
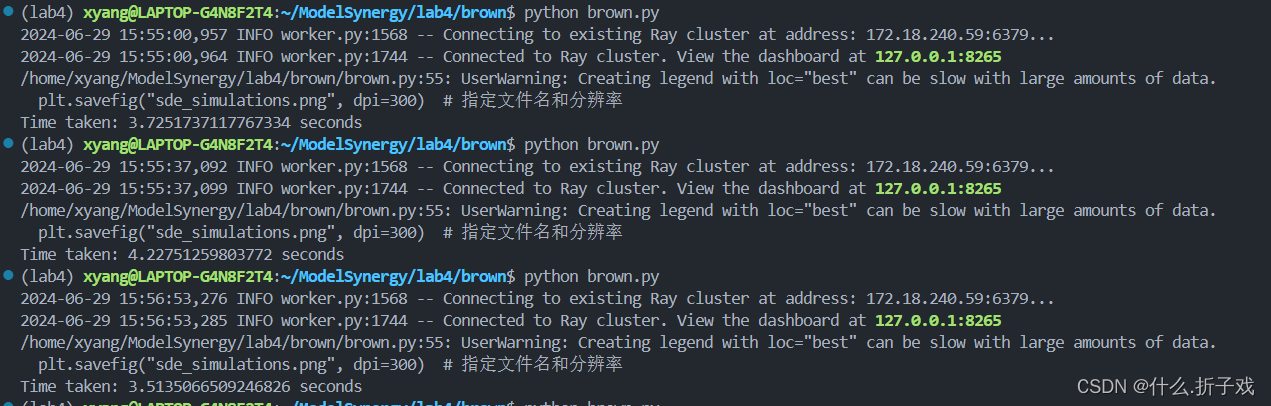
用RAY计算求解随机微分方程
随机微分方程与伊藤积分
- 随机微分方程是描述随机过程的微分方程,其形式通常为:
d X t = μ ( X t , t ) d t + σ ( X t , t ) d W t dX_t = \mu(X_t, t) dt + \sigma(X_t, t) dW_t dXt=μ(Xt,t)dt+σ(Xt,t)dWt
这里,
- X t X_t Xt 是随时间 t t t 变化的随机过程,
- μ ( X t , t ) \mu(X_t, t) μ(Xt,t) 是漂移系数,描述了确定性部分,
- σ ( X t , t ) \sigma(X_t, t) σ(Xt,t) 是扩散系数,描述了随机波动部分,
- W t W_t Wt 是维纳过程(或布朗运动),表示随机扰动。
SDE的解通常是一个随机过程,它可以用来描述系统在随机环境下的演化。
- 伊藤积分是为了处理随机微分方程中的随机扰动项 d W t dW_t dWt 而引入的。与传统的黎曼积分不同,伊藤积分处理的是非确定性的积分。
对于给定的适应过程 f ( t , ω ) f(t, \omega) f(t,ω),其关于维纳过程 W t W_t Wt 的伊藤积分定义为:
∫ 0 t f ( s , ω ) d W s \int_0^t f(s, \omega) dW_s ∫0tf(s,ω)dWs
具体任务
随机微分方程 (SDE) :
d
A
(
t
)
=
σ
A
(
t
)
d
W
t
dA(t) = \sigma \, A(t) \, dW_t
dA(t)=σA(t)dWt
通常被称为几何布朗运动 (Geometric Brownian Motion, GBM)。其中Wt是标准布朗运动
其可用于:
- 工程与控制系统
- 时间序列分析
- 强化学习
对于方程
d
A
(
t
)
=
σ
A
(
t
)
d
W
t
dA(t) = \sigma A(t) dW_t
dA(t)=σA(t)dWt,解的形式为:
A
(
t
)
=
A
(
0
)
exp
(
σ
W
t
−
1
2
σ
2
t
)
A(t) = A(0) \exp\left( \sigma W_t - \frac{1}{2} \sigma^2 t \right)
A(t)=A(0)exp(σWt−21σ2t)
其中
A
(
0
)
A(0)
A(0) 是初始值,
W
t
W_t
Wt 是标准布朗运动。
这种解法揭示了几何布朗运动中指数增长或衰减的性质.
利用RAY模拟求数值解
求解该随机微分方程,可以采用循环累加的方式,将
∫
0
T
σ
X
(
t
)
d
W
t
\int_0^T \sigma \, X(t) \, dW_t
∫0TσX(t)dWt
的T拆分为dt,本次实验中dt = 1 000 000
- 用
numpy.random.normal(0, numpy.sprt(dt))模拟布朗运动的正态增量,由其增量独立性,可并行的进行
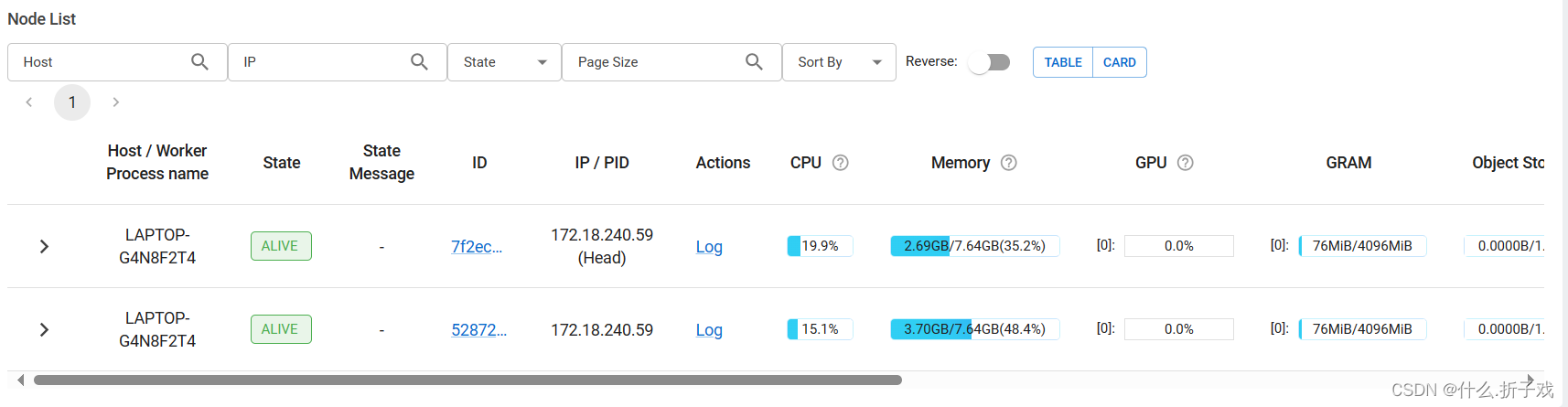
部署RAY
首先部署一个虚拟环境venv
python3 -m venv venv
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">








评论记录:
回复评论: