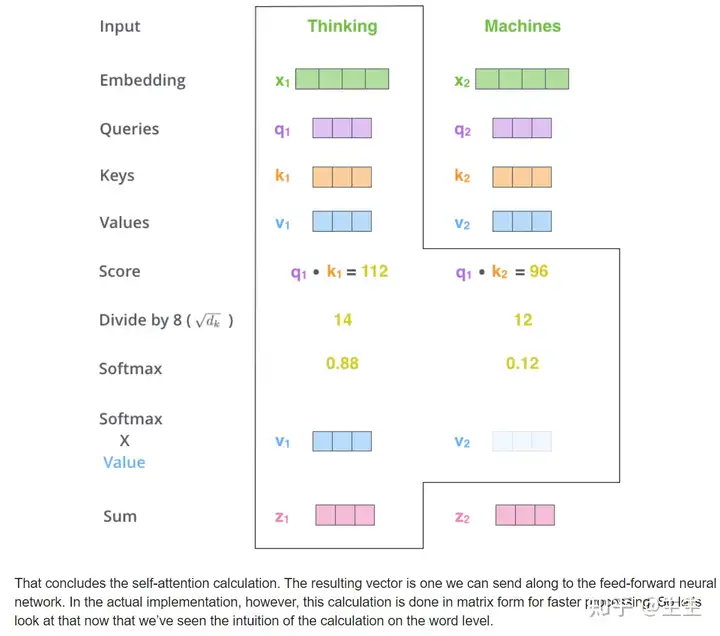
这就是自注意力计算的结论。我们可以将得到的向量发送到前馈神经网络。然而,在实际实现中,为了加快处理速度,这个计算是以矩阵形式进行的。既然我们已经了解了单词级计算的直观原理,那么现在让我们来看一下。
第一步:使用矩阵的形式,计算得到Q, K, V
第二步,将前面的2-6步合成一步,用下面的公式计算输出
Multi Heads
论文通过添加一种称为“多头”注意力机制进一步完善了自注意力层。这从两个方面提高了注意力层的性能:
它扩展了模型关注不同位置的能力。是的,在上面的例子中,z1 包含了其他所有编码的一小部分,但它可能由实际单词本身主导。如果我们翻译“动物没有过马路,因为它太累了”这样的句子,知道“它”指的是哪个词会很有用。
它为注意力层提供了多个“表示子空间”。正如我们接下来将看到的,有了多头注意力,我们不仅拥有一组,而且拥有多组查询/键/值权重矩阵(Transformer 使用八个注意力头,因此我们最终为每个编码器/解码器设置了八组)。这些集合中的每一个都是随机初始化的。然后,在训练之后,每个集合都用于将输入嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
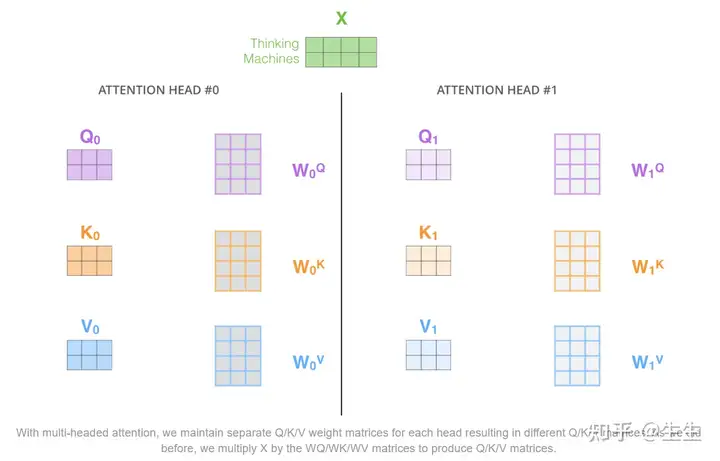
按照上面介绍的公式计算,可以得到8个不同的输出
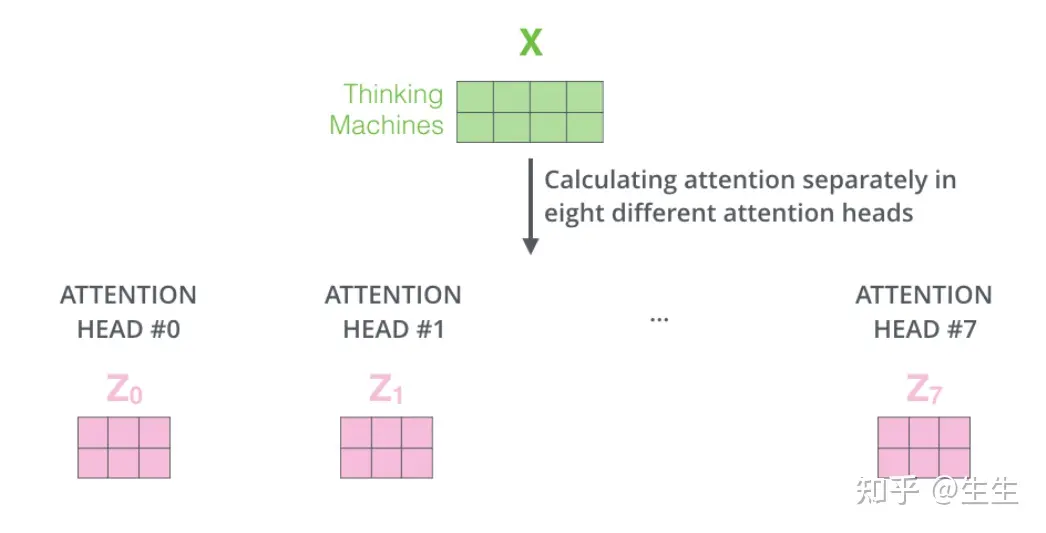
这给我们带来了一些挑战。前馈层并不期望八个矩阵——它期望一个矩阵(每个单词一个向量)。所以我们需要一种方法将这八个矩阵压缩成一个矩阵。
我们怎么做呢?我们将矩阵连接起来,然后将它们乘以额外的权重矩阵 WO。
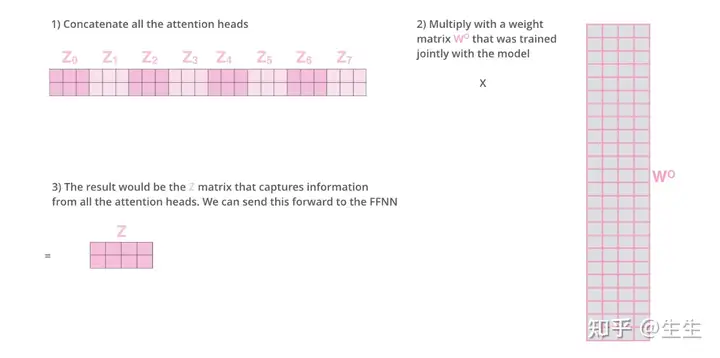
以上就是多头注意力机制的计算过程,现在做一个总结, 里面由四个关键矩阵,W_Q, W_K, W_V, W_O,模型训练就是训练这些矩阵内的值。
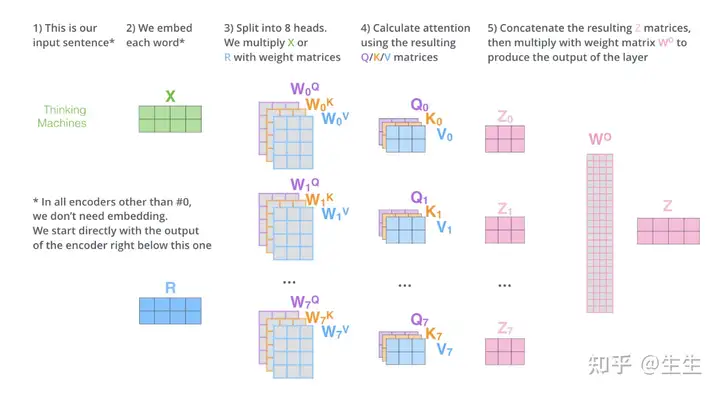
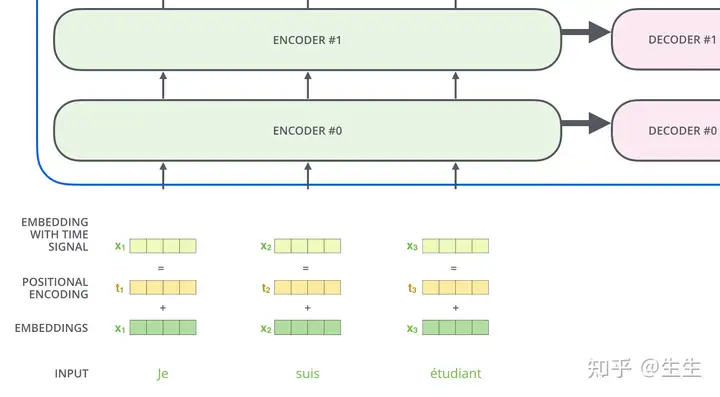
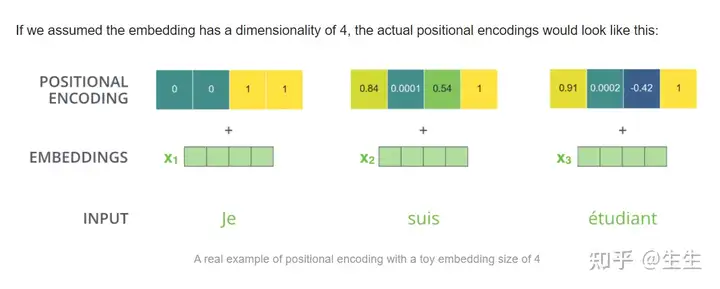
Position Embedding
到目前为止,我们所描述的模型中缺少的一件事是解释输入序列中单词顺序的方法。
为了解决这个问题,Transformer 为每个输入嵌入添加了一个向量。这些向量遵循模型学习的特定模式,这有助于它确定每个单词的位置或序列中不同单词之间的距离。这里的直觉是,将这些值添加到嵌入中,一旦它们被投影到 Q/K/V 向量中并在点积注意期间,就可以在嵌入向量之间提供有意义的距离。
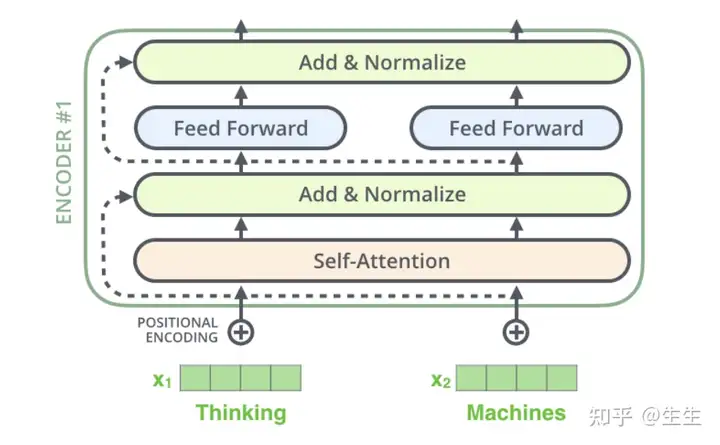
残差
在继续之前我们需要提及编码器架构中的一个细节,即每个编码器中的每个子层(SelfAttention,FFNN)周围都有一个残差连接,跟着一个layer-normalization步骤。
具体展开如下:
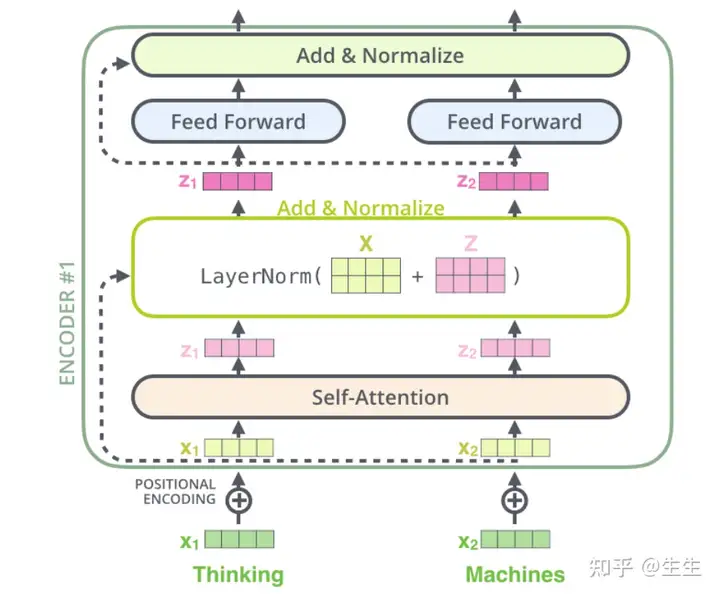
在decoder层也由这样的结构,考虑两层的transformer, 显示如下:
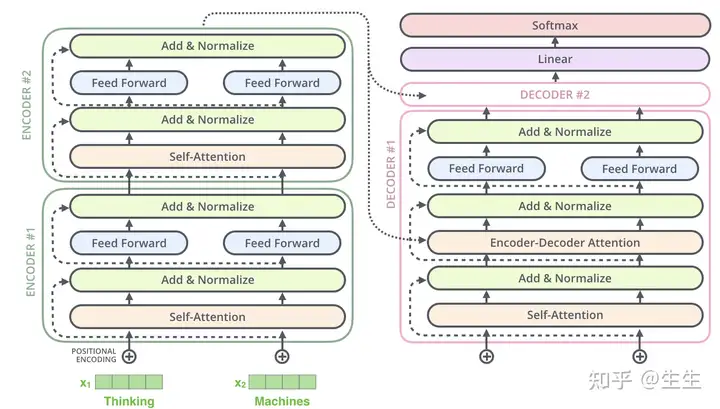
Decoder
编码器首先处理输入序列。然后,顶部编码器的输出被转换为一组注意向量 K 和 V。每个解码器将在其“编码器-解码器注意”层中使用它们,这有助于解码器将注意力集中在输入序列中的适当位置:
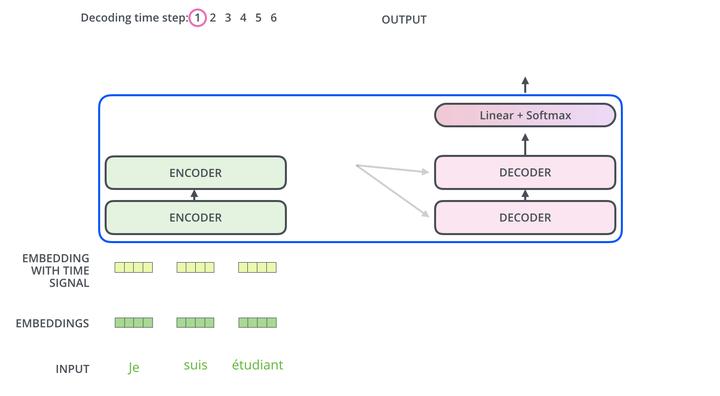
以下步骤重复该过程,直到出现一个特殊符号,表示 Transformer 解码器已完成输出。每个步骤的输出都会在下一个时间步骤中送到底部解码器,解码器会像编码器一样将其解码。就像我们对编码器输入所做的那样,我们在这些解码器输入中嵌入并添加位置编码,以指示每个单词的位置。
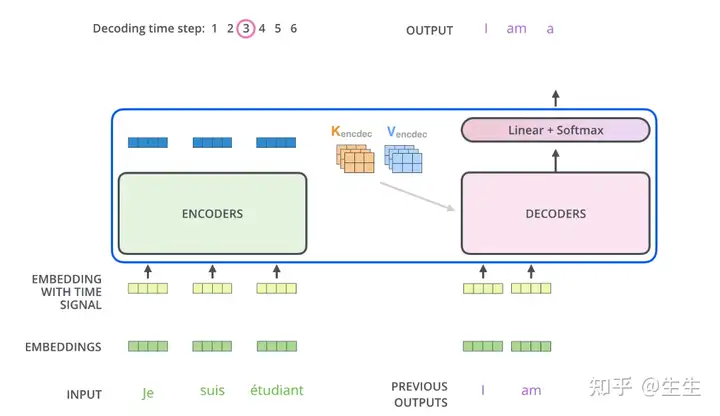
解码器中的自注意力层与编码器中的自注意力层的工作方式略有不同:
在解码器中,自注意力层仅允许关注输出序列中的较早位置。这是通过在自注意力计算 softmax 步骤之前屏蔽未来位置(将其设置为 -inf)来实现的。
“编码器-解码器注意力”层的工作原理与多头自注意力一样,只是它从其下方的层创建查询矩阵,并从编码器堆栈的输出中获取键和值矩阵。
最后输出
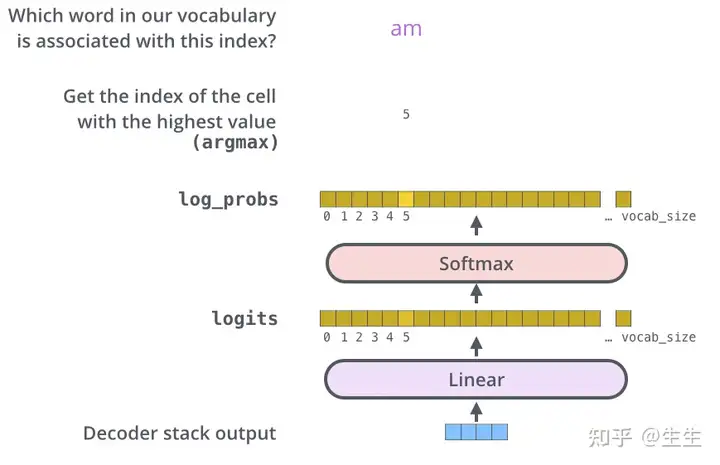
解码器堆栈输出一个浮点向量。我们如何将其转换为一个单词?这是最后一个线性层的工作,后面跟着一个 Softmax 层。
线性层是一个简单的全连接神经网络,它将解码器堆栈产生的向量投影到一个更大的向量中,称为 logits 向量。
假设我们的模型知道从训练数据集中学习到的 10,000 个独特的英语单词(我们模型的“输出词汇表”)。这将使 logits 向量有 10,000 个单元格宽 - 每个单元格对应一个独特单词的分数。
然后,softmax 层将这些分数转换为概率(所有都是正数,加起来都是 1.0)。选择概率最高的单元格,并生成与其相关的单词作为此时间步的输出。
训练过程
现在我们已经通过经过训练的 Transformer 介绍了整个前向传递过程,这对我们了解训练模型会很有用。
在训练期间,未经训练的模型将经历完全相同的前向传递。但由于我们在标记的训练数据集上对其进行训练,因此我们可以将其输出与实际正确的输出进行比较。
为了直观地展示这一点,我们假设我们的输出词汇表仅包含六个单词(“a”、“am”、“i”、“thanks”、“student”和“
一旦我们定义了输出词汇表,我们就可以使用相同宽度的向量来表示词汇表中的每个单词。这也称为独热编码。例如,我们可以使用以下向量表示单词“am”:

在回顾之后,让我们讨论一下模型的损失函数——我们在训练阶段优化的指标,以得到一个训练有素且希望非常准确的模型。
损失函数
假设我们正在训练模型。假设这是我们训练阶段的第一步,我们正在用一个简单的例子来训练它——将“merci”翻译成“thanks”。
这意味着,我们希望输出是一个表示“thanks”这个词的概率分布。但由于这个模型还没有经过训练,所以现在还不太可能实现。
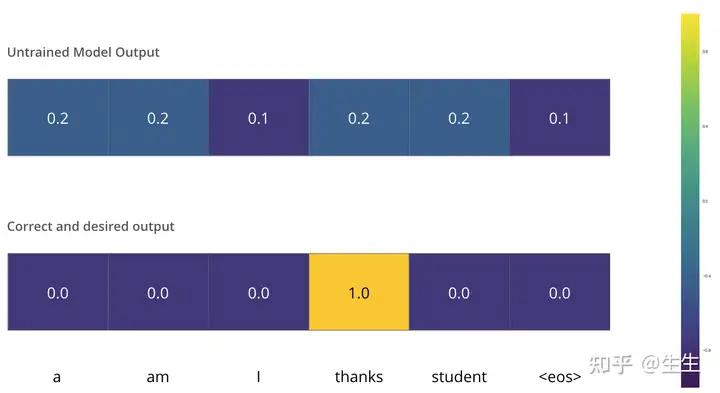
如何比较两个概率分布?我们只需将一个概率分布从另一个概率分布中减去即可。有关更多详细信息,请参阅交叉熵和 Kullback-Leibler 散度。
但请注意,这是一个过于简单的例子。更现实的是,我们将使用一个长度超过一个单词的句子。例如 - 输入:“je suis étudiant”和预期输出:“i am a student”。这实际上意味着,我们希望我们的模型连续输出概率分布,其中:
每个概率分布都由宽度为 vocab_size 的向量表示(在示例中为 6,但更现实的数字是 30,000 或 50,000)
- 一个概率分布在与单词“i”相关的单元格处具有最高概率
- 第二个概率分布在与单词“am”相关的单元格处具有最高概率
- 依此类推,直到第五个输出分布指示“<句子结束>”符号,该符号在 10,000 个元素词汇表中也有一个与之相关的单元格。
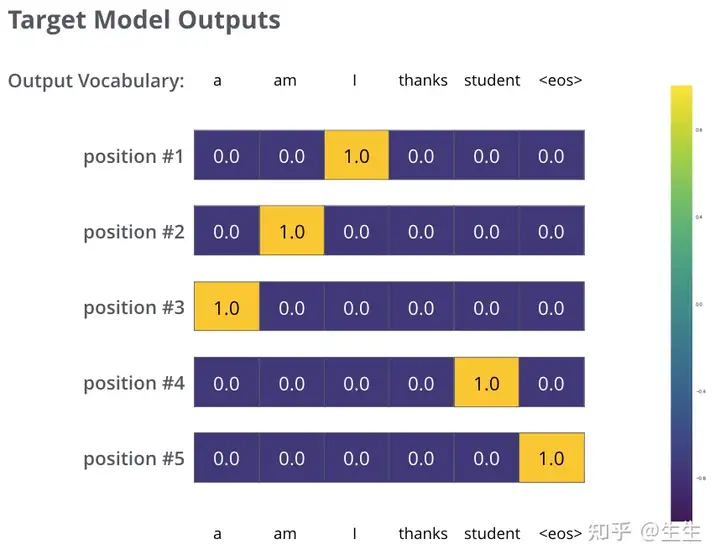
在足够大的数据集上对模型进行足够时间的训练后,我们希望产生的概率分布如下所示:
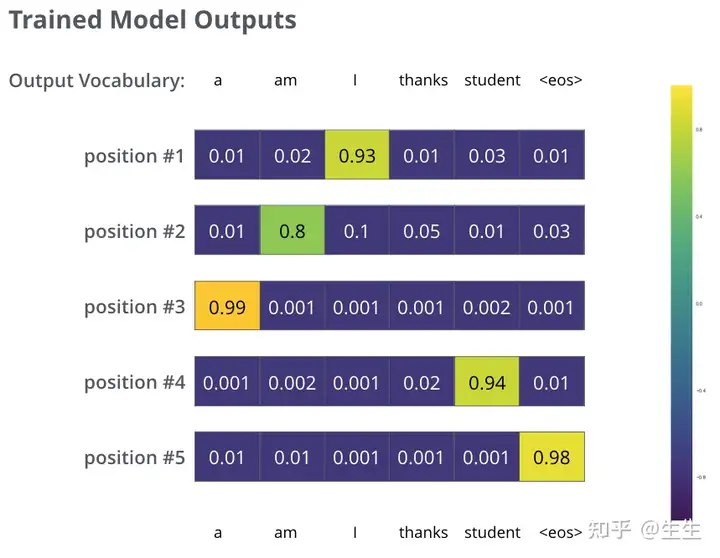
现在,由于模型每次只产生一个输出,我们可以假设模型从概率分布中选择概率最高的单词,并丢弃其余单词。这是一种方法(称为贪婪解码)。另一种方法是保留前两个单词(例如“I”和“a”),然后在下一步中运行模型两次:一次假设第一个输出位置是单词“I”,另一次假设第一个输出位置是单词“a”,并且保留考虑位置 #1 和 #2 时产生较少误差的版本。我们对位置 #2 和 #3 重复此操作……等等。这种方法称为“波束搜索”,在我们的示例中,beam_size 为 2(意味着在任何时候,内存中都保留两个部分假设(未完成的翻译)),top_beams 也是 2(意味着我们将返回两个翻译)。这些都是您可以尝试的超参数。
评论记录:
回复评论: