
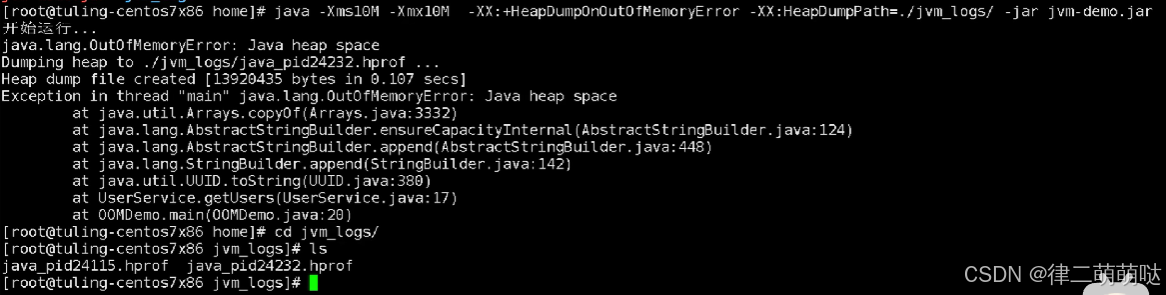
1. 如何定位线上OOM
- 造成OOM的原因

- 如何快速定位OOM

2. 如何防止重复下单
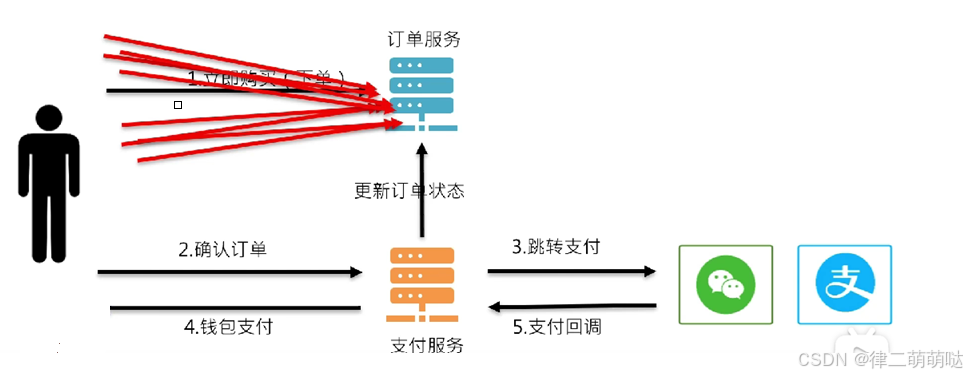
方案一:
前端提交订单按钮置灰
用户点击下单按钮后置灰,防止用户无意点击多次
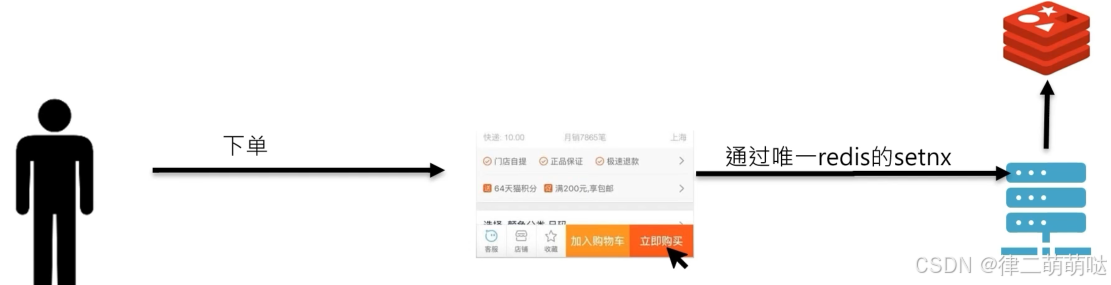
方案二:
后端Redis setnx
用户token +商品URL+ KEY 用setnx 命令并设置过期时间3-5秒防止重复下单
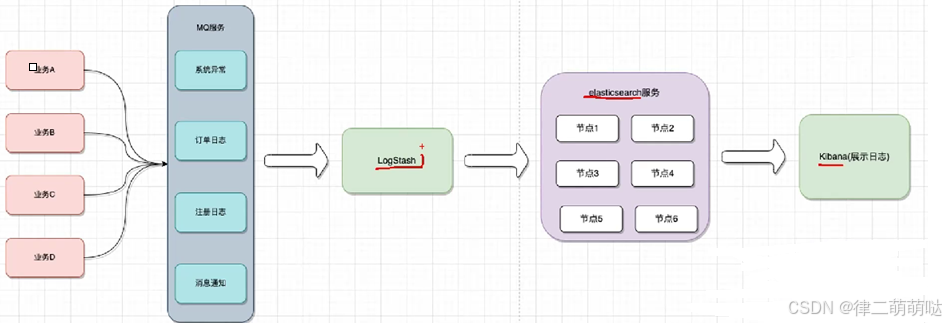
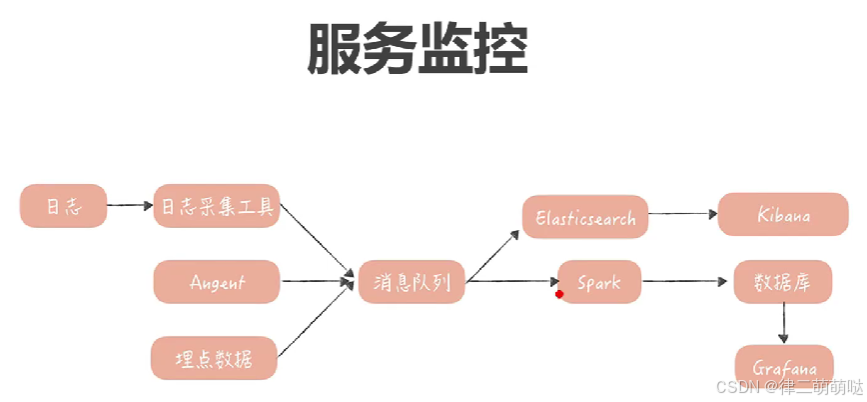
3. 如何设计分布式日志存储架构
单体项目 使用Logback, Log4j记录日志到文件中
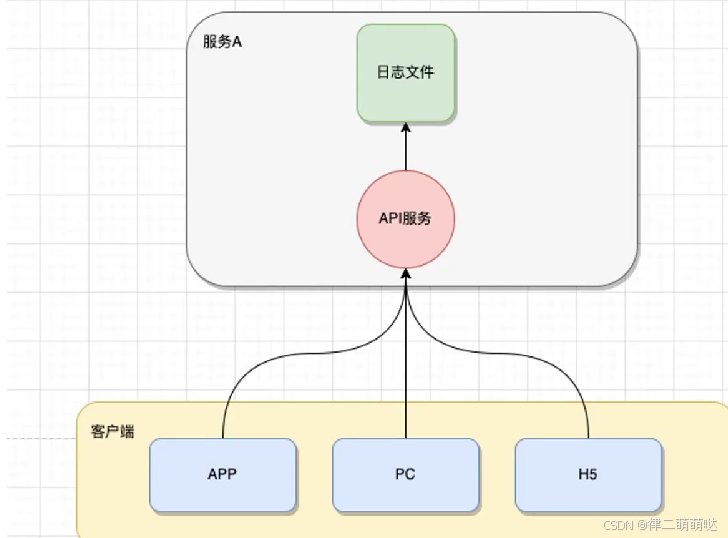
- 优点:部署简单,成本低,容易维护,性能高,稳定
- 缺点:在分布式环境下不方便排查问题
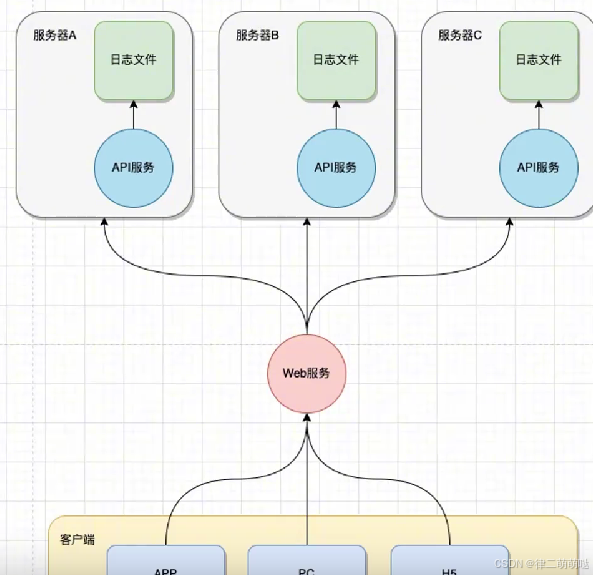
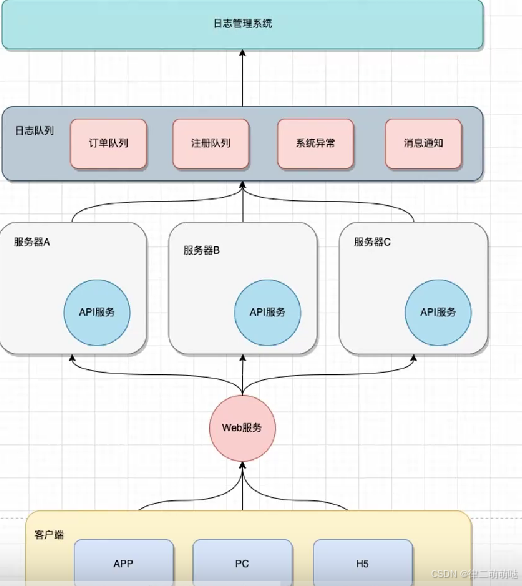
如何实现日志分布式系统
MongoDB存储
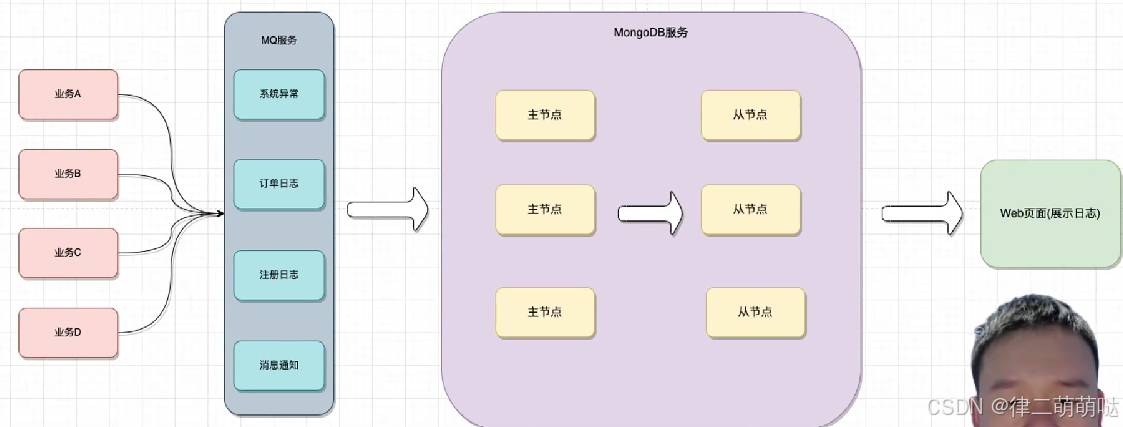
2. ELK存储
4. 给你以一亿个 Redis keys, 统计双方共同好友
要统计双方共同好友,可以使用Redis的Set数据结构来实现。以下是一个详细的步骤:
-
使用Redis的Set数据结构 :
将每个用户的好友列表存储在一个Set中。例如,用户userid:20002和userid:20003的好友列表可以分别存储在两个Set中。 -
使用交集命令
SINTERSTORE:
Redis自带的交集命令SINTERSTORE可以用来求两个Set的交集,并将结果存储在一个新的Set中。示例命令如下:
SINTERSTORE userid:new userid:20002 userid:20003
- 1
这条命令会计算userid:20002和userid:20003的好友列表的交集,并将结果存储在Set userid中。
- 处理大量数据:
存储一亿个数据在Redis中成本可能过高,因为Redis是内存数据库,存储大量数据会占用大量内存资源。因此,需要考虑其他解决方案。
一个更适合的解决方案是使用MySQL作为主要存储,通过分库分表策略分散数据存储压力,并使用缓存(如Redis)存储热点数据,以提高查询效率。
- 使用其他数据库:
如果社交数据非常复杂,可以考虑使用图数据库(如Neo4J)来存储和查询好友关系。Neo4J能够通过命令直接查询可能认识的好友、共同好友等关系。
- 监控和优化:
对于如此大量的数据,需要持续监控Redis的性能和内存使用情况,确保系统的稳定性和高效性。
可以通过使用Redis的INFO命令来获取服务器的状态信息,如内存使用情况、连接数、命中率等,以便及时进行调优。
请注意,处理如此大量的数据需要谨慎设计系统架构,并考虑到数据的扩展性、安全性和性能。在实际操作中,可能还需要根据具体情况进行进一步的优化和调整。
另外,由于Redis是内存数据库,对于存储大量数据(如一亿个key)的情况,需要确保有足够的物理内存来支持,并考虑使用持久化机制(如RDB和AOF)来防止数据丢失。
5. 如何使用redis记录上亿用户连续登录天数
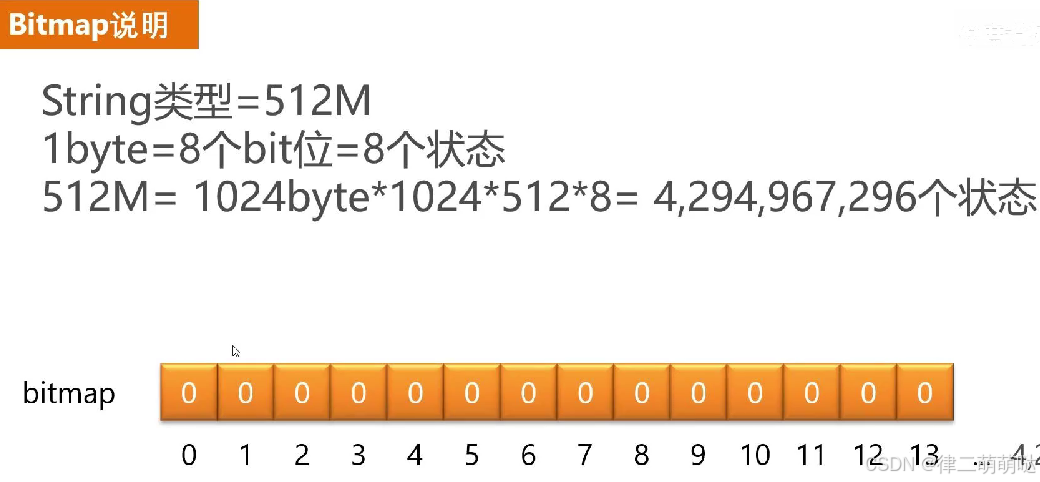
可以采用Redis提供的Bitmap(位图)数据结构来实现。Bitmap实际上是由一个一个的bit的二进制位所组成的数组,每一个位只能存0和1,非常适合用于这种二值统计的场景。
以下是使用Redis记录上亿用户连续登录天数的基本步骤:
选择数据结构:
使用Redis的Bitmap数据结构。Redis的Bitmap是由string类型所实现的,string类型最大可以存储512兆字节,换算成bit位,可以存储42亿多个bit位,因此足够存储上亿用户的连续登录状态。
设计key和offset:
使用日期作为Bitmap的key,例如“20250209”表示2025年2月9日。
将用户的ID映射到Bitmap的偏移位(offset)。假设用户ID是唯一的数字,那么可以直接将用户ID作为偏移量。例如,用户ID为5的登录状态就存储在offset为5的位上。

记录登录状态:
当用户登录时,使用Redis的SETBIT命令将对应日期和用户ID的位设置为1。例如,如果今天是2025年2月9日,用户ID为5的用户登录了,那么执行命令SETBIT 20250209 5 1。
统计连续登录天数:
要统计某个用户的连续登录天数,可以从当天开始,往前面的日期去推算。例如,要统计用户ID为5的连续登录天数,从当天开始,逐日检查对应位是否为1,直到遇到0为止。
使用Redis的GETBIT命令获取指定位置的bit值。
设置key的过期时间:
一般不需要统计超过30天的连续登录天数,因此可以将当前key的过期时间设置为30天,超过30天自动过期,这样可以有效利用Redis的内存。
6. 查询200条数据耗时200毫秒,怎么在500毫秒内查询1000条数据
如果查询可以并行化(即多个查询可以同时进行而不会相互影响),你可以考虑使用多线程或异步编程来同时发起多个查询。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class MultiThreadedQuery {
// 假设这是你的查询方法,单线程查询200条数据耗时200毫秒
private static List<Data> queryData(int start, int count) {
// 模拟查询操作
try {
Thread.sleep(count / 2); // 假设每条数据查询耗时0.5毫秒(仅为示例)
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
List<Data> dataList = new ArrayList<>();
for (int i = 0; i < count; i++) {
dataList.add(new Data(start + i)); // 添加模拟数据
}
return dataList;
}
// 使用多线程查询数据
public static List<Data> queryDataInParallel(int totalCount, int threadCount, int batchSize) {
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
List<Future<List<Data>>> futures = new ArrayList<>();
for (int i = 0; i < totalCount; i += batchSize) {
final int start = i;
final int count = Math.min(batchSize, totalCount - i);
futures.add(executor.submit(new Callable<List<Data>>() {
@Override
public List<Data> call() throws Exception {
return queryData(start, count);
}
}));
}
List<Data> result = new ArrayList<>();
for (Future<List<Data>> future : futures) {
try {
result.addAll(future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
executor.shutdown();
return result;
}
public static void main(String[] args) {
int totalCount = 1000;
int threadCount = 5; // 假设使用5个线程
int batchSize = 200; // 每个线程查询的批次大小
long startTime = System.currentTimeMillis();
List<Data> data = queryDataInParallel(totalCount, threadCount, batchSize);
long endTime = System.currentTimeMillis();
System.out.println("Queried " + data.size() + " items in " + (endTime - startTime) + " ms.");
}
// 假设的数据类
static class Data {
private int id;
public Data(int id) {
this.id = id;
}
// getter, setter, toString等方法可以根据需要添加
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
7. 怎么用java实现一个简单的消息队列
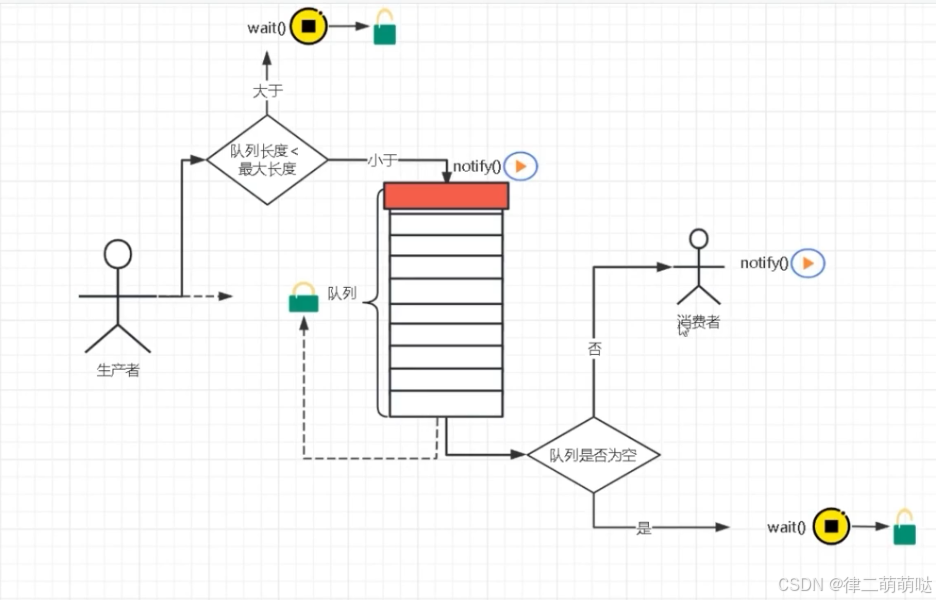
public class SharedQueue {
//声明队列最大长度
private int queueSize = 10;
private ArrayBlockingQueue<Integer> queue= new ArrayBlockingQueue<>(10);
public static void main(String[] args) {
SharedQueue sharedQueue = new SharedQueue();
//消费者持续运行
Consumer consumer = sharedQueue.new Consumer();
consumer.start();
//生产10条消息
for (int i = 1; i <= 10; i++) {
//创建10个生产者线程
Producer producer = sharedQueue.new Producer();
producer.start();
}
}
//生产者
class Producer extends Thread{
@Override
public void run() {
//保证生产者在整个过程中是安全的
synchronized (queue){
//1.判断当前队列长度是否小于最大长度
if(queue.size()<queueSize){
//2.如果小于,生产者就可以生产消息了
//2.1 往队列添加一条消息
queue.add(queue.size()+1);
System.out.println("生产者往队列中加入消息,队列当前长度:"+queue.size());
//唤醒消费者有活了
queue.notify();
try {
//模拟业务处理
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}else{
//3.如果大于,生产者停止工作,稍微歇一歇
try {
queue.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
class Consumer extends Thread{
@Override
public void run() {
//消费者需要重复的工作
while(true){
//保证整个消费过程是线程安全的
synchronized (queue){
//如果队列为空,睡眠
if(queue.isEmpty()){
System.out.println("当前队列为空....");
try {
queue.wait();
} catch (InterruptedException e) {
e.printStackTrace();
//如果出现异常,手动唤醒
queue.notify();
}
}else{
//队列不为空,消费者进行消费
//消费头部信息
Integer value = queue.poll();
System.out.println("消费者从队列中消费了信息"+value+",队列当前长度:"+queue.size());
//消费完消息,唤醒生产者可以继续生产了
queue.notify();
try {
//模拟业务处理
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
8. redis如何实现上亿用户实时积分排行榜
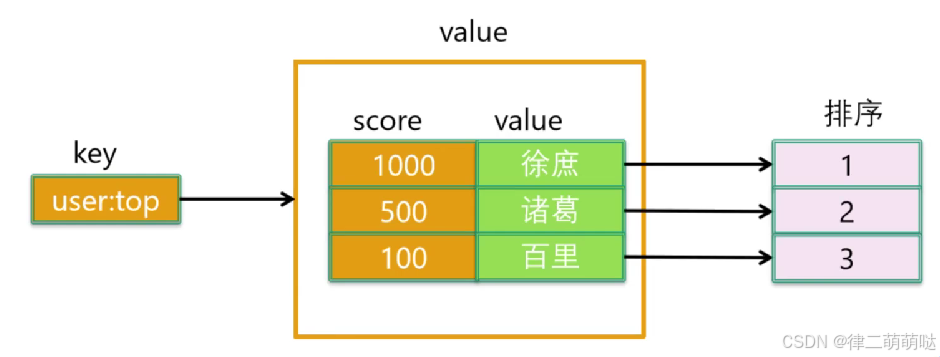
实现上亿用户实时积分排行榜是一个复杂且高性能要求的任务,但Redis凭借其出色的数据结构和性能,非常适合处理这种场景。以下是一个基于Redis的实现思路:
数据结构设计
使用Sorted Set(有序集合)
Redis的Sorted Set(ZSET)是带有权重的集合,其内部实现是跳表加字典,能够高效地支持按权重(这里是积分)的排序和范围查询。因此,我们可以使用Sorted Set来存储用户的积分信息。
- Key:可以是一个固定的字符串,比如"user_leaderboard"。
- Member:用户的唯一标识,比如用户ID。
- Score:用户的积分。
数据操作
添加或更新用户积分
当用户获得或失去积分时,需要更新排行榜。这可以通过Redis的ZADD命令来实现,该命令可以添加或更新集合中成员的分数。
ZADD user_leaderboard score member
- 1
例如,给用户ID为123的用户增加100积分:
ZADD user_leaderboard 100 123
- 1
如果用户已经存在,则ZADD会更新其积分。
查询排行榜
要获取积分排行榜,可以使用ZRANGE或ZREVRANGE命令。这两个命令分别按升序和降序返回集合中的元素。
# 获取积分前100名的用户
ZREVRANGE user_leaderboard 0 99 WITHSCORES
- 1
- 2
- 3
获取用户排名
要获取特定用户在排行榜中的排名,可以使用ZREVRANK命令。
# 获取用户ID为123的用户在排行榜中的排名(从0开始)
ZREVRANK user_leaderboard 123
- 1
- 2
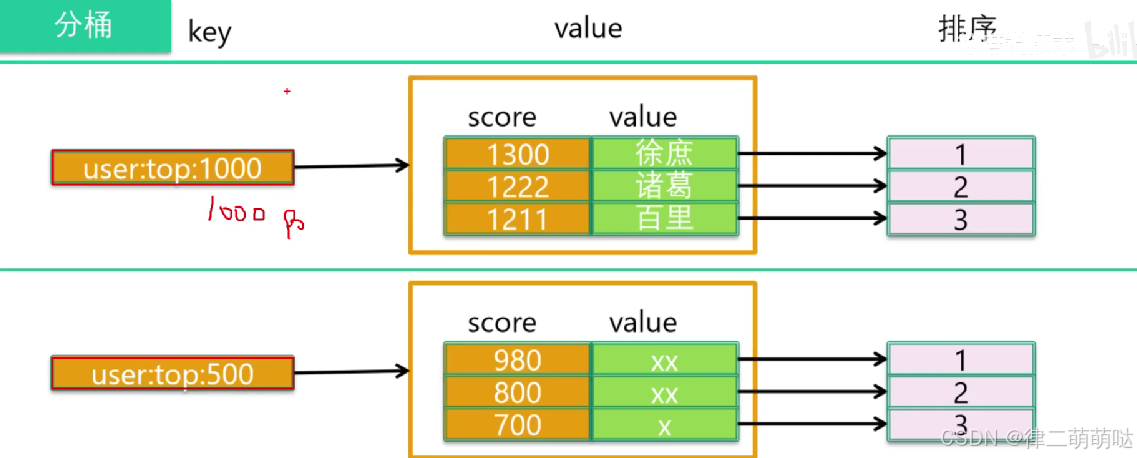
优化方案:分桶而治
一个key存储上亿用户太大,根据key来进行区分,1000以上的存到一个桶里
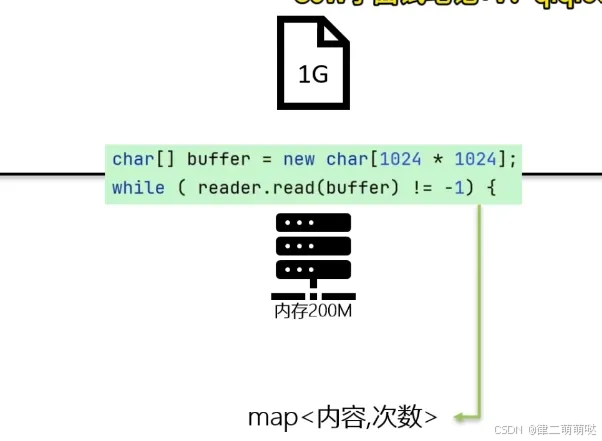
9. 内存200M读取1G文件并统计重复内容
分块读取并放到hashMap中
- 我们使用BufferedReader以流的方式逐块读取文件,每次读取一个字符数组(缓冲区)。
- 当我们遇到换行符时,我们认为这是一行的结束,并处理这一行(在这里,我们简单地统计了每一行的出现次数)。
- 我们使用一个HashMap来存储每行内容及其出现的次数。
- 最后,我们遍历HashMap并打印出出现次数大于1的内容。
这种方法的关键在于它不需要一次性将整个文件加载到内存中,而是逐行(或逐块)处理文件内容,因此非常适合处理大文件。你可以根据需要调整缓冲区的大小(BUFFER_SIZE),以及处理内容的方式(例如,按单词而不是按行统计)
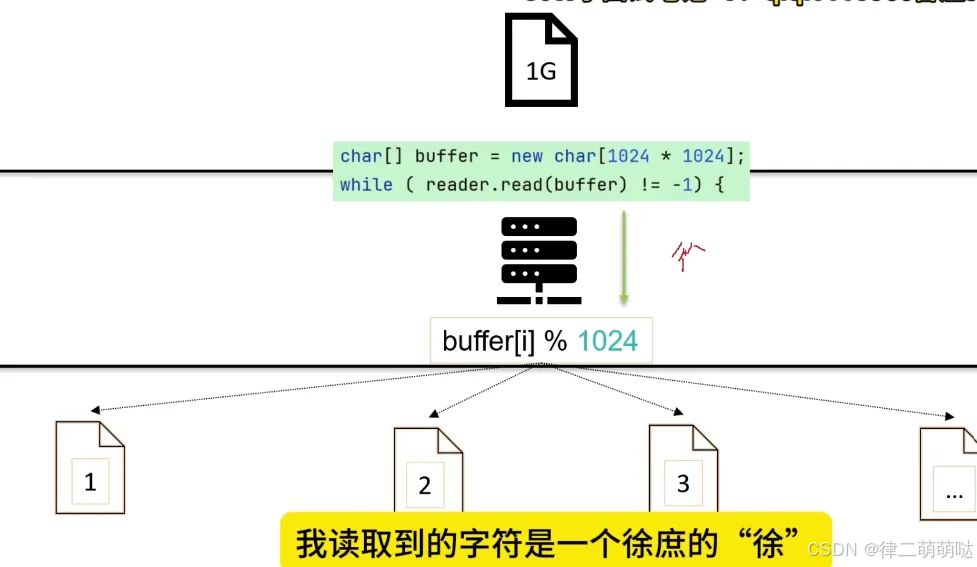
极端情况下内容不重复,那这个时候map就会产生大量的key, 此时可以先将数据写到每个分片文件,
读取每个分片文件,用map存储并统计
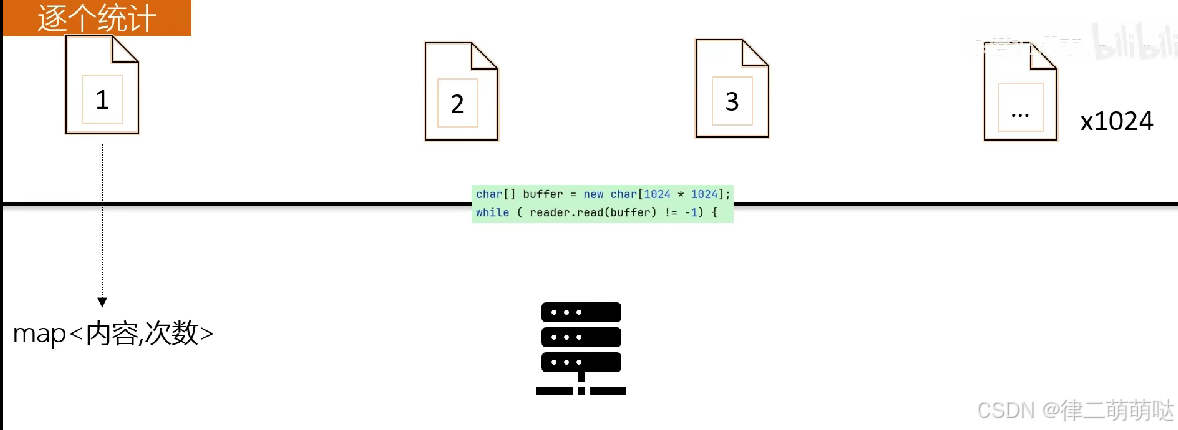
总结: 分块读取大文件 --> 文件分片 -->逐个统计
10. Springboot防盗链的几种方式
在Spring Boot中实现防盗链功能,可以通过多种方式来实现,主要包括使用过滤器(Filter)、拦截器(Interceptor)以及配置反向代理服务器(如Nginx)等。以下是几种方式的详细说明:
- 使用过滤器(Filter)
通过创建一个自定义过滤器,可以在请求到达实际资源之前检查HTTP头中的Referer字段。如果Referer不在允许的域名列表中,则返回403 Forbidden响应或重定向到其他页面。
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
public class HotlinkProtectionFilter implements Filter {
private final String[] allowedDomains = {"yourdomain.com"};
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletRequest httpRequest = (HttpServletRequest) request;
String referer = httpRequest.getHeader("Referer");
if (referer == null || Arrays.stream(allowedDomains).anyMatch(referer::contains)) {
chain.doFilter(request, response);
} else {
((HttpServletResponse) response).sendError(HttpServletResponse.SC_FORBIDDEN, "Hotlinking not allowed");
}
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {}
@Override
public void destroy() {}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
然后,将这个过滤器注册到Spring的上下文中:
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class WebConfig {
@Bean
public FilterRegistrationBean<HotlinkProtectionFilter> loggingFilter() {
FilterRegistrationBean<HotlinkProtectionFilter> registrationBean = new FilterRegistrationBean<>();
registrationBean.setFilter(new HotlinkProtectionFilter());
registrationBean.addUrlPatterns("/resources/*"); // 替换为你的资源路径
return registrationBean;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 配置Nginx等反向代理服务器
在网关层使用Nginx等反向代理服务器进行防盗链配置也是一种常见且简单的方式。通过拦截访问资源的请求,并检查请求头中的Referer地址是否为本站,如果不是则进行阻止或重定向。
server {
listen 80;
server_name www.yourdomain.com;
location / {
root /web;
index index.html;
}
location ~* \.(gif|jpg|png|jpeg)$ {
root /web;
valid_referers none blocked yourdomain.com;
if ($invalid_referer) {
return 403;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
11. springboot,springmvc和spring的区别
三者是包含的关系,springboot包含spring, spring 包含springmvc
Spring是全面的企业级开发框架,Spring MVC是Spring的Web MVC模块,Spring Boot是简化Spring应用开发的快速开发框架。
Spring:提供IoC和AOP等核心功能,支持企业级应用开发,涵盖web层、业务层、持久层等12。
Spring MVC:Spring的Web MVC框架,专注于Web应用的MVC架构,解决WEB开发问题,配置相对繁琐12。
Spring Boot:简化Spring应用开发的框架,提供自动配置和默认配置,降低项目搭建复杂度,快速上手开发
12. 如何防止SpringBoot反编译
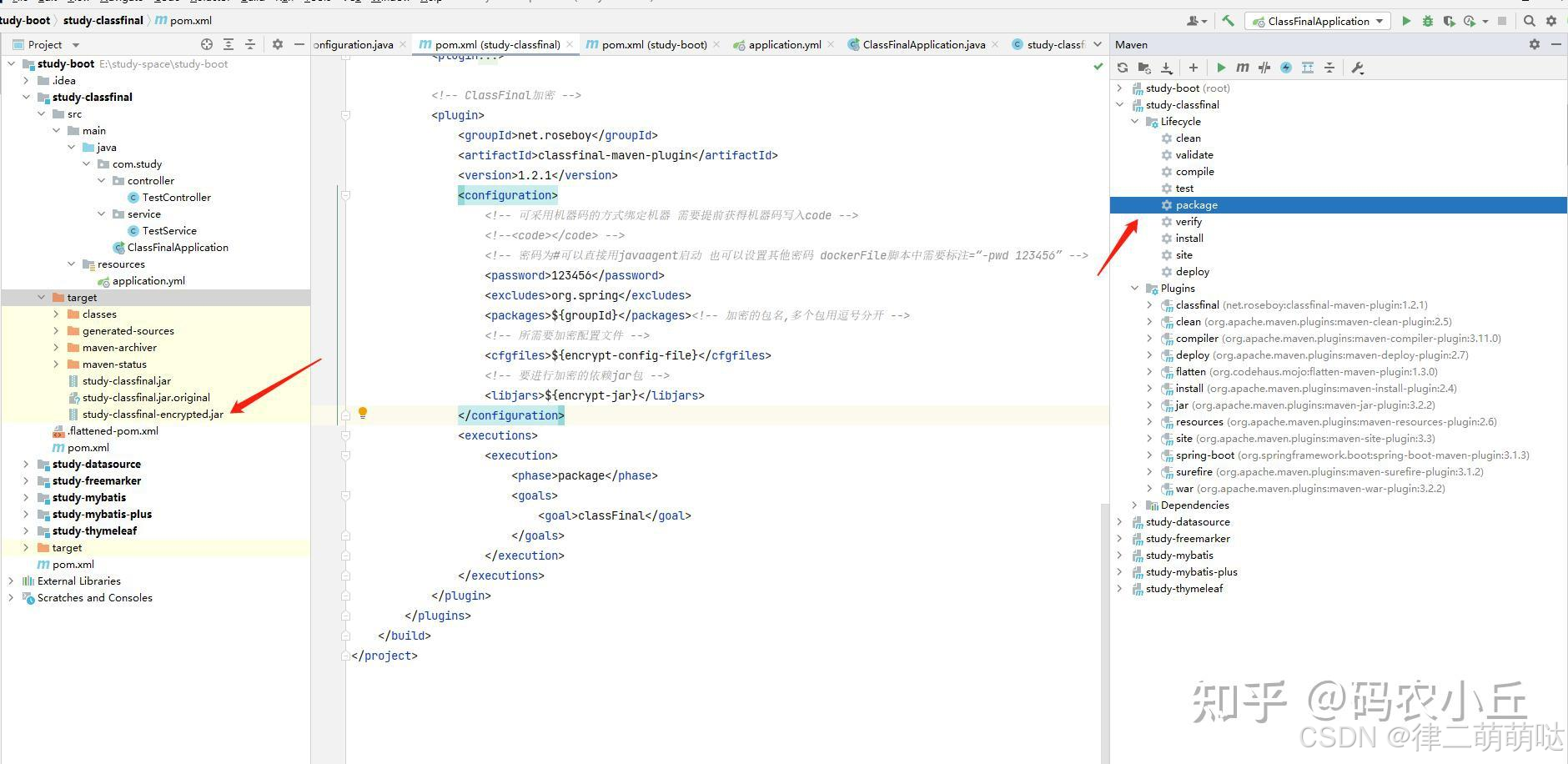
可以使用一些工具(如ClassFinal-maven-plugin, JBCO)将字节码加密,并在运行时动态解密。这种方法可以有效地保护源代码的安全性,但需要在运行时进行解密操作,可能会影响程序的性能。
- 引入插件
<plugin>
<groupId>net.roseboygroupId>
<artifactId>classfinal-maven-pluginartifactId>
<version>1.2.1version>
<configuration>
<password>123456password>
<excludes>org.springexcludes>
<packages>${groupId}packages>
<cfgfiles>${encrypt-config-file}cfgfiles>
<libjars>${encrypt-jar}libjars>
configuration>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>classFinalgoal>
goals>
execution>
executions>
plugin>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
-
打包
-
反编译工具(jd-gui)
下载地址;
Java Decompiler
https://java-decompiler.github.io/
- 1
启动包加密之后,方法体被清空,保留方法参数、注解等信息.主要兼容swagger文档注解扫描,反编译只能看到方法名和注解,看不到方法体的具体内容,启动过程中解密class,是在内存中解密,不留下任何解密后的文件。
yml配置文件留下空白:
controller,service层:
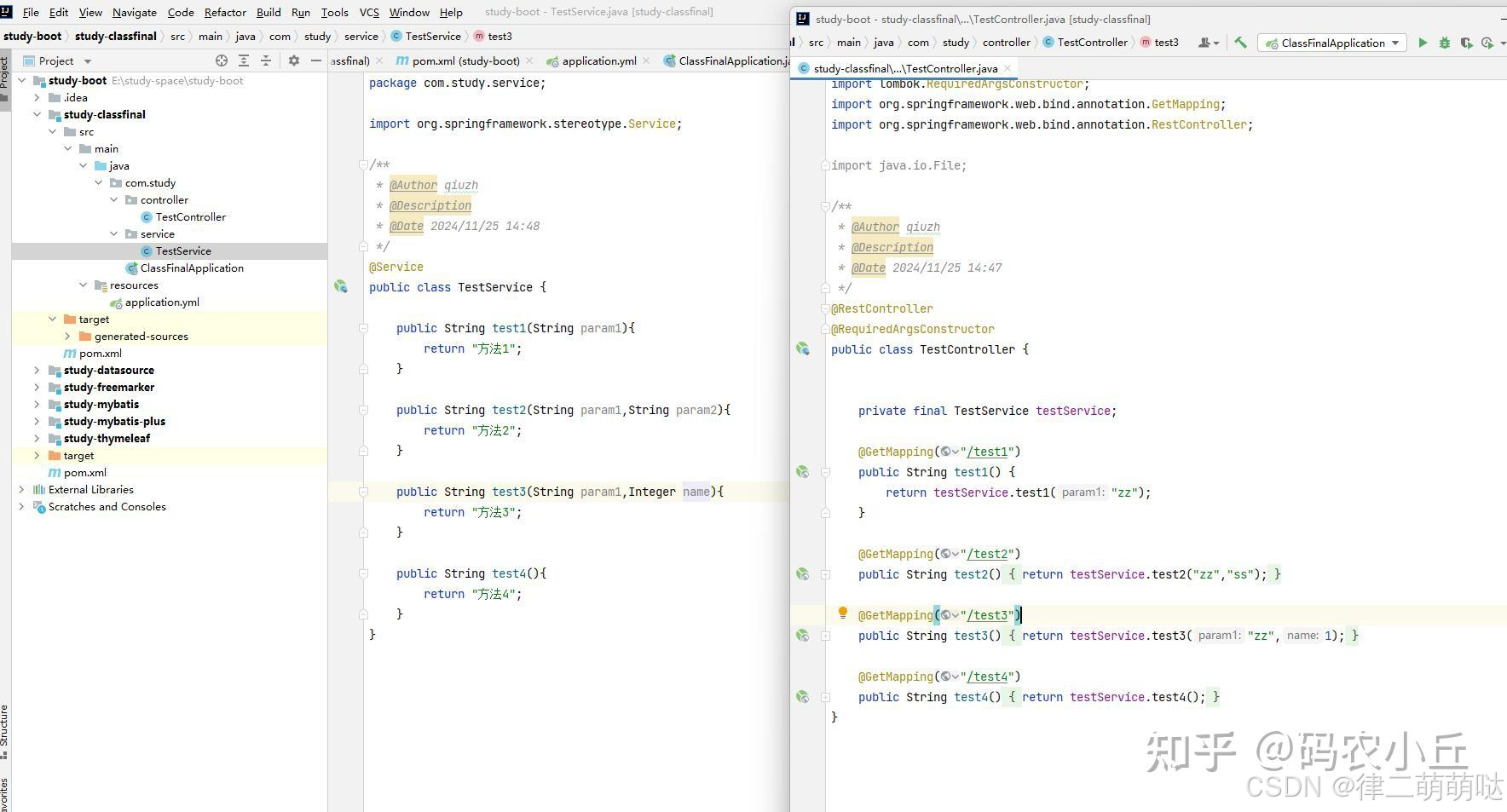
源文件:
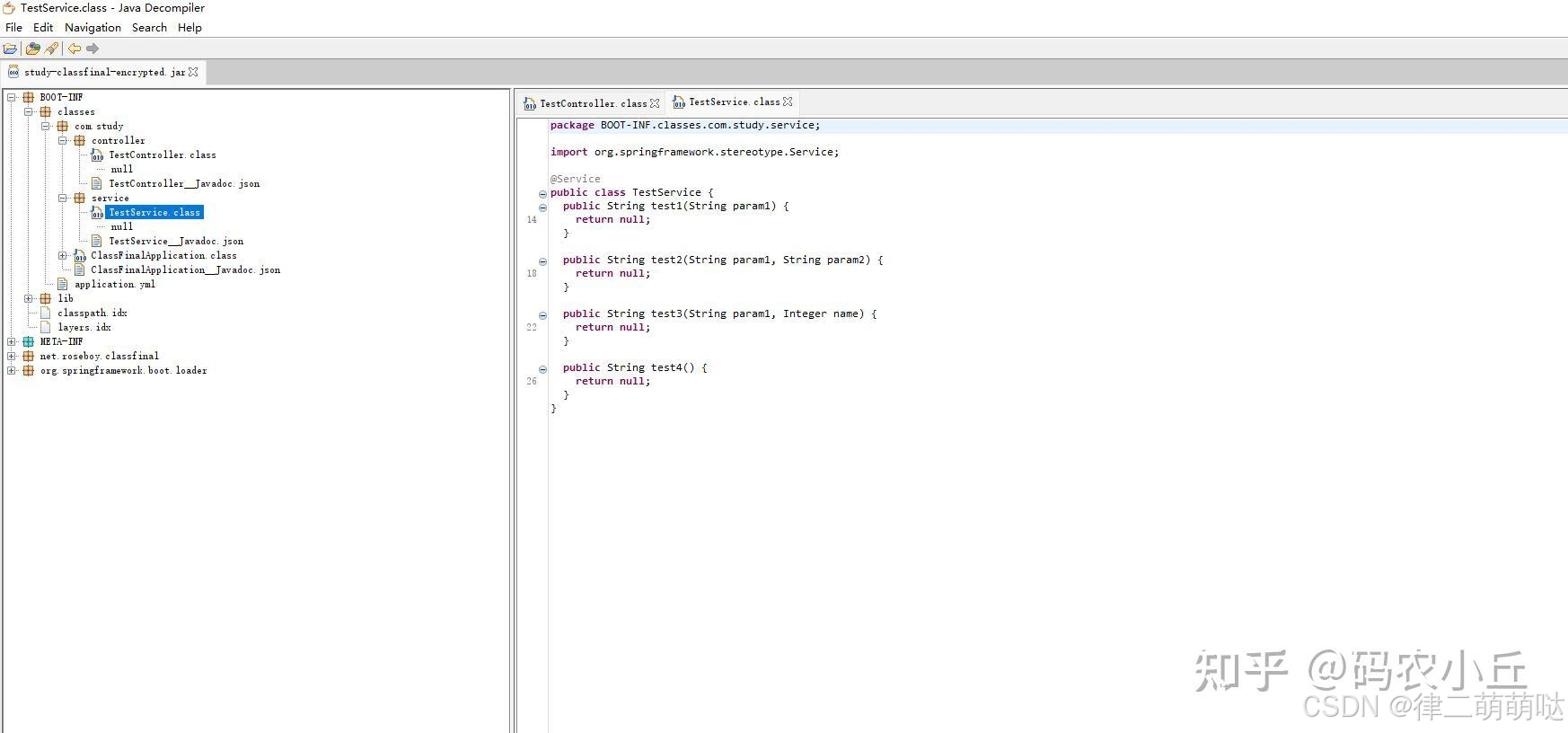
三:启动
命令启动方式:
#没有密码启动的方式
java -javaagent:study-classfinal-encrypted.jar -jar study-classfinal-encrypted.jar
#有密码启动方式
java -javaagent:study-classfinal-encrypted.jar=-pwd=123456 -jar study-classfinal-encrypted.jar
- 1
- 2
- 3
- 4
- 5
13. springboot配置文件中的敏感信息如何加密
在Spring Boot中,可以使用Jasypt库来加密配置文件中的敏感信息,如数据库密码、API密钥等。以下是使用Jasypt加密敏感信息的基本步骤:
1. 引入Jasypt依赖:
在项目的pom.xml文件中添加Jasypt的依赖。例如:
<dependency>
<groupId>com.github.ulisesbocchiogroupId>
<artifactId>jasypt-spring-boot-starterartifactId>
<version>3.0.5version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
2. 配置加密信息:
在配置文件中(如application.properties或application.yml)配置加密所需的秘钥。例如:
jasypt.encryptor.password=your-secret-key
- 1
- 加密敏感信息:
使用Jasypt提供的工具或代码对敏感信息进行加密。可以通过Maven插件或Java代码实现。例如,使用Maven插件加密的命令如下:
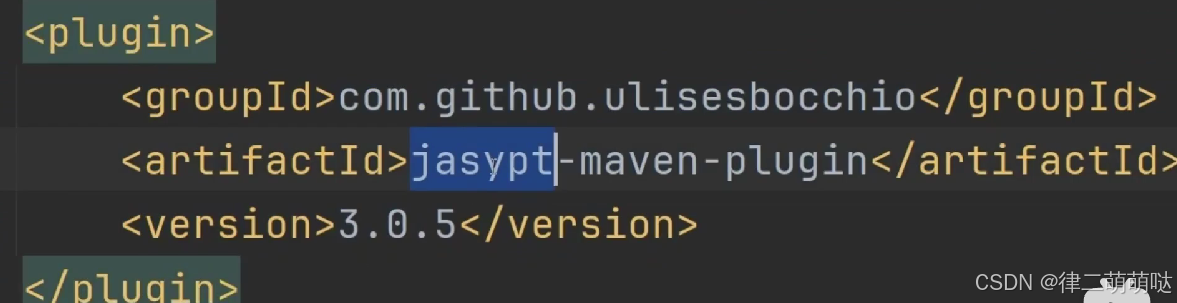
mvn jasypt:encrypt-value -Djasypt.encryptor.password=your-secret-key -Djasypt.plugin.value=your-sensitive-info
- 1
4. 替换明文:
将加密后得到的密文替换配置文件中的敏感信息,并使用ENC()包裹起来。例如:
spring.datasource.password=ENC(encrypted-password)
- 1
5. 启动项目:
启动Spring Boot项目时,Jasypt会自动解密配置文件中用ENC()包裹的密文。
需要注意的是,为了安全起见,不建议在配置文件中直接展示加密密钥。通常的做法是在启动项目时通过启动参数来传递密钥。例如,在IDEA中本地启动项目时,可以在运行配置中设置VM Options:
-Djasypt.encryptor.password=your-secret-key
- 1
或者在使用命令行启动项目时传递密钥:
java -jar -Djasypt.encryptor.password=your-secret-key your-application.jar
- 1
通过以上步骤,可以有效地保护Spring Boot配置文件中的敏感信息,防止其被泄露。同时,建议定期更换加密密钥,并妥善保管好密钥信息,以确保安全性。
14. MySQL分布式主键
在Mysql的分布式环境中,为什么不推荐使用自增主键?
'id' INT(10) NOT NULL AUTO_INCREMENT
- 1
单库情况下做主键是没有问题的,但分布式情况下就会存在问题。
负载均衡问题:
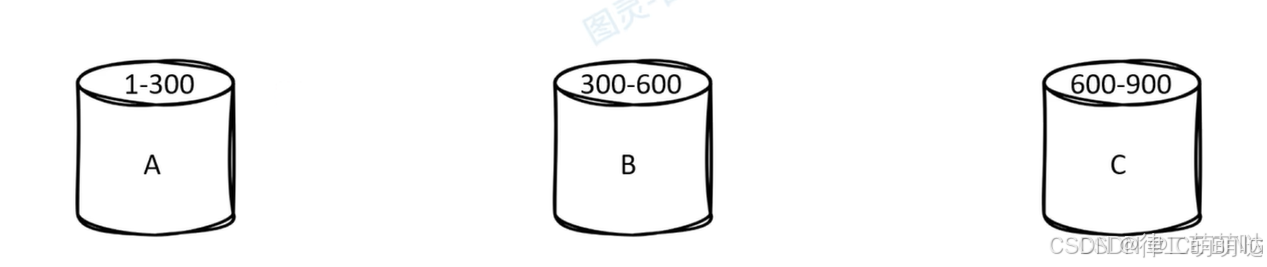
其中A库中的id用完之后才会使用B库,此时C库是闲置的,造成资源空置问题。
性能损耗问题:
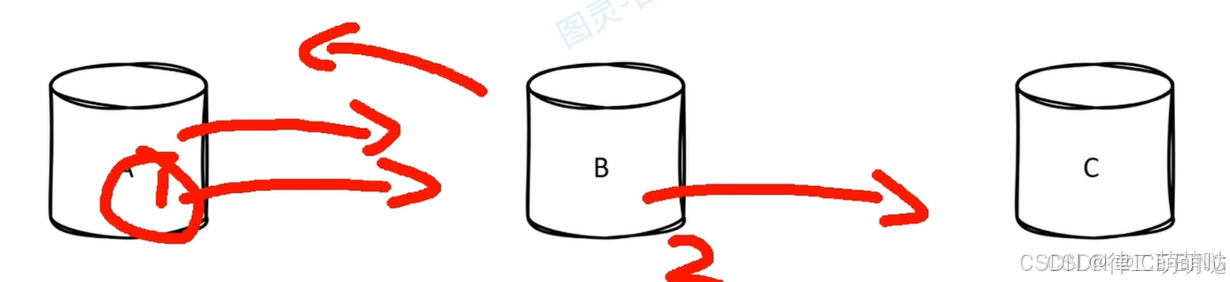
资源同步过程中需要加锁进行处理,自带id会损耗性能。
id冲突:
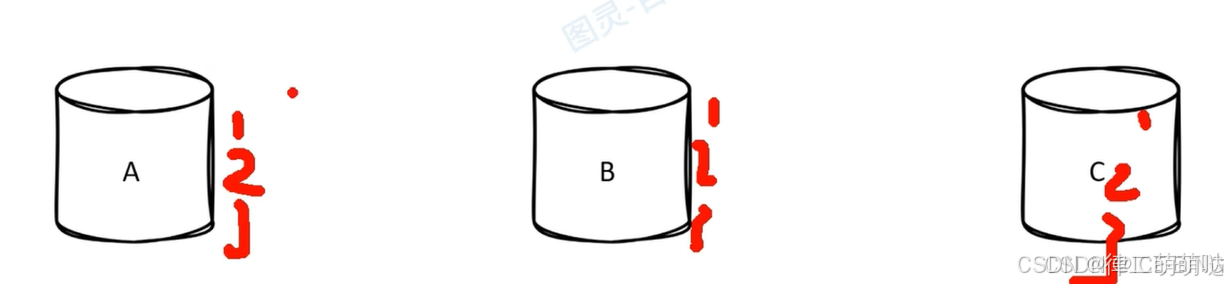
每个数据库都维护自己的id,例如:当三个库都从1,2,3…开始,就会出现数据冲突的问题(都出现id=1的情况)。
UUID可以用来做主键吗?会存在什么问题?
因为数据库底层是B+树结构:
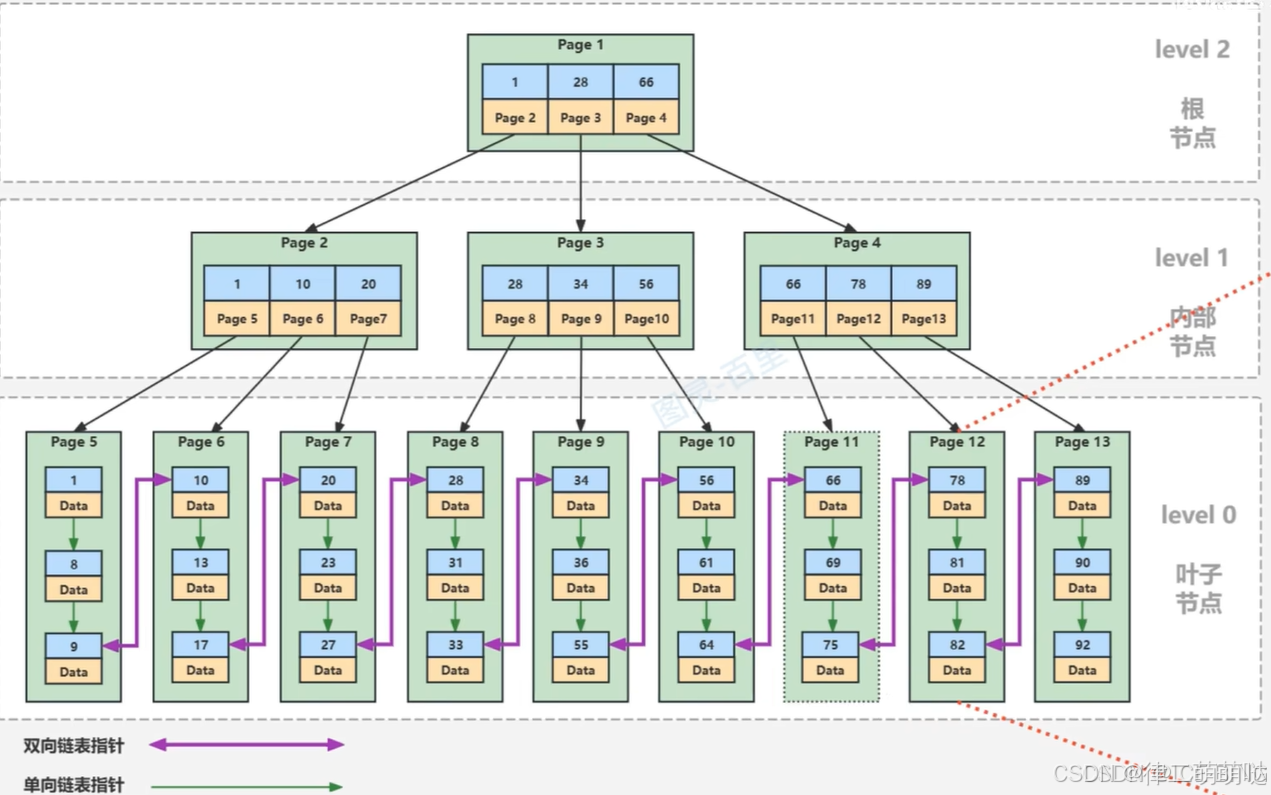
底层通过页为大小进行存储数据的,并且B+树是排好序的,而对于uuid的生成并不是有序的,这样在插入数据时就可能会造成频繁的数据移动问题,从而严重影响性能。
但在Mysql8.0版本推出一个(bin to UUID)函数,这个可以实现UUID有序。
雪花算法可以用做主键吗?原理是怎样的?有什么优缺点?如何解决这些缺点?
雪花算法的特点和定义:
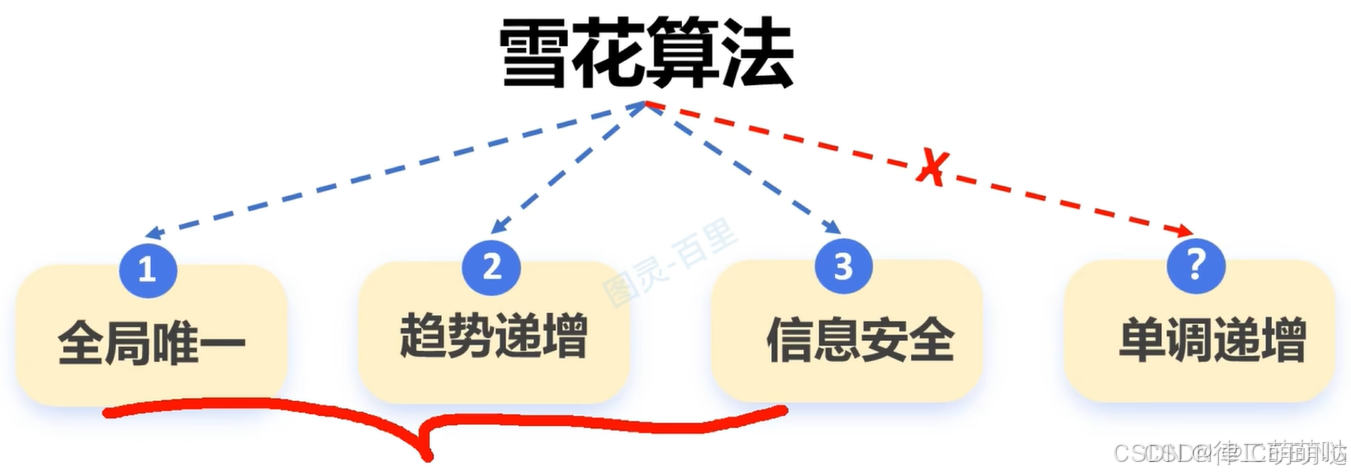
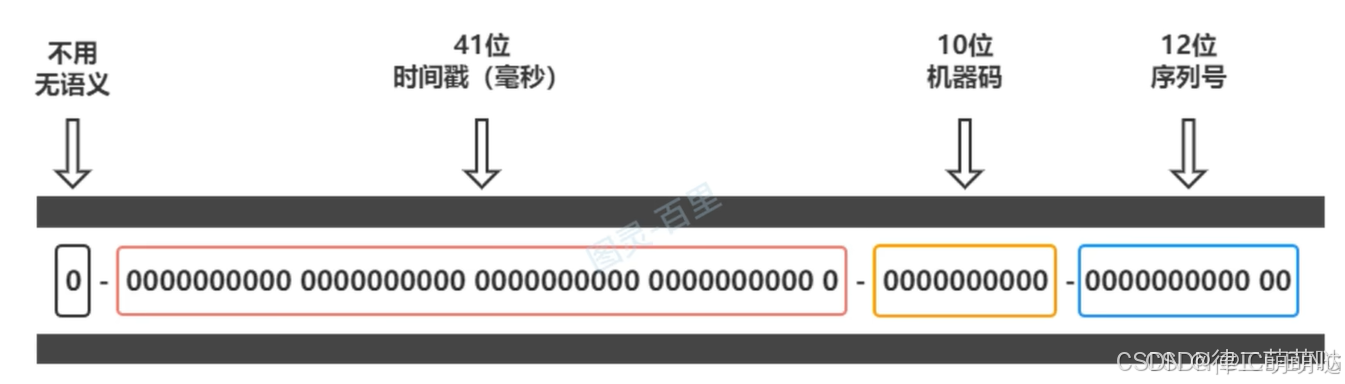

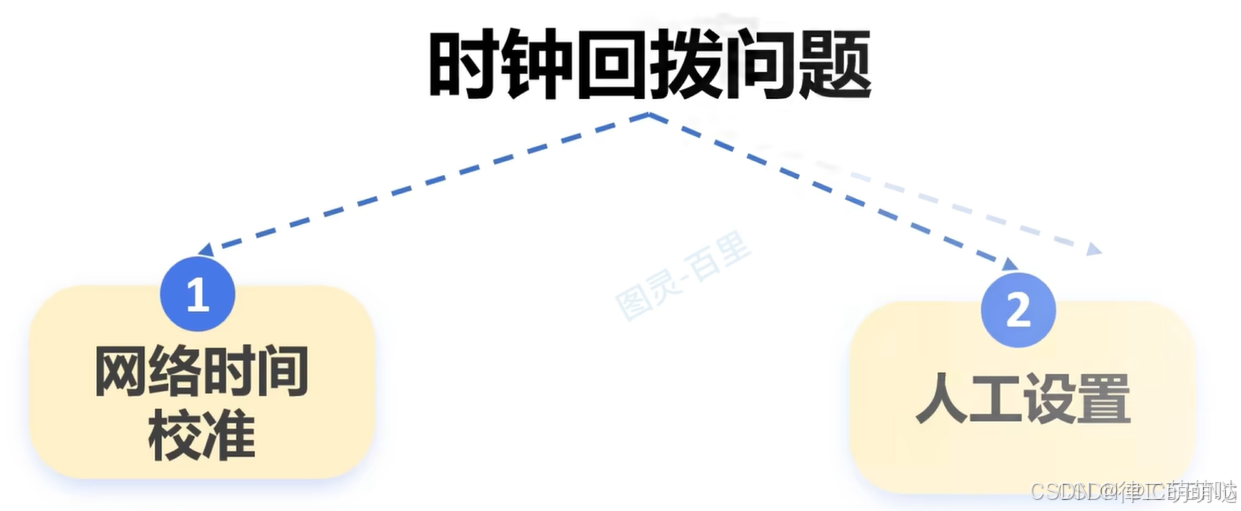
时钟回拨
可能会存在时钟回拨问题:

解决方案:
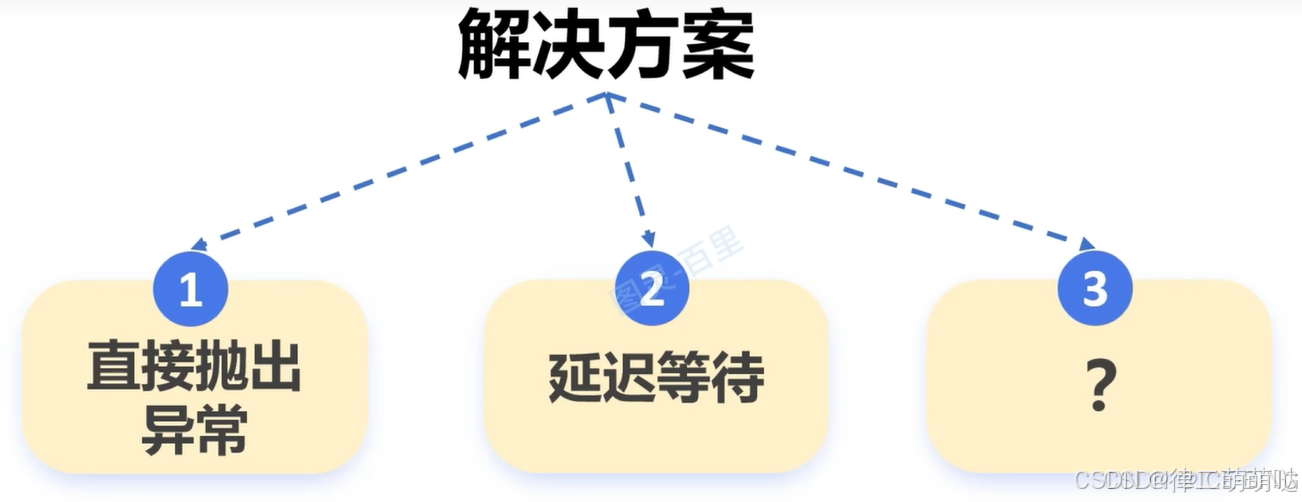
推荐第三种方案,对雪花算法进行改造:
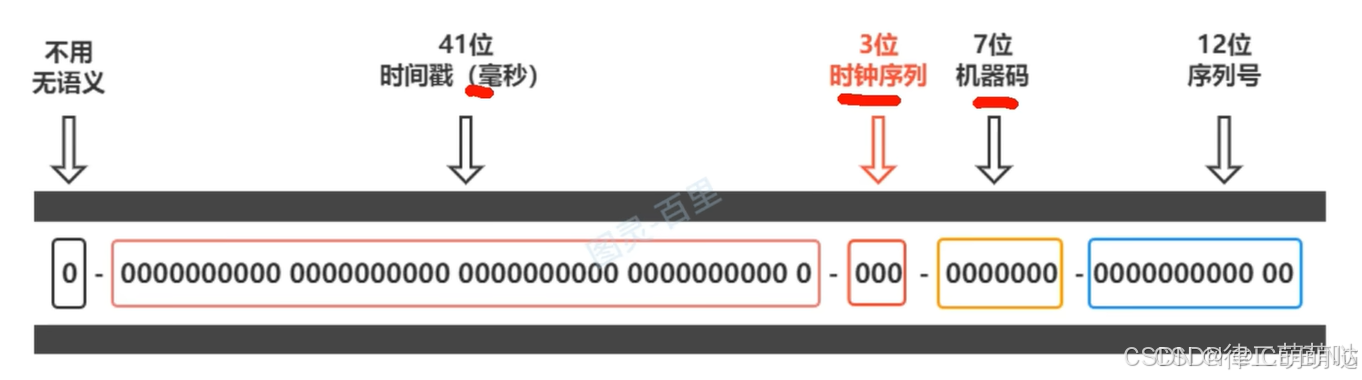
当发现始终回拨问题后就可以递增始终序列。如果三位不满足需求可以从序列号或机器码再借几位分配给时钟序列。
15. 如何设计一个高并发系统
在短时间内有大量用户请求访问系统,需要系统能够快速稳定的响应这些请求
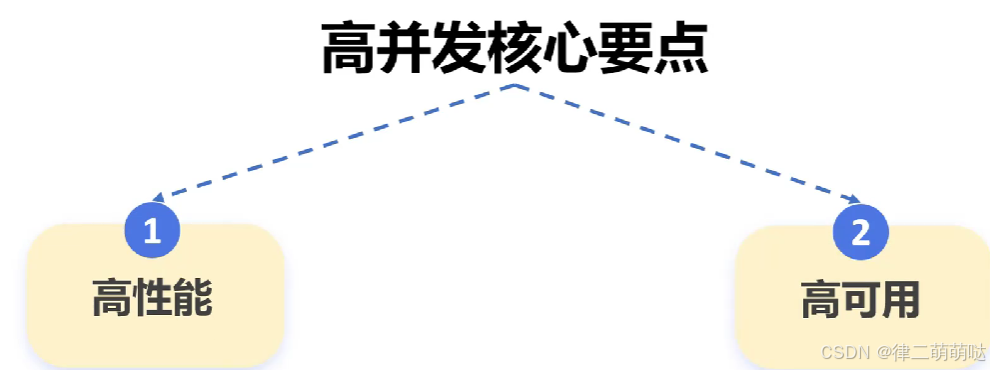
高并发系统必须具备的几个关键因素
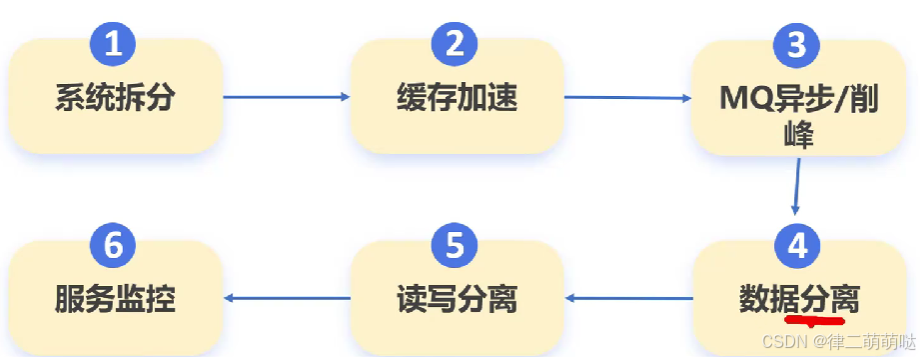
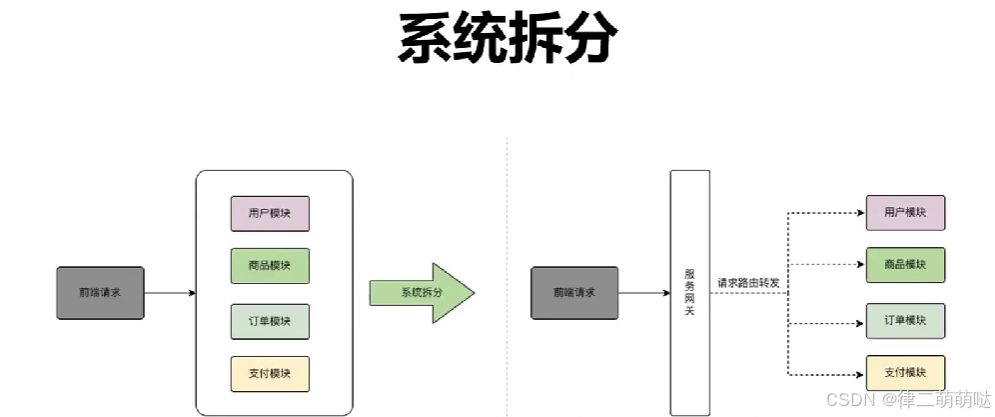
1. 系统拆分:
- 1
首先,将大型单体应用拆分为多个微服务。每个微服务负责特定的业务功能,这样可以减少单一服务的压力,提高系统的可扩展性和可维护性。
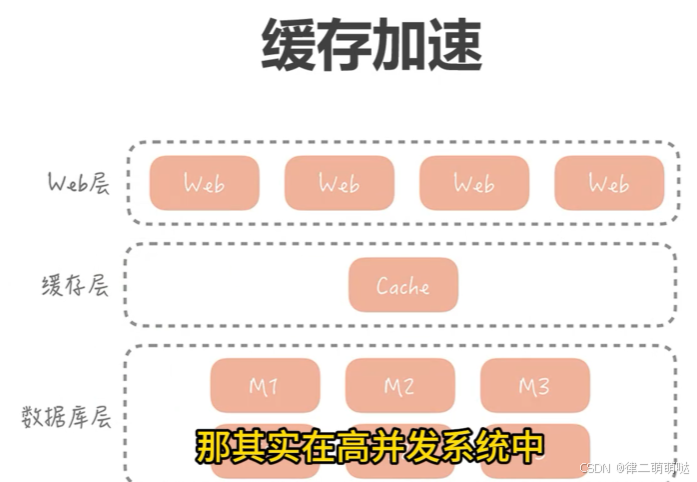
2. 缓存加速:
- 1
利用内存缓存技术,如Redis或Memcached,来存储频繁访问的数据。这样,当相同的数据被多次请求时,可以直接从缓存中获取,而无需访问数据库,从而大大减少数据库的压力。对于读多写少的场景,缓存可以显著提升系统的响应速度和吞吐量。
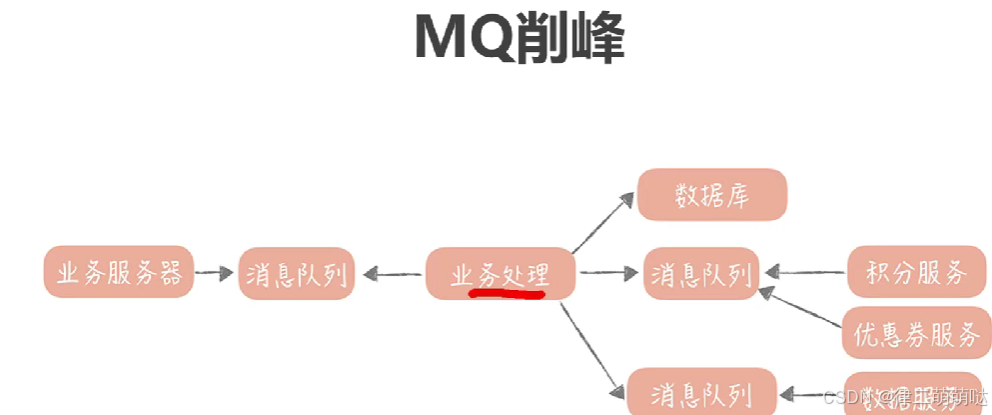
3. 异步处理与削峰:
- 1
引入消息队列(MQ),如RabbitMQ或Kafka,来实现任务的异步处理。通过将请求放入消息队列中,再由后台服务异步处理,可以避免请求直接访问数据库,减轻系统的瞬时压力。同时,消息队列还可以起到削峰填谷的作用,平滑请求的高峰期,保护系统不被瞬间高流量压垮。
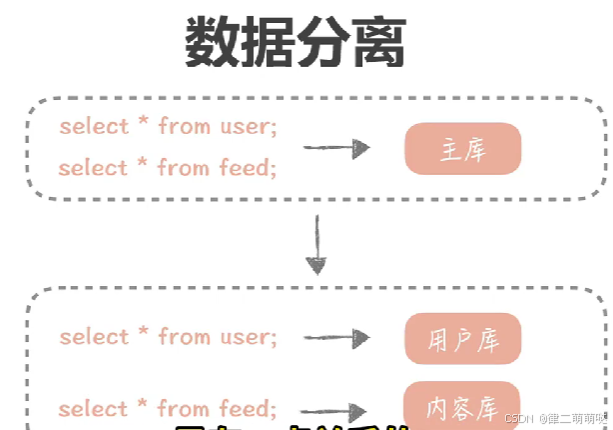
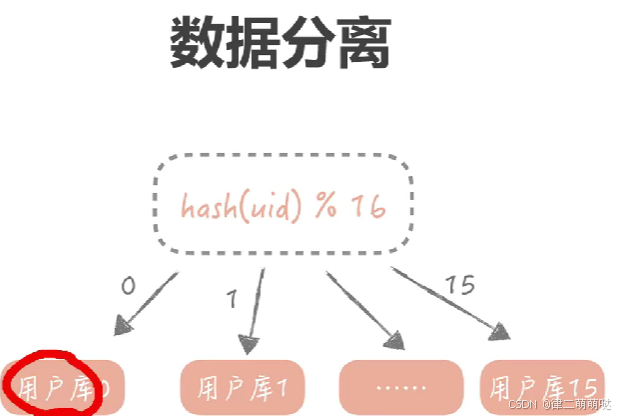
4. 数据分离:
- 1
根据数据的访问频率和重要性,将热点数据和普通数据分离。热点数据可以放在高性能的存储中,以提高访问速度;而普通数据则可以放在成本较低的存储中,以节省资源。此外,还可以使用数据库分库分表技术来减少单一数据库的瓶颈,提高系统的并发处理能力。
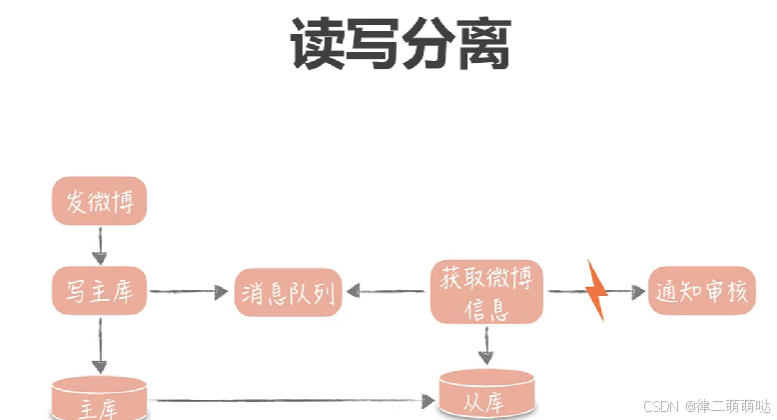
5. 读写分离:
- 1
在数据库层面进行读写分离,将读操作和写操作分离到不同的数据库实例上。读操作访问从库,写操作访问主库。这样可以提高系统的并发处理能力,因为读操作通常比写操作更频繁,且对数据的一致性要求较低。同时,需要确保数据的一致性和完整性,可以通过双写模式或延迟双写模式来实现。
6. 服务监控:
- 1
最后,建立全面的服务监控体系,实时监控系统的各项性能指标,如CPU使用率、内存占用率、网络流量以及请求响应时间等。一旦发现系统出现性能瓶颈或故障,应立即触发报警机制,通知运维团队进行处理。这样可以确保系统在高并发场景下依然能够高效、稳定运行
16. 如何设计百亿短url生成器
需求分析
- 1
短URL生成器,也称作短链接生成器,就是将一个比较长的URL生成一个比较短的URL,当浏览器通过短URL生成器访问这个短URL的时候,重定向访问到原始的长URL目标服务器,访问时序图如下。
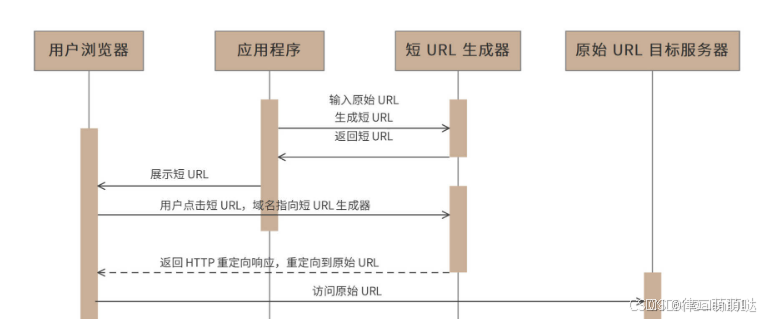
对于需要展示短URL的应用程序,由该应用调用短URL生成器生成短URL,并将该短URL展示给用户,用户在浏览器中点击该短URL的时候,请求发送到短URL生成器(短URL生成器以HTTP服务器的方式对外提供服务,短URL域名指向短URL生成器),短URL生成器返回HTTP重定向响应,将用户请求重定向到最初的原始长URL,浏览器访问长URL服务器,完成请求服务。
原始URL如何变短的
2进制转换为10进制长度会变短,当进制往高位转换时,长度会变短
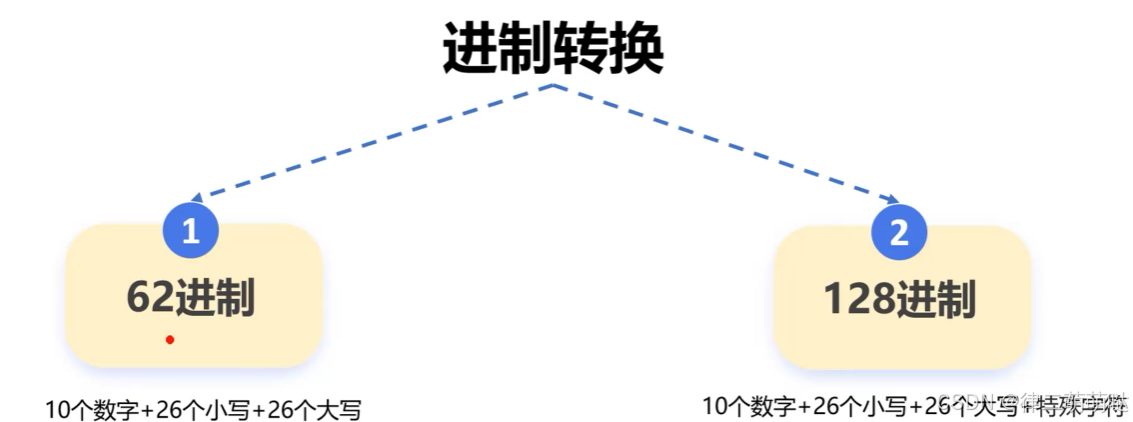
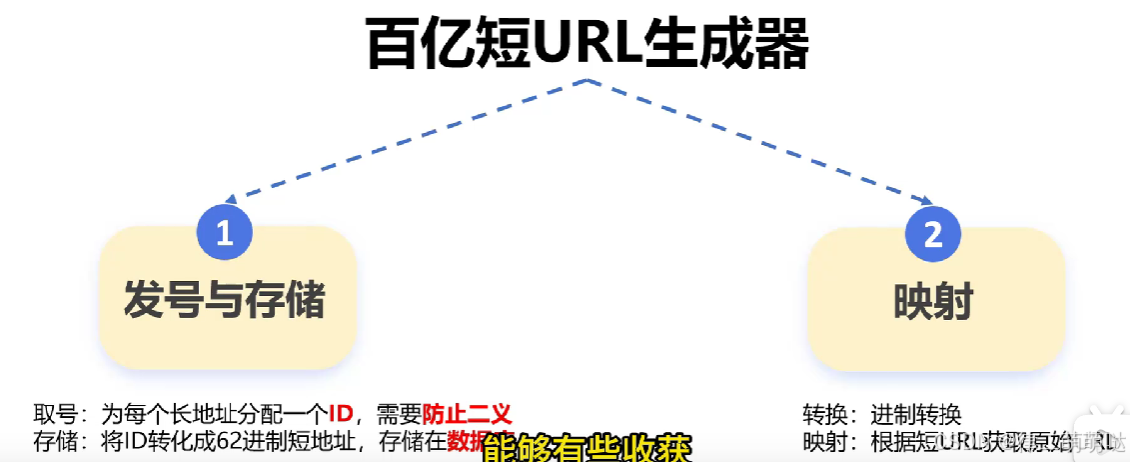
发号与存储:
- 取号:为每个长地址分配一个ID,需要防止二义性。
- 存储:将ID转化成62进制短地址,存储在数据库中。
映射:
- 转换:进制转换。
- 映射:根据短URL获取原始URL。
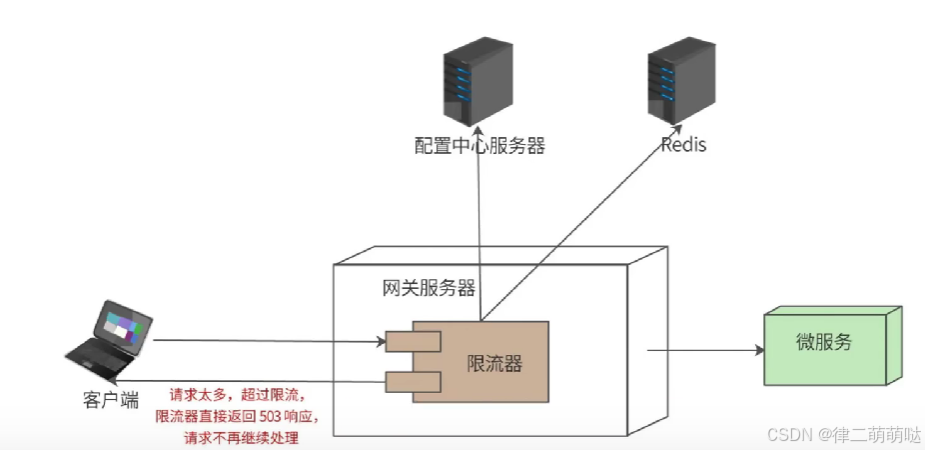
17. 怎么应对热点事件的突发访问压力
解决方案,在网关服务器中添加限流器
常见的限流算法有以下几种:
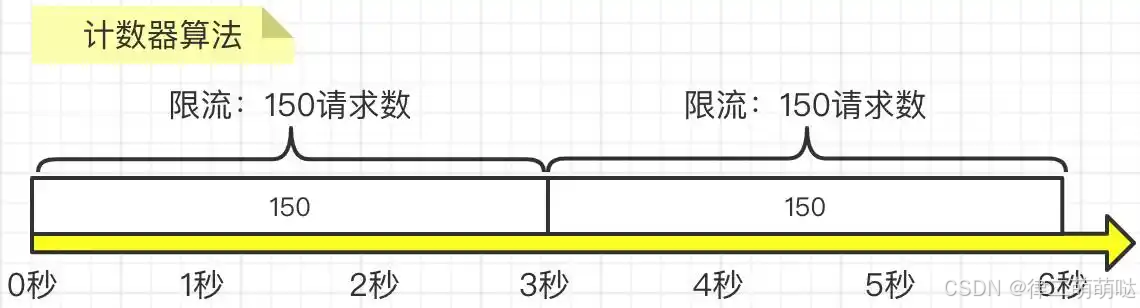
一、计数器算法
- 1
在指定周期内累加访问次数,当访问次数达到设定的阈值时,触发限流策略,当进入下一个时间周期时进行访问次数的清零。如图所示,我们要求3秒内的请求不要超过150次:
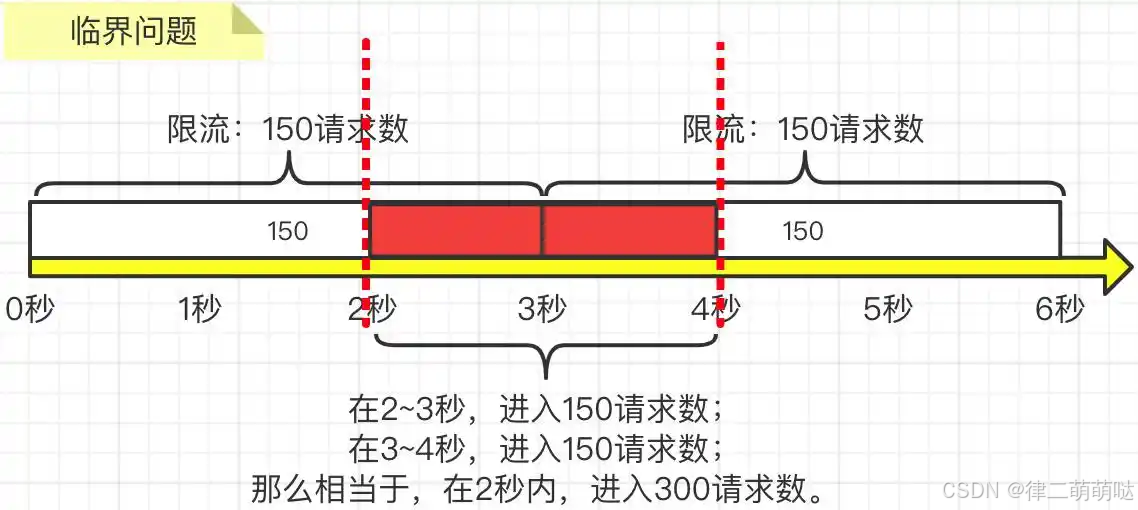
但是,貌似看似很“完美”的流量统计方式其实存在一个非常严重的临界问题,即:如果第2到3秒内产生了150次请求,而第3到4秒内产生了150次请求,那么其实在第2秒到第4秒这两秒内,就已经发生了300次请求了,远远大于我们要求的3秒内的请求不要超过150次这个限制,如下图所示:
二、滑动窗口算法
- 1
滑动窗口为固定窗口的改良版,解决了固定窗口在窗口切换时会受到两倍于阈值数量的请求,滑动窗口在固定窗口的基础上,将一个窗口分为若干个等份的小窗口,每个小窗口对应不同的时间点,拥有独立的计数器,当请求的时间点大于当前窗口的最大时间点时,则将窗口向前平移一个小窗口(将第一个小窗口的数据舍弃,第二个小窗口变成第一个小窗口,当前请求放在最后一个小窗口),整个窗口的所有请求数相加不能大于阈值。其中,Sentinel就是采用滑动窗口算法来实现限流的。如图所示:
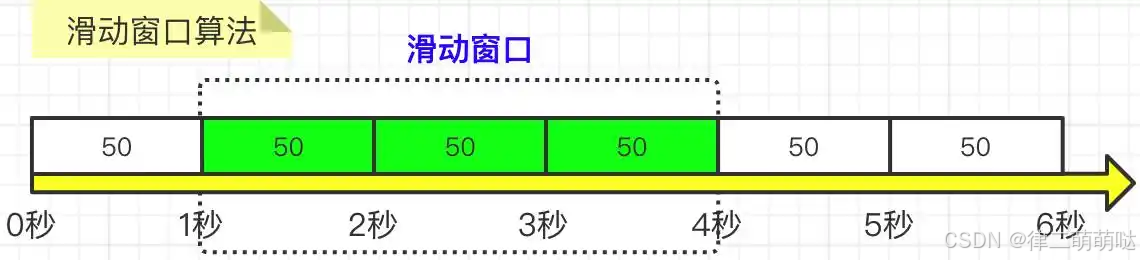
【1】 把3秒钟划分为3个小窗,每个小窗限制请求不能超过50个。
【2】 比如我们设置,3秒内不能超过150个请求,那么这个窗口就可以容纳3个小窗,并且随着时间推移,往前滑动。每次请求过来后,都要统计滑动窗口内所有小窗的请求总量。
三、令牌桶限流算法(控制令牌生成速度,取的速度不控制)
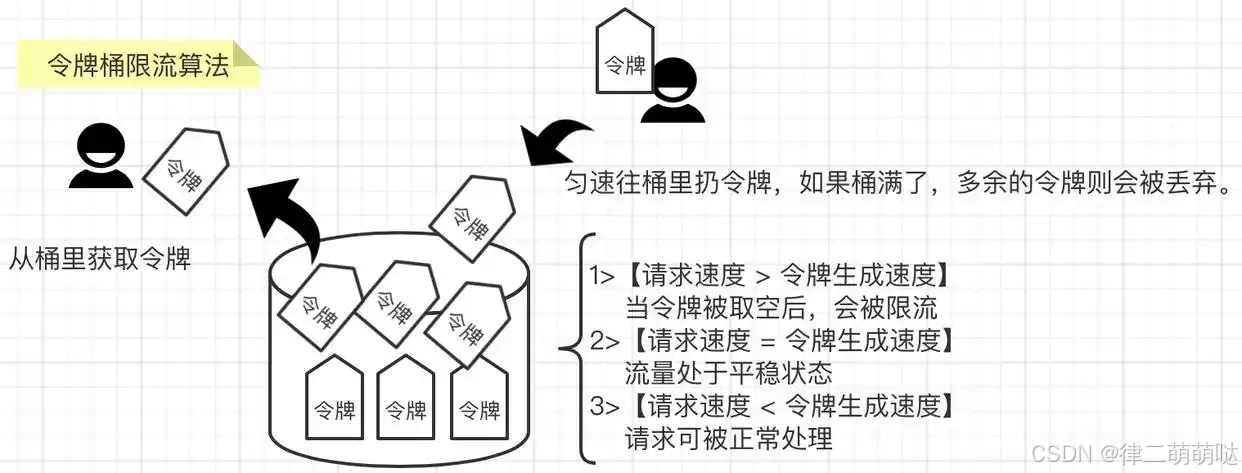
- 1
令牌桶是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。对于每一个请求,都需要从令牌桶中获得一个令牌;如果没有获得令牌,则需要触发限流策略。系统会以恒定速度(r tokens/sec)往固定容量的令牌桶中放入令牌。令牌桶有固定的大小,如果令牌桶被填满,则会丢弃令牌。
会存在三种情况:
【请求速度 大于 令牌生成速度】当令牌被取空后,会被限流
【请求速度 等于 令牌生成速度】流量处于平稳状态
【请求速度 小于 令牌生成速度】请求可被正常处理,桶满则丢弃令牌
如图所示:
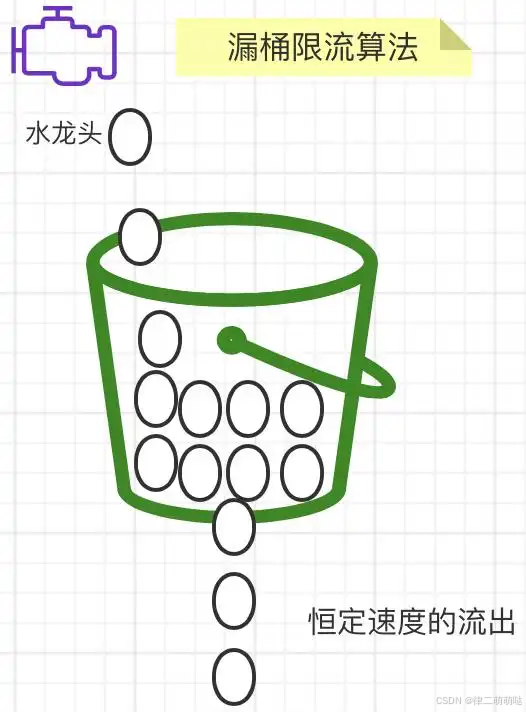
四、漏桶限流算法(控制水滴流出速度,不控制水滴产生速度)
- 1
主要的作用:
【1】 控制数据注入网络的速度。
【2】 平滑网络上的突发流量。
漏桶限流算法的核心就是:不管上面的水流速度有多块,漏桶水滴的流出速度始终保持不变。消息中间件就采用的漏桶限流的思想。如图所示:
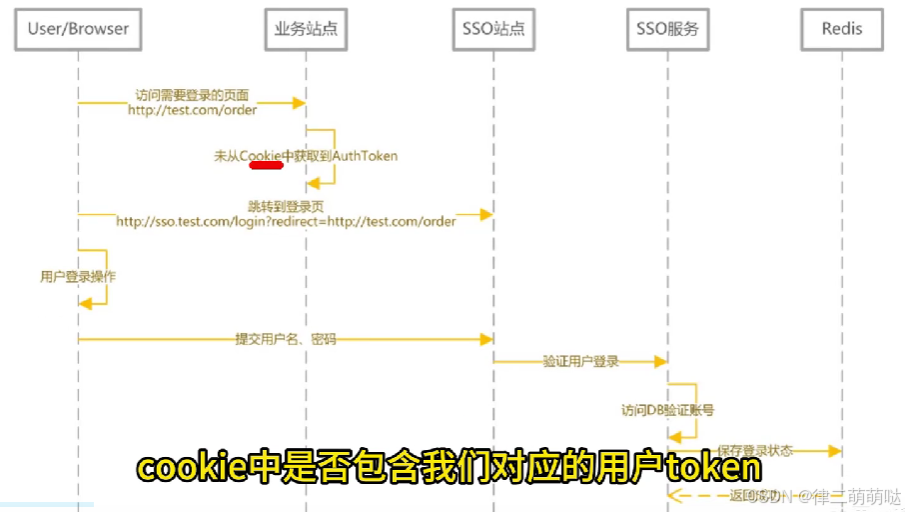
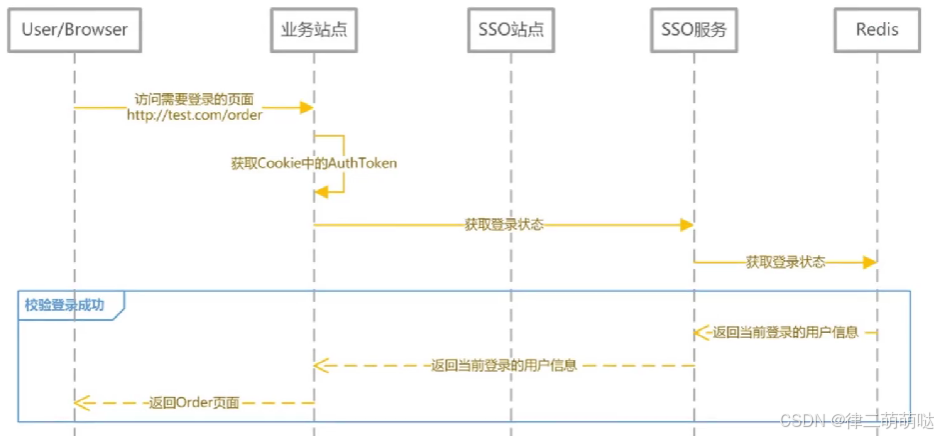
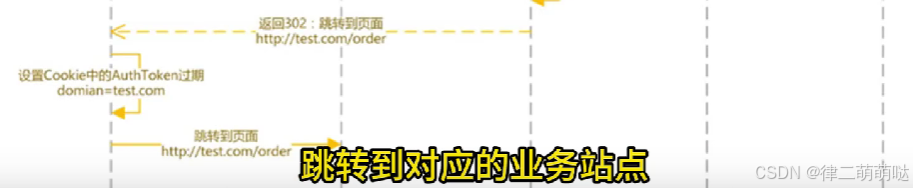
18. 如何实现单点登录
登录时序图
- 1
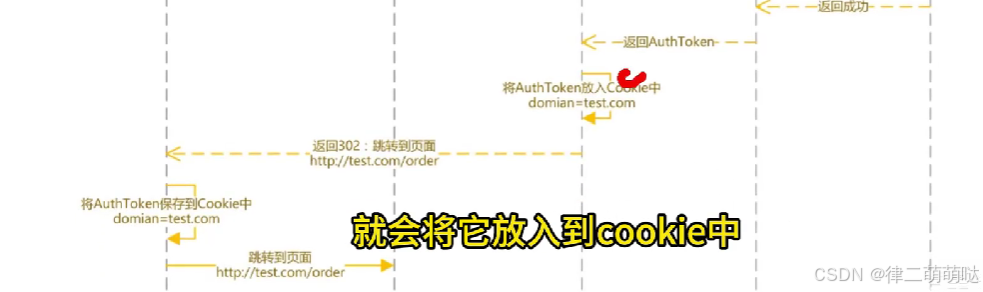
校验时序图
- 1
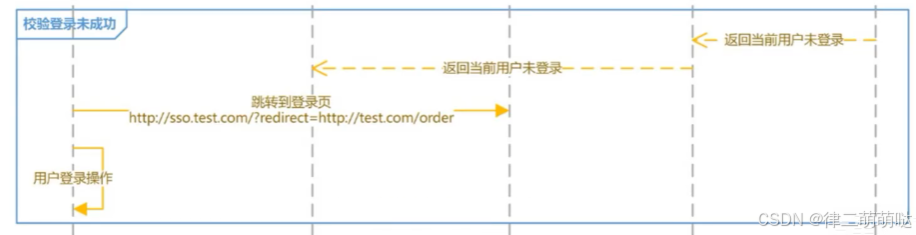
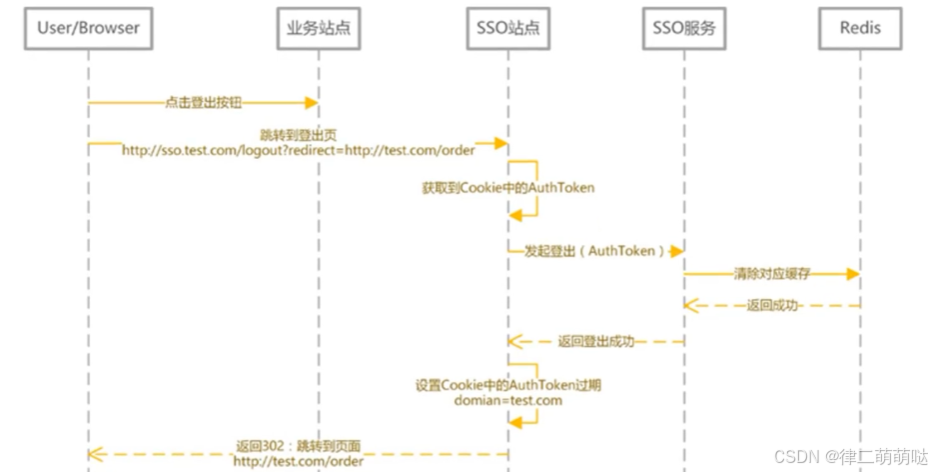
登出时序图
- 1
19. 如何优化慢SQL
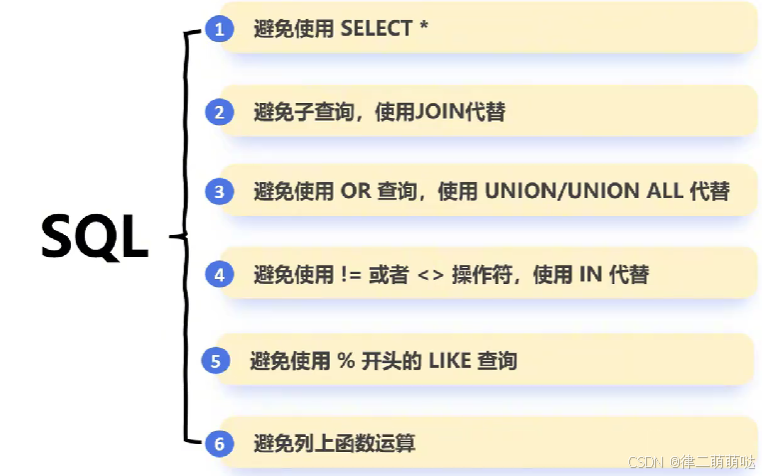
1. 分析SQL
- 1
2. 添加索引
- 1

其它
- 1

20. 定时任务的实现方案有哪些?
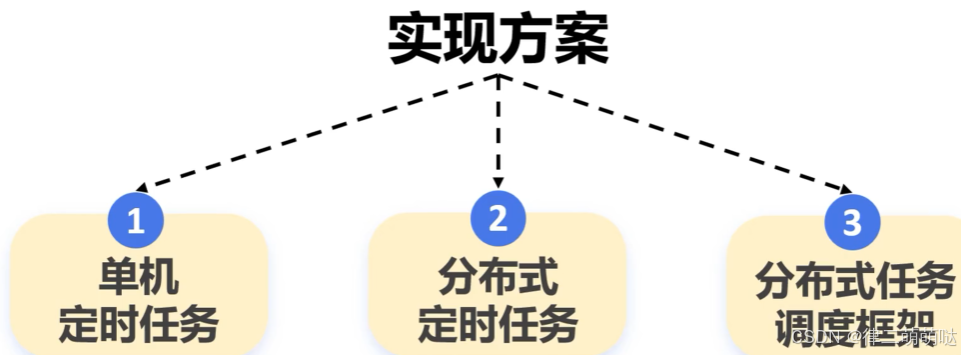
单机定时任务
- 1
1. Timer
Timer是Java标准库中提供的一个简单的定时任务调度类。它允许你安排一个任务在指定的时间执行或者周期性地执行。
优点是使用简单,但缺点是当添加并执行多个任务时,前面任务的执行用时和异常将影响到后面任务。

2. ScheduledExecutorService
ScheduledExecutorService是Java 5引入的Executor框架的一部分,提供了比Timer更强大的功能,包括更好的线程管理和并发控制。
优点是功能强大,适用于多线程环境,缺点是配置相对复杂。
- 1

3. springTask
使用Spring的@Scheduled注解:
如果你的项目使用了Spring框架,那么可以利用Spring提供的@Scheduled注解来配置定时任务。Spring会自动处理任务调度,支持多种配置方式(如固定速率、固定延迟、Cron表达式)。
优点是使用简单,与Spring框架集成良好,缺点是需要在Spring环境下使用。

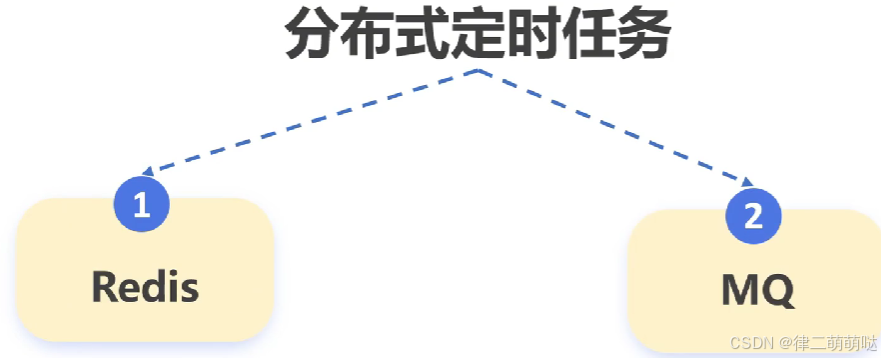
- 使用Redis实现分布式定时任务:
在分布式环境下,可以使用Redis的ZSet和键空间通知功能来实现定时任务。通过将定时任务存放到ZSet集合中,并利用Redis的过期时间来实现定时触发。
优点是适用于分布式环境,缺点是需要额外的Redis配置和管理。
- 使用rabbitMQ和RocketMQ的延时队列实现定时任务
分布式任务调度框架
- 1
-
使用Quartz框架:
Quartz是一个功能强大的开源作业调度框架,适用于企业级应用。它支持复杂的调度策略,如Cron表达式,并提供持久化和集群支持。
优点是功能强大,适用于复杂和高需求的调度任务,缺点是配置相对复杂。 -
使用第三方库如xxl-job:
xxl-job是一个分布式任务调度平台,支持任务的动态管理、调度、失败报警等功能。它提供了Java客户端库,你可以通过引入该库来在Java应用中实现定时任务的调度和管理。
xxl-job适用于需要分布式任务调度功能的场景,它提供了丰富的功能和良好的扩展性。
21. Redis常见三大常见缓存问题
Redis常见的三大缓存问题是:缓存穿透、缓存击穿、缓存雪崩。
缓存穿透:
- 1
描述:缓存穿透是指查询一个不存在的数据,由于缓存中没有数据,这个查询请求会直接穿过缓存层到达数据库层,造成数据库的压力。
解决方案:可以通过接口校验来过滤掉无效恶意的请求;使用空值缓存,当请求的数据在缓存和数据库中都不存在时,将空值缓存起来并设置一个较短的过期时间;或者利用布隆过滤器对请求进行预处理,过滤掉可能不存在的数据。
缓存击穿:
- 1
描述:缓存击穿发生在热点数据缓存失效时,大量请求直接穿透缓存层访问数据库,这会给数据库带来巨大压力。
解决方案:可以使用互斥锁或分布式锁来保护数据加载过程,确保只有一个线程去查询数据库并更新缓存;或者设置热点数据永不过期,后台定期异步更新缓存数据;还可以采用逻辑过期的方式,不设置缓存的过期时间,而是在缓存数据中添加一个逻辑过期时间的字段。
缓存雪崩:
- 1
描述:缓存雪崩指的是在某个时间段内,缓存中大量的数据同时失效,导致大量请求直接访问数据库,给数据库带来巨大压力。
解决方案:可以将缓存的过期时间设置为分散的随机值,避免大量缓存同时过期;使用多级缓存架构,提高缓存的可用性和稳定性;在系统低峰期提前加载热点数据到缓存中进行预热;还可以在缓存不可用或数据库压力过大时,对服务进行降级和限流
22. 为什么阿里禁止使用外键?
阿里禁止使用外键的主要原因包括性能问题、并发问题、级联删除问题以及数据迁移和耦合问题。
性能问题:
- 1
外键约束会增加数据库的负担,因为每次插入、更新或删除操作都需要进行额外的外键检查。这会导致性能下降,特别是在高并发的场景下。数据库需要额外检查外键约束,确保插入的数据符合外键关联关系,这增加了操作的开销。
并发问题:
- 1
外键约束会引入行级锁,导致主表写入时可能会被阻塞,从而影响系统的并发性能。在高并发情况下,大量的级联更新请求可能会相互阻塞,形成数据库更新风暴,导致数据库性能急剧下降甚至瘫痪。
级联删除问题:
- 1
多层级联删除可能会导致数据变得不可控。例如,删除一个主表记录时,所有相关的从表记录也会被删除,这可能会引发数据丢失或数据关系混乱。
数据迁移和耦合问题:
- 1
外键约束会导致数据库表之间的耦合度增加,数据迁移和维护变得更加困难。如果需要将数据迁移到其他数据库系统,必须先解除外键约束。此外,数据库层面数据关系产生耦合,也增加了数据迁移和维护的复杂性。
综上所述,阿里禁止使用外键是为了避免上述问题的发生,提高系统的性能和稳定性。在实际开发中,阿里建议在应用层面处理数据的一致性和完整性,而不是依赖数据库的外键约束。
23. 5分钟搞懂K8S
什么是Kubernetes(k8s)
Kubernetes 是一个开源的容器编排系统,用于自动化地部署、扩展和管理容器化应用程序。
Kubernetes 源自谷歌内部的 Borg 系统,旨在实现容器化应用的高效管理。它提供了服务发现、负载均衡、自动扩缩容等功能,并支持跨主机的容器管理。Kubernetes 的设计以“一切以服务为中心”为指导思想,通过高级调度、自我修复、自动推出和回滚、水平扩展和负载均衡等特性,实现了对容器化应用的全面自动化管理。
具体来说,Kubernetes 的主要功能包括:
- 自动调度:Kubernetes 提供高级调度器来启动容器,优化资源利用率。
- 自我修复:它能重新调度、替换和重新启动已失效的容器,确保服务的可用性。
- 自动推出和回滚:支持针对容器化应用程序的所需状态进行推出和回滚操作。
- 服务发现与负载均衡:Kubernetes 提供服务发现机制,无需修改应用程序即可使用陌生的服务发现。
- 横向扩展:可以根据要求自动扩展和缩减应用程序。
- 存储编排:自动挂载所选存储系统,包括本地存储和网络存储系统。
- 配置管理:允许部署和更新 Secrets 和应用程序的配置,而无需重新构建容器镜像。
此外,Kubernetes 架构遵循客户端-服务器模式,包含主节点(Master)和工作节点(Node)。主节点负责整个集群的管理,工作节点则负责运行容器。
总之,通过这些功能,Kubernetes 不仅简化了应用部署,还实现了云环境的无缝迁移、资源高效利用以及促进 CI/CD 流程,成为现代云原生应用的重要基础设施
K8S 架构图及各个组件
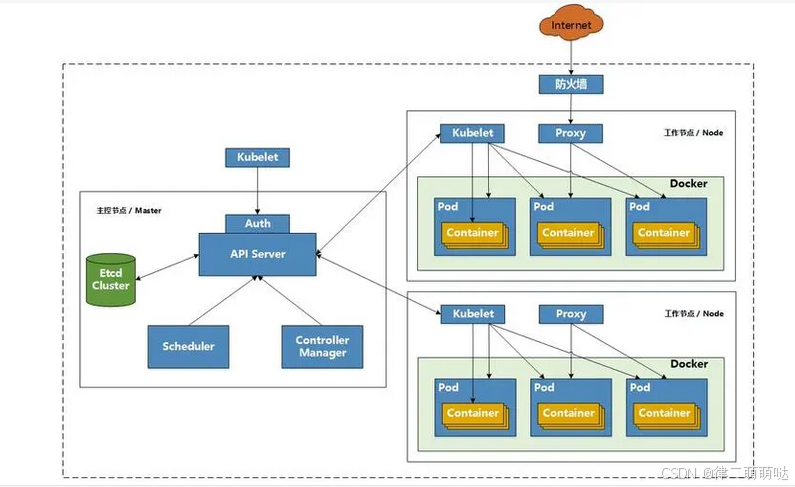

Kubernetes(k8s)的工作流程:
- 用户提交请求:用户通过
kubectl或其他客户端工具提交创建Pod等资源的请求。 - API Server处理请求:
API Server接收请求,进行认证和授权检查,然后将资源对象的数据存储到etcd中。 - 调度器选择节点:调度器监听新的Pod创建请求,根据调度算法和策略选择合适的工作节点(Node),并将绑定结果存储回etcd。
- Kubelet执行任务:各个工作节点上的Kubelet
定期从API Server获取需要运行的Pod清单,调用容器运行时接口(如Docker)创建和启动容器实例。 - 控制器确保状态同步:各类控制器(如部署控制器、副本集控制器)通过list-watch机制监控API
Server中的资源对象状态,确保实际状态与期望状态一致,如有必要,会自动调整以维持期望状态。
这个流程展示了Kubernetes如何通过其组件的紧密协作来自动化管理容器化应用程序,包括服务的部署、更新、扩缩容等操作。
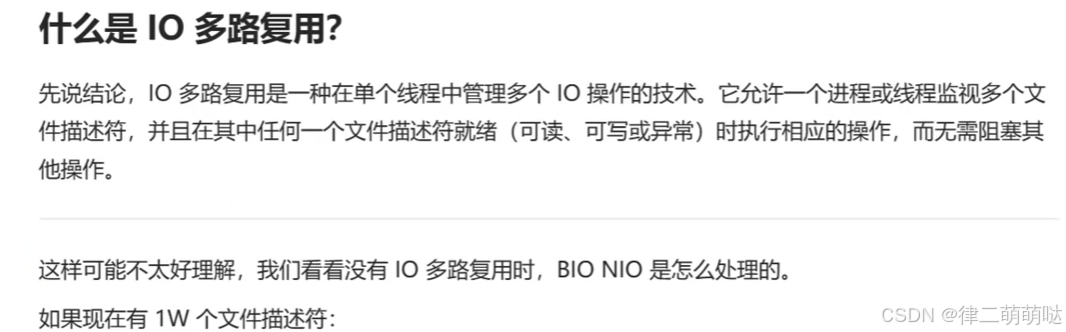
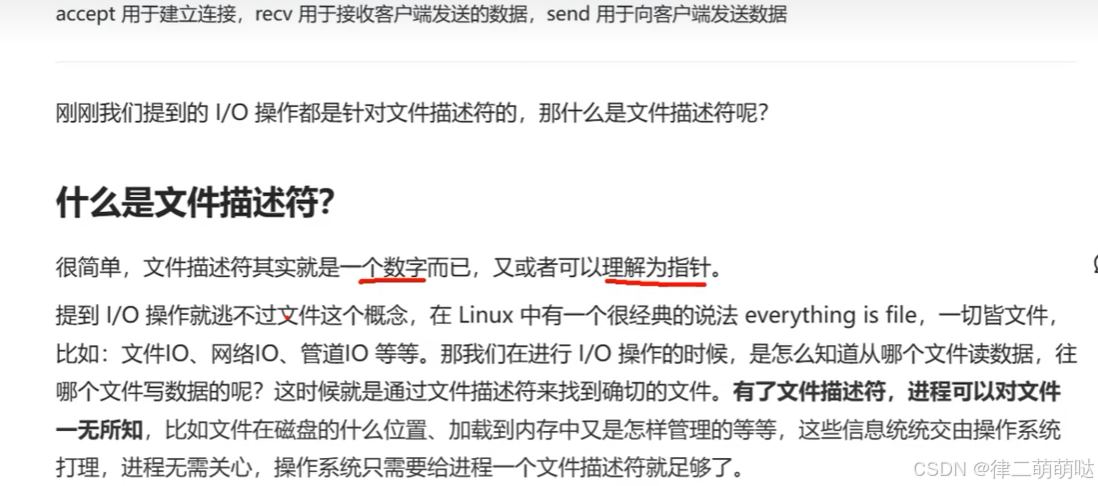
24. 轻松搞懂IO多路复用模型



25. 并行和并发有什么区别

26. Http 和RPC接口的区别




27. Autowired 和Resource的区别

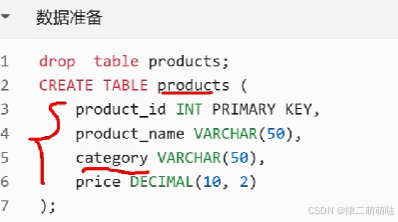
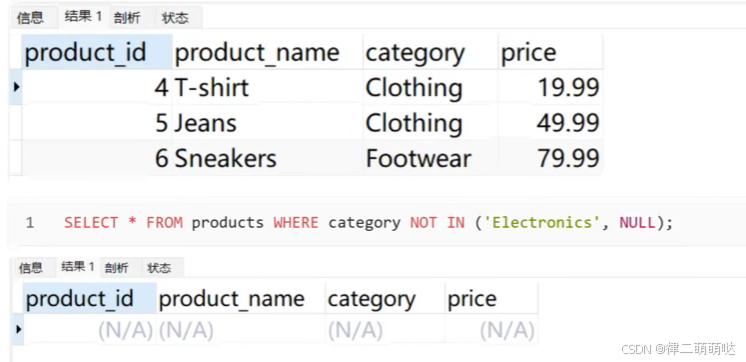
28. not in不仅会导致索引失效,还会导致什么



总结
NOT IN不仅会导致索引失效,还会导致查询效率低下和可能出现错误的查询结果。
查询效率低下:
- 1
当使用NOT IN进行大数据集的查询时,尤其是子查询中包含大量数据时,查询性能可能会显著下降。这是因为NOT IN在处理大数据集时往往不能有效地利用索引,从而导致全表扫描,增加了查询时间。
可能出现错误的查询结果:
当NOT IN的子查询中存在NULL值时,查询结果可能会受到影响。因为NULL值在索引中的处理方式可能导致查询结果不准确,从而返回错误的数据集
29. Redis的大key问题
在使用 Redis 的过程中,如果未能及时发现并处理 Big keys(下文称为“大Key”),可能会导致服务性能下降、用户体验变差,甚至引发大面积故障。
一、大Key的定义
在Redis中,大Key是指占用了较多内存空间的键值对。大Key的定义实际是相对的,通常以Key的大小和Key中成员的数量来综合判定,例如:
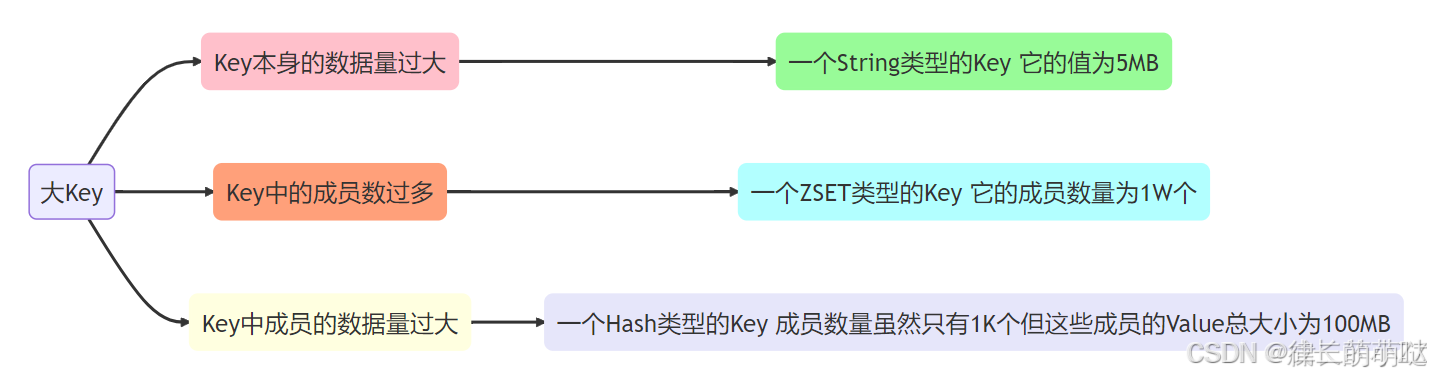
注意:上述例子中的具体数值仅供参考,在实际业务中,您需要根据Redis的实际业务场景进行综合判断。
- 1
二、大Key引发的问题
当Redis中存在大量的大键时,可能会对性能和内存使用产生负面影响,影响内容包括
- 客户端执行命令的时长变慢。
- Redis内存达到maxmemory参数定义的上限引发操作阻塞或重要的Key被逐出,甚至引发内存溢出(Out Of Memory)。
- 集群架构下,某个数据分片的内存使用率远超其他数据分片,无法使数据分片的内存资源达到均衡。
- 对大Key执行读请求,会使Redis实例的带宽使用率被占满,导致自身服务变慢,同时易波及相关的服务。
对大Key执行删除操作,易造成主库较长时间的阻塞,进而可能引发同步中断或主从切换。
上面的这些点总结起来可以分为三个方面:
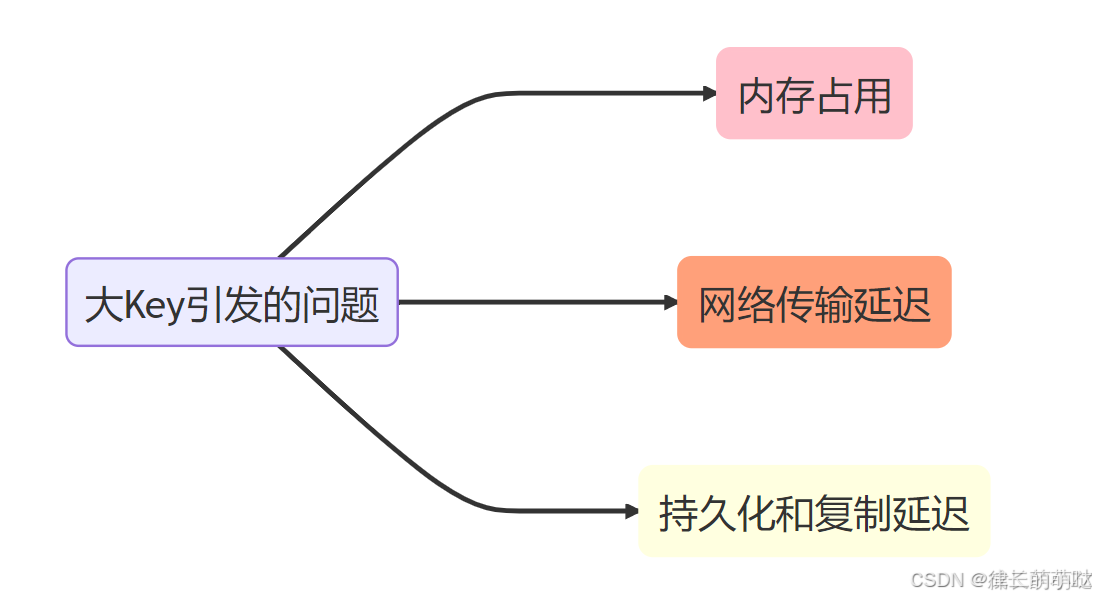
三、大Key产生的原因
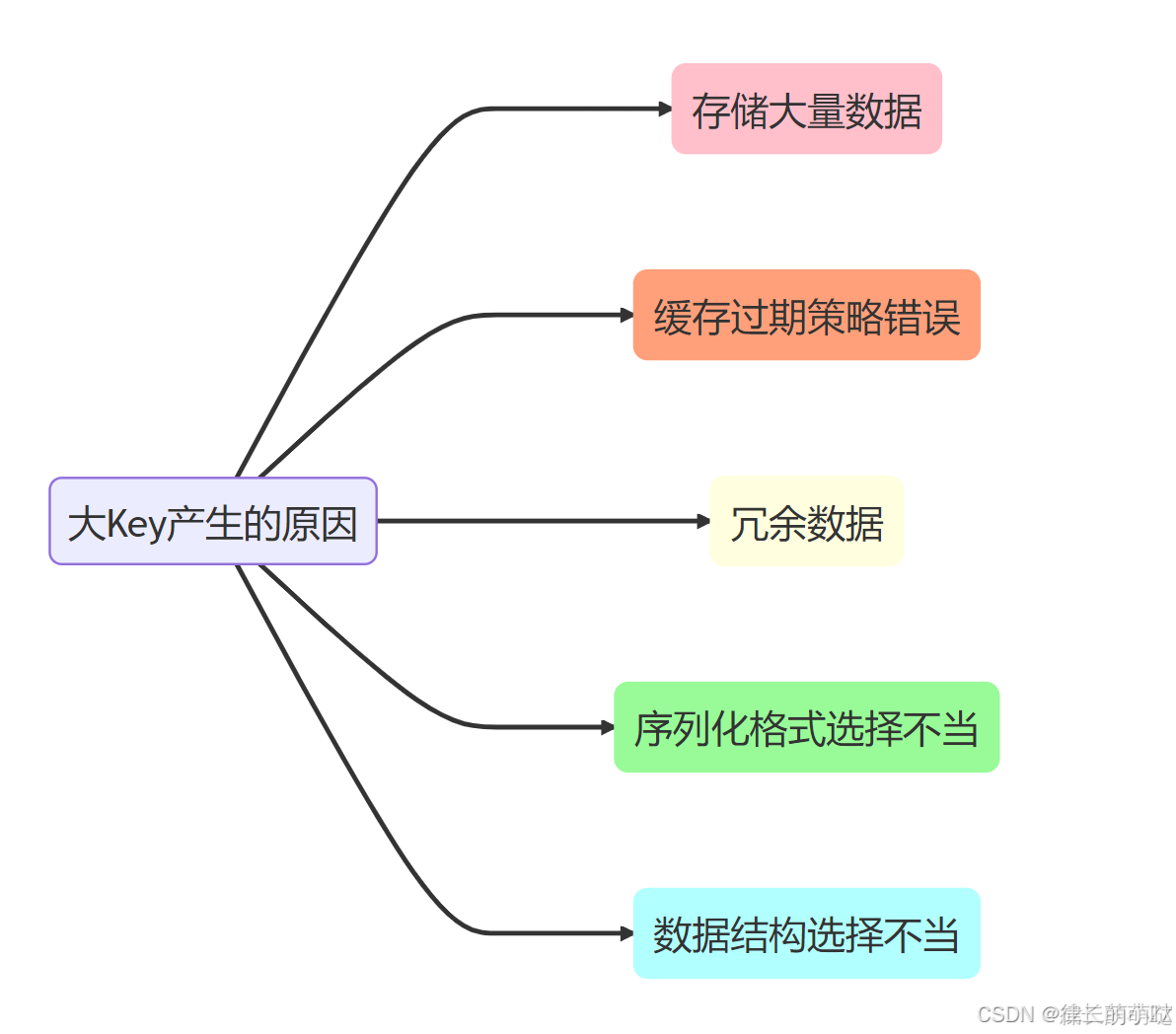
未正确使用Redis、业务规划不足、无效数据的堆积、访问量突增等都会产生大Key,如:在不适用的场景下使用Redis,易造成Key的value过大,如使用String类型的Key存放大体积二进制文件型数据;- 业务上线前规划设计不足,没有对Key中的成员进行合理的拆分,造成个别Key中的成员数量过多;
未定期清理无效数据,造成如HASH类型Key中的成员持续不断地增加;使用LIST类型Key的业务消费侧发生代码故障,造成对应Key的成员只增不减。
上面的这些点总结起来可以分为五个方面:
四、如何快速找出大Key
要快速找出Redis中的大键,可以使用Redis的命令和工具进行扫描和分析。以下是一些方法:
使用Redis命令扫描键:Redis提供了SCAN命令,可以用于迭代遍历所有键。您可以使用该命令结合适当的模式匹配来扫描键,并在扫描过程中获取键的大小(使用MEMORY
USAGE命令)。通过比较键的大小,您可以找出占用较多内存的大键。使用Redis内存分析工具:有一些第三方工具可以帮助您分析Redis实例中的内存使用情况,并找出大键。其中一种常用的工具是Redis的官方工具Redis
Memory Analyzer (RMA)。您可以使用该工具生成Redis实例的内存快照,然后分析快照中的键和它们的大小,以找出大键。使用Redis命令和Lua脚本组合:您可以编写Lua脚本,结合Redis的命令和Lua的逻辑来扫描和分析键。通过编写适当的脚本,您可以扫描键并获取它们的大小,然后筛选出大键。
现在大部分都是使用的云Redis,其本身一般也提供了多种方案帮助我们轻松找出大Key,具体可以参考一下响应云Redis的官网使用文档。
五、大Key的优化方案
大Key会给我们的系统带来性能瓶颈,所以肯定是要进行优化的,那么下面来介绍一下大Key都可以怎么优化。
5.1 对大Key进行拆分
例如将含有数万成员的一个HASH Key拆分为多个HASH Key,并确保每个Key的成员数量在合理范围。在Redis集群架构中,拆分大Key能对数据分片间的内存平衡起到显著作用。
5.2 对大Key进行清理
将不适用Redis能力的数据存至其它存储,并在Redis中删除此类数据。
注意
Redis 4.0及之后版本:可以通过UNLINK命令安全地删除大Key甚至特大Key,
该命令能够以非阻塞的方式,逐步地清理传入的Key。
Redis 4.0之前的版本:建议先通过SCAN命令读取部分数据,然后进行删除,
避免一次性删除大量key导致Redis阻塞。
- 1
- 2
- 3
- 4
- 5
5.3 对过期数据进行定期清理
堆积大量过期数据会造成大Key的产生,例如在HASH数据类型中以增量的形式不断写入大量数据而忽略了数据的时效性。可以通过定时任务的方式对失效数据进行清理。
注意:在清理HASH数据时,建议通过HSCAN命令配合HDEL命令对失效数据进行清理,避免清理大量数据造成Redis阻塞。
5.4 特别说明
如果你用的是云Redis服务,要注意云Redis本身带有的大key的优化方案
30. Mysql同步ES的4种方案
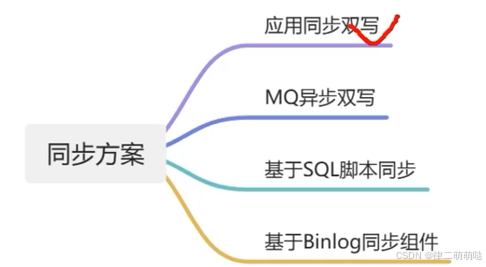
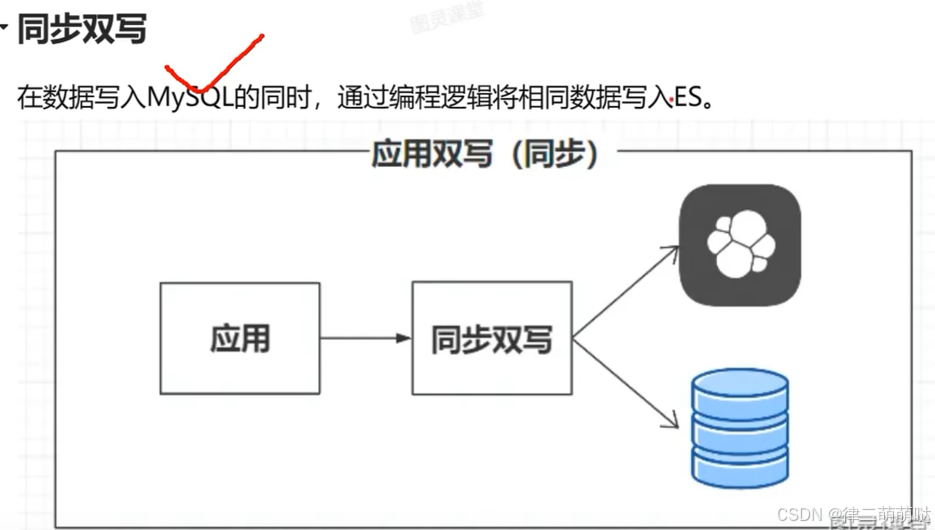
数据同步方案


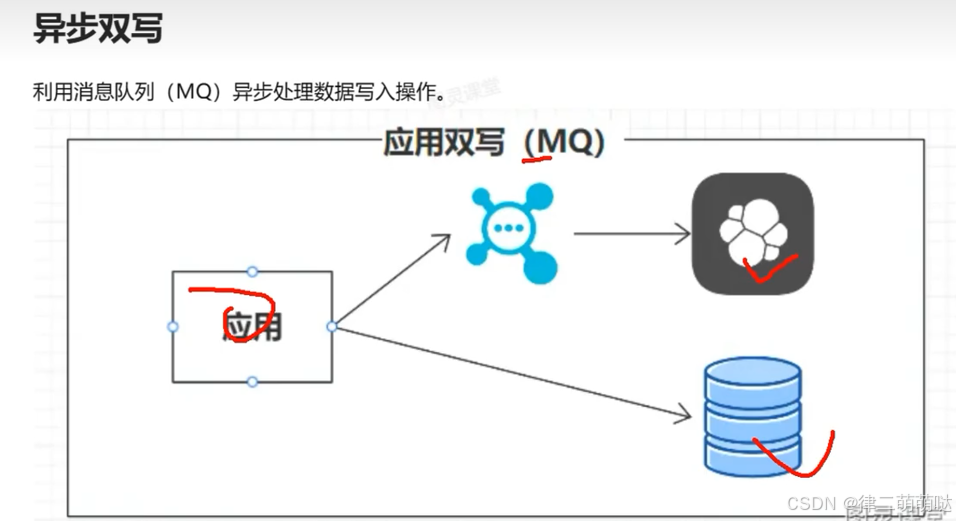


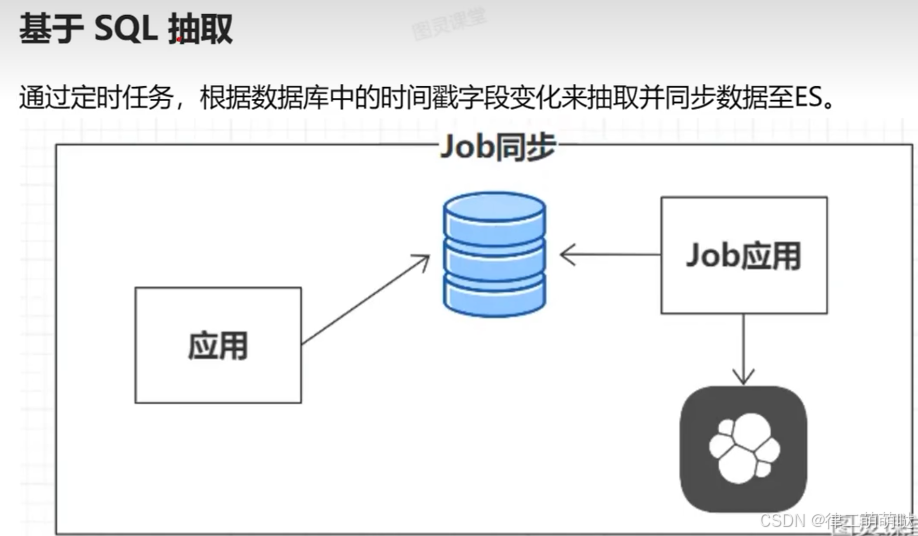


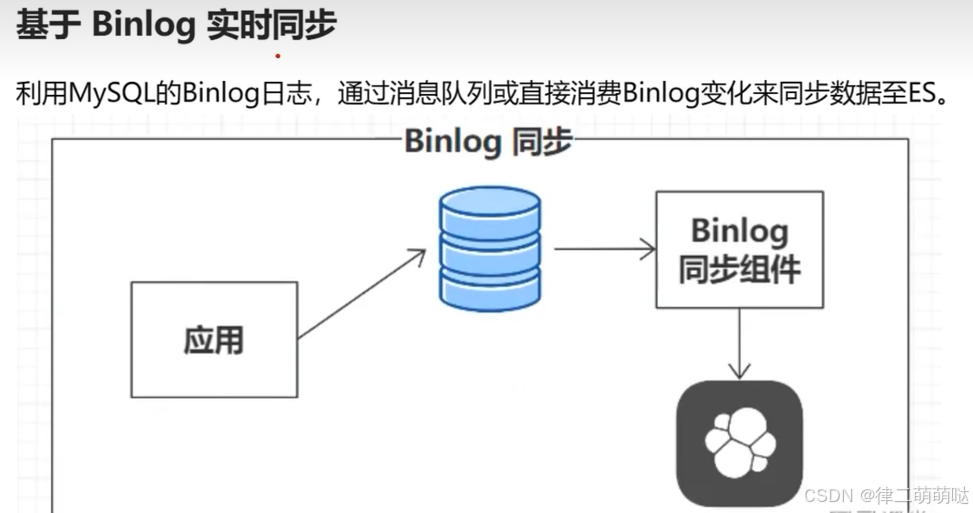



31. Redis事务
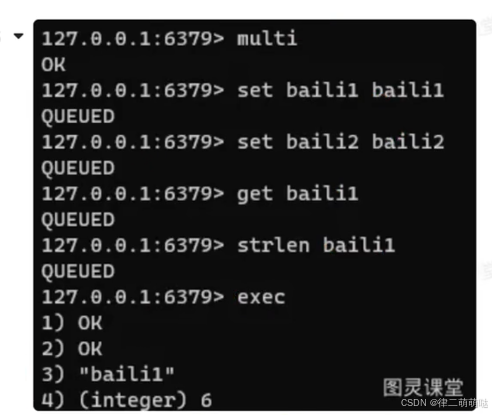
一、概述:
概念:可以一次执行多个命令,本质是一组命令的集合。一个事务中的所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞。
常用命令:
-
multi:开启一个事务,multi 执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即被执行,而是被放到一个队列中。 -
exec:执行队列中所有的命令。 -
discard:中断当前事务,然后清空事务队列并放弃执行事务。 -
watchkey1 key2 …:监视一个(或多个) key,如果在事务执行之前这个(或这些) key
被其他命令所改动,那么事务将被打断。
通过了解这些概念和命令,可以更好地掌握和使用相关命令集合,确保命令按顺序执行,并提供事务的原子性和可靠性。
二、使用
正常执行

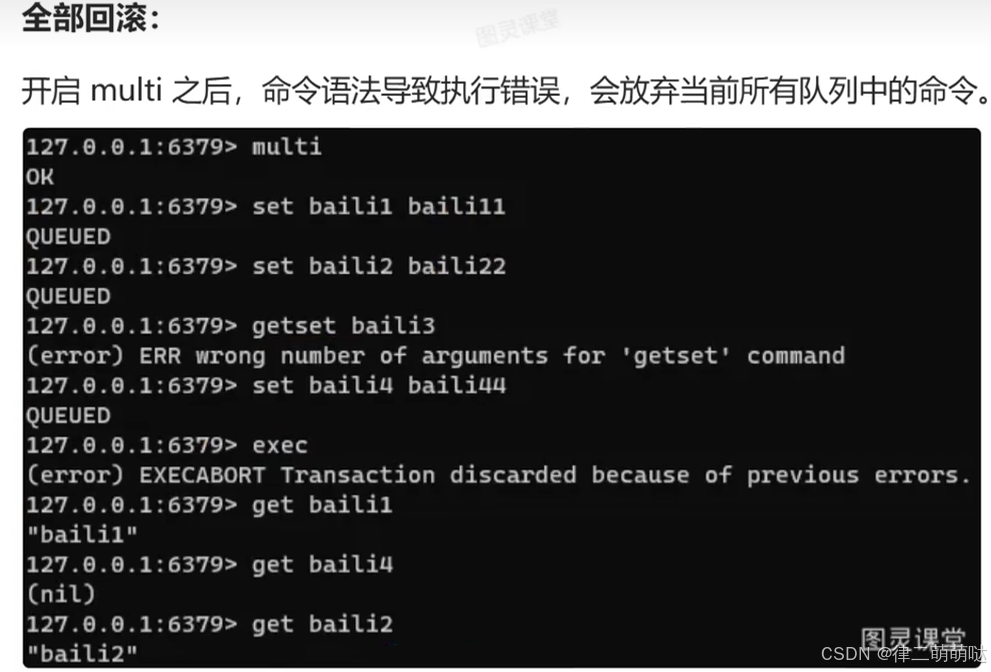
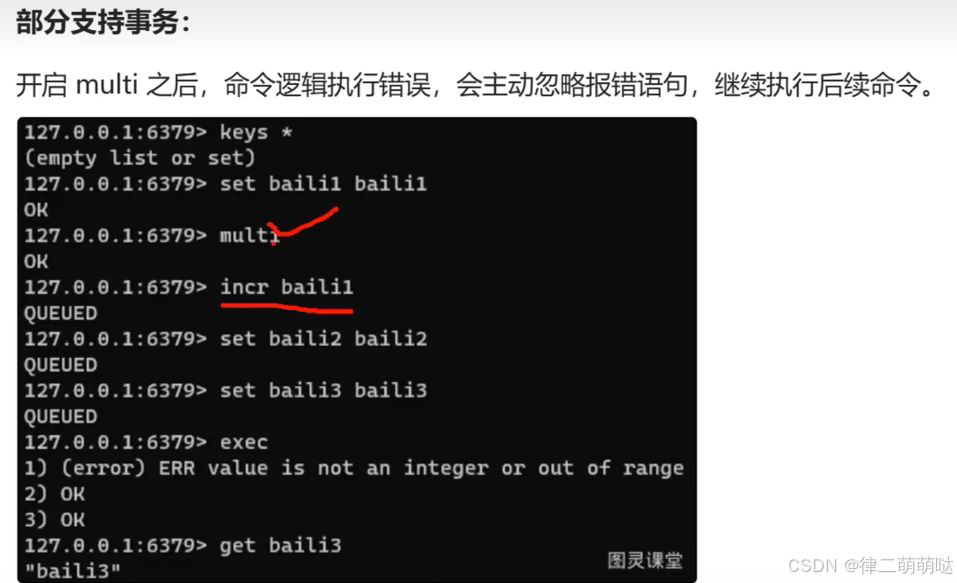
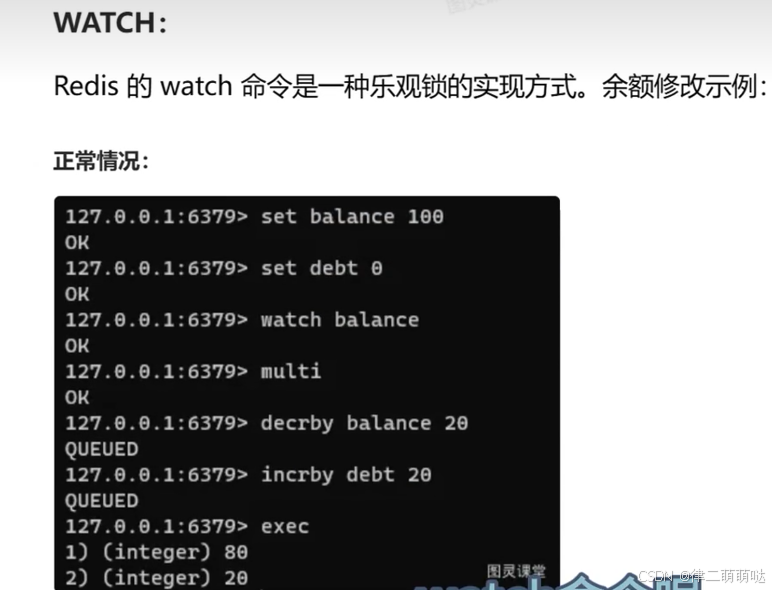
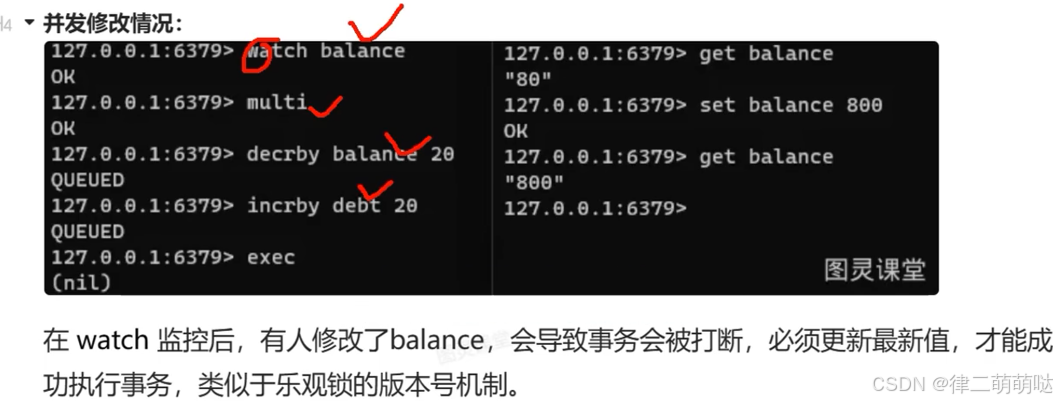
32. 正向代理与反向代理的区别
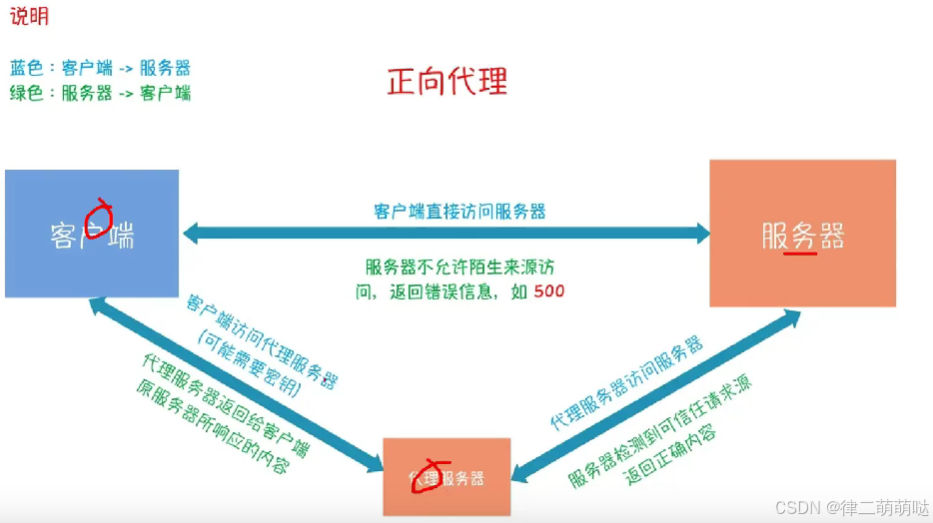
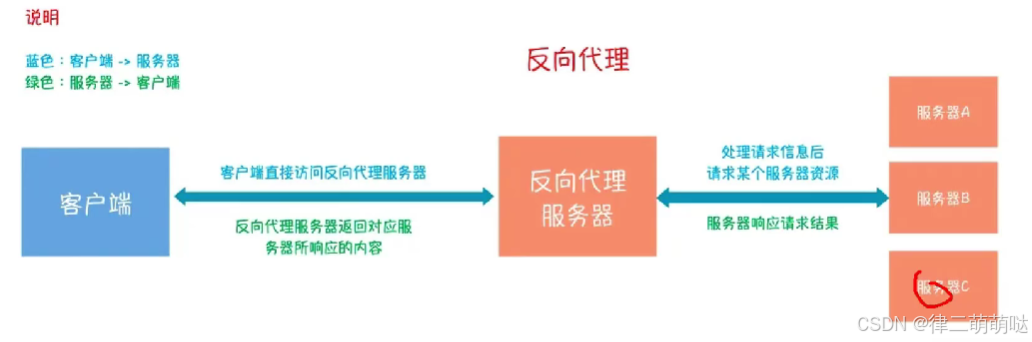
1. 代理对象不同
- 正向代理:代理的是
客户端,帮助客户端访问其无法直接访问的服务器资源。在正向代理中,服务器不知道真正的客户端是谁。 - 反向代理:代理的是
服务器,将外部网络连接请求转发给内部网络上的服务器在这里插入代码片。在反向代理中,客户端不知道真正的服务器是谁。
2. 架设位置不同
-
正向代理:通常由客户端架设,如在自己的机器上安装代理软件。
-
反向代理:通常由服务器架设,如在服务器集群中部署。
3. 用途和目的不同
-
正向代理:
主要用于解决访问限制问题,如访问国外网站。正向代理的典型用途是为在防火墙内的局域网客户端提供访问Internet的途径。 -
反向代理:
主要用于负载均衡、安全防护等。反向代理的典型用途是将防火墙后面的服务器提供给Internet用户访问。
33. 如何保证redis中的数据都是热点数据
惰性删除(Lazy Deletion)
惰性删除是指在Redis中,当一个键(key)的过期时间到达后,并不会立即从内存中删除它,而是等到该键被访问时(例如,执行GET命令)才检查其是否过期,并在此时进行删除操作。
特点:
- 优点:减少了不必要的删除操作,提高了Redis的性能和效率,特别是在访问频率较低的键时。
- 缺点:如果
过期键长时间未被访问,它们会一直存在于内存中,可能导致内存占用过高。但在Redis中,这通常不是问题,因为Redis有内存限制和淘汰策略来缓解内存压力。
定期删除
Redis会定期(例如,每秒10次)扫描一部分设置了过期时间的键。
检查这些键是否已过期,如果过期则删除它们。
这种方式是Redis管理过期数据的一种实际机制,它可以在一定程度上保证过期数据的及时删除,
同时避免了对每个键进行精确定时删除所带来的性能开销。
- 1
- 2
- 3
- 4
- 5
内存淘汰策略
当Redis的内存使用达到其配置的限制(maxmemory)时,Redis会根据配置的内存淘汰策略来释放内存空间。
- 1
主要策略:
-
noeviction:
不进行数据淘汰,当内存达到maxmemory时,拒绝所有写入操作并返回错误信息。适用于不希望丢失任何数据的场景。 -
volatile-random:在设置了
过期时间的键值对中,随机移除某个键值对。适用于对过期数据没有特殊要求的场景。 -
volatile-ttl:在设置了
过期时间的键值对中,移除即将过期的键值对(ttl最小的)。可以优先释放即将过期的数据。 -
volatile-lru:在设置了
过期时间的键值对中,移除最近最少使用的键值对。这是最常见的淘汰策略之一,适用于缓存场景。 -
volatile-lfu:在设置了
过期时间的键值对中,移除最近最不频繁使用的键值对。适用于需要频繁访问热数据的场景。 -
allkeys-random:在
所有键值对中,随机移除某个键值对。可能导致重要数据被误删除。 -
allkeys-lru:在
所有键值对中,移除最近最少使用的键值对。与volatile-lru类似,但适用于所有数据。 -
allkeys-lfu:在
所有键值对中,移除最近最不频繁使用的键值对。与volatile-lfu类似,但适用于所有数据。
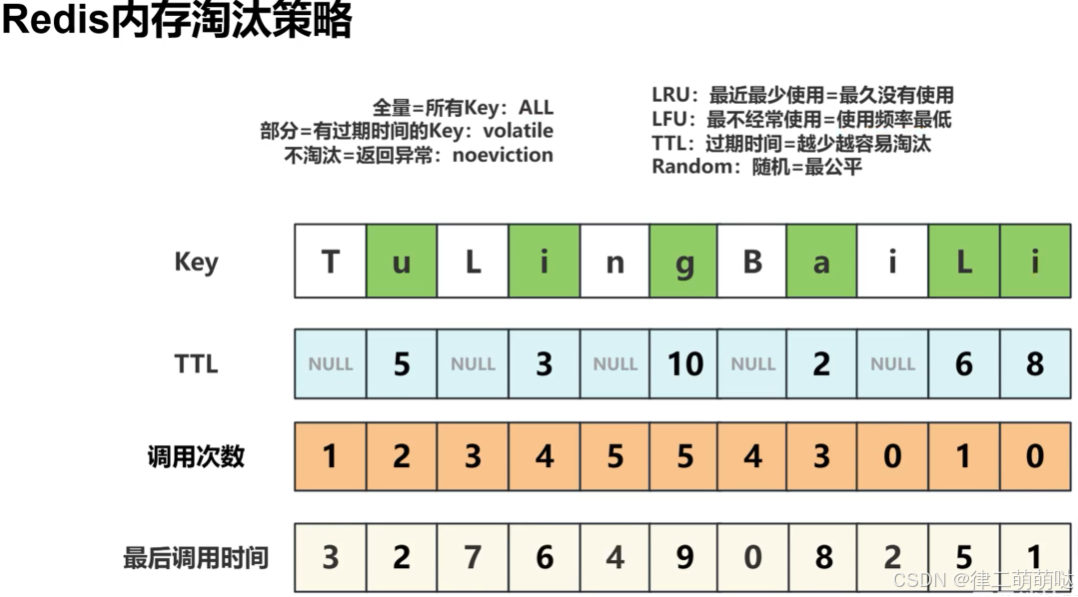
总结 如何保证redis中的数据都是热点数据呢,通过惰性删除+定期删除+内存淘汰策略保证的
- 1
34. 为什么有redis还需要本地缓存
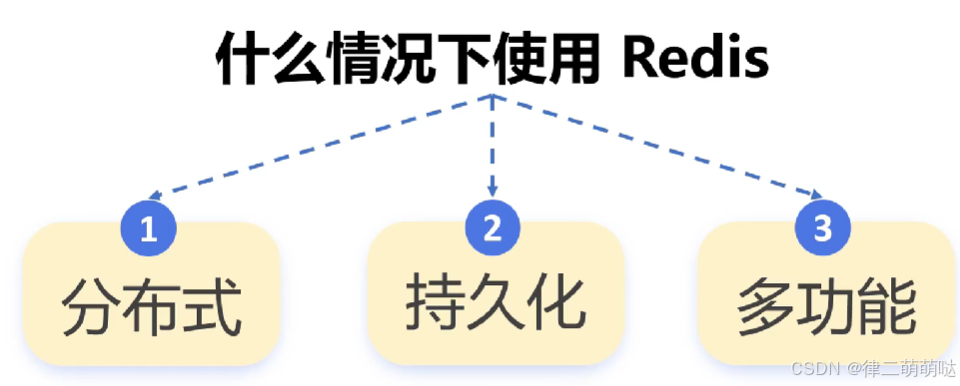
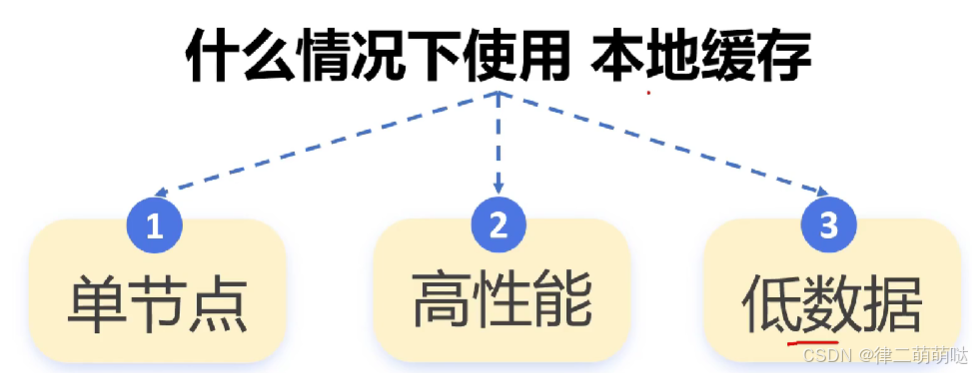
本地缓存是将数据存储在应用程序所在的本地内存中的缓存方式。既然,已经有了 Redis 可以实现分布式缓存了,为什么还需要本地缓存呢?接下来,我们一起来看。
为什么需要本地缓存?
尽管已经有 Redis 缓存了,但本地缓存也是非常有必要的,因为它有以下优点:
速度优势:本地缓存直接利用本地内存,访问速度非常快,能够显著降低数据访问延迟。减少网络开销:使用本地缓存可以减少与远程缓存(如 Redis)之间的数据交互,从而降低网络 I/O 开销。降低服务器压力:本地缓存能够分担服务器的数据访问压力,提高系统的整体稳定性。
因此,在生产环境中,我们通常使用本地缓存+Redis 缓存一起组合成多级缓存,来共同保证程序的运行效率。
34. 我有一个朋友,不小心删库了,该怎么办

这里主要演示binlog怎么恢复
CREATE TABLE `user1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`age` tinyint(4) NOT NULL,
`address` varchar(50) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`, `age`)
) ENGINE=InnoDB DEFAULT CHARSET=UTF8MB4;
INSERT INTO `user1` (`name`, `age`, `address`) VALUES
('Alice', 40, 'address1'),
('Amy', 23, 'address2'),
('Tom', 18, 'address3'),
('Mike', 22, 'address4');
delete table user1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
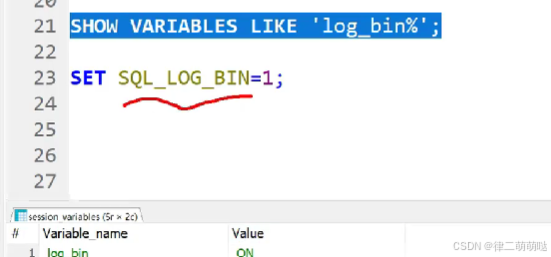
- 查询binlog开启状态
首先要保证binlog是开启的,不然数据肯定是没办法恢复回来的
SHOW VARIABLES LIKE 'log_bin';
- 1
- 2
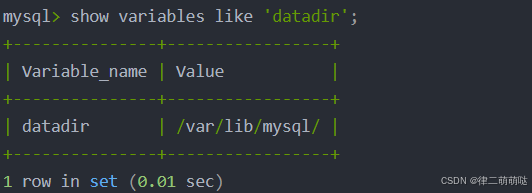
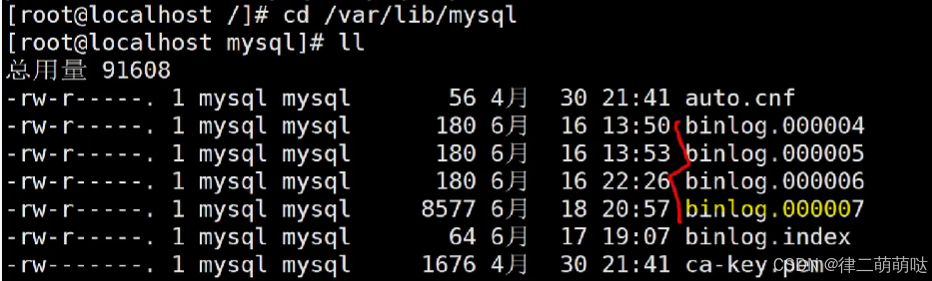
- 查看mysql工作目录
show variables like 'datadir';
- 1
- 确定binlog文件并下载到本地

- 打开文件找到恢复数据的截至id
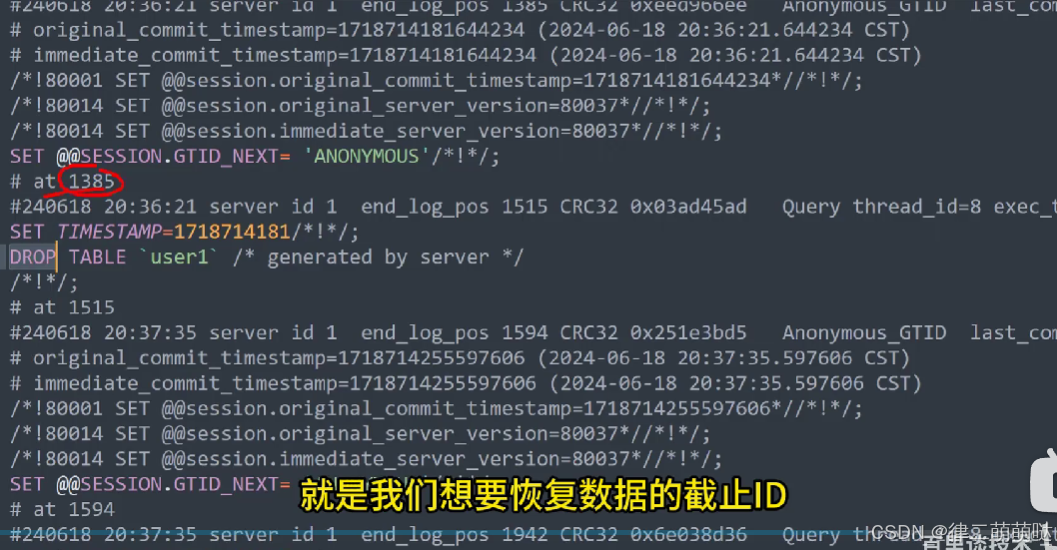
- 恢复binlog.00007之前的数据

- 恢复binlog.00007文件数据的截至id1385 之前的数据
[root@localhost mysql]# mysqlbinlog --start-position=1 --stop-position=1385 ./binlog.000007 | mysql -uroot -plqaz@WSX
- 1

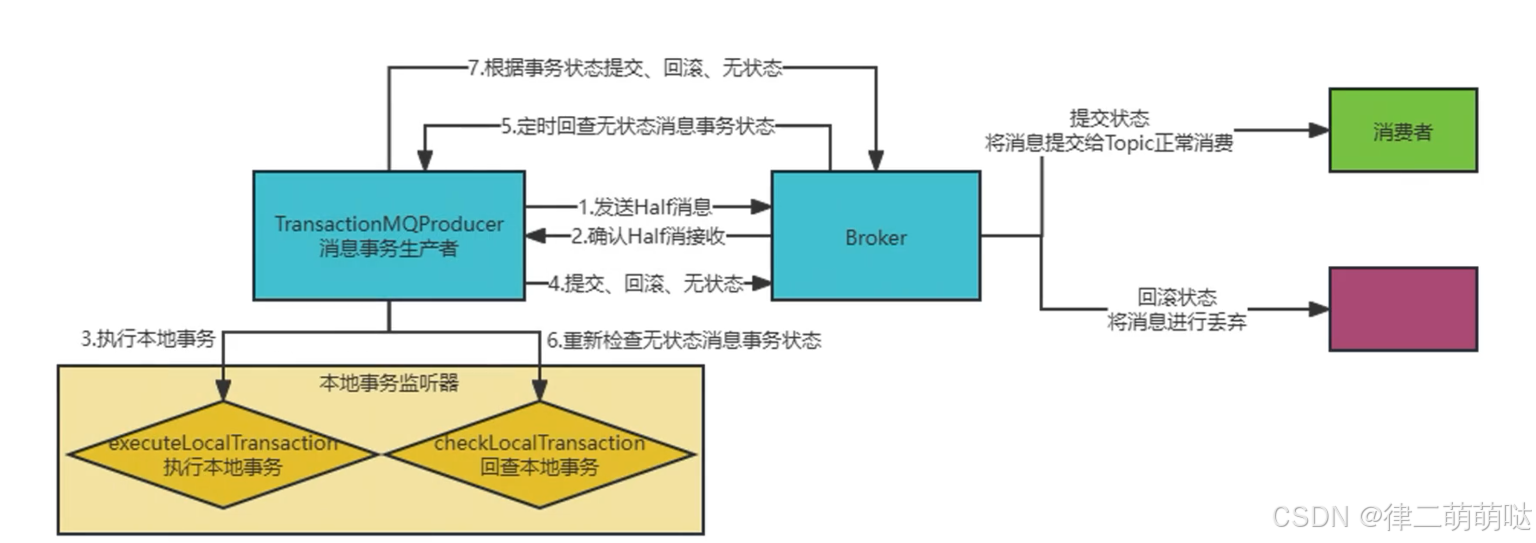
35. RocketMQ事务消息原理
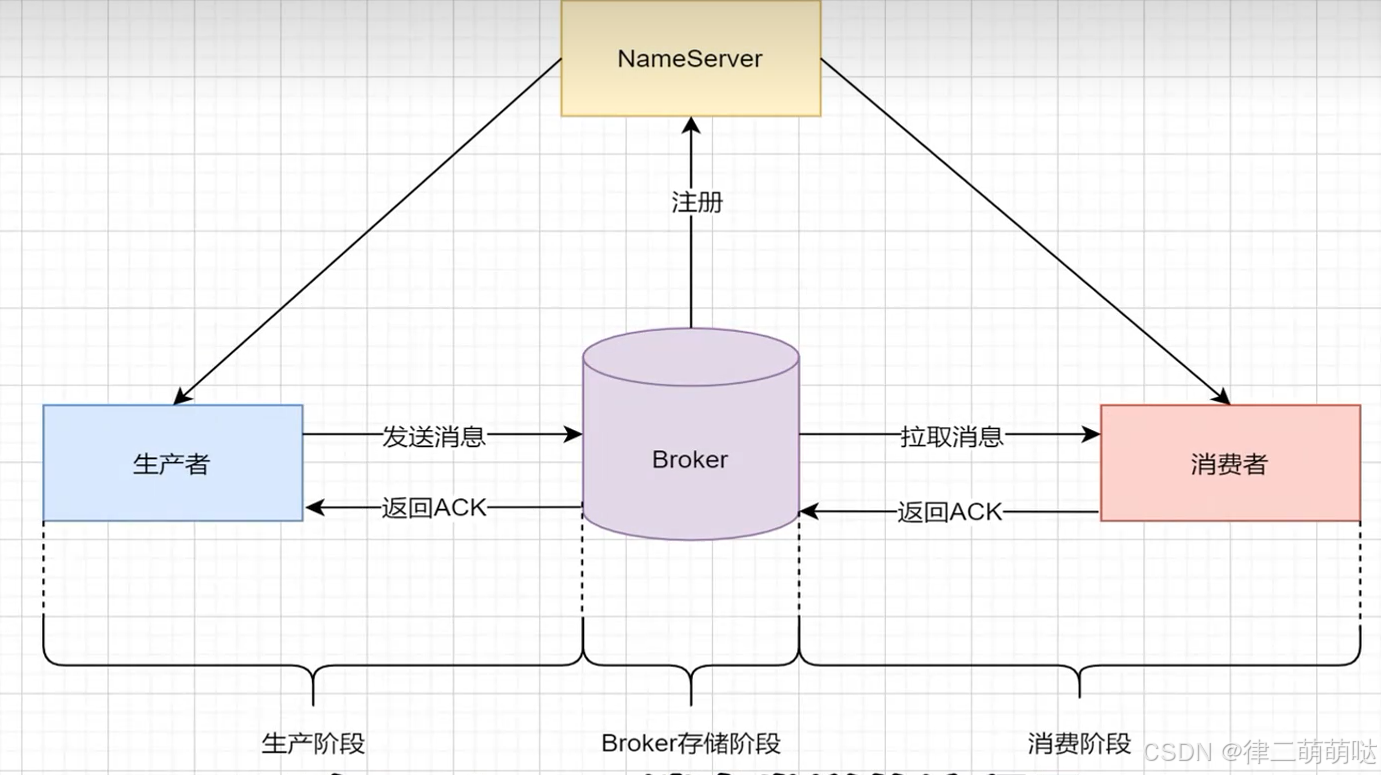
36. RocketMQ如何保证消息不丢失
消息发送过程
RocketMQ 的消息想要确保不丢失,需要生产者、消费者以及 Broker 的共同努力,缺一不可。
生产者(Producer)
1. 发送方式:选择同步发送
-
同步发送:发送消息后,需要阻塞等待 Broker 确认收到消息,生产者才能拿到返回的 SendResult
-
异步发送:Producer 首先构建一个向 broker 发送消息的任务,把该任务提交给线程池,等执行完该任务时,回调用户自定义的回调函数,执行处理结果。
2. 重试机制
- 生产者因为网络故障、服务异常等原因导致调用, RocketMQ 内置请求重试逻辑,默认
重试 3 次。重试 3 次意思是一共会发 4 次消息,1 次原始消息,3 次重试消息。
消息存储过程
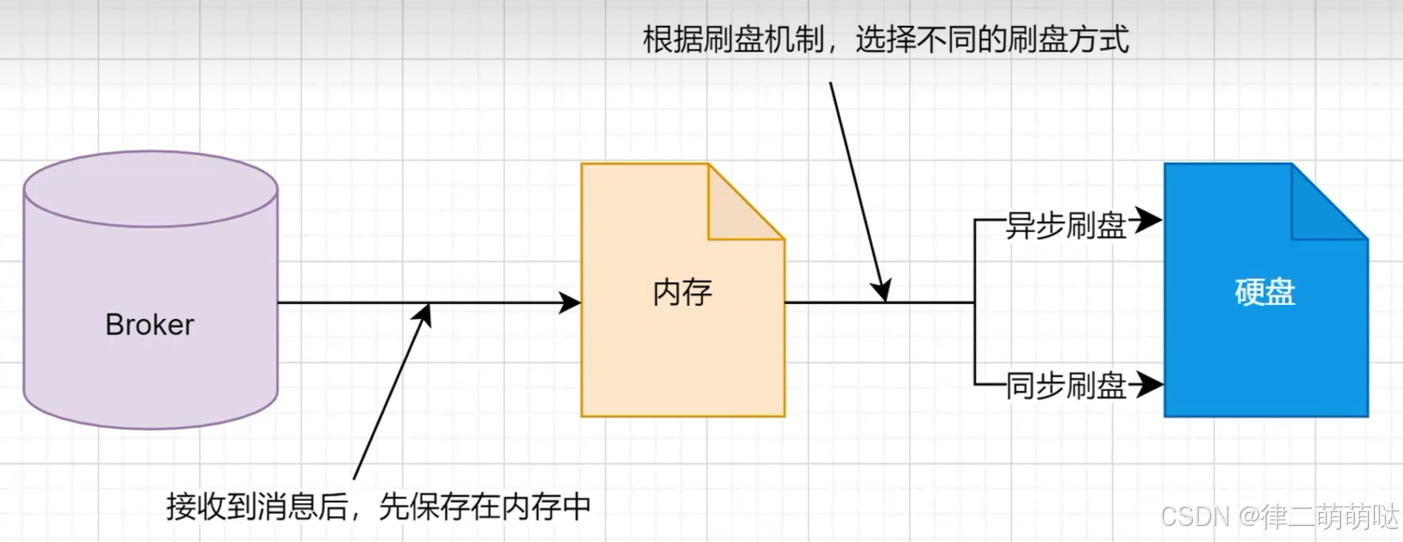

37. 如何快速判断海量数据中是否存在某个元素
判断一个值是否存在?通常有以下两种解决方案:
- 使用哈希表:可以将数据进行
哈希操作,将数据存储在相应的桶中。查询时,根据哈希值定位到对应的桶,然后在桶内进行查找。这种方法的时间复杂度为O(1),但需要额外的存储空间来存储哈希表。如果桶中存在数据,则说明此值已存在,否则说明未存在。 - 使用布隆过滤器:
布隆过滤器是一种概率型数据结构,用于判断一个元素是否在集合中。它利用多个哈希函数映射数据到一个位数组,并将对应位置置为1。查询时,只需要对待查询的数据进行哈希,并判断对应的位是否都为 1。如果都为 1,则该数据可能存在;如果有一个位不为1,则该数据一定不存在。布隆过滤器的查询时间复杂度为 O(k),其中 k 为哈希函数的个数。
相同点和不同点
它们两的相同点是:它们都存在误判的情况。例如,使用哈希表时,不同元素的哈希值可能相同,所以这样就产生误判了;而布隆过滤器的特征是,当布隆过滤器说,某个数据存在时,这个数据可能不存在;当布隆过滤器说,某个数据不存在时,那么这个数据一定不存在。
结论
哈希表和布隆过滤器都能实现判重,但它们都会存在误判的情况,但布隆过滤器存储占用的空间更小,
更适合海量数据的判重。
- 1
- 2
布隆过滤器实现原理
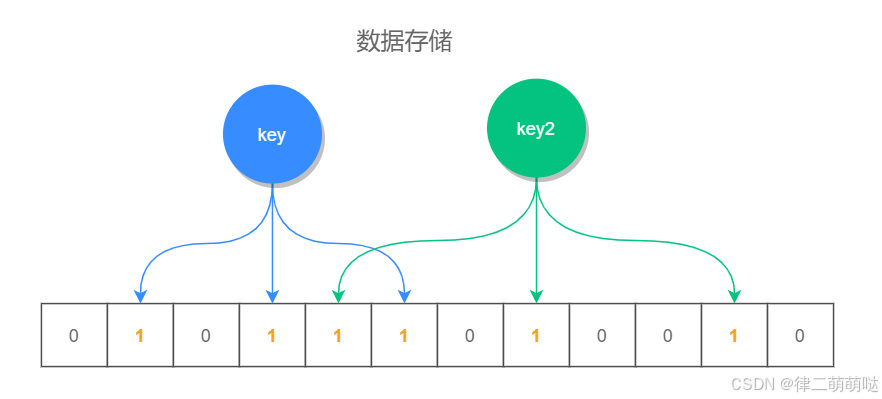
布隆过滤器的实现,主要依靠的是它数据结构中的一个位数组,每次存储键值的时候,不是直接把数据存储在数据结构中,因为这样太占空间了,它是利用几个不同的无偏哈希函数,把此元素的 hash 值均匀的存储在位数组中,也就是说,每次添加时会通过几个无偏哈希函数算出它的位置,把这些位置设置成 1 就完成了添加操作。
当进行元素判断时,查询此元素的几个哈希位置上的值是否为 1,`如果全部为 1,则表示此值存在,如果有一个值为 0,则表示不存在。因为此位置是通过 hash 计算得来的,所以即使这个位置是 1,并不能确定是那个元素把它标识为 1 的,因此布隆过滤器查询此值存在时,此值不一定存在,但查询此值不存在时,此值一定不存在。
并且当位数组存储值比较稀疏的时候,查询的准确率越高,而当位数组存储的值越来越多时,误差也会增大。
位数组和 key 之间的关系,如下图所示:
如何实现布隆过滤器?
布隆过滤器的实现通常有以下两种方案:
- 通过程序实现(内存级别方案):使用 Google Guava 库和 Apache Commons 库实现布隆过滤器。
- 通过中间件实现(支持数据持久化):使用 Redis 4.0 之后提供的布隆过滤插件来实现,它的好处是支持持久化,数据不会丢失。
Guava 实现布隆过滤器
使用 Google Guava 库实现布隆过滤器总共分为以下两步:
① 引入 Guava 依赖
<dependency>
<groupId>com.google.guavagroupId>
<artifactId>guavaartifactId>
dependency>
- 1
- 2
- 3
- 4
使用 Guava API 操作布隆过滤器
具体实现如下。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample {
public static void main(String[] args) {
// 创建一个布隆过滤器,设置期望插入的数据量为10000,期望的误判率为0.01
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.unencodedCharsFunnel(), 10000, 0.01);
// 向布隆过滤器中插入数据
bloomFilter.put("data1");
bloomFilter.put("data2");
bloomFilter.put("data3");
// 查询元素是否存在于布隆过滤器中
System.out.println(bloomFilter.mightContain("data1")); // true
System.out.println(bloomFilter.mightContain("data4")); // false
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在上述示例中,我们通过 BloomFilter.create() 方法创建一个布隆过滤器,指定了元素序列化方式、期望插入的数据量和期望的误判率。然后,我们可以使用 put() 方法向布隆过滤器中插入数据,使用 mightContain() 方法来判断元素是否存在于布隆过滤器中。
小结
在海量数据如何确定一个值是否存在?通常有两种解决方案:哈希表和布隆过滤器,而它们两都存在误判的情况,但布隆过滤器更适合海量数据的判断,因为它占用的数据空间更小。布隆过滤器的特征是:当布隆过滤器说,某个数据存在时,这个数据可能不存在;当布隆过滤器说,某个数据不存在时,那么这个数据一定不存在。
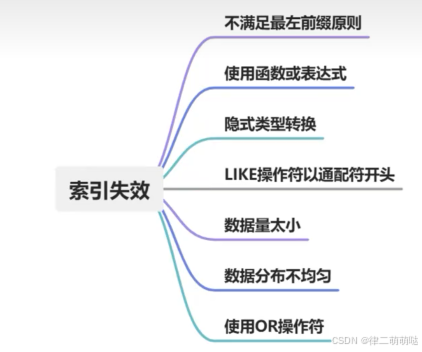
38. mysql什么情况下会导致索引失效
39. List如何去重
方法一:使用HashSet去重
HashSet是一个不包含重复元素的集合,因此可以利用它将List中的重复元素去除。
import java.util.*;
public class ListDeduplication {
public static void main(String[] args) {
List<String> listWithDuplicates = Arrays.asList("a", "b", "c", "a", "d");
// 使用HashSet去重
Set<String> set = new HashSet<>(listWithDuplicates);
List<String> listWithoutDuplicates = new ArrayList<>(set);
System.out.println(listWithoutDuplicates);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
方法二:使用LinkedHashSet去重并保持顺序
如果你希望去重后的List保持原始元素的顺序,可以使用LinkedHashSet。
import java.util.*;
public class ListDeduplication {
public static void main(String[] args) {
List<String> listWithDuplicates = Arrays.asList("a", "b", "c", "a", "d");
// 使用LinkedHashSet去重并保持顺序
Set<String> set = new LinkedHashSet<>(listWithDuplicates);
List<String> listWithoutDuplicates = new ArrayList<>(set);
System.out.println(listWithoutDuplicates);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
方法三:使用Java 8的Stream API去重
Java 8引入了Stream API,可以方便地对集合进行各种操作,包括去重。
import java.util.*;
import java.util.stream.Collectors;
public class ListDeduplication {
public static void main(String[] args) {
List<String> listWithDuplicates = Arrays.asList("a", "b", "c", "a", "d");
// 使用Stream API去重
List<String> listWithoutDuplicates = listWithDuplicates.stream()
.distinct()
.collect(Collectors.toList());
System.out.println(listWithoutDuplicates);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
40. Mysql orderBy排序原理
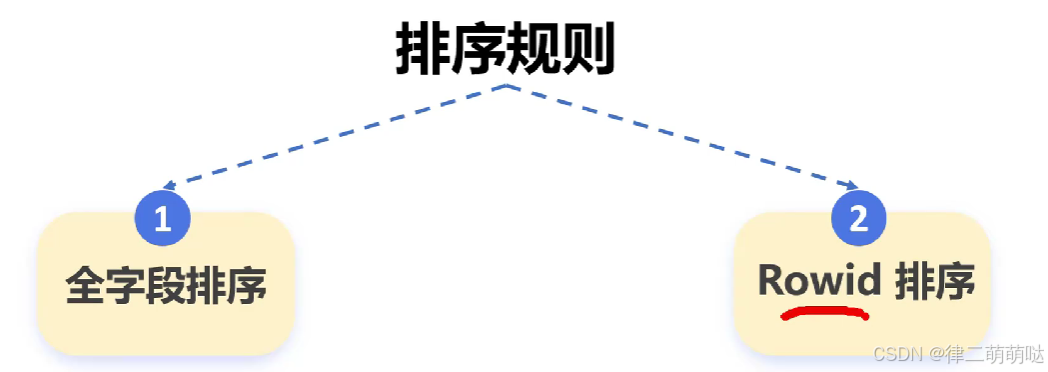
MySQL的排序规则主要涉及两个方面:
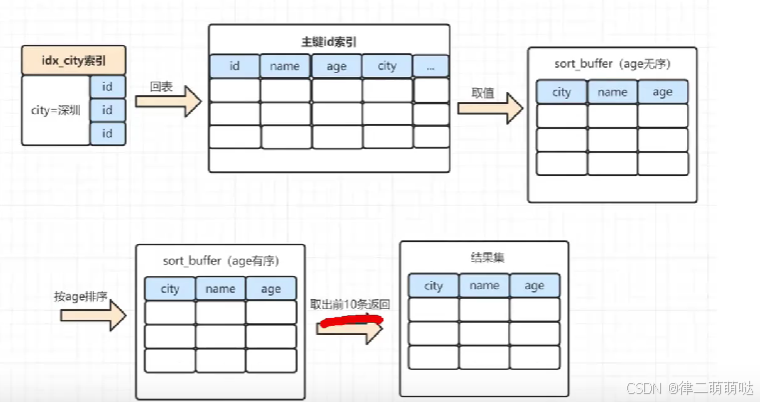
全字段排序:
在这种排序方式中,MySQL会对查询结果集中的所有指定字段进行完整的排序操作。
全字段排序确保了排序结果的精确性,因为它基于所有相关字段的值进行比较和排序。
这种排序方式适用于需要严格控制排序顺序的场景,但可能在处理大量数据时效率较低。
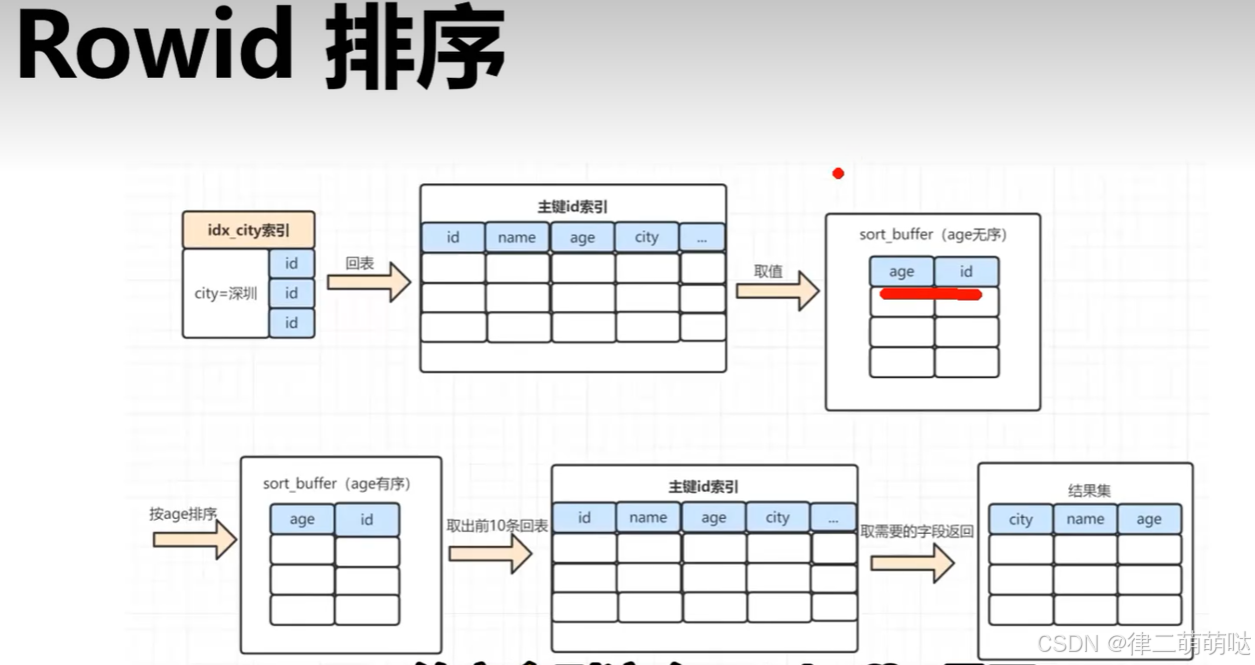
Rowid排序:
Rowid排序是MySQL利用表中的行ID(即Rowid)来进行排序的一种方式。
由于只基于行ID进行排序,这种方式通常比全字段排序更高效,特别是在处理大型数据集时。
然而,Rowid排序不保证跨页或跨表的顺序一致性,因此在某些需要严格排序一致性的场景下可能不适用。

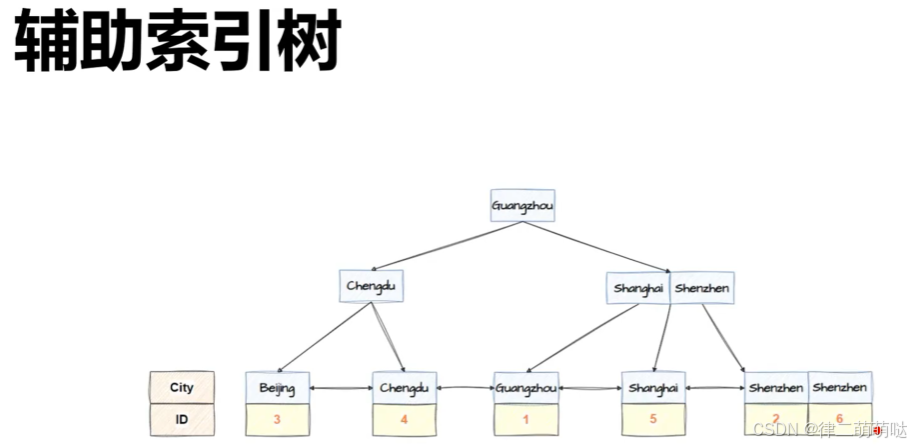
- 辅助索引树 非叶子节点是索引字段组成的,叶子节点是索引字段+对应的主键ID组成的
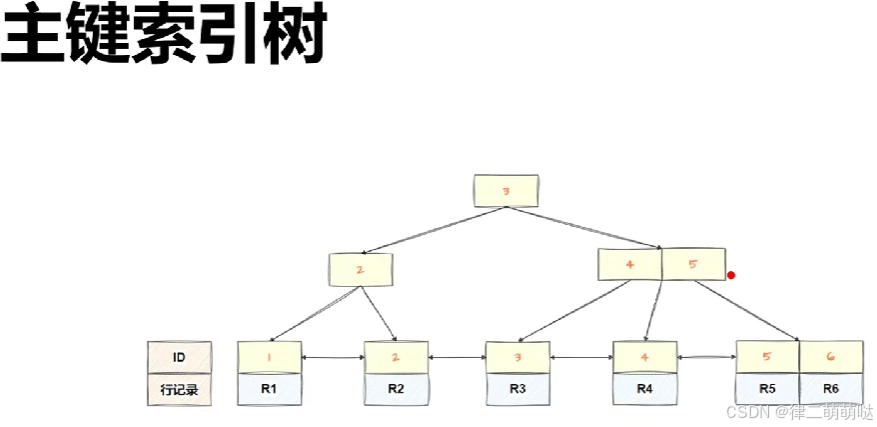
- 主键索引树 非叶子节点是主键ID组成的,叶子节点是主键ID+整行数据组成的
全字段排序流程
RowId排序流程
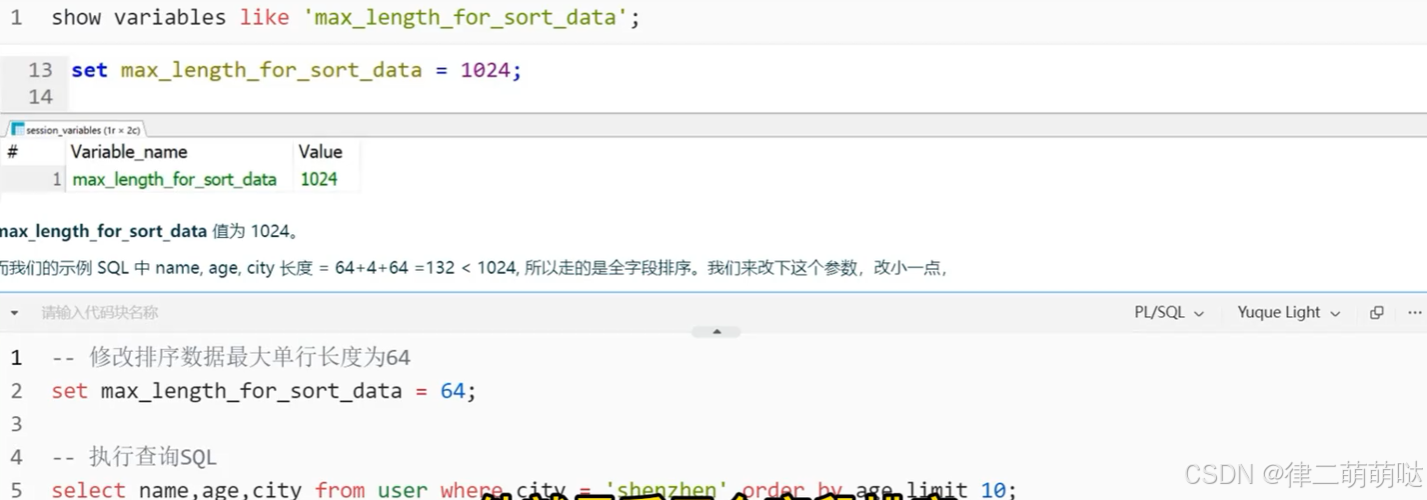
怎么区分,通过字段max_length_for_sort_data字段长度判断

40. List常见集合计算
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
* List集合计算 交集,并集,差集,去重并集,我只需要一行代码
*/
public class ListOperationTest {
public static void main(String[] args) {
List<String> list1 = new ArrayList<>();
list1.add("1");
list1.add("2");
list1.add("3");
list1.add("4");
list1.add("5");
list1.add("6");
List<String> list2 = new ArrayList<>();
list2.add("1");
list2.add("3");
list2.add("5");
list2.add("9");
//交集
List<String> intersection = list1.stream().filter(item -> list2.contains(item)).collect(Collectors.toList());
System.out.println("-----交集-----");
System.out.println(intersection);
//差集 list1-list2
List<String> reduce = list1.stream().filter(l -> !list2.contains(l)).collect(Collectors.toList());
System.out.println("------差集------");
System.out.println(reduce);
//差集 list2-list1
List<String> reduce2 = list2.stream().filter(l -> !list1.contains(l)).collect(Collectors.toList());
System.out.println("------差集------");
System.out.println(reduce2);
//并集
list1.addAll(list2);
List<String> listAllDistinct = list1.stream().distinct().collect(Collectors.toList());
System.out.println("------并集去除重复------");
System.out.println(listAllDistinct);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
41. java反射原理

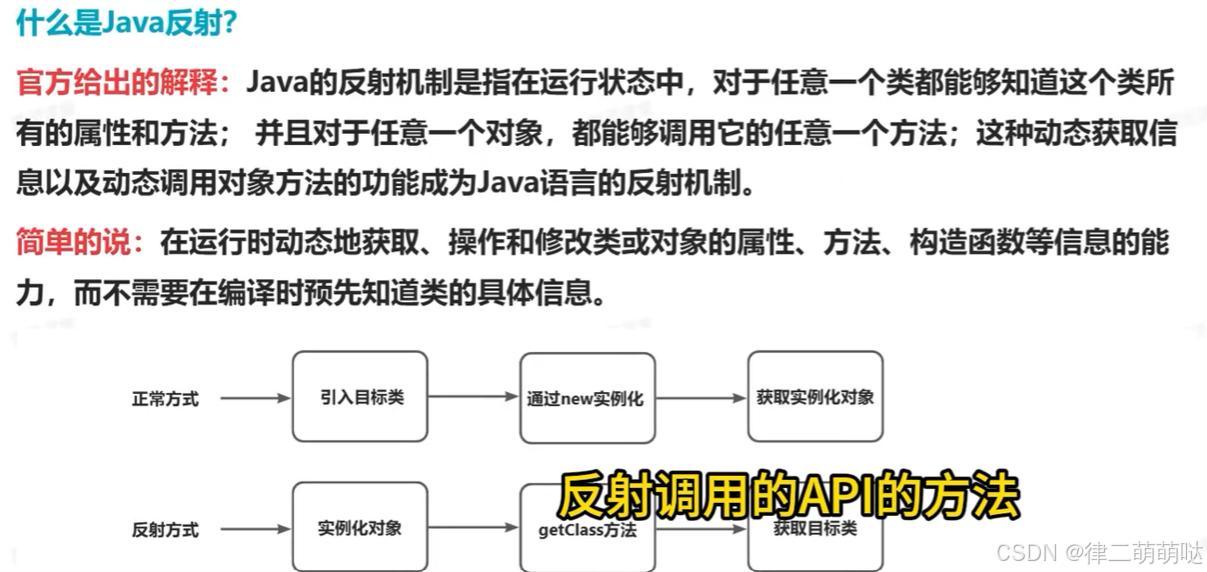
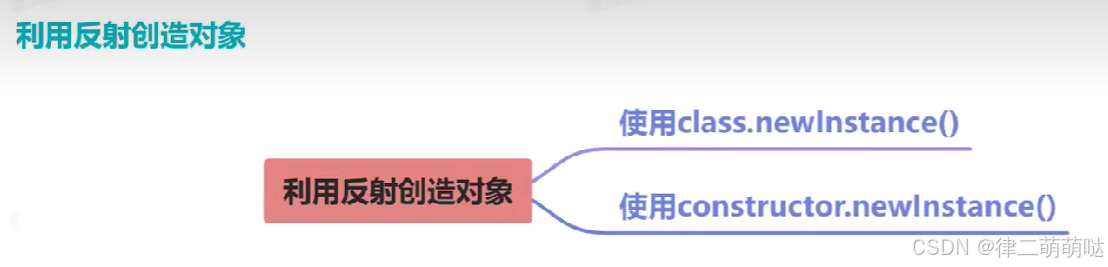
// 方式一
Class class1 = Class.forName("polo.User");
User user = (User) class1.newInstance();
System.out.println(user);
// 方式二
Constructor constructor = class1.getConstructor();
User user1 = (User) constructor.newInstance();
System.out.println(user1);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

// 打印指定类 "polo.User" 的所有 public 类型的方法
Class class1 = Class.forName("polo.User");
Method[] methods = class1.getMethods();
System.out.println(Arrays.toString(methods));
- 1
- 2
- 3
- 4

1 Class class1 = Class.forName("polo.User");
2 Field email = class1.getDeclaredField("email");
3 System.out.println(email);
4 Field username = class1.getDeclaredField("username");
5 System.out.println(username);
- 1
- 2
- 3
- 4
- 5
- 6
42. 5分钟了解Java自定义注解
在Java中,自定义注解是一种用于为代码添加元数据(即数据的数据,或者关于数据的描述性信息)的机制。通过自定义注解,你可以在代码中嵌入额外的信息,这些信息可以在运行时或编译时被读取和处理。自定义注解通常用于框架开发、代码生成、编译时检查等场景。
下面是一个简单的步骤来创建和使用自定义注解:
1. 定义注解
首先,你需要使用@interface关键字来定义一个新的注解。注解的定义通常包括两个主要部分:元注解和注解元素。
元注解(meta-annotation)是注解其他注解的注解,它们定义了你的注解应该如何被处理。常见的元注解包括@Retention、@Target、@Documented、@Inherited等。
@Retention:指定注解的保留策略(RetentionPolicy),即注解在何时有效。常见的值有SOURCE(只在源代码中保留,编译时会被丢弃)、CLASS(在编译后的class文件中保留,但在运行时不会被VM保留)、RUNTIME(在运行时可以通过反射机制读取注解)。@Target:指定注解可以应用的Java元素类型,如类、方法、字段、参数等。它是一个ElementType类型的数组。
注解元素则是注解中定义的属性,它们可以具有默认值。
下面是一个简单的自定义注解示例:
package cn.itcast.springboot.annotation;
import java.lang.annotation.*;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME) //生命周期
@Documented
public @interface RepeatSubmit {
int lockTime() default 5;
String methodName() default "";
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2. 使用注解
定义了注解之后,你就可以在代码中应用它了。
import cn.itcast.springboot.annotation.RepeatSubmit;
import cn.itcast.springboot.handler.RepeatSummitHandler;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TestController {
@RepeatSubmit(lockTime = 10,methodName = "test")
@GetMapping("/test")
public void testRepeatSubmit() {
new RepeatSummitHandler().handler();
System.out.println("请求成功");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3. 读取注解
最后,你需要通过反射机制来读取和处理注解。
import cn.itcast.springboot.annotation.RepeatSubmit;
import cn.itcast.springboot.controller.TestController;
import java.lang.reflect.Method;
public class RepeatSummitHandler {
public void handler(){
Class<TestController> testControllerClass = TestController.class;
Method[] methods = testControllerClass.getDeclaredMethods();
for (Method method : methods) {
if(method.isAnnotationPresent(RepeatSubmit.class)){
RepeatSubmit annotation = method.getAnnotation(RepeatSubmit.class);
System.out.println(annotation.lockTime());
System.out.println(annotation.methodName());
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
43. 不用写一行代码统计方法耗时
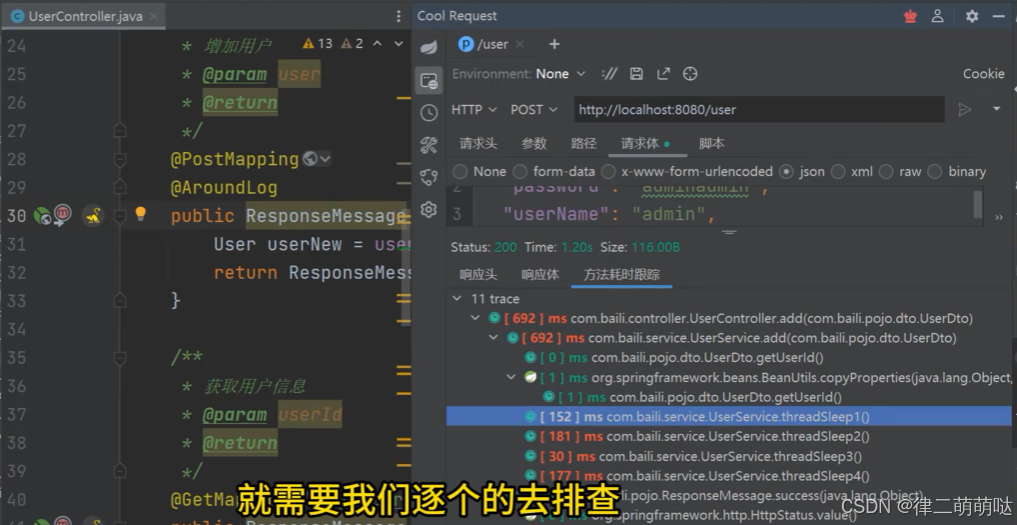
使用Cool Request插件 可以统计方法耗时
什么是Cool Request
Cool Request是一个IDEA中的接口调试插件,除了可以发起基本的HTTP请求之外,还提供了强大的反射调用能力,可以绕过拦截器,这点广受网友的好评,当然伴随着还有Spring中对@Scheduled注解的调用,以及xxl-job的支持,这是不是很酷(Cool)?
什么是Trace
Trace可以统计除了java包的任意包,为什么不能统计java的?因为可能会出现不稳定的情况,再说,java包怎么可能有问题,有问题的也是你的代码(手动狗头)。
Trace如果在启用状态下,将在你发起请求的时候,自动从Controller方法下开始跟踪,如果深度为1,那么则只跟踪Controller方法,如果深度为2,则跟踪Controller下所有方法,深度为3,那就跟踪Controller下所有方法下的所有方法,以此类推,但是会出现你设置了一个很大的值,却跟踪不到这个深度,因为有些是通过接口(interface)调用的,静态代码分析无法分析到是哪个实现类,所以没办法继续向下跟踪,可以右击任意方法,手动添加方法跟踪。
模拟请求得到哪些方法耗时比较长
44. 为何有http还需要websocket
HTTP协议存在局限性,而WebSocket协议能够弥补这些局限,提供更为高效和实时的通信方式。
HTTP协议是基于TCP协议的,但它设计为短连接、无状态以及请求/响应模式的通信协议。这意味着在同一时间里,客户端和服务器只能有一方主动发数据,是半双工通信。每次客户端发起请求后,服务器处理请求并返回响应,之后连接便会关闭,每次交互都必须重新建立连接。这种模式在传统的网页浏览中足够高效,但对于需要频繁、实时地进行数据交换的应用而言,如网页游戏、在线教育、视频弹幕、体育实况更新、视频会议和聊天等,会产生大量的性能开销。

此外,HTTP协议通信过程中,只有客户端可以主动发起请求,服务器无法主动向客户端发送消息。如果客户端需要获取最新数据,它必须定期地发送请求去轮询服务器,这样既增加了服务器的负担,也导致数据更新存在延迟。
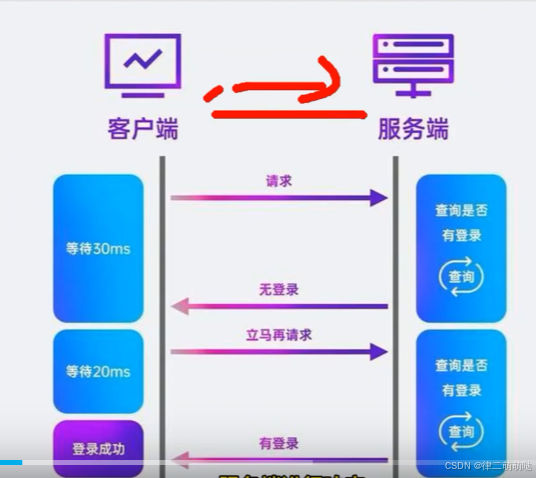
而WebSocket协议则提供了一个持续的连接通道,允许数据在客户端和服务器之间双向流动,并且连接一旦建立后就会保持打开状态,直到有一方主动关闭连接。这使得WebSocket协议非常适合用于实时应用程序,因为它不需要不断地建立和关闭连接,也无需客户端定期轮询服务器,从而减少了通信延迟和服务器负担。

WebSocket协议的优势还包括:
- 高效性:WebSocket连接中的头信息比HTTP协议的小得多,因此可以减少不必要的数据传输,提高传输效率。
- 低延迟:由于建立了长连接,避免了HTTP的频繁连接和断开,从而减少了通信的延迟。
- 更好的扩展性:WebSocket可以轻松地与现有的Web应用程序集成,同时支持自定义的协议扩展。
因此,尽管WebSocket协议并不完全替代HTTP协议,但在实际应用中,它通常与HTTP协议结合使用,以满足现代Web应用中日益增长的实时交互需求。
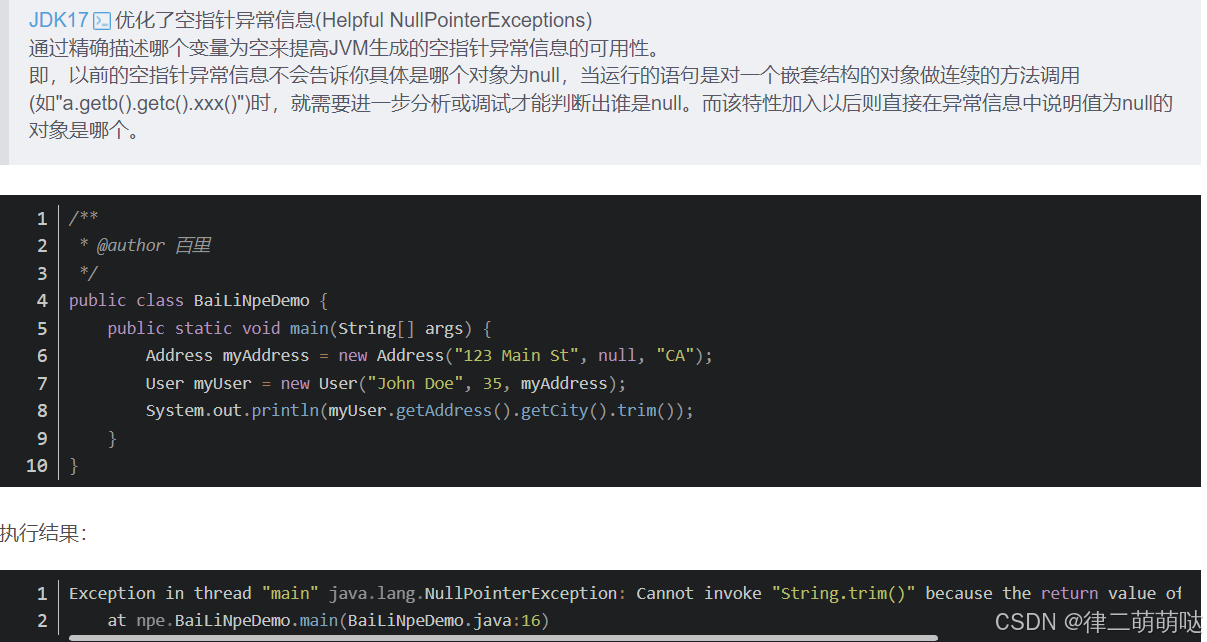
45. 如何优雅的避免空指针异常
空指针异常是导致java程序运行中断最常见的原因,相信每个程序猿都碰见过,
也就是NullPointException,我们通常简称为NPE,本文告诉大家如何优雅避免NPE。
- 1
- 2
1.数据准备
User
package cn.itcast.springboot.pojo;
public class User {
private String name;
private int age;
private Address address;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
public User(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
", address=" + address +
'}';
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
Address
package cn.itcast.springboot.pojo;
public class Address {
private String street;
private String city;
private String country;
public String getStreet() {
return street;
}
public void setStreet(String street) {
this.street = street;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getCountry() {
return country;
}
public void setCountry(String country) {
this.country = country;
}
@Override
public String toString() {
return "Address{" +
"street='" + street + '\'' +
", city='" + city + '\'' +
", country='" + country + '\'' +
'}';
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
常见解决方式如下
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.Assert;
import java.util.Optional;
/**
* 获取人员所在的城市
* @author 百里
*/
@SpringBootTest
public class NullTest {
public static void main(String[] args) {
Address address = new Address();
User user = new User("john",22,address);
String city = user.getAddress().getCity().trim();//容易出现空指针异常
System.out.println(city);
}
/**
* 1.使用if-else判断;避免了出现空指针的问题,但是代码结构层次嵌套多,不美观
*/
@Test
public void testNull(){
Address myAddress = new Address();
User myUser = new User("John Doe", 35, myAddress);
if (myUser != null) {
Address address = myUser.getAddress();
if (address != null) {
String city = address.getCity();
if (city != null && !"".equals(city)) {
System.out.println("使用if判断字符串:" + "一键三连");
}
}
}
}
/**
* 2.使用Optional解决了层次多的问题也避免了空指针的问题,当我们配合使用orElse时,
* 会先执行orElse方法,然后执行逻辑代码,不管是否出现了空指针。
*/
@Test
public void testNull2(){
Address myAddress = new Address();
User myUser = new User("John Doe", 35, myAddress);
String city = Optional.ofNullable(myUser)
.map(User::getAddress)
.map(Address::getCity).orElse("北京");
System.out.println(city);
}
/**
* 3.使用断言处理接口入参,检查假设和前置条件是否满足,以及检查空值情况,提前捕获空指针异常并进行处理
*/
@Test
public void testNull3(){
Address myAddress = new Address();
User myUser = new User("John Doe", 35, myAddress);
Assert.notNull(myUser,"user is null");
Address address = myUser.getAddress();
Assert.notNull(address,"address is null");
String city = address.getCity();
Assert.notNull(city,"city is null");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
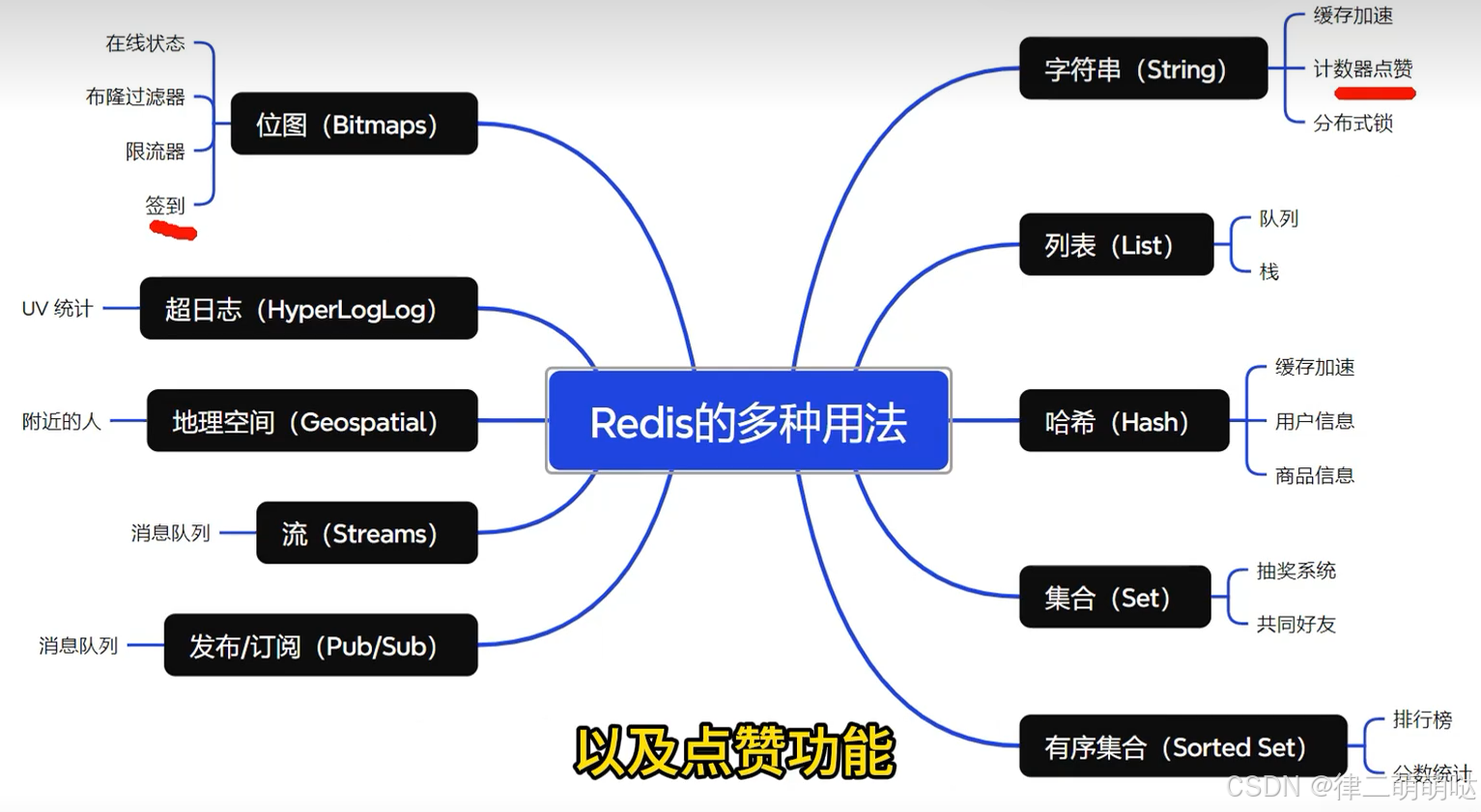
46. Redis除了做缓存加速,还能做什么
47. Redis与MySQL,如何保一致?
? 保持Redis和MySQL数据一致性是确保系统稳定运行的关键。以下是几种有效的策略:
1️⃣ 同步更新:在更新MySQL数据后,立即同步更新Redis。这种方法虽然简单,但存在短暂的数据不一致风险。
2️⃣ 异步更新:通过消息队列实现数据的异步更新,可以减少性能开销,但可能会引入时间差。
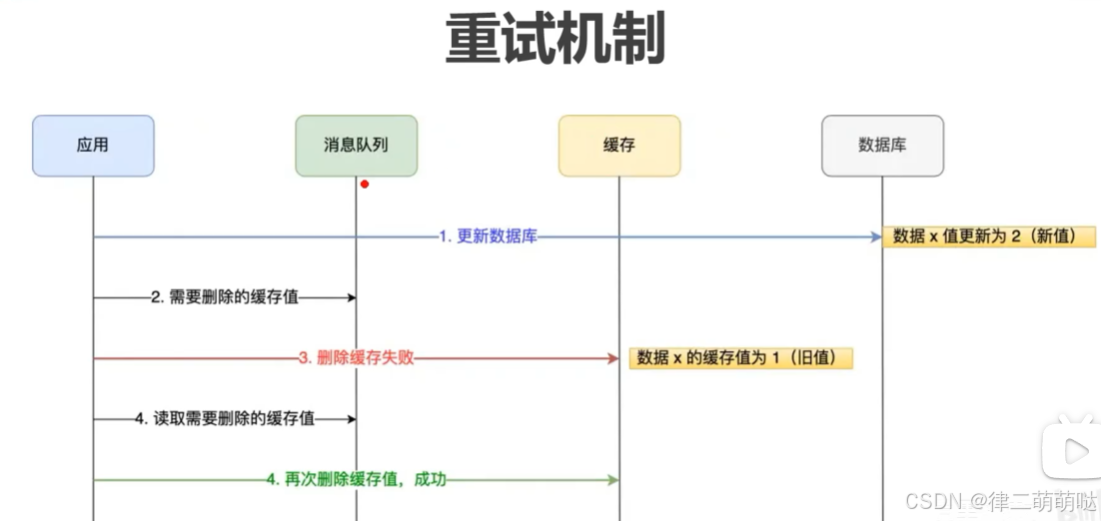
3️⃣ 延时双删:更新数据时,先更新MySQL,然后删除Redis中的缓存数据。通过异步任务延迟一段时间再清理缓存,以防短时间内大量相同的数据请求导致的缓存击穿问题。
适用场景:适用于数据更新后需要立即生效,但可以容忍一定时间内的不一致。
优缺点:牺牲了一部分一致性以换取性能上的提升,但在某些敏感操作中,可能需要更严格的一致性保证。
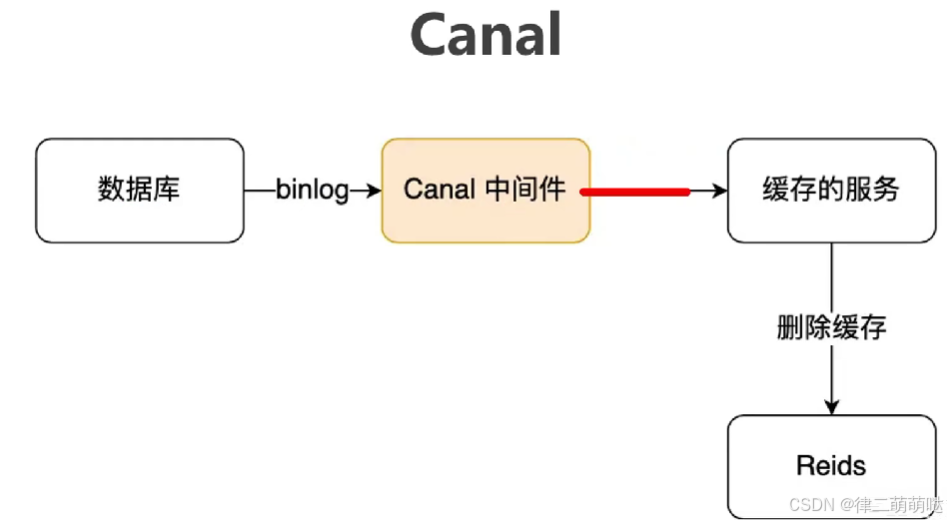
4️⃣ Binlog订阅:利用MySQL的Binlog日志来实现数据变更的实时同步。当MySQL数据发生变化时,通过监听Binlog日志,实时更新或删除Redis中的缓存。
适用场景:适用于需要实时同步,但又不想在业务代码中增加太多开销的情况。
优缺点:实现较为复杂,但可以有效地减少对业务代码的影响,提高系统的整体性能和数据一致性。
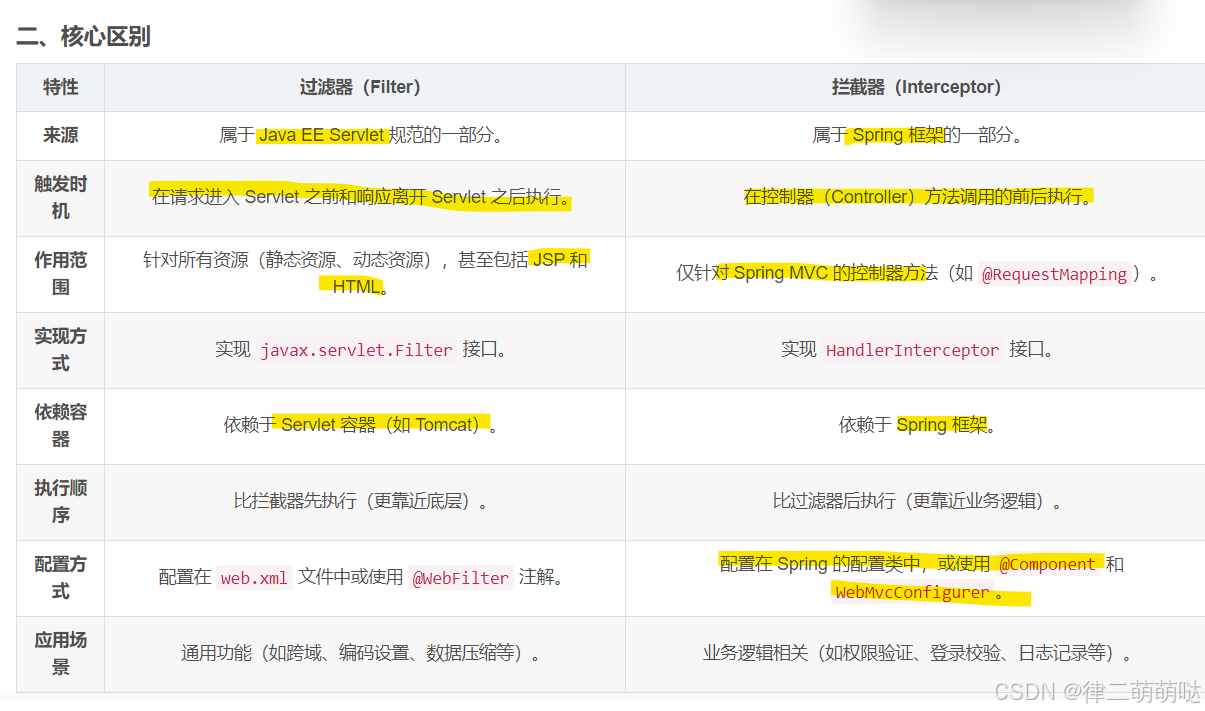
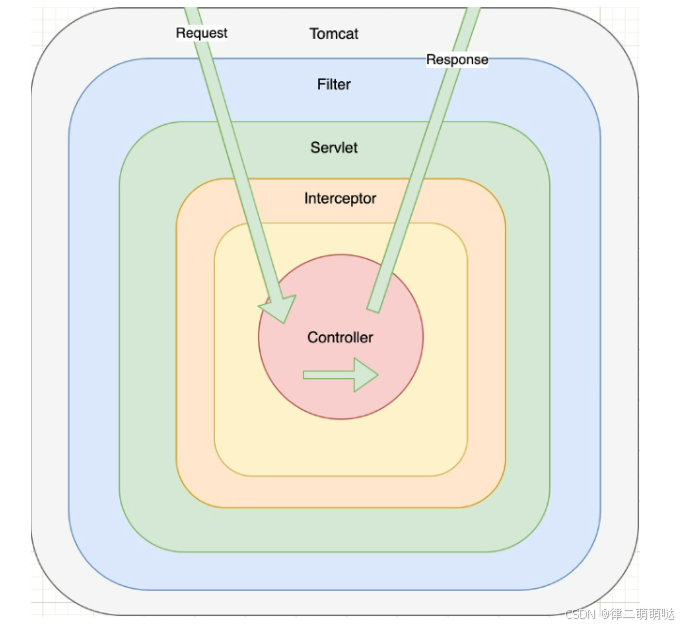
48. 过滤器和拦截器的区别
过滤器和拦截器的区别详解
过滤器(Filter)和拦截器(Interceptor) 是 Web 开发中常用的工具,它们可以在请求处理流程中拦截请求或响应,用于完成某些通用功能或业务逻辑控制。尽管它们有很多相似之处,但本质上是两个完全不同的概念。以下是两者的详细区别及使用场景。



四、具体实现
- 过滤器的实现
基于函数回调机制,通过调用 FilterChain.doFilter() 来控制请求的继续执行。
使用 javax.servlet.Filter 接口开发过滤器,需要实现以下三个方法:
示例代码如下:
import jakarta.servlet.*;
import jakarta.servlet.annotation.WebFilter;
import java.io.IOException;
@WebFilter(urlPatterns = "/*")
public class TestFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("执行过滤器 init()方法");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("开始执行过滤器 doFilter 方法");
filterChain.doFilter(servletRequest, servletResponse);
System.out.println("结束执行过滤器 doFilter 方法");
}
@Override
public void destroy() {
System.out.println("执行过滤器 destroy()方法");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
启用过滤器在启动类上加上注解 @ServletComponentScan

import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
@Component
public class TestInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("执行过滤器preHandle方法");
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("执行拦截器 postHandle()方法");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("执行拦截器 afterCompletion()方法");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
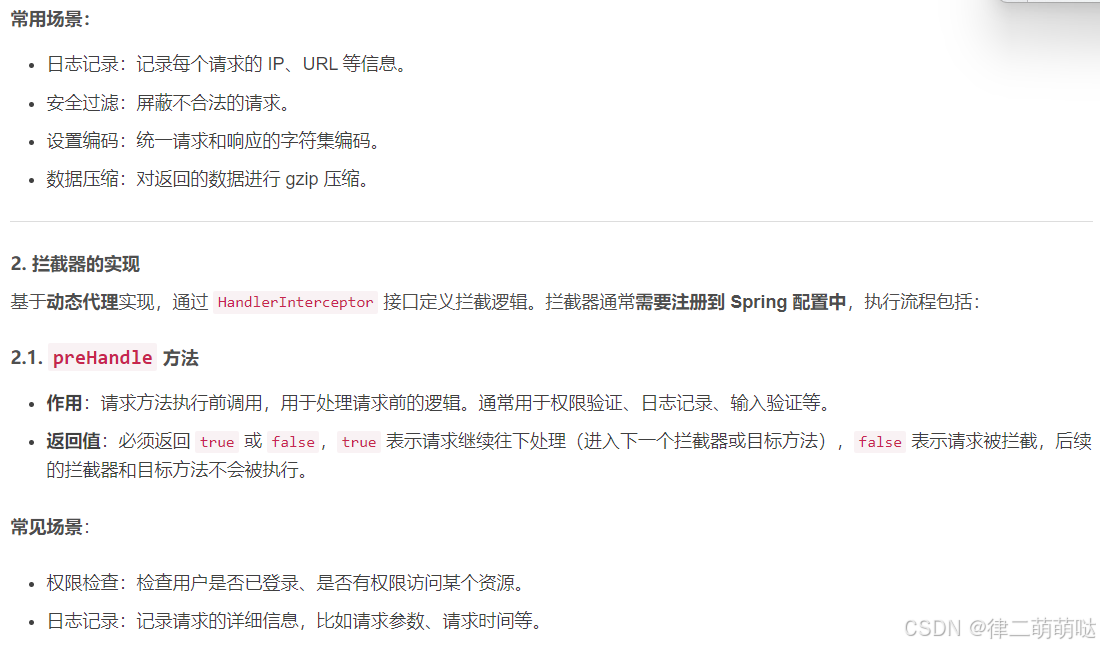
配置拦截器:
将拦截器加入到 Spring 配置中:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class InterceptorConfig implements WebMvcConfigurer {
@Autowired
private TestInterceptor testInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(testInterceptor) //添加拦截器
.addPathPatterns("/**"); //拦截所有地址
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
49. 接口性能优化

1. 缓存机制:
利用如@Cacheable等注解实现缓存,可以减少重复数据的处理和查询时间,特别是针对频繁请求的数据。合理利用缓存能够显著减少数据访问时间。
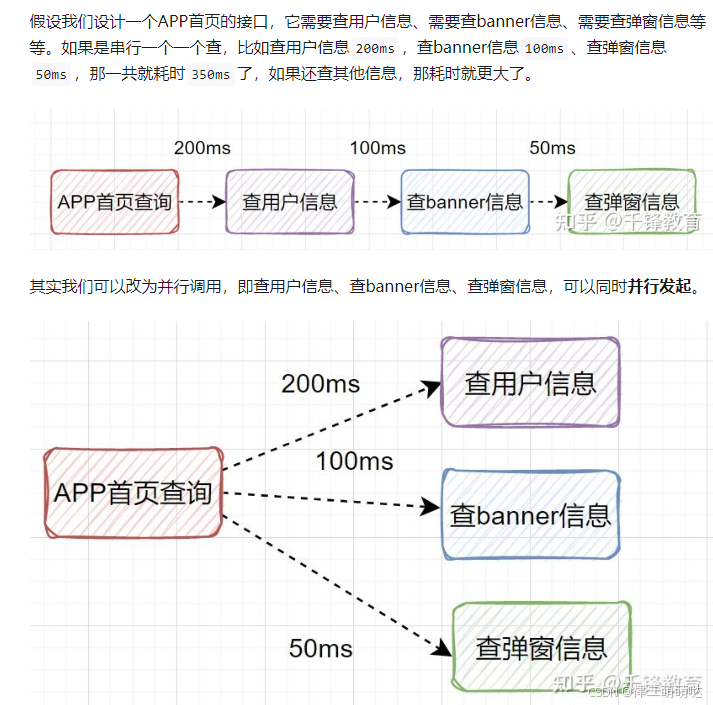
2. 并发调用:
并发调用可以减少API整体执行时间,提高响应
3.同步接口异步化
通过标记方法为异步,例如使用@Async注解,可以让长时间运行的任务在后台执行,从而不阻塞主线程。
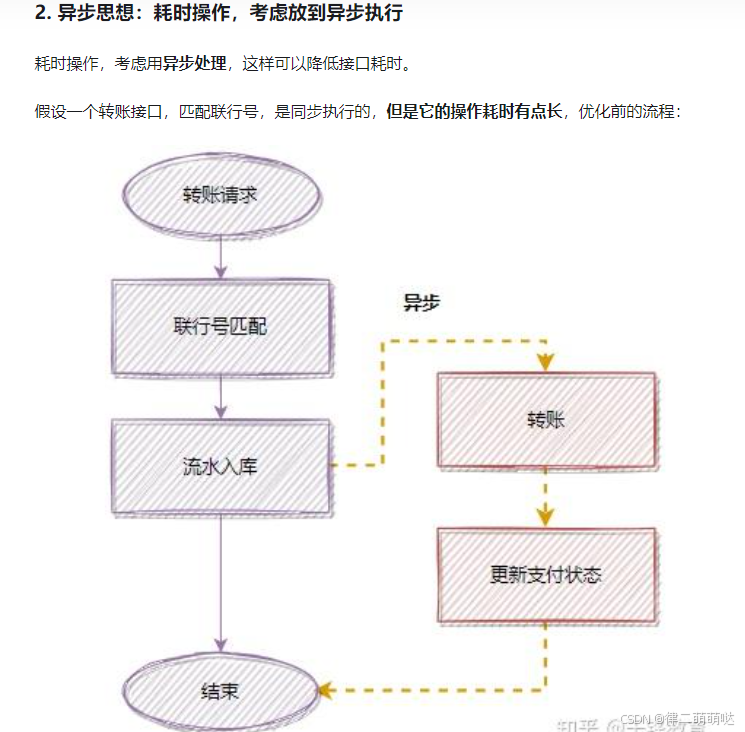
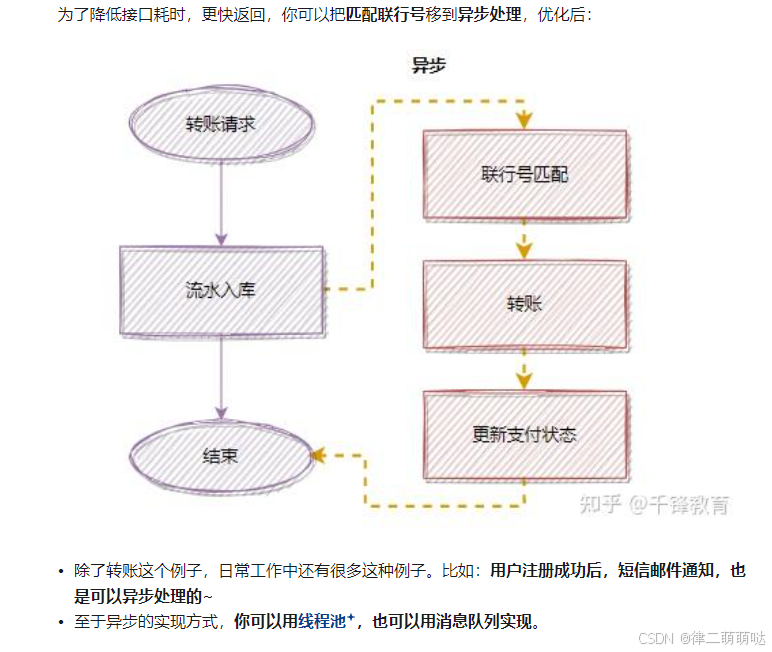
4.优化日志记录:
合理配置日志级别并在生产环境中关闭不必要的日志,可以减少日志记录对性能的影响。
5.避免大事务:
避免大事务可以防止数据库连接耗尽,提升系统稳定性。




13.2 延迟关联法
延迟关联法,就是把条件转移到主键索引树,然后减少回表。优化后的SQL如下:
select acct1.id,acct1.name,acct1.balance
FROM account acct1
INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2
on acct1.id= acct2.id;
- 1
- 2
- 3
- 4
优化思路就是,先通过idx_create_time二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。

50. OOM一定会导致JVM退出吗
在Java中,发生了OutOfMemoryError(OOM)不一定会导致整个JVM退出。是否退出取决于发生OOM错误的线程和错误处理逻辑。这是一个复杂的问题,具体行为会因应用程序实现方式、错误发生的情境以及错误处理策略而异。
-
主线程中未处理的OOM:
如果在主线程中发生OOM且没有被捕获,JVM通常会终止程序并退出。这是因为JVM中没有其他存活的非守护线程来保持程序运行。 -
子线程中未处理的OOM:
在非主线程中,如果OOM发生且未被捕获,该线程会停止执行。但如果其他非守护线程仍在运行,JVM不会退出。 -
捕获并处理OOM:
如果在代码中捕获并正确处理了OOM错误,JVM则可以继续执行其余的程序代码。合适的错误处理可能包括释放内存资源或提示用户进行适当的操作。
public class OOMExample {
public static void main(String[] args) throws InterruptedException{
// 子线程中发生OOM并及时处理
Thread thread1 = new Thread(() -> {
try {
oomMethod();
} catch (OutOfMemoryError e) {
System.out.println("Handled OOM in thread. JVM will not exit.");
}
});
// 子线程中发生OOM不处理
Thread thread2 = new Thread(() -> {
oomMethod();
});
thread1.start();
Thread.sleep(3000);
thread2.start();
Thread.sleep(3000);
// 主线程中发生OOM并且及时处理,JVM不会退出
try {
oomMethod();
} catch (OutOfMemoryError e) {
System.out.println("Handled OOM in main. JVM will continue.");
}
// 主线程中发生OOM而未处理,JVM会马上退出
System.out.println("JVM退出前");
oomMethod();
System.out.println("JVM退出后");
}
public static void oomMethod() {
int[] array = new int[Integer.MAX_VALUE]; // 试图分配过大的数组,触发OOM
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
输出结果:
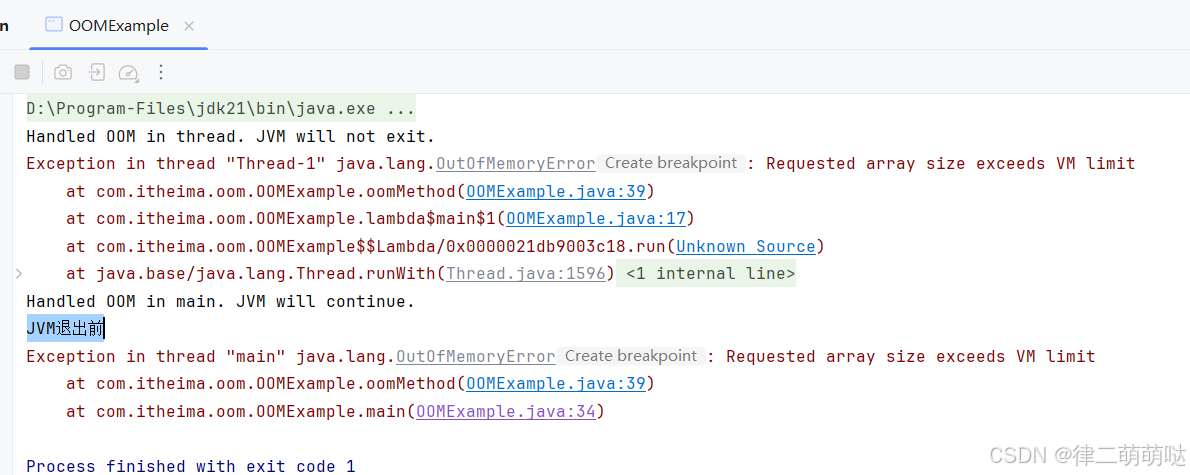
行为解释
- 在主线程中,如果未捕获的OOM发生,程序将立即终止。
在子线程中,我们捕获了OOM并进行了打印处理。即使发生了OOM,该子线程停止,但主线程继续执行主线程外的任务。如果没有捕获,子线程停止,但JVM不会退出,因为主线程仍在运行。此示例代码通过捕获异常展示了如何使程序在发生OOM时继续执行,但开发者应合理处理这些错误以避免不必要的错误传播和程序行为失常。
注意事项
不建议频繁捕获OOM并继续执行程序,因为这样可能表明程序有严重的内存管理问题,应尽量优化内存使用。
在关键路径中发生OOM时,通常应记录日志并考虑安全停机,因为无法保证系统在内存压力下的正确性。
- 1
- 2
51. 为什么大厂的线上数据库禁止delete
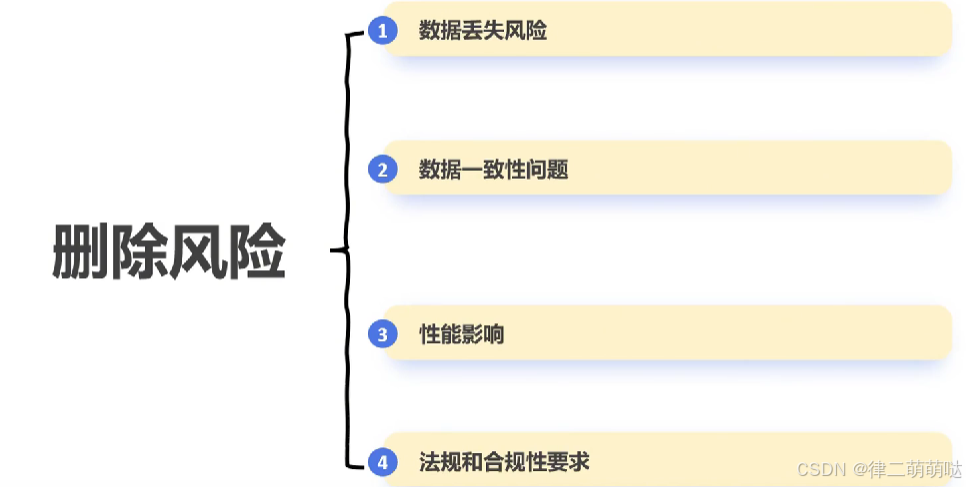
1. 数据丢失风险
- 1
案例:某公司在生产环境中执行了一条错误的 DELETE语句,结果误删了大量用户数据,导致服务中断和用户投诉。 数据丢失风险 原因:DELETE操作是不可逆的,一旦执行,数据将被永久删除。如果没有及时备份或其他保护措施,数据恢复将非常困难。
2. 数据一致性问题
- 1
案例:在一个分布式系统中,某个服务直接删除了数据库中的记录,但其他依赖该数据的服务没有同步更新,导致数据不一致。 数据一致性问题 原因:直接删除数据可能导致系统中其他部分的数据不一致,尤其是在分布式系统中,数据同步和一致性是非常重要的。
3. 性能影响
- 1
案例:某电商平台在高峰期执行了一次大规模的 DELETE操作,导致数据库锁定,影响了其他查询的性能,最终导致网站响应缓慢。 性能影响 原因:DELETE操作会锁定表或行,尤其是在大规模删除时,会导致性能下降,影响其他查询的执行。
4. 法规合规性要求
- 1
案例:某金融机构需要保留所有交易记录以满足监管要求,直接删除数据可能导致合规性问题。 法规和合规性要求 原因:许多行业有法规要求保留数据一定时间,直接删除可能违反这些法规。
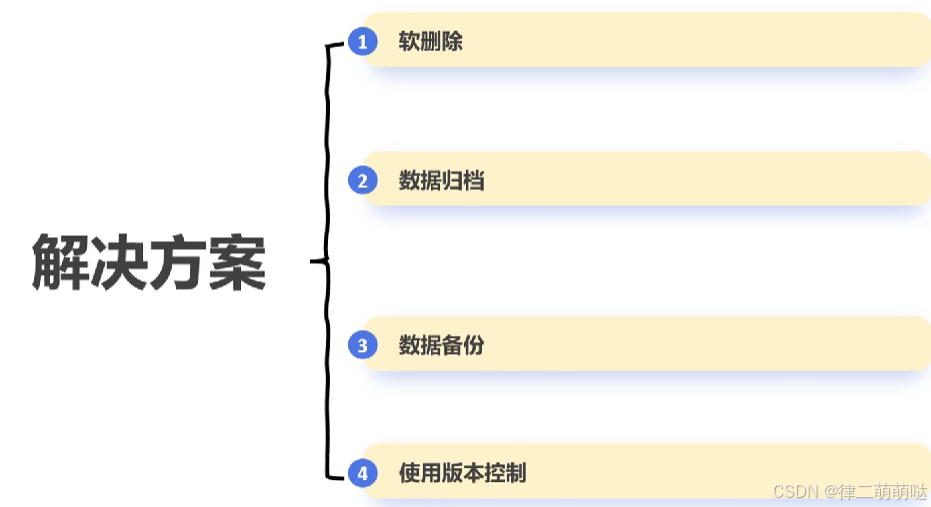
1. 软删除
- 1
实现:在需要删除数据时,将is_deleted字段设置为true或1。在查询数据时,添加条件过滤掉标记为已删除的数据(如WHERE is_deleted= 0)。
优点:数据仍然保留在数据库中,可以随时恢复。不影响数据的完整性和一致性,支持数据审计和追踪。
2. 数据归档
- 1
方法:将不再需要频繁访问的数据移动到一个专门的归档表或数据库中。
实现:定期将旧数据从主表中复制到归档表,并在主表中标记或删除。归档表可以存储在性能要求较低的存储介质上。
优点:减少主表的数据量,提高查询性能。归档数据仍然可用,可以在需要时进行查询。
3. 数据备份
- 1
方法:定期对数据库进行备份,以确保在需要时可以恢复数据。
实现:使用数据库提供的备份工具或第三方工具进行定期备份,确保备份数据的安全性和可用性。
优点:提供数据恢复的保障。备份数据可以用于灾难恢复和数据审计。
3. 使用版本控制
- 1
方法:对数据的每次变更进行版本控制,保留历史版本。
实现:在数据表中添加版本号字段。每次更新数据时,增加版本号并保留旧版本。
优点:支持数据的历史追踪和恢复。提供数据变更的透明性。
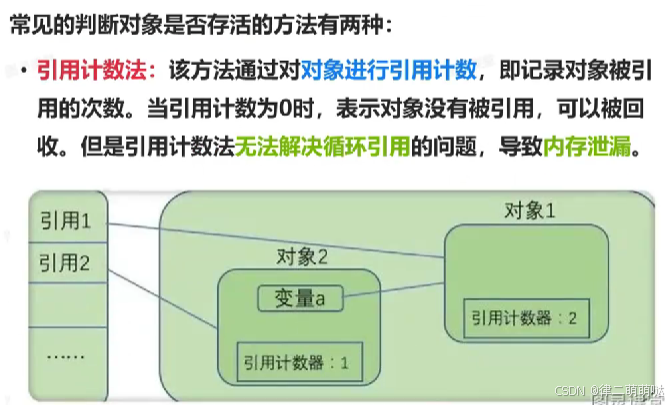
52. 如何判断对象依然存活
二、可达性分析法
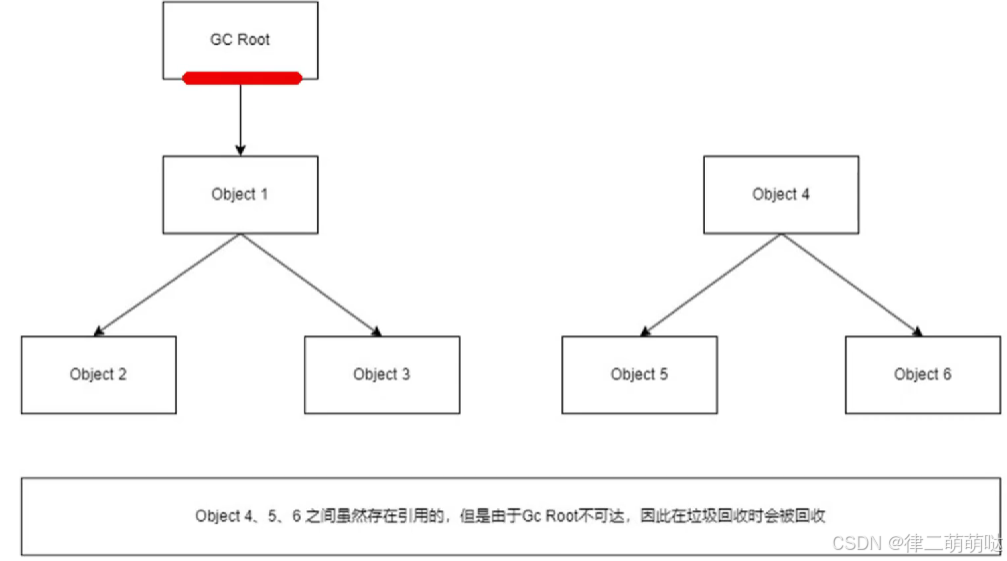
从一个被称为GC Roots 的对象向下搜索,如果一个对象到 GC Roots 没有任何引用链相连接时,说明此对象不可用,在java 中可以作为 GC Roots 的对象有以下几种:
1、虚拟机栈中引用的对象
2、方法区类静态属性引用的变量
3、方法区常量池引用的对象
4、本地方法栈JNI 引用的对象
- 1
- 2
- 3
- 4
但一个对象满足上述条件的时候,不会马上被回收,还需要进行两次标记;
-
第一次标记:判断当前对象
是否有finalize()方法并且该方法没有被执行过,若不存在则标记为垃圾对象,等待回收;若有的话,则进行第二次标记; -
第二次标记将当前对象放入F-Queue队列,并生成一个 finalize线程去执行该方法,虚拟机不保证该方法一定会被执行,这是因为如果线程执行缓慢或进入了死锁,会导致回收系统的崩溃; 如果执行了finalize方法之后仍然没有与 GC Roots 有直接或者间接的引用,则该对象会被回收。
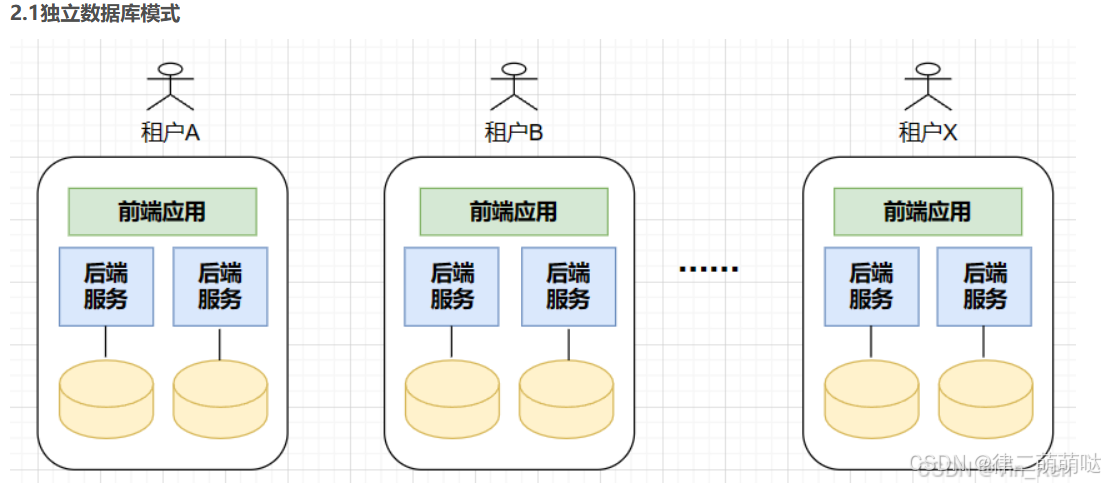
53. Saas多租户隔离解决方案
一、多租户的概念
- 多租户本质上是一种软件的技术架构,最核心的特征是多个租户可以共享一个系统实例,并且租户间是可以实现数据和行为的隔离
多租户架构是 SaaS 模式中的重要且常见的架构,通过共享和复用资源降低成本,提高效率和可扩展性。其中最需要关注就是:数据/行为的隔离、身份/角色的认证与授权、底层硬件资源管理、高性能与高可用、定制化和可扩展、数据一致性、系统安全性等。
二、隔离模式
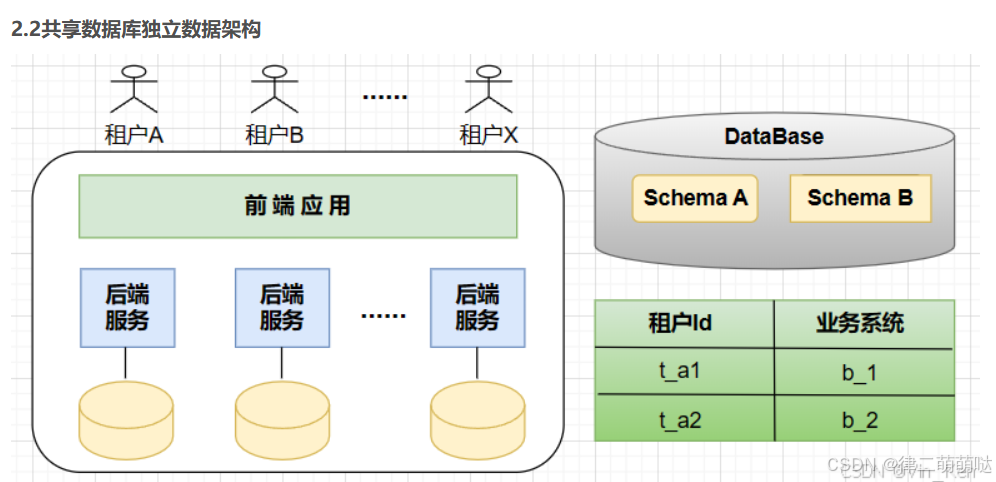
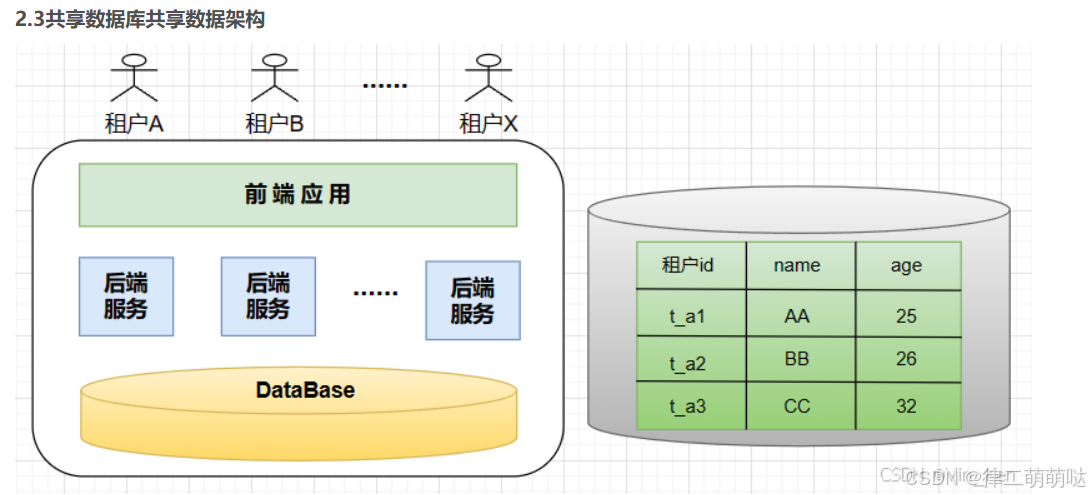
常见的有3种隔离模式:独立数据库、共享数据但独立数据架构、共享数据库且共享数据架构。



54. 什么是间隙锁
- 间隙锁就是两个值之间的空隙加锁,是InnoDB在可重复读隔离级别下为了
解决幻读问题而引入的一种锁机制。需注意间隙锁只会在可重复读隔离级别(REPEATABLE-READ)下才会生效。
SQL示例:
drop TABLE orders;
CREATE TABLE orders (
order_id INT NOT NULL PRIMARY KEY,
product_name VARCHAR(50) NOT NULL,
quantity INT NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO orders (
order_id,
product_name,
quantity
) VALUES
(1, 'iPhone', 2),
(2, 'iPad', 1),
(3, 'MacBook', 3),
(7, 'AirPods', 7),
(10, 'Apple Watch', 10);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
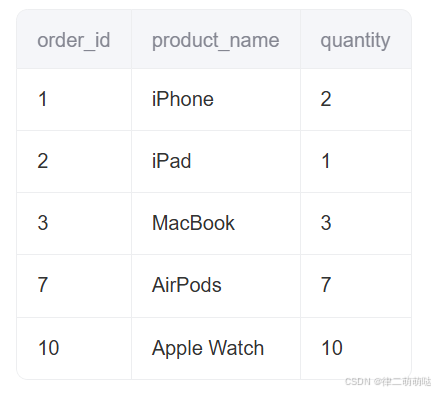
此时的order表存在(3,7),(7,10),(10,正无穷)。
-- 事务A
set tx_isolation = 'REPEATABLE-READ';
BEGIN;
SELECT * FROM orders WHERE order_id = 8 FOR UPDATE;
#commit;
- 1
- 2
- 3
- 4
- 5
其他事务无法在这个(7,10)区间插入任何数据。
-- 事务A
set tx_isolation = 'REPEATABLE-READ';
BEGIN;
SELECT * FROM orders WHERE order_id = 15 FOR UPDATE;
#commit;
- 1
- 2
- 3
- 4
- 5
其他事务无法在这个(10,正无穷)区间插入任何数据。
操作步骤如下:
开启事务修改order_id为8的数据,但是不提交事务,同时开启事务进行插入id为8的数据(此操作会因事务A的锁而阻塞)。
# 事务A
set tx_isolation = 'REPEATABLE-READ';
BEGIN;
SELECT * FROM orders WHERE order_id = 8 FOR UPDATE;
COMMIT;
# 事务B
set tx_isolation = 'REPEATABLE-READ';
BEGIN;
INSERT INTO orders (
order_id,
product_name,
quantity
) VALUES
(8, 'AirPods Pro', 2);
COMMIT;
# 事务C
BEGIN;
SELECT * FROM orders WHERE order_id = 10 FOR UPDATE;
COMMIT;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
此时事务B阻塞无法插入成功;再开启事务C进行数据修改,可以修改成功;将事务A进行提交,事务B随即插入成功。
间隙锁可以锁定一个范围内的所有记录,包括不存在的记录,从而防止其他事务在该范围内插入或修改数据。
- 1
55. MySQL自增主键一定是连续的吗
自增主键的特点是当表中每新增一条记录时,主键值会根据自增步长自动叠加,通常会将自增步长设置1,也就是说自增主键值是连续的。那么MySQL自增主键值一定会连续吗?今天这篇文章就来说说这个问题,看看什么情况下自增主键会出现不连续?
drop TABLE increment_test;
-- 创建包含自增主键的表
CREATE TABLE increment_test (
id INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
col1 INT(11) NOT NULL,
col2 INT(11) NOT NULL,
col3 INT(11) NOT NULL,
UNIQUE KEY (col1)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
INSERT INTO increment_test (col1, col2, col3) VALUES (3, 3, 3);
INSERT INTO increment_test (col1, col2, col3) VALUES (4, 4, 4);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
一、自增值的属性特征
1.自增主键值是存储在哪的?
MySQL5.7版本
- 在 MySQL 5.7 及之前的版本,
自增值保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值max(id),然后将 max(id)+1 作为这个表当前的自增值。
MySQL8.0之后版本
- 在 MySQL 8.0 版本,将自增值的变更记录在了
redo log中,重启的时候依靠 redo log 恢复重启之前的值。
可以通过看表详情查看当前自增值,以及查看表参数详情AUTO_INCREMENT值(AUTO_INCREMENT就是当前数据表的自增值)
2.自增主键值的修改机制?
在表t中,我定义了主键id为自增值,在插入一行数据的时候,自增值的行为如下:
1)如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段;
2)如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。
根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设,某次要插入的值是 X,
当前的自增值是 Y。
1)如果 X<Y,那么这个表的自增值不变;
2)如果 X≥Y,就需要把当前自增值修改为新的自增值。
- 1
- 2
- 3
- 4
- 5
3.自增值修改流程
上述我们了解了自增值的存储机制与修改机制,自增值修改是在哪个环境呢?那需要了解自增值修改流程。
INSERT INTO increment_test (col1, col2, col3)
VALUES(3,3,3);
- 1
- 2
以上述SQL为例,我们假如数据库里已经有2条数据了,它的执行流程如下:
- 执行器调用InnoDB引擎接口将分析器优化后的SQL传入,并将值(3,3,3)一起传过去。
- InnoDB发现用户没有指定自增id列,会先获取表increment_test当前的自增值3;
- 将ID列补充完整,并且将自增值填入(3,3,3,3);
- 然后将表的自增值改成4;
- 继续执行插入数据操作;
自增字段值的生成是由存储引擎自动完成的,而不是由优化器完成的。因此,在执行SQL语句时,即使未指定自增字段列,也不会对性能产生任何影响。
二、导致自增值不连续的原因
2.1
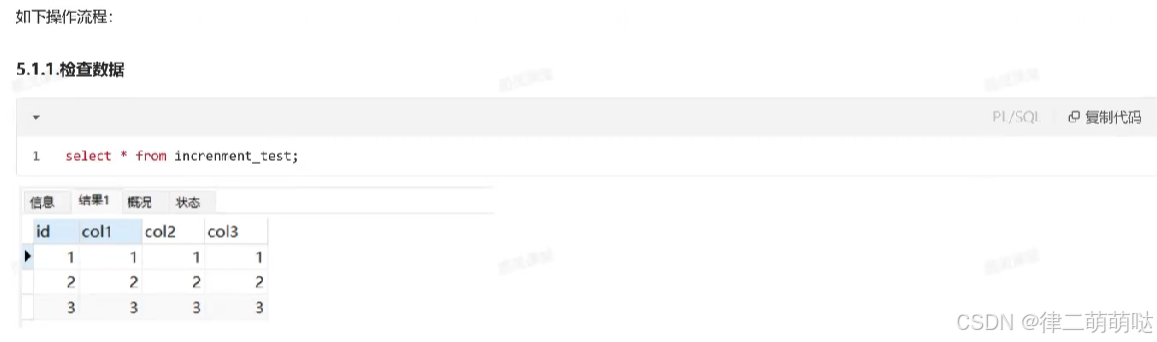
唯一性冲突
比如increment_test中已经存在了col1为3的记录,我们继续插入col1为3的记录,此时会出现唯一性冲突插入失败,但是没有将自增值再改回去,重新插入col1为4的值,此时对应的id为5。
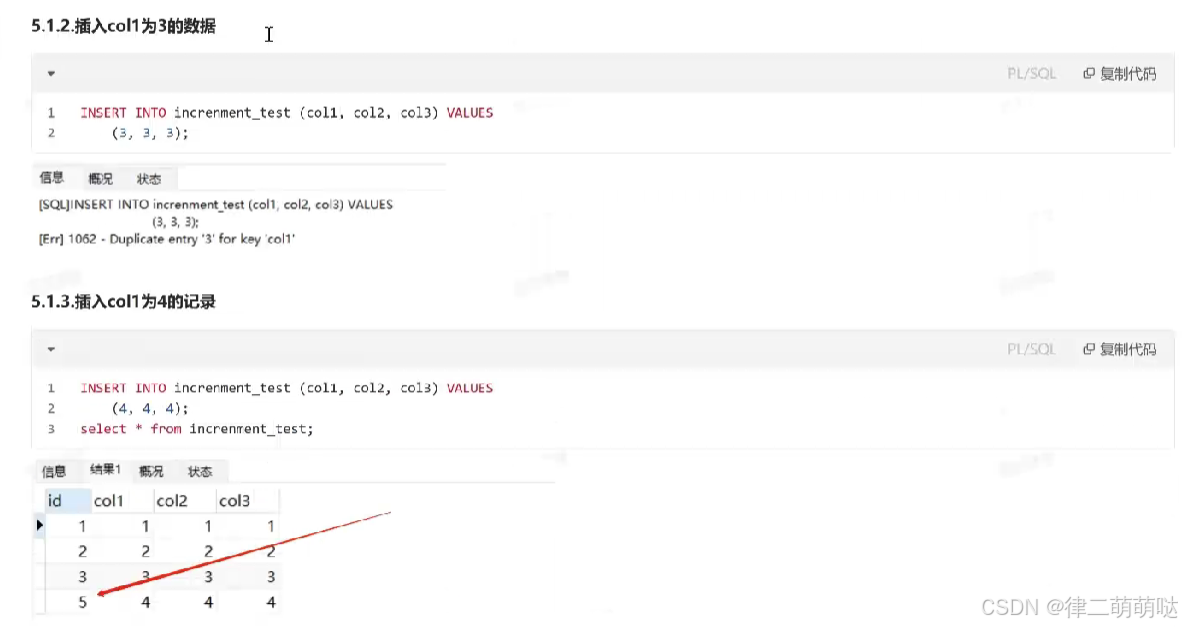
2.2
事务回滚
开启一个事务插入col1为6的数据,然后进行回滚。回滚后重新插入col1为6的记录,此时col1为6对应的id值为7
BEGIN;
INSERT INTO increment_test (col1, col2, col3) VALUES (6, 6, 6);
ROLLBACK;
BEGIN;
INSERT INTO increment_test (col1, col2, col3) VALUES (6, 6, 6);
COMMIT;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
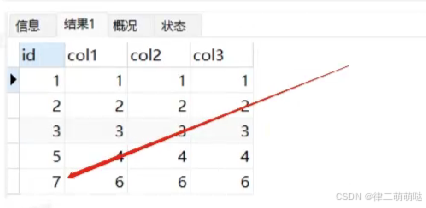
2.3
批量插入数据
对于批量插入数据的语句,MySQL有一个批量申请自增id的策略:
- SQL语句执行过程中,第1次申请自增id,会分配1个;
- 1个用完以后,第2次申请自增id,会分配2个;
- 2个用完以后,第3次申请自增id,会分配4个;
依此类推,同一个语句去申请自增id,每次申请到的自增id个数都是上一次的两倍。
drop table increment_test2;
create table increment_test2 like increment_test;
INSERT INTO increment_test2 (col1, col2, col3)
SELECT col1, col2, col3 FROM increment_test;
INSERT INTO increment_test2 (col1, col2, col3) VALUES (8, 8, 8);
SELECT * FROM increment_test2;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

因为increment_test2 批量插入了两条数据,按照自增id的批量申请策略,5条数据分三次进行申请
56. SQL的7种进阶用法
1、自定义排序(ORDER BY FIELD)
在MySQL中ORDER BY排序除了可以用ASC和DESC之外,还可以使用自定义排序方式来实现。
CREATE TABLE movies (
id INT PRIMARY KEY AUTO_INCREMENT,
movie_name VARCHAR(255),
actors VARCHAR(255),
price DECIMAL(10, 2) DEFAULT 50,
release_date DATE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO movies (movie_name, actors, price, release_date) VALUES
('咱们结婚吧', '靳东', 43.2, '2013-04-12'),
('四大名捕', '刘亦菲', 62.5, '2013-12-21'),
('猎场', '靳东', 68.5, '2017-11-03'),
('芳华', '范冰冰', 55.0, '2017-09-15'),
('功夫瑜伽', '成龙', 91.8, '2017-01-28'),
('惊天解密', '靳东', 96.9, '2019-08-13'),
('铜雀台', null, 65, '2025-12-16'),
('天下无贼', '刘亦菲', 44.9, '2004-12-16'),
('建国大业', '范冰冰', 70.5, '2009-09-21'),
('赛尔号4:疯狂机器城', '范冰冰', 58.9, '2021-07-30'),
('花木兰', '刘亦菲', 89.0, '2020-09-11'),
('警察故事', '成龙', 68.0, '1985-12-14'),
('神话', '成龙', 86.5, '2005-12-22');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
使用如下:
通常用法
select * from movies order by movie_name asc;
- 1
进阶用法
select * from movies ORDER BY FIELD(movie_name,'神话','猎场','芳华','花木兰',
'铜雀台','警察故事','天下无贼','四大名捕','惊天解密','建国大业',
'功夫瑜伽','咱们结婚吧','赛尔号4:疯狂机器城');
- 1
- 2
- 3
会根据我们自定义的字段以及数据进行排序
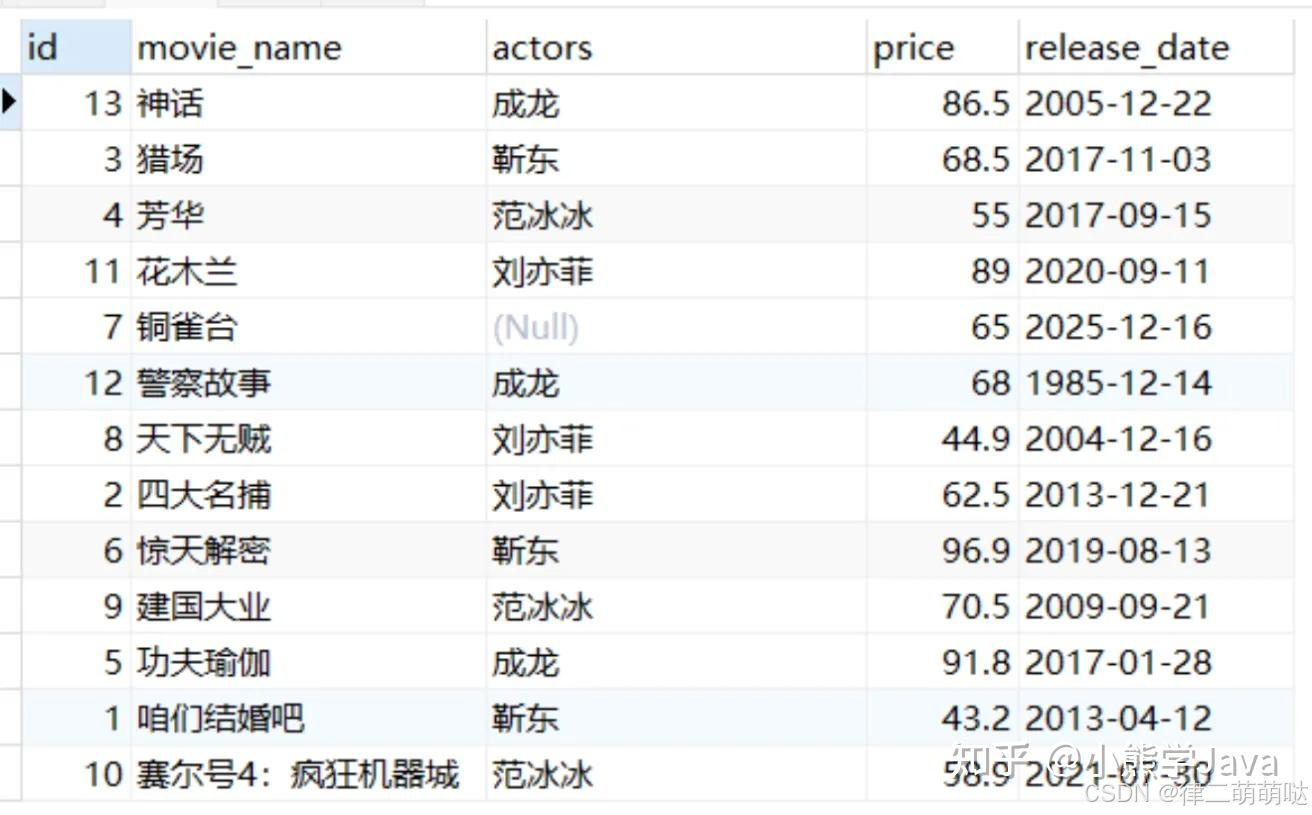
2、空值NULL排序(ORDER BY IF(ISNULL))
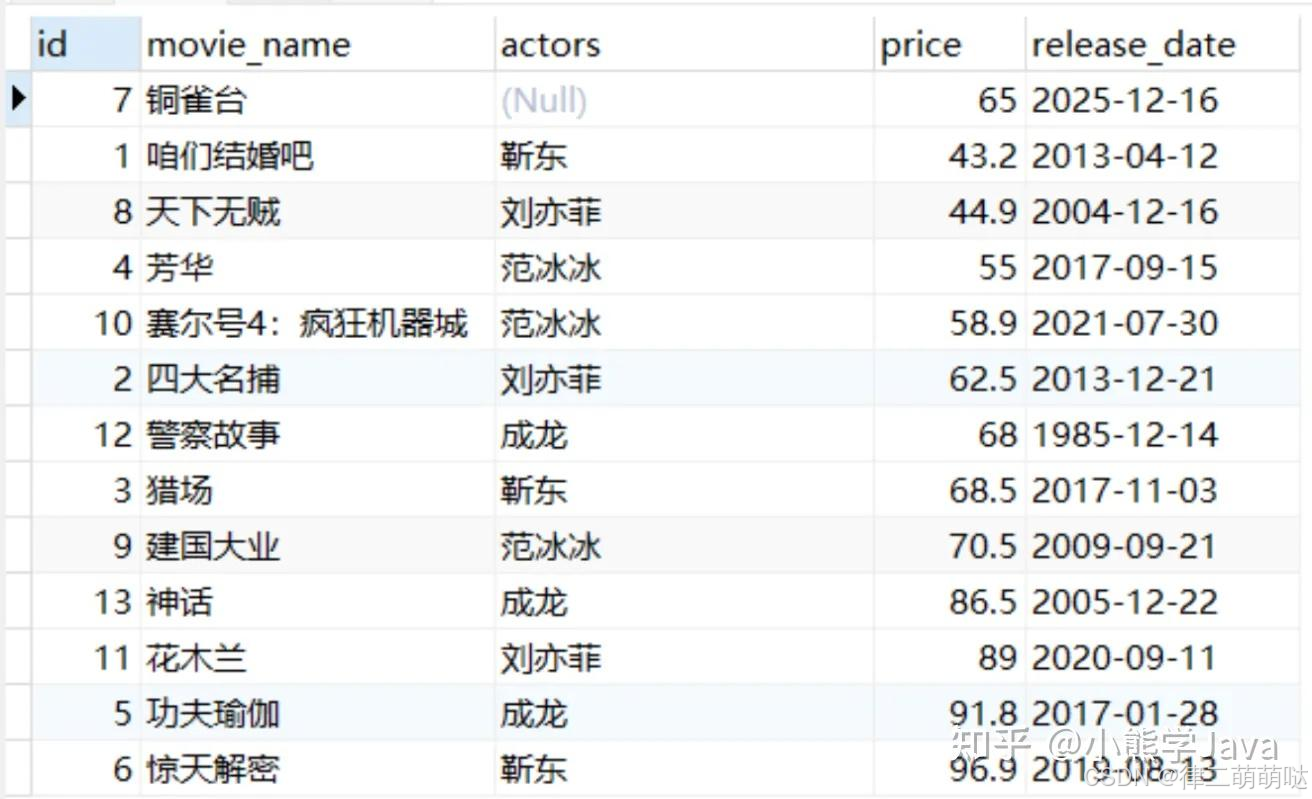
- 在MySQL中使用ORDER BY关键字加上我们需要排序的字段名称就可以完成该字段的排序。
- 如果字段中存在NULL值就会对我们的排序结果造成影响。 这时候我们可以使用
ORDER BY IF(ISNULL(字段), 0, 1)语法将NULL值转换成0或1,实现NULL值数据排序到数据集前面还是后面。
如果字段的值是NULL (ISNULL(字段) 返回真),则 IF 函数返回0。
如果字段的值不是NULL,IF 函数返回1。
select * from movies ORDER BY actors, price desc;
select * from movies ORDER BY if(ISNULL(actors),0,1), actors, price;
- 1
- 2
- 3
相反,如果你想让NULL值排在最后,你可以将表达式中的0和1互换位置。 ORDER BY IF(ISNULL(字段), 1, 0), 字段 ASC
3、CASE表达式(CASE···WHEN)
在实际开发中我们经常会写很多if ··· else if ··· else,这时候我们可以使用CASE···WHEN表达式解决这个问题。
以学生成绩举例。比如说:学生90分以上评为优秀,分数80-90评为良好,分数60-80评为一般,分数低于60评为“较差”。那么我们可以使用下面这种查询方式:
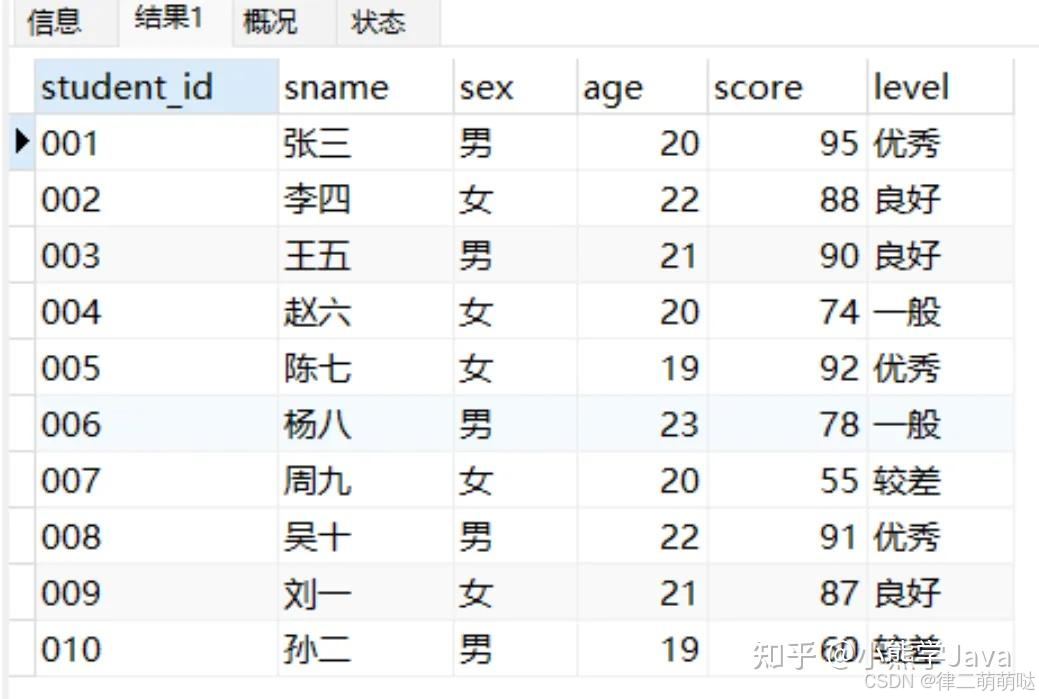
CREATE TABLE student (
student_id varchar(10) NOT NULL COMMENT '学号',
sname varchar(20) DEFAULT NULL COMMENT '姓名',
sex char(2) DEFAULT NULL COMMENT '性别',
age int(11) DEFAULT NULL COMMENT '年龄',
score float DEFAULT NULL COMMENT '成绩',
PRIMARY KEY (student_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='学生表';
INSERT INTO student (student_id, sname, sex, age , score)
VALUES ('001', '张三', '男', 20, 95),
('002', '李四', '女', 22, 88),
('003', '王五', '男', 21, 90),
('004', '赵六', '女', 20, 74),
('005', '陈七', '女', 19, 92),
('006', '杨八', '男', 23, 78),
('007', '周九', '女', 20, 55),
('008', '吴十', '男', 22, 91),
('009', '刘一', '女', 21, 87),
('010', '孙二', '男', 19, 60);
查询语句如下:
select *,case when score > 90 then '优秀'
when score > 80 then '良好'
when score > 60 then '一般'
else '较差' end level
from student;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
结果如下:
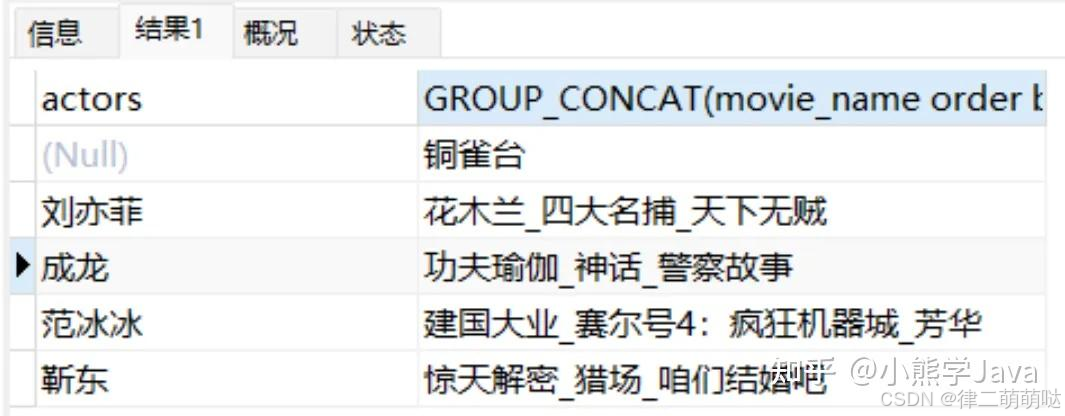
4、分组连接函数(GROUP_CONCAT)
分组连接函数可以在分组后指定字段的字符串连接方式,并且还可以指定排序逻辑;连接字符串默认为英文逗号。
比如说根据演员进行分组,并将相应的电影名称按照票价进行降序排列,而且电影名称之间通过“_”拼接。用法如下:
select actors,
GROUP_CONCAT(movie_name),
GROUP_CONCAT(price) from movies GROUP BY actors;
select actors,
GROUP_CONCAT(movie_name order by price desc SEPARATOR '_'),
GROUP_CONCAT(price order by price desc SEPARATOR '_')
from movies GROUP BY actors;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 第一个查询将返回每个演员参演的所有电影名称和价格,但这些值将以默认的逗号分隔符连接。
- 第二个查询将电影名称和价格连接成字符串,而且还按照价格降序排列,并使用下划线作为分隔符。
这意味着每个演员参演的电影将按价格从高到低排列,电影名称和价格之间用下划线分隔。
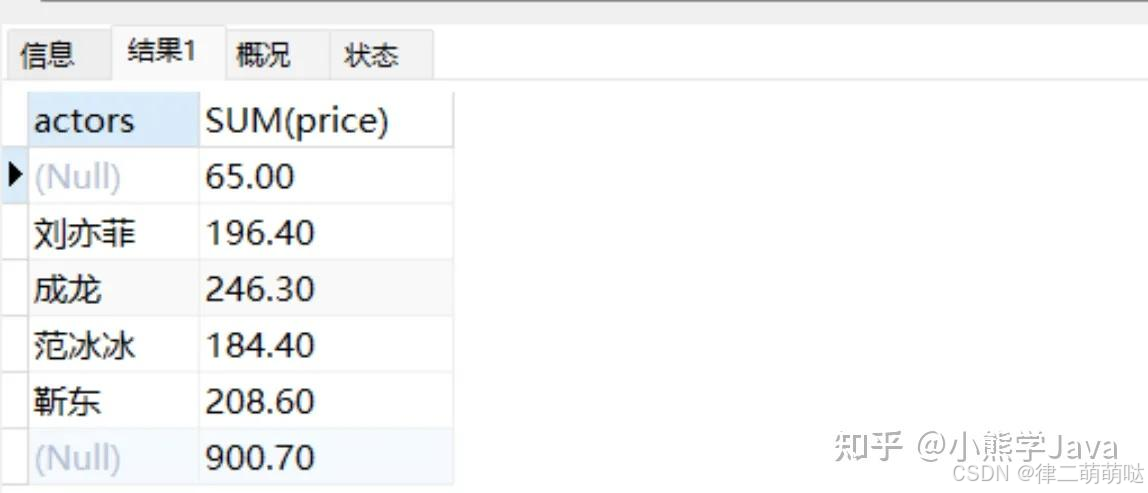
5、分组统计数据后再进行统计汇总(with rollup)
在MySQL中可以使用 with rollup在分组统计数据的基础上再进行数据统计汇总,即将分组后的数据进行汇总.
SELECT actors, SUM(price) FROM movies GROUP BY actors;
SELECT actors, SUM(price) FROM movies GROUP BY actors WITH ROLLUP;
- 1
- 2
- 3
6、子查询提取(with as)
如果一整句查询中多个子查询都需要使用同一个子查询的结果,那么就可以用with as将共用的子查询提取出来并取一个别名。后面查询语句可以直接用,对于大量复杂的SQL语句起到了很好的优化作用。
#需求:获取演员刘亦菲票价大于50且小于65的数据。
with m1 as (select * from movies where price > 50),
m2 as (select * from movies where price >= 65)
select * from m1 where m1.id not in (select m2.id from m2) and m1.actors = '刘亦菲';
- 1
- 2
- 3
- 4
- 5

7、优雅处理数据插入、更新时主键、唯一键重复
在MySQL中插入、更新数据有时会遇到主键重复的场景,通常的做法就是先进行删除在插入达到可重复执行的效果,但是这种方法有时候会错误删除数据。
插入数据时我们可以使用IGNORE,它的作用是插入的值遇到主键或者唯一键重复时自动忽略重复的数据,不影响后面数据的插入,即有则忽略,无则插入。示例如下:
select * from movies where id >= 13;
INSERT INTO movies (id, movie_name, actors, price, release_date) VALUES
(13, '神话', '成龙', 100, '2005-12-22');
INSERT IGNORE INTO movies (id, movie_name, actors, price, release_date) VALUES
(13, '神话', '成龙', 100, '2005-12-22');
INSERT IGNORE INTO movies (id, movie_name, actors, price, release_date) VALUES
(14, '神话2', '成龙', 114, '2005-12-22');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
还可以使用REPLACE关键字,当插入的记录遇到主键或者唯一键重复时先删除表中重复的记录行再插入,即有则删除+插入,无则插入,示例如下:
REPLACE INTO movies (id, movie_name, actors, price, release_date) VALUES
(14, '神话2', '成龙', 100, '2005-12-22');
REPLACE INTO movies (id, movie_name, actors, price, release_date) VALUES
(15, '神话3', '成龙', 115, '2005-12-22');
- 1
- 2
- 3
- 4
- 5

更新数据时使用on duplicate key update。它的作用就是当插入的记录遇到主键或者唯一键重复时,会执行后面定义的UPDATE操作。相当于先执行Insert 操作,再根据主键或者唯一键执行update操作,即有就更新,没有就插入。示例如下:
INSERT INTO movies (id, movie_name, actors, price, release_date) VALUES
(15, '神话3', '成龙', 115, '2005-12-22') on duplicate key update price = price + 10;
INSERT INTO movies (id, movie_name, actors, price, release_date) VALUES
(16, '神话4', '成龙', 75, '2005-12-22') on duplicate key update price = price + 10;
- 1
- 2
- 3
- 4
- 5

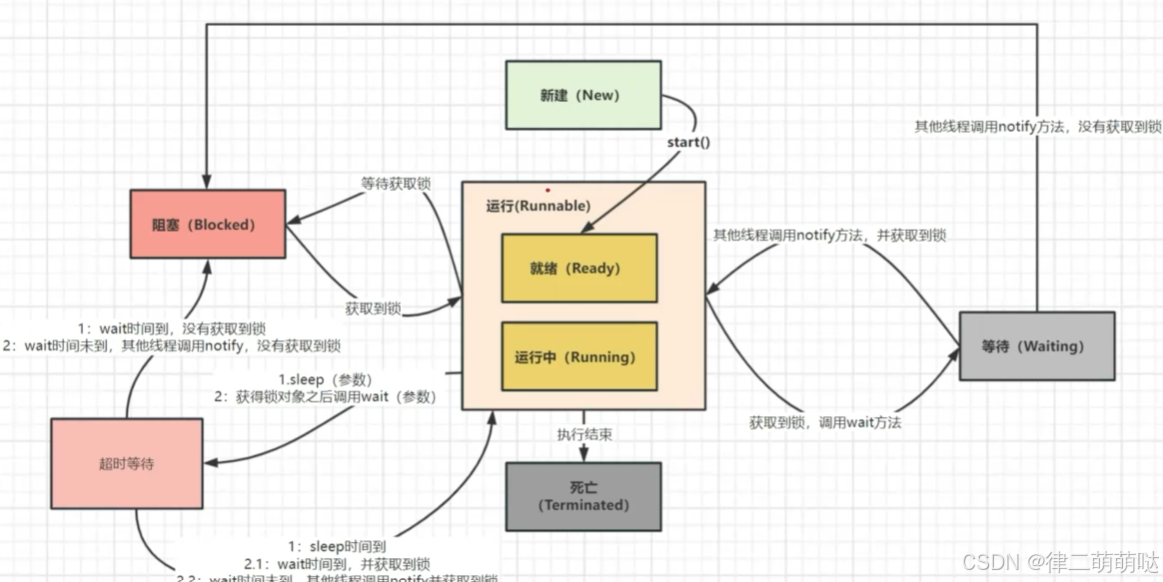
57. 线程有几种状态
- 新建(New) 初始状态:线程被创建,但还没有调用start()方法
- 就绪状态(可运行状态):调用
线程的start()方法后,该线程就处于就绪状态,但是没有获取到CPU时间片 - 运行中(Running) 运行状态:线程已经获得CPU时间片并正在执行
- 阻塞(Blocked) 阻塞状态:表示
线程阻塞锁 - 等待状态:表示线程进入等待状态,进入该状态表示当前线程需要等待其他线程做出一些特定动作(通知或中断)
- 超时等待(Timed waiting) 超时等待状态:也可以称为
计时等待。该状态不同于WAITING,它可以在指定的时间自行返回 - 终止(Terminated) 终止状态:表示当前线程已经执行完毕
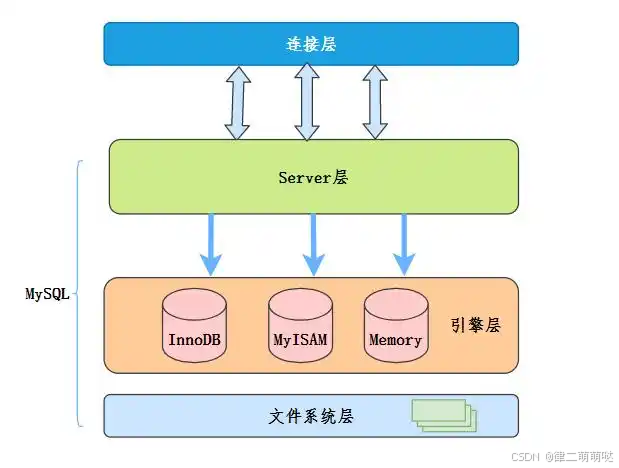
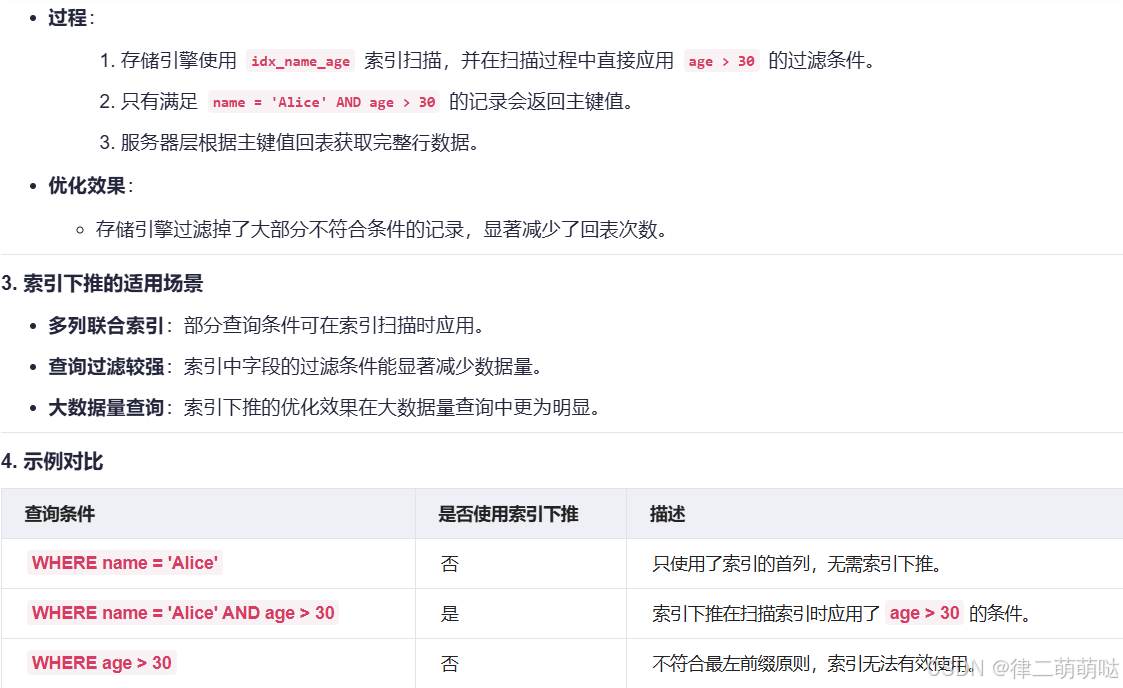
58. 什么是索引下推?
2. 示例分析
假设有如下表结构和索引:
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
department VARCHAR(50),
KEY idx_name_age (name, age)
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(1)传统查询方式(未启用索引下推)
执行以下查询:
SELECT * FROM employees WHERE name = 'Alice' AND age > 30;
- 1

(2)启用索引下推
执行相同的查询:
SELECT * FROM employees WHERE name = 'Alice' AND age > 30;
- 1
59. Sql的执行过程
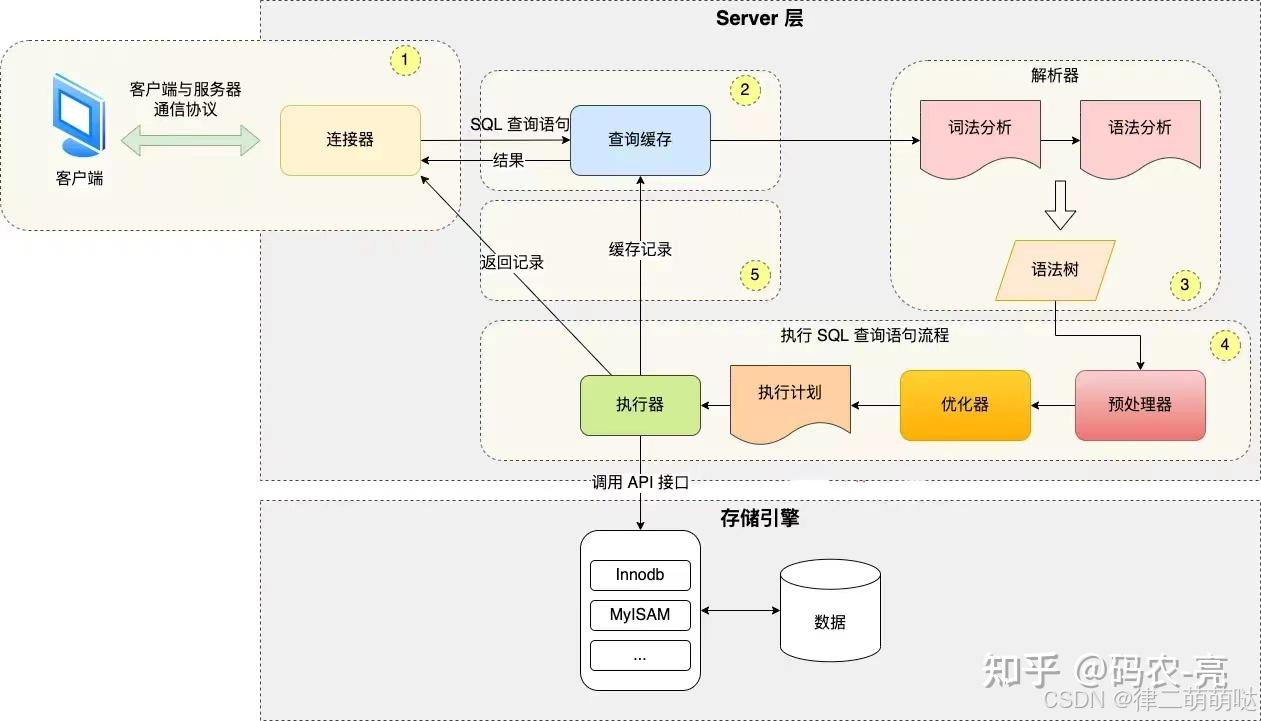
SQL的执行过程主要包括以下几个步骤:
1. 客户端请求:
客户端通过特定的通信协议与数据库服务器建立连接,并发送SQL查询请求。
- 1
2. 查询缓存:
服务器首先会检查查询缓存,看是否存在之前已经执行过且结果仍然有效的相同查询。
如果缓存命中,则直接返回缓存中的结果,避免重复执行查询,提高效率。
- 1
- 2
3. 语法分析:
如果查询缓存未命中,查询请求会进入解析器阶段。
解析器对SQL语句进行词法分析和语法分析,确保SQL语句的语法是正确的。
- 1
- 2
4. 预处理:
预处理器对语法分析后的查询语句进行进一步的预处理,确保查询语句在执行前是有效的,
例如检查表和列是否存在,以及用户是否有足够的权限执行该查询。
- 1
- 2
5. 查询优化:
优化器对预处理后的查询语句进行优化,生成最优的执行计划。
这一步骤涉及选择最佳的访问路径、连接顺序、索引使用等,以提高查询效率。
- 1
- 2
6. 执行计划生成与执行:
执行器根据优化器生成的执行计划,调用存储引擎接口执行SQL查询语句。
存储引擎负责实际的数据存取操作,如从磁盘读取数据、执行数据筛选和排序等。
- 1
- 2
7. 返回结果:
执行器将查询结果返回给客户端。
客户端接收到结果后,可以进行进一步的处理或展示。
- 1
- 2
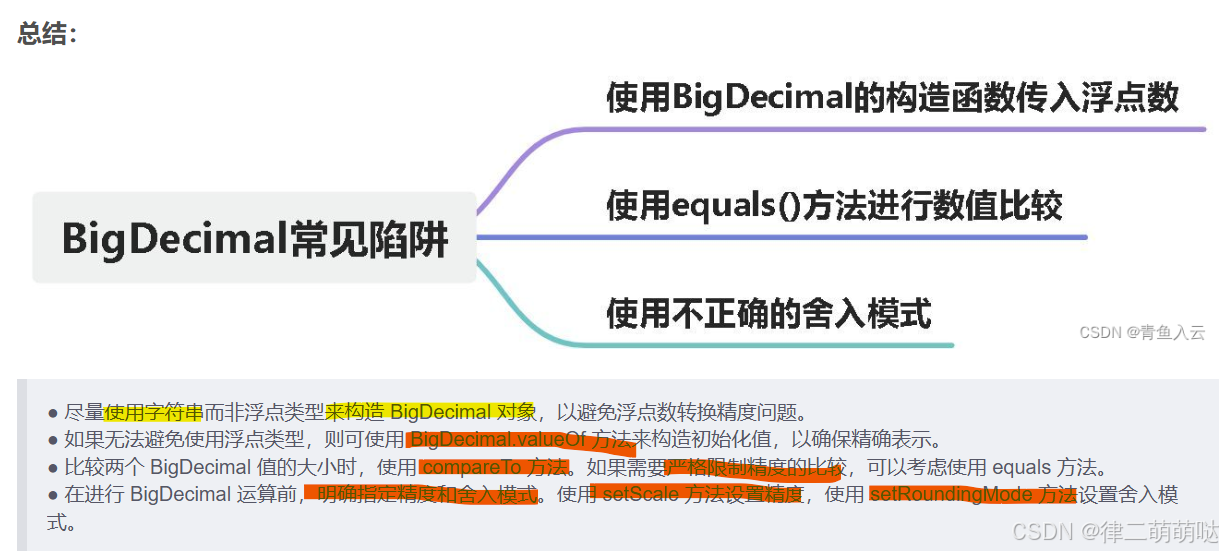
59. BigDecimal的常见陷阱
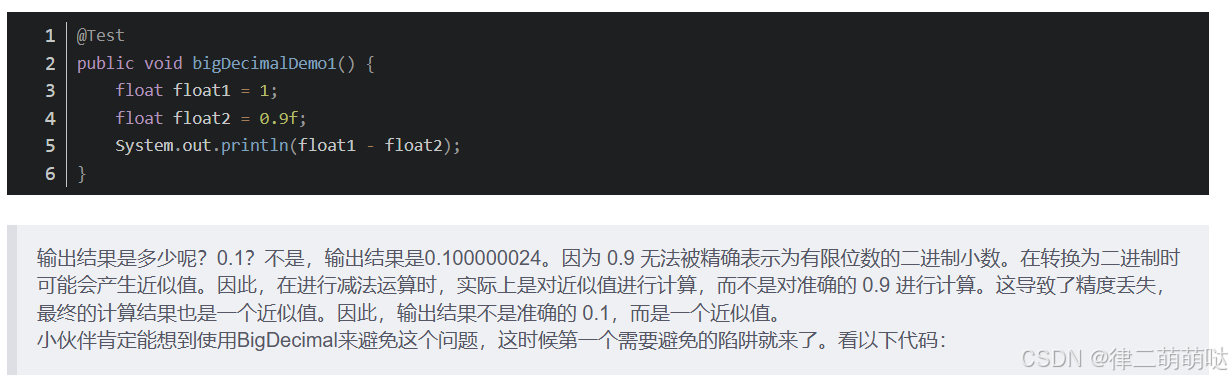
@Test
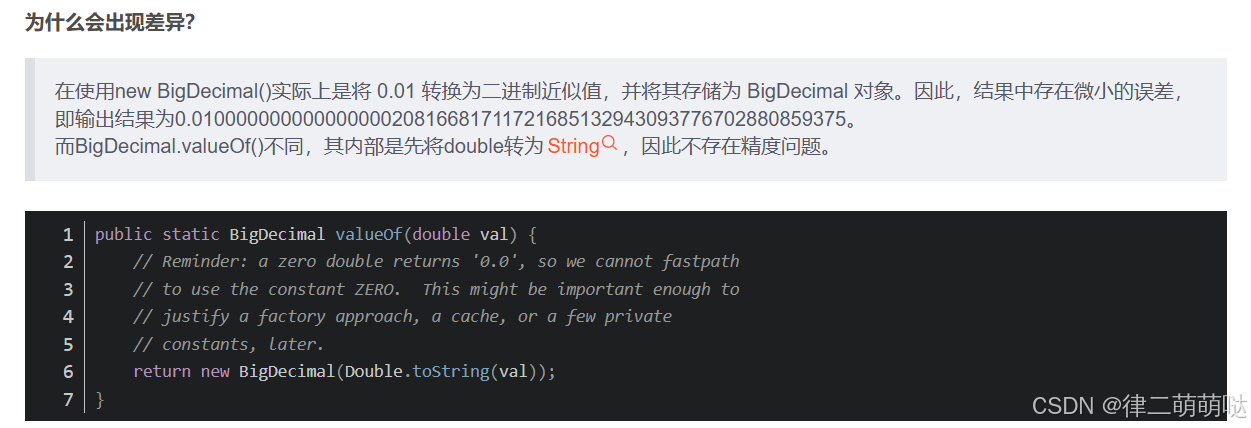
public void bigDecimalDemo2(){
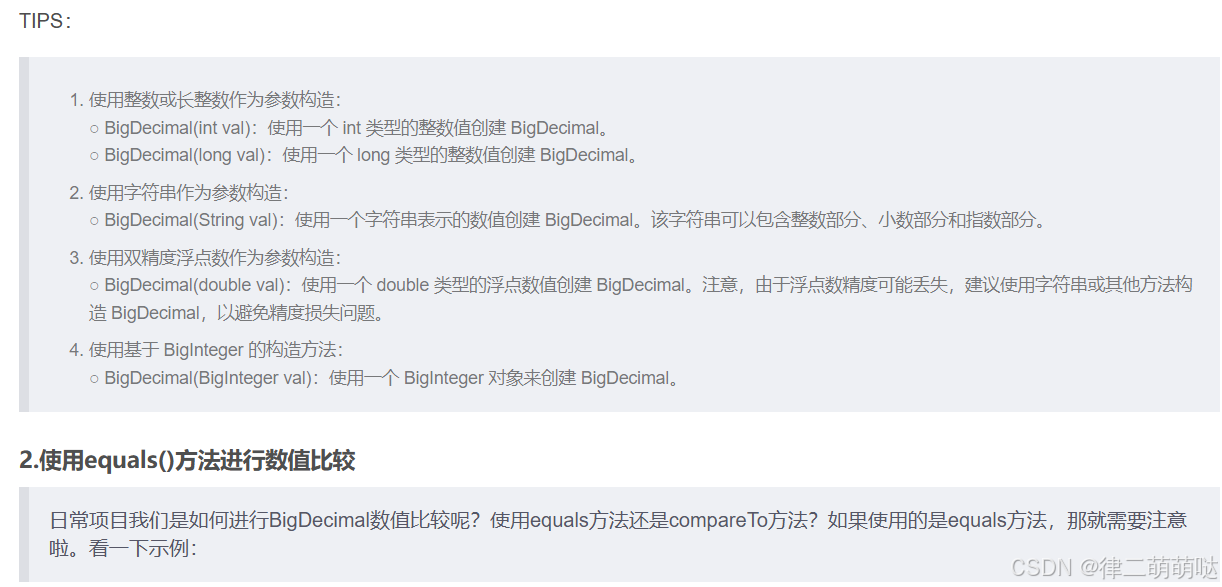
BigDecimal bigDecimal1 = new BigDecimal(0.01);
BigDecimal bigDecimal2 = BigDecimal.valueOf(0.01);
System.out.println("bigDecimal1 = " + bigDecimal1);
System.out.println("bigDecimal2 = " + bigDecimal2);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
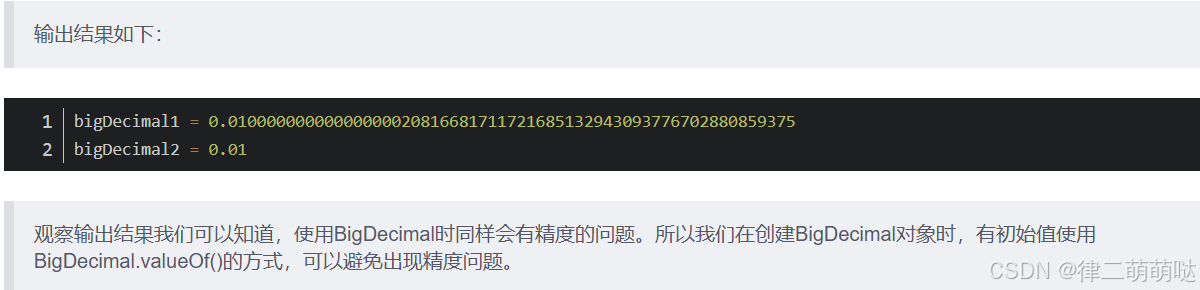
@Test
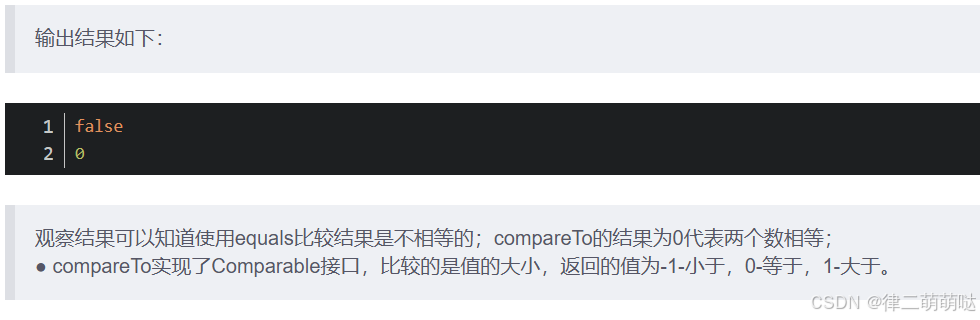
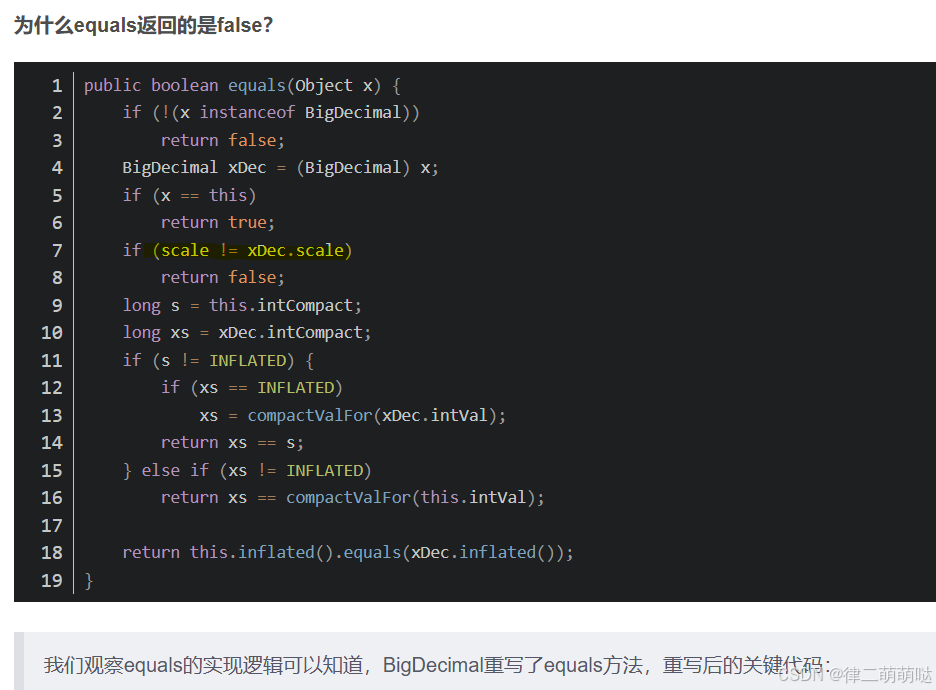
public void bigDecimalDemo3(){
BigDecimal bigDecimal1 = new BigDecimal("0.01");
BigDecimal bigDecimal2 = new BigDecimal("0.010");
System.out.println(bigDecimal1.equals(bigDecimal2));
System.out.println(bigDecimal1.compareTo(bigDecimal2));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
@Test
public void bigDecimalDemo4(){
BigDecimal bigDecimal1 = new BigDecimal("1.00");
BigDecimal bigDecimal2 = new BigDecimal("3.00");
BigDecimal bigDecimal3 = bigDecimal1.divide(bigDecimal2);
System.out.println(bigDecimal3);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
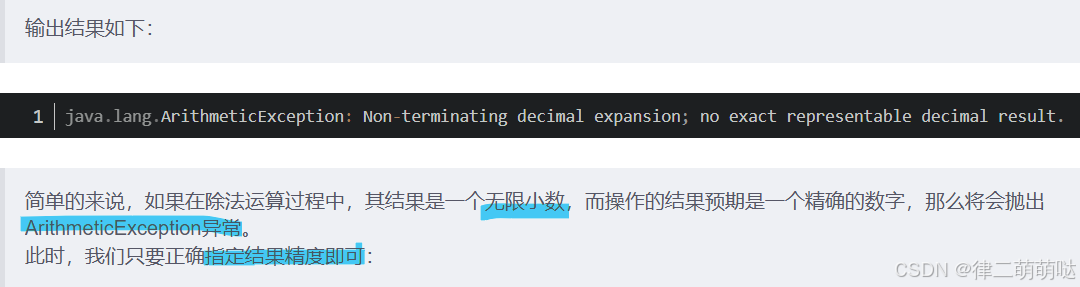
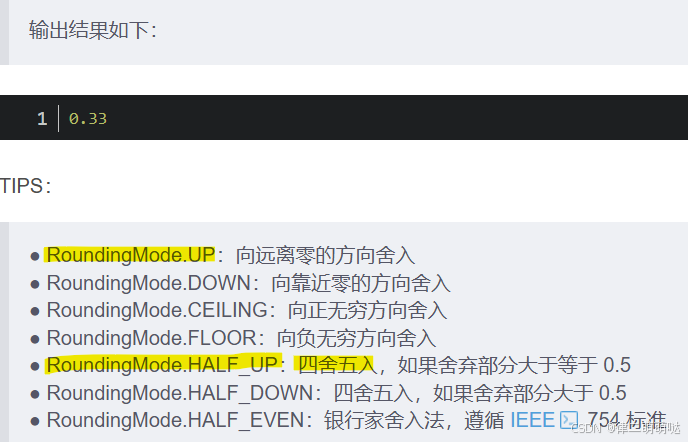
@Test
public void bigDecimalDemo4(){
BigDecimal bigDecimal1 = new BigDecimal("1.00");
BigDecimal bigDecimal2 = new BigDecimal("3.00");
BigDecimal bigDecimal3 = bigDecimal1.divide(bigDecimal2, 2, RoundingMode.HALF_UP);
System.out.println(bigDecimal3);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
60. 浅谈JVM的三色标记算法
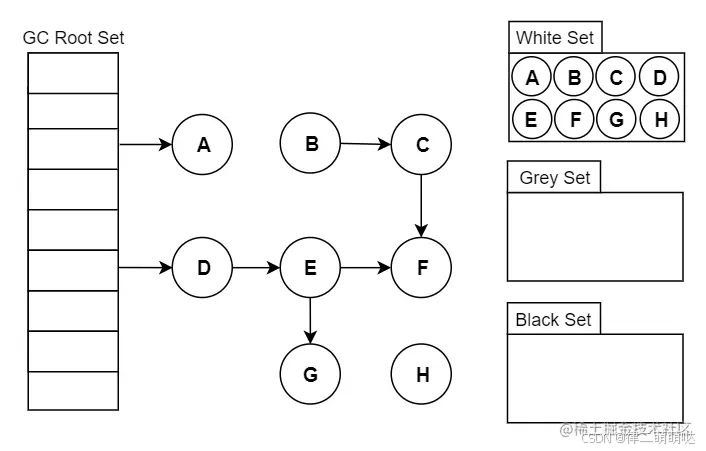
一、三色标记法:
三色标记是一种用于垃圾回收的算法,主要在JAVA堆内存回收中使用。
其核心思想是将对象的引用分为三种颜色:白色、黑色和灰色。
- 1
- 2
我们把gcRoots可达性分析便利对象过程中遇到的对象,按照“是否访问过”这个条件标记成以下三种颜色。
- 黑色:表示
对象已经被垃圾收集器访问过,且这个对象的所有引用都已经扫描过。黑色对象表示已经扫描过,它是安全存活的,如果有其它对象引用指向黑色对象,无需再扫描一遍。黑色对象不可能直接(不经过灰色对象)只想某个白色对象 - 灰色:表示
对象已经被垃圾收集器访问过,但这个对象还有至少存在一个引用没有被扫描过。 - 白色:表示
对象尚未被垃圾收集器访问过。显然在可达性分析阶段刚开始,所有的对象标记都是白色,但是如果在分析结束阶段,仍然是白色,表示不可达,即白色对象未引用。
标记过程:
- 在 GC 标记开始的时候,所有的对象均为白色;
- 在将所有的 GC Roots 直接引用的对象标记为灰色集合;
- 如果判断灰色集合中的对象不存在子引用,则将其放入黑色集合,若存在子引用对象,则将其所有的子引用对象存放到灰色集合,当前对象放入黑色集合。
- 按照此步骤 3 ,依此类推,直至灰色集合中所有的对象变黑后,本轮标记完成,并且在白色集合内的对象称为不可达对象,即垃圾对象。
- 标记结束后,为白色的对象为 GC Roots 不可达,可以进行垃圾回收。
误标
三色标记的过程中,标记线程和用户线程是并发执行的,那么就有可能在我们标记过程中,用户线程修改了引用关系,把原本应该回收的对象错误标记成了存活。(简单来说就是 GC 已经标黑的对象,在并发过程中用户线程引用链断掉,导致实际应该是垃圾的白色对象但却依旧是黑的,也就是浮动垃圾)。这时产生的垃圾怎么办呢?答案是本次不处理,留给下次垃圾回收处理。
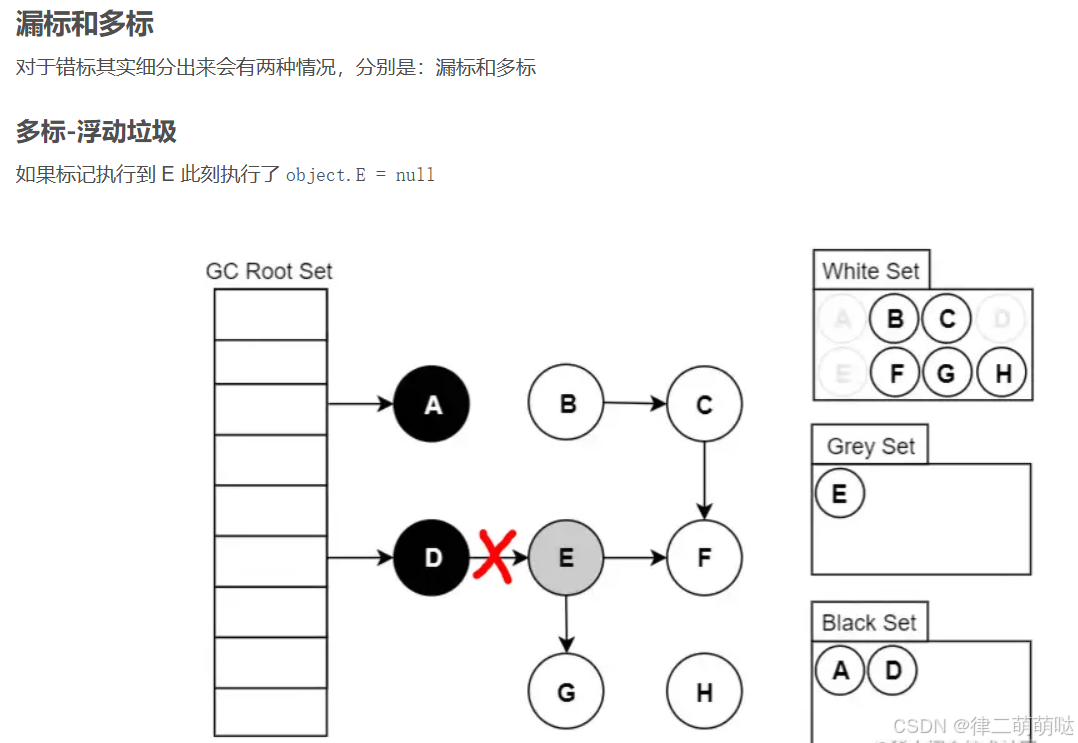
而误标问题,意思就是把本来应该存活的垃圾,标记为了死亡。这就会导致非常严重的错误。那么这类垃圾是怎么产生的呢?
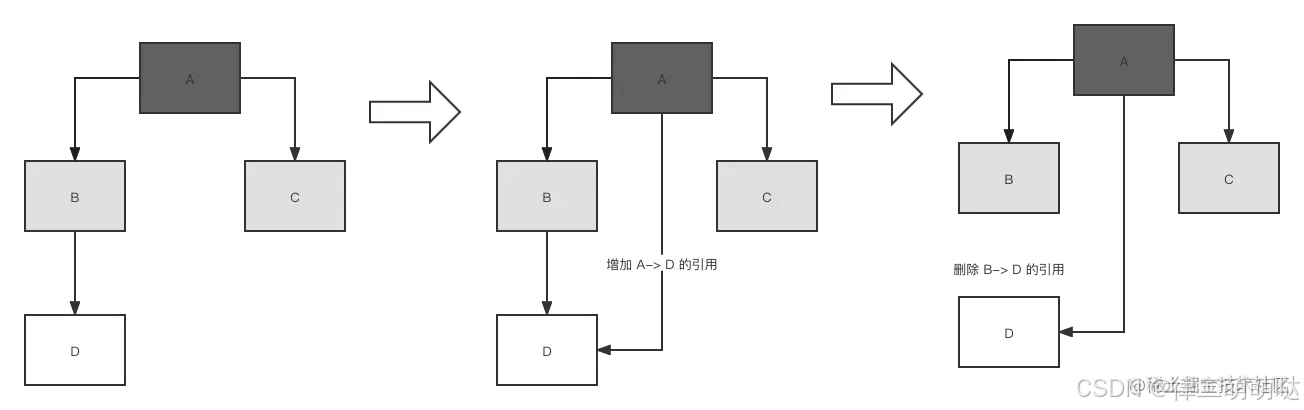
途中对象 A 被标记为了黑色,此时它所引用的两个对象 B,C 都在被标记的灰色阶段。此时用户线程把B->D之间的的引用关系删除,并且在A->D 之间建立引用。此时B对象依然未扫描结束,而A对象又已经被扫描过了,不会继续接着往下扫描了。因此 D对象就会被当做垃圾回收掉。
什么是误标?当下面两个条件同时满足,会产生误标:
- 赋值器插入了一条或者多条黑色对象到白色对象的引用
- 赋值器删除了全部从灰色对象到白色对象的直接引用或者间接引用

评论记录:
回复评论: