
摘要
区块链已广泛应用于农产品溯源、供应链管理、物流运输等各个领域。作为联盟区块链不可缺少的组成部分,共识算法保证了网络中每个节点的一致性和可信度。然而,由于通信过程的复杂性,现有的大规模联盟区块链场景中的共识算法存在低系统吞吐量和高延迟的问题,使得它们不适合实际使用。为了解决这些问题,本文提出了一种新的共识算法,称为基于信用评估的实际拜占庭容错(CE-PBFT)。该算法设计了一种考虑节点完成率、共识衰减和节点行为的节点信用评估模型。它能有效地衡量和反映系统运行过程中各节点的具体可靠性状态,从而提高系统的可靠性和安全性。此外,本文还介绍了创新地使用决策树算法来分析网络节点行为,并简化了现有的共识协议。根据分类结果将节点分为优秀、良好、普通和差,并动态选择非拜占庭节点。这大大提高了系统的整体效率。通过实验验证了CE-PBFT的性能,并与PBFT、G-PBFT、RBFT、WBFT和PPoR进行了比较。实验结果表明,在大规模联盟场景下,CE-PBFT显著提高了系统吞吐量,有效降低了事务延迟和通信开销,优于对比协议。
1. Introduction
区块链被归类为分布式账本技术的一种形式(Zhao et al., 2021),最初由比特币的创造者提出,用于支持比特币的去中心化数字货币体系。随着时间的推移,区块链技术逐渐发展并得到广泛应用,不仅仅是在加密货币领域。区块链的发展经历了几个阶段(Yang, 2019;Nuttah et al., 2023)。最初,区块链主要用于支持加密货币的交易和记账功能。比特币作为首个区块链应用,引领了加密货币的兴起和区块链技术的探索。随后,人们开始意识到区块链技术潜在的应用价值,并开始探索在其他领域的应用。如今,区块链已在许多领域得到应用(Rahman et al., 2021;Jindal et al., 2020;Song等人,2021),包括金融(Saba等人,2023)、供应链管理(Vangala等人,2021)和医疗保健(Myrzashova等人,2023)。
根据参与者的权限和可及性,区块链可分为公共区块链(Tian et al., 2019;Khor等人,2023),财团区块链(Bai等人,2022)和私人区块链(Wang等人,2023;Chen et al., 2022b)。财团区块链由一组已知和可信的节点组成,在一个或多个实体、组织或企业之间建立合作关系。它的作用是为参与者提供一个安全、高效和可信的环境,促进信息共享和交易的发展(Boateng et al., 2022)。联盟区块链具有多方参与、限制访问权限、高度隐私保护等特点。此外,它们在可跟踪性和可审计性方面具有优势,可以轻松跟踪事务起源和历史。通过选择合适的共识机制,联盟区块链可以为处理交易和数据提供更高的性能和可扩展性,满足组织或行业的特定需求。
由于它适合于多个组织之间的合作和数据共享,因此在许多领域显示出良好的应用前景。目前广泛应用于农业溯源(Misra et al., 2022)、供应链管理(Viriyasitavat et al., 2022)、物联网通信(Li and Shi, 2023)、物流运输(Li et al., 2020)等领域。以农业溯源领域为例,联盟区块链可以提供实时数据共享和协同机制,减少传统农业溯源中的信息不对称和繁琐程序。这反过来又提高了农产品可追溯性的效率,同时减少了劳动力和时间成本(Guan et al., 2023)。同时,财团区块链技术记录农产品从生产到消费的全过程,包括种植、加工、运输等环节。通过共享数据和智能合约,确保参与者共同验证和记录交易信息,提供可靠的数据,实现农产品的全过程可追溯,提高产品的可追溯性、透明度和可信度。
一些农产品企业和组织利用联合体区块链技术建立了可追溯平台,对农产品的生产、加工、运输等信息进行记录,并通过区块链技术保证数据的可信度。通过联盟区块链的可追溯系统,消费者可以获得农产品的真实信息和证明,增强对产品的信任感。通过扫描二维码,在区块链上查看交易记录,将农产品的追溯信息展示给消费者,从而提升产品的品牌价值和市场竞争力。图给出了区块链在可追溯领域的应用示意图。
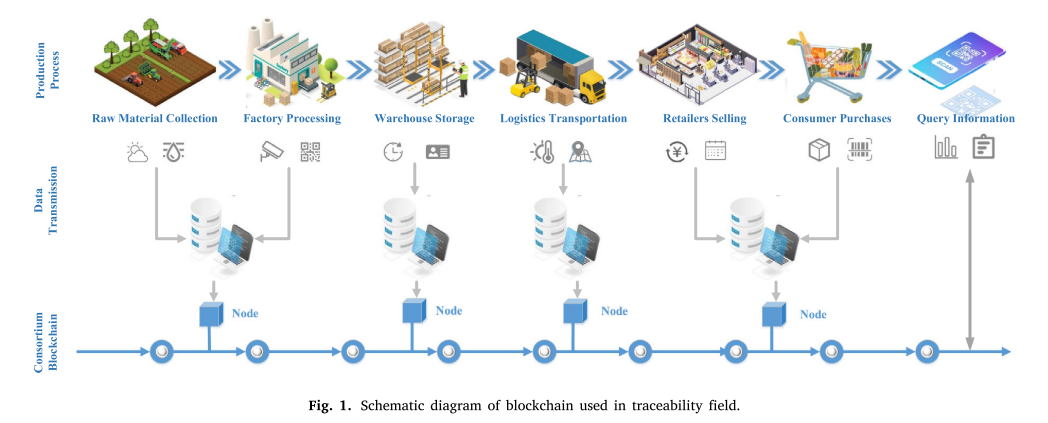
作为财团区块链网络的重要组成部分,共识算法通过协调网络中的各个节点,在确保区块链核心特征中交易和状态的一致性方面发挥着至关重要的作用(Kang et al., 2019)。然而,目前的共识算法普遍面临着一系列的局限性和挑战。
共识算法在处理大规模网络时可能会遇到性能瓶颈。随着节点数量的增加和网络规模的扩大,共识算法需要更多的计算和通信资源来实现共识,从而导致性能下降(Zhang et al., 2022)。与处理延迟和吞吐量相关的问题变得更加突出,影响事务处理的速度和效率。
此外,共识算法的安全性也是一个值得关注的问题(Sun et al., 2021)。恶意节点的存在可能会通过破坏共识一致性或操纵交易数据的破坏性行为对共识过程构成威胁。因此,共识算法需要具备抵御各种攻击、保护网络安全的机制。但是,某些共识算法在某些场景下可能安全性不足,导致数据被篡改等漏洞,从而影响整个系统的可信度和安全性。
面对这些限制和挑战,研究人员正在积极寻求解决方案。近年来,基于声誉值的共识算法逐渐成为研究热点。这些算法评估节点的信誉值,以确定其在共识过程中的权威和可信度。通过建立节点间的信任机制和相互信任关系,有效防止双花攻击、拜占庭攻击、51%攻击和Sybil攻击,确保共识的正确性、一致性和安全性。通过基于声誉的共识算法,联盟链可以增强交易的可靠性,防止数据篡改和恶意行为,增强整个系统的安全性和可信度。此外,它们有可能提高联盟区块链网络的性能和可扩展性,使它们能够适应不断增长的网络规模。
在此背景下,本文通过考虑节点完成率、共识参与水平和节点行为等因素,提出了一种新的共识算法CE-PBFT。该算法引入了一种新颖的节点信用评估系统,可以有效地评估系统运行过程中节点的可靠性。这种方法不仅提高了系统的可靠性,而且增强了系统的安全性。此外,该算法创新性地利用了ID3决策树算法,该算法具有可解释性强、对离散特征适应性强、处理缺失值、效率高等特点,分析了网络节点行为,简化了现有的共识协议。通过这种方法,将节点分为优秀、良好、普通和差,并根据这些分类动态选择非拜占庭节点,显著提高了系统的整体运行效率。
具体而言,本文的主要贡献如下:
(1)在本文中,提出了一种新的联盟区块链共识算法,称为基于信用评估的实用拜占庭容错(CE-PBFT)。该算法引入了新的节点信用评估模型,并利用ID3决策树算法对联盟区块链节点的行为进行分析,有效解决了大规模联盟区块链场景下的挑战。
(2)设计并实现了一种考虑节点完成率、共识衰减和节点行为指标的节点信用评价体系。该系统能够准确测量区块链系统运行中各节点的可信度和可靠性。创新之处在于,采用ID3决策树算法将节点分为优秀、良好、平均、差四类。在此基础上动态选择非拜占庭节点,大大提高了系统的安全性。
(3)进一步简化了共识协议,优化了协议内的通信开销,大幅提高了系统的整体性能。此外,对视图更改协议进行了改进,将主节点PN (Primary node)的选择限制在具有较高节点可信度的节点上,从而有效地保证了系统的可靠性。
(4)本文通过一系列实验对CE-PBFT的性能进行了实证验证。实验结果表明,与PBFT、G-PBFT、RBFT、WBFT和PPoR相比,CE-PBFT在大规模联盟场景下的系统吞吐量、事务延迟和通信开销方面具有显著优势。
本文的其余部分组织如下。在第2节中,描述了相关工作,包括对区块链技术和一些最流行的共识算法的简要概述。第3节介绍了原始的PBFT一致性算法。提出的共识算法将在第4节中描述。实验结果和相关讨论见第5节。第6节将给出结论和未来的研究方向。
2. 相关工作
共识算法作为联盟区块链网络不可缺少的组成部分,是保证区块链网络安全、可靠、一致运行的基石(Xu et al., 2019)。通过共识算法,区块链网络可以防止各种恶意行为和攻击。在共识算法机制下,网络参与者必须达成协议并验证交易的有效性,才能加入区块链。这样,任何试图进行恶意操作的参与者都将被其他诚实的参与者拒绝。同时,所有参与者都可以看到相同的事实和状态,没有差异或冲突。这样既保证了区块链的可靠性,又保证了区块链网络的一致性。许多关于区块链的研究提出了各种共识算法。本节将回顾现有的共识算法。
X证明(PoX)是一种经典的共识协议,其中X代表不同的属性,工作量证明(PoW),权益证明(PoS)和空间证明。这些协议不同于传统的中心化共识机制,中心化共识机制通过参与者提供具体的证明来确保系统的一致性。PoW是第一个应用于区块链的共识算法(Feng and Luo, 2020)。在PoW中,参与者需要解决复杂的数学问题来获得权威的区块验证权限,但这个问题需要大量的计算能力和能源消耗。PoS根据参与者持有的加密货币数量确定其在共识过程中的权威(Cao et al., 2020)。与PoW不同,PoS消耗的能源更少,而且更环保。委托堆栈证明(DPoS)是一种改进的共识算法(Liu et al., 2021)。其核心思想是通过选举代表来验证和包装交易,从而确定区块链的共识状态。DPoS旨在解决传统PoS算法的资源集中化和性能可扩展性问题。PoX (proof of X)共识算法在区块链领域得到了广泛的应用,但它们也存在一些缺点和不足。pox算法可能导致少数大参与者控制网络的情况。在这种情况下,资源集中可能会削弱去中心化的目标,增加潜在的安全风险。此外,PoX还存在效率低、计算能力高、能耗高等问题。这使得PoX算法无法适应财团区块链的各种实际使用场景。
拜占庭容错(BFT)和实用拜占庭容错(PBFT)是基于共识算法的两种常见解决方案,旨在解决分布式系统中的拜占庭容错问题(Ge et al., 2022;Misic et al., 2021)。它们在确保区块链网络的安全性和一致性方面也起着至关重要的作用。BFT是共识算法的一种范例,用于使分布式系统在存在拜占庭错误(如节点故障、恶意行为等)的情况下正常运行。PBFT是一种特殊的BFT算法,它提供了一种实用的解决方案。PBFT算法的核心思想是通过多个副本节点的交互达成共识,并要求少数节点正确达成共识决策。PBFT算法可以容忍一定数量的拜占庭错误节点,因此具有一定的容错性。然而,PBFT算法需要对每个请求进行复杂的消息交互,这使得它的开销更高,并且需要更高的事务延迟和带宽。
由于PBFT共识算法在实际应用中存在这些问题,许多学者对PBFT的各个方面进行了改进(Misic et al., 2023)。为了减少车联网共识过程的延迟,优化共识过程的交易频率,Kumar等人(2023)设计了一种快速智能的声誉PBFT共识协议R-PBFT,该协议利用逻辑回归获得的声誉来优化PBFT共识聚合过程;最后可以利用该协议减轻车联网服务器的负载压力。Li et al.(2021)针对大规模网络中PBFT节点可扩展性低的问题,采用节点分层通信的方式设计了最佳的双层PBFT,最终构建了可扩展的多层PBFT共识协议,降低了协议通信的复杂性。Qushtom等人(2023)受PoS的启发,利用PoS原理对PBFT共识机制进行优化,得到了基于信任评分和奖励机制的两阶段PBFT共识协议。利用信任评分和奖励机制,可以有效地激励诚实节点,有效地处理不诚实节点。Chen等(2022a)在改进PBFT的基础上,提出了特征分组和信用优化的拜占庭容错(Byzantine fault tolerance, FCBFT)。通过设计的特征分组模型,将大型联合体区块链的节点划分为不同的机构,并进一步设计了信誉评分奖励机制。利用信誉值选择主节点,提高了共识聚合过程的效率。Xu等人(2022)利用提出的分数分组机制对传统PBFT进行改进,设计了一种新的分数分组PBFT协议,缩短了共识聚合过程的时间,提高了车辆认证效率和车辆网络的鲁棒性。Tong et al.(2022)根据设计的链码对平台用户声誉的评估,提出了一种新的共识协议——基于声誉的PBFT,并将其进一步应用于设计的混合型区块链众包平台。提高了平台的交易吞吐量,优化了平台的容错性。然而,上述共识算法在追求一致性和安全性的同时,也牺牲了系统的性能。由于复杂的消息传递和共识协议,这些算法在处理大量事务或多个节点时可能会表现出低吞吐量和延迟。同时,随着分布式系统规模的增长,这些算法面临着可扩展性的挑战。它可能无法在大规模网络中有效扩展,从而导致性能下降或无法应对节点的快速增长。
为了解决上述问题,设计了一种基于决策树和信用评估机制的新型改进拜占庭共识算法。在第4节中,将详细描述该算法。
3. PBFT概述
区块链共识算法PBFT是一种基于拜占庭容错的共识算法,旨在解决分布式系统中的拜占庭错误问题。它通过节点之间的相互协作达成共识,确保系统在面对恶意节点的攻击时能够保持安全性和一致性。PBFT的原理是基于拜占庭一般问题,这是一个经典的分布式系统问题。一组成员需要就某项行动达成共识,但有些成员可能是恶意的或不受信任的。PBFT通过引入多个节点的协作和验证来解决这一问题。
PBFT的核心思想是通过节点间的相互验证和消息交换达成共识。节点将对来自PN(主节点)和其他节点的消息进行验证,并根据一定的规则判断消息的合法性和一致性。只有当一个节点接收到足够数量的合法消息时,它才会进入下一阶段,并将自己的消息广播给其他节点。PBFT通过多个节点的协作和验证,可以达成共识,确保系统在面对拜占庭式故障时仍能保持安全性和一致性。具体来说,它通过一致性协议、视图更改协议和检查点协议来保证系统的一致性和容错性。
3.1. Consistency protocol
PBFT协议中的一致性协议是其核心组件,用于保证系统中所有副本节点对请求的顺序和结果的一致性。PBFT一致性协议分为预准备、准备、提交和回复四个阶段。为了更好地说明协议,算法的一致性协议图如图图2所示,图3进一步给出了PBFT算法运行示意图。
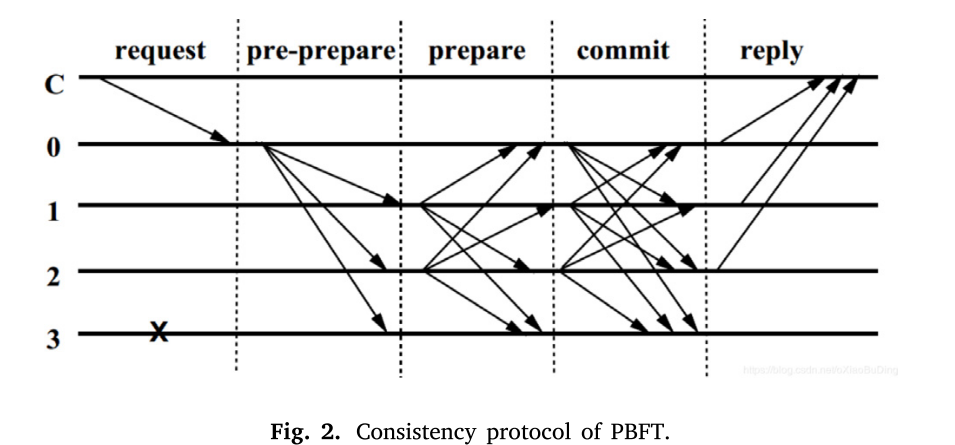
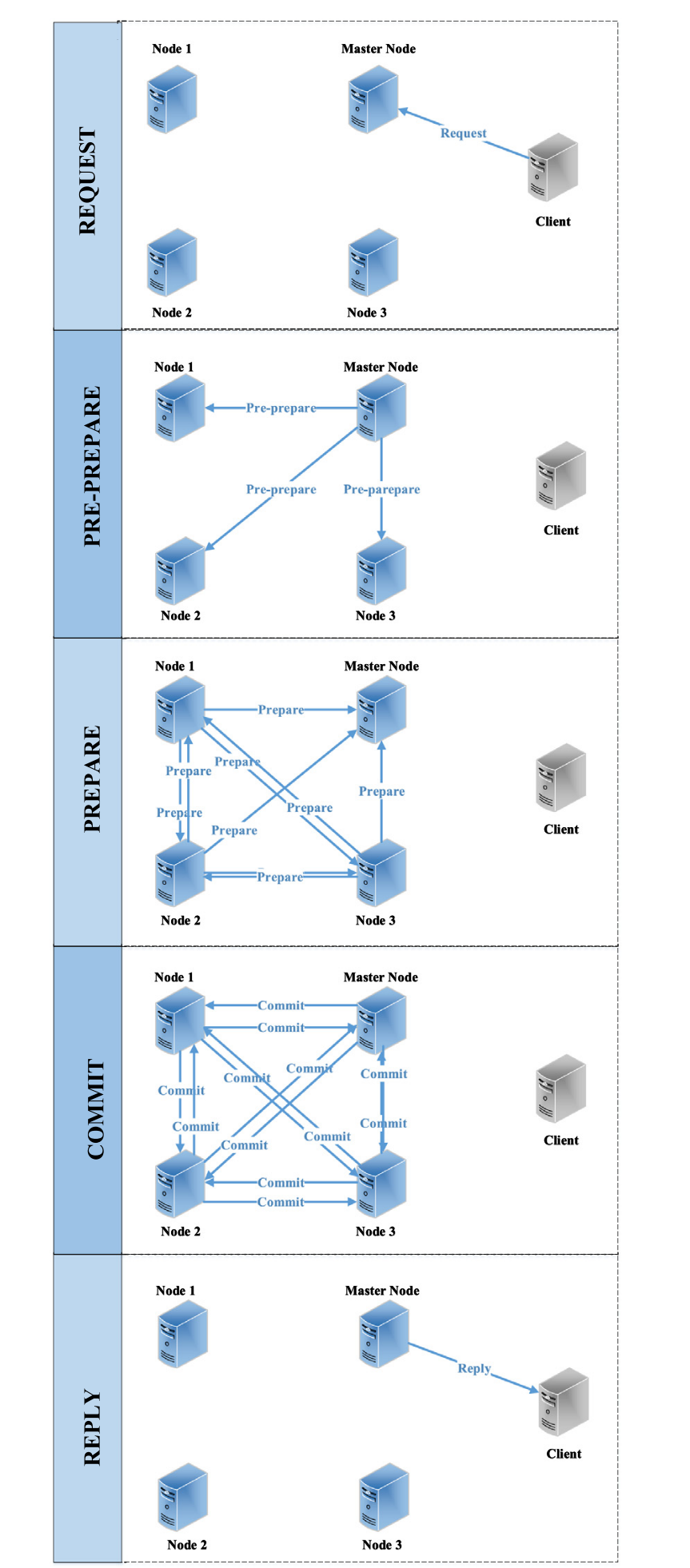
在预准备阶段,客户端将请求发送到PN, PN将请求广播到其他副本节点。预准备消息包含诸如请求的摘要和序列号之类的信息。其他副本节点验证请求的有效性并记录预准备消息。接下来是准备阶段。复制节点收到预准备消息后,向其他复制节点广播准备消息,包括预准备消息的确认。准备消息包含请求摘要、序列号和对消息的承诺。当副本节点接收到足够数量的准备消息时,它可以进入下一阶段。提交阶段在副本节点接收到足够数量的准备消息后触发。副本节点向其他节点发送提交消息,表明请求已被确认。提交消息包含请求摘要、序列号和消息确认。当副本节点接收到足够数量的提交消息时,它执行请求的结果并向客户机发送应答消息。最后是回复阶段。在执行请求后,副本节点向客户机发送应答消息,其中包括请求的结果。在接收到足够数量的应答消息后,客户端可以确认请求已被处理,并继续发送下一个请求。
通过这一系列阶段和消息交互,PBFT协议确保所有副本节点就请求的顺序和结果达成一致。只有在足够数量的副本节点确认并接受请求后,系统才会进行下一步操作。这种机制使PBFT协议能够容忍拜占庭错误,并在某些复制节点失败或恶意行为时保持一致性和正确性。适用于分布式系统中需要保证一致性和可靠性的场景。
3.2. View change protocol
PBFT协议中的视图转换协议是为了解决PN的故障或崩溃而设计的。当复制节点检测到该PN失效时,需要通过view change协议重新选择新的PN,以保证系统的正常运行和一致性。观点变更协议的过程包括观点提出、观点提出和确认、观点变更。
首先,当复制节点检测到PN故障时,它将广播一条包含建议的新视图号的视图提议消息。这些消息被传播到其他复制节点,触发新视图的选举过程。接下来,在收到视图建议消息后,副本节点将在一定条件下确认该建议。这些条件可能包括接收到足够数量的同意消息,或者等待一段时间以确保有足够数量的复制节点接收到提议。当足够数量的复制节点确认相同的视图建议时,它们可以进入下一个视图。一旦确认了新视图,副本节点将更新视图号并重新进入准备阶段。新的PN将负责协调副本节点的消息传递和共识过程。这样,即使出现PN故障,系统也能继续正常运行,保持一致性。
视图更改协议的关键是确保有足够数量的副本节点在新视图上达成一致。通过投票和消息交换,副本节点可以达成共识并选择新的PN。这样,PBFT协议可以在PN故障时实现快速、可靠的视图转换,保证系统的连续性和一致性。视图变更协议是一种解决PN失效的机制,通过复制节点之间的消息交换和共识机制来选择新的PN,保证在PN失效的情况下系统能够继续正常运行并保持一致性。这使得PBFT协议具有较高的容错性和可靠性。
3.3. Checkpoint protocol
PBFT协议中的检查点协议是为了减少状态传输的开销而引入的一种机制。定时保存系统的检查点状态,通过相互验证保证一致性。检查点协议的过程包括检查点提议、检查点消息和检查点验证。首先,在一定的时间间隔内,PN向复制节点发送检查点建议消息,要求复制节点保存当前系统的检查点状态。检查点建议消息包含检查点序列号和相关信息。
副本节点收到检查点提议消息后,将验证提议的有效性,如果满足条件,则保存检查点状态。验证的条件可能包括确保检查点提出的序列号按升序排列,以及副本节点在检查点之前保存了所有请求结果。一旦复制节点保存了检查点状态,它将向其他复制节点发送检查点消息,包括检查点序列号和验证信息。其他复制节点收到检查点消息后,将对检查点进行验证,并将检查点验证消息发送给验证通过的复制节点。当副本节点接收到足够数量的检查点验证消息时,它将检查点状态标记为已完成。这样,在故障恢复过程中,系统可以直接从最近的检查点状态开始,而不需要传输所有历史请求的执行结果。
基于检查点协议的PBFT协议可以减少故障恢复过程中的状态传输量,提高系统的效率和性能。副本节点只需要将请求结果从最近的检查点状态传输到当前状态,而不需要传输所有的历史请求结果。这样可以减少网络带宽的使用和传输延迟,使系统可以更快地恢复状态并达到一致性。
PBFT通过一致性协议保证复制节点对请求的一致性,通过视图变更协议解决PN失效问题,通过检查点协议减少状态传输开销。基于这些协议,PBFT可以在容忍拜占庭误差的条件下实现组件布网络的一致性。但是,PBFT对节点数量有一定的限制。为了保证系统的安全性,至少需要三分之二的节点是诚实的。这意味着当节点数量较大时,可能难以保证超过三分之二的节点是可靠的,这可能导致PBFT的性能下降。此外,PBFT对节点间通信要求较高,需要一定的网络带宽和时延。当节点数量较大或网络条件较差时,PBFT的性能和安全性将受到很大影响。
4. The proposed CE-PBFT algorithm
本研究旨在设计一种低通信开销、高可用性的共识算法。为此,提出了一种基于迭代二分类器3 (ID3)决策树分类的改进拜占庭容错算法,称为CE-PBFT。该算法简化了一致性协议,优化了通信开销。同时,介绍了信誉积分机制。在达成共识后,该机制会统计持续达成共识的次数、停机时间、错误通信和节点活动级别。并根据节点属性,采用决策树分类算法将节点划分为优质节点、良好节点、普通节点和低质量节点。特别地,节点活动级别由节点响应时间与接收消息数量之比获得。这样可以动态调整节点身份,消除系统中的恶意节点,从而提高节点的可靠性。此外,改进了视图变更协议,在系统中选择高信誉的高质量节点作为PN和候选节点。根据节点的功能,将节点分为PN节点、候选节点和共识节点。具体而言,表1列出了本文中的字符。
PN是负责生成区块和处理客户端指令的节点。它回复客户端,表明共识已经完成。在CE-PBFT算法中,PN的选择是基于优秀节点中信誉得分最高的节点。当PN正常工作时,候选节点负责接收和响应PN发送的消息,并参与共识过程。当PN出现问题时,候选节点成为新的PN以启动共识过程。一般情况下,根据PN的选择,将剩余的优秀节点作为候选节点。共识节点负责接收和响应PN消息,并参与共识过程。共识节点由良好节点和候选节点组成。
4.1. 节点信誉计算
节点信誉分(reputation points)的计算需要根据节点的行为来判断,而节点的行为会受到各种因素的影响。节点行为可以通过节点共识的完成、节点共识行为的表现等因素来体现。改进算法的核心是考虑影响因素计算节点信誉评分,并对节点进行评分和划分。接下来,将详细描述声誉分的影响因素。
节点完成率(Node completion rate)是指参与共识过程并成功完成共识的节点所占的比例,用C???表示。这反映了节点在系统中参与共识的情况。
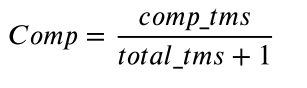
式(1)中,????_???表示节点完成的共识数,?????_???表示总共识数。随着????_???与?????_???的比值增大,其值逐渐增大。值越大,表示该节点的性能越好。
共识衰减衡量的是共识时间对节点信誉评分的影响。它反映了参与共识的时间对声誉衰减的影响。共识衰减函数,具体计算方法参照公式(2)。
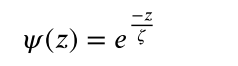
其中,z为本次一致的次数与前一次一致的次数之间的间隔。参数?为影响因子,用于调整影响变化程度。?的值为1∕??2,因此共识衰减程度受z影响。很明显,随着z的增加,ψ逐渐减小。ψ值越小,节点的前一个一致值离这个一致值越远,衰减程度越高。
节点行为性能(behavior performance)是指节点的性能。节点行为分为正常参与共识和非参与共识两类。
对于正常参与共识的节点,将给予奖励声誉分数???(reward)。对于在共识过程中缺席的节点,将给出一个惩罚信誉评分???(penalty)。这些分数会影响节点声望值(reputation points)的计算。节点的声誉得分受节点行为的各种因素的影响。对节点进行综合评估。式(3)给出了评价的声誉得分。


信誉评分的计算是一种追求更准确节点情况的综合评价方法。节点信誉积分计算的算法设计如下:
4.2. Node classification 节点分类
决策树在机器学习中的可解释性、适应性、自动特征选择、鲁棒性和高效性使其适合于联盟区块链节点的分类任务。ID3决策树算法是一种机器学习和数据挖掘算法,主要用于分类问题。通过递归选择最优特征对数据集进行分区,构建决策树。ID3算法的核心在于以信息增益作为特征选择的准则。信息增益是基于熵的概念,熵衡量的是数据的不确定性。通过选择信息增益最高的特征,可以快速降低数据的不确定性。
将ID3决策树算法应用于财团区块链共识算法中的节点分类,可以为分类模型提供显著的可解释性。它可以直观地显示决策规则,可以解释和理解节点的分类过程。这对于可追溯性场景中的联盟区块链应用程序特别有价值。此外,ID3算法非常适合处理离散特征,这在财团区块链共识算法中很普遍。此外,该算法可以处理缺失值,即使节点信息不完整也可以进行分类。最后,ID3算法计算复杂度低,执行效率高,有利于财团区块链共识算法中的节点分类。
因此,相对于共识算法中的其他节点分类方法,ID3决策树算法具有不可替代的优势。与KNN (K-Nearest Neighbors)算法相比,ID3算法可以处理离散特征,生成具有更好可解释性的决策树。与支持向量机(SVM)相比,ID3算法的计算复杂度较低,而支持向量机需要复杂的参数调优和核函数选择。此外,与神经网络相比,ID3算法不需要大量的训练数据或迭代过程,使其更容易实现和理解。
将ID3决策树算法应用于财团区块链共识算法中的节点分类,具有可解释性强、对离散特征适应性强、缺失值处理能力强、效率高、支持共识算法的安全性和可靠性等优点。图4描述了节点分类过程的示意图。同时,CE-PBFT的流程图如图图5所示。
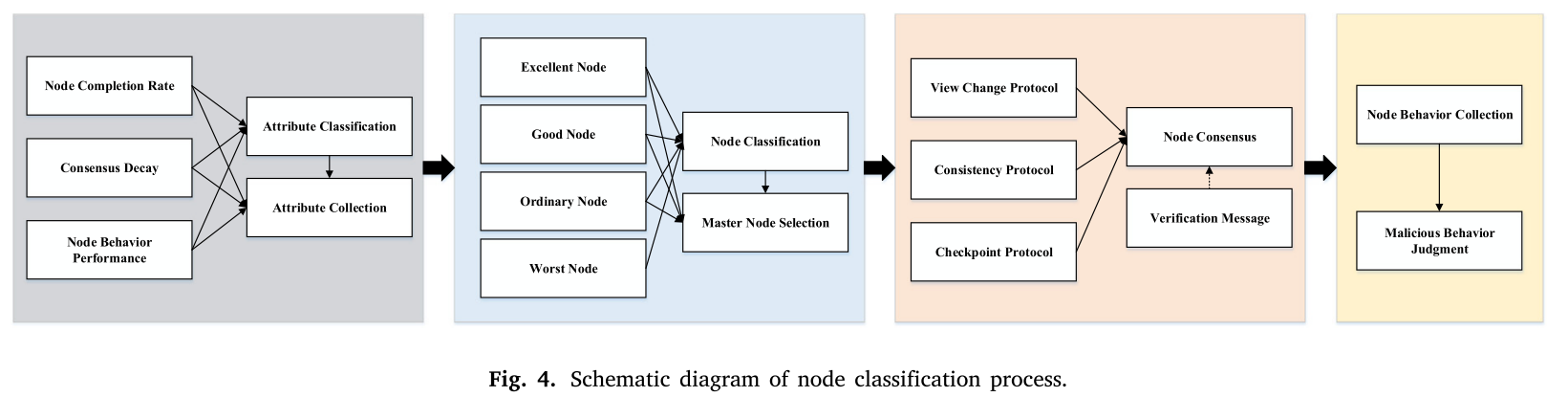
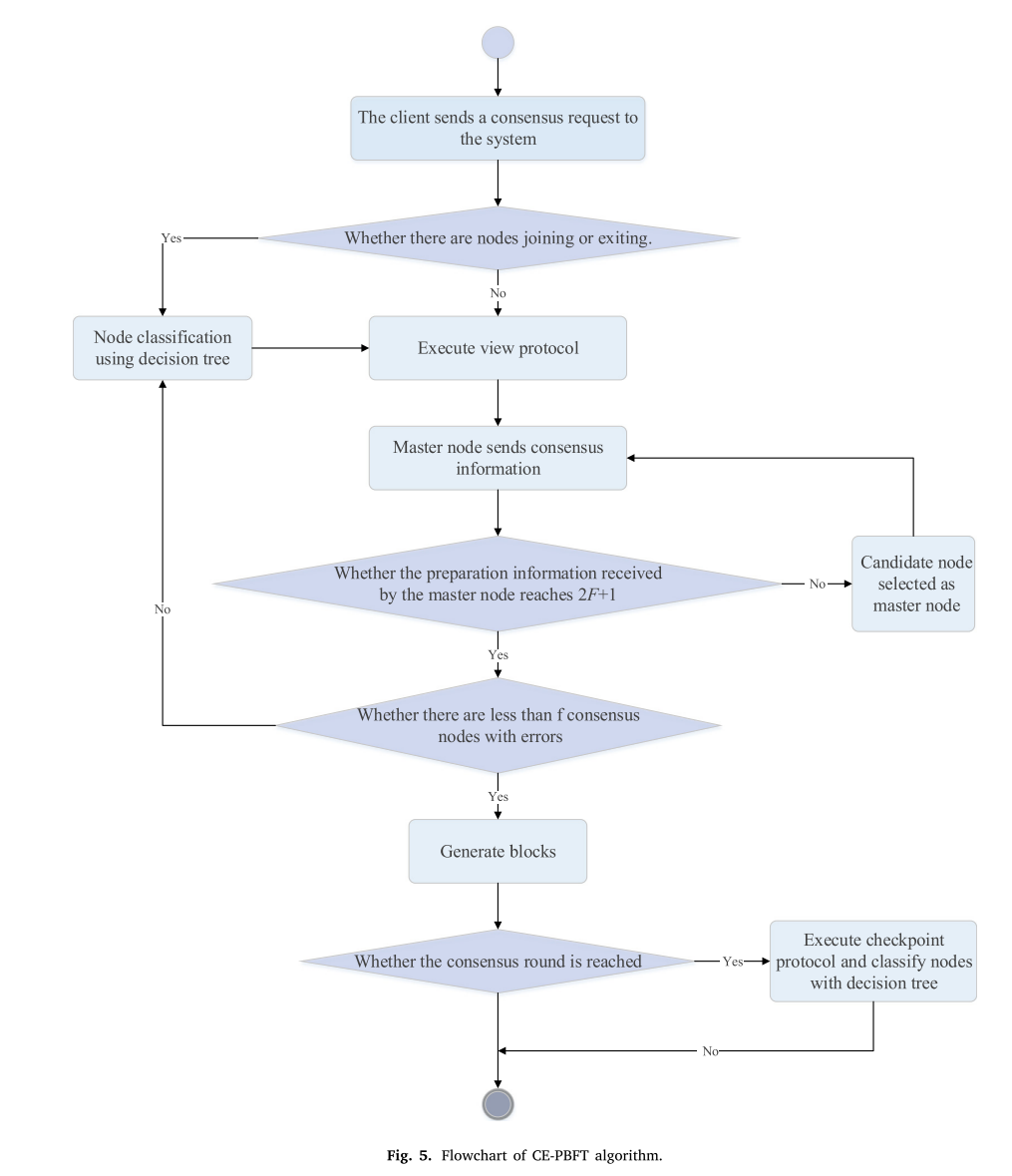
在改进的CE-PBFT一致性算法中,引入了一种决策树分类算法。当系统完成每一轮共识时,节点将收集信誉点、停机时间、连续共识时间、错误通信时间、节点活动水平等一系列特征属性。这些属性被用作特征,而优秀节点、良好节点、普通节点和差节点是类别属性。首先,联盟区块链收集分类属性并进行分类。然后,通过视图变更协议选出主节点,并在此过程中对节点进行验证。最后,收集节点行为并消除不良节点。被移除的拜占庭节点无法参与以下公式流程,如果需要重新进入系统,需要得到财团区块链管理员的确认。
构建决策树的第一步需要计算信息熵,信息熵是用来衡量样本集是否属于同一类别的指标。假设当前训练集中样本属于优秀节点、良好节点、普通节点和差节点类别的概率分别为P1、P2、P3和P4,则基于训练集计算的类别信息熵可表示为式(4)。
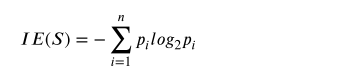
其中?表示类别的数量。
其次,计算信息增益,它代表了信息的不确定性程度( 信息增益用于衡量选择某个特征进行分割后,样本集熵的减少量。信息增益越大,说明该特征对分类的帮助越大。 )。在训练集中,我们选择属性特征向量?对集合进行划分。该特征向量?有5个可能的值,分别是节点信誉评估得分、连续达成共识的尝试次数、停机尝试次数、错误通信尝试次数和节点活动。根据式(4)计算出的信息熵,将集合S与属性特征向量?相除的信息增益计算方法如式(5)所示。
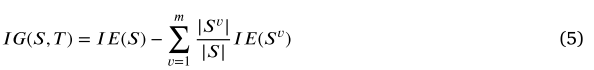

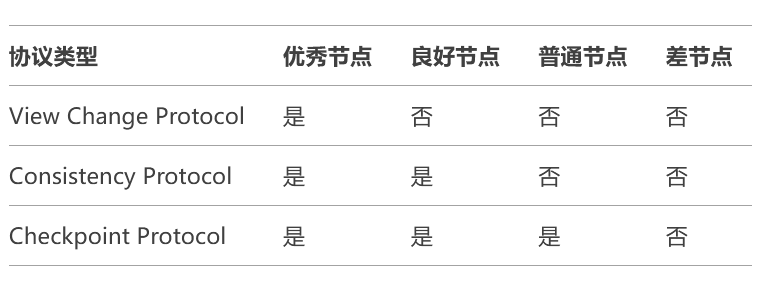
基于上述过程生成的ID3决策树,对系统中的节点进行分类,每个节点属于三种类别中的一种:优秀节点、良好节点和普通节点。其中,优秀节点数量占20%,良好节点数量占30%,普通节点数量占50%。这三种节点可以参与的协议如表2所示。

节点的级别是动态的。当增加一个新的系统节点时,算法将为其分配一个初始积分70。新节点的连续共识次数、停机次数、错误通信次数、节点活动次数均为0。
新节点可以通过完成共识来提升自己的节点级别。共识过程完成后,系统中所有节点的信誉评分加1,并统计每个节点的连续共识次数、停机次数、错误通信次数,并计算节点活跃度。然后等待下一次节点身份调整。
如果一个好的节点在达成共识的过程中出现了拜占庭错误,即节点传递了错误的信息,那么它的信誉评分将被降低5分,在下一次ID3决策树分类后将被降为普通节点。
当PN发生拜占庭错误时,其他节点将直接将该节点从本轮共识中移除,并将其降为普通节点。被淘汰的节点将成为正常节点中的最后一个节点。
系统通过定期运行ID3决策树分类算法,动态调整节点身份。当系统中的优秀节点超过系统的20%时,这些节点将不再成为优秀节点,并作为优秀节点中序号最高的节点。当新增或删除节点导致优秀节点数量低于20%时,等待系统自动升级为优秀节点。其他节点的调整方法类似。
4.3. Consistency protocol
CE-PBFT保留了PBFT的所有阶段,并消除了网络节点之间的通信过程,从而减少了网络带宽的使用。该算法选择系统中较好的节点作为共识节点,以保证系统中节点的可靠性和安全性。算法的一致性协议图如图图所示。
在请求阶段,客户端C向PN P发送请求(request,O,T,C),其中包括请求的状态机O,时间戳T和客户端编号C。

在预准备阶段,PN P从客户端接收到编号为N的提议,生成prepare proposal,<

准备阶段



确认阶段
然后在确认阶段,PN 接收到共识节点发送的准备消息后,检查所有消息是否正确且相同,并生成确认信息

主节点会将确认信息广播给所有共识节点,并通知客户端新的区块已经确认并添加到区块链中。
如果有少于 F 个共识节点发送的消息与主节点的消息不一致,系统将继续发送确认消息并生成新的区块。对于消息不一致的节点,将扣除其信誉分并记录其行为。如果有超过 F个共识节点发送的消息与主节点的消息不一致,主节点将终止当前轮的共识过程,扣除消息不一致的共识节点的信誉分,并重新启动共识过程。
4.4. View change protocol
改进后的视图变更协议从系统中的优秀节点中选择主节点(PN),而不是从所有节点中选择。其余的优秀节点将作为候选节点,在主节点发生故障时接管其角色。根据信誉评分,系统中分类的优秀节点按照评分编号为 0, 1, ..., ∣excel∣−1。主节点的选择概率与其编号相关,编号越小,节点成为主节点的概率越大。

其中,primprim 表示最终选择的主节点(PN)的序列号,view表示当前视图的编号,∣excel∣ 表示所有优秀节点的数量。当主节点在固定时间 t1 内未收到 2F+1 条准备信息时,将执行改进后的视图变更协议,其中 FF 表示所有节点中允许的最大故障节点数。此外,当在指定时间 t2 内未能生成区块时,也会触发改进后的视图变更协议,其中 t2>t1。
4.5. Time complexity analysis
在PBFT中,完全共识过程中的通信次数按公式(7)计算。
![]()
其中,N表示节点的数目。然而,在改进的CEPBFT中,由于简化了一致性协议,并且没有考虑决策树分类过程,因此三个阶段的通信次数为N,因此可以表示为?2 = 4N。可以看出?1 >?2。通过忽略决策树分类过程,CE-PBFT的通信复杂度从?(?^2)降低到O(N)。当系统需要移除拜占庭节点时,考虑到ID3决策树算法的复杂性,当存在拜占庭节点时,CE-PBFT算法可能会导致更高的时间复杂度。但是,由于CE-PBFT相对于其他协议在吞吐量、事务延迟和通信开销方面的有效改进,与改进优化带来的好处相比,这部分时间复杂度的增加是值得的。
4.6. Correctness analysis
CAP原则是分布式系统设计的一个基本原则,它指出分布式计算系统不能同时满足一致性、可用性和分区容忍度三个属性。一致性是指系统中所有节点在同一时间具有相同的数据副本或数据视图。可用性要求系统能够随时响应请求,即系统无故障、无延迟。分区容忍度要求系统能够继续工作,即使网络的某些部分无法通信或出现故障。根据CAP原理,当网络发生分区时,为了保证可用性和容错性,系统需要在分区内的不同节点之间复制数据副本,这可能导致不同节点之间的数据不一致。相反,如果系统需要一致性,即所有节点具有相同的数据,则需要牺牲可用性或分区容忍度。
CAP原则的存在意味着在分布式系统的设计中必须权衡和选择一致性、可用性和分区容错性的程度。不同的系统可能对这三个属性做出不同的选择,并根据特定的应用程序需求和业务场景确定哪些属性是最重要的。根据CAP定理,CE-PBFT算法的一致性协议简化了过程,保证了可用性。在CE-PBFT中,每个非故障共识节点都会向其PN发送响应,以确保算法的可用性。CEPBFT通过决策树分类消除故障节点,当PN发生故障时,通过改进的视图变更协议及时替换PN,保证算法的容错性。CE-PBFT算法的一致性是指强一致性,即在满足可用性和分区容限的情况下,通过适当的方式达到一致的状态。在CE-PBFT算法中,每个节点保存记录。当增加新的网络节点时,通过一致性协议中的消息传输同步块信息,最终实现算法的强一致性。
5. Experiment and discussion
5.1. Experiment setting
为了评估所提出的CE-PBFT的性能,在一台Intel Core [email protected] GHz处理器和Ubuntu 18.04操作系统的计算机上,用JAVA对区块链系统进行了仿真和实现。将CE-PBFT与PBFT (Castro等人,1999)、G-PBFT (Lao等人,2020)、RBFT (Lei等人,2018)、WBFT (Qin等人,2022)和PPoR (Abishu等人,2021)进行比较,使用通信开销、吞吐量和延迟作为性能指标。进行了一系列的实验,并收集了相应的实验数据。为了模拟可追溯性场景中大型财团区块链应用程序的事务工作负载,需要创建和生成一系列事务数据。这些交易数据包括原材料采购、生产过程和物流运输等各个阶段的信息。网络中的节点数量从100个逐渐增加到700个,用于实验测试。所有节点的初始信任值设置为70。系统运行10分钟后,客户端发起200组请求。实验重复20次,取20次实验结果的平均值作为最终结果。具体实验设置如表3所示。
在实验中,通过记录成功完成的事务的数量来衡量系统的吞吐量。每秒事务数(TPS)用作度量吞吐量的指标。通过不断增加并发事务数,观察系统在单位时间内成功处理的事务数,得到系统的吞吐量。为了测量事务延迟,记录从事务启动到确认和执行所花费的时间。在实验中,模拟了一个并发事务的场景,并测量了每个事务的执行时间。通过测量多个事务,得到系统的平均事务延迟。为了测量通信开销,记录共识过程中节点之间传输的消息的数量和大小。在实验中监控节点间的通信,记录每个节点发送和接收的消息数。通过分析和总结这些数据,确定了系统中的通信开销。
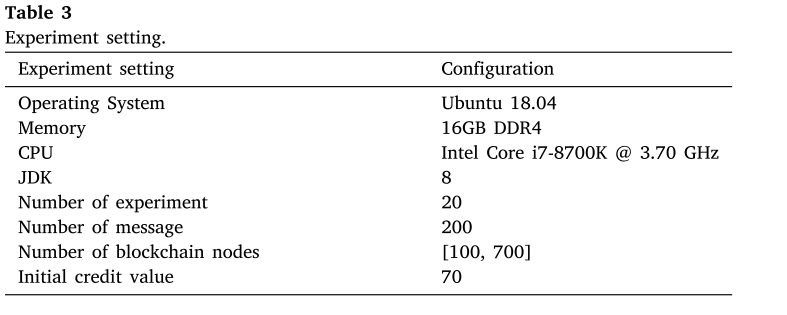
5.2. Transaction latency
事务延迟表示从一个节点发起共识请求到系统中所有节点达成协议所花费的时间。它反映了共识算法处理请求和达成共识所需的时间。更低的事务延迟意味着更快的共识过程,可以获得更好的系统响应速度。
图7显示了PBFT、G-PBFT、RBFT、WBFT、PPoR以及所提出的CE-PBFT的事务延迟随网络节点增加的变化情况。图中的横坐标表示网络节点数量,纵坐标表示事务延迟。由图可以看出,在相同条件下,PBFT算法和RBFT算法的延迟都高于CE-PBFT算法。在相同事务处理和不同节点数量的条件下,事务延迟会随着节点数量的增加而增加,但改进的CE-PBFT算法的共识延迟低于PBFT算法。当节点数为100时,6种共识算法的时延在1ms ~ 3ms之间。随着网络节点的增加,PBFT和RBFT的时延迅速增加。当网络节点数为700时,PBFT的时延为15.6,RBFT的时延为13.9782,CE-PBFT的时延为5.654,分别比PBFT和RBFT低63.75%和59.55%。在所有的共识算法中,表现第二好的共识算法是PPOR,延迟为7.4476。然而,性能最好的CEPBFT却降低了24.83%。PBFT算法和RBFT算法的延迟明显高于CE-PBFT算法,这是因为PBFT算法和RBFT算法的三阶段共识算法的时间复杂度较高,节点在两两通信中消耗大量时间,增加了共识延迟。CERBFT根据信誉机制选择信誉点数高的节点参与共识。这些共识节点具有良好的稳定性和可靠性,有利于减少共识过程的误差,有效提高共识的效率。
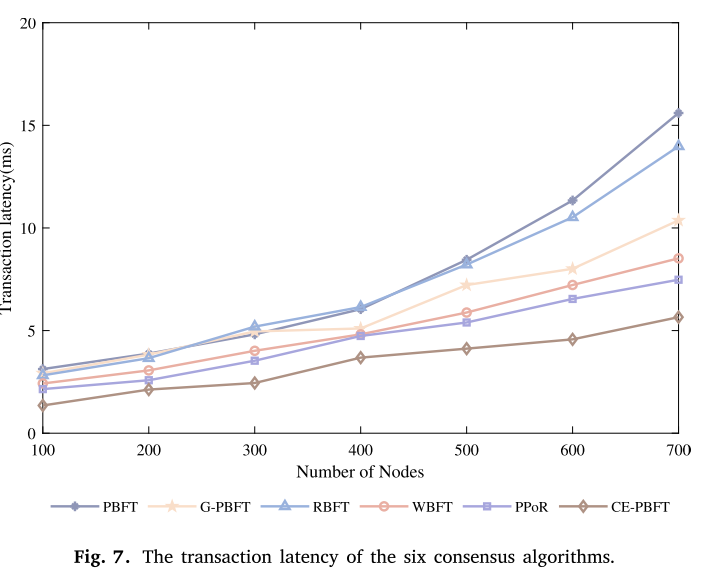
图8显示了这六种共识算法在700节点联盟区块链场景下的20次独立实验结果。通过图8可以清楚地看到CE-PBFT不仅值更小,而且曲线波动范围也更小。CE-PBFT的延迟在6 ms左右波动,而其他共识算法的延迟都在7 ms以上,RBFT和PBFT的延迟甚至在13 ms以上。延迟值更小,这进一步表明使用CE-PBFT的财团区块链比许多共识算法具有更低的延迟。曲线波动范围较小,表明CE-PBFT的延迟结果比其他共识算法更稳定。
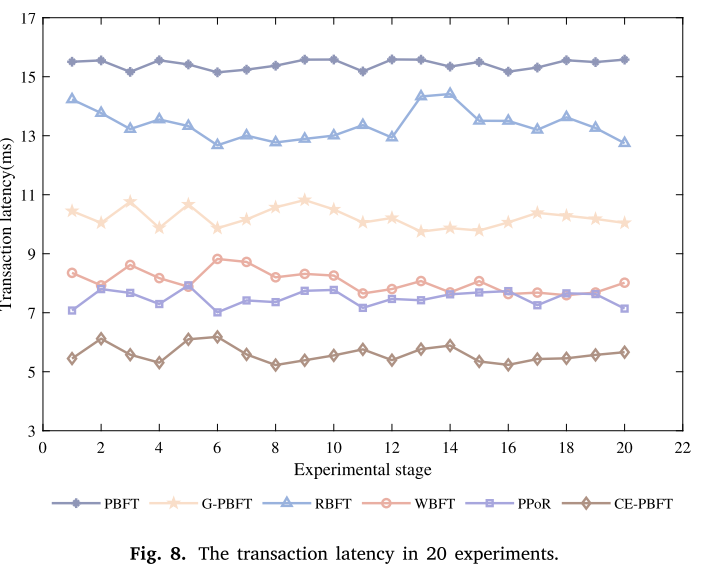
CE-PBFT的延迟降低可以归因于视图转换协议的改进和优化。为了防止拜占庭节点成为PN,频繁更改视图导致系统效率低的问题,改进了视图更改协议,将PN的范围缩小到具有良好节点信誉的优秀节点,从而保证了PN选择的效率和可信度。CEPBFT实现的低延迟对于快速的事务确认和响应至关重要。它保证了更快的交易处理,缩短了交易验证过程中的等待时间,提高了用户体验。通过测试,验证了CE-PBFT一致性算法在时延方面的有效性。CE-PBFT提供的低延迟使其成为低延迟事务处理的关键解决方案。
5.3. Throughput
为了评价CE-PBFT在吞吐量方面的性能,我们进行了一系列实验,比较了不同节点数下PBFT、G-PBFT、RBFT、WBFT、PPoR和CE-PBFT的性能。吞吐量表示系统在给定时间内可以完成的一致请求的数量。它衡量了共识算法的处理能力和系统的容量。更高的吞吐量意味着系统可以处理更多的请求或事务,具有更高的处理效率。从100个财团区块链节点开始,逐渐增加到700个节点。针对每种不同的场景,测量了所有实验中六种共识算法的平均吞吐量。
图9显示了PBFT、G-PBFT、RBFT、WBFT、PPoR以及所提出的CE-PBFT的吞吐量随网络节点增加的变化情况。图9中横坐标的值表示网络节点数量,纵坐标的值表示网络吞吐量。结果表明,在相同的实验条件下,CE-PBFT的吞吐量大大高于其他算法。当网络节点数为100时,PBFT算法与CE-PBFT算法的吞吐量接近,约为800,G-PBFT、RBFT、WBFT等算法的吞吐量约为600。随着网络节点的逐渐增加,各种算法的吞吐量都在下降。PBFT的下降率远高于其他算法,最终成为6种共识算法中吞吐量最低的共识算法。当系统中有700个节点时,PBFT算法的吞吐量为92,其他算法的吞吐量都小于200,但CE-PBFT算法的吞吐量为268。在很多场景下,CE-PBFT一致性算法的吞吐量高于比较算法,下降率不高于比较算法,说明CE-PBFT算法的性能高于5种比较算法,且节点越多,其表现越明显。这意味着CE-PBFT可以更有效地处理事务,并达到更高的共识速度。
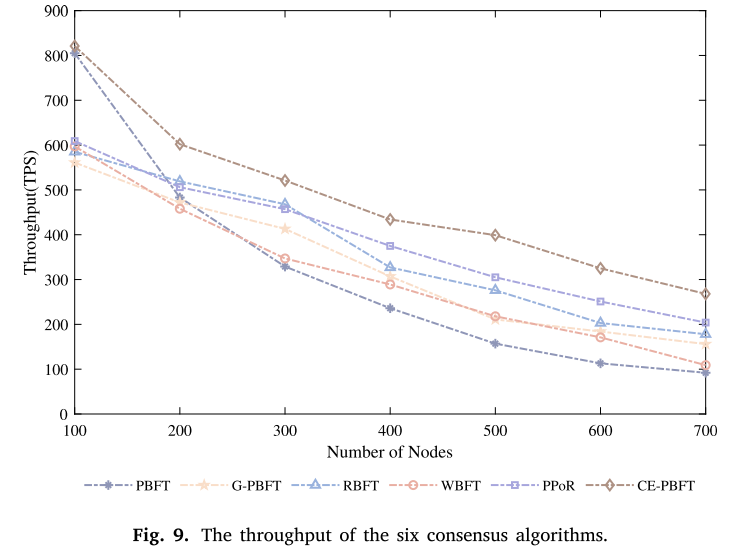
CE-PBFT的高吞吐量可归因于优化的声誉评估机制。通过减少冗余的消息交换和提高消息验证的效率,CE-PBFT可以更快地处理事务,从而实现更高的吞吐量。改进后的共识协议还降低了复杂性,并通过减少达成共识所需的时间进一步提高了吞吐量。
5.4. Communication overload
在本节中,介绍了PBFT、G-PBFT、RBFT、WBFT、PPoR以及所提出的CE-PBFT在通信负载性能方面的实验结果。通过一系列实验测量了这些共识算法在不同工作场景下的通信负荷。在实验中,我们通过改变联盟区块链节点的数量来测量共识过程中所需的网络流量。通信开销是指共识算法中节点间消息传递和通信所需的资源和成本,可以有效地衡量共识算法的效率。较低的通信开销意味着共识算法可以以更有效的方式进行通信,从而减少网络负载和资源消耗。具体来说,通过记录算法执行期间传递的消息数量来比较不同算法的通信开销。
图10显示了当系统节点越来越多时,六种公式算法的共识通信开销的变化情况。在图10中,横坐标值表示网络节点数量,纵坐标值表示共识通信开销。从实验结果可以看出,在每个节点数量下,CE-PBFT的通信开销相对较低。当节点数较少时,所有共识算法的通信负荷都很小。然而,随着系统节点数量的增加,网络中的通信开销也会迅速增加。在所有算法的性能方面,PBFT一致性算法的上升率明显高于比较算法,而CE-PBFT的上升率最小。当场景中有700个节点时,CE-PBFT、G-PBFT、RBFT和PPoR算法的通信开销是性能最好的4种算法。G-PBFT算法的通信开销为478267,RBFT算法的通信开销为581029,PPoR算法的通信开销为354786,CE-PBFT算法的通信开销为241837,分别降低了49.43%、58.38%和31.84%。这表明CE-PBFT可以减少节点之间的消息传递量并降低通信开销。
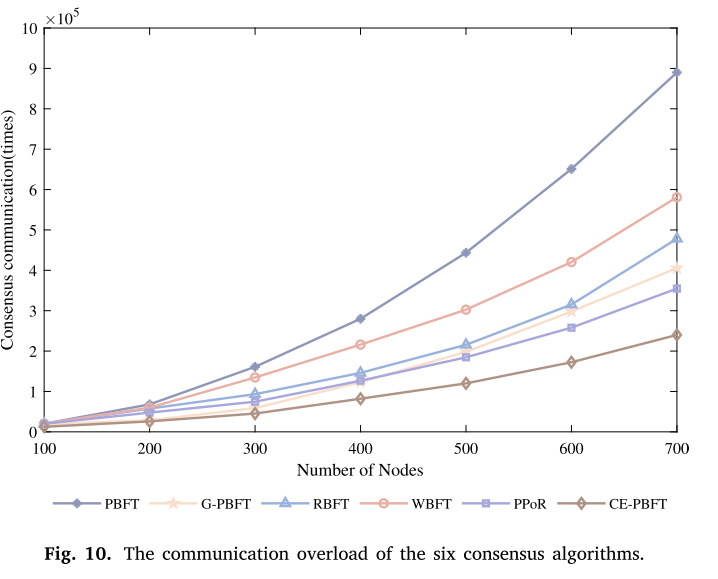
CE-PBFT的通信负荷降低主要是由于改进了原有的一致性协议,降低了实际场景中的通信开销。低通信负载对于大规模联盟区块链来说非常重要,可以减少网络拥塞,降低带宽利用率,保证更有效地利用网络资源。实验结果验证了CE-PBFT通信负载的有效性。CE-PBFT提供的低通信负载使其成为需要有效利用网络资源的应用程序的一个有前途的解决方案。
实验结果表明,CE-PBFT算法在高动态或高系统可靠性要求的网络环境中具有优异的性能,例如在可追溯场景中应用的大规模联盟。CE-PBFT中的节点信用评价模型综合考虑了节点完成率、共识衰减、行为等因素,动态评价和反映了节点的可靠性。这使得CE-PBFT能够适应网络中节点状态的频繁变化,并在不断变化的网络环境中保持高效的共识机制。此外,CE-PBFT中引入了节点信用评价模型和决策树算法,有效解决了节点的拜占庭化问题,提高了系统的整体可靠性和安全性。
6. Conclusion
本文设计了一种新的共识算法CE-PBFT,通过所设计的节点信用评价模型和决策树算法分析网络节点的行为,对网络节点进行分类,并根据分类结果动态选择非拜占庭节点。它有效地减少了共识过程中的消息数量和通信过载。与PBFT、G-PBFT、RBFT、WBFT、PPoR进行比较。CE-PBFT在系统吞吐量、事务延迟和通信开销方面明显优于比较协议。
本文提出的CE-PBFT在处理拜占庭节点时表现出良好的容错性能,但对于其他类型的故障(如崩溃故障或延迟故障)仍有一定的局限性。在未来的研究中,我们将进一步探索如何处理各种类型的故障,以提高系统的鲁棒性和容错性。同时,我们将对提出的算法进行改进,并将其应用到更广泛的实际场景中,以实现更可靠、更高效的分布式共识。
评论记录:
回复评论: