
【LLM】本地部署LLM大语言模型+可视化交互聊天,附常见本地部署硬件要求(以Ollama+OpenWebUI部署DeepSeekR1为例)
1、本地部署LLM(以Ollama为例)
本地部署LLM的框架
- 129k-Ollama 1
是一个提供简单命令行接口的工具,可以轻松下载和运行本地 AI 模型。 - 139k-Transformers 2
Hugging Face 的 Transformers 库支持多种预训练语言模型,并提供简单的 API 以在本地运行这些模型,适合进行微调和推理。 - 75k-llama.cpp, 3
CPU友好,一个高效的 C++ 实现,支持在各种设备上运行 LLaMA 模型,适合追求性能的用户。 - 39k-vllm, link
GPU优化,vLLM 是一个高效的、用于推理的框架,特别针对大型语言模型的并行推理进行优化。它利用了内存和计算资源的高效管理,提供了显著的性能提升。 - 69k-stable-diffusion,link
虽然主要用于图像生成,它也在开源领域取得了极大的关注,且可以灵活地与文本模型结合使用。
ollama是什么
- Ollama 是一个用于构建和运行本地 AI 模型的开源工具。
- 它可以帮助开发者和研究人员更方便地利用 AI 模型进行各种应用,如自然语言处理、图像识别等。
下载ollama
- 要安装Ollama,可以官方网站的下载页面:Ollama下载页面
- 支持的模型列表
- 参考安装 1
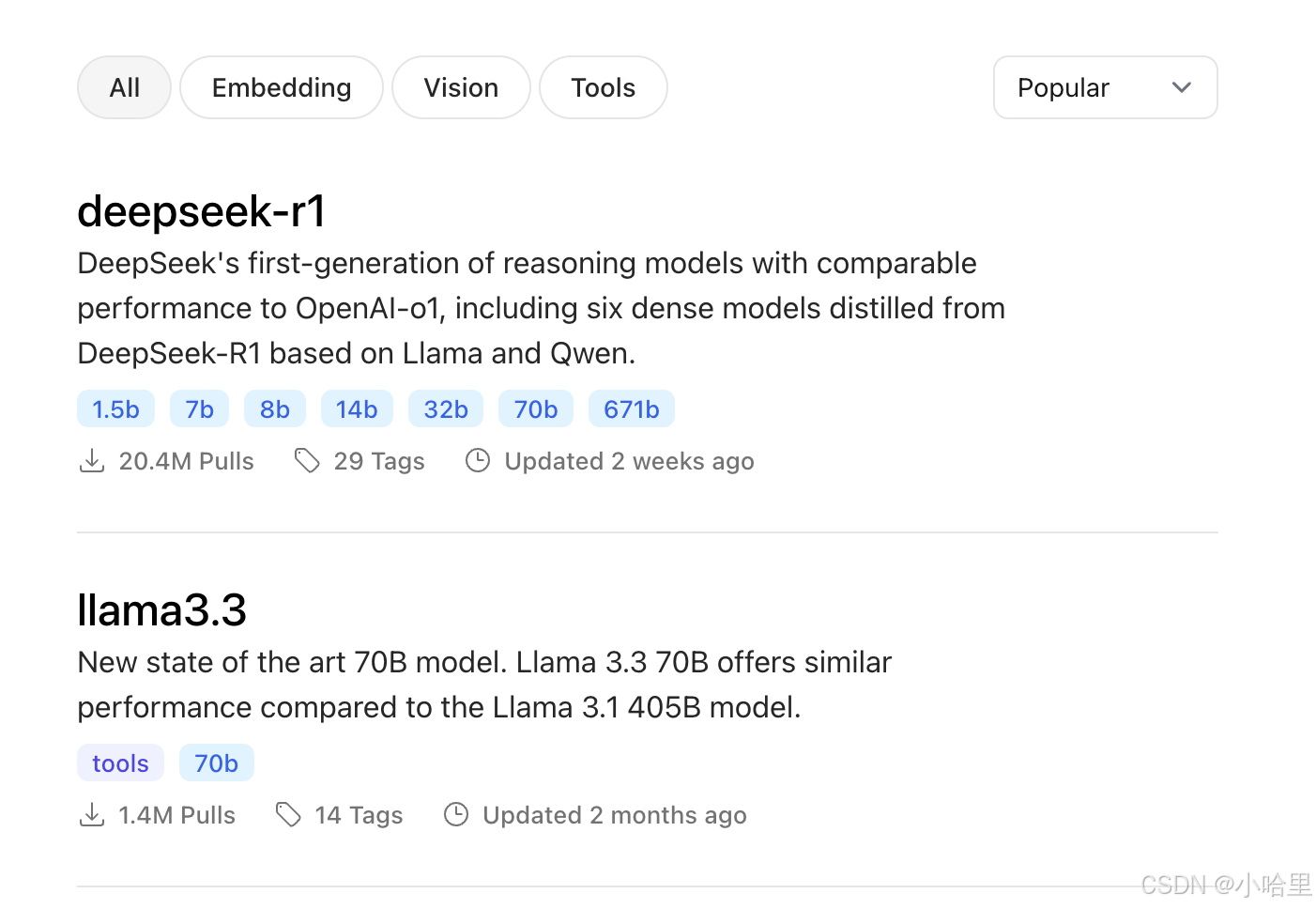
使用ollama
ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
例子,安装deepseek r1
# ollma --version
ollama version is 0.5.12
# ollama pull deepseek-r1:1.5b
pulling manifest
pulling aabd4debf0c8... 100% ▕██████████████████████████████████▏ 1.1 GB
pulling 369ca498f347... 100% ▕██████████████████████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕██████████████████████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕██████████████████████████████████▏ 148 B
pulling a85fe2a2e58e... 100% ▕██████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
# ollama run deepseek-r1:1.5b
# ollama run llama3.2:1b
# ollama list
NAME ID SIZE MODIFIED
llama3.2:1b baf6a787fdff 1.3 GB 3 minutes ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 2 hours ago
# systemctl stop ollama
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2、本地LLM交互界面(以OpenWebUI为例)
本地LLM交互界面项目
-
78k-OpenWebUI, link
OpenWebUI是一个开源Web用户界面,旨在让用户能够方便地与本地大语言模型(如GPT、LLaMA等)进行交互。用户可以通过简单的Web界面进行对话,支持多种模型。 -
82k-Nextchat(ChatGPT Next Web) , link
兼容本地LLM,轻量快速的 AI 助手。支持:Web | iOS | MacOS | Android | Linux | Windows。一键免费部署私人 ChatGPT 网页应用,支持 Claude, GPT4 & Gemini Pro 模型。 -
32k-ChatBox , link
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。
客户端安装参考 1,2:选择使用自己的api-key或本地模型,目前支持 -
72k-GPT4All, link
GPT4All 在日常台式机和笔记本电脑上私下运行大型语言模型 (LLM)。无需 API 调用或 GPU - 您只需下载应用程序并开始使用即可。 -
42k-text-generation-webui, link
适用于大型语言模型的 Gradio Web UI,支持多个推理后端。其目标是成为文本生成的stable-diffusion-webui 。 -
39k-AnythingLLM, link
全栈应用程序,可以将任何文档、资源(如网址链接、音频、视频)或内容片段转换为上下文,以便任何大语言模型(LLM)在聊天期间作为参考使用。
此应用程序允许您选择使用哪个LLM或向量数据库,同时支持多用户管理并设置不同权限。 -
150k-stable-diffusion-webui, link
支持一键安装的stable Diffusion网页用户界面。 -
jetbrain-idea/goland集成插件, link
设置-插件里安装后,配置Ollama API 默认调用端口号:11434
OpenWebUI是什么?
- 一个可扩展、功能丰富且用户友好的自托管WebUI,它支持完全离线操作,并兼容Ollama和OpenAI的API。
- 这为用户提供了一个可视化的界面,使得与大型语言模型的交互更加直观和便捷。
安装openwebUI
# 基于docker的安装
# 电脑上有Ollama
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
# Ollama在其他服务器上,OLLAMA_BASE_URL替换为地址
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
# 安装完成后,您可以通过http://localhost:3000 访问OpenWebUI
# 这个时候会发现【Select a model】可以选择我们刚刚下载好的模型
# 并且他还可以一次性加入多个模型,一起对话对比使用
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、本地部署硬件要求对应表
大模型名称中的数字含义
- 例如 1.5b、7b、8b、14b、32b、70b和671b等
- 这些数字代表模型的参数量(Parameters),单位为 「B」(Billion,十亿)。例如:
1.5B:15 亿参数
7B:70 亿参数
671B:6710 亿参数(接近万亿规模) - 参数量的意义:
模型能力:参数量越大,模型就有更强的理解和生成能力,但是需要更多计算资源。
硬件需求:参数越多,对内存(RAM)和显存(VRAM)的需求就越高。
运行速度:参数量大的模型,推理速度更慢,尤其是资源不足的时候。1
本地部署的硬件配置「最低」要求(按模型规模分类)
-
1.3B、1.5B 模型
适用场景:简单文本生成、问答、轻量级任务
CPU:4 核以上(需支持 AVX2 指令集)
内存(RAM):8GB 以上
GPU(可选):显存 ≥ 4GB(如 NVIDIA GTX 1650)
存储:需 3~5GB 硬盘空间(模型文件 + 依赖库)
说明:可在纯 CPU 环境下运行,但速度较慢(约 1~2 秒/词)。 -
6.7b、7B、8B 模型
适用场景:复杂文本生成、代码生成、多轮对话
CPU:8 核以上(推荐 Intel i7 或 AMD Ryzen 7)
内存(RAM):32GB 以上(纯 CPU 运行时需更高内存)
GPU(推荐):显存 ≥ 16GB(如 RTX 4090 或 Tesla T4)
存储:需 15~20GB 硬盘空间
优化建议:
使用 4-bit 量化可将显存需求降至 8GB。
使用 vLLM 或 HuggingFace TGI 框架提升推理速度。 -
32B、70B 模型
适用场景:企业级应用、高精度需求
CPU:无法纯 CPU 运行
内存(RAM):≥ 128GB(用于加载中间数据)
GPU:显存 ≥ 80GB(如 A100 80GB x2 或 H100)
存储:需 70~150GB 硬盘空间
关键点:
必须使用多卡并行(如 NVIDIA NVLink 互联)。
推荐 FP16 或 8-bit 量化以降低显存占用。
硬件选择对比表
| 模型规模 | CPU 需求 | 内存需求 | 显卡 型号 | 适用场景 |
|---|---|---|---|---|
| 1.5B | 纯 CPU | 4GB | RTX 3050 | 个人学习 |
| 7B | 7GB | 16GB | RTX 4090 | 个人学习 |
| 14B | 24GB | A5000 x2 | 264GB | 小型项目 |
| 32B | 48GB | A100 40GB | x2 | 专业应用 |
| 40GB | 80GB | x4 | RTX 7000 | 企业级服务 |
| 64GB+H100 | H100 | 640GB+H100 | 集群不可行 |
一些QA
- 能否用 Mac 电脑运行这些DeepSeek模型?
可以,但仅限于小模型(如 7B以下)。需使用 llama.cpp 的 Metal 后端,M1/M2 芯片需 16GB 以上统一内存。 - 官方仓库(如 HuggingFace Hub)、开源社区(如 modelscope)。
如果使用Ollama在本地部署,那么直接在Ollama中下载。 - 为什么实际显存占用比参数量大很多?
除了模型权重,还需存储中间计算结果(KV Cache),尤其在长文本生成时占用显著增加。 - 没有显存、显存的笔记本电脑,能在本地部署和运行DeepSeek吗?
可以。但是内存要求更高,文本生成速度慢。1,
更多部署教程
1 从零到一:本地部署Llama3大模型的简明指南,
2 本地部署 DeepSeek-R1-671B 满血版大模型教程
3 预算50-100万:4 * H100 80GB + NVLink,8 * A100 80GB + NVLink

 微信公众号
微信公众号

评论记录:
回复评论: