

智谱清影的魅力:使用CogVideoX-2b生成6秒视频的真实体验!
在8月6日,智谱 AI 发布了一则令人振奋的消息:他们决定开源其视频生成模型CogVideoX。
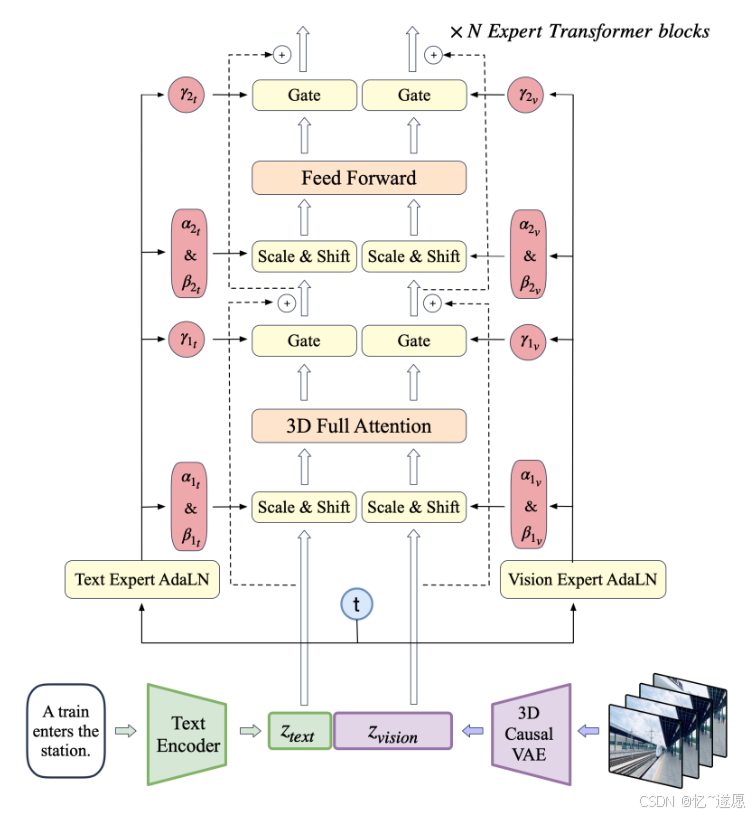
1 3D变分自编码器与3D RoPE
作为一名开发者,我近期才来体验这个新工具,多少有点姗姗来迟的感觉。
作为一名开发者,我近期才来体验这个新工具,多少有点姗姗来迟的感觉。
当前的模型支持的提示词上限为226个token,能够生成长度为6秒的视频,帧率为8帧/秒,分辨率达到720x480。
这仅仅是模型的初版,未来更高性能、更大参数量的版本也在计划中,这让我对其未来充满期待。
CogVideoX的核心技术是3D变分自编码器,这项技术极大地优化了视频数据的处理效率。
通过将视频数据压缩至原来的2%,它显著降低了计算资源的需求,这在我的实际使用中表现得尤为明显。
以往处理视频生成时常常会面临资源不足的问题,但使用CogVideoX后,我能在较低配置的设备上顺利运行,这让我感到非常满意。
2 精确描述与多样化输入
该技术有效保持了视频帧之间的连贯性,有效避免了生成过程中常见的闪烁问题,这一细节无疑提升了用户体验。
为了进一步提升内容的连贯性,CogVideoX引入了3D旋转位置编码(3D RoPE)技术。
这项技术让我在处理视频时,能够更好地捕捉到时间维度上的帧间关系,构建出视频中长期的依赖关系。
这意味着我生成的视频序列更加流畅,观看体验显著提升。
每个帧之间的过渡变得自然,让我产生了一种“观看电影”的感觉,而不是简单的帧拼接。

在可控性方面,智谱 AI 还研发了一款端到端的视频理解模型,这一创新让我眼前一亮。
这个模型能够生成与视频内容紧密相关的精确描述,这对于需要为生成视频添加注释或解释的场景而言,无疑是一个巨大的助力。
通过与文本的高相关性,CogVideoX确保生成的视频不仅能贴合用户输入,还能够处理更长且复杂的文本提示。
这为我在制作内容时,提供了更多的创造空间。
我在使用CogVideoX时,尝试了多个不同类型的输入。
从简单的描述到复杂的故事情节,模型都能够迅速理解并生成相应的视频。

这种高度的灵活性让我能够快速迭代,探索不同的创意方向。
在与其他视频生成工具的对比中,CogVideoX的反应速度和生成质量让我深感惊艳。
虽然我在最初的实验中也遇到了一些挑战,例如对特定指令的理解并不总是准确,但随着使用次数的增加,模型的表现也逐渐改善。
这让我意识到,随着对模型的熟悉和反馈的不断优化,CogVideoX的潜力可以得到充分挖掘。
3 配置环境和依赖
丹摩平台已预置了调试好的代码库,可开箱即用。
- 进入 JupyterLab 后,打开终端,首先拉取
CogVideo代码的仓库。
wget http://file.s3/damodel-openfile/CogVideoX/CogVideo-main.tar
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
 class="blog_extension_card_cont">
class="blog_extension_card_cont">


评论记录:
回复评论: