
论文阅读-Nature:Detecting hallucinations in large language models using semantic entropy(使用语义熵来检测大模型中的幻觉)
- 作者:Sebastian Farquhar, Jannik Kossen , Lorenz Kuhn & Yarin Gal
- 单位: 牛津大学,计算机科学学院,OATML实验室
- 期刊: Nature
- 时间线: 2023年7月提交 → 2024年6月发表
概要
大型语言模型(LLM),如chatgpt1或gemini2,在近年来展现了令人印象深刻的推理和问答能力,引发了新一轮的科技热潮。但在实际使用的过程中,大模型有时会产生错误输出和未经证实的答案,这被学界和业界称为“幻觉”。这样的“幻觉”降低了大模型的可靠性,也阻碍了大模型在医疗、法律、新闻等许多专业领域的落地。
本文针对大模型“幻觉”问题中的一个子类 —— (“胡言乱语”)“虚构内容”(confabulations),即大模型毫无依据的 自己胡乱生成的 错误回答,提出了一种检测指标——语义熵。语义熵大的回答被本文认为是“虚构内容”的可能性大。
本文利用语义熵在多个数据集和模型上进行了“虚构内容”的检测,结果表明这样的检测有效的帮助大模型减轻了幻觉的发生
背景
关于幻觉的背景相信各位读者都已经熟知了,这里不在赘述
本文欲解决的问题
本文的目的是为了解决大预言模型的幻觉问题,但由于“幻觉”的定义是过于广泛的,且导致幻觉的原因是多种的,本文只关注“幻觉”的一个子集(一个种类)—— —— (“胡言乱语”)“虚构内容”(confabulations),即大模型毫无依据的 自己胡乱生成的 错误回答。
对于“虚构内容”(confabulations)的一个举例:
当大模型被问到一个医学问题“sotorasib(一种用于治疗非小细胞肺癌的抗癌药物)的目标是什么?”时,大模型会随机的出现下面两个回答:
- KRASG12“c”(正确)
- KRASG12“d”(不正确)→ 一个confabulations
但是笔者更建议读者将这样的现象认为是confabulations,更容易理解(
此外,作者强调还有以下的原因会导致出现和confabulations 类似的情况:
- LLM的训练数据错误
- LLM明知正确答案,但是为了追求“奖励”而故意撒谎
- LLM 推理能力不足或者系统失败
本文强调由于这些原因导致的大模型幻觉不属于confabulations ,也不在本文讨论的范围之内。
方法
对大模型的回答计算语义熵,让大模型不回答语义熵大的问题或者提醒用户这个问题不能很好的回答,以避免confabulations的出现。
语义熵:大模型回答的混乱程度
信息熵
为了理解语义熵,我们需要首先学习或者说信息熵的概念。信息熵由克劳德·香农提出,通常用符号 H H H表示。信息熵越高,表示系统的不确定性越大。
信息熵的公式为:
H ( X ) = − ∑ i = 1 n P ( x i ) log 2 P ( x i ) H(X)=-\sum_{i=1}^nP(x_i)\log_2P(x_i) H(X)=−i=1∑nP(xi)log2P(xi)
其中:
- ( X ) (X ) (X) 是一个离散随机变量,取值为 x 1 , x 2 , . . . , x n {x_1, x_2, ..., x_n } x1,x2,...,xn。
- P ( x i ) P(x_i) P(xi)是随机变量 X X X 取值为 x i x_i xi 的概率。
- l o g 2 log_2 log2 表示以 2 为底的对数。
具体例子:
假设我们有一个简单的天气系统,只有三种可能的天气:晴天、阴天和雨天。它们的概率分别是:
- 晴天: ( P ( 晴天 ) = 0.5 ) (P(晴天) = 0.5 ) (P(晴天)=0.5)
- 阴天: ( P ( 阴天 ) = 0.3 ) (P(阴天) = 0.3 ) (P(阴天)=0.3)
- 雨天: ( P ( 雨天 ) = 0.2 ) (P(雨天) = 0.2 ) (P(雨天)=0.2)
我们可以计算这个系统的信息熵:
H ( X ) = − ( 0.5 l o g 2 0.5 + 0.3 l o g 2 0.3 + 0.2 l o g 2 0.2 ) H(X) = - (0.5 log_2 0.5 + 0.3 log_2 0.3 + 0.2 log_2 0.2) H(X)=−(0.5log20.5+0.3log20.3+0.2log20.2)
计算每一项:
- 0.5 l o g 2 0.5 = 0.5 × ( − 1 ) = − 0.5 0.5 log_2 0.5 = 0.5 × (-1) = -0.5 0.5log20.5=0.5×(−1)=−0.5
- 0.3 l o g 2 0.3 ≈ 0.3 × ( − 1.737 ) ≈ − 0.521 0.3 log_2 0.3 ≈ 0.3 × (-1.737) ≈ -0.521 0.3log20.3≈0.3×(−1.737)≈−0.521
- 0.2 l o g 2 0.2 ≈ 0.2 × ( − 2.322 ) ≈ − 0.464 0.2 log_2 0.2 ≈ 0.2 × (-2.322) ≈ -0.464 0.2log20.2≈0.2×(−2.322)≈−0.464
将它们相加:
H ( X ) = − ( − 0.5 − 0.521 − 0.464 ) = 1.485 H(X) = -(-0.5 - 0.521 - 0.464) = 1.485 H(X)=−(−0.5−0.521−0.464)=1.485
因此,这个天气系统的信息熵约为 1.485 比特。这表示在这个系统中,每天的天气平均需要约 1.485 比特的信息量来描述。信息熵越高,表示天气的不确定性越大。
语义熵
一个语义熵的计算可以分为以下三个步骤:
-
生成回答:对于同一个上下文,多次采样LLM的回答(可以理解为用一个问题向LLM提问多次),并记录每个回答出现的概率(开源大模型应该能直接查看这个数据,像gpt4这种就只能通过多次提问,然后每个回答的概率是1/提问次数)
-
聚类:对所有回答进行聚类,有着相同语义的回答被视为一类。具体的判断条件见下述原文
我们根据同一聚类中的答案是否双向相互关联来确定答案。也就是说,如果句子A意味着句子B为真,反之亦然,那么我们认为它们属于同一类。如句子“法国的首都是巴黎”和“巴黎是法国的首都”
-
计算语义熵:将一类视为一个整体,借鉴信息熵的思想,按如下公式计算语义熵:
S E ( x ) = − Σ P ( C i ∣ x ) l o g P ( C i ∣ x ) SE(x)=-\Sigma P(C_i|x)logP(C_i|x) SE(x)=−ΣP(Ci∣x)logP(Ci∣x)
其中 x x x表示上下文, P ( C i ∣ x ) P(C_i|x) P(Ci∣x)表示在上下文 x x x的情况下 C i C_i Ci类别出现的概率,
具体例子:
a. 单个句子层次(字符较少):
下面我们根据文中的案例,对“Where is the Effier Tower”这个问题进行语义熵的计算
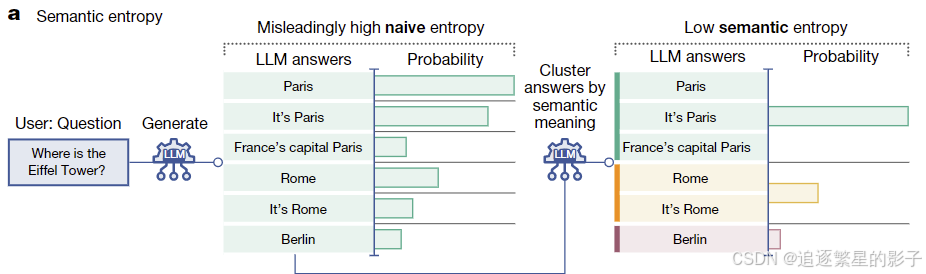
-
问题设置:
模型被问到"Where is the Eiffel Tower?"(埃菲尔铁塔在哪里?)
-
模型生成:
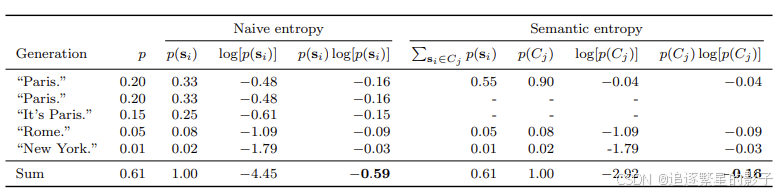
模型生成了5个回答,每个回答都有一个原始概率p和长度归一化的概率p(si)。
-
生成的回答及其概率:
- “Paris.” (出现两次,每次p=0.20, p(si)=0.33)
- “It’s Paris.” (p=0.15, p(si)=0.25)
- “Rome.” (p=0.05, p(si)=0.08)
- “New York.” (p=0.01, p(si)=0.02)
-
原始熵(Native entropy,即只要一个句子组成不同就认为是不同的句子(a是b,b是a被认为是不同的句子),这里主要是为了对比,凸显语义熵的好处)计算:
- 对每个生成序列,计算p(si) * log[p(si)]
- 将这些值相加,得到-0.59
-
语义熵(Semantic entropy)计算:
- 将语义等价的回答聚类:"Paris"和"It’s Paris"合并为一个类别
- 计算每个类别的总概率:Paris类别为0.55,Rome为0.05,New York为0.01,归一化之后为 0.90、0.08、0.02
- 对每个类别,计算p(Cj) * log[p(Cj)]
- 将这些值相加,得到-0.16
-
离散语义熵变体:
- 将每个生成视为均匀分布
- "Paris"类别权重为0.6(0.2+0.2+0.2),其他两个类别各为0.2
- 计算结果为0.41 = -0.6log(0.6) - 0.2log(0.2) - 0.2log(0.2)
-
重要说明:
- 原始概率p不总和为1,因为它们是每个实际采样输出的概率
- p(si)是通过将原始概率除以总和来归一化的,p(Ci)同理
- 语义熵比原始熵低,因为它考虑了语义等价性
- 离散语义熵变体提供了一种替代方法,特别是在没有准确概率信息的情况下(比如面临闭源大模型)
b.段落层次(字符较多)
对于大段文字,首先提取出多个事实片段,对每个片段,用LLM想出多个回答应该是这个片段的问题,再把每个问题向大模型提问,能得到关于这一个事实的很多个回答(提问方式并不一样),把这些回答和事实片段放在一起,聚类,看熵的情况(和a中逻辑一致),然后判断是否是confabulations
实验
前置知识
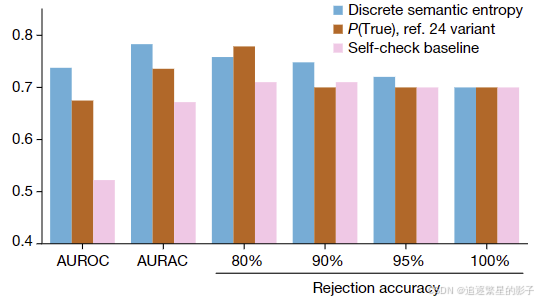
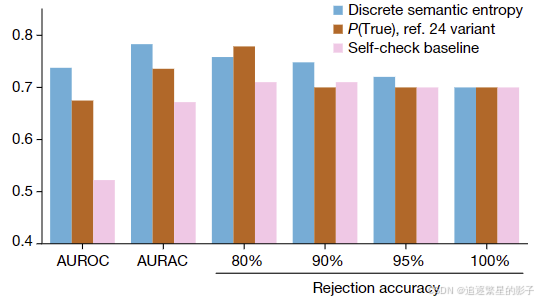
AUROC
Area Under the Receiver Operating Characteristic (AUROC) curve ,ROC曲线下面积,ROC曲线以真正例率为纵轴,假正例率为横轴作图。基础知识,详细见百度。该值越高,说明模型效果越好。
AURAC
the Area Under the ‘Rejection Accuracy’ curve,RAC曲线下面基,RAC曲线是本文自己提出的曲线,横轴为判定为正例的百分比(例如这个值为20%,那么语义熵最高的80%被认为为反例,也就是confabulations),纵轴为 正例的回答的正确率,该值越高,说明模型效果越好。
测试对象
- 模型:LLaMA 2 Chat、Falcon Instruct、Mistral Instruct → 句子层次的实验,GPT4 → 段落层次的实验
- 数据集:TriviaQA、SQuAD 1.1、BioASQ、NQ-Open 、SVAMP→ 句子层次的实验,FactualBio(一个人物传记数据集)→ 段落层次的数据集
对比方案
结果
句子层次(展示的为五个数据上的平均值)
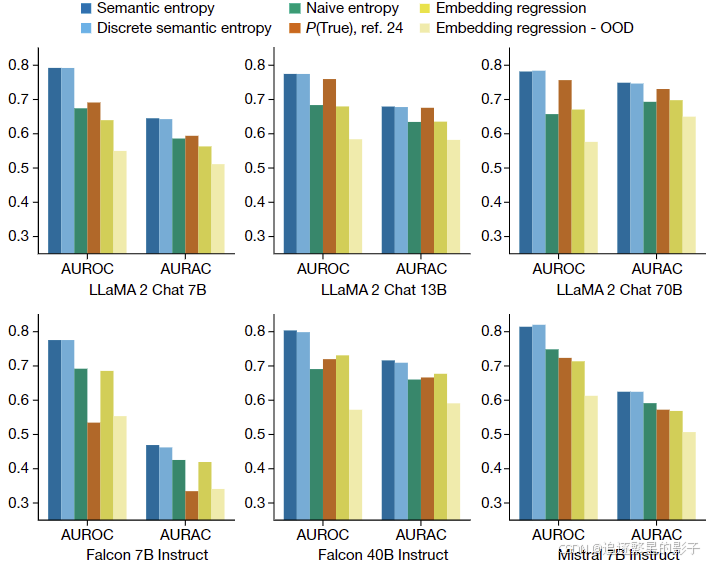
段落层次
意义
-
提出了一种不需要先验知识的幻觉检测方法-语义熵
即使模型的能力不断提高,因为人类无法可靠地监督的情况和案例会持续存在,怎么在没有先验知识的前提下回答问题或者判断问题是无法回答的,这对大模型的发展至关重要
-
使用经典的概率机器学习方法解决了问题,而不是走深度学习的路子
-
语义熵的成功,说明LLM能够知道自己不知道,“他们只是不知道 自己知道自己不知道的东西”, 而语义熵则搭建了这一桥梁
评论记录:
回复评论: