
一,NoSQL介绍
NoSQL(Not Only SQL)泛指非关系型数据库,用于解决传统关系型数据库(如MySQL、PostgreSQL)在大数据、高并发、灵活数据模型等场景下的局限性。NoSQL数据库通常具有高扩展性、高性能、灵活的数据模型等特点。
1.1 NoSQL的特点
| 特性 | 说明 |
|---|---|
| 灵活的数据模型 | 不需要预定义表结构,支持动态字段(如JSON、键值对、图结构等)。 |
| 高扩展性 | 支持水平扩展(通过分片、集群),适合海量数据存储。 |
| 高性能 | 优化读写速度,适合高并发场景(如缓存、实时分析)。 |
| 弱一致性(部分) | 部分NoSQL数据库采用最终一致性(如Cassandra),而非强一致性(如ACID)。 |
1.2 NoSQL 的常见类型
- 键值存储(Key-Value Store)
- 特点:最简单的NoSQL模型,数据以键值对(Key-Value)形式存储。
- 适用场景:缓存、会话存储、配置管理。
- 代表数据库:
- Redis(内存数据库,支持持久化)
- DynamoDB(AWS托管,自动扩展)
- Etcd(分布式键值存储,用于Kubernetes)
- 文档数据库(Document Store)
- 特点:存储半结构化数据(如JSON、XML),支持嵌套结构。
- 适用场景:内容管理、用户配置、日志存储。
- 代表数据库:
- MongoDB(最流行的文档数据库)
- CouchDB(支持离线同步)
- Firestore(Google的实时文档数据库)
- 列族存储(Column-Family Store)
- 特点:数据按列存储(而非行),适合大规模数据分析。
- 适用场景:日志分析、时序数据、大数据存储。
- 代表数据库:
- Cassandra(高可用、分布式)
- HBase(基于Hadoop,适合大数据)
- ScyllaDB(高性能,兼容Cassandra)
- 图数据库(Graph Database)
- 特点:以图(节点+边)存储数据,适合复杂关系分析。
- 适用场景:社交网络、推荐系统、欺诈检测。
- 代表数据库:
- Neo4j(最流行的图数据库)
- ArangoDB(多模型,支持图+文档)
- Dgraph(分布式图数据库)
1.3 NoSQL vs SQL(关系型数据库)
| 对比项 | NoSQL | SQL(关系型数据库) |
|---|---|---|
| 数据模型 | 灵活(无固定模式) | 固定表结构(Schema) |
| 扩展性 | 水平扩展(分布式) | 垂直扩展(单机优化) |
| 事务支持 | 部分支持(如MongoDB 4.0+) | 完整ACID事务(如MySQL) |
| 查询语言 | 无标准(各数据库不同) | SQL(标准化) |
| 适用场景 | 大数据、高并发、灵活数据 | 强一致性、复杂查询、事务需求 |
1.4 NoSQL 的典型应用场景
- 缓存加速(如Redis)
- 实时数据处理(如MongoDB存储日志)
- 社交网络关系(如Neo4j存储用户关系)
- 物联网时序数据(如Cassandra存储传感器数据)
- 内容管理系统(如Firestore存储动态内容)
1.5 如何选择 NoSQL 数据库
- 需要缓存? → Redis
- 存储JSON文档? → MongoDB
- 超大规模数据分析? → Cassandra/HBase
- 复杂关系分析? → Neo4j
- 需要ACID事务? → 考虑 SQL 或 MongoDB(4.0+支持事务)
二,Redis介绍
Redis诞生于2009年全称是Remote Dictionary Server,远程词典服务器,是一个基于内存的键值型NOSOL数据库
Redis特征:
- 数据结构多样性:Redis支持多种数据结构,包括字符串、哈希表、列表、集合、有序集合、位图等,这使得它非常灵活,能够应对各种不同的用例。
- 事务支持:Redis支持事务,允许将多个操作作为一个原子操作进行执行,这可以确保多个命令在一个事务中要么全部成功,要么全部失败。
- 内存存储:Redis将数据存储在内存中,因此读取速度非常快,适用于对响应时间要求严格的应用。
- 持久性:虽然Redis是内存数据库,但它支持数据持久化,可以将数据保存到磁盘,以防止数据丢失。Redis提供两种主要的持久化方式:RDB快照和AOF日志。
- 高可用性:Redis可以配置为具有主从复制,即一个主节点和多个从节点,以提供数据的备份和故障恢复。
- 支持多语言客户端
- 缓存:Redis常用于缓存层,用来加速读取频繁的数据,如数据库查询结果、API响应等。由于其高性能和低延迟特性,Redis非常适合作为缓存系统的组件。
- 集群:Redis支持集群模式,可以将数据分布在多个节点上,以提供更高的可扩展性和负载均衡。
Redis的使用场景包括但不限于缓存、实时分析、会话存储、排行榜、队列、发布/订阅系统等。
二,Redis客户端
2.1 Redis命令行客户端
Redis安装完成后就自带了命令行客户端: redis-cli,使用方式如下:
sh代码解读复制代码redis-cli [options] [commonds]
其中常见的options有:
-h 127.0.0.1指定要连接的redis节点的IP地址,默认是127.0.0.1-p 6379:指定要连接的redis节点的端口,默认是6379-a 123456指定redis的访问密码
其中commonds就是Redis的操作命令,例如:
ping与redis服务端做心跳测试,服务端正常就会返回pong- 不指定commond时,会进入
redis-cli的交互控制台
2.2 Redis图形化客户端
直接去Github仓库找即可:github.com/lework/Redi…
三,Redis常见命令
3.1 Redis的数据结构
Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样

3.2 Redis通用命令
-
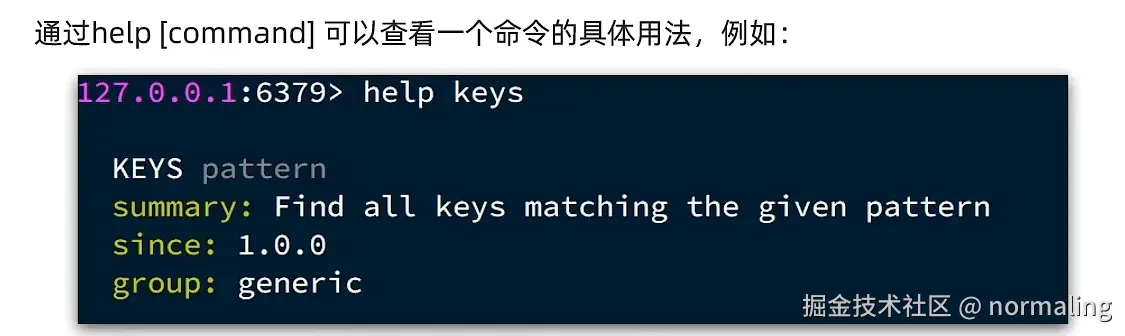
KEYS(查找匹配的 key)作用:查找符合模式的 key(生产环境慎用,可能导致性能问题)。
语法:
bash代码解读复制代码KEYS pattern示例:
bash代码解读复制代码# 插入测试数据 SET hello "world" SET hallo "redis" SET heello "example" # 查询单个字符匹配(? 代表一个字符) KEYS h?llo # 返回 hallo(匹配 h + 任意1字符 + llo) # 查询多个字符匹配(* 代表任意多个字符) KEYS h*llo # 返回 hello, hallo, heello(匹配 h + 任意字符 + llo) -
DEL(删除 key)作用:删除一个或多个 key。 语法:
bash代码解读复制代码DEL key [key ...]示例:
bash代码解读复制代码# 删除单个 key DEL hello # 删除 key="hello" # 删除多个 key DEL hallo heello -
EXISTS(检查 key 是否存在)作用:判断 key 是否存在(存在返回
1,不存在返回0)。 语法:bash代码解读复制代码EXISTS key示例:
bash代码解读复制代码EXISTS hello # 返回 1(存在)或 0(不存在) -
EXPIRE(设置 key 过期时间)作用:给 key 设置有效期(单位:秒),到期自动删除。 语法:
bash代码解读复制代码EXPIRE key seconds示例:
bash代码解读复制代码# 设置 key="temp_data" 10秒后过期 SET temp_data "test" EXPIRE temp_data 10 # 10秒后,temp_data 自动删除 -
TTL(查看 key 剩余存活时间)
markdown 代码解读复制代码 **作用**:返回 key 的剩余生存时间(单位:秒)。
markdown 代码解读复制代码 - `-2`:key 不存在
- `-1`:key 存在但没有设置过期时间
- `>=0`:剩余秒数
**语法**:
```bash
TTL key
```
**示例**:
```bash
TTL temp_data # 返回剩余秒数(如 5),或 -1/-2
```
6. SELECT(切换数据库)
go 代码解读复制代码 **作用**:Redis 默认有 16 个数据库(0-15),`SELECT` 用于切换。
**语法**:
```bash
SELECT index
```
**示例**:
```bash
SELECT 1 # 切换到数据库 1
SET db1_key "value_in_db1"
SELECT 0 # 切换回默认数据库 0
```
7. MOVE(移动 key 到另一个数据库)
go 代码解读复制代码 **作用**:将当前数据库的 key 移动到另一个数据库。
**语法**:
```bash
MOVE key db_index
```
**示例**:
```bash
# 将 key="mykey" 从当前数据库移动到数据库 2
MOVE mykey 2
```
8. RENAME(重命名 key)
vbnet 代码解读复制代码 **作用**:修改 key 的名称(如果新 key 已存在,会覆盖旧值)。
**语法**:
```bash
RENAME old_key new_key
```
**示例**:
```bash
SET old_name "redis"
RENAME old_name new_name # 修改 key 名
GET new_name # 返回 "redis"
```
9. TYPE(查看 key 的数据类型)
go 代码解读复制代码 **作用**:返回 key 存储的数据类型(如 `string`、`hash`、`list` 等)。
**语法**:
```bash
TYPE key
```
**示例**:
```bash
SET name "Alice"
TYPE name # 返回 "string"
LPUSH tasks "task1"
TYPE tasks # 返回 "list"
```
命令很简单,忘记了直接去查官方文档:Commands | Redis
通用命令一共分3类
- 查询:
keys,EXISTS,TTL,TYPE - 修改:
EXPIRE,RENAME,MOVE,SELECT - 删除:
DEL
四 Redis常用数据类型
4.1 String类型
String 类型是 Redis 最基础的数据结构,适用于 缓存、计数器、分布式锁 等场景,根据字符串的格式不同,又可以分为3类
- string:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。字符串类型的最大空间不能超过512m
String 的核心特性
- 灵活的数据格式:
- 普通字符串(如
"hello")。 - 数字(整型/浮点型,支持自增操作)。
- 二进制数据(如 ProtoBuf、JSON 序列化后的数据)。
- 普通字符串(如
- 高性能:所有操作时间复杂度均为
O(1)。 - 原子性操作:如
INCR、APPEND等命令是线程安全的。
String 的常见命令
-
基本操作
命令 作用 示例 SET key value设置键值对(覆盖旧值) SET username "Alice"GET key获取键的值 GET username→ 返回"Alice"DEL key删除键 DEL usernameEXISTS key检查键是否存在 EXISTS username→ 返回1或0示例:
bash代码解读复制代码SET greeting "Hello, Redis!" GET greeting # 返回 "Hello, Redis!" -
批量操作
命令 作用 示例 MSET key1 value1 key2 value2批量设置多个键值对 MSET k1 "v1" k2 "v2"MGET key1 key2批量获取多个键的值 MGET k1 k2→ 返回["v1", "v2"]示例:
bash代码解读复制代码MSET name "Bob" age 30 MGET name age # 返回 ["Bob", "30"] -
数字操作
命令 作用 示例 INCR key将整数值自增 1 INCR counter→1INCRBY key increment将整数值自增指定步长 INCRBY counter 5→6INCRBYFLOAT key increment将浮点数值自增指定步长 INCRBYFLOAT price 0.5DECR key将整数值自减 1 DECR stock→99示例:
bash代码解读复制代码SET views 100 INCR views # views = 101 INCRBY views 10 # views = 111 -
条件操作
命令 作用 示例 SETNX key value仅当键 不存在 时设置值 SETNX lock 1(实现分布式锁)SETEX key seconds value设置值并指定过期时间(秒) SETEX session 3600 "token"PSETEX key milliseconds value设置值并指定过期时间(毫秒) PSETEX temp 5000 "data"示例:
bash代码解读复制代码SETNX lock 1 # 如果 lock 不存在,则设置成功(返回 1) SETEX cache:user:1 60 "{...JSON数据...}" # 60秒后自动删除 -
字符串操作
命令 作用 示例 APPEND key suffix向字符串尾部追加内容 APPEND greeting "!!"→"Hello!!"STRLEN key获取字符串长度 STRLEN greeting→5GETRANGE key start end获取子字符串(支持负数索引) GETRANGE greeting 0 3→"Hell"SETRANGE key offset value替换字符串指定位置的内容 SETRANGE greeting 6 "Redis"示例:
bash代码解读复制代码SET msg "Hello" APPEND msg " World" # msg = "Hello World" GETRANGE msg 6 -1 # 返回 "World"
KEY的结构
Redis的key允许有多个单词形成层级结构,多个单词之间用:隔开,格式如下

例如我们的项目名称叫heima,有user和product两种不同类型的数据,我们可以这样定义key:
- user相关的key:
heima:user:1 - product相关的key:
heima:product:1
如果Value是一个ava对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:

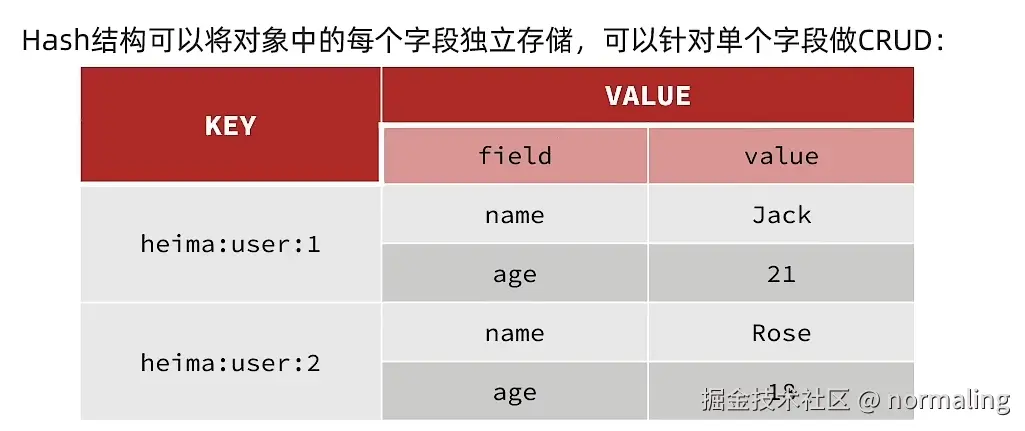
4.2 Hash类型
Hash(哈希)是Redis中一种字段-值(field-value)映射表结构,适合存储对象型数据(如用户信息、商品详情)。每个Hash可以存储 2³² - 1 个键值对(约40亿)。
核心特性
-
结构化存储:类似JSON对象,一个key对应多个field-value。
bash代码解读复制代码user:1 = { "name":"Alice", "age":25, "email":"[email protected]" } -
高效访问:单个字段的读写复杂度为
O(1)。 -
内存优化:多个字段共享同一个key,比多个String更省内存。
Hash的常用命令
-
基础操作
命令 作用 示例 HSET key field value设置字段值 HSET user:1 name "Alice"HGET key field获取字段值 HGET user:1 name→"Alice"HDEL key field删除字段 HDEL user:1 emailHEXISTS key field检查字段是否存在 HEXISTS user:1 age→1示例:
bash代码解读复制代码HSET product:100 name "iPhone" price 5999 stock 100 HGET product:100 price # 返回 "5999" -
批量操作
命令 作用 示例 HMSET key field1 value1 ...批量设置字段(旧版) HMSET user:2 name "Bob" age 30HMGET key field1 field2 ...批量获取字段值 HMGET user:2 name ageHGETALL key获取所有字段和值 HGETALL user:2示例:
bash代码解读复制代码HMSET employee:101 name "Charlie" department "IT" salary 8000 HMGET employee:101 name salary # 返回 ["Charlie", "8000"] -
数字操作
命令 作用 示例 HINCRBY key field increment整数字段自增 HINCRBY product:100 stock -1(库存-1)HINCRBYFLOAT key field increment浮点数字段自增 HINCRBYFLOAT account:1 balance 50.5示例:
bash代码解读复制代码HSET counter:page_views home 0 HINCRBY counter:page_views home 1 # home访问量+1 -
查询字段信息
命令 作用 示例 HKEYS key获取所有字段名 HKEYS user:1→["name", "age"]HVALS key获取所有字段值 HVALS user:1→["Alice", "25"]HLEN key获取字段数量 HLEN user:1→2
总结,Hash的命令与String的命令很类似,记忆方法是在前面加上H,而且Hash多了4个String没有的方法
HLEN:获取字段数量HGETALL:获取所有字段和值HKEYS:获取所有字段名HVALS:获取所有字段值
4.3 List类型
List 是 Redis 的 双向链表数据结构,支持在头部/尾部高效插入和删除元素,适合实现 栈、队列、消息流 等场景。
List 的核心特性
- 有序性:元素按插入顺序排列。
- 可重复:允许存储相同值。
- 操作高效:
- 头部/尾部操作:
O(1)时间复杂度。 - 中间操作(如按索引查询):
O(n)时间复杂度。
- 头部/尾部操作:
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等
List 常用命令
-
插入元素
命令 作用 示例 LPUSH key element在 列表头部 插入元素 LPUSH tasks "task1"RPUSH key element在 列表尾部 插入元素 RPUSH tasks "task2"LINSERT key BEFORE/AFTER pivot element在指定元素前/后插入 LINSERT tasks BEFORE "task2" "urgent"示例:
bash代码解读复制代码LPUSH messages "hello" # 列表: ["hello"] RPUSH messages "world" # 列表: ["hello", "world"] LINSERT messages BEFORE "world" "Redis" # 列表: ["hello", "Redis", "world"] -
删除元素
命令 作用 示例 LPOP key移除并返回 头部第一个元素 LPOP tasks→ 返回 "task1"RPOP key移除并返回 尾部最后一个元素 RPOP tasks→ 返回 "task2"LREM key count element删除指定值的元素( count=0删除所有匹配)LREM tasks 0 "spam"示例:
bash代码解读复制代码LPOP messages # 移除 "hello",列表剩余: ["Redis", "world"] LREM messages 1 "Redis" # 删除 1 个 "Redis",列表剩余: ["world"] -
查询元素
命令 作用 示例 LRANGE key start stop获取指定索引范围的元素(支持负数索引) LRANGE tasks 0 -1(获取全部)LINDEX key index获取指定位置的元素 LINDEX tasks 0→ 返回第一个元素LLEN key获取列表长度 LLEN tasks→ 返回元素数量示例:
bash代码解读复制代码LRANGE messages 0 -1 # 返回所有元素: ["world"] LINDEX messages 0 # 返回 "world" LLEN messages # 返回 1 -
阻塞操作(适合消息队列)
命令 作用 示例 BLPOP key timeout阻塞式弹出头部元素(列表为空时等待) BLPOP tasks 10(等待10秒)BRPOP key timeout阻塞式弹出尾部元素 BRPOP tasks 5适用场景:实现简单的消息队列(生产者-消费者模型)。
4.4 Set类型
Set(集合)是Redis中的无序、唯一元素集合,底层由哈希表实现,支持高效的添加、删除、查找操作(时间复杂度均为O(1))。每个Set最多可存储 2³² - 1 个元素(约40亿)。
核心特性
- 唯一性:自动去重,重复元素无法插入。
- 无序性:元素无固定顺序,但支持随机获取。
- 集合运算:支持并集(
SUNION)、交集(SINTER)、差集(SDIFF)。 - 高性能:所有操作均基于哈希表,效率极高。
Set的常用命令
-
基本操作
命令 作用 示例 SADD key member1 member2添加元素(自动去重) SADD tags "redis" "db"SREM key member删除指定元素 SREM tags "db"SMEMBERS key获取所有元素(无序) SMEMBERS tags→["redis"]SISMEMBER key member判断元素是否存在 SISMEMBER tags "redis"→1示例:
bash代码解读复制代码SADD fruits "apple" "banana" "orange" SMEMBERS fruits # 可能返回 ["apple", "banana", "orange"](无序) SREM fruits "banana" -
集合运算
命令 作用 示例 SINTER key1 key2返回多个集合的交集 SINTER set1 set2SUNION key1 key2返回多个集合的并集 SUNION set1 set2SDIFF key1 key2返回第一个集合的差集 SDIFF set1 set2SINTERSTORE dest key1 key2存储交集到新集合 SINTERSTORE result set1 set2示例:
bash代码解读复制代码SADD group1 "user1" "user2" "user3" SADD group2 "user2" "user3" "user4" SINTER group1 group2 # 返回 ["user2", "user3"] -
随机操作
命令 作用 示例 SPOP key [count]随机移除并返回元素(抽奖场景) SPOP prizes 1SRANDMEMBER key [count]随机返回元素(不删除) SRANDMEMBER users 2示例:
bash代码解读复制代码SADD raffle "ticket1" "ticket2" "ticket3" SPOP raffle # 随机抽出一个奖品(如 "ticket2") -
统计与移动
命令 作用 示例 SCARD key获取集合元素数量 SCARD tags→3SMOVE source dest member将元素移动到另一个集合 SMOVE set1 set2 "apple"
4.5 SortedSet类型
Sorted Set(有序集合,简称ZSET)是Redis中最灵活的数据结构之一,它结合了Set的去重特性和List的排序能力,每个元素关联一个分数(score),通过分数自动排序并支持范围查询。
核心特性
- 唯一性:成员(member)不可重复,但分数(score)可以重复。
- 有序性:按分数(score)从小到大排序(默认升序)。
- 高性能:
- 插入/删除/查找:
O(log N)(基于跳跃表实现)。 - 范围查询:
O(log N + M)(N是元素总数,M是返回数量)。
- 插入/删除/查找:
- 多用途:支持排名、排行榜、范围筛选等场景。
Sorted Set 常用命令
-
基本操作
命令 作用 示例 ZADD key score member添加/更新元素(分数可重复) ZADD leaderboard 100 "Alice"ZREM key member删除指定成员 ZREM leaderboard "Bob"ZSCORE key member获取成员的分数 ZSCORE leaderboard "Alice"→"100"ZINCRBY key increment member增加成员的分数 ZINCRBY leaderboard 50 "Alice"→150示例:
bash代码解读复制代码ZADD players 2000 "Carl" 1500 "Alice" 1800 "Bob" ZSCORE players "Alice" # 返回 "1500" -
查询操作
命令 作用 示例 ZRANGE key start stop [WITHSCORES]按升序返回排名范围内的成员 ZRANGE leaderboard 0 2(返回前3名)ZREVRANGE key start stop [WITHSCORES]按降序返回排名范围内的成员 ZREVRANGE leaderboard 0 2(返回Top3)ZRANGEBYSCORE key min max返回分数在[min, max]间的成员 ZRANGEBYSCORE players 1500 2000ZCOUNT key min max统计分数范围内的成员数量 ZCOUNT players 1500 2000→3示例:
bash代码解读复制代码ZADD hits 10 "page1" 20 "page2" 30 "page3" ZRANGE hits 0 -1 WITHSCORES # 返回所有成员及分数(升序) -
排名与统计
命令 作用 示例 ZRANK key member获取成员升序排名(从0开始) ZRANK players "Alice"→1ZREVRANK key member获取成员降序排名 ZREVRANK players "Alice"→2ZCARD key获取集合成员总数 ZCARD players→3示例:
bash代码解读复制代码ZREVRANK players "Alice" # 返回降序排名(如第2名) -
集合运算
命令 作用 示例 ZUNIONSTORE dest numkeys key1 key2并集存储到新集合 ZUNIONSTORE combined 2 set1 set2ZINTERSTORE dest numkeys key1 key2交集存储到新集合 ZINTERSTORE result 2 set1 set2
评论记录:
回复评论: