
在开始部署操作之前,请务必检查以下CheckList中的条件是否满足
CheckList
适合阅读人群
- 有需要做本地化方案的人群
- AI开发者
新手建议直接上手线上API
- 运维
硬件
- 首先你得有显卡(nvidia),没有可以去租
显存>= 24g
软件
- 操作系统为Linux, 本次以Ubuntu 22.04 为例
- 正确得安装了显卡的驱动, 注意cuda版本应该>=12.4, 执行
nvidia-smi可以看到如下界面
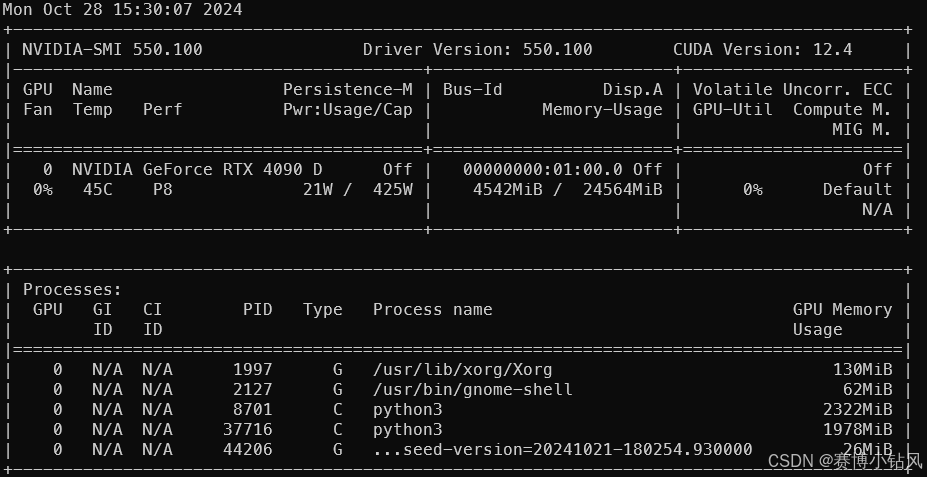
- 正确的安装了
docker以及nvidia-docker、docker-compose
使用docker就不用处理烦人的依赖啦
vllm
核心概念
vllm 是一个高效的大模型推理库,通过PagedAttention技术高效管理注意力键和值的内存使用,优化推理过程。
以下表格是vllm开发者对自己的介绍, 以及本人使用过程中的实际评价。
| 特点 | 描述 | 评价 |
|---|---|---|
| 先进的吞吐量 | 提供卓越的服务性能,满足高需求的推理工作负载。 | 所言不虚 |
| PagedAttention 技术 | 高效管理注意力键和值的内存使用,优化推理过程。 | 所言不虚 |
| 连续批处理 | 支持无缝批量处理传入请求,显著提升吞吐量,减少延迟。 | 所言不虚 |
| 快速模型执行 | 通过 CUDA/HIP 图形加速模型的执行效率。 | 所言不虚 |
| 多种量化选项 | 支持 GPTQ、AWQ、INT4、INT8 和 FP8 等多种量化技术,优化模型的大小和性能。 | 量化模型是显存不足情况下的无奈之举,部分情况下会出现模型抽风的现象(反复输出同样的内容) , 能上满血的满血还是尽量跑满血的模型 |
| 优化的 CUDA 内核 | 集成 FlashAttention 和 FlashInfer,进一步提升性能。 | 所言不虚 |
| 推测解码和分块预填充 | 采用先进的解码技术,提高响应速度。 | 确实很快 |
| 无缝集成 HuggingFace | 轻松引入流行的 HuggingFace 模型,适用于多种应用场景。 | 在国内的环境使用并不轻松,基本上是网络问题引起的,注意上网方式 |
| 高吞吐量解码算法 | 支持多种解码策略,如并行采样和束搜索,满足不同需求。 | 一张4090跑7B抗10个并发不是问题? |
| 并行计算支持 | 提供张量并行和流水线并行,充分发挥分布式推理的优势。 | 如上 |
| 流式输出功能 | 支持实时应用的流式输出,提升用户体验。 | 实现打字机效果必备 ? |
| 兼容 OpenAI API | 提供与 OpenAI 框架兼容的 API,简化集成过程。 | 无缝接入, 接入时只需要改初始化的base_url地址即可 |
| 硬件兼容性 | 支持 NVIDIA GPU、AMD CPU 和 GPU、Intel CPU 和 GPU、PowerPC CPU、TPU,以及 AWS Trainium 和 Inferentia 加速器。 | 目前只尝试了N卡 |
| 前缀缓存与多 Lora 支持 | 通过前缀缓存和多 Lora 功能,进一步提升模型的性能与灵活性。 | 暂未尝试 |
部署
准备工作
- 第一步拉取镜像:
sudo docker pull vllm/vllm-openai:v0.6.1
- 1
- 下载模型
从HF上下载模型qwen2.5-7b-instruct , 下载地址 点击下载
如果速度较慢可以配置加速地址,操作方法如下
export HF_ENDPOINT=https://hf-mirror.com
- 1
之后直接clone repo
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- 1
- 2
下载完成之后的文件列表如下
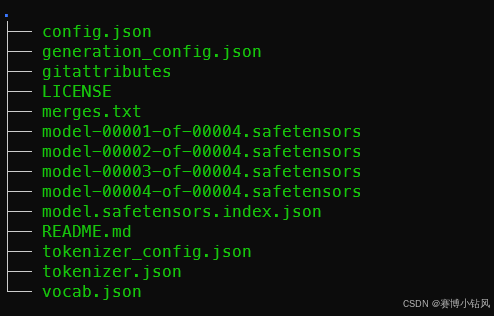
如果git无法clone下来可以上modelscope或者, 更改上网方式在HF上逐个下载保存到本地
下载完成之后,将模型保存至和docker-compose.yaml同一父目录的models文件夹中便于统一管理
使用docker-compose部署
docker-compose.yaml 文件如下
services:
vllm:
container_name: vllm
restart: no
image: vllm/vllm-openai:v0.6.1
ipc: host
volumes:
- ./models:/models
command: ["--model", "/models/Qwen2.5-7B-Instruct", "--served-model-name", "qwen2.5-7b-instruct", "--gpu-memory-utilization", "0.90"]
ports:
- 8000:8000
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
启动参数解释
–model 模型的路径,vllm会尝试本地有没有这个文件夹以及HF上有没有对应的repo,如果本地没有并且HF上有对应的repo则会自动下载模型
–served-model-name 模型的名称,api调用的时候需要保持一致
–gpu-memory-utilization 占用显存的上限,此参数会影响并发和模型上下文长度,后续本专栏将会提供vllm参数解析
执行命令, 启动vllm
sudo docker compose up -d
- 1
查看日志
sudo docker logs -f vllm
- 1

查看显存占用
nvidia-smi
- 1
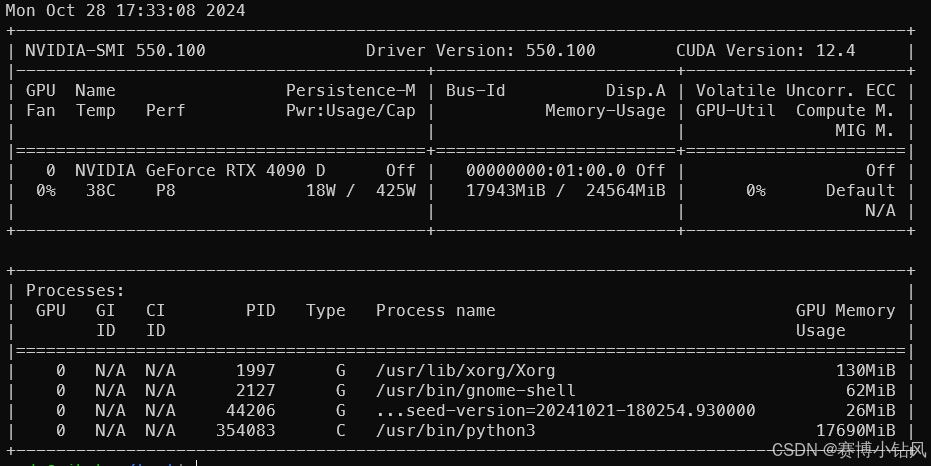
使用
import openai
client = openai.OpenAI(
base_url='http://127.0.0.1:8000/v1',
api_key='NOT_NEED'
)
predict_ret = client.chat.completions.create(
model='qwen2.5-7b-instruct', # 此处名称要和vllm中的served-model-name一致
messages=[
{'role': 'user', 'content': '你是谁'}
]
)
print(
predict_ret.choices[0].message.content
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
输出如下:
我是阿里云开发的一种超大规模语言模型,我叫Qwen。作为一个AI助手,我的目标是帮助用户获得准确、有用的信息,解决他们的问题和困惑。我会不断学习和进步,不断提升自己的能力。如果您有任何问题或需要帮助,请随时告诉我。
- 1
评论记录:
回复评论: