
概述
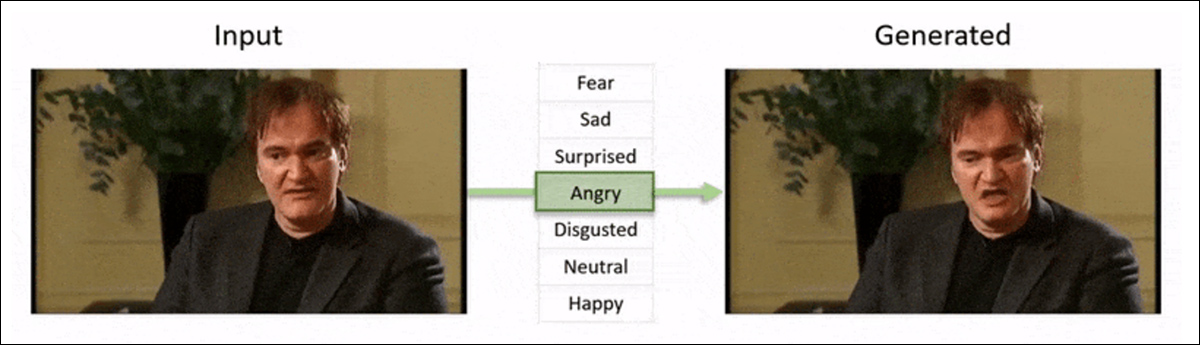
2019 年,美国众议院议长南希·佩洛西成为了一次针对性的、技术含量相对较低的“深度伪造”式攻击的目标。真实的佩洛西视频被编辑,让她看起来像是喝醉了酒。这一不真实的事件在真相大白之前被分享了数百万次,而且在一些人没有关注后续报道的情况下,可能已经对她的政治资本造成了不可挽回的损害。
尽管这种误导性的视频只需要进行一些简单的音视频编辑,而不是使用任何人工智能技术,但它仍然是一个关键的例子,展示了对真实音视频输出进行细微改动可能产生的毁灭性影响。
当时,深度伪造领域主要由 2017 年末首次亮相的基于自编码器的面部替换系统主导,这些系统的质量自那以后并没有显著提升。这些早期系统很难创造出这种小但重要的改动,或者追求现代研究方向中的表情编辑等技术:
行业现状
如今,情况已经大不相同。电影和电视行业对使用机器学习方法对真实表演进行后期修改表现出了浓厚的兴趣,人工智能助力的“事后完美主义”甚至最近也受到了一些批评。
为了满足(或者可以说创造了)这种需求,图像和视频合成研究领域已经推出了一系列项目,这些项目提供了对面部捕捉的“局部编辑”,而不是直接替换。这类项目包括 Diffusion Video Autoencoders、Stitch it in Time、ChatFace、MagicFace 和 DISCO 等。

新问题与新挑战
然而,使这些编辑成为可能的技术发展速度远远超过了检测它们的方法。在文献中出现的几乎所有深度伪造检测方法都在用过时的数据集追逐过时的深度伪造方法。直到本周,还没有一种方法能够解决人工智能系统在视频中创建小而有针对性的局部改动的潜在威胁。
现在,来自印度的一篇新论文填补了这一空白,提出了一种能够识别通过基于人工智能技术进行编辑(而不是替换)的面部的系统:

该系统旨在识别涉及微妙、局部面部操作的深度伪造,这是一种被忽视的伪造类别。该方法不是专注于全局不一致性或身份不匹配,而是针对细微的表情变化或对特定面部特征的小改动。
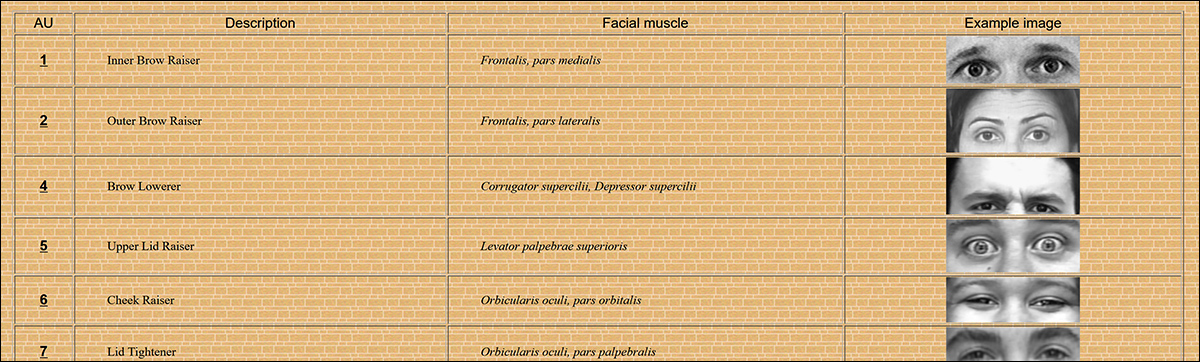
该方法利用了面部动作编码系统(FACS)中的动作单元(AUs)分隔符,该系统定义了面部的 64 个可能的可变区域,这些区域共同构成了表情。
作者在多种最近的编辑方法上评估了他们的方法,并报告了在旧数据集以及更新的攻击向量上的一致性能提升。
“通过使用基于 AU 的特征来引导通过掩码自编码器(MAE)学习的视频表示,我们的方法有效地捕捉了对检测微妙面部编辑至关重要的局部变化。”
“这种方法使我们能够构建一个统一的潜在表示,它编码了局部编辑和更广泛的面部视频中的变化,为深度伪造检测提供了一个全面且可适应的解决方案。”
这篇名为《使用动作单元引导的视频表示检测局部深度伪造操作》的新论文由印度理工学院马德拉斯分校的三位作者撰写。
方法
与 VideoMAE 采用的方法一致,新方法首先对视频进行面部检测,并采样以检测到的面部为中心的均匀间隔的帧。然后将这些帧划分为小的 3D 分区(即时间启用的补丁),每个分区捕获局部空间和时间细节。
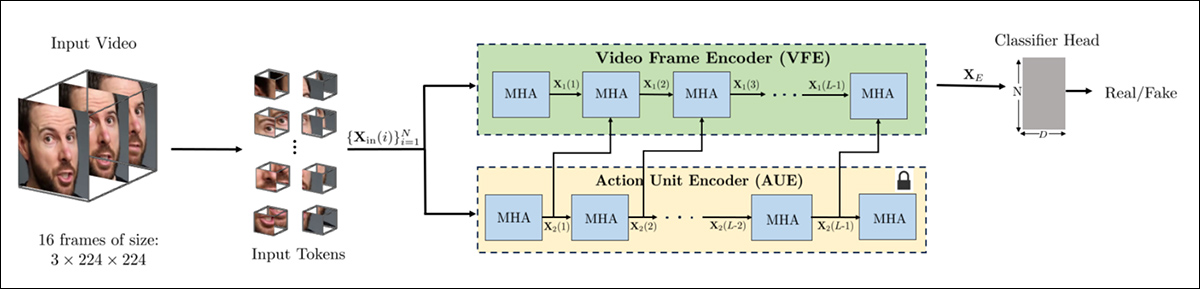
新方法的架构。输入视频经过面部检测处理,以提取均匀间隔的、以面部为中心的帧,然后将这些帧划分为“管状”补丁,并通过编码器传递,该编码器融合了来自两个预训练预任务的潜在表示。最终的向量被分类器用来判断视频是真实的还是伪造的。
每个 3D 补丁包含来自少量连续帧(例如 2 帧)的固定大小的像素窗口(例如 16×16)。这使得模型能够学习短期的运动和表情变化——不仅仅是面部的外观,还有它是如何运动的。
在传递到编码器之前,补丁被嵌入并进行位置编码,该编码器旨在提取能够区分真实与伪造的特征。
作者承认,当处理微妙的操作时,这尤其困难,因此他们通过构建一个结合了两种独立学习表示的编码器来解决这个问题,使用交叉注意力机制将它们融合。这旨在产生一个更敏感且更具泛化的特征空间,用于检测局部编辑。
预任务
第一种表示是一个经过掩码自编码任务训练的编码器。将视频划分为 3D 补丁(其中大部分被隐藏),然后编码器学习重建缺失的部分,迫使其捕捉重要的时空模式,例如面部运动或随时间的一致性。
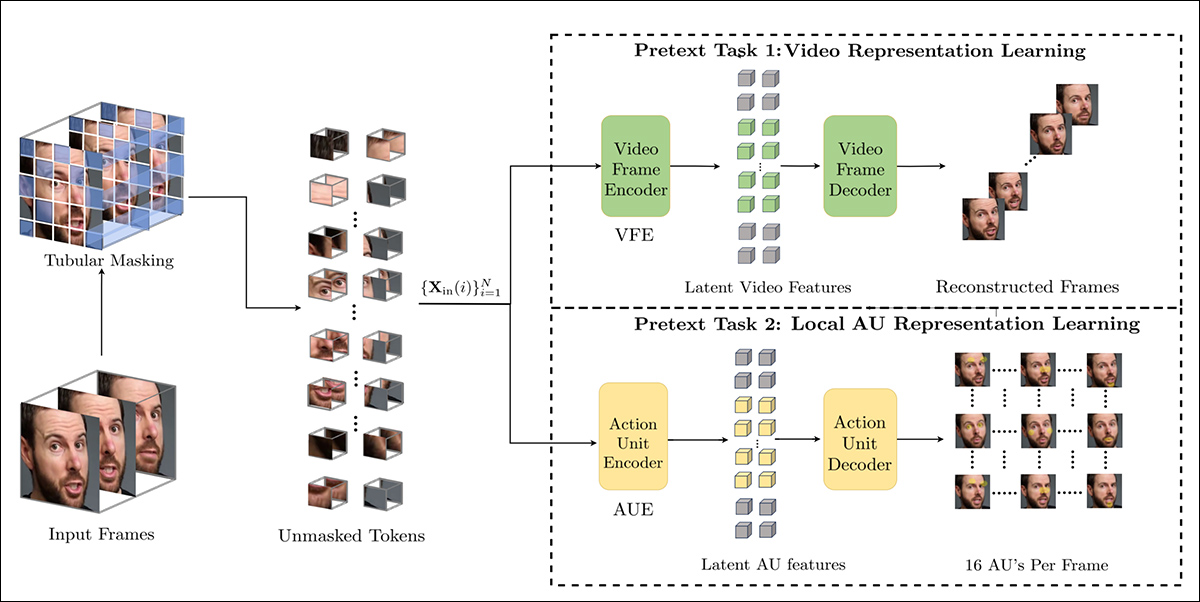
然而,论文指出,这本身并不能提供足够的灵敏度来检测细粒度的编辑,因此作者引入了第二个经过训练以检测面部动作单元(AUs)的编码器。对于这个任务,模型学习从部分掩码的输入中重建每帧的密集 AU 图。这促使它专注于局部肌肉活动,许多微妙的深度伪造编辑就发生在这里。

更多的面部动作单元(FAUs 或 AUs)示例。来源:EIA Group
两个编码器经过预训练后,使用交叉注意力将它们的输出结合起来。而不是简单地合并这两组特征,模型使用基于 AU 的特征作为查询,引导对从掩码自编码中学习到的时空特征的注意力。实际上,动作单元编码器告诉模型该看哪里。
结果是一个融合的潜在表示,旨在捕捉更广泛的运动背景和局部表情级别的细节。这个组合的特征空间随后用于最终的分类任务:预测视频是真实的还是被操纵过的。
数据和测试
实现
作者使用基于 PyTorch 的 FaceXZoo 面部检测框架对输入视频进行预处理,从每个剪辑中获取 16 个以面部为中心的帧。上述预任务随后在 CelebV-HQ 数据集上进行训练,该数据集包含 35,0
00 个高质量的面部视频。

一半的数据示例被掩码,迫使系统学习一般原则,而不是对源数据过拟合。
对于掩码帧重建任务,模型被训练以使用 L1 损失 预测视频帧的缺失区域,最小化原始内容与重建内容之间的差异。
对于第二个任务,模型被训练以生成 16 个面部动作单元的地图,每个单元代表眉毛、眼睑、鼻子和嘴唇等区域的微妙肌肉运动,同样由 L1 损失监督。
经过预训练后,两个编码器被融合并在 FaceForensics++ 数据集上进行微调,该数据集包含真实和被操纵的视频。

为了应对 类别不平衡,作者使用了 Focal Loss(交叉熵损失 的一种变体),在训练期间强调更具挑战性的示例。
所有训练都在单个 RTX 4090 GPU 上进行,该 GPU 拥有 24Gb 的 VRAM,批量大小为 8,进行 600 个周期(对数据的完整审查),使用 VideoMAE 的预训练检查点来初始化每个预任务的权重。
测试
对多种深度伪造检测方法进行了定量和定性评估:FTCN、RealForensics、Lip Forensics、EfficientNet+ViT、Face X-Ray、Alt-Freezing、CADMM、LAANet 以及 BlendFace 的 SBI。在所有情况下,这些框架的源代码都是可用的。
测试集中在局部编辑的深度伪造上,只有源剪辑的一部分被修改。使用的架构包括 Diffusion Video Autoencoders(DVA)、Stitch It In Time(STIT)、Disentangled Face Editing(DFE)、Tokenflow、VideoP2P、Text2Live 和 FateZero。这些方法采用了多种方法(例如 DVA 使用扩散,STIT 和 DFE 使用 StyleGAN2 等)。
作者指出:
“为了确保对不同面部操作的全面覆盖,我们纳入了各种面部特征和属性编辑。对于面部特征编辑,我们修改了眼睛大小、眼睛与眉毛之间的距离、鼻子比例、鼻子与嘴巴之间的距离、嘴唇比例和脸颊比例。对于面部属性编辑,我们改变了微笑、愤怒、厌恶和悲伤等表情。”
“这种多样性对于验证我们模型在广泛局部编辑上的鲁棒性至关重要。总共,我们为上述每种编辑方法生成了 50 个视频,并验证了我们方法在深度伪造检测方面的强大泛化能力。”
旧的深度伪造数据集也被包括在测试中,分别是 Celeb-DFv2(CDF2)、DeepFake Detection(DFD)、DeepFake Detection Challenge(DFDC)和 WildDeepfake(DFW)。
评估指标为 曲线下面积(AUC)、平均精度 和平均 F1 分数。
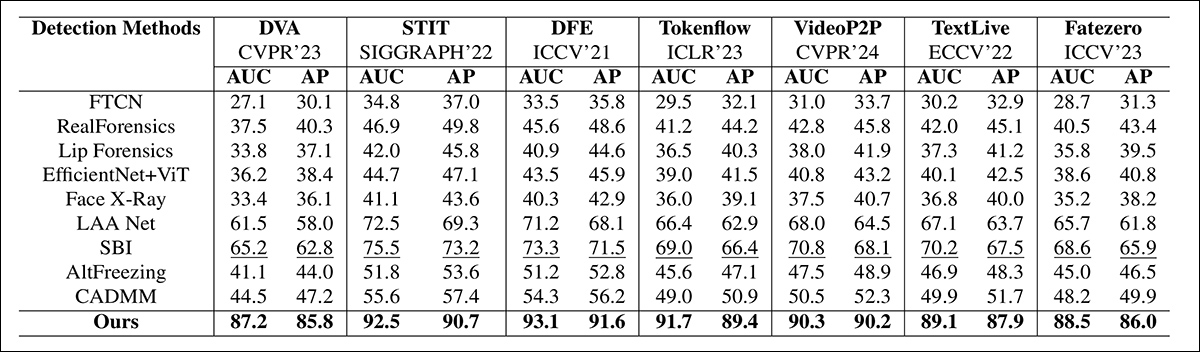
作者还提供了一个局部操纵视图的视觉检测比较(由于篇幅有限,此处仅部分复制):

真实视频经过三种不同的局部操作以产生在视觉上与原始视频相似的伪造品。此处展示了代表性帧以及每种方法的平均伪造检测分数。尽管现有的检测器在这些微妙的编辑上挣扎,但所提出的模型始终给出了较高的伪造概率,表明其对局部变化的敏感性更高。
研究人员评论道:
“现有的最先进的检测方法(LAANet、SBI、AltFreezing 和 CADMM)在最新的深度伪造生成方法上的性能显著下降。当前最先进的方法的 AUC 低至 48% 至 71%,显示出它们对最近的深度伪造的泛化能力较差。”
“另一方面,我们的方法表现出强大的泛化能力,AUC 在 87% 至 93% 之间。在平均精度方面也有类似的趋势。如图所示,我们的方法在标准数据集上的表现也一直很高,AUC 超过 90%,并且与最近的深度伪造检测模型具有竞争力。”
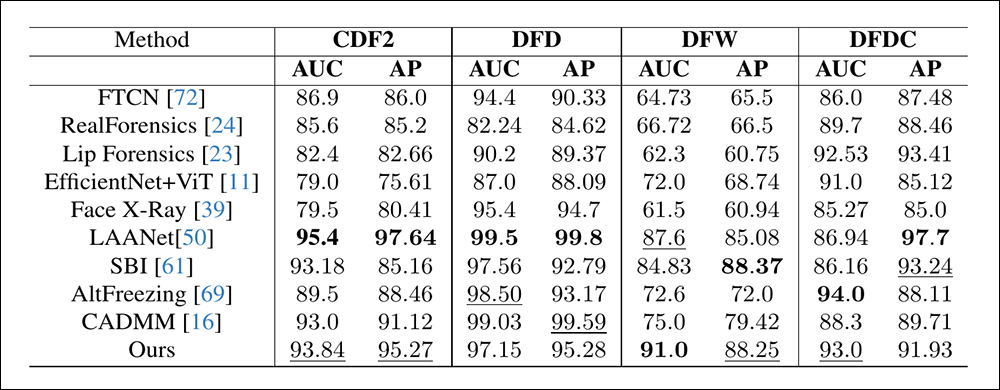
作者指出,这些最后的测试涉及的模型可能被认为是过时的,并且是在 2020 年之前引入的。
为了更详细地展示新模型的表现,作者在论文末尾提供了一个详细的表格,此处仅部分复制:

在这些示例中,真实视频经过三种局部编辑以产生在视觉上与原始视频相似的伪造品。这些操作的平均置信度分数表明,所提出的方法比其他领先方法更可靠地检测到了伪造品。请参阅源 PDF 的最后一页以获取完整结果。
作者认为,他们的方法在检测局部编辑方面的置信度分数超过了 90%,而现有的检测方法在相同任务上的表现低于 50%。他们将这一差距视为他们方法的敏感性和泛化能力的证据,以及当前技术在处理这种微妙的面部操作时面临的挑战。
为了评估模型在现实世界条件下的可靠性,并按照 CADMM 的方法,作者测试了其在经过常见失真处理的视频上的表现,包括对饱和度和对比度的调整、高斯模糊、像素化以及块状压缩伪影,以及加性噪声。
结果显示,在这些干扰下,检测精度在大多数情况下保持稳定。唯一显著的下降发生在加入高斯噪声时,这导致了性能的适度下降。其他改变影响甚微。
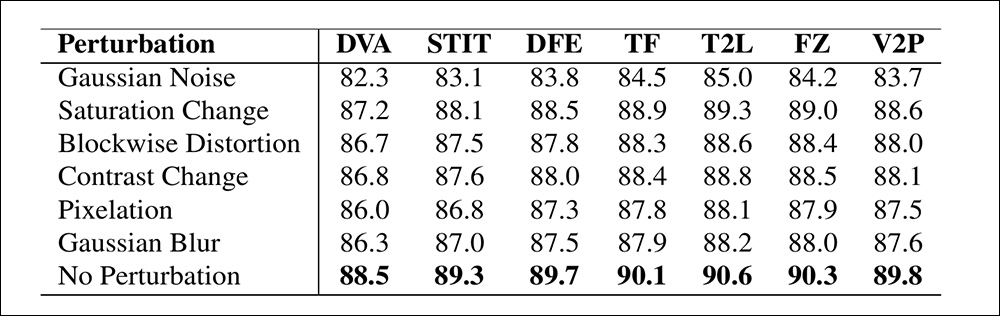
检测精度在不同视频失真下的变化示意图。新方法在大多数情况下保持稳定,AUC 只有小幅下降。最显著的下降发生在引入高斯噪声时。
这些发现,作者认为,表明该方法检测局部操作的能力不容易被视频质量的典型退化所干扰,支持其在实际设置中可能的鲁棒性。
结论
人工智能操纵在公众意识中主要以传统的深度伪造形式存在,即一个人的身份被强加到另一个人身上,后者可能正在从事与身份所有者原则相悖的行为。这种观念正在逐渐更新,以承认新型视频深度伪造的能力,以及潜在扩散模型(LDMs)的一般能力。
因此,可以合理地预期,新论文关注的这种局部编辑可能不会引起公众的注意,直到发生类似佩洛西事件的转折点,因为人们被更容易引起轰动的话题(如视频深度伪造欺诈)分散了注意力。
尽管如此,正如演员尼古拉斯·凯奇一直对后期制作过程“修改”演员表演的可能性表示担忧一样,我们也应该鼓励对这种“微妙”的视频调整有更高的认识——尤其是因为我们天生对微小的面部表情变化非常敏感,而且情境可以显著改变小的面部动作的影响(考虑在葬礼上微笑的破坏性影响,例如)。

 QQ群名片
QQ群名片

评论记录:
回复评论: