
ElasticSearch简介
Elaticsearch,简称为es, es是一个基于apache开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ElasticSearch应用方向
- 1- 信息检索
- 2- 企业内部系统搜索
- 3- 数据分析引擎:Elasticsearch 聚合可以对数十亿行日志数据进行聚合分析,探索数据的趋势和规律
ElasticSearch特点
1- 海量数据存储和处理:
大型分布式集群(数百台规模服务器)
处理PB级数据
也可以进行单机部署
2- 开箱即用:
简单易用, 操作非常简单
快速部署生产环境
3- 作为传统数据库的补充:
传统关系型数据库不擅长全文检索(MySQL自带的全文索引,与ES性能差距非常大)
传统关系型数据库无法支持搜索排名、海量数据存储、分析等功能
Elasticsearch可以作为传统关系数据库的补充,提供RDBMS无法提供的功能
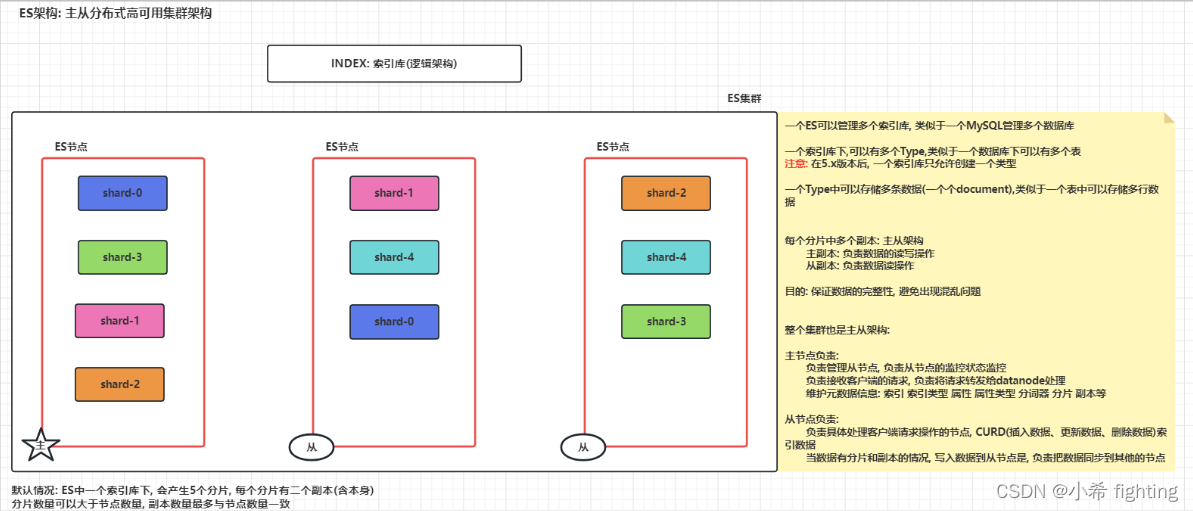
ElasticSearch架构及其基本概念
ES相关角色:
Master: 主节点
作用:
负责管理从节点, 负责从节点的监控状态监控
负责接收客户端的请求, 负责将请求转发给datanode处理
维护元数据信息: 索引 索引类型 属性 属性类型 分词器 分片 副本等
注意:
1- 集群架构可以分成分布式和单机版。单机版的时候,该节点既是主节点也是从节点
2- 当是分布式的时候,主节点是一个轻量级的节点,尽可能不会去存储数据,即使存储也只存放从副本,只负责数据的读
DataNode: 从节点
作用:
负责具体处理客户端请求操作的节点, CURD(插入数据、更新数据、删除数据)索引数据
当数据有分片和副本的情况, 写入数据到从节点时, 负责把数据同步到其他的节点
注意: 数据写入请求,会被发送到从节点,先写入到从节点中的主副本,再从主副本同步到其他从副本。也就是从节点上可能有主副本,也可能有从副本。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
ES与传统关系型数据库结构对比:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
- 1
- 2
ES中相关的专有名词:
index : 索引 表示索引库, 一个es下可以有多个索引库
settings : 主要对索引库分片 和副本的设置 , 默认 有 5分片 2副本
type : 在一个索引库下, 可以有多个type类型, 类似于在一个数据库中可以有多个表
注意: 目前新的版本中, 已经只允许创建一个type(_doc)
filed: 字段, 从一个type下可以有个字段, 类似于 在一个表中可以有一个列
mapping: 映射关系, 主要是对字段进行相关的设置的
比如: 字段类型 字段是否需要进行分词 字段的原始数据是否保存...
document: 文档, 表示的每一行的数据
cluster: 集群, es的集群
node: es的节点
shards : 分片 默认 一个索引库有 5个
replicas: 副本 默认 每一个分片 都有一个副本加上本身 为 2个
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Index索引创建完成以后,可以任意时间动态修改副本的数量;但是不能修改分片的数量
如果后续数量增大了,分片数量不够了如何解决?
1- 先创建一个具有更多分片的新Index索引库
2- 后续的新数据写入到这个新的Index索引库
3- 旧的Index索引库数据导入到新的Index索引库
- 1
- 2
- 3
- 4
- 5
ElasticSearch的安装
需要注意的是ES不支持root用户安装, 必须使用普通用户
问题: 解决单节点告警问题
由于当前ES为单节点, 在构建一个新的索引库的时候, 依然会产生多个分片和副本的情况(默认), 但是只有一个节点, 多余的副本就无法放置, ES会变为告警状态(黄色)
解决思路: 修改副本数量为1即可
curl -XPUT http://192.168.88.166:9200/_settings?pretty -d '{ "index": { "number_of_replicas": 0 } }' -H "Content-Type: application/json"
- 1
ES的基本使用
字段类型
- es的类型
- 基本数据类型:text | keywords => string
text是可以进行分词字符串类型
keywords是不能进行分词,
long,
float,
date,
binary - 地址位置相关的类型
geo_point,geo_shape - 分词器
分词器是针对一段文本,进行词的拆分方式 - 分词类型
standard analyse:英文分词器,标准分词器
IK analyse:一种中文分词器
JieBa:另外一种分词器
- 基本数据类型:text | keywords => string
- 完整数据类型
- https://www.elastic.co/guide/en/elasticsearch/reference/7.10/mapping-types.html
ES-SQL
ES SQL特点:
- 本地集成
- Elasticsearch SQL是专门为Elasticsearch构建的。每个SQL查询都根据底层存储对相关节点有效执行。
- 没有额外的要求
- 不依赖其他的硬件、进程、运行时库,Elasticsearch SQL可以直接运行在Elasticsearch集群上
- 轻量且高效
- 像SQL那样简洁、高效地完成查询
- 目前支持单表查询
SELECT select_expr [, ...]
[ FROM table_name ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count ] ]
[ PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] ) ) ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
es cli的官方指导文档:
- https://www.elastic.co/guide/en/elasticsearch/reference/7.10/sql-cli.html
- https://www.elastic.co/guide/en/elasticsearch/reference/7.10/sql-cli.html
- https://www.elastic.co/guide/en/elasticsearch/reference/7.10/sql-syntax-show-tables.html
- https://www.elastic.co/guide/en/elasticsearch/reference/7.10/sql-cli.html
- https://www.elastic.co/guide/en/elasticsearch/reference/7.10/sql-cli.html
-
es sql简单操作
- es-sql不适合做表关联查询
- es-sql开源版支持的功能有限
- 官方网站:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/sql-syntax-select.html
-
es只适合单表,大宽表存储,类似于hbase、mongo
ElasticSearch目前不支持对多表关联查询。

ES的Python代码编程
from elasticsearch import Elasticsearch
if __name__ == '__main__':
# 1- 创建ES连接
es = Elasticsearch(hosts=["192.168.88.166:9200"])
# 2- CRUD操作
# 新增数据
res = es.index(index="job_idx",id=1000001,body={"salary":"1000001"})
print(res)
# 更新数据
res = es.update(index="job_idx",id=1000001,body={"doc":{"salary":"1000002"}})
print(res)
# 查询
res = es.search(index="job_idx",body={"query": {"ids": {"values": ["1000001"]}}})
print(res)
# 删除
res = es.delete(index="job_idx",id=1000000)
print(res)
# 3- 释放资源
es.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
ES的相关原理
ES的写入数据的流程
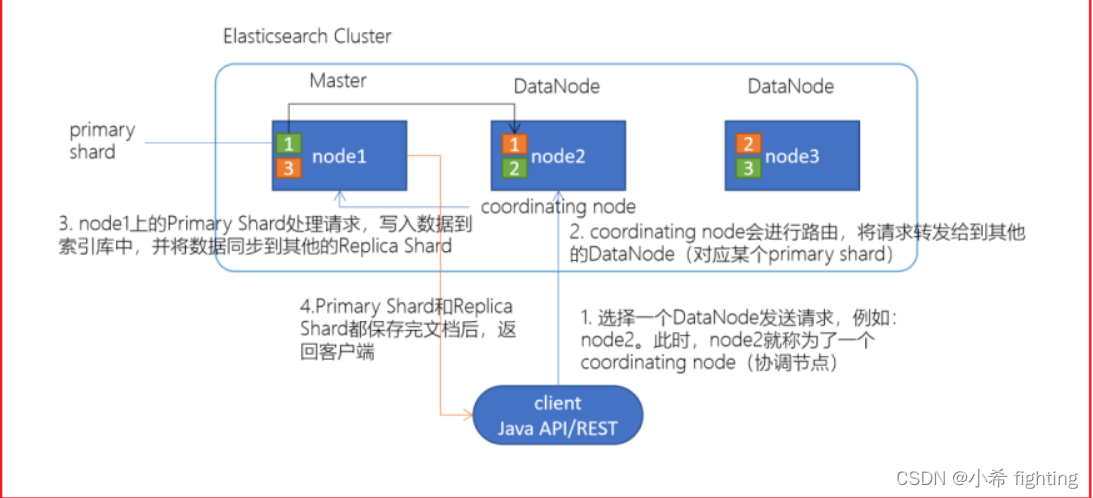
1- 客户端进行数据写入操作,随机连接一台节点。连接上谁,那么谁就成为了协调节点(coordinating node),并且也是该次请求的管理者
2- 协调节点计算当前写入的数据应该存放到哪个分片的主副本上,底层是基于文档ID的Hash取模方案
3- 判断成功以后,找到对应分片的主副本。如果该主副本就在当前协调节点,直接写入即可;如果不在当前节点,需要将请求转发给到对应的分片的主副本所在的节点
4- 对应的主副本节点接收到数据写入请求后,执行数据写入操作。写入成功以后并且将数据同步到其他从副本中
5- 当主副本和从副本都对数据同步完成以后,最终将写入成功的请求由协调节点返回给到客户端
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
ES的读取数据的流程
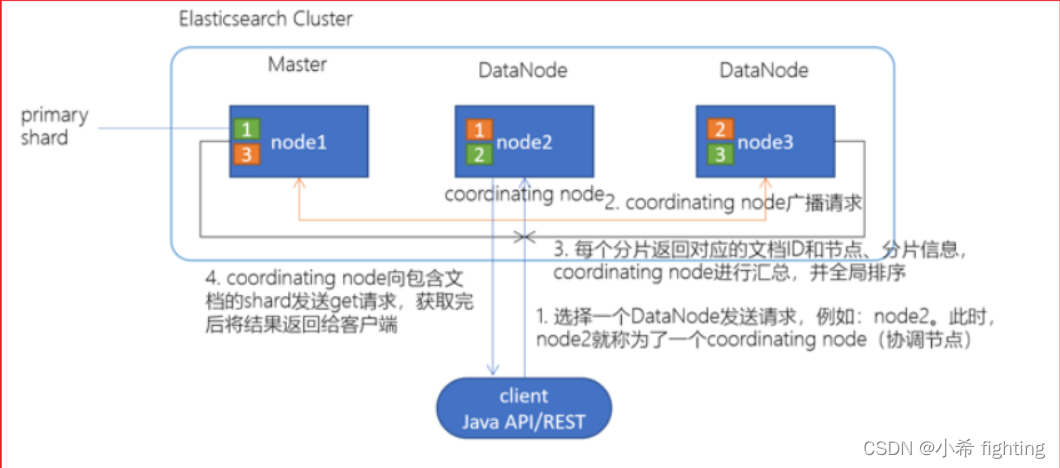
1- 客户端发送数据查询的请求,连接任意一台ES节点。连接上谁,谁就是协调节点(coordinating node),并且也是该次请求的管理者
2- 根据查询的方案:
2.1- 如果是基于文档ID的查询,此时会计算当前这个ID对应的数据存放在哪个分片上,接着将请求转发给到对应的分片的副本
2.2- 如果不是基于文档ID的查询,例如通过文本内容关键字查询,此时需要将该查询需求广播给到所有的节点,由各个节点查询自己服务器上的数据,并且将查询到的结果数据汇聚到协调节点
3- 由协调节点负责汇总数据,并且对数据进行排序操作,是全局降序排序
4- 最后将结果返回给到客户端
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
评论记录:
回复评论: