
引言
卷积神经网络(Convolutional Neural Networks,简称 CNNs)是一种深度学习架构,专门用于处理具有网格结构的数据,如图像、视频等。它们在计算机视觉领域取得了巨大成功,成为图像分类、目标检测、图像分割等任务的核心技术。
CNNs 的核心思想是利用卷积操作(convolution)来提取数据中的局部特征,并通过层次化的结构逐步学习更复杂的模式。
一、卷积神经网络
卷积神经网络,主要用于处理具有网格结构的数据,一般有以下几个关键组成部分:
1.1 输入
输入层是网络的初始数据入口点。在基于图像的任务中,输入层代表图像的像素值。在以下示例中,假设我们正在处理大小为 28x28 像素的灰度图像。
from tensorflow.keras.layers import Input
input_layer = Input(shape=(28, 28, 1))
- 1
- 2
- 3
1.2 卷积层
卷积层是 CNNs 的核心构建块。这些层通过对输入数据应用卷积操作来提取特征,例如边缘、纹理和模式。
from tensorflow.keras.layers import Conv2D
conv_layer = Conv2D(filters=32, kernel_size=(3, 3),
activation='relu')(input_layer)
- 1
- 2
- 3
- 4
在卷积神经网络(CNNs)中,“核”和“滤波器”这两个术语经常可以互换使用,它们指的是同一个概念。让我们来剖析一下这两个术语的含义:
2.1 核:核是卷积操作中使用的一个小矩阵。它是一组可学习的权重,应用于输入数据以生成输出特征图。核是使 CNNs 能够自动学习输入数据中空间层次特征的关键元素。在图像处理中,核可能是一个 3x3 或 5x5 的小矩阵。
2.2 滤波器:另一方面,滤波器是一组多个核。在大多数情况下,卷积层使用多个滤波器来捕获输入数据中的不同特征。每个滤波器都与输入进行卷积以生成特征图,网络通过在训练过程中调整这些滤波器的权重(参数)来学习提取各种模式。
在这个示例中,我们定义了一个具有 32 个滤波器的卷积层,每个滤波器的大小为 3x3。在训练过程中,神经网络会调整这 32 个滤波器的权重(参数),以从输入数据中学习不同的特征。让我们通过一个图像示例来看一下:
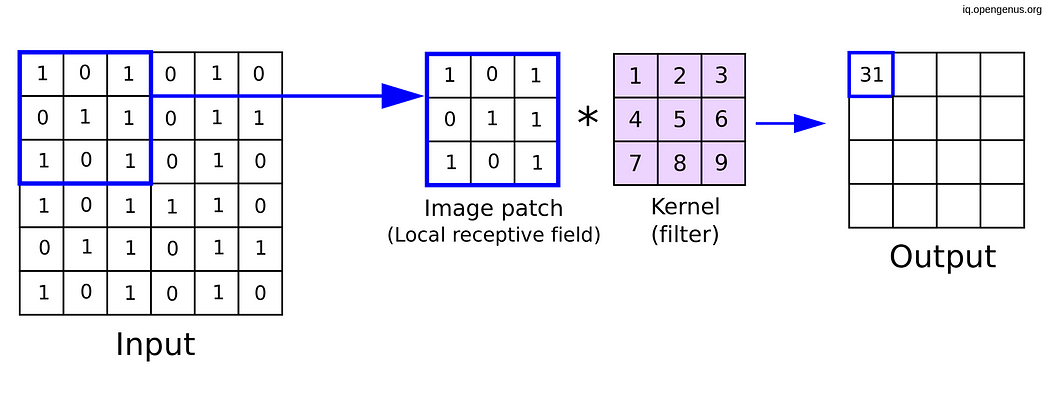
卷积机制。核形状(3x3)。图片来源:OpenGenus
总之,核是滑动或卷积穿过输入数据的小矩阵,而滤波器是一组这样的核,用于从输入中提取各种特征,从而使神经网络能够学习层次化的表示。
1.3 激活层(ReLU)
在卷积操作之后,通常会应用激活函数,通常是修正线性单元(ReLU),以逐元素地引入非线性。ReLU 有助于网络学习复杂的关系,并使模型更具表现力。完全取决于你的用例,你将使用哪种激活函数。在大多数情况下,研究人员使用 ReLU,也有一些其他激活函数可以使用,例如 Leaky ReLU、ELU。
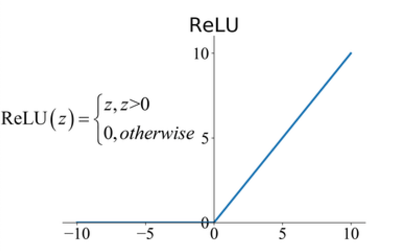
ReLU 激活。来源:ResearchGate
在 Python 中实现修正线性单元(ReLU)函数非常简单。ReLU 是一种常用于神经网络的激活函数,用于引入非线性。以下是一个简单的 Python 实现:
def relu(x):
return max(0, x)
- 1
- 2
1.4 池化层
池化层(例如 最大池化 或 平均池化)会降低由卷积层生成的特征图的空间维度。例如,最大池化会从一组值中选择最大值,专注于最显著的特征。
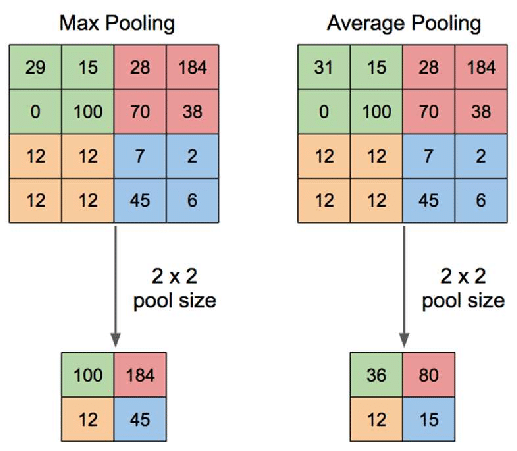
最大池化 — 平均池化。来源:ResearchGate
池化层可以降低空间维度。最大池化通常被使用:
from tensorflow.keras.layers import MaxPooling2D
pooling_layer = MaxPooling2D(pool_size=(2, 2))(conv_layer)
- 1
- 2
- 3
1.5 全连接(密集)层
全连接层将一层中的每个神经元连接到下一层中的每个神经元。这些层通常位于网络的末端,将学到的特征转换为预测或类别概率。全连接层通常用于分类任务:
from tensorflow.keras.layers import Dense, Flatten
flatten_layer = Flatten()(pooling_layer)
dense_layer = Dense(units=128, activation='relu')(flatten_layer)
- 1
- 2
- 3
- 4
1.6 Dropout 层
Dropout 层用于正则化,以防止过拟合。在训练过程中,随机神经元会被“丢弃”,即忽略它们,迫使网络学习更健壮和泛化的特征。它通过在训练过程中随机忽略输入单元的一部分来帮助防止过拟合:
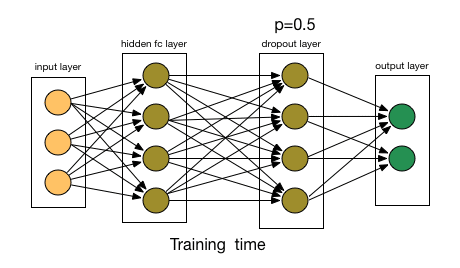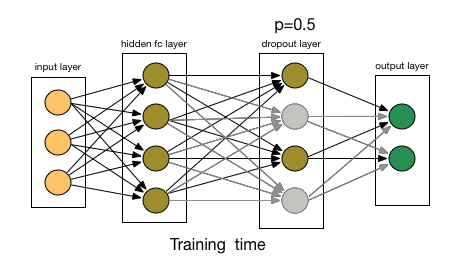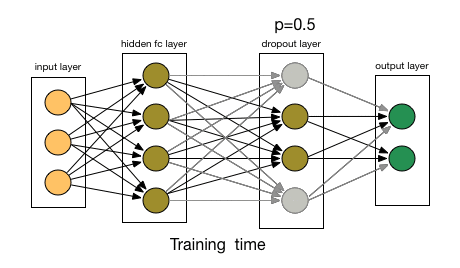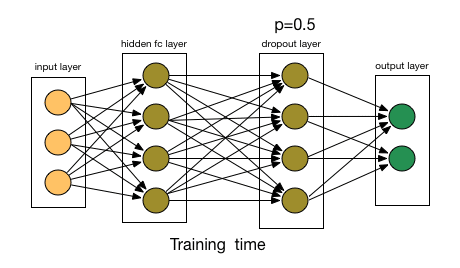
Dropout 机制。来源:nagadakos
from tensorflow.keras.layers import Dropout
dropout_layer = Dropout(rate=0.5)(dense_layer)
- 1
- 2
- 3
1.7 批量归一化层
批量归一化(BN)是一种用于神经网络的技术,用于稳定和加速训练过程。它通过在训练过程中调整和缩放输入来归一化输入。批量归一化的数学细节涉及归一化、缩放和移动操作。让我们深入探讨批量归一化的数学原理。
假设我们有一个大小为 m 的小批量,包含 n 个特征。批量归一化的输入可以总结如下:
7.1. 计算均值:计算每个特征的小批量的均值 μ :
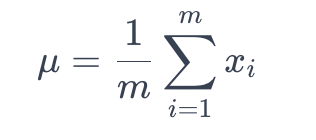
数组 X 的均值
这里,_xi_ 表示小批量中第 i 个特征的值。
7.2. 计算方差:计算每个特征的小批量的方差 σ² :
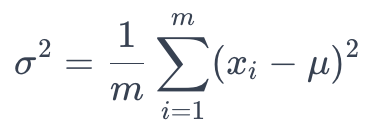
方差计算
7.3. 归一化:通过减去均值并除以标准差 (σ) 来归一化输入:
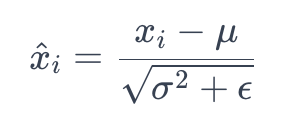
这里,ϵ 是一个很小的常数,用于避免除以零。
7.4. 缩放和移动:引入可学习的参数 (γ 和 β) 来缩放和移动归一化的值:
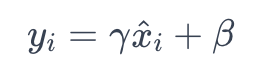
这里,γ 是缩放参数,β 是移动参数。
批量归一化操作通常插入在神经网络层的激活函数之前。它已被证明具有正则化效果,并可以减轻内部协变量偏移等问题,使训练更稳定、更快。以下是一个简单的批量归一化代码,用于 CNN 或任何深度神经网络:
from tensorflow.keras.layers import BatchNormalization
batch_norm_layer = BatchNormalization()(dropout_layer)
- 1
- 2
- 3
总之,批量归一化归一化输入,缩放和移动归一化的值,并引入可学习的参数,以便网络在训练过程中进行调整。批量归一化的使用已成为深度学习架构的标准实践。
1.8 展平层
展平层将多维特征图转换为一维向量,为输入到全连接层做准备。
flatten_layer = Flatten()(batch_norm_layer)
- 1
1.9 上采样层
上采样是一种用于深度学习的技术,用于增加特征图的空间分辨率。它通常用于图像分割和生成等任务。以下是常见上采样方法的简要描述:
9.1. 最近邻(NN)上采样:最近邻(NN)上采样,也称为通过复制或重复进行上采样,是一种简单直观的方法。在这种方法中,输入中的每个像素都会被复制或重复以生成更大的输出。虽然简单,但 NN 上采样可能会导致块状伪影和细节丢失,因为它不会在相邻像素之间进行插值。
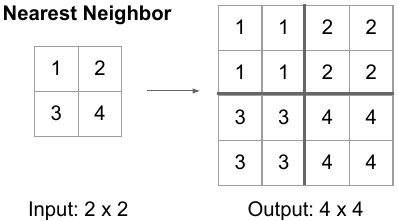
9.2. 转置卷积(反卷积)上采样:转置卷积通常称为反卷积,是一种可学习的上采样方法。它涉及使用具有可学习参数的卷积操作来增加输入的空间维度。转置卷积层中的权重在优化过程中进行训练,允许网络学习特定于任务的上采样模式。
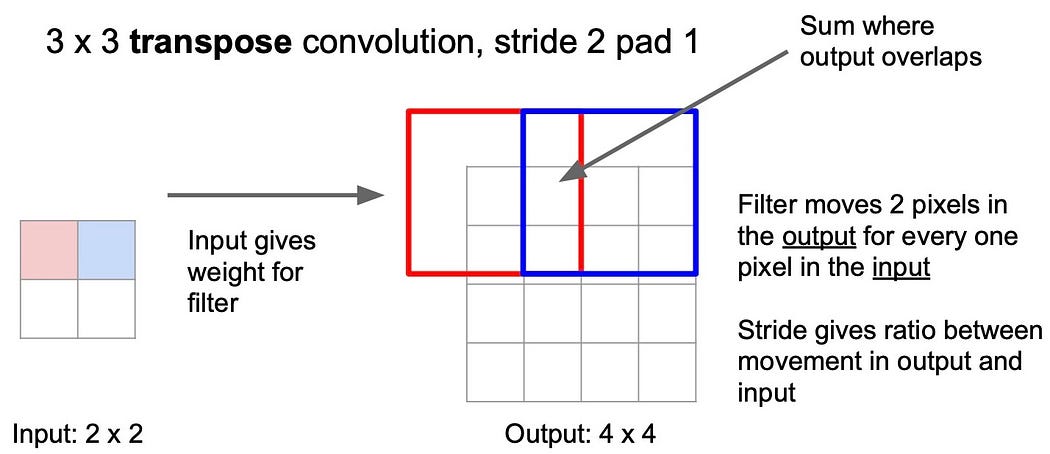
import tensorflow as tf
from tensorflow.keras.layers import Conv2DTranspose
# 转置卷积上采样
transposed_conv_upsampling = Conv2DTranspose(filters=32, kernel_size=(3, 3), strides=(2, 2), padding='same')
- 1
- 2
- 3
- 4
- 5
每种上采样方法都有其优势和权衡,选择取决于任务的具体需求和数据的特性。
二、填充和步长
填充和步长是卷积神经网络(CNNs)中的关键概念,它们会影响卷积操作后输出特征图的大小。让我们讨论三种类型的填充,并解释步长的概念。
2.1 有效填充(无填充)
在有效填充中,也称为无填充,输入在应用卷积操作之前不会添加任何额外的填充。因此,卷积操作仅在滤波器与输入完全重叠的地方进行。这通常会导致输出特征图的空间维度减小。
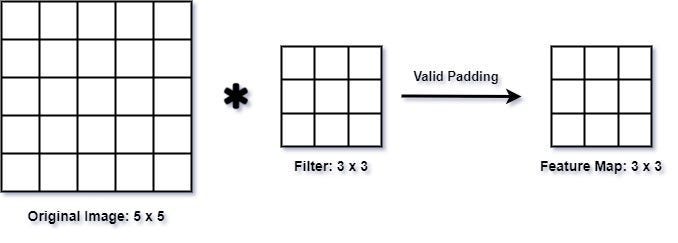
from tensorflow.keras.layers import Conv2D
# 有效填充
valid_padding_conv = Conv2D(filters=32, kernel_size=(3, 3),
strides=(1, 1), padding='valid')
- 1
- 2
- 3
- 4
- 5
2.2 相同填充
相同填充确保输出特征图具有与输入相同的空间维度。它通过向输入添加零填充来实现,使得滤波器可以在输入上滑动而不会超出其边界。填充量会计算以保持维度相同。
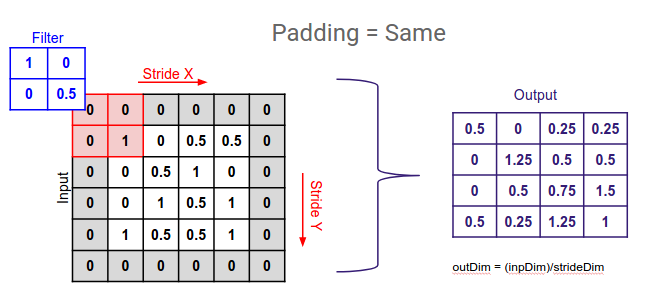
from tensorflow.keras.layers import Conv2D
# 填充在 Keras 中
same_padding_conv = Conv2D(filters=32, kernel_size=(3, 3),
strides=(1, 1), padding='same')
- 1
- 2
- 3
- 4
- 5
2.4 步长
步长定义了滤波器在卷积过程中跨输入移动的步长。较大的步长会导致输出特征图的空间维度减小。步长可以调整以控制网络中的下采样程度。
from tensorflow.keras.layers import Conv2D
# 示例:在 Keras 中带有步长的卷积
conv_with_stride = Conv2D(filters=32, kernel_size=(3, 3),
strides=(2, 2), padding='same')
- 1
- 2
- 3
- 4
- 5
在这个示例中,步长设置为 (2, 2),表示滤波器在水平和垂直方向上每次移动两个像素。步长是一个关键参数,用于控制特征图的空间分辨率并影响网络的感受野。
三、图像分类
下面从头开始构建一个简单的卷积神经网络。来进行计算机视觉中最流行的分类任务之一:猫与狗分类。
3.1 导入库
import tensorflow_datasets as tfds
import tensorflow as tf
from tensorflow.keras import layers
import keras
from keras.models import Sequential, Model
from keras.layers import Dense, Conv2D, Flatten, MaxPooling2D, GlobalAveragePooling2D
from keras.utils import plot_model
import numpy as np
import matplotlib.pyplot as plt
import scipy as sp
import cv2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.2 加载数据:猫与狗数据集
!curl -O https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip
!unzip -q kagglecatsanddogs_5340.zip
!ls
- 1
- 2
- 3
下面的单元格将对图像进行预处理,并在输入到我们的模型之前创建批次。
def augment_images(image, label):
# 转换为浮点数
image = tf.cast(image, tf.float32)
# 归一化像素值
image = (image/255)
# 调整大小为 300 x 300
image = tf.image.resize(image, (300, 300))
return image, label
# 使用上述工具函数对图像进行预处理
augmented_training_data = train_data.map(augment_images)
# 在训练前打乱并创建批次
train_batches = augmented_training_data.shuffle(1024).batch(32)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.3 过滤损坏的图像
在处理大量真实世界的图像数据时,损坏的图像很常见。让我们过滤掉不包含“JFIF”字符串的损坏图像。
import os
num_skipped = 0
for folder_name in ("Cat", "Dog"):
folder_path = os.path.join("PetImages", folder_name)
for fname in os.listdir(folder_path):
fpath = os.path.join(folder_path, fname)
try:
fobj = open(fpath, "rb")
is_jfif = tf.compat.as_bytes("JFIF") in fobj.peek(10)
finally:
fobj.close()
if not is_jfif:
num_skipped += 1
# 删除损坏的图像
os.remove(fpath)
print("Deleted %d images" % num_skipped)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.4 生成 Dataset
image_size = (300, 300)
batch_size = 128
train_ds, val_ds = tf.keras.utils.image_dataset_from_directory(
"PetImages",
validation_split=0.2,
subset="both",
seed=1337,
image_size=image_size,
batch_size=batch_size,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.5 可视化数据
以下是训练数据集中的前 9 张图像。正如你所看到的,标签 1 是“狗”,标签 0 是“猫”。
import matplotlib.pyplot as plt
plt.figure(figsize=(6, 6))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(int(labels[i]))
plt.axis("off")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

狗:1,猫:0
3.6 使用图像数据增强
当你没有一个大型图像数据集时,通过应用随机但现实的变换(如随机水平翻转或小随机旋转)来人为地引入样本多样性是一种很好的做法。这有助于让模型接触到训练数据的不同方面,同时减缓过拟合。
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
]
)
- 1
- 2
- 3
- 4
- 5
- 6
让我们通过反复将 data_augmentation 应用于数据集中的第一张图像,来看看增强后的样本是什么样的:
plt.figure(figsize=(6, 6))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")
- 1
- 2
- 3
- 4
- 5
- 6
- 7

图像增强。(示例:翻转、旋转)
3.7 配置数据集以提高性能
让我们将数据增强应用于我们的训练数据集,并确保使用缓冲预取,以便我们可以在不阻塞 I/O 的情况下从磁盘获取数据。
# 将 `data_augmentation` 应用于训练图像。
train_ds = train_ds.map(
lambda img, label: (data_augmentation(img), label),
num_parallel_calls=tf.data.AUTOTUNE,
)
# 在 GPU 内存中预取样本有助于最大化 GPU 利用率。
train_ds = train_ds.prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.prefetch(tf.data.AUTOTUNE)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.8 构建分类器
这将看起来很熟悉,因为它几乎与我们之前构建的模型相同。关键区别在于输出只是一个单位,使用 Sigmoid 激活。这是因为我们只处理两个类别。
class CustomModel(Sequential):
def __init__(self):
super(CustomModel, self).__```python
super(CustomModel, self).__init__()
self.add(Conv2D(16, input_shape=(300, 300, 3), kernel_size=(3, 3), activation='relu', padding='same'))
self.add(MaxPooling2D(pool_size=(2, 2)))
self.add(Conv2D(32, kernel_size=(3, 3), activation='relu', padding='same'))
self.add(MaxPooling2D(pool_size=(2, 2)))
self.add(Conv2D(64, kernel_size=(3, 3), activation='relu', padding='same'))
self.add(MaxPooling2D(pool_size=(2, 2)))
self.add(Conv2D(128, kernel_size=(3, 3), activation='relu', padding='same'))
self.add(GlobalAveragePooling2D())
self.add(Dense(1, activation='sigmoid'))
# 实例化自定义模型
model = CustomModel()
# 显示模型摘要
model.summary()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
模型的损失函数可以根据之前的设置进行调整,以适应两个类别的分类任务。为此,我们选择 binary_crossentropy。
# 训练大约需要 30 分钟才能完成,如果使用 GPU 的话。
# 如果你的本地机器没有 GPU,可以免费使用 Google Colab 来获取 GPU 访问权限。
model.compile(loss='binary_crossentropy',
metrics=['accuracy'],
optimizer=tf.keras.optimizers.RMSprop(lr=0.001))
model.fit(train_ds,
epochs=25,
validation_data=val_ds,)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.9 测试模型
让我们下载一些图像,看看分类激活图是什么样子的。
!wget -O cat1.jpg https://storage.googleapis.com/laurencemoroney-blog.appspot.com/MLColabImages/cat1.jpg
!wget -O cat2.jpg https://storage.googleapis.com/laurencemoroney-blog.appspot.com/MLColabImages/cat2.jpg
!wget -O catanddog.jpg https://storage.googleapis.com/laurencemoroney-blog.appspot.com/MLColabImages/catanddog.jpg
!wget -O dog1.jpg https://storage.googleapis.com/laurencemoroney-blog.appspot.com/MLColabImages/dog1.jpg
!wget -O dog2.jpg https://storage.googleapis.com/laurencemoroney-blog.appspot.com/MLColabImages/dog2.jpg
- 1
- 2
- 3
- 4
- 5
# 工具函数,用于预处理图像并显示分类激活图
def convert_and_classify(image):
# 加载图像
img = cv2.imread(image)
# 在输入到模型之前对图像进行预处理
img = cv2.resize(img, (300, 300)) / 255.0
# 添加一个批次维度,因为模型需要它
tensor_image = np.expand_dims(img, axis=0)
# 获取特征和预测结果
features, results = cam_model.predict(tensor_image)
# 生成分类激活图
show_cam(tensor_image, features, results)
convert_and_classify('cat1.jpg')
convert_and_classify('cat2.jpg')
convert_and_classify('catanddog.jpg')
convert_and_classify('dog1.jpg')
convert_and_classify('dog2.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3.10 输出


 QQ群名片
QQ群名片

评论记录:
回复评论: