

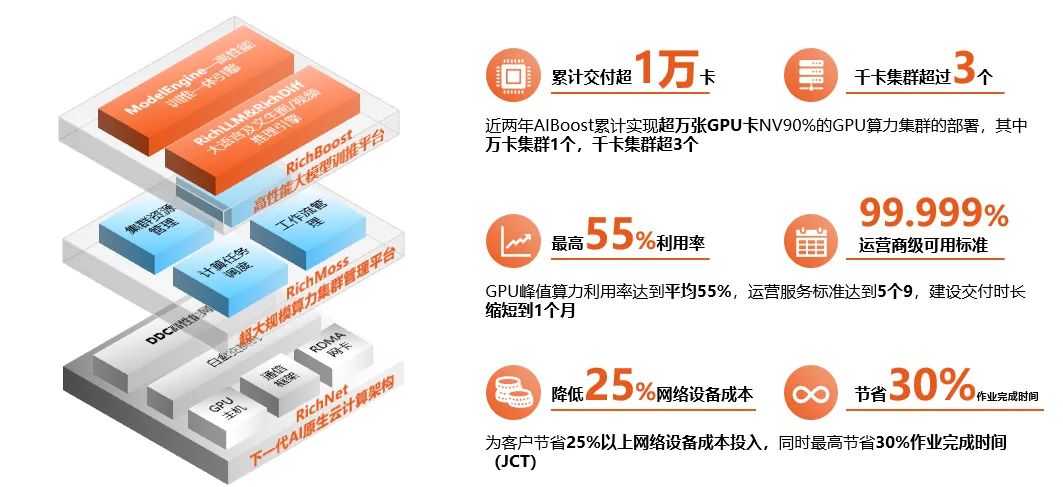
2024年10月11日,第12届中国移动全球合作伙伴大会在广州盛大开幕,彩讯股份AI原生云计算解决方案Rich AICloud在大会亮相,Rich AICloud致力于为大模型应用开发构建坚实的智算基础设施底座。
算力是大模型构建不可或缺的基石,算力直接关乎大模型训练的效率和成果。大模型的计算特性为:大数据、大计算,例如GPT4、Meta Llama3的训练都是基于几万卡GPU集群,然而当前国内智算集群的建设仍面临一定的困境:第一,算力可靠性几何式降低:一个任务在数十、数百台机器中运行,单台可靠性是99%,百台机器是99%^100=36.6%,GPU规模越大,则整体可靠性就越低;第二,系统优化配置复杂:构建稳定高效的大模型系统,需要对网络、框架、模型诸多参数进行调优;第三,工具少,生态弱:国外厂商封锁算力集群建设及优化技术,国内GPU厂商的软件生态尚在建设中,万卡集群建设仍面临一定的挑战。
如何控制算力成本,提升集群规模,高效管理集群,提升大模型训练推理速度,是各大企业及算力提供商面临的难题。
Rich AICloud
智算基础设施底座
针对当前算力的挑战,彩讯股份推出了AI原生(AI-Native)云计算解决方案,该方案是集合了下一代AI原生云计算网络架构、超大规模算力集群管理平台、高性能大模型训推平台的AI算力构建及大模型运营一体化解决方案,旨在帮助企业快速构建大规模算力集群、部署运营专属大模型,赋能智能化转型。
Rich AICloud分为三层:其底层是RichNet下一代AI原生云计算架构,中间层是可实现万卡集群管理的RichMoss超大规模算力集群管理平台,顶层是针对大语言模型/文生图/视频的RichBoost高性能大模型训推平台。通过将AICloud平台部署到 GPU算力集群硬件服务器上,可以低成本、高效率构建起高可用、高性能的 AI 算力集群。
RichNet
下一代AI原生云计算架构
AI大模型对网络性能需求是大带宽、高负载、零丢包的无损网络。随着技术的发展,现在数据中心内的高性能网络传输机制,已经从TCP/IP逐步切换到RDMA,即远程直接内存访问。RoCE(RDMA over Converged Ethernet),是一种能在以太网上进行RDMA的集群网络通信协议,它可以大大降低以太网通信的延迟,提高带宽的利用率。
RichNet的RoCE网络交换机,聚焦于下一代高性能网络,提供先进的RoCE网络整体解决方案,提供端到端RDMA计算通信互联系统,基于RoCE以太网络带宽利用率可达到IB网络90-96%,All-Reduce基准测试稳定性提升20%+,AI-to-AI基准测试吞吐量提升20%+。
RichNet具备多重领先优势,在千卡集群中,方案可为客户节省超过一千五百万元的成本开支;方案通用性高,支持快速交付与响应,传统IB交货周期需要数月,而RichNet RoCE交货周期仅需数周;通过自研系统与算法,保证了较高的稳定性(传输抖动程度)和高性能(链路利用率)。
RichMoss
超大规模算力集群管理平台
RichMoss超大规模算力集群管理平台,支持云原生、容器化的部署方式,支持异构GPU设备。通过计算抽象能力+高级调度功能,连接AI工作负载与底层计算资源,并通过高效、灵活的调度机制和策略,优化地运行各种AI负载,最大化资源利用。
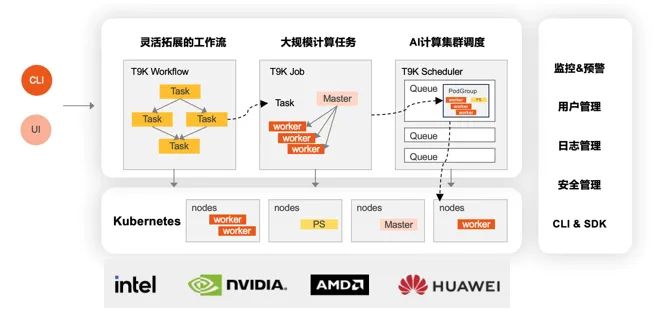
先进的 AI 计算集群调度器,提供运行大规模工作负载所需的高级调度功能,支持根据业务目标灵活定义和设置调度策略;异构GPU调度,池化 GPU 等各种计算资源,支持不同厂商GPU,支持集群规模的动态扩展;弹性分配工作负载,自动回收闲置资源,优化现有计算资源利用率,允许在同一硬件上运行更多计算;灵活扩展的工作流系统,能够把复杂的计算步骤灵活地组合在一起,进行统一管理和调度,在集群中实现复杂大规模计算工作流自动化,支撑企业级、复杂、大规模的 AI 工作负载;全面可视化的监控能力,可视化的界面提供 CPU、Memory、GPU、网络、存储等硬件资源监控,达到对平台计算任务的全面观测和管理。
RichBoost
高性能大模型训推平台
彩讯股份提供高性能的大语言模型推理引擎RichLLM及高性能文生图/视频推理引擎RichDiff,从底层深度优化加速。
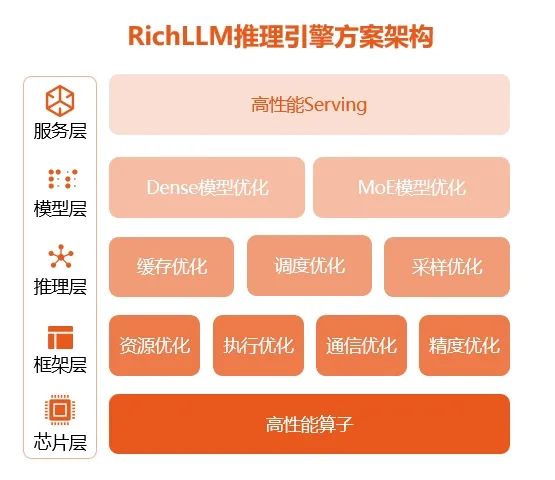
RichLLM是一款高效、易用、可扩展的大语言模型推理引擎,旨在为用户提供开箱即用的推理加速能力,大幅降低模型的部署成本。得益于底层的深度优化、高效的推理框架、创新的通信机制、深度优化的模型,平台加速比可达5倍以上,执行效率、显存利用效率、分布式通信效率得到充分优化。在各种推理场景中,最高效率可达同类开源产品的10倍;同时,经过对模型、机制、框架、算子等联合优化,可实现SOTA推理效率;平台也支持一键启动高效LLM推理服务。
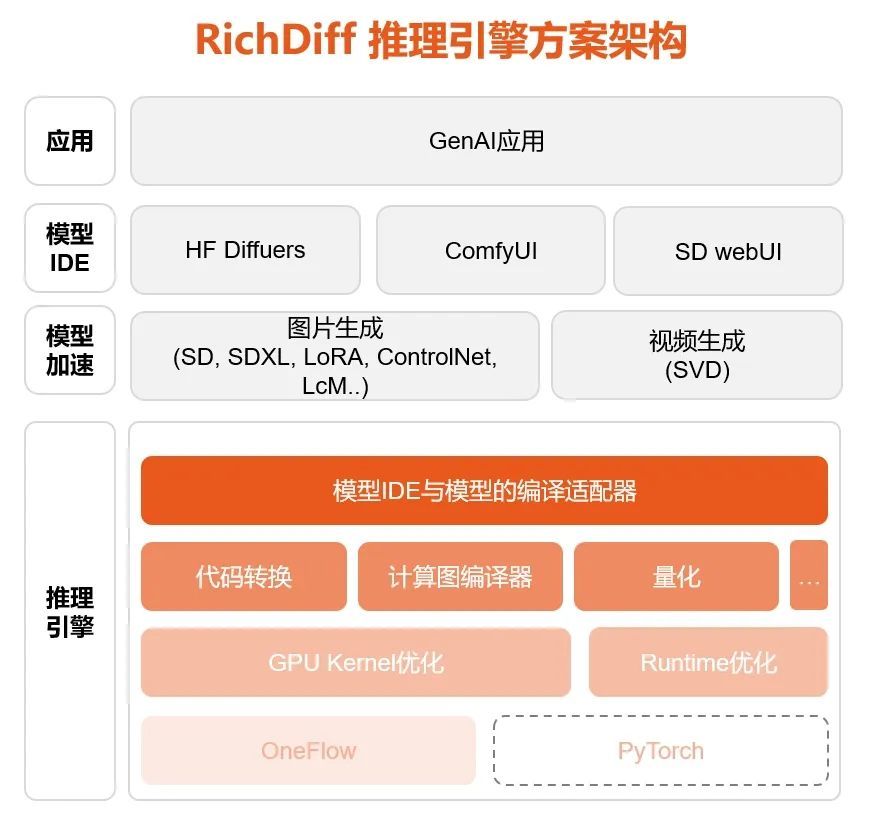
RichDiff是一款高性能多模态推理加速引擎,专为图片和视频生成的推理加速设计。它凭借出色的性能,能实现高达基准引擎3倍的图像生成速度,同时保持图像质量与原生PyTorch一致。RichDiff具有灵活的对接能力,兼容多种深度学习引擎和前端应用框架,满足多样化需求。即插即用,无需做模型转换;加速模型的保存与加载耗时仅需几秒。RichDiff使SDXL端到端推理速度最快提升3倍, SVD端到端推理速度最快提升3倍 。
彩讯Rich AICloud AI原生(AI-Native)云计算解决方案目前已在多个千亿参数级别的大模型训练、大模型推理、AI工具加速等方面成功落地,大幅降低模型训推成本,加速AI产品的落地。面向未来,彩讯股份将持续深化AI智算领域技术和方案研究,推动AI技术的持续进步与革新,不断携手更多合作伙伴,赋能千行百业智能化变革。
评论记录:
回复评论: