
像许多IT专业人士一样,在笔记本电脑上拥有一个Kubernetes集群对于展示和测试产品非常有益。在某些情况下,你可能需要运行具有多个节点或集群的Kubernetes集群,以进行复杂的演示或测试,例如多集群服务网格。这些场景需要多个服务器来创建所需的集群,这进而需要大量的RAM和一个用于运行虚拟机的虚拟化管理程序。
要在多集群场景下进行完整的测试,你需要为每个集群创建多个节点。如果你使用虚拟机创建集群,就需要有足够的资源来运行多个虚拟机。每台虚拟机都有额外的开销,包括磁盘空间、内存和CPU使用率。
想象一下,如果可以仅使用容器来建立一个集群。通过使用容器而不是完整的虚拟机,你可以利用减少的系统需求,运行更多的节点。这种方法允许你通过一个命令在几分钟内快速创建和删除集群。此外,你还可以使用脚本来简化集群的创建,甚至在单个主机上运行多个集群。
使用容器运行Kubernetes集群为你提供了一个环境,由于资源限制,大多数人使用虚拟机或物理硬件难以部署这种环境。幸运的是,有一个工具可以实现这一点,叫做KinD(Kubernetes in Docker),它允许我们在单台机器上运行Kubernetes集群。KinD是一种工具,提供了一种简单、快速且便捷的方法来部署开发用的Kubernetes集群。与其他替代方案如Minikube甚至K3s相比,KinD更加小巧,非常适合大多数用户在自己的系统上运行。
我们将使用KinD来部署一个多节点集群,你将在未来的章节中使用该集群来测试和部署组件,如Ingress控制器、认证、RBAC(基于角色的访问控制)、安全策略等。
在本章中,我们将涵盖以下主要内容:
- 介绍Kubernetes组件和对象
- 使用开发集群
- 安装KinD
- 创建一个KinD集群
- 查看你的KinD集群
- 为Ingress添加自定义负载均衡器
让我们开始吧!
技术要求
本章有以下技术要求:
- 一台运行Docker的Ubuntu 22.04+服务器,最低4 GB内存,建议8 GB内存。
- 来自GitHub仓库chapter2文件夹的脚本,你可以通过访问本书的GitHub仓库获取:github.com/PacktPublis…。
我们认为有必要强调,本章将提及各种Kubernetes对象,其中有些可能缺乏详细的上下文。不过,在第3章《Kubernetes训练营》中,我们将深入探讨Kubernetes对象,并提供大量示例命令,以增强你的理解。为了确保实际的学习体验,我们建议在阅读训练营章节时拥有一个集群。
本章涵盖的大多数基础Kubernetes主题将在后续章节中讨论,所以如果在阅读本章后有些主题变得模糊,不用担心!它们将在后续章节中详细讨论。
介绍 Kubernetes 组件和对象
由于本章将讨论各种常见的 Kubernetes 对象和组件,我们在表格中简要定义了每个术语。这将为你提供必要的上下文,帮助你在阅读本章时理解相关术语。
在第3章《Kubernetes训练营》中,我们将详细介绍 Kubernetes 的组件以及集群中包含的基本对象集。由于我们将在本章中使用一些基本对象,因此我们在下表中列出了一些常见的 Kubernetes 组件和资源。
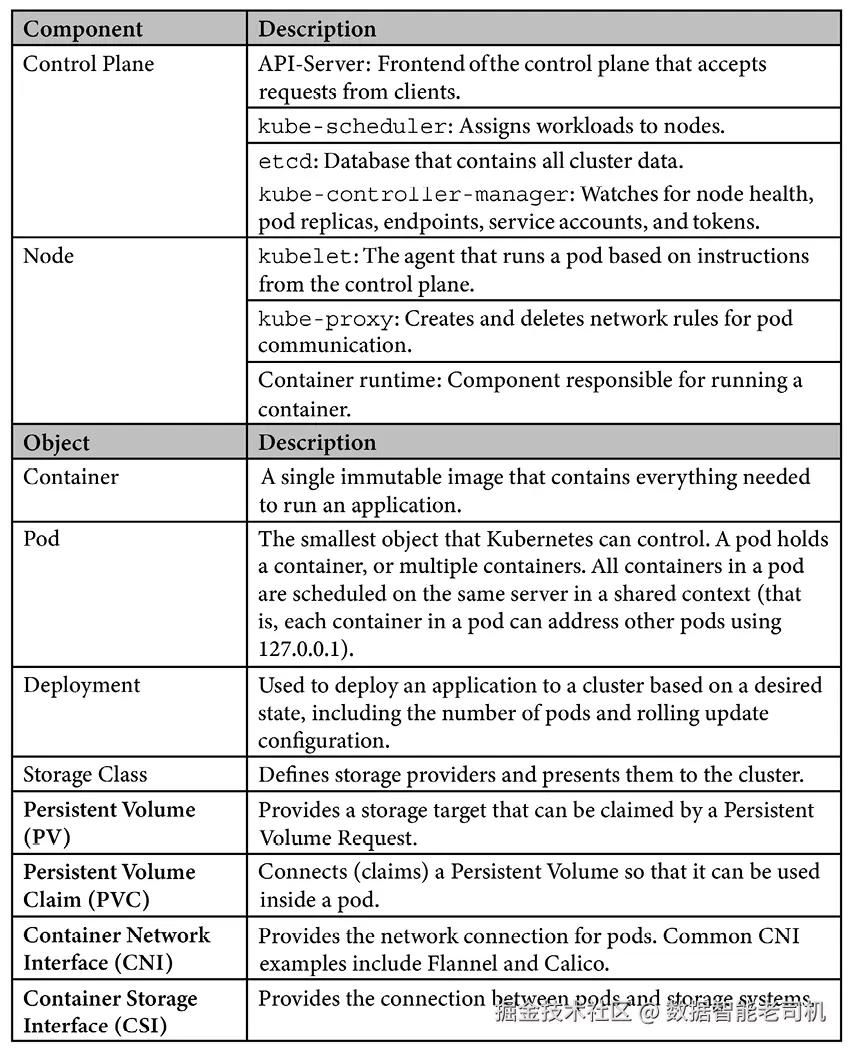
尽管这些只是 Kubernetes 集群中可用对象的一小部分,但它们是我们将在本章讨论的对象。了解每个资源是什么并具备其基本功能的知识,将有助于你理解本章内容。
与集群交互
要与集群交互,你需要使用 kubectl 可执行文件。我们将在第3章《Kubernetes训练营》中详细介绍 kubectl,但由于我们将在本章中使用一些命令,因此我们提供了基本命令的表格,并解释了各选项的作用。
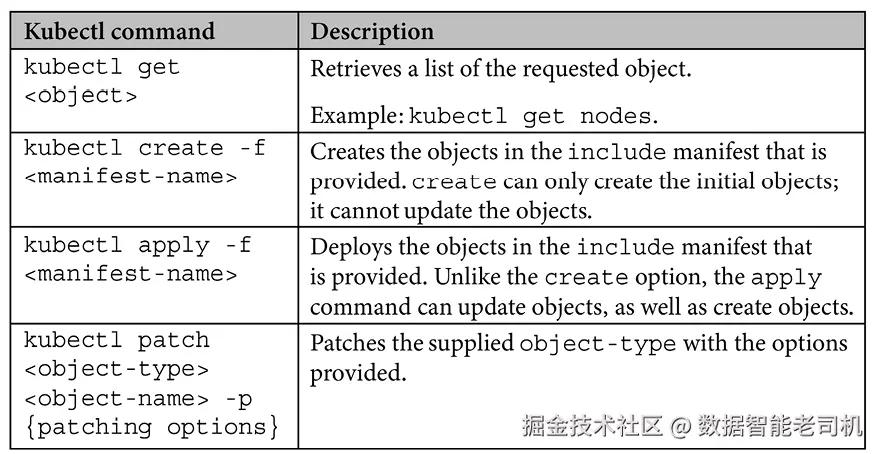
在本章中,你将使用这些基本命令来部署我们将在本书中使用的集群部分。
接下来,我们将介绍开发集群的概念,并重点介绍用于创建开发集群的最受欢迎的工具之一——KinD。
使用开发集群
随着时间的推移,已经开发了几种解决方案来简化开发Kubernetes集群的安装,使管理员和开发人员能够在本地系统上进行测试。虽然这些工具在基本的Kubernetes测试中效果显著,但它们通常存在一些限制,无法完全满足更高级的场景需求。
一些常见的解决方案如下:
- Docker Desktop
- K3s
- KinD
- kubeadm
- minikube
- Rancher Desktop
每个解决方案都有其优点、限制和适用场景。有些解决方案将你限制在单节点上,该节点同时运行控制平面和工作节点。其他解决方案支持多节点,但需要额外的资源来创建多个虚拟机。根据你的开发或测试需求,这些解决方案可能无法完全满足你的要求。
要真正了解Kubernetes,你需要拥有一个至少包含控制平面和一个工作节点的集群。你可能希望测试突然移除一个工作节点的场景,以查看工作负载的反应;在这种情况下,你需要创建一个包含控制平面节点和三个工作节点的集群。为了创建这些不同类型的集群,我们可以使用Kubernetes特别兴趣小组(SIG)开发的一个项目,称为KinD。
KinD(Kubernetes in Docker)能够在单个主机上创建多个集群,每个集群可以有多个控制平面和工作节点。这个功能使得高级测试场景得以实现,否则需要使用其他解决方案并分配更多的资源。社区对KinD的反馈非常积极,GitHub上的活跃社区(github.com/kubernetes-…)以及专门的Slack频道(#kind)都证明了这一点。
虽然KinD是一个出色的开发集群创建工具,但请不要将KinD用作生产集群或将其暴露在互联网上。尽管KinD集群提供了大多数生产集群所需的功能,但它并未设计用于生产环境。
为什么我们选择KinD用于本书?
在编写本书时,我们的目标是将理论知识与实际操作经验相结合。KinD成为实现这一目标的重要工具,使我们能够使用脚本快速搭建和拆除集群。虽然其他解决方案也可能提供类似的功能,但KinD在几分钟内建立多节点集群的能力使其脱颖而出。我们希望提供一个既有控制平面又有工作节点的集群,以模拟更“真实”的集群环境。为了减少硬件需求并简化Ingress配置,我们选择将本书中大多数练习场景限制为一个控制平面节点和一个工作节点。
有些人可能会问,为什么我们不使用kubeadm或其他工具来部署一个具有多个控制平面节点和工作节点的集群。正如我们所说,虽然KinD并非用于生产环境,但它需要的资源较少,可以模拟多节点集群,使大多数读者能够操作一个类似于企业级Kubernetes集群的环境。
多节点集群可以在几分钟内创建,一旦测试完成,可以在几秒钟内拆除。快速启动和停止集群的能力使KinD成为我们练习的理想平台。KinD的要求很简单:你只需要一个运行中的Docker守护进程来创建集群。这意味着它与大多数操作系统兼容,包括以下系统:
- Linux
- 运行Docker Desktop的macOS
- 运行Docker Desktop的Windows
- 运行WSL2的Windows
在撰写本文时,KinD尚不支持Chrome OS。KinD Git仓库中有一些帖子介绍了在Chrome OS上运行KinD的步骤,但这不受官方支持。
虽然KinD支持大多数操作系统,但我们选择了Ubuntu 22.04作为我们的主机系统。本书中的一些练习要求文件位于特定目录中,并执行特定命令;选择单一的Linux版本可以帮助我们确保练习按设计运行。如果你家中没有可用的Ubuntu服务器,你可以在云提供商如Google Cloud Platform (GCP) 上创建计算实例。Google提供300美元的信用额度,这足够运行一台Ubuntu服务器几周。你可以在cloud.google.com/free/查看GCP的免费选项。
最后,用于部署练习的脚本都固定在特定版本的KinD和其他依赖项上。Kubernetes和云原生领域发展迅速,我们无法保证你在阅读本书时使用的最新系统版本能够像预期一样工作。
现在,让我们解释一下KinD的工作原理以及一个基本的KinD Kubernetes集群是什么样子的。在我们继续创建用于本书练习的集群之前,先介绍一下如何操作基本的KinD Kubernetes集群。
使用基本的KinD Kubernetes集群
从更广泛的角度来看,KinD集群可以看作是由一个Docker容器组成,该容器负责运行控制平面节点和工作节点,创建一个Kubernetes集群。为了确保部署简单且具有弹性,KinD将所有Kubernetes对象打包成一个统一的镜像,称为节点镜像。该节点镜像包含创建单节点或多节点集群所需的所有Kubernetes组件。
为了展示KinD容器中运行的内容,我们可以利用Docker在控制平面节点容器中执行命令并检查进程列表。在进程列表中,你会看到在控制平面节点上活动的标准Kubernetes组件。如果我们执行以下命令:docker exec cluster01-worker ps -ef。
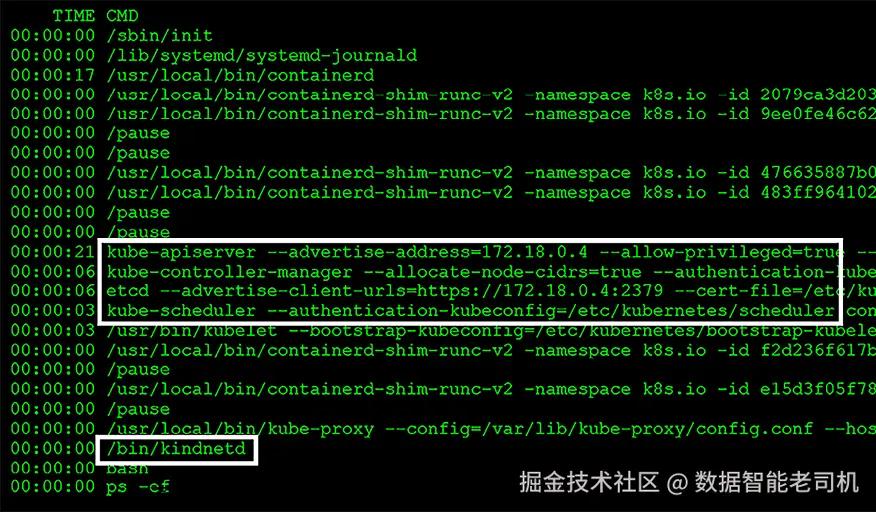
如果你进入一个工作节点检查其组件,你会看到所有标准的工作节点组件:

我们将在第3章《Kubernetes训练营》中介绍标准的Kubernetes组件,包括kube-apiserver、kubelets、kube-proxy、kube-scheduler和kube-controller-manager。
除了标准的Kubernetes组件外,KinD节点(控制平面节点和工作节点)还包含一个额外的组件,称为Kindnet,这是大多数标准Kubernetes安装中不包含的部分。Kindnet是一个容器网络接口(CNI)解决方案,它包含在默认的KinD部署中,为Kubernetes集群提供网络功能。
Kubernetes的CNI是一种规范,允许Kubernetes使用大量的网络软件解决方案,包括Calico、Flannel、Cilium、Kindnet等。
虽然Kindnet是默认的CNI,但可以将其禁用并选择其他替代方案,如Calico,我们将在我们的KinD集群中使用Calico。虽然Kindnet可以满足我们大多数任务的需求,但它并不是你在实际运行Kubernetes集群时会遇到的CNI。由于本书旨在帮助你踏上Kubernetes企业之旅,我们希望用更常用的CNI,如Calico,替换默认的CNI。
现在我们已经讨论了每个节点和Kubernetes组件,让我们看看基础的KinD集群包含哪些内容。为了展示整个集群以及所有正在运行的组件,我们可以运行 kubectl get pods --all 命令。该命令将列出集群中所有正在运行的组件,包括基础组件,这些组件将在第3章《Kubernetes训练营》中讨论。除了基础的集群组件外,你可能会注意到一个在命名空间local-path-storage中运行的Pod,以及一个名为local-path-provisioner的Pod。这个Pod运行了KinD附带的一个附加组件,为集群提供自动配置PersistentVolumeClaims的能力:
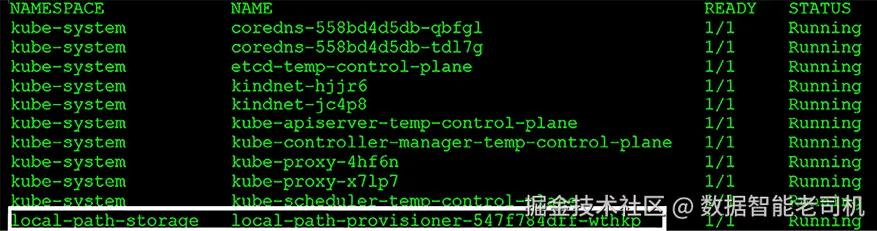
每个开发集群选项通常都提供类似的功能,主要用于测试部署。这些选项通常包括Kubernetes控制平面、工作节点以及用于网络需求的默认容器网络接口(CNI)。虽然大多数解决方案满足这些基本需求,但有些提供了额外的功能。随着Kubernetes工作负载的发展,你可能会发现需要像local-path-provisioner这样的附加组件。在本书中,我们在各种练习中高度依赖此组件,它在部署本书中展示的许多示例中起着关键作用。没有它,完成这些练习将变得相当困难。
为什么在开发集群中使用持久卷很重要?这是因为当你使用大多数企业级Kubernetes集群时,会遇到相关的知识。随着Kubernetes的成熟,许多组织已经将有状态的工作负载迁移到容器中,要求为其数据提供持久存储。能够在KinD集群中与存储资源交互,可以让你获得使用存储的知识,而不需要额外的资源。
local-path-provisioner非常适合开发和测试,但不应在生产环境中使用。大多数运行Kubernetes的生产集群都会为开发人员提供持久存储。通常,这些存储由基于块存储、S3(简单存储服务)或NFS(网络文件系统)的存储系统支持。
除了NFS之外,大多数家庭实验室很少有资源运行功能齐全的存储系统。local-path-provisioner通过使用本地磁盘资源为你的KinD集群提供类似于昂贵存储解决方案的所有功能,从而消除了这一限制。
在第3章《Kubernetes训练营》中,我们将讨论一些与Kubernetes存储相关的API对象。我们将讨论CSIdrivers、CSInodes和StorageClass对象。这些对象由集群使用,提供对后端存储系统的访问。一旦安装和配置完成,pods将通过PersistentVolumes和PersistentVolumeClaims对象使用存储。理解存储对象很重要,但在它们首次发布时,由于大多数Kubernetes开发环境不包含这些对象,测试它们对大多数人来说是困难的。
KinD认识到了这一限制,并选择集成了来自Rancher Labs(现为SUSE的一部分)的项目local-path-provisioner,该项目构建在Kubernetes本地持久卷框架之上,最初在Kubernetes 1.10中引入。
你可能会想,既然Kubernetes本身支持本地主机持久卷,为什么还需要一个附加组件呢?尽管Kubernetes增加了对本地持久存储的支持,但并未增加自动配置的功能。虽然CNCF(云原生计算基金会)确实提供了一个自动配置程序,但它必须作为独立的Kubernetes组件安装和配置。KinD的配置程序消除了这种配置,使你可以在开发集群上轻松使用持久卷。Rancher的项目为KinD提供了以下功能:
- 当创建
PersistentVolumeClaim请求时,自动创建PersistentVolumes。 - 一个默认的存储类(StorageClass),名为
standard。
当自动配置程序检测到PersistentVolumeClaim(PVC)请求到达API服务器时,会创建一个PersistentVolume,并将pod的PVC绑定到新创建的PersistentVolume。然后,PVC可以由需要持久存储的pod使用。
local-path-provisioner为KinD集群增加了一个功能,极大地扩展了你可以运行的测试场景。如果没有自动配置持久磁盘的能力,测试需要持久磁盘的部署将变得困难。
在Rancher的帮助下,KinD为你提供了一种解决方案,让你可以实验动态卷、存储类和其他存储测试,而这些测试在昂贵的家庭实验室或数据中心之外通常是无法进行的。
我们将在多个章节中使用该配置程序,为不同的部署提供卷。了解如何在Kubernetes集群中使用持久存储是一项非常有用的技能,在后续章节中,你将看到该配置程序的实际应用。
现在,让我们继续解释KinD节点镜像,它用于部署控制平面和工作节点。
理解节点镜像
节点镜像赋予了KinD在Docker容器内运行Kubernetes的“魔力”。这是一个令人印象深刻的成就,因为Docker依赖于systemd运行系统和其他组件,而这些组件并不包含在大多数容器镜像中。
KinD以一个基础镜像为起点,这是团队开发的镜像,包含了运行Docker、Kubernetes和systemd所需的一切。由于节点镜像基于Ubuntu基础镜像,团队删除了不需要的服务,并为Docker配置了systemd。
如果你想了解基础镜像是如何创建的细节,可以查看KinD团队的GitHub仓库中的Docker文件:github.com/kubernetes-…。
KinD 和 Docker 网络
使用 KinD 时,它依赖 Docker 或 Red Hat 的 Podman 作为容器引擎来运行集群节点,需注意集群具有与标准 Docker 容器相同的网络限制。虽然这些限制不会妨碍从本地主机测试 KinD Kubernetes 集群,但当尝试从网络中的其他机器测试容器时,可能会引发一些问题。
Podman 超出了本书的讨论范围,它被提及是因为 KinD 现在支持它作为替代选择。从高层次来看,Podman 是 Red Hat 的一个开源产品,旨在替代 Docker 作为运行时引擎。它在许多企业用例中具有相对于 Docker 的优势,如增强的安全性、不需要系统守护进程等。虽然它有一些优势,但对于刚接触容器技术的人来说,也可能增加复杂性。
当你在 Docker 主机上安装 KinD 时,将创建一个新的 Docker 桥接网络,名为 kind。这种网络配置是在 KinD v0.8.0 中引入的,解决了之前版本中使用默认 Docker 桥接网络的多个问题。大多数用户可能不会注意到这一变化,但了解它很重要;当你开始创建带有额外容器的更高级的 KinD 集群时,可能需要运行在与 KinD 相同的网络上。如果你需要在 KinD 网络上运行额外的容器,你需要在 docker run 命令中添加 --net=kind 参数。
除了 Docker 网络的考虑,我们还必须考虑 Kubernetes 的 CNI。KinD 支持多种不同的 CNI,包括 Kindnet、Calico、Cilium 等。官方支持的唯一 CNI 是 Kindnet,但你可以选择禁用默认的 Kindnet 安装,这将创建一个没有 CNI 的集群。在集群部署后,你需要部署 CNI,如 Calico。由于在小型开发集群和企业集群的许多 Kubernetes 安装中,Tigera 的 Calico 被用作 CNI,我们选择在本书的练习中使用它作为 CNI。
跟踪嵌套的“套娃”
像 KinD 这样基于容器套容器的解决方案的部署可能会让人感到困惑。我们将其比作俄罗斯套娃的概念,一层套一层。使用 KinD 创建集群时,你可能会迷失在主机、Docker 和 Kubernetes 节点之间的通信路径中。为了保持清晰和理智,深入理解每个容器的位置以及如何与它们交互是至关重要的。
图2.6显示了 KinD 集群的三层结构和网络流。重要的是要认识到,每一层只能与其正上方的一层进行交互,因此第三层中的 KinD 容器只能与第二层中运行的 Docker 镜像通信,而 Docker 镜像只能访问在第一层运行的 Linux 主机。如果你希望在主机和 KinD 集群内运行的容器之间建立直接通信,你需要先通过 Docker 层,然后才能到达第三层中的 Kubernetes 容器。
理解这一点非常重要,这样你才能有效地将 KinD 用作测试环境:
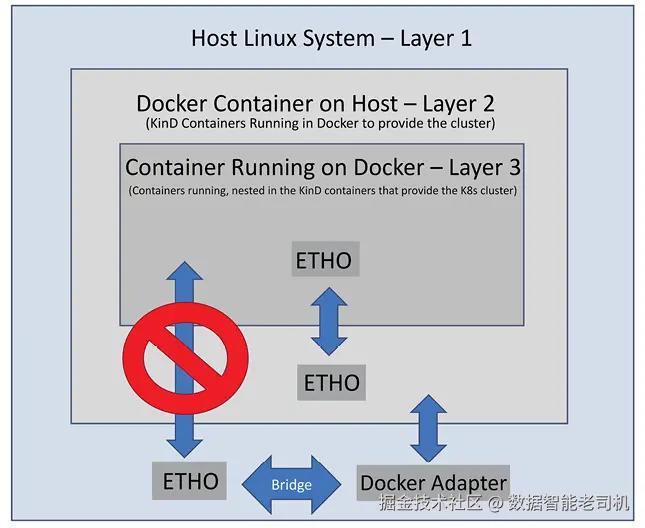
假设你打算将一个Web服务器部署到你的Kubernetes集群中作为示例。在成功在KinD集群中部署了Ingress控制器之后,你想在Docker主机或网络中的其他工作站上使用Chrome测试该网站。然而,当你尝试通过端口80访问主机时,浏览器无法建立连接。为什么会出现这个问题?
问题的原因在于,Web服务器的Pod运行在第3层,无法直接接收来自主机或网络机器的流量。要从主机访问Web服务器,你必须将流量从Docker层转发到KinD层。具体来说,你需要为端口80和端口443启用端口转发。当容器在指定端口启动时,Docker守护进程将负责将来自主机的传入流量路由到正在运行的Docker容器。
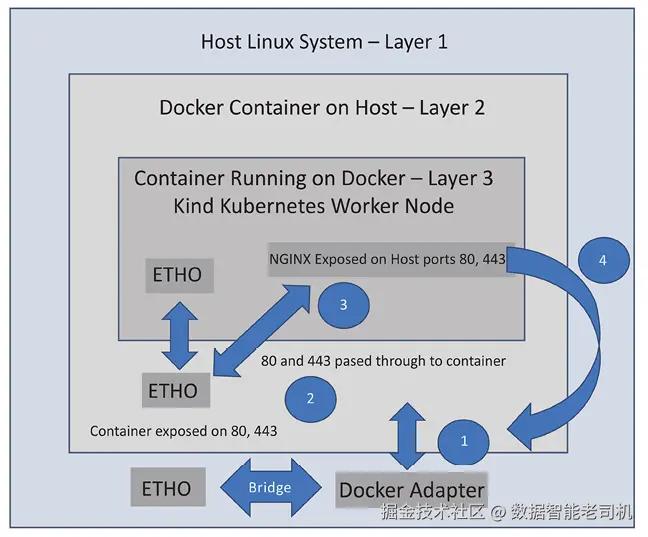
当Docker容器暴露了80和443端口后,Docker守护进程现在将接受针对端口80和443的传入请求,从而允许NGINX Ingress控制器接收流量。这之所以有效,是因为我们在两个地方暴露了80和443端口,首先是在Docker层,然后是在Kubernetes层,通过在主机上运行我们的NGINX控制器,并使用端口80和443。
现在,让我们来看一下这个示例中的流量流向。
在主机上,你对在Kubernetes集群中有Ingress规则的Web服务器发出请求:
- 请求查看请求的IP地址(在本例中是本地IP地址),然后将流量发送到在主机上运行的Docker容器。
- 运行Kubernetes节点的Docker容器上的NGINX Web服务器监听端口80和443的IP地址,因此请求被接受并发送到正在运行的容器。
- Kubernetes集群中的NGINX Pod已配置为使用主机的80和443端口,因此流量被转发到Pod。
- 用户通过NGINX Ingress控制器从Web服务器接收到请求的网页。
这有点复杂,但随着你对KinD的使用和交互越来越多,这个过程会变得更加简单。
为了使用KinD集群来满足你的开发需求,了解KinD的工作原理非常重要。到目前为止,你已经了解了节点镜像及其在集群创建中的作用。你还熟悉了Docker主机与运行在KinD中的集群容器之间的网络流量流向。拥有这些基础知识后,我们将进入创建Kubernetes集群的第一步:安装KinD。
安装 KinD
在撰写本文时,当前版本的 KinD 是 0.22.0,支持的 Kubernetes 集群版本最高为 1.30.x。
部署 KinD 以及我们将在各章中使用的集群组件所需的文件位于仓库的 chapter2 文件夹下。位于 chapter2 目录根目录中的脚本 create-cluster.sh 将执行本章其余部分讨论的所有步骤。阅读本章时,你无需立即执行命令;你可以按照这些步骤进行,但在执行仓库中的安装脚本之前,必须删除已部署的任何 KinD 集群。
部署脚本包含内联注释来解释每个步骤;不过,我们将在下一节中详细解释安装过程中的每一步。
安装 KinD – 前置条件
安装 KinD 有多种方法,但最简单和最快的方式是下载 KinD 二进制文件以及标准的 Kubernetes kubectl 可执行文件,以便与集群进行交互。
安装 kubectl
由于 KinD 是一个单独的可执行文件,它不会安装 kubectl。如果你还没有安装 kubectl,并且使用的是 Ubuntu 22.04 系统,可以通过运行 snap 命令来安装,或者直接从 Google 下载。
要使用 snap 安装 kubectl,你只需要运行以下命令:
css 代码解读复制代码sudo snap install kubectl --classic
要直接从 Google 安装 kubectl,你需要下载二进制文件,赋予它执行权限,并将其移动到系统路径中的位置。可以按照以下步骤完成:
bash 代码解读复制代码curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
从上面的 curl 命令可以看出,初始 URL 用于查找当前的发布版本,在撰写本文时为 v1.30.0。使用 curl 命令返回的值,我们从 Google 存储下载该版本。
现在你已经安装了 kubectl,我们可以继续下载 KinD 可执行文件,以便开始创建集群。
安装 KinD 二进制文件
现在我们已经有了 kubectl,接下来需要下载 KinD 二进制文件,它是一个用于创建和删除集群的可执行文件。可以通过以下URL直接下载 KinD v0.22.0 的二进制文件:
github.com/kubernetes-…。
create-cluster.sh 脚本将下载二进制文件,将其重命名为 kind,标记为可执行文件,并将其移动到 /usr/bin。要手动下载 KinD 并将其移动到 /usr/bin,可以执行以下命令:
bash 代码解读复制代码curl -Lo ./kind https://github.com/kubernetes-sigs/kind/releases/download/v0.22.0/kind-linux-amd64
chmod +x ./kind
sudo mv ./kind /usr/bin
KinD 可执行文件提供了维护集群生命周期所需的所有选项。除了创建和删除集群,KinD 还具备以下功能:
- 可以创建自定义构建基础镜像和节点镜像
- 可以导出
kubeconfig或日志文件 - 可以检索集群、节点或
kubeconfig文件 - 可以将镜像加载到节点中
成功安装 KinD 二进制文件后,你即将创建第一个 KinD 集群。
由于本书中的一些练习还需要其他一些可执行文件,脚本还会下载 Helm 和 jq。要手动下载这些工具,你可以执行以下命令:
bash 代码解读复制代码curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
sudo snap install jq --classic
如果你是这些工具的新手,Helm 是一个 Kubernetes 包管理器,旨在简化应用程序和服务的部署和管理过程。它简化了在集群中创建、安装和管理应用程序的过程。另一方面,jq 允许你从文件、命令输出和API中提取、过滤、转换和格式化 JSON 数据。它提供了一组功能来处理 JSON 数据,便于数据操作和分析。
现在我们已经准备好所有前置条件,可以开始创建集群了。不过,在创建第一个集群之前,了解 KinD 提供的各种创建选项非常重要。了解这些选项可以确保集群创建过程的顺利进行。
创建一个 KinD 集群
KinD 工具提供了创建单节点集群的灵活性,也支持更复杂的设置,如多个控制平面节点和工作节点。在本节中,我们将深入探讨 KinD 可执行文件提供的各种选项。本章结束时,你将拥有一个完全可操作的双节点集群,包括一个控制平面节点和一个工作节点。
注意
Kubernetes 集群的概念,包括控制平面和工作节点,将在下一章《第3章:Kubernetes 训练营》中详细介绍。
在本书的练习中,我们将设置一个多节点集群。下一节提供的简单集群配置仅作为入门示例,不适用于本书中的练习。
创建一个简单集群
我们将在本章稍后创建一个集群,但在此之前,先解释一下如何使用 KinD 创建不同类型的集群。
要创建一个简单的集群,其中控制平面和工作节点运行在一个容器中,你只需使用 create cluster 选项执行 KinD 可执行文件。
执行此命令后,将创建一个名为 kind 的集群,其中包含所有必要的 Kubernetes 组件,并运行在一个 Docker 容器中。该 Docker 容器将被命名为 kind-control-plane。如果你想为集群指定自定义名称,而不是使用默认名称,可以在 create cluster 命令中添加 --name <集群名称> 选项,例如:kind create cluster --name custom-cluster。
输出示例:
vbscript 代码解读复制代码Creating cluster "kind" ...
Ensuring node image (kindest/node:v1.30.0)
Preparing nodes
Writing configuration
Starting control-plane
Installing CNI
Installing StorageClass
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community
create 命令会创建集群并修改 kubectl 配置文件。KinD 会将新集群添加到当前的 kubectl 配置文件中,并将新集群设置为默认上下文。如果你对 Kubernetes 及其上下文的概念不熟悉,上下文是用于访问集群和命名空间的一组凭据配置。
集群部署完成后,你可以使用 kubectl get nodes 命令列出节点,验证集群是否成功创建。该命令会返回集群中的运行节点,对于一个基本的 KinD 集群,通常是单节点:
代码解读复制代码NAME STATUS ROLES AGE VERSION kind-control-plane Ready control-plane,master 32m v1.30.0
部署这个单节点集群的主要目的是展示 KinD 如何快速创建一个可用于测试的集群。对于我们的练习,我们希望将控制平面和工作节点分开,因此可以按照下一节中的步骤删除此集群。
删除集群
当你不再需要集群时,可以使用 KinD delete cluster 命令将其删除。该命令会快速删除集群,包括 kubeconfig 文件中与 KinD 集群相关的任何条目。
如果你在执行 delete 命令时没有提供集群名称,它将尝试删除名为 kind 的集群。在前面的示例中,我们在创建集群时没有提供集群名称,因此使用了默认名称 kind。如果在创建集群时命名了集群,则删除命令需要使用 --name 选项来删除正确的集群。例如,如果我们创建了一个名为 cluster01 的集群,删除它的命令为:kind delete cluster --name cluster01。
虽然快速创建的单节点集群对于许多用例来说很有用,但你可能需要创建一个多节点集群来进行各种测试场景。要创建更复杂的多节点集群,需使用配置文件。
创建集群配置文件
在创建多节点集群时,例如带有自定义选项的双节点集群,我们需要创建一个集群配置文件。该配置文件是一个 YAML 文件,其格式应该是熟悉的。在此文件中设置值可以自定义 KinD 集群,包括节点数量、API 选项等。我们用于本书集群的配置文件如下所示——它包含在本书的仓库中,路径为 /chapter2/cluster01-kind.yaml:
yaml 代码解读复制代码kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
runtimeConfig:
"authentication.k8s.io/v1beta1": "true"
"admissionregistration.k8s.io/v1beta1": true
featureGates:
"ValidatingAdmissionPolicy": true
networking:
apiServerAddress: "0.0.0.0"
disableDefaultCNI: true
apiServerPort: 6443
podSubnet: "10.240.0.0/16"
serviceSubnet: "10.96.0.0/16"
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 2379
hostPort: 2379
extraMounts:
- hostPath: /sys/kernel/security
containerPath: /sys/kernel/security
- role: worker
extraPortMappings:
- containerPort: 80
hostPort: 80
- containerPort: 443
hostPort: 443
- containerPort: 2222
hostPort: 2222
extraMounts:
- hostPath: /sys/kernel/security
containerPath: /sys/kernel/security
以下表格提供了文件中每个自定义选项的详细信息:
| 配置选项 | 选项详情 |
|---|---|
| apiServerAddress | 此配置选项告诉安装程序 API 服务器将监听的 IP 地址。默认情况下,它使用 127.0.0.1,但由于我们计划从其他联网设备访问集群,因此设置为监听所有 IP 地址。 |
| disableDefaultCNI | 此设置用于启用或禁用 Kindnet 安装。默认值为 false,但由于我们想使用 Calico 作为 CNI,因此需要将其设置为 true。 |
| podSubnet | 设置将由 Pod 使用的 CIDR 范围。 |
| serviceSubnet | 设置将由服务使用的 CIDR 范围。 |
| Nodes | 此部分定义集群的节点。在我们的集群中,我们将创建一个控制平面节点和一个工作节点。 |
| - role: control-plane | 此角色部分允许为节点设置选项。第一个角色部分是控制平面。 |
| - role: worker | 这是第二个节点部分,允许你配置工作节点使用的选项。由于我们将部署 Ingress 控制器,因此我们添加了 NGINX Pod 将使用的额外端口。 |
| extraPortMappings | 要将端口暴露给 KinD 节点,需要将它们添加到配置的 extraPortMappings 部分。每个映射有两个值:容器端口和主机端口。主机端口是用于访问集群的端口,而容器端口是容器监听的端口。 |
表 2.1:KinD 配置选项
了解可用的选项可以根据你的具体需求自定义 KinD 集群。这包括集成高级组件,如 Ingress 控制器,它可以有效地将外部流量路由到集群内的服务中。它还提供了在集群中部署多个节点的能力,使你能够进行测试和故障恢复操作,以确保集群的弹性和稳定性。利用这些功能,你可以微调集群以满足应用程序和基础设施的确切需求。
现在你已经了解如何创建一个用于运行集群的简单集成容器以及使用配置文件创建多节点集群,接下来我们将讨论一个更复杂的集群示例。
多节点集群配置
如果你只想创建一个不带额外选项的多节点集群,可以创建一个简单的配置文件,列出你想要的节点数量和节点类型。以下示例配置文件将创建一个包含三个控制平面节点和三个工作节点的集群:
yaml 代码解读复制代码kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: control-plane
- role: control-plane
- role: worker
- role: worker
- role: worker
引入多个控制平面服务器会增加复杂性,因为 kubectl 配置文件只能针对单个主机或IP。为了使该解决方案能够跨所有三个控制平面节点工作,需要在集群前部署一个负载均衡器。该负载均衡器将有助于将控制平面流量分发到控制平面服务器。需要注意的是,默认情况下,HAProxy 不会在工作节点之间进行负载均衡。要对工作节点进行流量负载均衡则更加复杂,我们将在本章后面讨论。
KinD 已考虑到这一点,如果你部署多个控制平面节点,安装程序将创建一个额外的容器运行 HAProxy 负载均衡器。在创建多节点集群时,你会看到有关配置额外负载均衡器、加入其他控制平面节点和额外工作节点的几行输出,如以下示例所示,我们使用示例集群配置创建了一个包含三个控制平面和工作节点的集群:
sql 代码解读复制代码Creating cluster "multinode" ...
Ensuring node image (kindest/node:v1.30.0)
Preparing nodes
Configuring the external load balancer
Writing configuration
Starting control-plane
Installing StorageClass
Joining more control-plane nodes
Joining worker nodes
Set kubectl context to "kind-multinode"
You can now use your cluster with:
kubectl cluster-info --context kind-multinode
Thanks for using kind!
在上面的输出中,你会看到一行“Configuring the external load balancer”。此步骤部署了一个负载均衡器,将传入的 API 服务器流量路由到三个控制平面节点。
如果查看来自多节点控制平面配置的运行容器,会看到六个节点容器和一个 HAProxy 容器:
| 容器 ID | 镜像 | 端口 | 名称 |
|---|---|---|---|
| d9107c31eedb | kindest/haproxy:haproxy | 0.0.0.0:6443 | multinode-external-load-balancer |
| 03a113144845 | kindest/node.30.0 | 127.0.0.1:44445->6443/tcp | multinode-control-plane3 |
| 9b078ecd69b7 | kindest/node.30.0 | multinode-worker2 | |
| b779fa15206a | kindest/node.30.0 | multinode-worker | |
| 8171baafac56 | kindest/node.30.0 | 127.0.0.1:42673->6443/tcp | multinode-control-plane |
| 3ede5e163eb0 | kindest/node.30.0 | 127.0.0.1:43547->6443/tcp | multinode-control-plane2 |
| 6a85afc27cfe | kindest/node.30.0 | multinode-worker3 |
表 2.2: KinD 配置选项
由于我们只有一个主机运行 KinD,每个控制平面节点和 HAProxy 容器必须运行在不同的端口上。为了启用传入请求,有必要将每个容器暴露在唯一的端口上,因为同一网络端口只能绑定到单个进程。在这种情况下,你可以看到 6443 端口分配给了 HAProxy 容器。如果你检查 Kubernetes 配置文件,你会发现它指向 https://0.0.0.0:6443,代表 HAProxy 容器分配的端口。
当使用 kubectl 执行命令时,它会直接发送到 6443 端口上的 HAProxy 服务器。通过 KinD 在集群创建时生成的配置文件,HAProxy 容器知道如何在三个控制平面节点之间路由流量,提供一个高可用的控制平面用于测试。
包含的 HAProxy 镜像是不可配置的。它仅用于处理控制平面并平衡控制平面 API 流量。由于此限制,如果你想为工作节点使用负载均衡器,则需要提供自己的负载均衡器。我们将在本章后面解释如何部署第二个 HAProxy 实例,用于在多个工作节点之间进行负载均衡。
一个典型的使用场景是跨多个工作节点使用 Ingress 控制器。在这种情况下,需要一个负载均衡器接受端口 80 和 443 上的传入请求,并将流量分配到各个工作节点,每个工作节点上运行一个 Ingress 控制器实例。在本章后面,我们将展示一个使用自定义 HAProxy 设置的配置,以在工作节点之间平衡流量。
你经常会发现自己创建的集群可能需要额外的 API 设置用于测试。下一节中,我们将展示如何为集群添加额外选项,包括添加 OIDC 值和启用功能开关等选项。
自定义控制平面和 Kubelet 选项
你可能希望超越简单集群来测试诸如 OIDC 集成或 Kubernetes 功能开关等功能。
OIDC 为 Kubernetes 提供通过 OpenID Connect 协议的身份验证和授权,基于用户身份实现对 Kubernetes 集群的安全访问。
在 Kubernetes 中,功能开关是用于启用实验性或 alpha 级功能的工具。它像一个开关,可以让管理员根据需要启用或禁用特定功能。
要实现这一点,你需要修改组件(如 API 服务器)的启动选项。KinD 使用与 kubeadm 安装相同的配置,允许你添加所需的任何可选参数。例如,如果你想将集群与 OIDC 提供程序集成,可以将所需的选项添加到配置补丁部分:
yaml 代码解读复制代码kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
metadata:
name: config
apiServer:
extraArgs:
oidc-issuer-url: "https://oidc.testdomain.com/auth/idp/k8sIdp"
oidc-client-id: "kubernetes"
oidc-username-claim: sub
oidc-client-id: kubernetes
oidc-ca-file: /etc/oidc/ca.crt
nodes:
- role: control-plane
- role: control-plane
- role: control-plane
- role: worker
- role: worker
- role: worker
这只是部署 KinD 集群时可以进行自定义的一个小例子。要查看可用的配置选项列表,请访问 Kubernetes 网站上的使用 kubeadm 自定义控制平面配置页面。
现在你已经创建了集群文件,接下来我们讨论如何使用配置文件创建 KinD 集群。
创建自定义 KinD 集群
终于到了!现在你已经熟悉了 KinD,我们可以继续创建集群。
我们需要创建一个受控的已知环境,因此我们将为集群指定名称,并提供一个集群配置文件。
在开始之前,请确保你位于克隆的仓库中的 chapter2 目录。你将使用我们提供的脚本 create-cluster.sh 创建整个集群。
该脚本将使用名为 cluster01-kind.yaml 的配置文件创建一个集群,集群名称为 cluster01,包括一个控制平面和一个工作节点,并在工作节点上暴露端口 80 和 443 以供 Ingress 控制器使用。
我们没有在本章中列出每一步的细节,因为我们已经在脚本中进行了记录。你可以查看脚本的源代码,了解每一步的具体作用。以下是脚本执行的步骤概要列表:
- 下载 KinD v 0.22.0 二进制文件,将其设置为可执行文件并移动到
/usr/bin。 - 下载
kubectl,设置为可执行文件并移动到/usr/bin。 - 下载 Helm 安装脚本并执行。
- 安装
jq。 - 使用配置文件执行 KinD 创建集群,并声明要使用的镜像(我们这样做是为了避免与新版本以及本章脚本的兼容性问题)。
- 为 Ingress 标签工作节点。
- 使用
chapter2/calico中的custom-resources.yaml和tigera-operator.yaml清单部署 Calico。 - 使用
chapter2/nginx-ingress目录中的nginx-deploy.yaml清单部署 NGINX Ingress。
步骤 7 和 8 中使用的清单是来自 Calico 和 NGINX-Ingress 项目的标准部署清单。我们将它们存储在仓库中以加快部署速度,同时避免由于这些部署的更新选项可能导致 KinD 集群失败的问题。
恭喜!你现在拥有一个运行 Calico 和 Ingress 控制器的双节点 Kubernetes 集群。
检查你的 KinD 集群
现在你已经有了一个功能完整的 Kubernetes 集群,我们可以深入了解几个关键的 Kubernetes 对象,特别是存储对象。在下一章《Kubernetes 训练营》中,我们将深入探讨集群中的其他对象。虽然那一章会详细介绍集群中的大量对象,但此时介绍与存储相关的对象是很重要的,因为 KinD 提供了存储功能。
在本节中,我们将熟悉在 KinD 中无缝集成的存储对象。这些专为存储而设计的对象为集群中的工作负载扩展了持久存储能力,确保数据的持久性和弹性。通过熟悉这些存储对象,我们为在 Kubernetes 生态系统中无缝管理数据奠定了基础。
KinD 存储对象
请记住,KinD 包含 Rancher 的自动提供器,用于为集群提供自动化的持久磁盘管理。Kubernetes 具有多个存储对象,但自动提供器不需要其中的一个对象,因为它使用了 Kubernetes 的基础功能:CSIdriver 对象。由于使用本地主机路径作为 PVC(PersistentVolumeClaim)是 Kubernetes 的一部分,因此我们在 KinD 集群中不会看到任何本地存储的 CSIdriver 对象。
我们在 KinD 集群中讨论的第一个对象是 CSInodes。任何能够运行工作负载的节点都将有一个 CSInode 对象。在我们的 KinD 集群中,两个节点都有一个 CSInode 对象,你可以通过执行 kubectl get csinodes 来验证这一点:
代码解读复制代码NAME DRIVERS AGE cluster01-control-plane 0 20m cluster01-worker 0 20m
如果我们使用 kubectl describe csinodes 命令描述其中一个节点,你会看到该对象的详细信息:
yaml 代码解读复制代码Name: cluster01-worker
Labels:
需要重点指出的是输出的 Spec 部分。此部分列出了支持后端存储系统的任何已安装驱动程序的详细信息。在驱动程序部分,你会看到名为 csi.tigera.io 的驱动程序条目,该驱动程序是在我们安装 Calico 时部署的。此驱动程序由 Calico 使用,以便在 Calico 的 Felix(负责网络策略执行)和 Dikastes 之间启用安全连接,Dikastes 通过挂载共享卷管理 Kubernetes 网络策略的翻译和执行 pod。
需要注意的是,此驱动程序并未用于标准的 Kubernetes 持久存储部署。
由于本地提供器不需要驱动程序,因此我们不会在集群中看到用于本地存储的额外驱动程序。
存储驱动程序
在 Kubernetes 中,存储驱动程序扮演着重要角色,负责处理容器化应用与底层存储基础设施之间的通信。其主要功能是控制存储资源的供应、附加和管理,以支持部署在 Kubernetes 集群中的应用。
正如前面提到的,你的 KinD 集群不需要为本地提供程序安装额外的存储驱动程序,但我们确实有一个用于 Calico 通信的驱动程序。如果你执行 kubectl get csidrivers,你将看到列表中的 csi.tigera.io。
KinD 存储类
要附加到任何由集群提供的存储,集群需要一个 StorageClass 对象。Rancher 的提供程序创建了一个名为 standard 的默认存储类,并将其设置为默认的 StorageClass,因此你不需要在 PVC 请求中提供 StorageClass 名称。如果没有设置默认的 StorageClass,那么每个 PVC 请求都需要在请求中指定 StorageClass 名称。如果默认类未启用且 PVC 请求未能设置 StorageClass 名称,PVC 分配将失败,因为 API 服务器无法将请求与 StorageClass 关联。
在生产集群中,建议避免设置默认的 StorageClass。这种做法有助于防止部署时忘记指定类的潜在问题,避免默认存储系统无法满足部署需求的情况。此类问题可能只有在生产环境中变得至关重要时才会暴露,影响业务收入和声誉。不分配默认类可以让开发者在 PVC 请求失败时更快地发现问题,避免对业务造成负面影响。此外,这种方法鼓励开发人员明确选择符合性能要求的 StorageClass,从而使用具有成本效益的存储系统来支持非关键系统,或为关键工作负载提供高速存储。
要列出集群上的存储类,可以执行 kubectl get storageclasses 或使用缩写 sc 来代替 storageclasses:
lua 代码解读复制代码NAME ATTACHREQUIRED PODINFOONMOUNT STORAGECAPACITY
csi.tigera.io true true false
现在你已经了解了 Kubernetes 用于存储的对象,接下来我们学习如何使用提供器。
使用 KinD 的存储提供器
使用包含的提供器非常简单。由于它可以自动提供存储并设置为默认类,任何进入的 PVC 请求都会被提供器 pod 看到,进而创建 PersistentVolume 和 PersistentVolumeClaim。
为了演示这一过程,让我们走过必要的步骤。以下是运行 kubectl get pv 和 kubectl get pvc 在基础 KinD 集群上的输出:
arduino代码解读复制代码kubectl get pv No resources found
PVs 是集群级别的资源,不是命名空间对象,因此我们不需要在命令中添加命名空间选项。PVCs 是命名空间对象,所以当我们告诉 Kubernetes 显示可用的 PV 时,我们需要使用 kubectl get pvc 命令指定命名空间。由于这是一个新集群,并且默认工作负载不需要持久磁盘,因此当前没有 PV 或 PVC 对象。
如果没有自动提供器,我们需要先创建一个 PV,PVC 才能申请该卷。由于我们集群中运行了 Rancher 提供器,我们可以通过部署带有 PVC 请求的 pod 来测试创建过程,如下所示的配置文件 pvctest.yaml:
yaml 代码解读复制代码kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Mi
此 PVC 的名称为 test-claim,在默认命名空间中,因为我们没有提供命名空间,卷大小设置为 1 MB。同样,由于 KinD 已为集群设置了默认的 StorageClass,因此我们不需要包含 StorageClass 选项。
要生成 PVC,我们可以执行 kubectl create -f pvctest.yaml 命令。Kubernetes 会通过确认创建 PVC 进行响应。然而,重要的是要理解这一确认并不保证 PVC 的完全功能。尽管 PVC 对象本身已成功创建,但 PVC 请求中的某些依赖项可能不正确或缺失。在这种情况下,虽然对象已创建,但 PVC 请求本身可能不会得到满足并可能失败。
创建 PVC 后,你可以通过以下两种方式之一检查其真实状态。第一种是使用简单的 get 命令,即 kubectl get pvc。由于我们的请求在默认命名空间中,因此不需要在 get 命令中包含命名空间值(注意,我们必须缩短卷的名称以适应页面):
objectivec 代码解读复制代码NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-claim Bound pvc-b6ecf50… 1Mi RWO standard 15s
我们知道通过提交 PVC 清单创建了一个 PVC 对象,但我们没有创建 PV 请求。如果现在查看 PV,我们可以看到从 PVC 请求创建了一个 PV。再次说明,为了适应输出的页面,我们缩短了 PV 名称:
objectivec 代码解读复制代码NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM
pvc-b6ecf… 1Mi RWO Delete Bound default/test-claim
鉴于越来越多的工作负载依赖于持久磁盘,了解 Kubernetes 工作负载如何与存储系统集成是很重要的。在上一节中,你了解到 KinD 如何通过自动提供器增强集群功能。在第 3 章《Kubernetes 训练营》中,我们将进一步加强对这些 Kubernetes 存储对象的理解。
在下一节中,我们将讨论使用 HAProxy 为我们的 KinD 集群启用高可用集群的复杂话题。
为 Ingress 添加自定义负载均衡器
我们添加了本节内容,以便对如何在多个工作节点之间进行负载均衡感兴趣的读者进一步了解相关内容。本节讨论了如何添加一个自定义的 HAProxy 容器,用于在 KinD 集群中的多个工作节点之间进行负载均衡。这一设置不应部署在本书接下来章节中使用的 KinD 集群上。
在大多数企业环境中,你将与负载均衡器进行交互,因此我们想添加一个关于如何为工作节点配置 HAProxy 容器的部分,旨在实现三节点的 KinD 集群之间的负载均衡。
首先,我们不会在本书的任何章节中使用此配置。为了确保所有读者都能参与实验,并限制所需的资源,我们将始终使用本章前面创建的双节点集群。如果你想测试带有负载均衡器的 KinD 节点,建议你使用不同的 Docker 主机,或者等到完成本书后再删除你的 KinD 集群进行测试。
创建 KinD 集群配置
我们提供了一个脚本 create-multinode.sh,位于 chapter2/HAdemo 目录中,该脚本将创建一个集群,其中包含三个控制平面节点和三个工作节点。脚本将创建一个名为 multinode 的集群,这意味着控制平面节点将命名为 multinode-control-plane、multinode-control-plane2 和 multinode-control-plane3,而工作节点将命名为 multinode-worker、multinode-worker2 和 multinode-worker3。
由于我们将在 Docker 主机上通过暴露端口 80 和 443 来使用一个 HAProxy 容器,因此在 KinD 配置文件中不需要暴露任何工作节点端口。我们在脚本中使用的配置文件如下所示:
yaml 代码解读复制代码kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
apiServerAddress: "0.0.0.0"
disableDefaultCNI: true
apiServerPort: 6443
podSubnet: "10.240.0.0/16"
serviceSubnet: "10.96.0.0/16"
nodes:
- role: control-plane
- role: control-plane
- role: control-plane
- role: worker
- role: worker
- role: worker
请注意,我们没有为 Ingress 暴露工作节点上的任何端口,因此无需直接在节点上暴露端口。部署 HAProxy 容器后,它将暴露在端口 80 和 443 上,由于它与 KinD 集群位于同一主机上,HAProxy 容器能够通过 Docker 网络与节点通信。
此时,你应该拥有一个正常工作的多节点集群,API 服务器和工作节点的负载均衡器也已部署。其中一个工作节点将运行 NGINX Ingress 控制器,但它可能运行在任意一个节点上,那么 HAProxy 服务器如何知道哪个节点在运行 NGINX 呢?它会对所有节点进行健康检查,任何返回 200(成功连接)的节点都会被添加到后端服务器列表中。
在下一节中,我们将解释 HAProxy 配置文件,展示如何控制后端服务器和执行健康检查。
HAProxy 配置文件
HAProxy 提供了一个可以在 Docker Hub 上部署的容器,它只需要一个配置文件即可启动。
要创建配置文件,你需要知道集群中每个工作节点的 IP 地址。我们提供的脚本将为你查找这些信息,创建配置文件并启动 HAProxy 容器。
由于许多人可能不熟悉 HAProxy 配置,因此我们将对脚本的主要部分进行解释。该脚本通过查询工作节点容器的 IP 地址来为我们创建配置文件:
bash 代码解读复制代码global
log /dev/log local0
log /dev/log local1 notice
daemon
defaults
log global
mode tcp
timeout connect 5000
timeout client 50000
timeout server 50000
frontend workers_https
bind *:443
mode tcp
use_backend ingress_https
backend ingress_https
option httpchk GET /healthz
mode tcp
server worker 172.18.0.8:443 check port 80
server worker2 172.18.0.7:443 check port 80
server worker3 172.18.0.4:443 check port 80
frontend stats
bind *:8404
mode http
stats enable
stats uri /
stats refresh 10s
frontend workers_http
bind *:80
use_backend ingress_http
backend ingress_http
mode http
option httpchk GET /healthz
server worker 172.18.0.8:80 check port 80
server worker2 172.18.0.7:80 check port 80
server worker3 172.18.0.4:80 check port 80
前端部分是配置的关键。它告诉 HAProxy 要绑定到的端口以及后端流量所使用的服务器组。让我们来看第一个前端条目:
bash 代码解读复制代码frontend workers_https
bind *:443
mode tcp
use_backend ingress_https
该配置将一个名为 workers_https 的前端绑定到 TCP 端口 443。最后一行 use_backend 告诉 HAProxy 哪个服务器组将接收 443 端口的流量。
接下来,我们声明后端服务器,即将运行工作负载的节点集合。第一个后端部分包含属于 workers_https 组的服务器。
vbscript 代码解读复制代码backend ingress_https
option httpchk GET /healthz
mode tcp
server worker 172.18.0.8:443 check port 443
server worker2 172.18.0.7:443 check port 443
server worker3 172.18.0.4:443 check port 443
第一行包含规则的名称,在我们的示例中,规则命名为 ingress_https。option httpchk 告诉 HAProxy 如何对每个后端服务器进行健康检查。如果检查成功,HAProxy 将其添加为健康的后端目标。如果检查失败,服务器将不会将任何流量发送到失败的节点。最后,我们提供了服务器列表;每个端点都有自己的行,从 server 开始,后跟名称、IP 地址和要检查的端口——在我们的示例中为 443 端口。
你可以使用类似的配置块为 HAProxy 平衡其他端口的流量。在脚本中,我们配置 HAProxy 监听 TCP 端口 80 和 443,并使用相同的后端服务器。
我们还添加了一个后端部分,用于公开 HAProxy 的状态页面。状态页面必须通过 HTTP 暴露,并运行在端口 8404 上。此状态页面不需要转发到任何服务器组,因为状态页面是 Docker 容器的一部分。我们只需将其添加到配置文件中,当我们执行 HAProxy 容器时,需要添加 8404 端口映射(你将在下一段描述的 docker run 命令中看到这一点)。我们将在下一节展示状态页面及其使用方法。
最后一步是启动一个 Docker 容器,该容器运行 HAProxy,使用我们创建的包含三个工作节点的配置文件,并在 Docker 主机上暴露端口 80 和 443,连接到 Docker 中的 KinD 网络:
ruby 代码解读复制代码# 启动工作节点的 HAProxy 容器
docker run --name HAProxy-workers-lb --network $KIND_NETWORK -d -p 8404:8404 -p 80:80 -p 443:443 -v ~/HAProxy:/usr/local/etc/HAProxy:ro haproxy -f /usr/local/etc/HAProxy/HAProxy.cfg
现在你已经了解了如何为工作节点创建和部署自定义 HAProxy 负载均衡器,接下来让我们看看 HAProxy 的通信原理。
理解 HAProxy 的流量流向
该集群将有总共 8 个运行的容器。其中 6 个容器是标准的 Kubernetes 组件——即 3 个控制平面服务器和 3 个工作节点。其他两个容器分别是 KinD 的 HAProxy 服务器和自定义的 HAProxy 容器(docker ps 输出已简化以便格式显示):
| 容器 ID | 名称 |
|---|---|
| 3d876a9f8f02 | Haproxy |
| HAProxy-workers-lb | |
| 183e86be2be3 | kindest/node.30.1 |
| multinode-worker3 | |
| ce2d2174a2ba | kindest/haproxy |
| multinode-external-load-balancer | |
| 697b2c2bef68 | kindest/node.30.1 |
| multinode-control-plane | |
| f3938a66a097 | kindest/node.30.1 |
| multinode-worker2 | |
| 43372928d2f2 | kindest/node.30.1 |
| multinode-control-plane2 | |
| baa450f8fe56 | kindest/node.30.1 |
| multinode-worker | |
| ee4234ff4333 | kindest/node.30.1 |
| multinode-control-plane3 |
表 2.3:集群中运行的八个容器
名为 HAProxy-workers-lb 的容器暴露在主机的端口 80 和 443 上。这意味着,任何发送到主机 80 或 443 端口的请求将被定向到自定义 HAProxy 容器,随后流量将发送到 Ingress 控制器。
默认的 NGINX Ingress 部署只有一个副本,这意味着控制器只运行在一个节点上,但它随时可能移动到其他节点。我们可以使用上一节提到的 HAProxy 状态页面来查看 Ingress 控制器当前运行的位置。使用浏览器,我们需要指向 Docker 主机的 IP 地址和端口 8404。在本示例中,主机的 IP 地址为 192.168.149.129,因此我们在浏览器中输入 http://192.168.149.129:8404,这将显示类似于下图所示的 HAProxy 状态页面(图 2.8)。
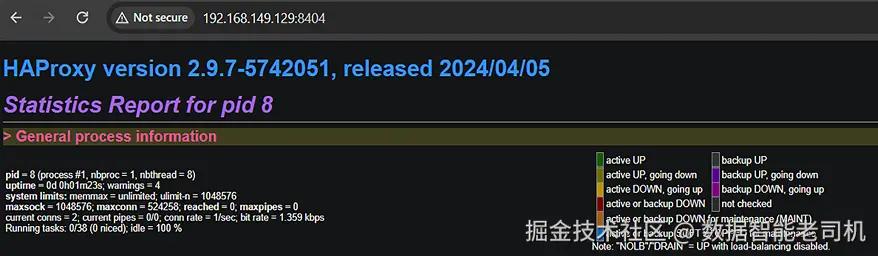
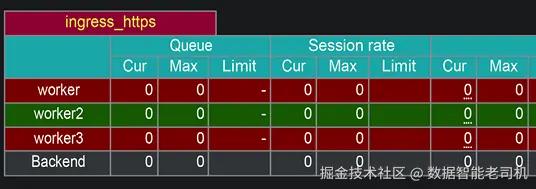
在状态页面的详细信息中,你将看到我们在 HAProxy 配置中创建的后端服务,以及每个服务的状态,包括哪个工作节点正在运行 Ingress 控制器。为了更详细地解释这一点,我们将重点关注传入的 SSL 流量详情。在状态页面上,我们将重点放在 ingress_https 部分,如图 2.9 所示。

在 HAProxy 配置中,我们创建了一个名为 ingress_https 的后端,其中包含集群中的所有工作节点。由于我们只运行了一个控制器副本,因此只有一个节点会运行 Ingress 控制器。在节点列表中,你会看到其中两个节点处于 DOWN 状态,而 worker2 处于 UP 状态。这是预期的结果,因为对于没有运行 Ingress 控制器副本的节点,HTTPS 的健康检查将会失败。
虽然在生产环境中我们会运行至少三个副本,但现在我们只有三个节点,目的是展示当 Ingress 控制器的 pod 从活动节点迁移到新节点时,HAProxy 如何更新后端服务。因此,我们将模拟一个节点故障,以证明 HAProxy 为我们的 NGINX Ingress 控制器提供高可用性。
模拟 kubelet 故障
在我们的例子中,我们希望证明 HAProxy 为 NGINX 提供高可用性支持。为了模拟故障,我们可以停止某个节点上的 kubelet 服务,这将通知 kube-apiserver 不再在该节点上调度任何其他 pod。我们知道当前运行的容器在 worker2 上,因此我们选择关闭该节点。
最简单的方式是发送 docker exec 命令到容器来停止 kubelet:
arduino代码解读复制代码docker exec multinode-worker2 systemctl stop kubelet
你不会看到该命令的输出,但等待几分钟后,集群将会收到更新的节点状态,你可以通过查看节点列表来验证节点是否已关闭:
arduino代码解读复制代码kubectl get nodes
你将看到如下输出:
css 代码解读复制代码NAME STATUS ROLES AGE VERSION
multinode-control-plane Ready control-plane 29m v1.30.0
multinode-control-plane2 Ready control-plane 29m v1.30.0
multinode-control-plane3 Ready control-plane 29m v1.30.0
multinode-worker Ready <none> 28m v1.30.0
multinode-worker2 NotReady <none> 28m v1.30.0
multinode-worker3 Ready <none> 28m v1.30.0
这证明我们成功模拟了 kubelet 故障,worker2 现在处于 NotReady 状态。
在 kubelet 故障之前运行的 pod 会继续运行,但 kube-scheduler 不会在该节点上调度任何新的工作负载,直到 kubelet 问题得到解决。由于我们知道 pod 不会在该节点上重新启动,因此我们可以删除该 pod,以便它可以在另一个节点上重新调度。
你需要获取 pod 名称,然后删除它以强制重新启动:
arduino代码解读复制代码kubectl get pods -n ingress-nginx
这将返回命名空间中的 pods,如下所示:
代码解读复制代码nginx-ingress-controller-7d6bf88c86-r7ztq
使用以下命令删除 Ingress 控制器 pod:
arduino 代码解读复制代码kubectl delete pod nginx-ingress-controller-7d6bf88c86-r7ztq -n ingress-nginx
这将强制调度器在另一个工作节点上启动容器。同时,HAProxy 容器会更新后端列表,因为 NGINX 控制器已迁移到另一个工作节点。
为了验证这一点,我们可以查看 HAProxy 状态页面,你会看到活动节点已更改为 worker3。由于我们模拟的故障发生在 worker2 上,当我们删除了该 pod 后,Kubernetes 将 pod 重新调度到另一个健康的节点上。
如果你打算继续使用这个高可用(HA)集群进行其他测试,那么你需要在 multinode-worker2 上重新启动 kubelet 服务。
如果你打算删除这个高可用集群,可以直接运行 KinD 集群删除命令,这样所有节点都会被删除。由于我们将集群命名为 multinode,因此你可以运行以下命令来删除 KinD 集群:
sql 代码解读复制代码bash
复制代码
kind delete cluster --name multinode
你还需要删除为工作节点部署的 HAProxy 容器,因为我们是通过 Docker 执行该容器,而不是通过 KinD 部署创建的。要清理工作节点的 HAProxy 部署,可以执行以下命令:
arduino代码解读复制代码bash 复制代码 docker stop HAProxy-workers-lb && docker rm HAProxy-workers-lb
至此,我们完成了这个 KinD 章节的内容!在本章中,我们提到了许多不同的 Kubernetes 服务,但实际上我们只是初步介绍了集群中包含的对象。在接下来的章节中,我们将进行一个关于集群组成组件的训练营,并概述集群中的基础对象。
总结
本章概述了 KinD 项目,这是一个由 Kubernetes SIG 维护的项目。我们讲解了如何在 KinD 集群中安装可选组件,如用于 CNI 的 Calico 和用于 Ingress 控制的 NGINX。此外,我们还探讨了 KinD 集群中包含的 Kubernetes 存储对象。
现在,你应该了解 KinD 带来的潜在优势。它提供了用户友好且高度可定制的 Kubernetes 集群部署,单个主机上能运行的集群数量仅受限于主机资源的可用性。
在下一章中,我们将深入探讨 Kubernetes 对象。我们将下一章称为 Kubernetes 训练营,因为它涵盖了大多数基本的 Kubernetes 对象及其用途。下一章可以被视为“Kubernetes 口袋指南”,提供了对 Kubernetes 对象及其功能的快速参考,并说明了何时使用它们。
这是一章内容丰富的章节,既可以作为有 Kubernetes 经验者的复习资料,也可以作为 Kubernetes 初学者的速成课程。通过这本书,我们的目标是深入探索基本 Kubernetes 对象之外的内容,因为市面上已经有许多书籍很好地介绍了 Kubernetes 的基础知识。
评论记录:
回复评论: