

前面讲的定位方式,都能够很方便的定位到网页元素。但是这些属性并非所有的网页元素都具备,可以这么说,绝大部分情况下都很难保证元素具备这些属性。
也就是很多时候需要使用其他的方式来定位,在 WebDriver 中提供了 Xpath 和 Css 选择器两种语言来辅助定位。这两种语言都很强大,能够定位网页上的任意元素。
在网络爬虫中,也通常会用借助 lxml 库使用 Xpath 进行网页的解析。
目录
-
-
基本定位语法
-
元素属性定位
-
层级属性结合定位
-
使用谓语定位
-
使用逻辑运算符
-
使用文本定位
-
使用部分匹配函数
-
什么是 Xpath?
-
绝对路径:
-
相对路径
-
验证 Xpath
-
什么是 Xpath?
Xpath 是一种用在 XML 文档中定位元素的语言,同样也支持 HTML 元素的解析。我们以百度中的HTML 代码为例。
- <form id="form" name="f" action="/s" class="fm">
- …
- <span class="bg s_ipt_wr quickdelete-wrap">
- <span class="soutu-btn"></span>
- <input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
- </span>
- <span class="bg s_btn_wr">
- <input type="submit" id="su" value="百度一下" class="bg s_btn">
- </span>
- …
- </form>
所谓 Xpath,是指 XML path language。path 就是路径,那么 Xpath 主要是通过路径来查找元素。
我们通过下面一张小图来了解一下 HTML 中的结构:

HTML 的结构就是树形结构,HTML 是根节点,所有的其他元素节点都是从根节点发出的。其他的元素都是这棵树上的节点
Node,每个节点还可能有属性和文本。
节点之间存在各种关系:
父节点(Parent):HTML 是 body 和 head 节点的父节点;
子节点(Child):head 和 body 是 HTML 的子节点;
兄弟节点(Sibling):拥有相同的父节点,head 和 body 就是兄弟节点。title 和 div 不是兄弟,因为他们不是同一个父节点。
祖先节点(Ancestor):body 是 form 的祖先节点,爷爷辈及以上?;
后代节点(Descendant):form 是 HTML 的后代节点,孙子辈及以下?。
Xpath 中的绝对路径从 HTML 根节点开始算,相对路径从任意节点开始。
通过开发者工具,我们可以拷贝到 Xpath 的绝对路径和相对路径代码:

但是由于拷贝出来的代码缺乏灵活性,也不全然准确。大部分情况下,都需要自己定义 Xpath 语句,因此 Xpath 语法还是有必要学习。
- 现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
- 如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
- 可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
- 分享他们的经验,还会分享很多直播讲座和技术沙龙
- 可以免费学习!划重点!开源的!!!
- qq群号:691998057【暗号:csdn999】

绝对路径:
Xpath 中最直观的定位策略就是绝对路径。
以百度中的输入框和按钮为例,通过拷贝出来的 full Xpath:
/html/body/div[2]/div/div/div/div/form/span/input这就是一个绝对路径我们可以看出,绝对路径是从根节点/html开始往下,一层层的表示出来直到需要的节点为止。
这明显不是理智的选项,因此了解以下即可,不用往心里去。
相对路径
除了绝对路径,Xpath 中更常用的方式是相对路径定位方法,以“//”开头。
相对路径可以从任意节点开始,一般我们会选取一个可以唯一定位到的元素开始写,可以增加查找的准确性。
相对路径可以通过以下的方式来定位元素:
基本定位语法
定位语法主要依赖于以下特殊符号:
| 表达式 | 说明 | 举例 |
|---|---|---|
/ | 从根节点开始选取 | /html/div/span |
// | 从任意节点开始选取 | //input |
. | 选取当前节点 | |
.. | 选取当前节点的父节点 | //input/… 会选取 input 的父节点 |
@ | 选取属性,或者根据属性选取 | //input[@data] 选取具备 data 属性的 input 元素 //@data 选取所有 data 属性 |
* | 通配符,表示任意节点或任意属性 |
元素属性定位
属性定位是通过 @ 符号指定需要使用的属性。
-
根据元素是否具备某个属性查找元素
//*[@data-recordid]选取包含data-recordid属性的所有节点。可以定位到以下元素:
<tr role="row" data-boundview="gridview-1029" data-recordid="B36BCA33" ></tr>-
根据属性是否等于某值查找元素
//span[@role='img']选取属性 role 的属性值为 img 的所有节点。可以定位到以下元素:
<span role="img" class="x-btn-icon-el" unselectable="on" style=""></span>注意,属性值必须要加引号,单双引号都可以。
层级属性结合定位
遇到某些元素无法精确定位的时候,可以查找其父级及其祖先节点,找到有确定的祖先节点后通过层级依次向下定位。
以下面的结构为例:
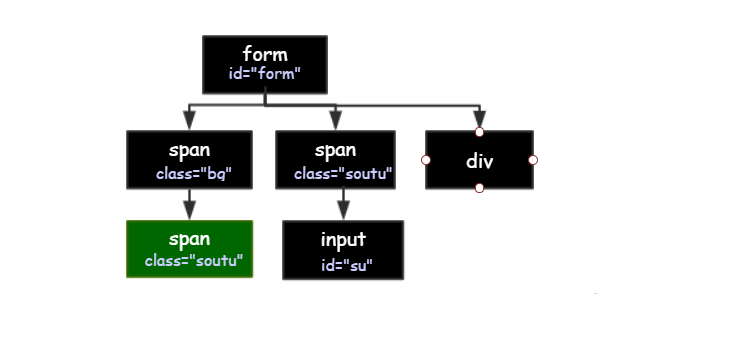
- <form action="search" id="form" method="post">
- <span class="bg">
- <span class="soutu">搜索</span>
- </span>
- <span class="soutu">
- <input type="text" name="key" id="su">
- </span>
- </form>
-
根据层级向下找,从 form 找到绿色的 span:
//form[@id="form"]/span/span-
查找某元素内部的所有元素,选取 form 元素内部的所有 span:
//form[@id="form"]//span第二个双斜杠,表示选取内部所有的 span,不管层级关系
-
使用星号找不特定的元素
//*[@id="form"]//*[@type="text"]选取 id 属性为 form 的任意属性内部,并且 type 属性为 text 的任意元素。这里会找到 input。
-
使用
..从下往上找,根据 input 查找其父节点 span:
//input[@name="key"]/..注意最后的两个点,找到 input 节点的上级节点,如果还要再往上再加
/..
-
找同级节点:
比如我们想通过第一个 span 标签去 找 div 标签。树形结构中,兄弟节点之间的关系是通过父节点建立起来的。所以可以先找到父节点,再通过父节点找同级节点。
//span[@class="bg"]/../div先通过
/..找到 span 的父节点,再通过父节点找到 div。
使用谓语定位
谓语是 Xpath 中用于描述元素位置。主要有数字下标、最后一个子元素last()、元素下标函数position()。
-
使用下标的方式,从 form 找到 input :
//form[@id="form"]/span[2]/inputXpath 中的下标从
1开始。
-
查找最后一个子元素,选取 form 下的最后一个 span:
//form[@id="form"]/span[last()]-
查找倒数第几个子元素,选取 form 下的倒数第一个 span:
//form[@id="form"]/span[last()-1]-
使用 position() 函数,选取 from 下第二个 span:
//form[@id="form"]/span[position()=2]-
使用 position() 函数,选取下标大于 2 的 span:
//form[@id="form"]/span[position()>2]使用逻辑运算符
如果元素的某个属性无法精确定位到这个元素,我们还可以用逻辑运算符 and 连接多个属性进行定位,以百度输入框为例。
-
使用
and:
//*[@name='wd' and @class='s_ipt']查找 name 属性为 wd 并且 class 属性为 s_ipt 的任意元素
-
使用
or:
//*[@name='wd' or @class='s_ipt']查找 name 属性为 wd 或者 class 属性为 s_ipt 的任意元素,取其中之一满足即可。
-
使用
|,同时查找多个路径,取或:
//form[@id="form"]//span | //form[@id="form"]//input选取 form 下所有的 span 和所有的 input。
使用文本定位
使用文本定位,是 Xpath 中的一大特色。在自动化测试中,为了让代码的可读性更高,可以使用文本的方式。
以下一个案例:

部分网页结构如下:
- <tr>
- <td valign="top">
- <input type="radio" name="payment" value="1" checked="" iscod="0">
- </td>
- <td valign="top">
- <strong>支付宝</strong>
- </td>
- </tr>
其实我们需要点的是前的单选框,但是单选框没有任何特殊的标识,不够灵活。我们可以通过后面的名称,如(支付宝、余额支付等)来找到其对应行的 radio,再去点击。
我们就需要先通过文本定位到“支付宝”,再去找其同一行(tr)的 input 节点。如果理不清楚,我们可以先画一个结构图:

红色箭头表示查找路径,先定位到“支付宝”所在的 strong,再定位 td -> tr -> td - >input 。那么要定位“支付宝”文本,就需要用到 Xpath 中的函数 text() 或 string(),注意是函数,所以括号不能少。
text():当前元素节点包含的文本内容;
表达式//div[text()="文本"],能找到:<div>文本</div>
1
不能找到:
<div><span>文本</span></div>
1
string():当前元素节点内部所有节点元素的文本内容。表达式//div[string()="文本"]上述两种情况都能找到。
好,接着写上面的内容。先通过 //strong[text()="支付宝"]定位到“支付宝”所在的元素 strong,再找上级 td -> tr,再向下找:
//strong[text()="支付宝"]/../../td[1]/input也可以写为:
//td[string()="支付宝"]/../td[1]/input使用部分匹配函数
Xpath 中有提供了几个函数,用来进行部分匹配。
| 函数 | 说明 | 举例 |
|---|---|---|
| contains | 选取属性或者文本包含某些字符 | //div[contains(@id, ‘data’)] 选取 id 属性包含 data 的 div 元素 //div[contains(string(), ‘支付宝’)] 选取内部文本包含“支付宝”的 div 元素 |
| starts-with | 选取属性或者文本以某些字符开头 | //div[starts-with(@id, ‘data’)] 选取 id 属性以 data 开头的 div 元素 //div[starts-with(string(), ‘银联’)] 选取内部文本以“银联”开头的 div 元素 |
| ends-with | 选取属性或者文本以某些字符开头 | //div[ends-with(@id, ‘require’)] 选取 id 属性以 require 结尾的 div 元素 //div[ends-with(string(), ‘支付’)] 选取内部文本以“支付”结尾的 div 元素 |
验证 Xpath
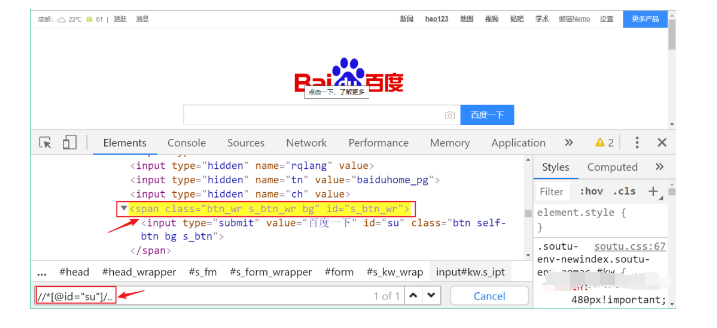
验证 xpath 有两种方法:
-
在开发者工具的 Elements 中按
Ctrl + F,在搜索框中输入 Xpath:
-
在开发者工具的 Console 中使用
$x()

下面是配套资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!

最后: 可以在公众号:程序员小濠 ! 免费领取一份216页软件测试工程师面试宝典文档资料。以及相对应的视频学习教程免费分享!,其中包括了有基础知识、Linux必备、Shell、互联网程序原理、Mysql数据库、抓包工具专题、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试、安全测试等。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!

 微信公众号
微信公众号

评论记录:
回复评论: