

1 leader和follower
1.1 kafka的副本
kafka副本的作用就是提高数据的可靠性,系统默认副本数量是1,生产环境一般配置数量是2个,保证数据可靠性;否则副本太多会增加磁盘的存储空间,增加网络上的数据传输,降低效率。
kafka的副本分为leader和follower,其中leader数据读写,follower只负责数据同步。关于副本有下面三个概念:
- ISR:表示和leader保持同步的follower集合
- OSR:表示follower与leader同步延时过多的副本
- AR:分区中所有副本统称为AR(Assigned Repllicas),AR = ISR + OSR,一个分区的AR集合在分配的时候就被指定,并且只要不发生重分配的情况,集合内部副本的顺序是保持不变的,而分区的ISR集合中副本的顺序可能会改变。
这里ISR在上一篇文章中也介绍了,如果follower长时间没有向leader发送通信请求或者同步数据,这个follower将会被提出ISR队列,这个时间阈值是由replica.lag.time.max.ms参数设置的,默认是30s。
如果leader发送故障,就会从ISR中选举出新的leader。
1.2 leader选举流程
分区leader的选举由kafka的broker leader(后面文章会以controller代替broker leader的描述)负责具体实施。
当创建分区(创建主题或增加分区都有创建分区的动作)或分区上线(比如分区中原先的leader副本下线,此时分区需要选举一个新的leader上线来对外提供服务)的时候都需要leader选举。选举的时候将会从AR集合中副本的顺序查找第一个存活的副本,并且要保证这个副本在ISR队列中。
另外当分区发生重分配的情况(下面会讲)也是需要执行leader选举,此时从重分配的AR列表中找到第一个存活的副本,且这个副本在目前的ISR队列中。
再有就是当某一个borker节点关闭的时候,位于这个节点上的leader副本都会下线,所以与此对应的分区需要执行leader的选举。此时将会从AR列表中找到第一个存活的副本,且这个副本在目前的ISR列表中,另外还要确保这个副本不处于正在被关闭的节点上。
1.3 Unclean leader选举
kafka还提供了一个参数配置:unclean.leader.election.enable,默认是true,参数规定是否允许非ISR的副本成为leader,如果设置为true,当ISR队列是空,ISR为空说明leader和follower都挂掉了,此时将选择那些不在ISR队列中的副本选择为新的leader,这写副本的消息可能远远落后于leader,所以可能会造成丢失数据的风险。生产环境中建议关闭这个参数,设置为false。
1.4 leader和follower故障流程
1.4.1 LEO和HW
在生产环境中可能会出现follower和leader出现故障,那么Kafka是如何处理这些故障的呢?下面简单介绍一下流程,在讲流程之前,先了解一下LEO和HW这两个概念。
- LEO(log end offset):每个副本的最后一个offset,LEO就是最新的offset+1
- HW(high watermark):所有副本中最小的LEO;
LEO和HW的概念产生其实是因为,数据先写入leader,然后follower拉取数据进行同步,但是同步速度不一致,会出现先后问题,那个这是后副本的offset是不一样的,此时kafka会使用所有副本中最小的offset+1,也是HW。

1.4.2 follower故障流程
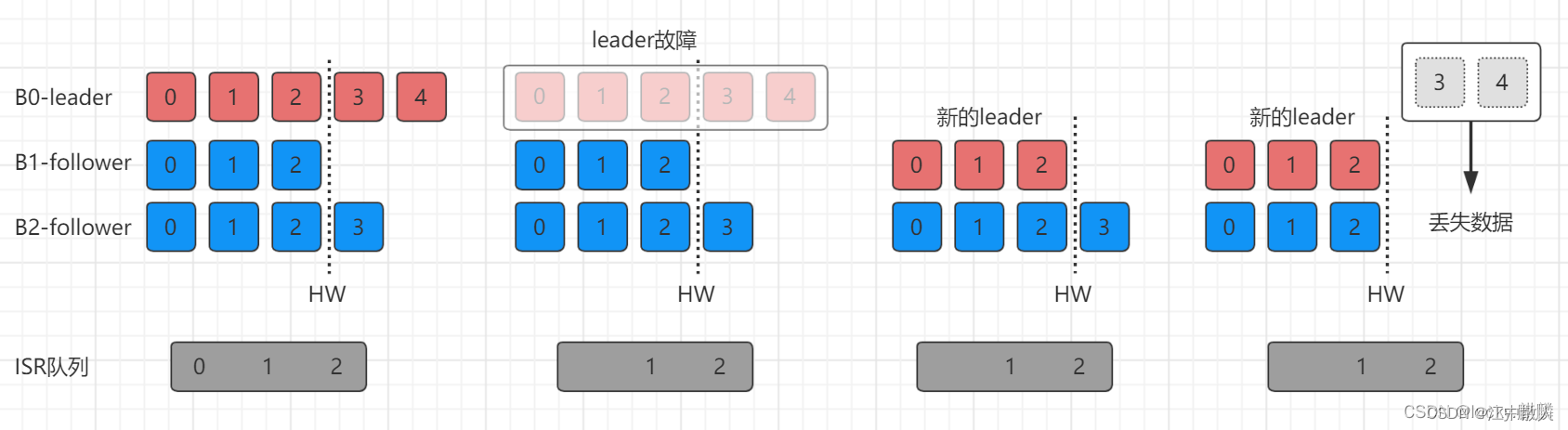
此时假如Broker1上的follower发生故障会出现什么情况呢?首先Broker1上的follower会被踢出ISR队列中,但是leader和其他的follower都还是会继续接受数据,并不会受到影响,对应的LEO和HW都会往后移动;如果此时发生故障的Broker1上的follower恢复后,此时Broker1上的follower会读取本地磁盘记录的上次HW位置,并将log文件中高于HW的部分截取掉,从HW开始向Leader进行同步;直到Broker1上的follower的LEO大于等于该分区的HW,此时说明这个follower追上了leader,就会将其重新加入ISR队列中。

1.4.3 leader故障流程
上面了解了follower故障的情况,那么如果leader发生故障呢?接着上面的图片来看,首先如果Broker0上的leader发生故障之后,也是一样会先从ISR队列中被踢出,然后从ISR中选出一个新的Leader来;此时为了保证多个副本之间的数据一致性,其他的follower会先将各自的log文件中高于HW的部分截取掉,然后从新的leader同步数据(由此可知这只能保证副本之间数据一致性,并不能保证数据不丢失或者不重复)。
1.5 分区副本的调整
在kafka集群中分区的副本分布是做到尽量的均匀分配到各个节点中,以此来保证每台机器的读写吞吐量是均匀的,但是出现某些broker宕机,会导致leader都集中在几台broker中,造成读写压力过大,并且就算恢复了宕机的broker,原来的leader也会变成follower并无法分担压力,造成集群负载不均衡。
1.5.1 Leader Partition自动平衡
为了解决上述问题kafka出现了自动平衡的机制。kafka提供了下面几个参数进行控制:
- auto.leader.rebalance.enable:自动leader parition平衡,默认是true;
- leader.imbalance.per.broker.percentage:每个broker允许的不平衡的leader的比率,默认是10%,如果超过这个值,控制器将会触发leader的平衡;
- leader.imbalance.check.interval.seconds:检查leader负载是否平衡的时间间隔,默认是300秒;
但是在生产环境中是不开启这个自动平衡,因为触发leader partition的自动平衡会损耗性能,或者可以将触发自动平衡的参数leader.imbalance.per.broker.percentage的值调大点。
1.5.2 手动调整副本分配
会导致服务器的性能不一样,服务器磁盘不足或者其他的原因需要将性能好、磁盘空间大的服务器节点多存放副本,那么在生产环境中如何去手动调整分区副本的分布比例呢?
下面先创建一个测试的主题:

下面演示一下如何更新分区间的副本配比,首先创建一个assign-replicas.json的文件,内容如下:
- {
- "version": 1,
- "partitions": [
- {"topic": "test-assign", "partition": 0, "replicas": [1, 2]},
- {"topic": "test-assign", "partition": 1, "replicas": [1, 2]},
- {"topic": "test-assign", "partition": 2, "replicas": [1, 2]}
- ]
- }
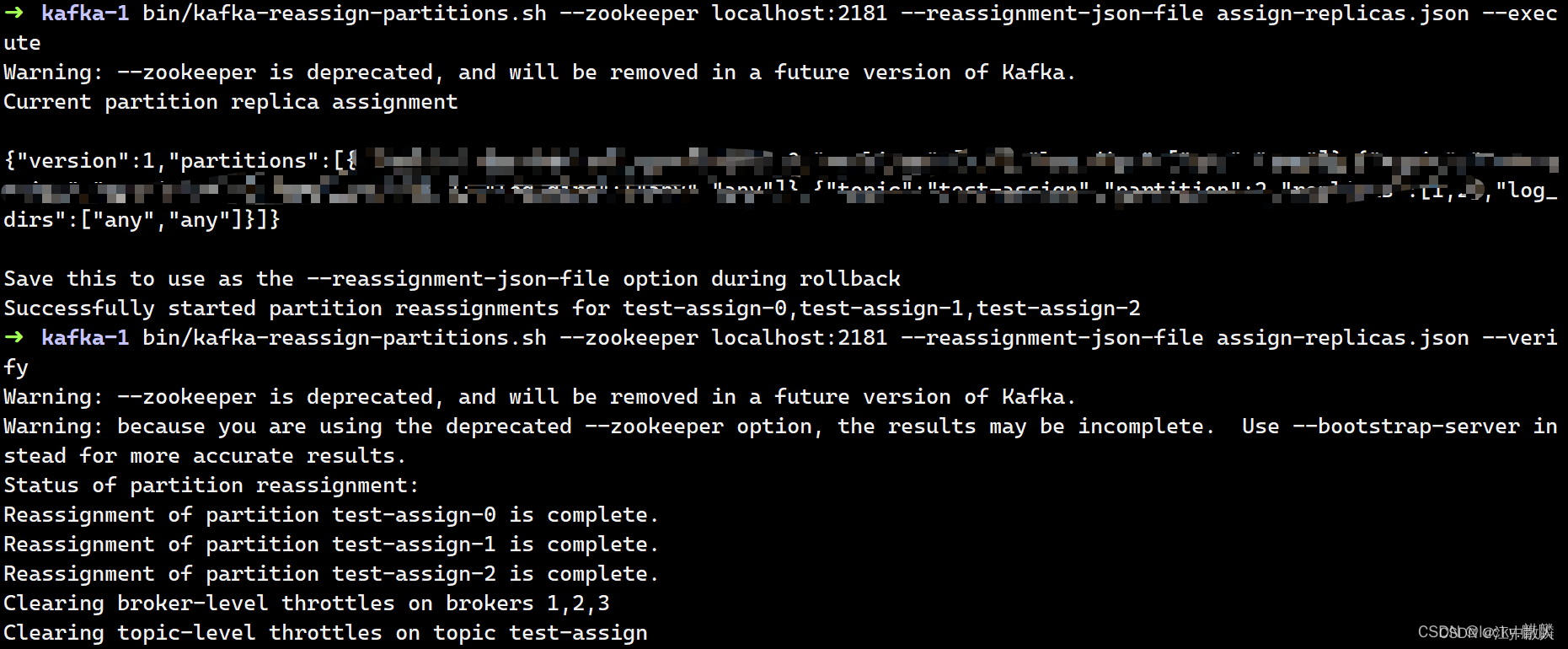
接着执行命令:
- bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file assign-replicas.json --execute
- bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file assign-replicas.json --verify
最后看一个这个主题的副本分布情况:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test-assign
1.5.3 增加副本因子
生产环境中由于某个主题的重要等级需要提升,考虑增加副本。下面演示下如何增加副本。
创建一个Json文件:add-relication-factor.json
- {
- "version": 1,
- "partitions": [
- {"topic": "test-assign", "partition": 0, "replicas": [3, 2, 1]},
- {"topic": "test-assign", "partition": 1, "replicas": [1, 3, 2]},
- {"topic": "test-assign", "partition": 2, "replicas": [2, 1, 2]}
- ]
- }
执行副本存储计划:
- bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file add-relicati
- on-factor.json --execute
参考链接
Kafka : Kafka入门教程和JAVA客户端使用-CSDN博客
再过半小时,你就能明白kafka的工作原理了(推荐阅读)
Kafka 设计与原理详解_kafka的设计初衷不包括-CSDN博客
Kafka知识总结之Broker原理总结_kafka broker-CSDN博客
评论记录:
回复评论: