
最核心的,包装和准备
个人项目,怎么包装?一定要写出代码才可以吗?
你可以在系统A中实现就可以,了解其中实现的细节,怎么跟面试官对线等等,这些话术到位了之后,再把它融入到系统B,这样即可。
举个例子

一个大前提,你要想好怎么跟面试官对线?
知道怎么对线后,自然就知道,怎么去提前准备这块内容,举例子:
你的简历写了这句话,那么你要怎么准备?
-
对热点数据做缓存,针对可能的缓存穿透,同时使用缓存空值与布隆过滤器解决;针对热点数据过期,根据不同的数据一致性要求,采用不同的缓存构建方案,防止缓存击穿;
-

你的简历写了异步秒杀业务,你又该怎么介绍?
1、业务大致逻辑的介绍
业务是用户可以抢购大额代金券,来抵扣购买课程所需金额,一个用户只能抢购一张大额优惠券
相关的表结构
平价券表
自增id、代金券标题、副标题、使用规则、支付金额、抵扣金额、类型 0普通 1秒杀、状态 1 2 3、创建时间、更新时间
秒杀券表
在平价优惠券基础上,秒杀优惠券有其他字段,独立成一张表。
关联平价券的自增id、库存、秒杀开始时间、秒杀结束时间、创建时间、更新时间
订单表
Id 订单编号(全局id)、下单用户id、购买的优惠券id、支付方式 1 2 3、订单状态 1 2 3 4 5 6 7、抢购时间、支付时间、核销时间、退款时间、更新时间
有啥难点?
一人一单、不超卖、保证并发量 等等
2、代码一步步实现的过程介绍
方案的比较
选择哪个锁?
整体逻辑的 初步设计是怎么样的?
使用基于数据库的锁 以及 JVM的锁实现功能
初步设计存在什么问题呢?
多集群部署时,JVM不能看到同一把锁
后续又基于什么、或者通过什么方式进行完善优化?
业务迁移到 redis 来做 、由最初的 JVM层面的队列,到引入redis的stream,再到引入MQ等等
那么优化了多少?
数据呈现!qps等等
怎么迭代优惠券秒杀功能?
业务场景是:用户可以抢购数量有限的大额优惠券,并且每个用户最多只能抢一张。
怎么解决超卖问题?方案对比,选择乐观锁
所以这个功能首先要完成的是:不要出现库存超卖的情况,
有两个解决方案:悲观锁syn & 乐观锁 cas
悲观锁的思想:认为我在减库存的时候,一定有其他用户也在减,为了防止这种现象,减库存时,加了一个同步锁synchronized,来解决并发问题
乐观锁的思想:乐观锁是认为我在减库存的时候,不一定会发生并发问题,就算有,我就放弃此次操作,再重新尝试减一次。实现这一机制:
就是在减库存的时候,判断 库存是否 > 0即可,只要是 > 0,就可以卖
当出现 <= 0时,就减库存失败
基于乐观锁的性能比悲观锁要好,因为
悲观锁只允许一个线程在同步代码块执行,其余线程必须等待锁释放,性能差
而基于库存是否 > 0的乐观锁,只有在库存真的 <= 0,才会并发失败,性能远远比悲观锁好。
经过以上方案的比较,项目采用乐观锁来解决超买问题。
接下来是要解决每个用户只能抢一张优惠券的问题
怎么保证每个用户只能抢一张优惠券呢?
项目是这样解决的,首先确定无法使用乐观锁来解决
因为用户抢到优惠券,在他没抢到之前,数据库并没有记录,无法根据字段进行乐观锁。
所以采用悲观锁的方案,因为目前是在解决单个用户发起的并发请求,只需要针对单个用户进行加锁,
确定锁的粒度为每个用户,锁对象为用户id,String 类型,为了防止加锁的对象不是同一个,采用的是toString().intern(),不同的请求,才会从字符串常量池中返回同一个对象,才能解决单个用户并发问题。
确定加锁范围判断用户是否已抢购 -> 乐观锁解决减库存问题 -> 把抢购记录,写入数据库
如果加锁范围只到乐观锁解决库存问题,是无法避免单个用户的并发请求问题的。
这是针对单个服务可用的方法,因为synchronized锁,基于JVM实例
如果部署多台服务,有多个JVM,synchronized无法做到分布式锁,
所以在集群部署下,还会出现一人一单并发问题
思考到集群下的JVM锁问题,采取分布式锁优化:
使用分布式锁,解决集群下的一人一单问题
为了解决上面说到的问题,决定使用跨JVM的锁,即分布式锁,redis就是很好的选择。
首先自定义了一个比较简单的分布式锁
存在的问题是锁超时释放,但是业务还未执行完毕
(想要更好的解决,可以使用redis分布式工具:redisson)
支持锁重入:利用hash结构,通过记录线程id、锁的数量,来达到重入
锁超时自动续费:保证是业务执行完毕,才释放的锁,不会被其他线程趁虚而入
每隔 1/3 的时间,会重置超时时间
支持锁等待:即获取不到锁时,利用发布订阅 & 信号量的机制,等锁释放了 再去重试,对CPU友好。
到目前位置,业务流程为查询优惠券信息 ->加分布式锁来解决同一用户的并发请求-> 进行一人一单的判断,需要查询数据库->进行乐观锁库存超卖的判断,需要更新数据库->抢购成功,创建订单,写入数据库。
可以看到目前的流程存在大量的IO& 锁,整体性能通过JMeter测试,
1000个用户,200库存的优惠券,处理请求的平均耗时接近500ms
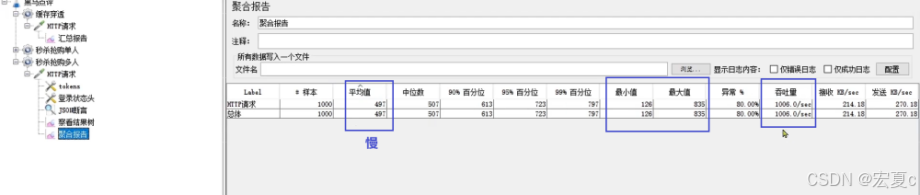
存在许多耗时的数据库操作 & 锁,还可以怎么提高性能呢?
基于redis:秒杀资格判断异步写入数据库思路
通过定时任务把MySQL中参与秒杀的代金券,同步到Redis中做库存的预扣减,基于Redis解决库存超卖与一人一单,RocketMQ实现异步解耦,QPS从400提升至1200;
对业务进行拆分,决定将耗时的数据库操作,放到redis来做,具体为:秒杀资格的判断
新增秒杀优惠券的同时,将优惠券信息预热在redis中
在redis中判断用户是否已经下过单,
使用redis数据类型:Set,存放已经下过单的用户信息,
方便以O(1)复杂度判断用户是否下单sismember、sadd
key为:seckill:order:优惠券id
如果还未下过单,使用redis判断库存是否充足,如果库存充足,则需要减1
使用redis数据类型:hash,存储优惠券信息
get、incrby减库存
key为:seckill:stock:优惠券id
上述过程,是多条命令,无法保证这些命令执行的原子性,会出现并发问题,所以使用lua脚本
保证执行上述命令的原子性
相当于把之前的分布式锁解决一人一单、乐观锁解决库存超卖的问题,通过基于内存的redis解决了
大大提高性能
RocketMQ实现异步解耦,QPS从400提升至1200;
若判断用户有资格抢购,在这之前采用的是同步操作,同步等待信息写入数据库,
即用户请求需要等待抢购信息写入数据库,才可以返回
优化的解决方案是:向消息队列RocketMQ中添加消息(分布式id、优惠券id、用户id),立刻返回用户请求,
开启异步线程,实现异步写入数据库的操作。减少响应时间,提高用户体验。
一开始使用的是JDK自带的阻塞队列,耗时200ms
阻塞队列在获取消息时,如果没有消息,就阻塞住;等到有消息加入了,就被唤醒

使用jdk自带的阻塞队列缺点:
-
使用的是JDK的阻塞队列,用的是JVM的内存,如果不加以限制,在高并发下,可能有无数的订单放到阻塞队列,可能会导致内存溢出,也就是内存受到限制。
-
消息一旦取出,就消失了,不能保证一定被消费
-
不支持持久化,目前是基于内存保存订单信息,如果服务宕机,内存所有订单信息都丢失;
选择Stream消息队列替代JDK自带的阻塞队列
耗时100ms

比较redis 不同方式实现消息队列之间的优缺点,即为什么选择Stream而不是List?
最重要的是记住Stream的优点(持久化、全局ID、解决消息漏读、pendin-list保证消息至少消费一次、独立于JVM的内存、支持消费者组消费,减少消息挤压、可以阻塞读取)
理解内部实现,来说明为什么有这些优点。
具体落实到项目中,怎么实现?
创建一个Stream消息队列,不指定上限
lua脚本判断有资格后,向消息队列添加消息
项目启动时,开启异步线程,阻塞读取Stream消息队列中的消息,完成写入数据库操作
如果成功消费,那么发送ack确认给消息队列,消息才会从pending队列中移除
如果消费出现问题,就到该消费者的pending队列中,再次消费
专业消息队列RocketMQ
RocketMQ使用并发消费模式,并设置合理的线程数量(IO类型,写库存),快速处理队列中堆积的消息,使
用Redis的分布式锁+自旋锁,对商品的库存进行并发控制,把并发压力转移到Redis中,缓解DB压力;
因为并发消费,对数据库减库存操作,是不安全的
除非直接利用数据库乐观锁减
而不是先去读再减 ,直接减
但是对DB压力大
使用redis乐观锁 + sleep + 自旋来解决
3、未来展望 or 再次迭代 or 这个功能有什么可以完善的地方?
如果没下单,库存怎么还回去?
使用延时队列? 那么又引出 - 延时队列怎么实现的?
其实redis 的 stream同样的,又引出八股文,这些都是需要准备的 Stream相关的八股
.....
自定义的分布式锁,相比官方提供的,存在缺陷,如:
最严重的 业务未结束,锁先超时释放了,其他线程趁虚而入、
不支持 锁重入:用hash即可、
不支持 阻塞等待:用信号量、发布/订阅机制 即可、
在多redis实例下,即主从模式下因为是异步复制的,导致分布式锁不可靠性:官方提供的 红锁 解决
redisson 针对前面三个缺陷、RedLock 红锁
4、实现过程中遇到了什么难点?什么bug?
@Transational失效,因为不是代理对象调用。深入了理解Spring事务原理 -- Aop。
怎么解决?
-
比较笨方法:新开一个类
-
或者 自己注入自己,进行调用,也是代理对象的调用
-
获取代理对象来解决。
JVM的syn悲观锁解决一人一单问题的时候:
用的是用户的id,忘记intern放到字符串常量池,
导致获取String对象的时候,每次都是新的对象,即 加 对象锁出现问题
还有syn锁范围设置的不够大,释放锁之后,事务还未写入,导致数据库记录还未变更,存在并发问题
.....
5、如果你的简历 关键字出现,分布式id、分布式锁、qps等等
心里就要思考到,哪些是会被提问的?
怎么进行压力测试的?
QPS、并发量、平均花费时间 等的关系:QPS和并发数和平均耗时的关系以及压测思路_qps和并发数的关系-CSDN博客
分布式id相关的准备
为什么不采用数据库自增id?
单一表的存储容量有上限
当分表存储时,会存在重复的id
规律性明显,容易看出订单销量等状态
分布式ID是什么?
是应用在分布式系统中,保证全局唯一的自增id。
它可以让一个业务,不管有多少个服务、多少张表,都可以拥有唯一的自增id。
全局唯一的分布式ID怎么实现?
使用redisString数据类型的incr自增命令,来帮助生成全局唯一id,有以下好处:
因为redis执行命令是单线程的,所以在执行自增命令生成自增id时,
不存在并发问题,自然不会导致id重复的问题;
并且是自增的,符合分布式id要求;
并且redis基于内存操作,性能极高;
为了保证生成的id安全性,具体如下操作:
采用long类型存储id,long类型64位
· 第一个符号位,永远为0
· 接下来的31bit,采用精确到秒的时间戳进行存储
o 时间戳如何计算得来:定义一个初始时间,用当前下单时间减去初始时间,得到31bit
· 后面的32bit,是为了解决在一秒内重复的下单,足够容纳一秒内的订单量
如何运算?
先得到当前时间 - 初始时间的时间戳,然后左移32位,给一天的订单量让出32位bit
使用自增命令,得到自增值,要保证不会超过32bit,然后直接进行或运算
return timestamp << COUNT_BITS | count;
时间戳的代码
/** * 初始时间的时间戳,本质是从1970-01-01 00:00:00 到2022-01-01 00:00:00 经过多少秒 */ private static final long BEGIN_TIMESTAMP = 1640995200L;
//测试时间戳 public static void main(String[] args) { LocalDateTime time = LocalDateTime.of(2022, 1, 1, 0, 0, 0); System.out.println( time.toEpochSecond(ZoneOffset.UTC)); }
自增命令的key怎么设置比较好?
在自增中,采用的是32bit来存储自增值,也就是说自增值超过32bit存储容量,就会不符合我们的要求。
所以在设置key时,采用一天一个key,一天订单量很难超过32bit,也就是自增值不会超过
o 如:("icr:" + keyPrefix + ":"+"2022:03:20"),keyPrefix 为业务名称
o 还带来统计方便的好处
§ 比如某天的订单数,直接看对应key的自增数字就可以。这样做统计简单很多。
自增id生成器代码
- @Component
- public class RedisIdWorker {
- /**
- \* 初始时间的时间戳,本质是从1970-01-01 00:00:00 到2022-01-01 00:00:00 经过多少秒
- */
- private static final long BEGIN_TIMESTAMP = 1640995200L;
-
- //测试时间戳
- public static void main(String[] args) {
- LocalDateTime time = LocalDateTime.of(2022, 1, 1, 0, 0, 0);
- System.out.println( time.toEpochSecond(ZoneOffset.UTC));
- }
-
- /**
- \* 序列号的位数
- */
- private static final int COUNT_BITS = 32;
-
- @Resource
- private StringRedisTemplate stringRedisTemplate;
-
- /**
- \* @param keyPrefix key前缀,不同业务有不同的key
- \* @return long型,作为id,占用更少空间,有利于索引建立
- */
- public long nextId(String keyPrefix) {
- // 符号位不用管,只要保证正数就可以,怎么保证? 时间戳中,当前时间 - 初始时间,当前时间要 > 初始时间
-
- // 1.生成当前时间的 时间戳
- LocalDateTime now = LocalDateTime.now();
- long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
- // 当前时间 - 初始时间
- long timestamp = nowSecond - BEGIN_TIMESTAMP;
-
- // 2.生成序列号
- // 2.1.获取当前日期,精确到天
- String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
-
- long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
-
- // 3.拼接并返回,如果直接拼接得到的是字符串,返回要long。所以这里采用位运算
- // 先把时间戳挪到高位,在这里 左移32位。 再跟序列号进行 或运算
- return timestamp << COUNT_BITS | count;
- }
- }
你还了解哪些分布式ID生成算法?
除了基于redis生成的分布式id,还了解雪花算法、uuid、数据库自增id
雪花算法 同样采用64bit存储
o 第一位表示符号位,为0
o 接下来的41bit,用于表示精确到毫秒的时间戳
o 接下来的10bit,(这一部分可以灵活调整)
§ 前5位表示机器id,后5位表示机房id
o 剩下的12bit,用来表示一毫秒内,能够生成的id数量
优点:
生成速度快,有序递增、易于再此基础上改造
缺点:
依赖于时间,当机器的时间对应不上时,可能导致重复id
uuid 基于时间、机器id的生成方案
缺点是:
占用内存大,128bit
时间问题,导致id重复
可以保证唯一,但是不是自增的
若redis服务宕机,分布式id如何生成?
采用redis主从复制 + 哨兵机制,来达到服务的高可用
当主节点宕机时,自动故障转移
主从复制保证数据同步。
6、分布式锁相关的准备
分布式锁是什么?
满足分布式或集群模式下,多线程可见 且 互斥的锁。
怎么基于redis实现?
使用redis的 setnx命令,来实现分布式锁,非阻塞,获取失败,直接返回
加锁操作:setnx
因为redis执行命令是单线程,不会并发安全问题
并且为了防止死锁,加了key的过期时间
并且将value设置唯一标识,是为了防止锁误删的现象
解锁操作:基于lua脚本,因为不止一条命令
首先判断该锁是不是自己加的,即检查唯一标识get
如果是,才可以进行解锁del
锁误删现象是什么?
比如目前线程A,持有锁,当时因为阻塞,导致业务没执行完,锁超时释放了
此时线程B重新持有锁,进行业务处理,
在线程B还没处理完业务时,线程A处理好了,并且二话不说,直接把锁删除了
这就导致线程B的锁,被线程A删掉的情况。导致锁误删
这时,其他线程又可以趁虚而入了。
唯一标识怎么设置?
因为目前讨论的是项目在集群部署的环境下,线程id可能重复
所以基于每个线程的id + UUID来进行唯一标识的设置。
为什么解锁要使用lua脚本
因为解锁是两个操作get、del,必须保证解锁的原子性,否则可能出现以下现象:锁误删
判断该锁是我之前加的
进行解锁时,阻塞了
知道锁超时释放,接着其他线程进行加锁
自己从阻塞状态恢复,执行业务,dek把别人的锁又给删除了
自定义的分布式锁,存在什么问题?
锁误删问题解决了,但是还存在一个比较严重的问题,就是锁超时时间的设置
如果设置的太短,可能业务还没执行完 或者 业务阻塞,导致锁超时释放
其他线程趁虚而入,又导致了一人不止下一单问题的出现。
不支持锁重入、锁超时自动续费、锁等待、
主从模式下因为是异步复制的,导致分布式锁不可靠性
怎么解决自定义分布式锁问题?
使用redis分布式工具:redisson
· 支持锁重入:利用hash结构,通过记录线程id、锁的数量,来达到重入
· 锁超时自动续费:保证是业务执行完毕,才释放的锁,不会被其他线程趁虚而入
o 每隔 1/3 的时间,会重置超时时间
· 支持锁等待:即获取不到锁时,利用发布订阅 & 信号量的机制,等锁释放了 再去重试,对CPU友好。
Redis 如何解决集群情况下分布式锁的可靠性?
redis官方是实现了红锁RedLock,专门来解决集群模式下分布式锁不可靠的问题,
redis推荐使用5个独立的redis主服务器
它加锁的过程如下:
记录开始访问的时间t1,线程依次访问5个主服务器,进行set nx px的操作,
会带上唯一标识
加上超时时间,是为了锁一定会被释放
并且还设定了获取锁的时间,一般设置为几十毫秒,
如果在时间内获取不到,那么就返回,不会再某个redis服务耗费太多的获取锁时间
最后统计线程成功获取了几把锁,要获取到一半以上,并且将获取锁的总时间 与 设置的锁过期时间对比
如果 获取锁的总时间>设置的锁过期时间,那么加锁失败
如果没有获取到一半以上的锁,在这里是3把锁,也是加锁失败
故加锁成功要同时满足两个条件:
· 获取到超过半数以上的锁
· 加锁的总耗时,不大于 锁的过期时间
并且在执行业务时,真正能够利用的锁时间为:设置的锁超时时间 - 获取锁的总耗时
如果觉得锁的时间已经来不及完成业务执行,那么可以直接释放全部锁,让下一个线程来操作
避免业务还没执行完,就出现释放锁的现象
解锁操作:
加锁失败后,会向所有redis主节点发起解锁操作,执行lua脚本保证解锁的原子性
完整代码,要稍微注意一下lua脚本怎么写
- // 在项目一启动类加载时就加载static代码块,只加载一次,性能最好。
- // DefaultRedisScript是实现类,泛型为脚本的返回值类型
- private static final DefaultRedisScript
UNLOCK_SCRIPT; - static {
- // 因为要写不止一行,所以放到代码块
- UNLOCK_SCRIPT = new DefaultRedisScript<>();
- // 去类路径下找
- UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
- // 设置返回值类型
- UNLOCK_SCRIPT.setResultType(Long.class);
- }
-
-
- @Override
- public void unlock() {
- // 释放锁
- // stringRedisTemplate.delete(KEY_PREFIX + name);
-
- /*// 获取线程标示
- String threadId = ID_PREFIX + Thread.currentThread().getId();
- // 获取锁中的标示
- String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
- // 判断标示是否一致
- if(threadId.equals(id)) {
- // 释放锁
- stringRedisTemplate.delete(KEY_PREFIX + name);
- }*/
- // 调用lua脚本
- stringRedisTemplate.execute(
- UNLOCK_SCRIPT,
- // 生成单元素的集合:singletonList方法
- Collections.singletonList(KEY_PREFIX + name),
- ID_PREFIX + Thread.currentThread().getId());
- }
评论记录:
回复评论: