
一、什么是原子操作
原子操作(Atomic Operation)是指在多线程并发编程中,作为一个不可分割的单元执行的操作。无论操作过程中是否有其他线程或进程的干扰,它都会以整体的方式执行完毕。换句话说,原子操作在执行时要么完全完成,要么完全不做,过程中不会被中断,并且中间状态也不会暴露给其他线程。
原子操作的关键特点包括:
- 不可分割性:在执行过程中,操作不会被其他线程或进程打断。
- 一致性:无论操作的执行顺序如何,结果都是一致的。
- 高效性:因为原子操作不需要使用锁(或者使用非常轻量的锁),所以它比传统的锁机制要高效,特别是在高并发的场景中。
这些特性可以总结为“原子性”,用一句话讲就是要么都做要么还没做,不会让其他核心看到执行的中间状态。
二、如何实现原子性
单处理器单核:只需要保证指令不被打断(该场景比较简单,不细说)
多处理器或多核:除了不被打断之外,还需避免其他核心操作相关的内存空间。通过lock指令,以往的lock指令是锁总线,避免所有内存的访问,现在的lock指令只需阻止其他核心对相关内存空间的访问。
三、存储体系结构——cpu cache
cpu cache即cpu缓存,它的作用是为了解决cpu运算速度与内存访问速度不匹配的问题,具体的结构和访问时间如图:
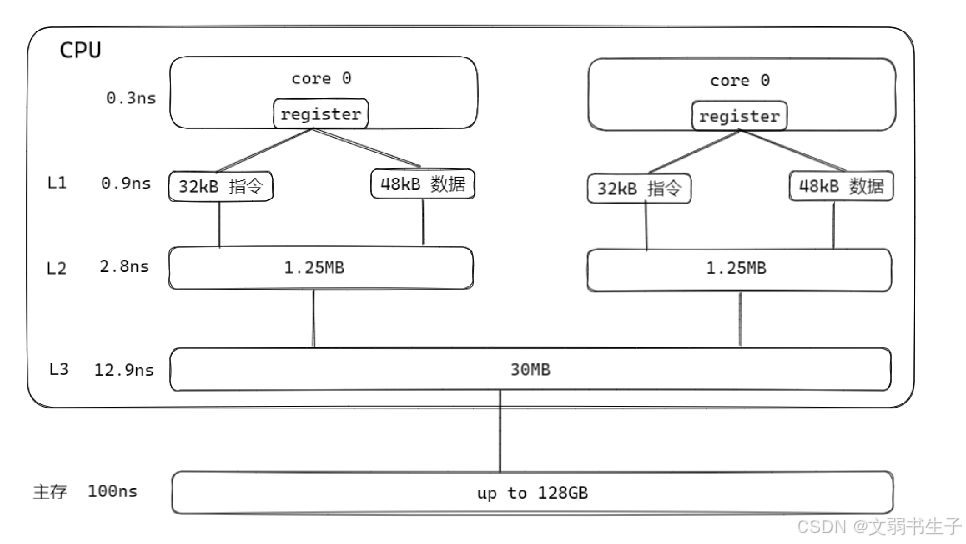
在cpu cache基础上,cpu读写数据有两种模式,一种是写直达(write-through),即cpu向缓存写入数据时,数据会同时写入内存,即每次缓存更新时内存也同步更新。该策略的优点在于保证了缓存与内存之间的数据一致性,但由于每次更新都要写入内存,会导致性能开销大,会增加延迟。另一种模式是写回(write-back),当数据写入缓存时,不立刻同步到内存,而是当缓存中的数据将要被替换时,才会将缓存中的数据刷入内存。
总结对比
| 特性 | 写直达(Write-Through) | 写回(Write-Back) |
|---|---|---|
| 写入操作 | 每次写入都同时更新缓存和主存。 | 写入时只更新缓存,主存只有在数据被驱逐时才更新。 |
| 性能 | 由于每次写入都涉及主存,性能较低。 | 提高性能,减少了对主存的写入次数。 |
| 一致性 | 保证缓存和主存的数据始终一致。 | 可能存在数据不一致,直到缓存被驱逐时才同步。 |
| 实现复杂度 | 相对简单,直接同步缓存和主存。 | 较为复杂,需要处理缓存替换和同步策略。 |
由于写回策略的性能更高,因此目前主流的方式都是写回策略。但这也会造成缓存一致性问题,因为cpu是多核的,可能某个核心修改了内存某个数据,但由于写回策略,并没有从缓存中刷回内存,因此当别的核心想要操作该内存的数据时,会产生不一致性。
为解决该问题,一般会采用总线监听,也叫总线嗅探机制(Bus Snooping),这是一种硬件级别的机制,它通过让每个处理器监听(snoop)总线上所有的数据传输来解决这一问题。当一个处理器发生缓存写操作时,它会将相关数据通过总线广播出去,其他所有处理器都可以监听并检查这个数据是否与它们缓存中的数据有关。如果相关处理器发现自己缓存中的数据与即将被写入的值不一致,它们就会根据缓存一致性协议采取适当的行动。
常见的缓存一致性协议为MESI协议,读者可以自行了解,以及该协议对应的状态机事件。
四、内存序
内存序是什么?内存序(Memory Ordering) 是指多线程或多处理器系统中,程序执行时对内存操作(如读写操作)顺序的规定和约束(相当于指令优化作用)。在多核处理器和多线程环境中,程序中的内存操作可能并不会按照代码中的顺序执行,甚至不同处理器对内存操作的视图可能是不同的,这就引入了内存序的问题。
为什么需要内存序?在多核或多处理器系统中,每个处理器通常有自己的本地缓存(L1、L2缓存),它们对内存的访问可能会不同步。为了提高性能,处理器通常会对指令执行顺序进行优化(如乱序执行、指令预取等),这可能导致内存操作的顺序与程序代码中书写的顺序不一致。
常见的内存序模式
不同 CPU 体系结构和编程语言提供不同级别的内存序支持。例如,在 C++ 内存模型中,有以下几种内存序:
memory_order_relaxed(无序):不保证操作顺序,适用于不涉及同步的数据共享。memory_order_acquire(获取):保证当前及之前的读操作不会被重排到之后。memory_order_release(释放):保证当前及之前的写操作不会被重排到之后。memory_order_acq_rel(获取-释放):综合acquire和release,保证同步变量的可见性。memory_order_seq_cst(顺序一致性):最严格的内存序,保证所有线程看到的操作顺序一致,但性能较差。
内存屏障:
内存屏障(又称为内存栅栏)是一种低级别的同步机制,用于控制编译器和处理器如何重排内存操作。内存屏障通常用于防止指令重排序,确保某些内存操作在特定的顺序中执行。
常见的内存屏障类型:
-
Load Barrier(加载屏障):- 确保在屏障之前的读操作不会被重排到屏障之后。
-
Store Barrier(存储屏障):- 确保在屏障之前的写操作不会被重排到屏障之后。
-
Full Barrier(全屏障):- 确保所有的读写操作都遵循屏障的顺序,防止它们在屏障前后发生重排。
内存序模式和内存屏障有着密切的关系,它们都用于控制多线程程序中内存操作的顺序。内存序模式通过高层次的编程接口告诉编译器和处理器如何在执行原子操作时排序,而内存屏障则通过强制约束来控制执行顺序。
内存序与内存屏障的相互作用:
-
内存序控制内存操作顺序:
- 通过设置内存序模式(如
memory_order_acquire,memory_order_release),程序员告诉处理器在不同的内存操作之间需要哪些顺序保证。例如,使用memory_order_acquire确保当前线程的操作在读取共享数据时不会被重排到后面。
- 通过设置内存序模式(如
-
内存屏障在硬件和编译器中的实现:
- 内存屏障则是在硬件层面或编译器层面通过插入特殊指令来阻止指令重排,确保内存操作顺序符合要求。例如,执行
store时可能需要一个 store barrier 来确保前面的写操作在屏障之前完成。
- 内存屏障则是在硬件层面或编译器层面通过插入特殊指令来阻止指令重排,确保内存操作顺序符合要求。例如,执行
-
结合使用:
- 在一些情况下,内存序模式和内存屏障结合使用。例如,当使用
memory_order_acquire时,处理器会确保之前的所有操作不会重排到之后,而对应的内存屏障也会强制执行这一点。 - 内存序模式更高层次,指定了操作的顺序要求,而内存屏障是具体的硬件实现机制,确保顺序的遵守。
- 在一些情况下,内存序模式和内存屏障结合使用。例如,当使用
内存序和内存屏障相辅相成,共同保证在多线程程序中内存操作的正确性和数据的一致性。
评论记录:
回复评论: