
本月初,微软发布最强 RAG知识库,开源方案 GraphRAG,项目上线即爆火,现在星标量已经达到 12.1 k。
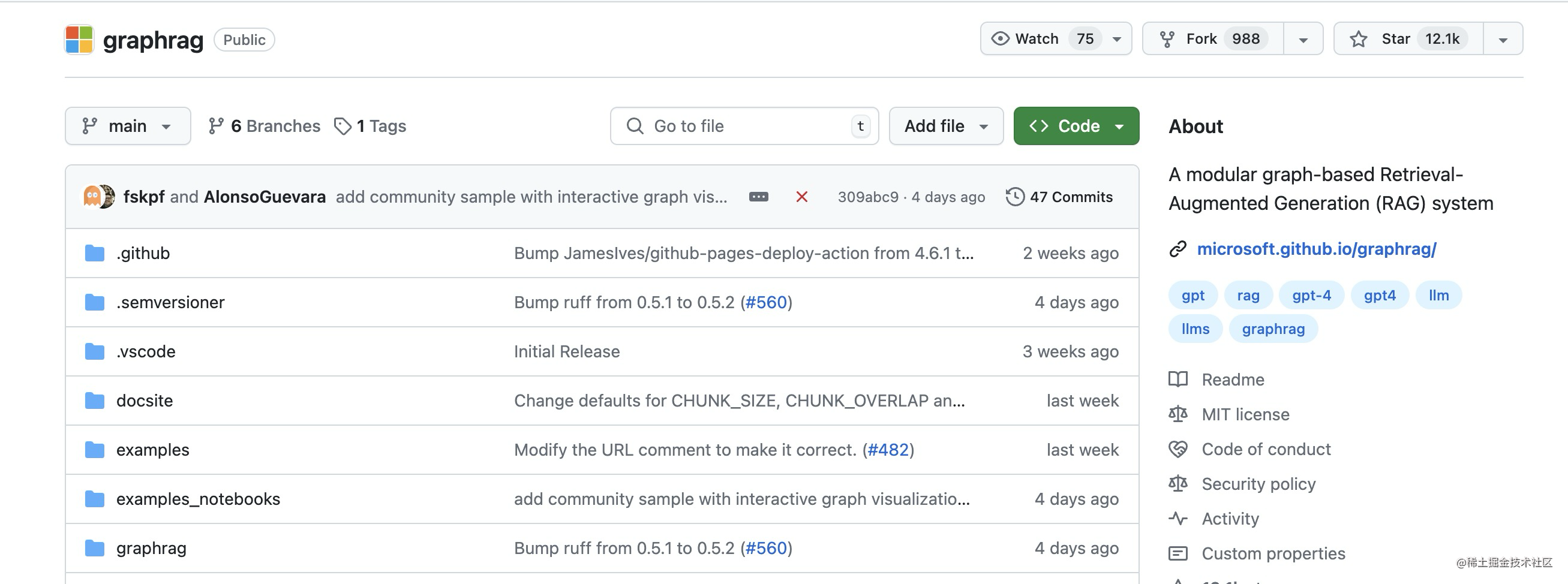
其意义在于,它能提升LLM的应答速度与品质,同时优化RAG能力的体验。它解决了基于向量的RAG在大规模文档环境下的理解与总结问题。具体实现步骤如下:
- 利用LLM在原始文档中抽取实体事件关系,构建知识图谱。
- 为关系密切的实体群预生成社区摘要。在提问时,各个社区摘要生成部分回应,最终汇总为完整答案。
本文是一篇偏实战的文档,RAG和LLM相关的原理在此就不多做赘述,接下来让我们尝试复现GraphRAG,揭开其神秘的面纱。
安装
坑:py版本目前3.11是最顺利的
我这里为了方便修改调试,直接在github上拉了原始代码下来编译,如果大家不想折腾,可以在microsoft.github.io/graphrag/po…找到源码以外的安装方式。
shell
代码解读
git clone https://github.com/microsoft/graphrag.git
- 1
- 2
- 3
- 4
整个项目是基于poetry构建的,所以在准备好graphrag的源码之后,我们需要安装python环境,这里通过作者的不断踩坑,目前py3.11版本是最顺利的。
准备一个venv虚拟环境,并激活
shell
代码解读
python3.11 -m venv venv # 创建一个pyenv环境
source venv/bin/active # 激活这个env环境
- 1
- 2
- 3
- 4
- 5
安装poetry
shell
代码解读
pip3 install poetry # 安装poetry
- 1
- 2
- 3
- 4
安装好poetry之后,我们执行以来的安装
shell
代码解读
poetry install
- 1
- 2
- 3
- 4
上述操作一切就绪之后,让我们开始初始化项目。
shell
代码解读
poetry run poe index --init --root .
- 1
- 2
- 3
- 4
命令执行完成之后,根目录中会生成如下目录
- input目录,存放需要索引的文件,默认配置只支持txt,当然也可以修改settings.yaml。
- output目录,存储生成的图、以及总结、日志等信息,如果生成过程中存在出错了,就可以在这里找到日志。
- prompts目录,存储默认的4个提示词文件:claim_extraction.txt、community_report.txt、entity_extraction.txt、summarize_descriptions.txt。
- cache目录,用于缓存提取实体和摘要等,能够减少LLM调用
- .env文件中只包含一个字幕GRAPHRAG_API_KEY,用于设置你的LLM API_KEY,当然你可以忽略,在settings.yaml直接改也是可以的,不过建议不要上生产环境。
- settings.yaml 文件较为复杂,配置项目也较多,运行本项目只需要修改两个。
修改配置文件settings.yaml
由于GraphRAG是基于OpenAI的库构建的,所以settings.yaml中基本都是基于OpenAI的字段定义的,为了解决这个问题我们需要使用能兼容OpenAI协议的大模型来平替。(PS:因为OpenAI太贵了,富哥也可以直接上GPT)
国内的话能够适配OpenAI SDK协议的有千问和月之暗面,大家可以自行选择。
这里我才用了千问的接口做实验,千问新账号免费100w token做实现绰绰有余。
在使用千问的时候有一些坑,需要关注下 1.top_p 必须设置0-1之间,要小于1,比如0.99这样。 2.max_tokens 必须设置为2000,超过会报错。 3.还有其他未知的错误,不要使用qwen-long,好像输入过长就会报错,让你走文件上传,建议使用qwen-turbo。 参考自:blog.csdn.net/Python_coco…
解决了llm之后,咱们还需要一个embed模型,这里我们使用qwen的7B模型,这里涉及到qwen环境的部署,就不多做描述,如有需要咱再来一篇文章讲一下如何在本地搭建qwen7B的模型。
这里贴上我改好的配置文件,各位可以自取,填上Token就可以启动。
yaml
代码解读
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: # 这里写一个API Key随意即可
type: openai_chat # or azure_openai_chat
model: gpt-4-turbo-preview
model_supports_json: true # recommended if this is available for your model.
max_tokens: 2000 # 千问限制
# request_timeout: 180.0
api_base: https://dashscope.aliyuncs.com/compatible-mode/v1
# api_version: 2024-02-15-preview
# organization:
# deployment_name:
tokens_per_minute: 30000 # set a leaky bucket throttle
requests_per_minute: 30 # set a leaky bucket throttle
max_retries: 3
max_retry_wait: 10
sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
concurrent_requests: 1 # the number of parallel inflight requests that may be made
# temperature: 0 # temperature for sampling
top_p: 0.5 # 千问限制
# n: 1 # Number of completions to generate
parallelization:
stagger: 0.3
# num_threads: 50 # the number of threads to use for parallel processing
async_mode: threaded # or asyncio
embeddings:
## parallelization: override the global parallelization settings for embeddings
async_mode: threaded # or asyncio
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # or azure_openai_embedding
model: text-embedding-ada-002
api_base: http://localhost:8080 # 本地的embed sever地址。
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
# batch_size: 16 # the number of documents to send in a single request
# batch_max_tokens: 8191 # the maximum number of tokens to send in a single request
# target: required # or optional

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
索引构建
解决完环境问题之后,咱们就开始了漫长的索引过程,启动索引的命令如下所示。
shell
代码解读
poetry run poe index --root .
- 1
- 2
- 3
- 4
这是一个漫长的过程,我索引的《全频段阻塞》全文大概2.9w字,花了30分钟左右。
下面是构建知识图谱的过程的截图。
1.提取文章中的实体关系,构建缓存。

2.基于实体关系构建实体实现联系。

使用
这里的查询方式有两种:
- 局部查询:通过将 AI 提取到知识图谱中的相关数据与原始文档的文本块相结合来生成答案,此方法适用于需要了解文档中提到的特定实体的问题。
- 全局查询:全局查询方法通过以 map-reduce 方式搜索所有 AI 生成的社区报告来生成答案。这是一种资源密集型方法,需要LLM支持的context window足够大,最好是32K的模型,但通常可以很好地回答需要了解整个数据集的问题。
局部查询
arduino
代码解读
poetry run poe query --root . --method local "塘沽前线发生了什么"
- 1
- 2
- 3
- 4
查询结果如下所示
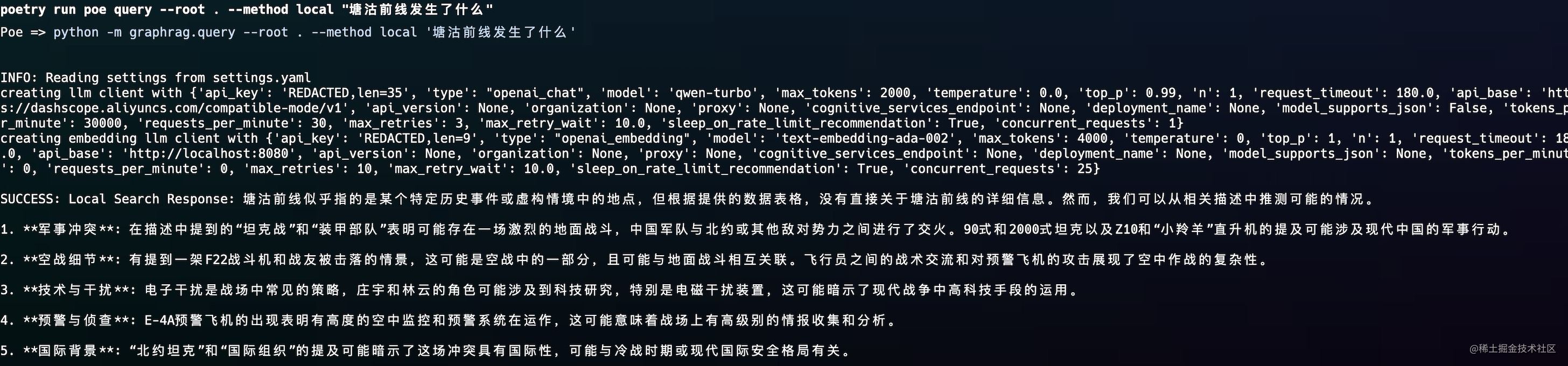
能大概检索出事件的前因后果,不过局限性是他是基于抽取的实体查询的,如果抽取的LLM能力不足的话,可能就会导致局部查询效果不佳的问题。
全局查询
arduino
代码解读
poetry run poe query --root . --method global "xxx"
- 1
- 2
- 3
- 4
这里俺的API扛不住,就没有测试,有能力的富哥可以自行尝试,命令俺贴上了。
总结
1.它是基于LLM构建的知识图谱,在构建过程中会消耗大量的Token,其中本次测试2.9w花费了大概13w token。
2.它支持2种搜索方法,局部和全局,全局效果最好,但是对模型的token处理能力有要求。
3.框架仅支持OpenAI SDK协议的的LLM,国内目前只有千问和月之暗面可以,如果精力充足的网友也可以基于OpenAI的协议魔改自己想要接入的大模型,其实就是封装一个网关。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。
二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程
LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
评论记录:
回复评论: