
文章信息:

发表于:2025 ICASSP
原文链接:https://arxiv.org/abs/2409.15936
源码:https://github.com/Jiaxin-Ye/DepMamba
Abstract
抑郁症是一种常见的心理障碍,影响着全球数百万人。尽管现有的多模态方法前景广阔,但它们依赖于对齐或聚合的多模态融合,存在两个显著局限性:(i)长时程建模效率低下,(ii)模态间融合与模态内处理之间的多模态融合效果欠佳。在本文中,我们提出了一种用于多模态抑郁症检测的视听渐进融合Mamba模型,称为DepMamba。DepMamba具有两个核心设计:分层上下文建模和渐进多模态融合。一方面,分层建模引入了卷积神经网络和Mamba,以提取长时程序列中的局部到全局特征。另一方面,渐进融合首先提出了一种多模态协作状态空间模型(SSM),用于提取每个模态的模态间和模态内信息,然后利用多模态增强的SSM进行模态融合。在两个大规模抑郁症数据集上的广泛实验结果表明,我们的DepMamba在性能上优于现有的最先进方法。
I. INTRODUCTION
抑郁症是最为普遍的心理障碍之一,其表现涵盖了一系列广泛的生理症状,如体重减轻和失眠,严重者甚至可能导致自杀或药物滥用[1]。抑郁症检测面临两大挑战:(1)患者人数持续增长,(2)人工诊断成本高昂。因此,开发一种高效的抑郁症检测系统迫在眉睫。
近年来,基于多模态的方法通过整合音频、视频和文本模态的信息,在抑郁症检测中展现出显著成效。这些方法主要聚焦于多模态融合,其可分为三类:特征级融合、决策级融合和模型级融合。
特征级融合通过连接多种模态来学习统一的表征以进行抑郁症检测[2]–[6]。例如,Cai等人[3]引入了一种线性组合技术,从每种模态的脑电信号中构建全局表征。
决策级融合则集成来自每种模态的决策输出以做出最终分类[7]–[12]。Zhang等人[9]提出了一种基于多智能体的决策级多模态融合方法。
模型级融合被认为是最为高效的方式,它学习模态间的相互关系[13]–[15]。例如,Fan等人[14]利用卷积神经网络(CNN)提取高级单模态特征,同时采用Transformer模型增强多模态特征。这些方法表明,多模态线索能够显著提升抑郁症检测的性能。
然而,现有方法仍面临两个显著局限性:(1)长时程建模效率低下,例如卷积神经网络(CNN)受限于有限的感受野,循环神经网络(RNN)存在梯度消失问题,而像Transformer这样的自注意力机制则面临计算效率低下的挑战;(2)多模态融合效果欠佳,现有技术往往侧重于学习模态共享特征或模态特定特征,但在保留模态特定信息的同时捕捉共享特征的能力不足。
为了解决这些局限性,我们提出了一种用于高效多模态抑郁症检测的视听渐进融合Mamba模型,称为DepMamba。具体而言,DepMamba具有两个核心设计:分层上下文建模和渐进多模态融合。首先,我们引入CNN和Mamba模块,从局部到全局尺度提取特征,丰富长时程序列中的上下文表征。其次,我们提出了一种多模态协作状态空间模型(SSM),通过共享状态转移矩阵来提取每种模态的模态间和模态内信息。随后,采用多模态增强的SSM处理拼接的视听特征,以提升模态融合效果。在两个大规模抑郁症数据集上的广泛实验结果表明,DepMamba在抑郁症检测的准确性和效率上均优于现有的最先进模型。
Contributions.本工作的贡献总结如下:首先,我们提出了DepMamba,这是一种新颖且高效的方法,结合了分层建模和渐进融合,标志着Mamba在抑郁症检测中的首次尝试。其次,我们开发了一种结合CNN和Mamba的分层建模方法,以更好地学习局部和全局上下文表征。第三,我们提出了一种渐进融合方法,其核心协作SSM在增强模态间融合的同时保留了模态内特征,为多模态融合提供了新的视角。最后,大量实验结果表明,与现有最先进的基线方法相比,所提出方法在性能和效率上均具有显著优势。
II. PROPOSED METHOD
A. Preliminary of Mamba
近年来,state space model(SSM)发展迅速[16]-[22],该模型源自经典控制理论,能够为长距离依赖建模提供线性可扩展性。SSM引入了一个隐状态
h
(
t
)
∈
R
N
\boldsymbol{h}(t)\in\mathbb{R}^N
h(t)∈RN,将输入
x
(
t
)
∈
R
L
\boldsymbol{x}(t)\in\mathbb{R}^L
x(t)∈RL映射到输出
y
(
t
)
∈
R
L
\boldsymbol{y}(t)\in\mathbb{R}^L
y(t)∈RL,其中
N
N
N和
L
L
L分别表示隐状态的数量和序列长度。连续SSM系统可以表述为:
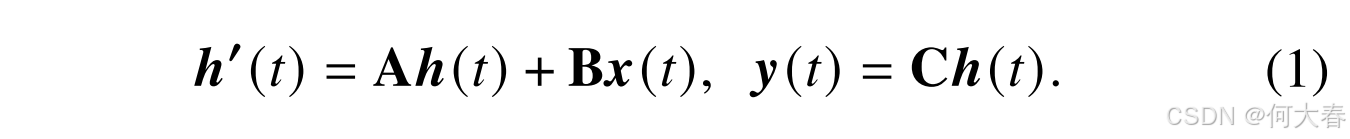
其中,状态矩阵 A ∈ R N × N \mathbf{A}\in\mathbb{R}^{N\times N} A∈RN×N,输入/输出投影矩阵 B ∈ R N × L \mathbf{B}\in\mathbb{R}^{N\times L} B∈RN×L(其中 L L L代表输入向量的维度), C ∈ R M × N \mathbf{C}\in\mathbb{R}^{M\times N} C∈RM×N(其中 M M M代表输出向量的维度)。Mamba[23]方法进一步使用时间尺度参数 Δ \Delta Δ来将连续参数 A \mathbf{A} A和 B \mathbf{B} B离散化为 A ‾ \overline{\mathbf{A}} A和 B ‾ \overline{\mathbf{B}} B。在默认情况下,该方法采用零阶保持(ZOH)原理进行离散化。离散化的状态空间方程可以表示为: A ‾ = exp ( Δ A ) \overline{\mathbf{A}} = \exp(\Delta\mathbf{A}) A=exp(ΔA)
以及一个近似的
B
‾
\overline{\mathbf{B}}
B,在离散化后,原连续系统的状态空间方程(假设为方程(1))可以转化为具有步长
Δ
\Delta
Δ的离散版本,该版本可以重写为递归形式:
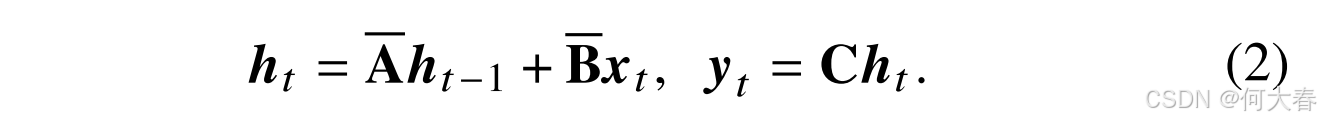
最终,方程(2)可以等价地转化为卷积形式: K ‾ = ( C B ‾ , … , C A ‾ − L − 1 B ‾ ) \mathbf{\overline {K}} = ( \mathbf{C} \mathbf{\overline {B}} , \ldots , \mathbf{C} \mathbf{\overline {A}} ^{- \mathbf{L} - \mathbf{1} }\mathbf{\overline {B}} ) K=(CB,…,CA−L−1B), y = x ⊛ K ‾ y= \boldsymbol{x}\circledast \mathbf{\overline {K}} y=x⊛K,其中 ⊛ \circledast ⊛ 表示卷积运算,全局卷积核 K ‾ ∈ R L \mathbf{\overline{K}}\in\mathbb{R}^L K∈RL。Mamba 通过其数据依赖机制和高效性极大地推动了深度学习的发展。在本文中,我们引入双向 Mamba(Bi-Mamba)[24]作为基线,它能够全面地建模长距离上下文。
B. Overview of DepMamba
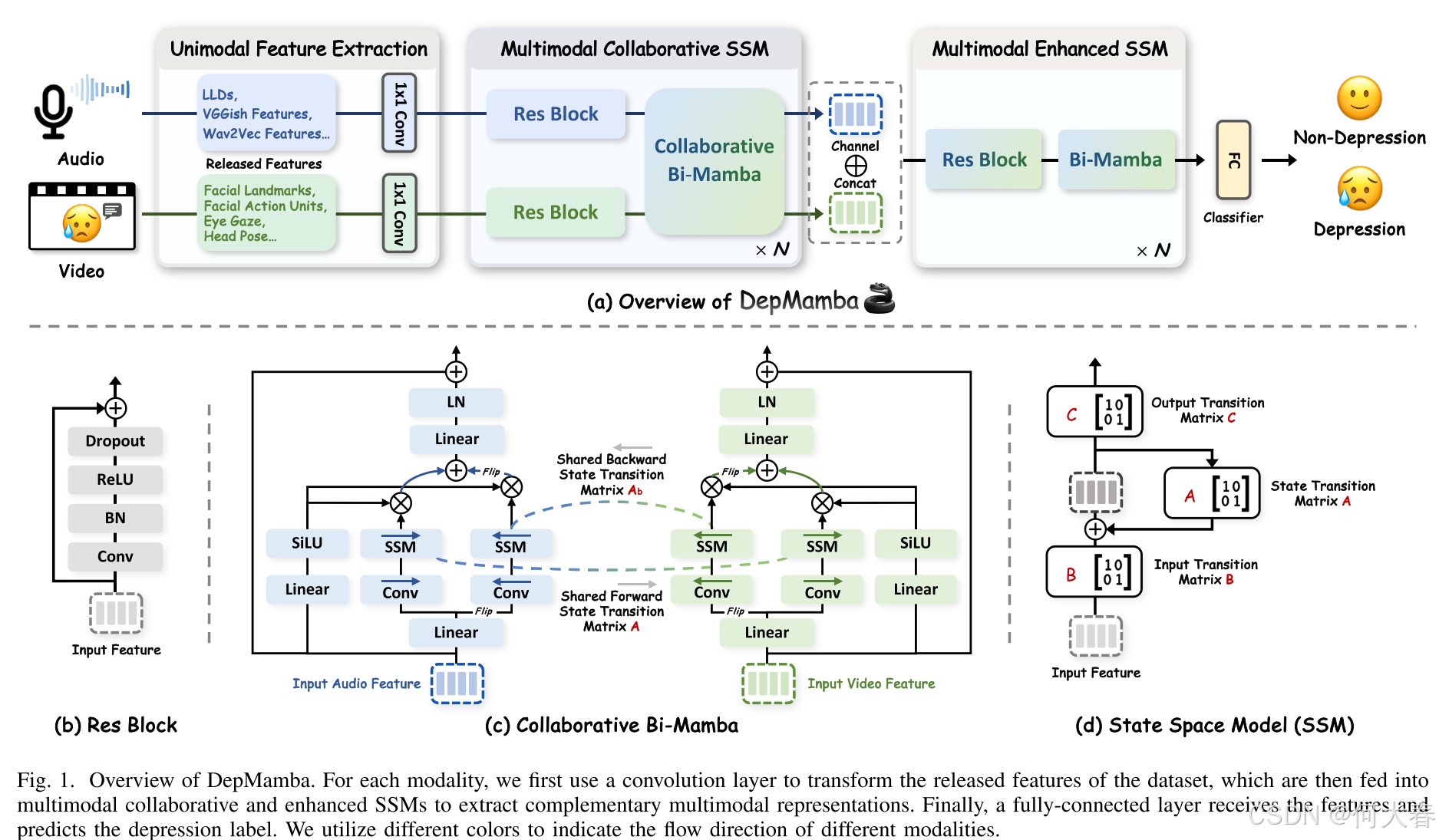
如图1(a)所示,所提出的DepMamba实现了层次化上下文建模和渐进式多模态融合,包含三个关键组件。(i) 单模态特征提取首先利用每个模态的已发布特征,因为现有的抑郁数据集[13]、[25]通常出于隐私考虑而不包含原始信号。然后,通过一维卷积将这些已发布特征分别转换到相同的维度空间。(ii) 多模态协作SSM(CoSSM)旨在建模层次化上下文信息,并聚合模态特定和模态共享的表示。每个CoSSM层包含两个残差块(Res Blocks)[26]和一个协作Bi-Mamba。(iii) 多模态增强SSM(EnSSM)首先连接音频和视觉特征,同时在每层使用ResBlock和Bi-Mamba增强多模态凝聚力的同时建模层次化信息。最后,采用一个线性层进行抑郁检测。我们将在以下各节中介绍每个部分。
C. Hierarchical Contextual Modeling
对于图1中的CoSSM和EnSSM,我们提议利用卷积神经网络(CNN)和双向Mamba(Bi-Mamba)实现从局部到全局尺度的层次化上下文建模,有效捕获长序列的音视频内容。具体而言,带有小卷积核的残差块擅长捕捉局部时序信息。而Bi-Mamba则结合了两个双向SSM,用于数据依赖的全局上下文建模,该模型构建了一个具有选择性注意力机制的1x1卷积-1x1卷积-全连接(FC)上下文的双向核心记忆。随后,这些局部和全局特征协同作用,丰富了上下文表示。这一过程有效地提取了长序列中固有的互补特征,从而提升了整体性能。
D. Progressive Multimodal Fusion
基于第二节C部分的模态无关上下文建模,我们进一步引入了两阶段渐进式多模态融合。
在第一阶段(即CoSSM),为了提取音视频模态之间的互补信息,我们提出了协作双向Mamba(Bi-Mamba)来促进模态间的交互。具体来说,前向SSM和后向SSM分别由状态转移矩阵 A ‾ \overline{\mathbf{A}} A、 B ‾ \overline{\mathbf{B}} B、 C \mathbf{C} C以及后向矩阵 A ‾ b \overline{\mathbf{A}}_\mathbf{b} Ab、 B ‾ b \overline{\mathbf{B}}_\mathbf{b} Bb、 C b \mathbf{C}_\mathbf{b} Cb构成)。状态转移矩阵 A ‾ \overline{\mathbf{A}} A和 A ‾ b \overline{\mathbf{A}}_\mathbf{b} Ab对系统影响最大,因为它们控制着当前隐藏状态的演变,而 B ‾ \overline{\mathbf{B}} B、 B ‾ b \overline{\mathbf{B}}_\mathrm{b} Bb以及 C \mathbf{C} C、 C b \mathbf{C}_\mathrm{b} Cb则主要影响输入和输出状态。因此,如图1( c)所示,我们提出跨模态共享双向状态转移矩阵 A \mathbf{A} A和 A b \mathbf{A}_\mathrm{b} Ab,以学习模态间共享的上下文信息。相比之下,不同模态的 B ‾ \mathbf{\overline{B}} B、 B ‾ b \mathbf{\overline{B}}_\mathrm{b} Bb以及 C \mathbf{C} C、 C b \mathbf{C}_\mathrm{b} Cb保持独立,以捕获模态特定的信息。前向协作SSM可以表述为:

其中,
x
t
a
\boldsymbol{x}_t^\mathrm{a}
xta、
x
t
v
\boldsymbol{x}_t^\mathrm{v}
xtv、
y
t
a
\boldsymbol{y}_t^\mathrm{a}
yta、
y
t
v
\boldsymbol{y}_t^\mathrm{v}
ytv以及
h
t
a
\boldsymbol{h}_t^\mathrm{a}
hta、
h
t
v
\boldsymbol{h}_t^\mathrm{v}
htv分别表示音频和视觉的输入、输出和隐藏特征。A是共享的前向状态转移矩阵,
B
a
\mathbf{B}^\mathrm{a}
Ba、
B
v
\mathbf{B}^\mathrm{v}
Bv是两种模态的输入矩阵,而
C
a
\mathbf{C}^\mathrm{a}
Ca、
C
v
\mathbf{C}^\mathrm{v}
Cv是输出矩阵。在不引入额外参数的情况下,基于控制系统理论的协作SSM(CoSSM)明确地建模了模态间共享和模态内特定信息,以实现互补的多模态表示学习。
此外,在第二阶段(即EnSSM),我们首先连接来自CoSSM的音频和视觉输出特征,并利用残差块(Res-Block)和双向Mamba(Bi-Mamba)通过层次化上下文建模来增强多模态的聚合性。通过采用两阶段流程,我们全面整合了模态内和模态间的信息,从而促进了更有效的多模态融合。最后,我们仅使用一个全连接层来进行抑郁分类。
III. EXPERIMENTS
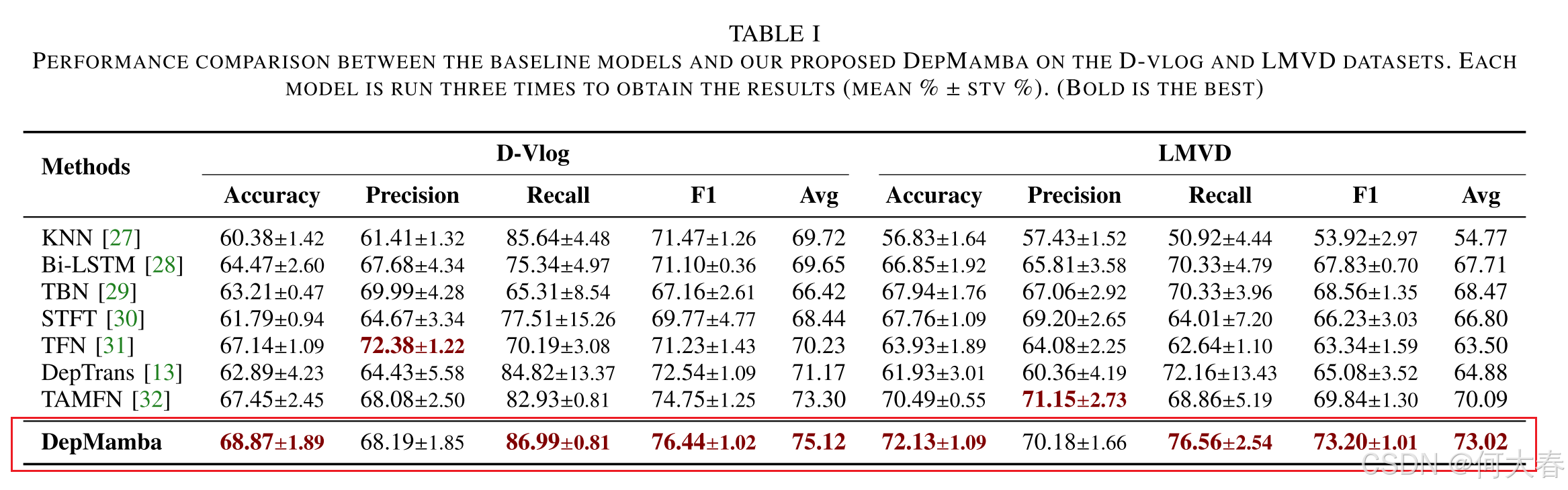
IV. CONCLUSION
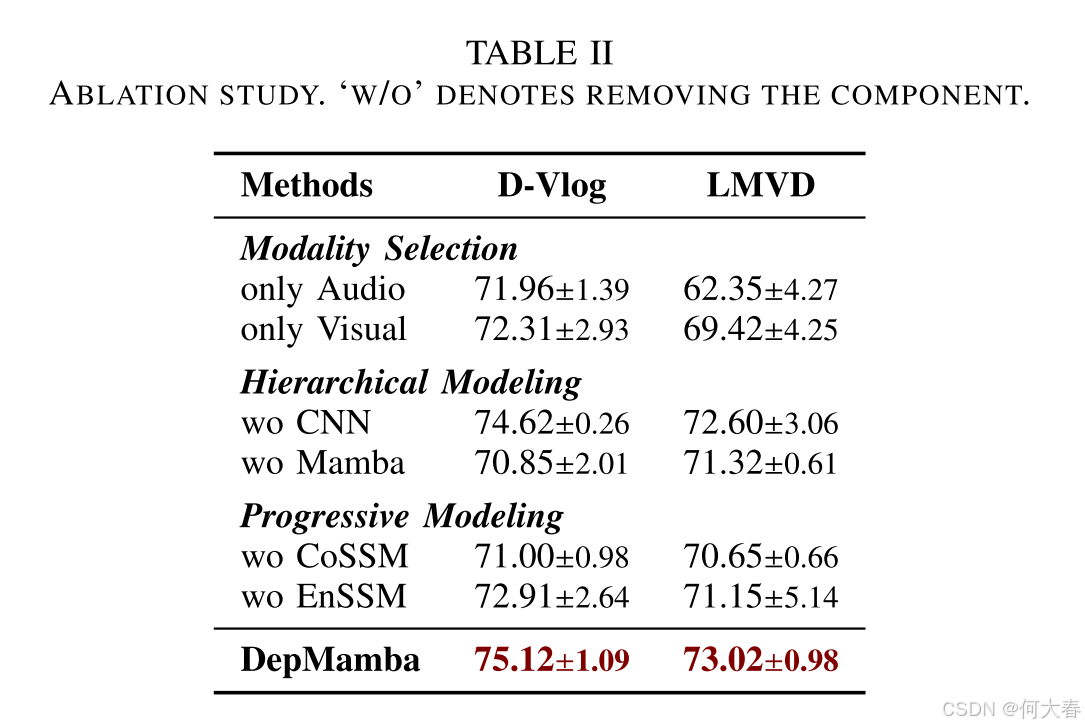
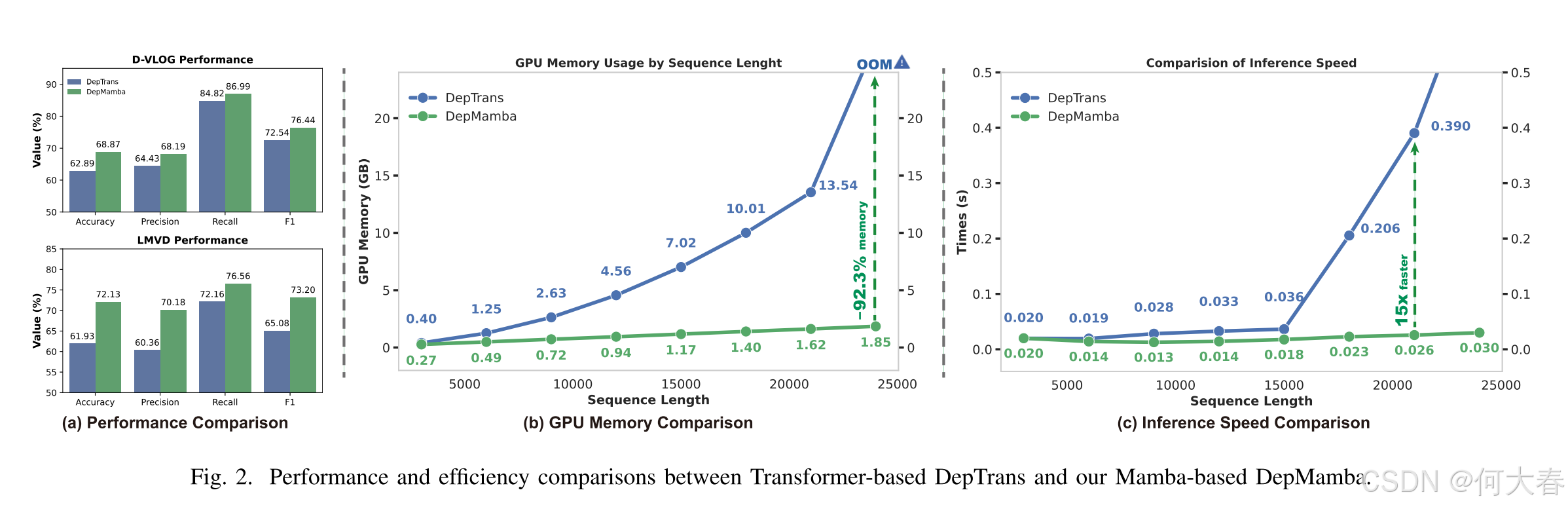
我们提出了 DepMamba,这是首个基于 Mamba 的多模态抑郁检测方法,旨在解决长程时间建模效率低下和多模态融合效果欠佳的问题。DepMamba 通过分层建模和渐进融合学习高效的表征,为未来多模态融合研究奠定了基础。实验结果表明,DepMamba 在性能和效率上均表现出优越性,与基于 Transformer 的方法相比,计算量(FLOPs)更低且推理速度更快。此外,在抑郁检测任务中,我们发现多模态特征比单模态特征更为重要,全局时间建模比局部建模更具影响力。未来,我们将研究基于 Mamba 和 Transformer 的混合架构,以提升跨领域抑郁检测任务中的表征泛化能力。DepMamba 在内存占用上减少了 92.3%,推理速度提升了 15 倍。
评论记录:
回复评论: