
本文详细介绍了基于扩散模型构建的文本到视频生成系统,展示了在MSRV-TT和Shutterstock视频标注数据集上训练的模型输出结果。以下是模型在不同提示词下的生成示例。
首先展示一些模型生成效果展示
提示词:“A person holding a camera”(训练10K步)

拿相机的人物场景
提示词:“Spaceship crossing the bridge”(训练10K步)

飞船穿过桥梁场景
提示词:“News Reporter speaking”(训练10K步)

新闻记者讲话场景
在Moving Mnist数据集上训练的模型(训练5K步)

使用训练模型生成的合成Moving Mnist数据
扩散模型理论基础
扩散模型是当前文本到视频生成领域的主流架构,被广泛应用于OpenAI Sora、Stable Video Diffusion等系统中。本文将从基本原理出发,实现一个基于扩散原理的架构,构建能够根据文本提示生成视频或GIF的模型系统。
扩散架构核心组件
3D U-Net结构:专为视频处理设计,能够有效处理随时间变化的帧序列。此U-Net架构融合了多重注意力机制:
- 时间注意力:负责捕捉帧间的时序关联
- 空间注意力:处理每一帧内的区域关系
- 这些注意力层与特殊功能模块协同工作,从视频数据中提取关键特征
扩散过程原理:模型的工作机制可以简述为以下步骤:
- 向训练视频添加噪声直至其变为纯随机分布
- 模型学习逆向过程,即从噪声中恢复原始信号
- 生成阶段,从随机噪声出发,模型逐步去除噪声
- 文本提示通过BERT转换为嵌入向量,引导UNet的去噪方向
- 通过反复迭代,最终生成与文本语义匹配的视频内容
为了更直观地理解系统架构,下面是一个简化的模型框架图:
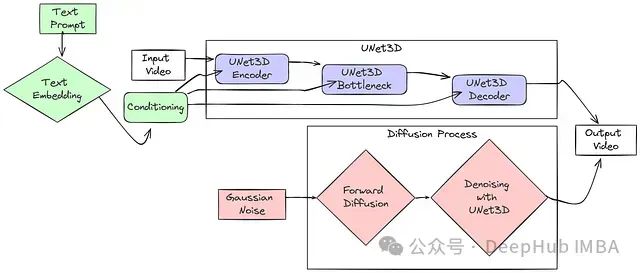
架构工作流程详解
- 输入视频处理:系统以原始视频或随机噪声作为起点
- UNet3D编码阶段:视频通过UNet3D编码器处理,该过程逐步降低空间维度并提取关键特征
- UNet3D瓶颈处理:在最小空间维度处理提取的特征,融合全局信息
- UNet3D解码阶段:处理后的特征被送入解码器,逐步恢复空间维度,重建视频结构
- 文本条件引导:输入的文本提示转换为语义嵌入向量,在UNet3D的各个层级提供引导信号
- 扩散过程实现:- 训练阶段:向视频添加噪声,模型学习预测并去除噪声- 生成阶段:从纯噪声开始,模型利用UNet3D逐步去除噪声,生成目标视频
- 输出视频生成:最终输出基于输入条件(噪声和文本提示)生成的视频序列
项目结构
text2video-from-scratch/
├── configs/
│ └── default.yaml # 训练参数和超参数的配置文件
├── src/
│ ├── architecture/
│ │ ├── attention.py # 包含用于注意力机制的Attention和EinopsToAndFrom类
│ │ ├── blocks.py # 包含Block、ResnetBlock和SpatialLinearAttention类(UNet的构建块)
│ │ ├── common.py # 包含架构中使用的常见层和实用工具
│ │ ├── unet.py # 包含主要的Unet3D模型定义
│ │ └── relative_position_bias.py # 包含用于位置编码的RelativePositionBias类
│ ├── data/
│ │ ├── dataset.py # 定义用于加载和预处理视频数据的Dataset类
│ │ └── utils.py # 处理视频和图像数据的实用函数
│ ├── diffusion/
│ │ └── gaussian_diffusion.py # 包含实现扩散过程的GaussianDiffusion类
│ ├── text/
│ │ └── text_handler.py # 使用预训练BERT模型处理文本输入的函数(标记化,嵌入)
│ ├── trainer/
│ │ └── trainer.py # 包含Trainer类,处理训练循环、优化、EMA、保存和采样
│ └── utils/
│ └── helper_functions.py # 通用辅助函数(exists, noop, is_odd, default, cycle等)
├── train.py # 主训练脚本:加载配置,创建模型,扩散,训练器,并开始训练
├── generate.py # 主生成脚本:加载配置,创建模型,扩散,训练器,并开始生成

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
核心文件说明:
train.py是训练模型的主脚本,负责加载配置、初始化模型组件并启动训练流程generate.py用于利用训练好的模型根据文本提示生成视频内容src目录包含模型架构、数据处理、扩散过程实现、文本处理和训练工具的核心代码
成功实现本项目需要对面向对象编程(OOP)和神经网络(NN)有深入理解。熟悉PyTorch框架将有助于理解和修改代码实现。源代码地址在文章最后
环境配置
首先需要克隆项目仓库并安装依赖:
git clone https://github.com/FareedKhan-dev/text2video-from-scratch
cd text2video-from-scratch
pip install -r requirements.txt
- 1
- 2
- 3
库导入
本项目使用的主要库及其功能:
# 系统操作相关
import os # 文件系统操作
import yaml # 配置文件解析
from pathlib import Path # 跨平台路径处理
import subprocess # 执行系统命令
import zipfile # ZIP文件处理
# 数据处理相关
import pandas as pd # 结构化数据处理
from tqdm import tqdm # 进度显示
# 图像、视频处理
from PIL import Image # 图像处理
from moviepy.editor import VideoFileClip # 视频编辑
from datasets import load_dataset # 数据集加载
# PyTorch核心组件
import torch # 深度学习框架
from torch import nn, einsum # 神经网络构建与张量运算
from torch.nn import functional as F # 函数式API
from torch.utils import data # 数据加载工具
# 张量操作工具
from einops import rearrange # 张量重排
from einops_exts import rearrange_many, check_shape # 扩展张量操作
from rotary_embedding_torch import RotaryEmbedding # 旋转位置编码
# 自然语言处理
from transformers import BertModel, BertTokenizer # BERT模型与分词器
# 其他工具
import copy # 对象复制
from torch.optim import Adam # 优化器
from torch.cuda.amp import autocast, GradScaler # 混合精度训练
import math # 数学函数
import colorsys # 颜色空间转换
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
训练数据准备
为了构建高质量的文本到视频生成模型,我们需要多样化的带标注视频数据集。MSR-VTT(Microsoft Research Video to Text)是理想选择,它包含来自20个类别的10,000个视频剪辑,每个剪辑都有对应的英文描述标注。以下是数据获取与处理的实现方法:
# 使用Kaggle API下载数据集
def download_kaggle_dataset(dataset_name: str, download_dir: str) -> None:
# 确保目录存在
Path(download_dir).mkdir(parents=True, exist_ok=True)
# 调用Kaggle命令行工具下载数据集
command = f"kaggle datasets download {dataset_name} -p {download_dir}"
subprocess.run(command, shell=True, check=True)
# 解压下载的数据文件
def unzip_file(zip_path: str, extract_dir: str) -> None:
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
zip_ref.extractall(extract_dir)
# 可视化数据集中的随机视频样本
def visualize_random_videos(videos_dir: str, num_videos: int = 8) -> None:
# 获取所有MP4文件
video_files = [f for f in os.listdir(videos_dir) if f.endswith('.mp4')]
# 随机抽样指定数量的视频
random_videos = random.sample(video_files, num_videos)
# 创建显示网格
fig, axes = plt.subplots(2, 4, figsize=(12, 6))
axes = axes.ravel()
# 处理并显示每个视频的首帧
for i, video_file in enumerate(random_videos):
video_path = os.path.join(videos_dir, video_file)
# 加载视频并提取前2秒帧
clip = VideoFileClip(video_path).subclip(0, 2)
# 获取首帧并显示
frame = clip.get_frame(0)
axes[i].imshow(frame)
axes[i].axis('off')
axes[i].set_title(f"Video {i+1}")
plt.tight_layout()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
实际执行数据下载与可视化:
# 数据集下载与解压
kaggle_dataset_name = 'vishnutheepb/msrvtt'
download_dir = './msrvtt_data'
unzip_dir = './msrvtt_data/msrvtt'
download_kaggle_dataset(kaggle_dataset_name, download_dir)
zip_file_path = os.path.join(download_dir, 'msrvtt.zip')
unzip_file(zip_file_path, unzip_dir)
# 可视化8个随机视频样本
videos_dir = os.path.join(unzip_dir, 'TrainValVideo')
visualize_random_videos(videos_dir)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

MSRVTT数据集样本展示
为便于训练,我们需要将视频转换为更高效的格式。我们选择将MP4文件转换为GIF格式并创建对应的文本描述文件:
# 创建训练数据集,转换视频格式并准备标注
def create_training_data(videos_dir: str, output_dir: str, size=(64, 64), duration=2) -> None:
Path(output_dir).mkdir(parents=True, exist_ok=True)
video_files = [f for f in os.listdir(videos_dir) if f.endswith('.mp4')]
for video_file in video_files:
video_path = os.path.join(videos_dir, video_file)
base_name = os.path.splitext(video_file)[0]
gif_path = os.path.join(output_dir, f"{base_name}.gif")
txt_path = os.path.join(output_dir, f"{base_name}.txt")
# 视频转GIF处理
clip = VideoFileClip(video_path).subclip(0, duration)
clip = clip.resize(size)
clip.write_gif(gif_path, program='ffmpeg')
# 创建文本描述文件
with open(txt_path, "w") as txt_file:
txt_file.write(f"{base_name}")
print(f"已处理: {video_file} -> {base_name}.gif and {base_name}.txt")
# 执行数据转换
videos_dir = "./msrvtt_data/msrvtt/TrainValVideo"
output_dir = "./training_data"
create_training_data(videos_dir, output_dir)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
经过处理,我们的训练数据将采用以下结构:
training_data/
|── video1.gif
|── video1.txt
|── video2.gif
|── video2.txt
...
- 1
- 2
- 3
- 4
- 5
- 6
此格式便于模型训练过程中高效地加载和处理数据。
辅助函数定义
为了提高代码的可维护性和模块化程度,我们定义了一系列辅助函数,用于处理常见任务如参数检查、数据迭代和掩码生成等:
# 检查变量是否存在(非None)
def exists(x: Union[None, object]) -> bool:
return x is not None
# 空操作函数,接受任意参数但不执行任何操作
def noop(*args, **kwargs) -> None:
pass
# 检查整数是否为奇数
def is_odd(n: int) -> bool:
return (n % 2) == 1
# 返回值或默认值
def default(val: Union[None, object], d: Union[object, Callable[[], object]]) -> object:
if exists(val):
return val
return d() if callable(d) else d
# 数据加载器循环迭代器
def cycle(dl: torch.utils.data.DataLoader) -> torch.utils.data.DataLoader:
while True:
for data in dl:
yield data
# 将总数划分为指定大小的组
def num_to_groups(num: int, divisor: int) -> List[int]:
groups = num // divisor
remainder = num % divisor
arr = [divisor] * groups
if remainder > 0:
arr.append(remainder)
return arr
# 生成概率掩码
def prob_mask_like(shape: Tuple[int, ...], prob: float, device: torch.device) -> torch.Tensor:
if prob == 1:
return torch.ones(shape, device=device, dtype=torch.bool)
elif prob == 0:
return torch.zeros(shape, device=device, dtype=torch.bool)
else:
return torch.zeros(shape, device=device).float().uniform_(0, 1) < prob
# 检查列表或元组是否只包含字符串
def is_list_str(x: Union[List[object], Tuple[object, ...]]) -> bool:
if not isinstance(x, (list, tuple)):
return False
return all([type(el) == str for el in x])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
注意力机制实现
注意力机制是扩散视频生成模型的核心组件,使模型能够有选择地关注输入的重要部分,无论是空间区域、时间帧还是文本信息。以下是注意力模块的实现:
class EinopsToAndFrom(nn.Module):
def __init__(self, from_einops: str, to_einops: str, fn: Callable[[torch.Tensor], torch.Tensor]) -> None:
super().__init__()
self.from_einops = from_einops # 输入形状描述
self.to_einops = to_einops # 目标形状描述
self.fn = fn # 要应用的变换函数
def forward(self, x: torch.Tensor, **kwargs) -> torch.Tensor:
shape = x.shape
# 创建重建原始形状所需的参数字典
reconstitute_kwargs = dict(tuple(zip(self.from_einops.split(' '), shape)))
# 重排张量到目标形状
x = rearrange(x, f'{self.from_einops} -> {self.to_einops}')
# 应用变换函数
x = self.fn(x, **kwargs)
# 恢复原始形状
x = rearrange(x, f'{self.to_einops} -> {self.from_einops}', **reconstitute_kwargs)
return x
class Attention(nn.Module):
def __init__(
self,
dim: int,
heads: int = 4,
dim_head: int = 32,
rotary_emb: Optional[nn.Module] = None
) -> None:
super().__init__()
self.scale = dim_head ** -0.5 # 注意力缩放因子
self.heads = heads
hidden_dim = dim_head * heads
self.rotary_emb = rotary_emb # 可选的旋转位置编码
self.to_qkv = nn.Linear(dim, hidden_dim * 3, bias=False) # QKV投影
self.to_out = nn.Linear(hidden_dim, dim, bias=False) # 输出投影
def forward(
self,
x: torch.Tensor,
pos_bias: Optional[torch.Tensor] = None,
focus_present_mask: Optional[torch.Tensor] = None
) -> torch.Tensor:
n, device = x.shape[-2], x.device
qkv = self.to_qkv(x).chunk(3, dim=-1) # 分离QKV向量
# 如果focus_present_mask全部激活,直接返回值向量
if exists(focus_present_mask) and focus_present_mask.all():
values = qkv[-1]
return self.to_out(values)
# 重排QKV用于多头处理
q, k, v = rearrange_many(qkv, '... n (h d) -> ... h n d', h=self.heads)
q = q * self.scale # 缩放查询向量
# 应用旋转位置编码(如提供)
if exists(self.rotary_emb):
q = self.rotary_emb.rotate_queries_or_keys(q)
k = self.rotary_emb.rotate_queries_or_keys(k)
# 计算注意力分数
sim = einsum('... h i d, ... h j d -> ... h i j', q, k)
# 应用位置偏置(如提供)
if pos_bias is not None:
sim = sim + pos_bias
# 处理焦点掩码
if focus_present_mask is not None and not (~focus_present_mask).all():
attend_all_mask = torch.ones((n, n), device=device, dtype=torch.bool)
attend_self_mask = torch.eye(n, device=device, dtype=torch.bool)
mask = torch.where(
rearrange(focus_present_mask, 'b -> b 1 1 1 1'),
rearrange(attend_self_mask, 'i j -> 1 1 1 i j'),
rearrange(attend_all_mask, 'i j -> 1 1 1 i j'),
)
sim = sim.masked_fill(~mask, -torch.finfo(sim.dtype).max) # 掩码应用
# 数值稳定性优化
sim = sim - sim.amax(dim=-1, keepdim=True).detach()
# 计算注意力权重
attn = sim.softmax(dim=-1)
# 加权汇总值向量
out = einsum('... h i j, ... h j d -> ... h i d', attn, v)
# 重排输出
out = rearrange(out, '... h n d -> ... n (h d)')
return self.to_out(out) # 应用输出投影
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
EinopsToAndFrom 类提供了张量形状转换的灵活机制,使模型能够在不同表示之间高效切换。而 Attention 类实现了多头注意力机制的核心算法,支持位置编码、掩码操作和数值稳定性优化,这些都是高质量视频生成的关键要素。
视频生成模型的基础构建模块
在深度学习视频生成架构中,基础构建模块是整个网络功能的关键组件。我们实现的U-Net架构采用了层次化结构,由多个专用模块组成,每个模块都具有特定的数据转换功能。
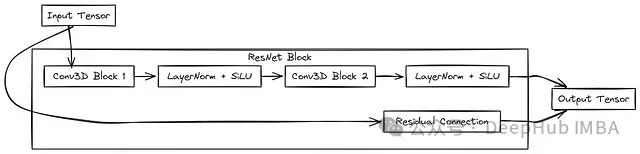
class Block(nn.Module):
def __init__(self, dim: int, dim_out: int) -> None:
super().__init__()
# 初始化具有内核大小(1, 3, 3)和填充(0, 1, 1)的3D卷积层
self.proj = nn.Conv3d(dim, dim_out, (1, 3, 3), padding=(0, 1, 1))
# 初始化输出维度的层归一化
self.norm = nn.LayerNorm(dim_out)
# 初始化SiLU激活函数(Sigmoid线性单元)
self.act = nn.SiLU()
def forward(self, x: torch.Tensor, scale_shift: Optional[Tuple[torch.Tensor, torch.Tensor]] = None) -> torch.Tensor:
# 对输入张量应用3D卷积
x = self.proj(x)
# 对张量应用层归一化
x = self.norm(x)
# 如果提供了缩放和偏移值,则应用它们
if exists(scale_shift):
scale, shift = scale_shift
# 对张量应用缩放和偏移
x = x * (scale + 1) + shift
# 应用SiLU激活函数
return self.act(x)
class ResnetBlock(nn.Module):
def __init__(self, dim: int, dim_out: int, *, time_emb_dim: Optional[int] = None) -> None:
super().__init__()
# 如果指定了time_emb_dim,则创建一个MLP来生成缩放和偏移值
self.mlp = nn.Sequential(
nn.SiLU(),
nn.Linear(time_emb_dim, dim_out * 2)
) if exists(time_emb_dim) else None
# 初始化定义的Block类的两个顺序块
self.block1 = Block(dim, dim_out)
self.block2 = Block(dim_out, dim_out)
# 如果输入和输出维度不同,则应用1x1卷积用于残差连接
self.res_conv = nn.Conv3d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
def forward(self, x: torch.Tensor, time_emb: Optional[torch.Tensor] = None) -> torch.Tensor:
scale_shift = None
# 如果定义了MLP,则处理时间嵌入以生成缩放和偏移因子
if exists(self.mlp):
assert exists(time_emb), 'time_emb must be passed in when time_emb_dim is defined'
time_emb = self.mlp(time_emb) # 通过MLP传递time_emb
time_emb = rearrange(time_emb, 'b c -> b c 1 1 1') # 重塑以启用广播
scale_shift = time_emb.chunk(2, dim=1) # 将时间嵌入分为缩放和偏移
# 应用第一个块,带有可选的缩放/偏移
h = self.block1(x, scale_shift=scale_shift)
# 应用第二个块,不带缩放/偏移
h = self.block2(h)
# 返回带有残差连接的结果
return h + self.res_conv(x)
class SpatialLinearAttention(nn.Module):
def __init__(self, dim: int, heads: int = 4, dim_head: int = 32) -> None:
super().__init__()
# 基于头维度的注意力分数的缩放因子
self.scale = dim_head ** -0.5
self.heads = heads # 注意力头的数量
hidden_dim = dim_head * heads # 多头注意力的总维度
# 1x1卷积,用于生成查询、键和值张量
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
# 注意力计算后用于输出投影的1x1卷积
self.to_out = nn.Conv2d(hidden_dim, dim, 1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 获取输入张量的形状
b, c, f, h, w = x.shape
# 重新排列输入张量以在注意力机制中处理
x = rearrange(x, 'b c f h w -> (b f) c h w')
# 应用1x1卷积计算查询、键和值
qkv = self.to_qkv(x).chunk(3, dim=1)
# 重新排列Q、K、V用于多头注意力
q, k, v = rearrange_many(qkv, 'b (h c) x y -> b h c (x y)', h=self.heads)
# 对查询应用softmax(跨空间位置)
q = q.softmax(dim=-2)
# 对键应用softmax(跨特征)
k = k.softmax(dim=-1)
# 缩放查询
q = q * self.scale
# 基于键和值计算上下文(加权和)
context = torch.einsum('b h d n, b h e n -> b h d e', k, v)
# 通过将查询应用于上下文来计算注意力输出
out = torch.einsum('b h d e, b h d n -> b h e n', context, q)
# 将输出重新排列回原始空间格式
out = rearrange(out, 'b h c (x y) -> b (h c) x y', h=self.heads, x=h, y=w)
# 应用输出卷积,投影回输入维度
out = self.to_out(out)
# 将输出重新排列回原始批量大小和帧数
return rearrange(out, '(b f) c h w -> b c f h w', b=b)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
视频生成架构的基础构建模块包括三个关键组件:
标准卷积块 (Block):作为神经网络的基础单元,实现了输入特征的基本转换处理。该模块采用3D卷积层、层归一化和SiLU激活函数的组合,支持通过scale-shift操作进行条件处理,使其能够根据不同的条件输入(如时间嵌入)动态调整特征响应。
残差块 (ResnetBlock):通过引入跳跃连接增强了网络训练稳定性,有效缓解了深层网络中的梯度消失问题。此模块包含两个串联的标准卷积块,并支持时间条件嵌入,通过MLP网络将时间信息转换为特征调制信号,从而使模型能够根据时间步信息调整特征表示。
空间线性注意力模块 (SpatialLinearAttention):在视频帧的空间维度上实现高效注意力计算,使模型能够捕获图像内的长距离依赖关系。该模块采用了多头注意力设计,分别对查询和键应用softmax操作,实现了对输入特征的自适应加权处理。
这些基础模块具有不同但相互补充的功能:Block模块处理局部特征转换,ResnetBlock增强训练稳定性并支持时间条件,而SpatialLinearAttention则捕获远距离空间依赖关系。通过组合这些模块,模型能够有效处理视频数据的时空复杂性。
视频生成模型的通用组件
视频生成架构需要多种辅助组件来增强模型功能和训练稳定性。这些组件包括参数平滑机制、归一化层和位置编码等,为模型提供了必要的数据处理能力。
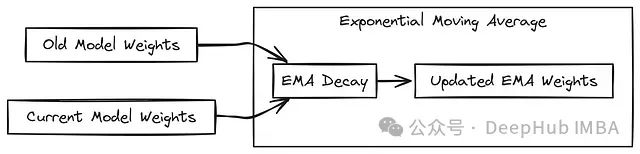
class EMA:
def __init__(self, beta: float) -> None:
super().__init__()
# 存储用于更新移动平均的衰减因子(beta)
self.beta = beta
def update_model_average(self, ma_model: nn.Module, current_model: nn.Module) -> None:
# 使用当前模型的参数更新移动平均模型
for current_params, ma_params in zip(current_model.parameters(), ma_model.parameters()):
# 从移动平均模型获取旧权重,从当前模型获取新权重
old_weight, up_weight = ma_params.data, current_params.data
# 更新移动平均权重
ma_params.data = self.update_average(old_weight, up_weight)
def update_average(self, old: Optional[torch.Tensor], new: torch.Tensor) -> torch.Tensor:
# 如果不存在旧值,则返回新值
if old is None:
return new
# 基于beta和新值更新移动平均
return old * self.beta + (1 - self.beta) * new
class Residual(nn.Module):
def __init__(self, fn: nn.Module) -> None:
super().__init__()
# 存储要在残差块中使用的函数
self.fn = fn
def forward(self, x: torch.Tensor, *args, **kwargs) -> torch.Tensor:
# 应用函数并将输入张量添加到其中,形成残差连接
return self.fn(x, *args, **kwargs) + x
class SinusoidalPosEmb(nn.Module):
def __init__(self, dim: int) -> None:
super().__init__()
# 存储位置嵌入的维度
self.dim = dim
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 获取输入张量的设备
device = x.device
# 正弦和余弦嵌入的一半维度
half_dim = self.dim // 2
# 嵌入范围的缩放因子
emb_scale = math.log(10000) / (half_dim - 1)
# 通过计算缩放arange值的指数创建正弦嵌入
emb = torch.exp(torch.arange(half_dim, device=device) * -emb_scale)
# 根据输入x应用位置编码(正弦)
emb = x[:, None] * emb[None, :]
# 连接嵌入的正弦和余弦变换
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
return emb
def Upsample(dim: int) -> nn.ConvTranspose3d:
# 返回用于上采样的3D转置卷积层
return nn.ConvTranspose3d(dim, dim, (1, 4, 4), (1, 2, 2), (0, 1, 1))
def Downsample(dim: int) -> nn.Conv3d:
# 返回用于下采样的3D卷积层
return nn.Conv3d(dim, dim, (1, 4, 4), (1, 2, 2), (0, 1, 1))
class LayerNorm(nn.Module):
def __init__(self, dim: int, eps: float = 1e-5) -> None:
super().__init__()
# 存储归一化中的数值稳定性的epsilon
self.eps = eps
# 创建可学习的缩放参数(gamma)
self.gamma = nn.Parameter(torch.ones(1, dim, 1, 1, 1))
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 计算输入张量在通道维度上的方差和均值(dim=1)
var = torch.var(x, dim=1, unbiased=False, keepdim=True)
mean = torch.mean(x, dim=1, keepdim=True)
# 通过减去均值并除以方差进行归一化
# 用gamma进行可学习的缩放
return (x - mean) / (var + self.eps).sqrt() * self.gamma
class RMSNorm(nn.Module):
def __init__(self, dim: int) -> None:
super().__init__()
# 基于输入维度(dim)计算缩放因子
self.scale = dim ** 0.5
# 创建可学习的缩放参数(gamma)
self.gamma = nn.Parameter(torch.ones(dim, 1, 1, 1))
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 在维度1(通道)上归一化输入张量并应用缩放
return F.normalize(x, dim=1) * self.scale * self.gamma
class PreNorm(nn.Module):
def __init__(self, dim: int, fn: nn.Module) -> None:
super().__init__()
# 存储归一化后要使用的函数
self.fn = fn
# 用指定维度初始化层归一化
self.norm = LayerNorm(dim)
def forward(self, x: torch.Tensor, **kwargs) -> torch.Tensor:
# 对输入张量应用归一化
x = self.norm(x)
# 将归一化的张量传递给函数(例如,注意力或MLP)
return self.fn(x, **kwargs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
视频生成架构的通用组件提供了多种功能增强机制:
指数移动平均 (EMA):实现了模型参数的平滑更新策略,有效降低训练过程中的参数波动。通过对历史权重和当前权重进行加权平均,提高了模型的泛化能力和推理稳定性。这在视频生成任务中尤为重要,因为它帮助模型产生更连贯的时序输出。
残差连接包装器 (Residual):为任意函数模块添加跳跃连接,促进梯度在深层网络中的高效传播。这种设计不仅简化了残差路径的实现,还提高了整个架构的训练效率。
正弦位置嵌入 (SinusoidalPosEmb):为一维输入(如时间步)生成周期性位置编码,使模型能够区分不同的时间位置。该组件采用正弦和余弦函数的组合,创建了一种具有良好插值特性的嵌入表示。
上采样和下采样函数:分别通过3D转置卷积和标准3D卷积实现特征图的分辨率变换,维持通道数不变的同时改变空间维度。这些操作在U-Net结构的编码器和解码器部分扮演关键角色。
自定义归一化层:实现了多种特化的归一化策略,包括:
- LayerNorm:实现通道维度上的特征归一化,带有可学习的缩放参数
- RMSNorm:提供基于均方根的归一化,计算复杂度更低
- PreNorm:在应用任意函数前执行归一化预处理,稳定深层网络中的信号传播
这些通用组件协同工作,确保了视频生成模型的训练稳定性和生成质量,为处理高维时空数据提供了必要的计算基础。
相对位置编码机制
相对位置编码在处理序列数据时至关重要,它使模型能够理解和利用输入元素之间的相对位置关系,而不依赖于绝对位置信息。这在视频生成等需要捕捉时空依赖关系的任务中尤为关键。
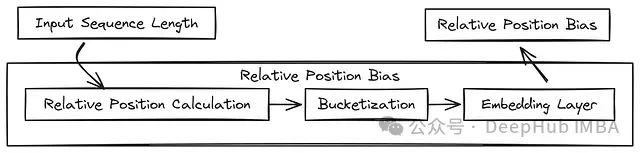
class RelativePositionBias(nn.Module):
def __init__(
self,
heads: int = 8, # 注意力头的数量
num_buckets: int = 32, # 相对位置编码的桶数量
max_distance: int = 128 # 要考虑的最大相对距离
) -> None:
super().__init__()
# 存储相对位置偏置的桶数和最大距离
self.num_buckets = num_buckets
self.max_distance = max_distance
# 为相对注意力偏置初始化嵌入层
self.relative_attention_bias = nn.Embedding(num_buckets, heads)
@staticmethod
def _relative_position_bucket(
relative_position: torch.Tensor,
num_buckets: int = 32,
max_distance: int = 128
) -> torch.Tensor:
# 初始化结果变量(从零开始)
ret = 0
# 取相对位置的负数(处理两个方向)
n = -relative_position
# 将桶数量减半
num_buckets //= 2
# 如果位置为负,将其分配到桶的后半部分
ret += (n < 0).long() * num_buckets
# 获取相对位置的绝对值
n = torch.abs(n)
# 桶的一半将对应确切的距离
max_exact = num_buckets // 2
# 小距离的标志
is_small = n < max_exact
# 对于较大的距离,使用对数尺度计算桶值
val_if_large = max_exact + (
torch.log(n.float() / max_exact) / math.log(max_distance / max_exact) * (num_buckets - max_exact)
).long()
# 确保大距离的值不超过最大桶索引
val_if_large = torch.min(val_if_large, torch.full_like(val_if_large, num_buckets - 1))
# 根据距离是小还是大来更新结果
ret += torch.where(is_small, n, val_if_large)
return ret
def forward(self, n: int, device: torch.device) -> torch.Tensor:
# 创建查询位置(q_pos)张量,范围从0到n-1
q_pos = torch.arange(n, dtype=torch.long, device=device)
# 创建键位置(k_pos)张量,范围从0到n-1
k_pos = torch.arange(n, dtype=torch.long, device=device)
# 计算每个键相对于每个查询的相对位置(形状:n x n)
rel_pos = rearrange(k_pos, 'j -> 1 j') - rearrange(q_pos, 'i -> i 1')
# 为每对查询和键位置计算相对位置桶
rp_bucket = self._relative_position_bucket(
rel_pos,
num_buckets=self.num_buckets,
max_distance=self.max_distance
)
# 从嵌入层获取相应的相对位置偏置
values = self.relative_attention_bias(rp_bucket)
# 重新排列值以匹配预期的输出形状(h, i, j)
return rearrange(values, 'i j h -> h i j')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
RelativePositionBias实现了一种高效的相对位置编码机制,通过桶化处理将相对位置映射到可学习的嵌入空间,具有以下特点:
自适应位置表示:与固定的位置嵌入不同,相对位置偏置学习不同位置元素之间的关系,而非绝对位置,这使模型在泛化到不同长度序列时更加灵活。
非线性桶化机制:通过
_relative_position_bucket
- 1
方法实现了一种智能的相对位置量化策略,对近距离位置使用线性分桶(提供精确表示),对远距离位置使用对数分桶(提供高效表示)。这种设计兼顾了计算效率和表示能力。
方向感知:通过区分正负相对距离,模型能够感知序列元素的相对方向,对于捕捉视频中的时序关系至关重要。
多头兼容设计:通过为每个注意力头生成独立的位置偏置,允许不同注意力头专注于不同类型的位置模式和依赖关系。
可扩展性:通过
num_buckets
- 1
和
max_distance
- 1
参数,该机制可以灵活调整以适应不同长度和复杂度的序列数据。
此位置编码组件通过为自注意力层提供精确的位置信息,使视频生成模型能够更好地理解时间和空间结构,在保持计算效率的同时提高生成质量。
视频数据处理工具
# 将通道数映射到相应图像模式的字典
CHANNELS_TO_MODE = {
1: 'L', # 1通道对应灰度模式('L'模式)
3: 'RGB', # 3通道对应RGB颜色模式
4: 'RGBA' # 4通道对应RGBA颜色模式(带透明度)
}
# 生成器函数,用于从多帧图像(如GIF)中提取所有图像
def seek_all_images(img: Image.Image, channels: int = 3):
# 确保指定的通道数有效
assert channels in CHANNELS_TO_MODE, f'channels {channels} invalid'
# 获取通道数对应的模式
mode = CHANNELS_TO_MODE[channels]
i = 0
while True:
try:
# 寻找图像中的第i帧
img.seek(i)
# 转换图像帧为所需模式并返回
yield img.convert(mode)
except EOFError:
# 帧结束(EOF),跳出循环
break
i += 1
# 将视频张量转换为GIF并保存到指定路径的函数
def video_tensor_to_gif(
tensor: torch.Tensor,
path: str,
duration: int = 120,
loop: int = 0,
optimize: bool = True
):
# 将视频张量中的每一帧转换为PIL图像
images = map(T.ToPILImage(), tensor.unbind(dim=1))
# 解包第一张图像和其余图像
first_img, *rest_imgs = images
# 保存GIF并指定参数
first_img.save(
path,
save_all=True, # 将所有帧保存为GIF的一部分
append_images=rest_imgs, # 将其他帧附加到GIF中
duration=duration, # 设置每帧的持续时间(毫秒)
loop=loop, # 设置GIF的循环次数(0表示无限循环)
optimize=optimize # 启用GIF文件优化
)
# 返回图像列表作为结果
return images
# 将GIF转换为张量(帧序列)的函数
def gif_to_tensor(
path: str,
channels: int = 3,
transform: T.Compose = T.ToTensor()
) -> torch.Tensor:
# 从给定路径打开GIF图像
img = Image.open(path)
# 将GIF中的所有帧转换为张量,应用转换
tensors = tuple(map(transform, seek_all_images(img, channels=channels)))
# 沿帧维度将张量堆叠成单个张量
return torch.stack(tensors, dim=1)
# 恒等函数:返回不变的输入张量
def identity(t, *args, **kwargs):
return t
# 将图像张量归一化到[-1, 1]范围的函数
def normalize_img(t: torch.Tensor) -> torch.Tensor:
# 通过将张量值从[0, 1]缩放到[-1, 1]来归一化
return t * 2 - 1
# 将图像张量反归一化回[0, 1]范围的函数
def unnormalize_img(t: torch.Tensor) -> torch.Tensor:
# 通过将张量值从[-1, 1]缩放到[0, 1]来反归一化
return (t + 1) * 0.5
# 确保张量具有指定帧数的函数
def cast_num_frames(t: torch.Tensor, *, frames: int) -> torch.Tensor:
# 获取张量中当前的帧数
f = t.shape[1]
if f == frames:
# 如果帧数已经符合要求,则返回不变的张量
return t
if f > frames:
# 如果帧数超过需要,则截取张量到所需帧数
return t[:, :frames]
# 如果帧数不足,则用零填充张量(无新帧)
return torch.nn.functional.padding(t, (0, 0, 0, 0, 0, frames - f))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
上述工具函数集实现了对视频和帧序列数据的多种处理能力。
seek_all_images
- 1
函数提供了从多帧图像(如GIF)中逐帧提取单帧的机制,而
video_tensor_to_gif
- 1
允许将模型生成的视频张量转换为标准GIF格式并保存至存储设备。与此相对应,
gif_to_tensor
- 1
则实现了从GIF文件到PyTorch张量的转换,便于后续的神经网络处理。
此外,辅助函数如
normalize_img
- 1
和
unnormalize_img
- 1
提供了图像值域在标准化区间([-1,1])与图像标准区间([0,1])之间的双向转换,这是深度学习模型处理图像数据的常见需求。
cast_num_frames
- 1
函数则灵活处理视频帧数调整,通过截取或填充操作确保视频序列符合模型的输入要求。
数据集转换实现
为了支持扩散模型的训练过程,我们实现了专用的数据集类,用于高效处理视频数据与对应的文本描述。该类确保数据以PyTorch可用的批次形式加载,同时实现了必要的预处理转换。
# 用于处理GIF或视频文件的自定义数据集类
class Dataset(data.Dataset):
# 使用所需参数初始化数据集
def __init__(
self,
folder: str, # 存储数据集的文件夹路径
image_size: int, # 每个图像调整到的大小
channels: int = 3, # 颜色通道数(默认为3,RGB)
num_frames: int = 16, # 每个视频提取的帧数(默认为16)
horizontal_flip: bool = False, # 是否应用水平翻转增强
force_num_frames: bool = True, # 是否强制视频张量具有确切的`num_frames`帧数
exts: List[str] = ['gif'] # 要查找的文件扩展名列表(默认为['gif'])
) -> None:
# 调用父构造函数(来自PyTorch的Dataset)
super().__init__()
# 初始化数据集属性
self.folder = folder
self.image_size = image_size
self.channels = channels
# 获取文件夹(及子文件夹)中与给定扩展名匹配的所有文件路径
self.paths = [
p for ext in exts for p in Path(f'{folder}').glob(f'**/*.{ext}')
]
# 定义必要时用于转换帧数的函数
# 如果`force_num_frames`为True,我们应用`cast_num_frames`函数,否则使用恒等函数
self.cast_num_frames_fn = partial(cast_num_frames, frames=num_frames) if force_num_frames else identity
# 定义要应用于每个图像的转换(调整大小、随机翻转、裁剪和转换为张量)
self.transform = T.Compose([
T.Resize(image_size), # 将图像调整到目标大小
T.RandomHorizontalFlip() if horizontal_flip else T.Lambda(identity), # 如果指定则应用随机水平翻转
T.CenterCrop(image_size), # 中心裁剪图像到目标大小
T.ToTensor() # 将图像转换为PyTorch张量
])
# 返回数据集中样本的总数
def __len__(self) -> int:
return len(self.paths)
# 通过索引获取特定样本(图像及其对应文本,如果有)
def __getitem__(self, index: int) -> Tuple[torch.Tensor, Optional[str]]:
# 获取给定索引的样本文件路径
path = self.paths[index]
# 使用`gif_to_tensor`函数将GIF(或视频)转换为张量
# 应用先前定义的转换
tensor = gif_to_tensor(path, self.channels, transform=self.transform)
# 将张量转换为具有正确帧数(如果需要)
tensor = self.cast_num_frames_fn(tensor)
# 检查此图像是否有对应的文本文件(相同名称,.txt扩展名)
text_path = path.with_suffix(".txt")
if text_path.exists():
# 如果文本文件存在,读取其内容
with open(text_path, 'r') as f:
text = f.read()
# 返回张量和文件中的文本
return tensor, text
else:
# 如果没有文本文件,返回张量,文本为`None`
return tensor, None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
Dataset
- 1
类提供了完整的视频数据加载解决方案,通过初始化时接收的参数灵活配置数据处理行为。它在实例化过程中扫描指定文件夹中符合条件的视频文件,并建立转换管道用于图像处理。该类支持数据集大小查询和基于索引的数据获取,核心功能包括:
- 通过
__init__方法配置数据源位置、图像尺寸、通道数和预处理参数 - 利用
__len__方法返回数据集的样本总数 - 通过
__getitem__方法检索指定索引的视频数据及其对应文本描述
此数据集类支持数据增强(如水平翻转),帧数调整,并处理视频与文本的自动关联匹配,为模型训练提供高质量的数据流。
高斯扩散过程
高斯扩散过程是本系统生成视频的核心机制,负责实现视频的逐步去噪生成。该过程模拟了从随机噪声逐渐恢复有意义视频内容的过程,通过深度神经网络指导每一步去噪。

高斯扩散原理示意图
# 根据时间步从张量中提取值的辅助函数
def extract(a: torch.Tensor, t: torch.Tensor, x_shape: torch.Size) -> torch.Tensor:
b, *_ = t.shape # 获取批量大小
out = a.gather(-1, t) # 根据时间步提取值
return out.reshape(b, *((1,) * (len(x_shape) - 1))) # 重塑以匹配输入形状
# 为beta创建余弦调度的函数
def cosine_beta_schedule(timesteps: int, s: float = 0.008) -> torch.Tensor:
steps = timesteps + 1
x = torch.linspace(0, timesteps, steps, dtype=torch.float64) # 创建时间网格
alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * torch.pi * 0.5) ** 2 # 余弦函数
alphas_cumprod = alphas_cumprod / alphas_cumprod[0] # 归一化
betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1]) # 计算beta值
return torch.clip(betas, 0, 0.9999) # 确保beta值保持在范围内
# 高斯扩散模型的主类
class GaussianDiffusion(nn.Module):
def __init__(self, denoise_fn: nn.Module, *, image_size: int, num_frames: int, timesteps: int = 1000):
super().__init__()
self.denoise_fn = denoise_fn
self.image_size = image_size
self.num_frames = num_frames
betas = cosine_beta_schedule(timesteps) # 获取beta调度
# 初始化模型计算的各种张量
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.)
timesteps, = betas.shape
self.num_timesteps = int(timesteps)
# 注册缓冲区(不通过梯度下降更新的张量)
register_buffer = lambda name, val: self.register_buffer(name, val.to(torch.float32))
register_buffer('betas', betas)
register_buffer('alphas_cumprod', alphas_cumprod)
register_buffer('alphas_cumprod_prev', alphas_cumprod_prev)
# 更多初始化,用于各种系数(用于计算后验和前向过程)
register_buffer('sqrt_alphas_cumprod', torch.sqrt(alphas_cumprod))
register_buffer('sqrt_one_minus_alphas_cumprod', torch.sqrt(1. - alphas_cumprod))
register_buffer('log_one_minus_alphas_cumprod', torch.log(1. - alphas_cumprod))
# 计算q分布的均值、方差和对数方差的函数
def q_mean_variance(self, x_start: torch.Tensor, t: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
mean = extract(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
variance = extract(1. - self.alphas_cumprod, t, x_start.shape)
log_variance = extract(self.log_one_minus_alphas_cumprod, t, x_start.shape)
return mean, variance, log_variance
# 从噪声数据预测图像起点的函数
def predict_start_from_noise(self, x_t: torch.Tensor, t: torch.Tensor, noise: torch.Tensor) -> torch.Tensor:
return (
extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
)
# 计算后验分布的函数
def q_posterior(self, x_start: torch.Tensor, x_t: torch.Tensor, t: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
posterior_mean = (
extract(self.posterior_mean_coef1, t, x_t.shape) * x_start +
extract(self.posterior_mean_coef2, t, x_t.shape) * x_t
)
posterior_variance = extract(self.posterior_variance, t, x_t.shape)
posterior_log_variance_clipped = extract(self.posterior_log_variance_clipped, t, x_t.shape)
return posterior_mean, posterior_variance, posterior_log_variance_clipped
# 使用模型预测进行去噪的函数
def p_mean_variance(self, x: torch.Tensor, t: torch.Tensor, clip_denoised: bool) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
x_recon = self.predict_start_from_noise(x, t=t, noise=self.denoise_fn(x))
if clip_denoised: # 如果需要,对去噪后的图像进行裁剪
x_recon = x_recon.clamp(-1., 1.)
model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start=x_recon, x_t=x, t=t)
return model_mean, posterior_variance, posterior_log_variance
# 单个去噪步骤的函数
@torch.inference_mode()
def p_sample(self, x: torch.Tensor, t: torch.Tensor) -> torch.Tensor:
model_mean, _, model_log_variance = self.p_mean_variance(x=x, t=t, clip_denoised=True)
noise = torch.randn_like(x) # 添加随机噪声
return model_mean + noise * (0.5 * model_log_variance).exp() # 返回去噪后的图像
# 生成样本的函数(整个循环)
@torch.inference_mode()
def p_sample_loop(self, shape: torch.Size) -> torch.Tensor:
img = torch.randn(shape, device=self.device) # 从随机噪声开始
for t in reversed(range(self.num_timesteps)): # 迭代去噪
img = self.p_sample(img, t)
return (img + 1) * 0.5 # 返回适当范围内的最终图像
# 生成一批样本的函数
@torch.inference_mode()
def sample(self, batch_size: int = 16) -> torch.Tensor:
return self.p_sample_loop((batch_size, self.channels, self.num_frames, self.image_size, self.image_size))
# 计算噪声图像和去噪图像之间的损失(如L1损失)的函数
def p_losses(self, x_start: torch.Tensor, t: torch.Tensor, noise: torch.Tensor = None) -> torch.Tensor:
x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise) # 向图像添加噪声
x_recon = self.denoise_fn(x_noisy, t) # 使用模型去噪
# 计算噪声输出和去噪输出之间的损失
return F.l1_loss(noise, x_recon)
# 模型的前向传递
def forward(self, x: torch.Tensor) -> torch.Tensor:
t = torch.randint(0, self.num_timesteps, (x.shape[0],)) # 随机时间步
return self.p_losses(x, t) # 计算损失
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
GaussianDiffusion
- 1
类实现了扩散过程的核心机制,它基于指定的去噪网络构建完整的视频生成流程。该类在初始化时计算扩散过程所需的各种参数,包括基于余弦调度的噪声水平控制。主要组件包括:
- 前向扩散过程:通过
q_sample方法向原始视频添加噪声 - 反向去噪过程:通过
p_sample和p_sample_loop方法从纯噪声逐步恢复视频内容 - 损失计算:
p_losses方法衡量预测噪声与实际噪声之间的差异 - 条件生成:
sample方法支持基于文本条件的视频生成
扩散过程的精妙之处在于通过数学建模将视频生成分解为多步有监督去噪任务,每一步都基于神经网络对噪声分布的准确预测,最终实现从纯噪声到高质量视频的演化。
文本处理模块
为了实现文本条件引导的视频生成,我们需要将文本转换为神经网络可处理的向量表示。下面实现了基于BERT的文本编码系统:

# 检查值是否存在(不为None)的函数
def exists(val: Optional[Union[torch.Tensor, any]]) -> bool:
return val is not None
# 将模型和标记器变量初始化为None
MODEL: Optional[BertModel] = None
TOKENIZER: Optional[BertTokenizer] = None
BERT_MODEL_DIM: int = 768 # BERT模型输出的维度大小
# 获取BERT模型标记器的函数
def get_tokenizer() -> BertTokenizer:
global TOKENIZER
if not exists(TOKENIZER): # 如果标记器尚未加载
TOKENIZER = BertTokenizer.from_pretrained('bert-base-cased') # 加载标记器
return TOKENIZER
# 获取BERT模型的函数
def get_bert() -> BertModel:
global MODEL
if not exists(MODEL): # 如果模型尚未加载
MODEL = BertModel.from_pretrained('bert-base-cased') # 加载BERT模型
if torch.cuda.is_available(): # 如果GPU可用
MODEL = MODEL.cuda() # 将模型移至GPU
return MODEL
# 对输入文本(单个字符串或字符串列表)进行分词的函数
def tokenize(texts: Union[str, List[str], Tuple[str]]) -> torch.Tensor:
if not isinstance(texts, (list, tuple)): # 如果输入是单个字符串,将其转换为列表
texts = [texts]
tokenizer = get_tokenizer() # 获取标记器
encoding = tokenizer.batch_encode_plus(
texts, # 输入文本
add_special_tokens=True, # 为BERT添加特殊标记
padding=True, # 将序列填充到相同长度
return_tensors='pt' # 作为PyTorch张量返回
)
return encoding.input_ids # 返回标记ID(数值表示)
# 从标记ID获取BERT嵌入(特征)的函数
@torch.no_grad() # 推理时不需要跟踪梯度
def bert_embed(
token_ids: torch.Tensor,
return_cls_repr: bool = False, # 是否仅返回[CLS]标记表示
eps: float = 1e-8, # 小值,防止除零
pad_id: int = 0 # 填充标记ID(BERT通常为0)
) -> torch.Tensor:
model = get_bert() # 获取BERT模型
mask = token_ids != pad_id # 为填充标记创建掩码(忽略它们)
if torch.cuda.is_available(): # 如果GPU可用,将张量移至GPU
token_ids = token_ids.cuda()
mask = mask.cuda()
# 运行BERT模型并获取输出(所有层的隐藏状态)
outputs = model(
input_ids=token_ids,
attention_mask=mask, # 只关注非填充标记
output_hidden_states=True # 获取所有层的隐藏状态
)
hidden_state = outputs.hidden_states[-1] # 获取最后的隐藏状态(最后一层)
if return_cls_repr: # 如果我们需要[CLS]标记表示,则返回它
return hidden_state[:, 0]
# 如果没有掩码,返回所有隐藏状态的平均值
if not exists(mask):
return hidden_state.mean(dim=1)
# 如果有掩码,计算忽略填充标记的平均值
mask = mask[:, 1:] # 移除第一个标记的填充
mask = rearrange(mask, 'b n -> b n 1') # 重新排列以便广播
numer = (hidden_state[:, 1:] * mask).sum(dim=1) # 对掩码标记求和
denom = mask.sum(dim=1) # 计算非填充标记的数量
masked_mean = numer / (denom + eps) # 计算掩码平均值(避免除零)
return masked_mean # 返回最终嵌入(平均值或[CLS]表示)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
文本处理模块提供了从自然语言文本到语义向量的转换能力,是文本条件视频生成的关键组件。该模块采用预训练的BERT模型将文本转换为上下文感知的嵌入向量,实现了以下核心功能:
- 惰性加载机制:通过全局变量和初始化检查,确保BERT模型和分词器只加载一次
- 文本分词:将原始文本转换为BERT可处理的标记ID序列
- 向量嵌入提取:从BERT模型获取文本的语义表示,支持多种嵌入方式- 句子级表示:使用[CLS]标记作为整个文本的表示- 平均池化表示:对所有非填充标记的隐藏状态进行平均
这些文本嵌入随后被注入到扩散模型中,引导视频生成过程朝向与文本语义一致的方向发展,实现"文本到视频"的精确转换。
训练器设计
训练器模块封装了模型训练的完整流程,包括数据加载、优化、模型保存等关键环节。下面是训练器的核心实现:
class Trainer:
def __init__(self, diffusion_model: nn.Module, folder: str, *, ema_decay: float = 0.995, train_batch_size: int = 32,
train_lr: float = 1e-4, train_num_steps: int = 100000, gradient_accumulate_every: int = 2, amp: bool = False,
save_model_every: int = 1000, results_folder: str = './results'):
# 初始化训练器、数据集、优化器和其他配置
self.model = diffusion_model # 扩散模型
self.ema = EMA(ema_decay) # 用于平均权重的EMA模型
self.ema_model = copy.deepcopy(self.model) # EMA的副本
self.batch_size = train_batch_size # 批量大小
self.train_num_steps = train_num_steps # 总训练步数
self.ds = Dataset(folder, image_size=diffusion_model.image_size) # 视频数据集
self.dl = cycle(torch.utils.data.DataLoader(self.ds, batch_size=train_batch_size, shuffle=True)) # 数据加载器
self.opt = Adam(diffusion_model.parameters(), lr=train_lr) # 优化器
self.step = 0 # 步数计数器
self.amp = amp # 混合精度标志
self.scaler = GradScaler(enabled=amp) # 用于混合精度的缩放器
self.results_folder = Path(results_folder) # 保存结果的文件夹
self.results_folder.mkdir(exist_ok=True, parents=True) # 如果不存在则创建结果文件夹
def reset_parameters(self):
# 重置EMA模型以匹配模型的参数
self.ema_model.load_state_dict(self.model.state_dict())
def step_ema(self):
# 如果训练步数超过阈值,则更新EMA模型
if self.step >= 2000: # 2000步后开始更新EMA
self.ema.update_model_average(self.ema_model, self.model)
def save(self, milestone: int):
# 在里程碑保存模型、EMA模型和优化器状态
torch.save({'step': self.step, 'model': self.model.state_dict(), 'ema': self.ema_model.state_dict(), 'scaler': self.scaler.state_dict()},
self.results_folder / f'model-{milestone}.pt')
def load(self, milestone: int):
# 从检查点加载模型
data = torch.load(self.results_folder / f'model-{milestone}.pt')
self.step = data['step']
self.model.load_state_dict(data['model'])
self.ema_model.load_state_dict(data['ema'])
self.scaler.load_state_dict(data['scaler'])
def train(self, log_fn: Callable[[dict], None] = noop):
# 训练循环
while self.step < self.train_num_steps:
for _ in range(self.gradient_accumulate_every): # 在多个步骤上累积梯度
data = next(self.dl) # 加载数据
video_data, text_data = data[0].cuda(), data[1] if len(data) == 2 else None # 将数据移至GPU
with autocast(enabled=self.amp): # 混合精度
loss = self.model(video_data, cond=text_data) # 前向传递
self.scaler.scale(loss / self.gradient_accumulate_every).backward() # 反向传播损失
print(f'{self.step}: {loss.item()}') # 打印损失
if self.step % 10 == 0: # 每10步更新EMA
self.step_ema()
# 如有必要,使用梯度裁剪的优化器步骤
self.scaler.unscale_(self.opt)
nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
self.scaler.step(self.opt)
self.scaler.update()
self.opt.zero_grad()
# 每指定步数保存模型
if self.step % self.save_model_every == 0:
self.save(self.step // self.save_model_every)
log_fn({'loss': loss.item()}) # 记录损失
self.step += 1 # 增加步数
print('训练完成。')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
Trainer
- 1
类提供了扩散模型训练的完整框架,集成了现代深度学习训练技术,包括:
- 模型权重管理:通过指数移动平均(EMA)机制维护模型参数的平滑版本
- 优化控制:支持混合精度训练、梯度累积和梯度裁剪,提高训练效率和稳定性
- 检查点机制:定期保存模型状态,支持训练中断后的恢复
- 数据流管理:高效处理视频数据与文本描述的批次加载
训练器类的设计充分考虑了扩散模型训练的特殊需求,通过配置参数如批量大小、学习率和训练步数等,可以灵活适应不同的训练场景和计算资源。整体训练流程由
train
- 1
方法协调,它实现了数据加载、前向传播、损失计算、反向传播和参数更新的完整循环。
配置系统
为确保模型训练和推理过程的可复现性和灵活性,我们实现了配置系统来管理所有相关参数:
# 内容:用于使用文本到视频扩散训练TinySora模型的默认配置文件
training_data_dir: "./training_data" # 包含训练数据(文本和视频帧)的目录
model:
dim: 64 # 模型的维度(嵌入大小)
use_bert_text_cond: True # 为模型输入启用基于BERT的文本条件
dim_mults: [1, 2, 4, 8] # 每个模型块的缩放因子(增加深度)
init_dim: null # 初始维度,未指定(默认为None)
init_kernel_size: 7 # 初始层的内核大小(通常用于卷积层)
use_sparse_linear_attn: True # 为效率启用稀疏注意力机制
block_type: "basic" # 模型块的类型(例如,'basic'、'resnet'等)
diffusion:
image_size: 32 # 视频帧的高度和宽度
num_frames: 5 # 视频中的帧数(序列长度)
timesteps: 10 # 训练期间使用的扩散时间步数
loss_type: "l1" # 优化的损失函数('l1'表示L1损失)
use_dynamic_thres: False # 是否在训练期间使用动态阈值
dynamic_thres_percentile: 0.9 # 用于动态阈值的阈值百分比
trainer:
ema_decay: 0.995 # 模型权重的指数移动平均衰减率
train_batch_size: 2 # 训练期间每批的样本数
train_lr: 0.0001 # 训练学习率
train_num_steps: 10000 # 总训练步数(轮次)
gradient_accumulate_every: 1 # 梯度累积频率(1表示不累积)
amp: False # 是否使用自动混合精度进行训练(默认:False)
step_start_ema: 2000 # 开始应用EMA平滑的步骤
update_ema_every: 10 # 更新EMA权重的频率(每10步)
save_model_every: 10 # 每10步保存一次模型
results_folder: "./saved_models" # 保存结果(模型、样本)的文件夹
num_sample_rows: 4 # 采样期间显示的行数(可视化)
max_grad_norm: null # 用于裁剪的最大梯度范数(null表示不裁剪)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
配置系统采用YAML格式,将参数组织为三个主要部分:
- 模型配置:定义了架构规模和特性,如维度、注意力机制类型和文本条件使用
- 扩散过程配置:设置了图像尺寸、帧数和扩散步数等关键参数
- 训练器配置:管理训练流程的各方面,包括批量大小、学习率和保存频率
这种参数化设计使研究者能够在不修改代码的情况下轻松调整模型行为,便于进行实验和比较不同配置的效果。
模型初始化与训练
完成所有组件的定义后,我们可以初始化模型并启动训练过程:
# 使用模型的配置参数初始化3D U-Net模型。
# 此模型被移动到GPU(cuda)。
model = Unet3D(**config['model']).cuda()
# 以U-Net模型作为去噪函数初始化GaussianDiffusion模型。
# 从`config['diffusion']`加载扩散过程的其他配置参数。
# 模型被移动到GPU(cuda)。
diffusion = GaussianDiffusion(
denoise_fn = model, # 该模型将用于在扩散过程中去除噪声图像。
**config['diffusion'] # 其他扩散设置,如时间步、噪声调度等。
).cuda()
# 使用扩散模型、训练配置和包含训练数据的文件夹初始化Trainer类。
# 这也被移动到GPU。
trainer = Trainer(
diffusion_model = diffusion, # 要训练的扩散模型。
**config['trainer'], # 训练过程的配置设置(例如,学习率、批量大小)。
folder = config['training_data_dir'] # 存储训练数据的目录。
)
# 开始训练
trainer.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
训练过程会在每次迭代后显示损失值,输出类似于:
0: 0.9512512
1: 0.5235211
...
- 1
- 2
- 3
训练完成后,模型权重将保存在配置的
results_folder
- 1
目录中,随时可用于视频生成。
视频生成实现
要使用训练好的模型生成视频,我们需要实现以下辅助函数:
def generate_video(diffusion: GaussianDiffusion, text: str, batch_size: int, cond_scale: float) -> torch.Tensor:
"""使用训练好的扩散模型生成视频。"""
with torch.no_grad():
video = diffusion.sample(cond=[text], batch_size=batch_size, cond_scale=cond_scale)
return video
def save_video_as_gif_pil(video_tensor: torch.Tensor, output_path: str) -> None:
video_np = (video_tensor.squeeze(0).permute(1, 2, 3, 0).cpu().numpy() * 255).astype(np.uint8)
frames = [Image.fromarray(frame) for frame in video_np]
frames[0].save(output_path, save_all=True, append_images=frames[1:], duration=100, loop=0)
print(f"已保存GIF:{output_path}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
以下是使用训练好的模型生成视频的完整流程:
# 对于推理,我们应该加载预训练模型
DEFAULT_MODEL_PATH = "./saved_models"
DEFAULT_OUTPUT_DIR = "./results"
# 找到最新的模型检查点
model_path = DEFAULT_MODEL_PATH
if os.path.isdir(model_path):
checkpoint_files = [f for f in os.listdir(model_path) if f.endswith(".pt")]
if not checkpoint_files:
raise FileNotFoundError(f"在{model_path}中未找到模型检查点")
checkpoint_files.sort()
model_path = os.path.join(model_path, checkpoint_files[-1])
print('从路径加载模型:', model_path)
trainer.load(milestone=-1) # 加载最新模型
# 生成视频
text_prompt = "News Reporter talking"
batch_size = 1
cond_scale = 2.0
generated_video = generate_video(diffusion, text_prompt, batch_size, cond_scale)
# 保存视频
gif_filename = sanitize_filename(text_prompt) + ".gif"
output_path = os.path.join(DEFAULT_OUTPUT_DIR, gif_filename)
# 如果输出目录不存在,则创建
Path(DEFAULT_OUTPUT_DIR).mkdir(parents=True, exist_ok=True)
save_video_as_gif_pil(generated_video, output_path)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
模型生成的视频示例(经过10K轮训练):

"新闻记者讲话"提示生成的视频
未来研究方向
本项目可通过以下方向进一步拓展和优化:
- 数据多样化:除MSR-VTT外,可使用COCO或ActivityNet等数据集进行训练,或针对特定应用场景收集定制数据
- 架构改进:- 增加时间分辨率,生成更长的视频序列- 提高空间分辨率,生成更高清的视频内容
- 训练策略优化:- 实现渐进式训练,先学习低分辨率再提升到高分辨率- 探索不同的噪声调度方案
- 新的条件控制:- 添加姿态引导或布局控制- 结合图像和文本作为混合条件
通过以上改进,可以构建更强大、生成更高质量视频的系统,进一步推动文本到视频生成技术的发展。
github地址:
https://avoid.overfit.cn/post/88567712b4f547469d74113f6d0810e0
—— 作者:Fareed Khan

 微信公众号
微信公众号

评论记录:
回复评论: