



快速排序算法
(1) 快速排序法
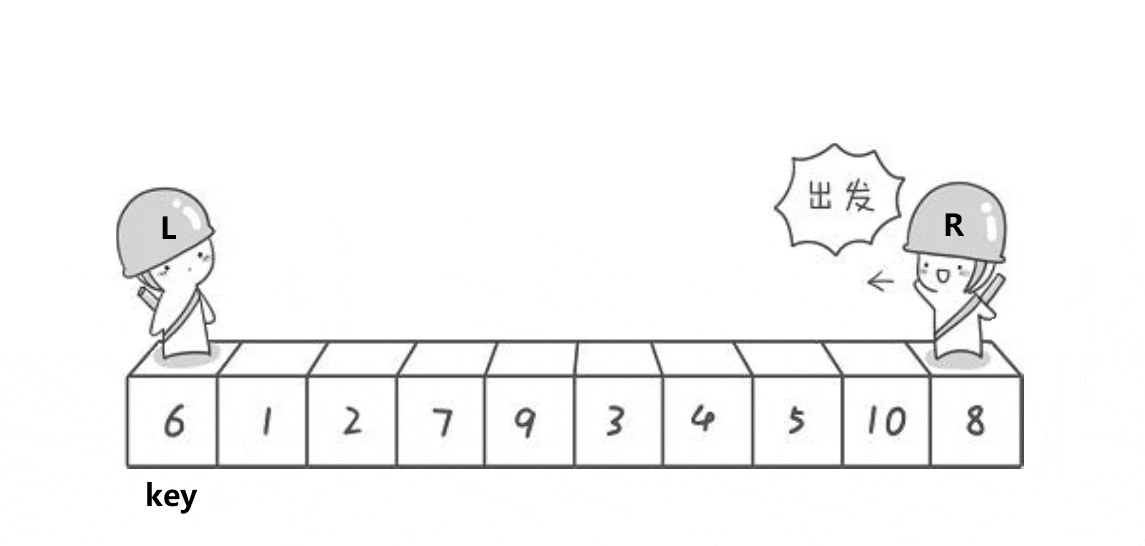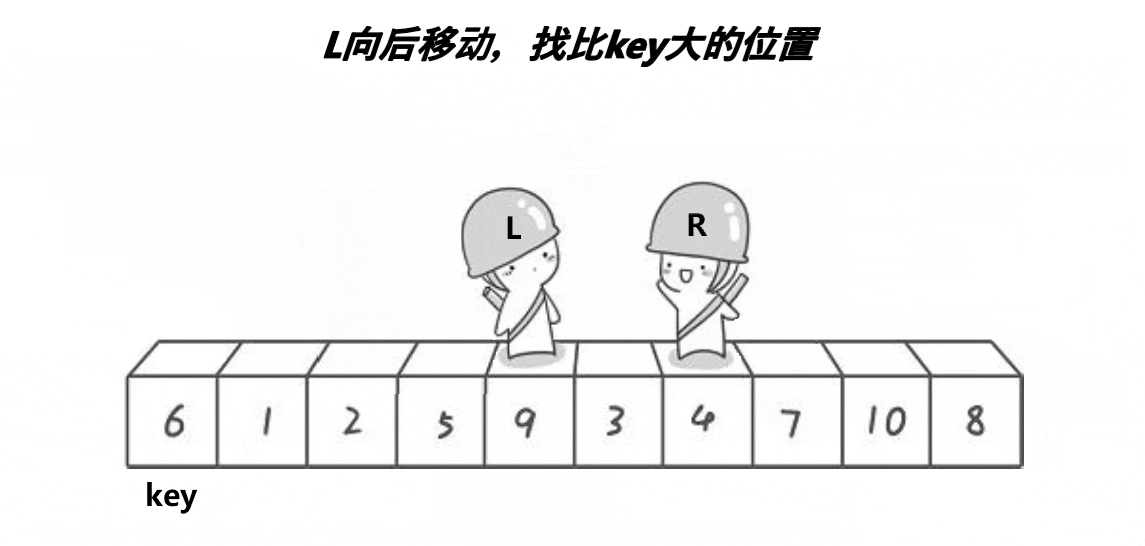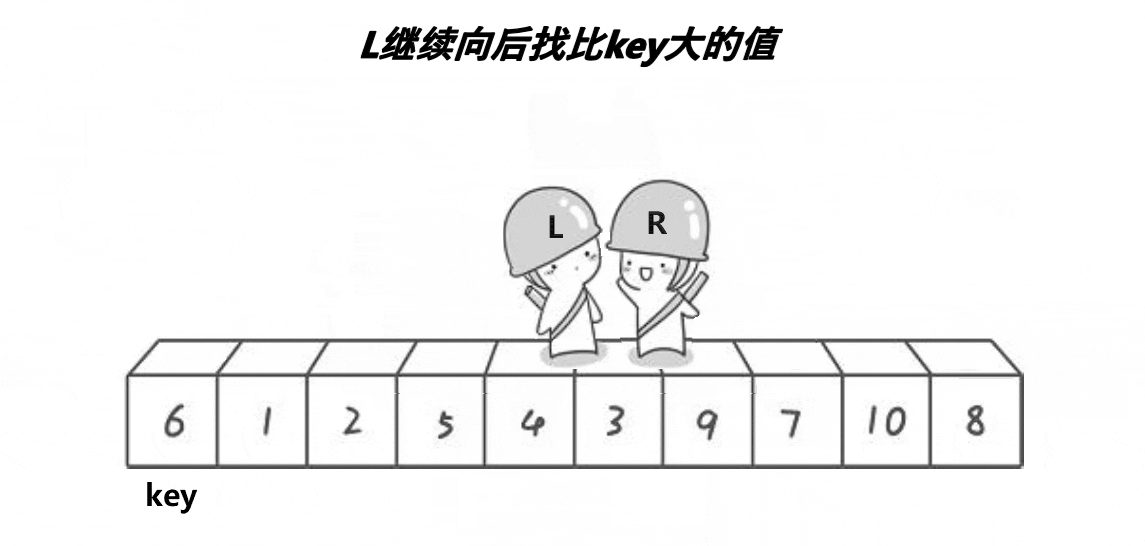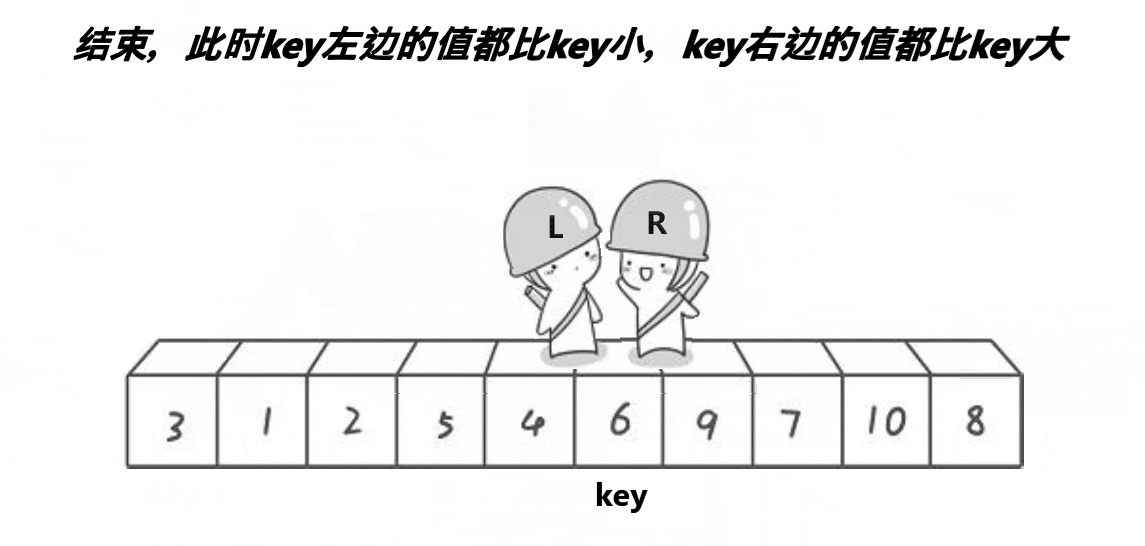
(2) 快排前后指针
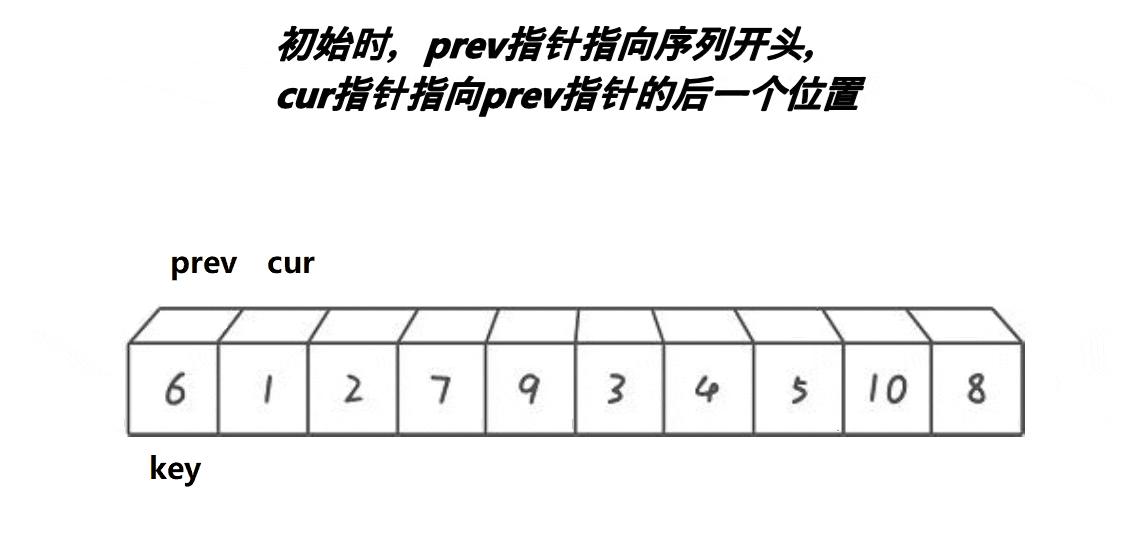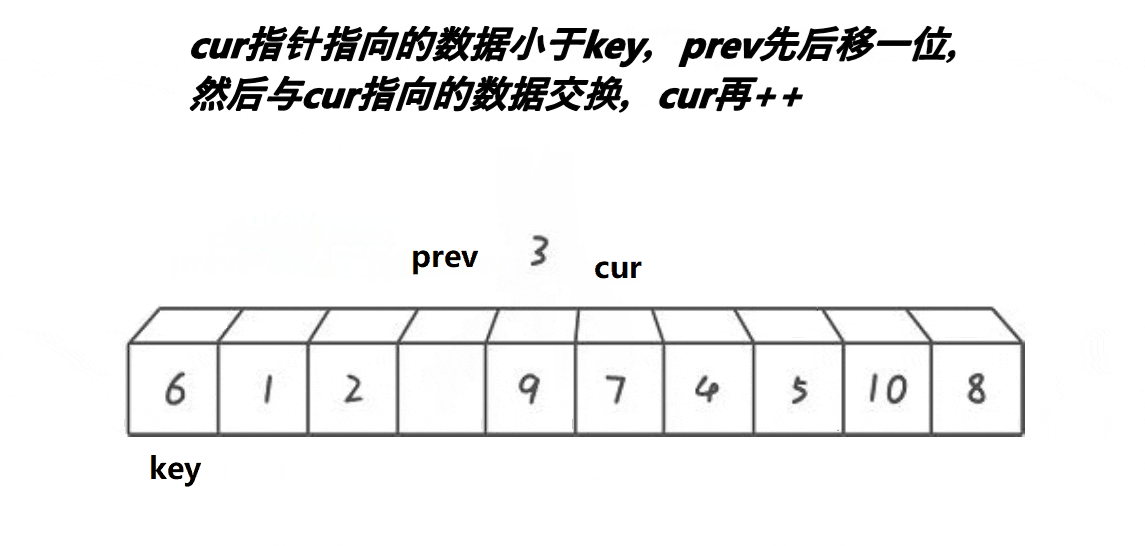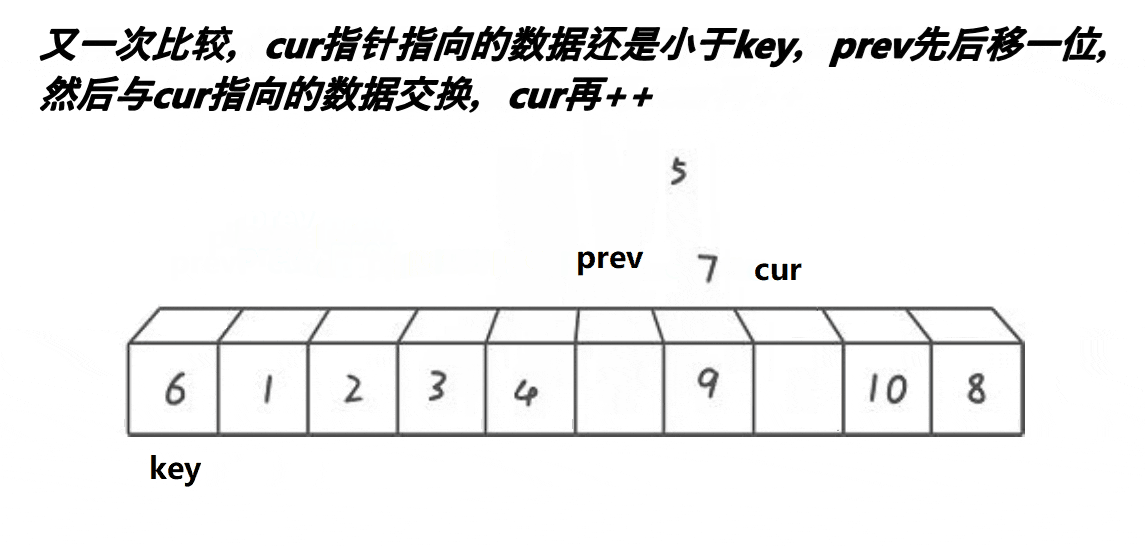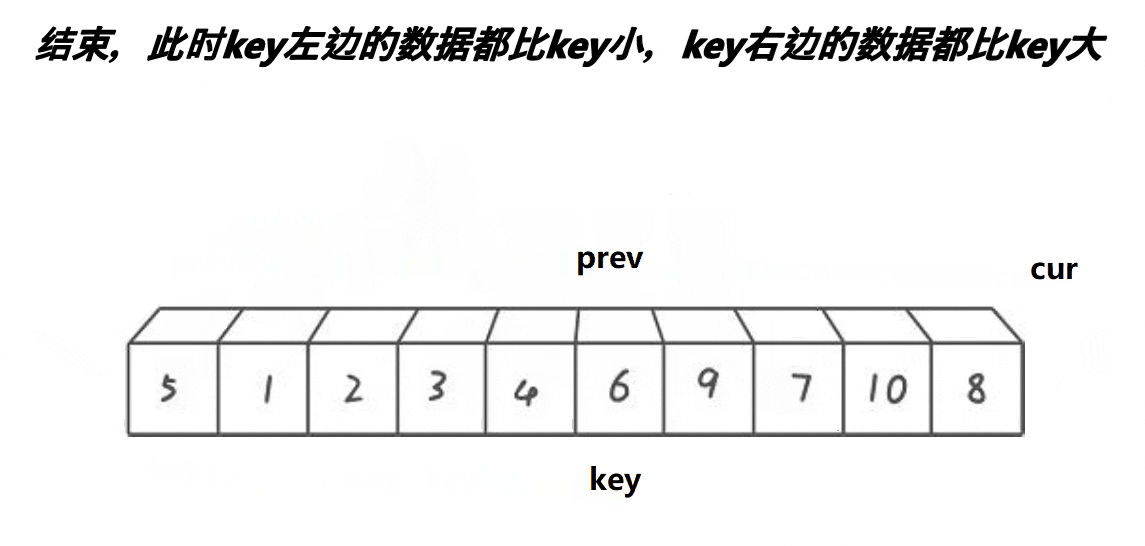
(3) 快排挖坑法
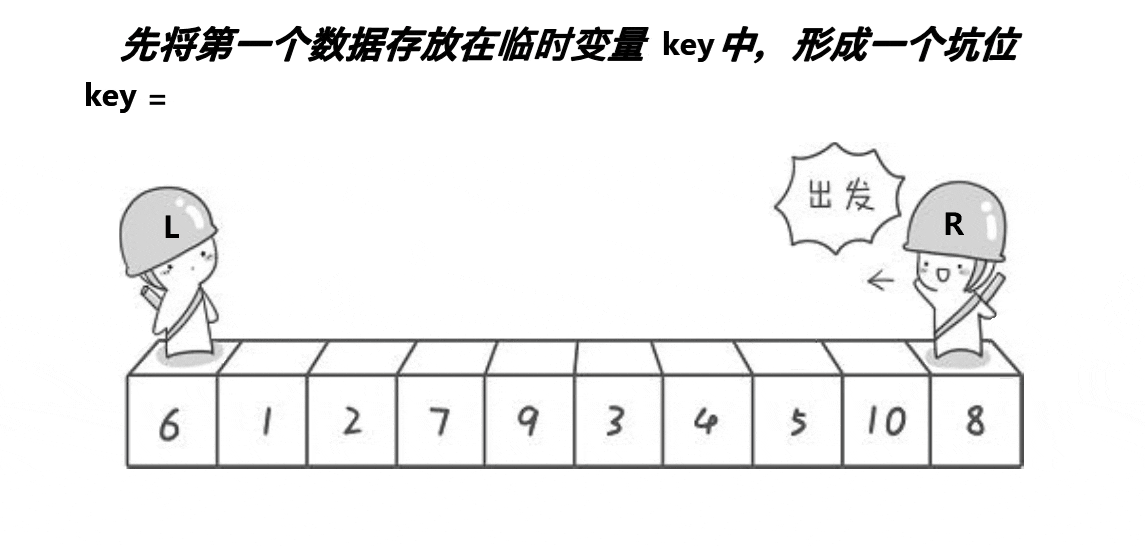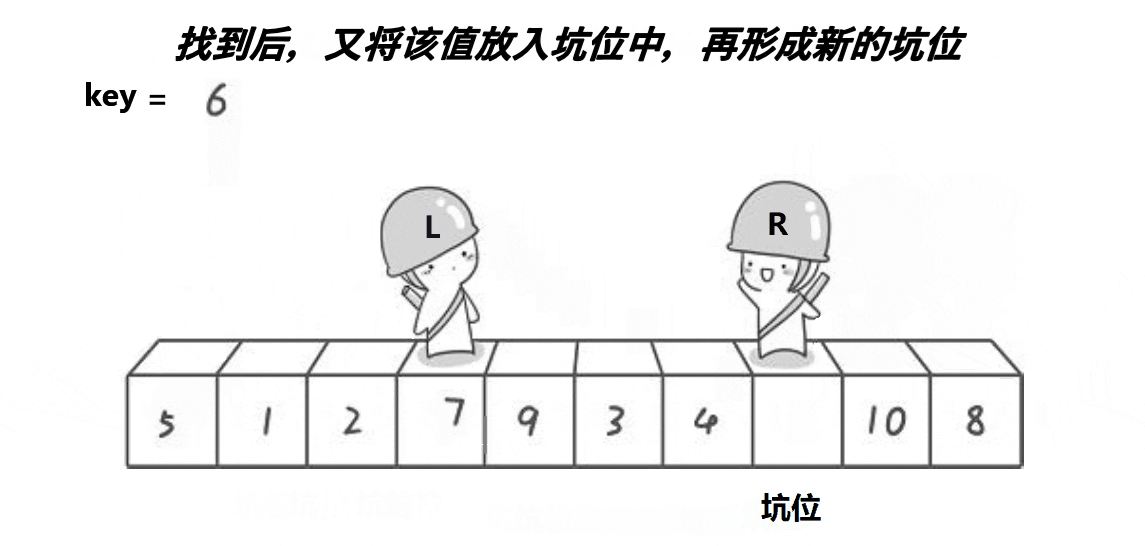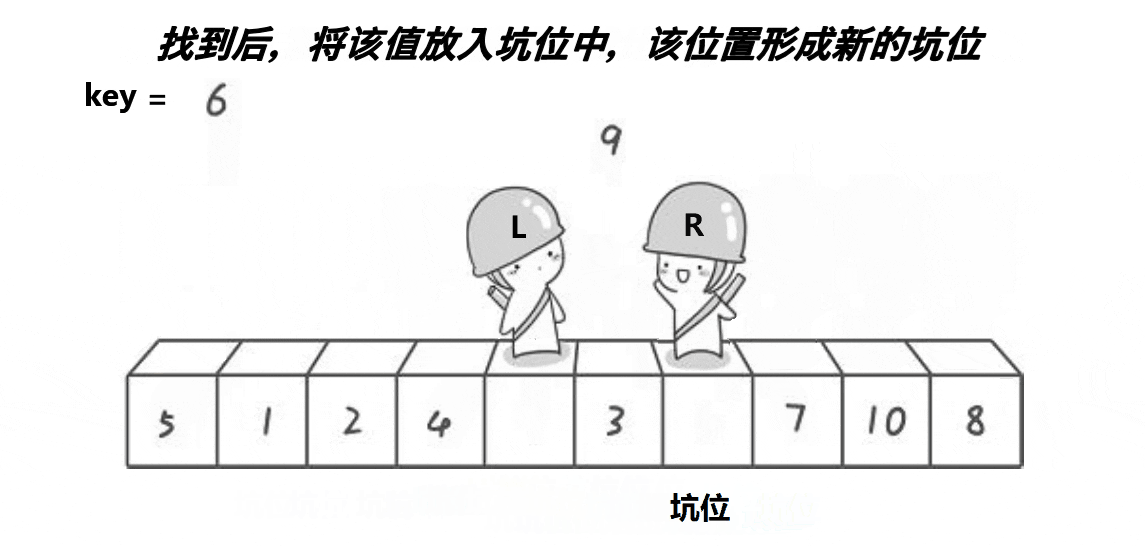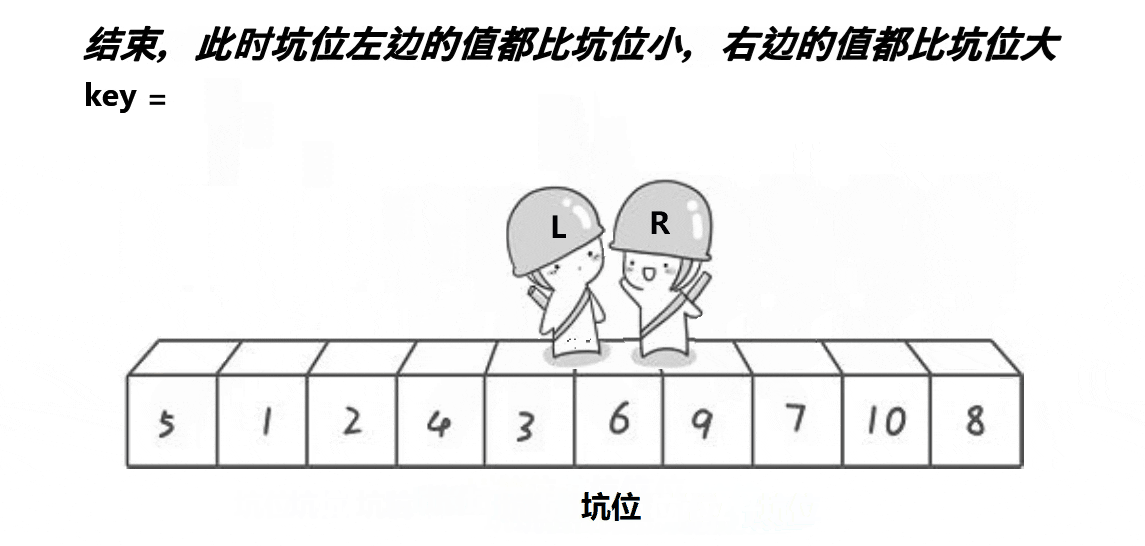
颜色分类
题目解析

算法原理
简述移动零的算法原理
- cur 在从前往后扫描的过程中,如果扫描的数符合 f 性质,就把这个数放到 dest 之前的区域;
- 符合 g 性质则不管,知道 cur 遍历到最后,dest 指针就可以把数组划分成两个部分;
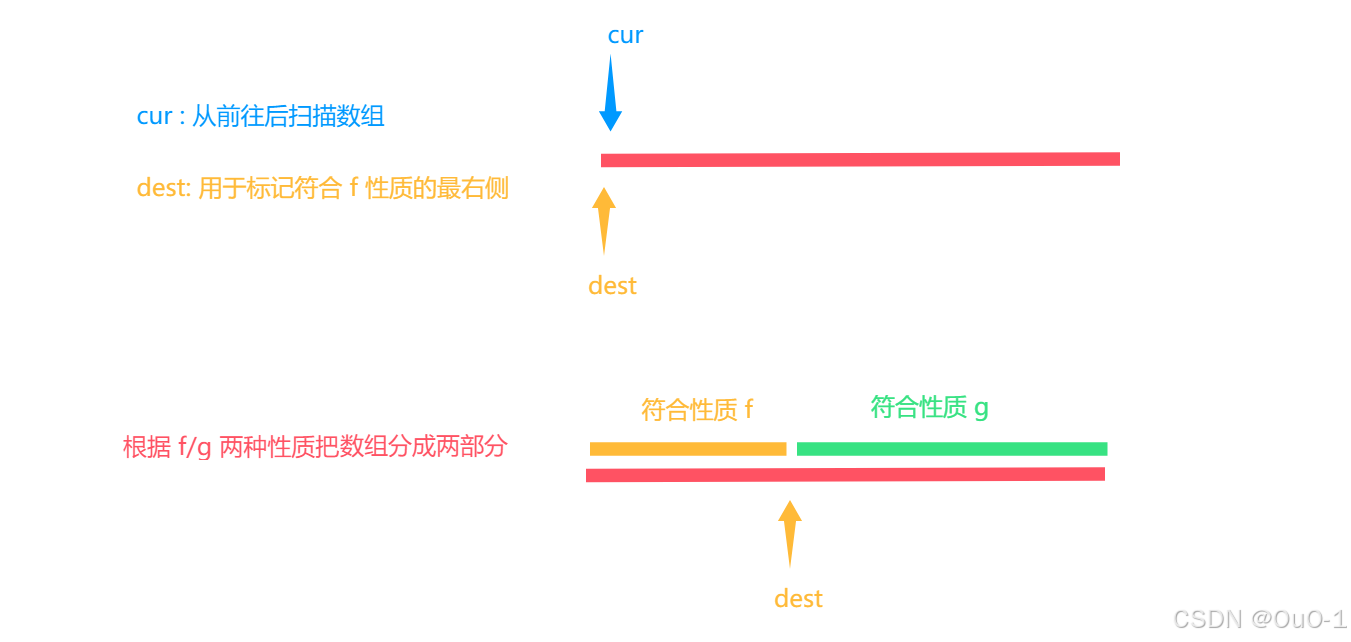
解法:三指针
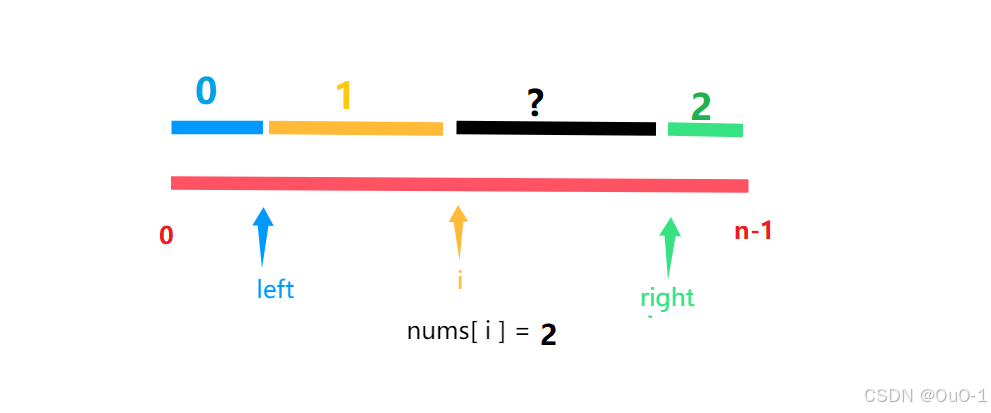
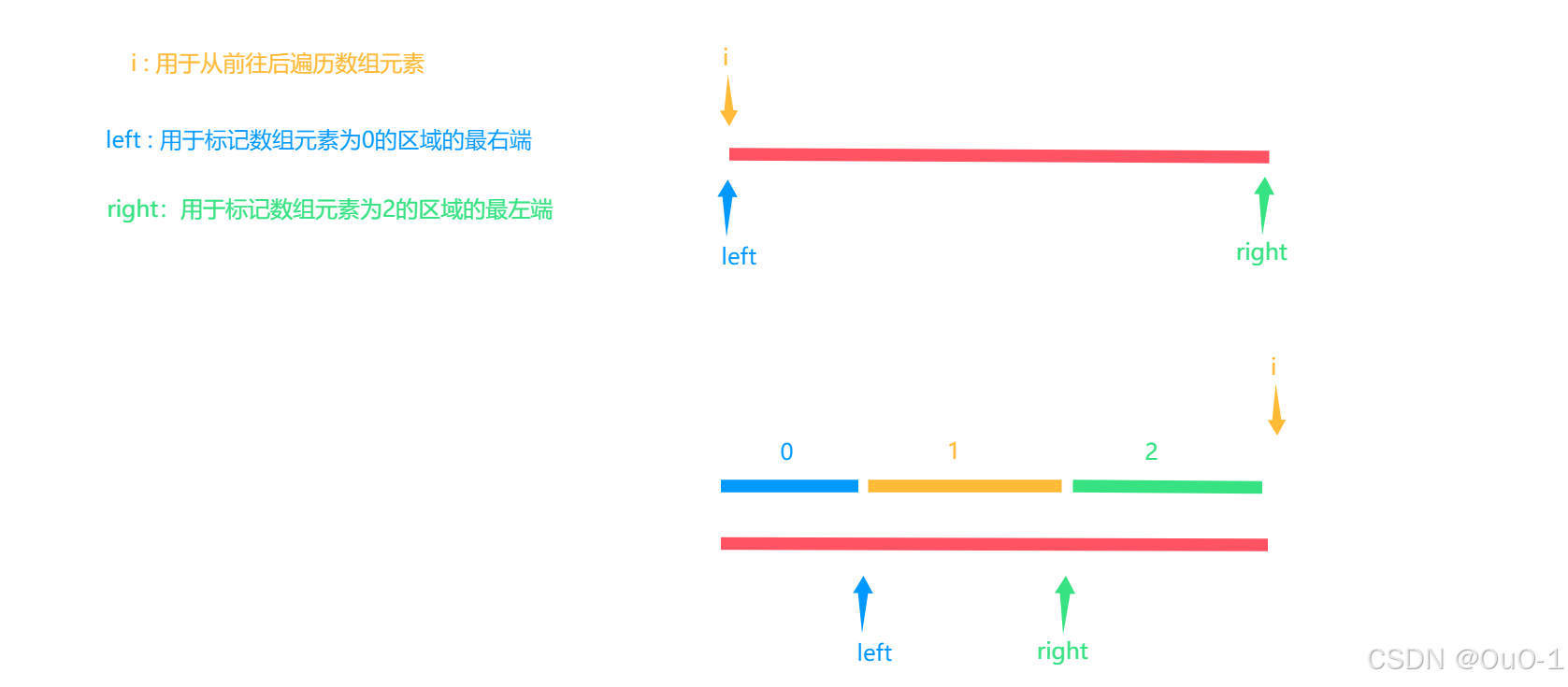 当 i 遍历结束数组后,整个数组就被排好序了,并且数组以 left,right 两个指针为分界线分成三个部分;
当 i 遍历结束数组后,整个数组就被排好序了,并且数组以 left,right 两个指针为分界线分成三个部分;
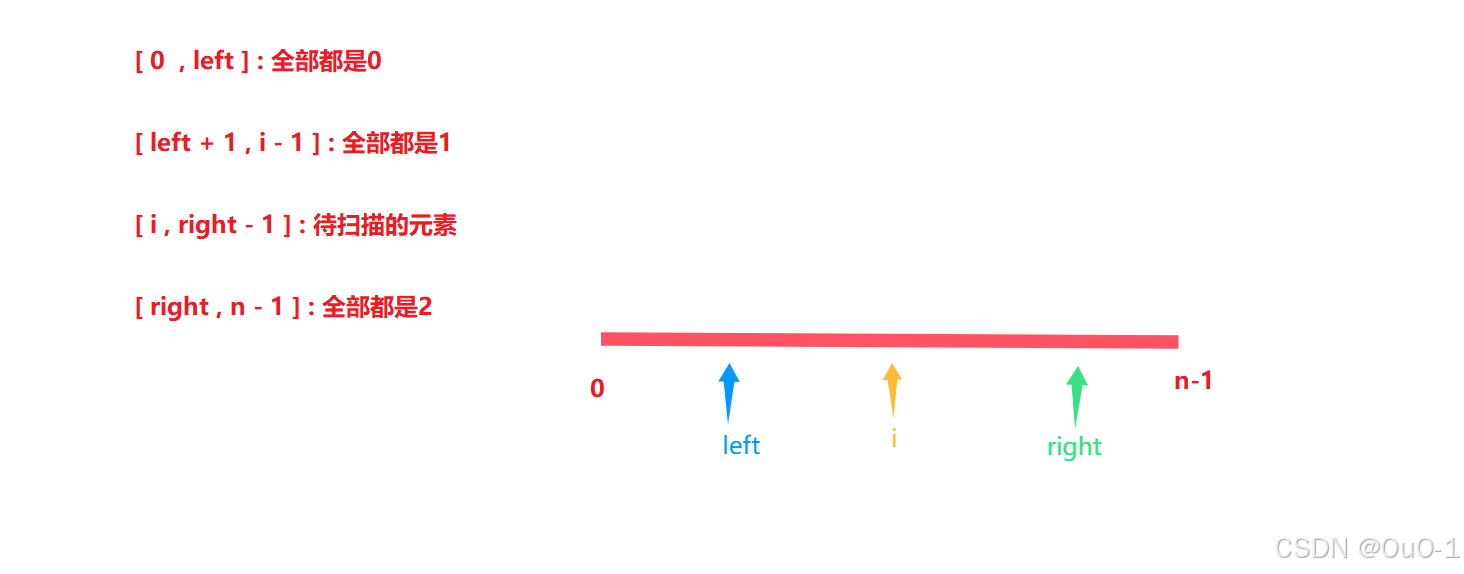
在遍历的过程中,整个数组会被划分成四个部分:
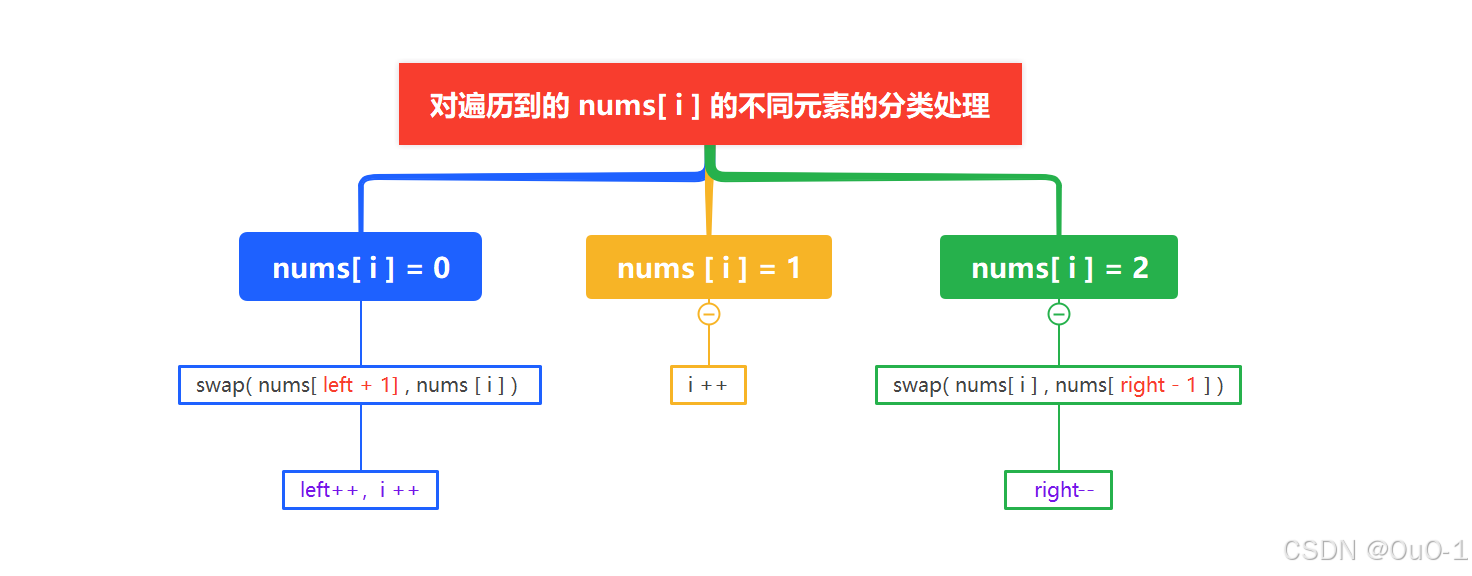
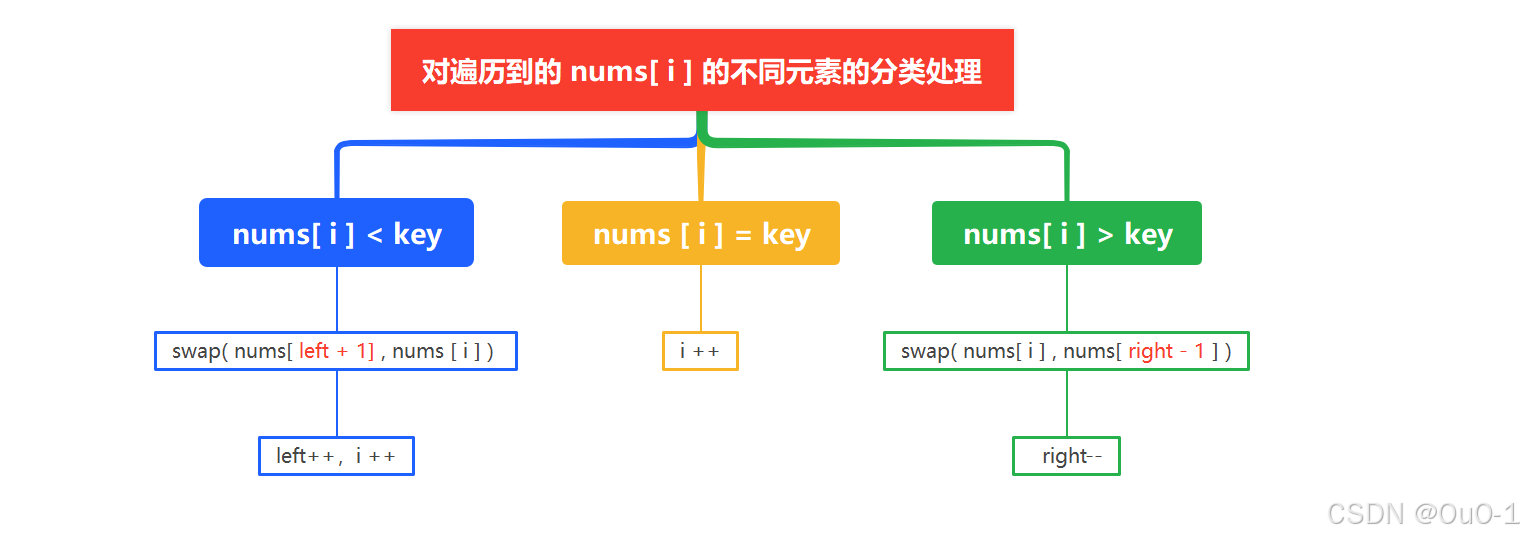
对遍历到的 nums[ i ] 的不同元素的分类处理
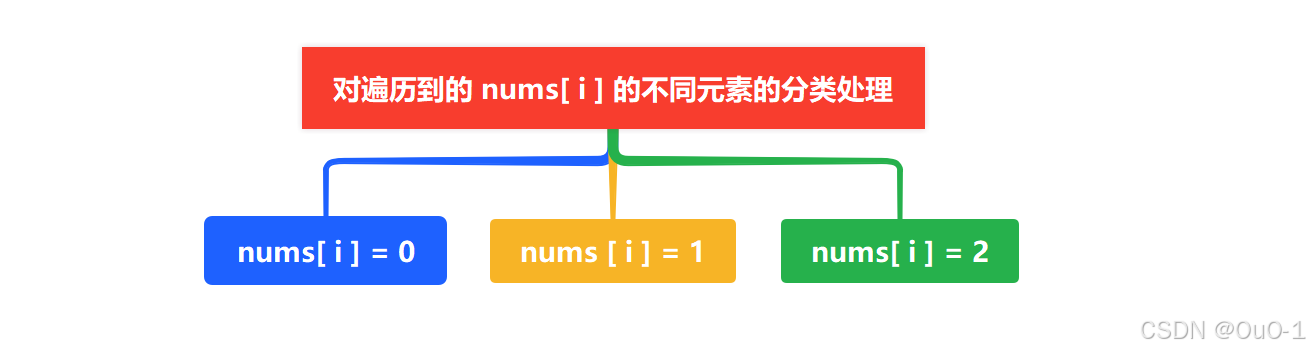
nums[ i ] = 0
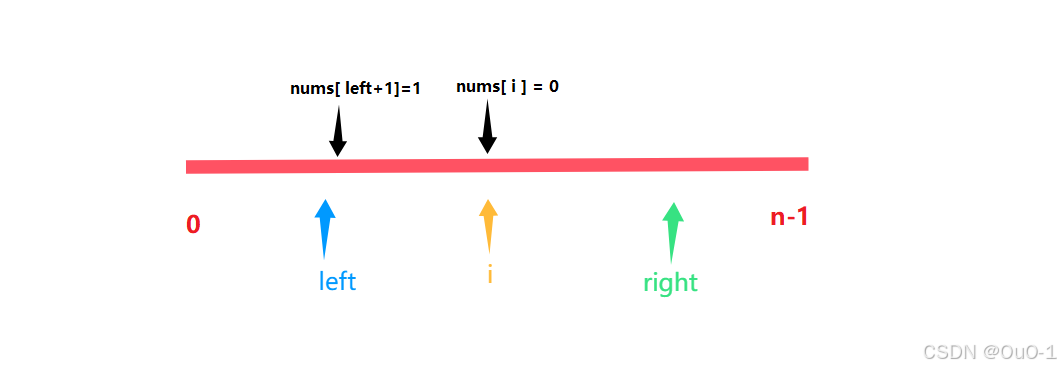 对于上面这种情况,我们只需要 swap( nums[ left + 1] , nums [ i ] ) left++,i ++ 即可,要注意nums[left+1]=1 ;
对于上面这种情况,我们只需要 swap( nums[ left + 1] , nums [ i ] ) left++,i ++ 即可,要注意nums[left+1]=1 ;
但是有一种极端情况,就是如果 i = left + 1,并且也符合 nums[ i ] = 0 的情况,我们依旧要执行 swap( nums[ left + 1] , nums [ i ] );
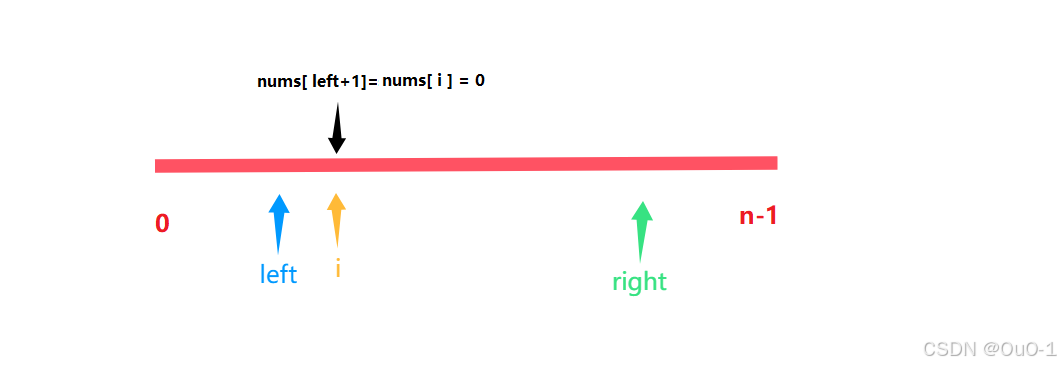
虽然这种极端情况是变成自己和自己交换,但是处理方法不变:交换完成后,left ++ , i ++;
nums[ i ] = 1
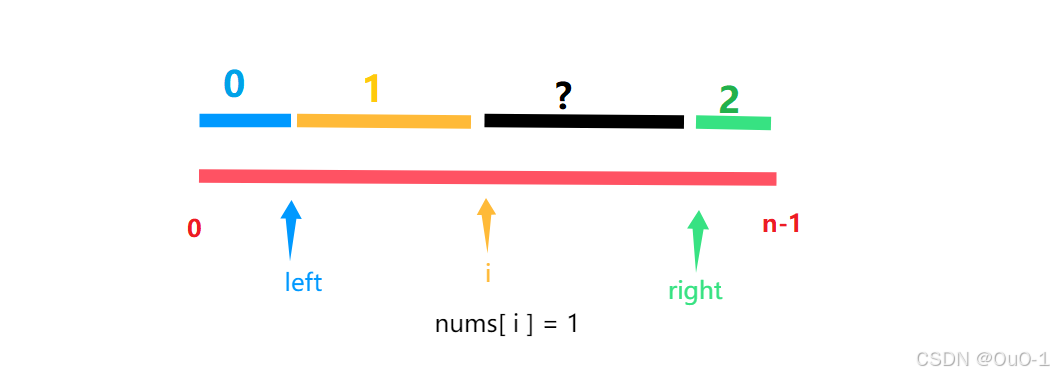 此时我们令 i ++ 即可;
此时我们令 i ++ 即可;
nums[ i ] = 2
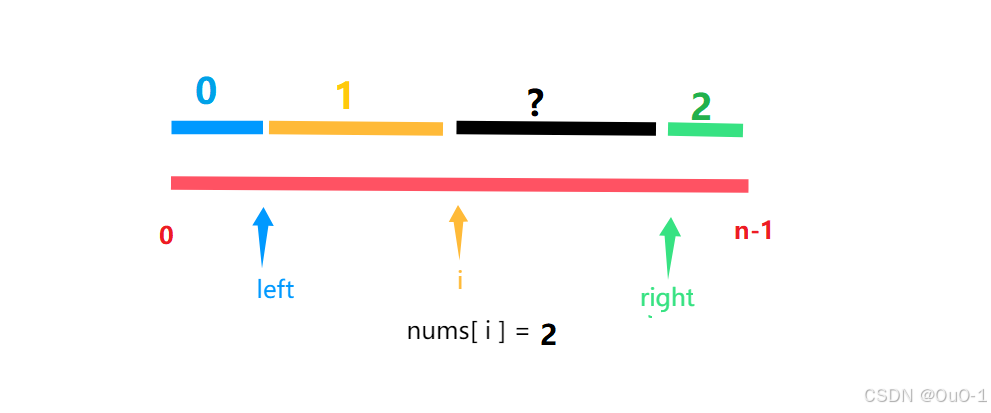 对于这种情况,我们可以 swap( nums[ i ] , nums[ right - 1 ] ) ,然后 right-- ;
对于这种情况,我们可以 swap( nums[ i ] , nums[ right - 1 ] ) ,然后 right-- ;
此时需要特别注意,swap( nums[ i ] , nums[ right - 1 ] ) 后,i 是不可以 ++ 的,因为 [ i ,right-1 ] 是待扫描区域,交换后,nums[ i ] 依旧是待扫描元素,所以 i 如果是和 right -1交换的情况,i 是一定不可以++的
处理细节问题
循环终止条件
当待扫描区域已经没有元素,说明此时数组所有元素已经全部被扫描并且分好类了,结束循环即可,所以循环终止条件是 i != right;
指针初始化
根据我们上面的算法原理,为了保证 left 指向 0 区域的最右边, right 区域指向 2 区域的最左边,我们交换元素是不会让 nums[ left ] ,nums[ right ] 亲自和 nums[ i ] 进行交换的:
所以我们的指针初始化的值如下:
 这样的操作是为了避免漏掉对 nums[ 0 ] ,nums [ n - 1 ] 的扫描;
这样的操作是为了避免漏掉对 nums[ 0 ] ,nums [ n - 1 ] 的扫描;
编写代码
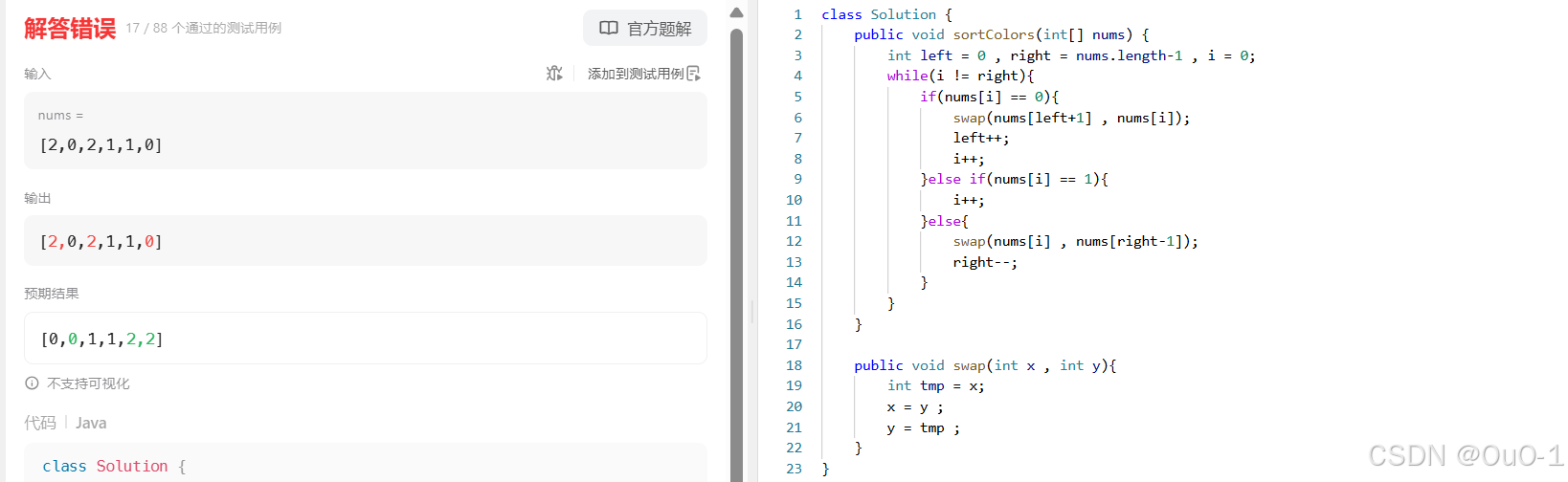
报错原因
- 交换元素的方法不对;
- 并且初始化 left,和 right 的操作没有处理好,会漏掉对 nums[ 0 ] ,nums [ n - 1 ] 的扫描
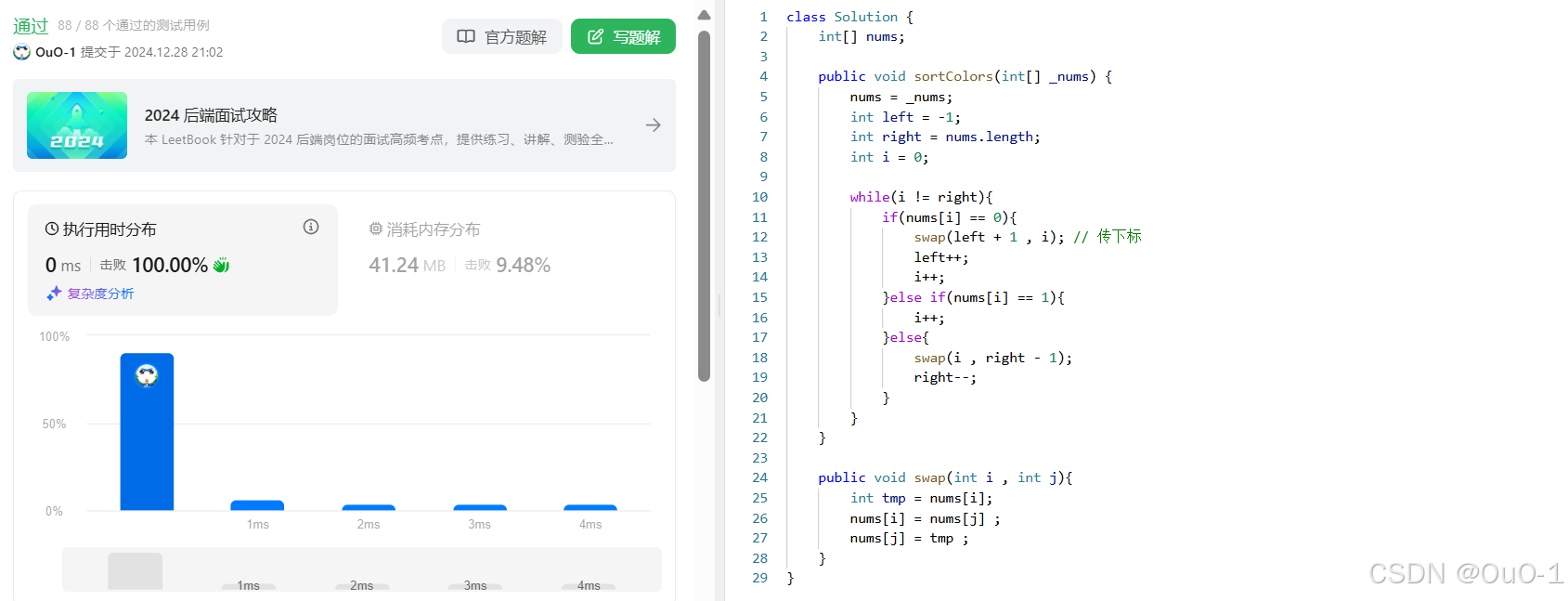
使用快速排序来排序数组
题目解析

算法原理
解法:原始快速排序
原始快速排序
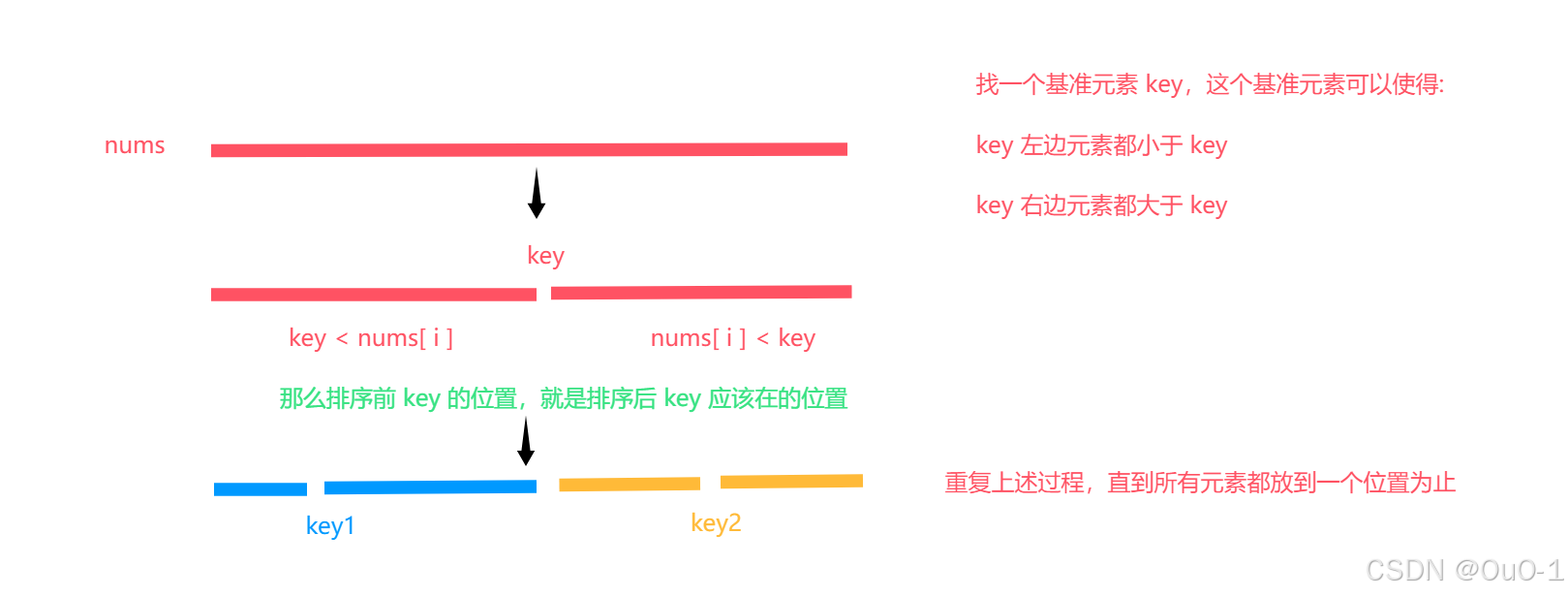
而原始快速排序的方法最核心的步骤,就在于根据基准元素进行数据划分的过程,这个步骤的名字是 partation;
但是,如果使用快速排序的数组有重复元素,那么快排的时间复杂度就会退化:

解法:用" 数组分三块 " 的思想实现快速排序
这是基于原始快速排序的优化策略,用于应对快速排序的数组有大量重复元素的情况,从对数组分成两块划分为分成三块:
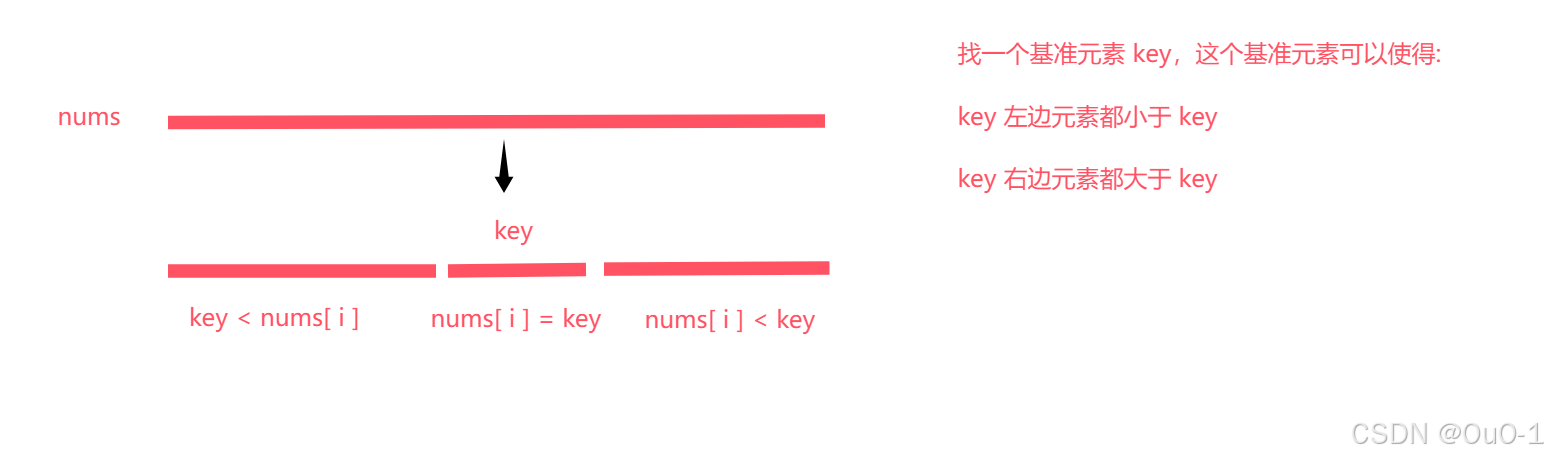
在数组出现大量重复元素时,通过把数组分成三段,可以把时间复杂度从 O(N^2) 降到 O(N);
分类讨论
 我们通过递归不断对划分的小区域排序,最终得到排好序的数组;
我们通过递归不断对划分的小区域排序,最终得到排好序的数组;
优化:用随机的方式选择基准元素
如果要想让快排的时间复杂度趋于 O(N* logN) ,就需要随机地选择基准元素;
 随机选择基准元素,就是给我们一个数组,我们要等概率地返回区间上的任意一个数;
随机选择基准元素,就是给我们一个数组,我们要等概率地返回区间上的任意一个数;
如何随机地选择一个基准元素呢?

编写代码
准备工作
传入要排序的左区间和右区间:

如果 L >= R,则说明排序的区间要么只有一个,要么这个区间没有元素,说明整个数组已经排序完毕;
随机生成基准元素 & 初始化下标
要记一下如何生成随机数下标,以及要特别注意这里的初始化 left != -1 ,right != nums.length:
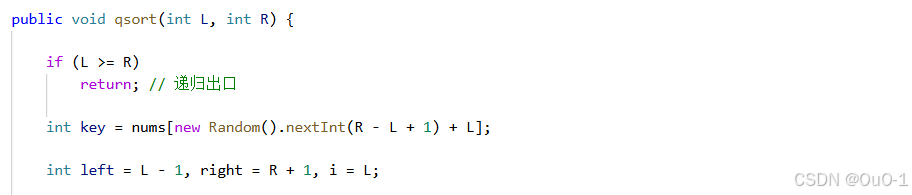

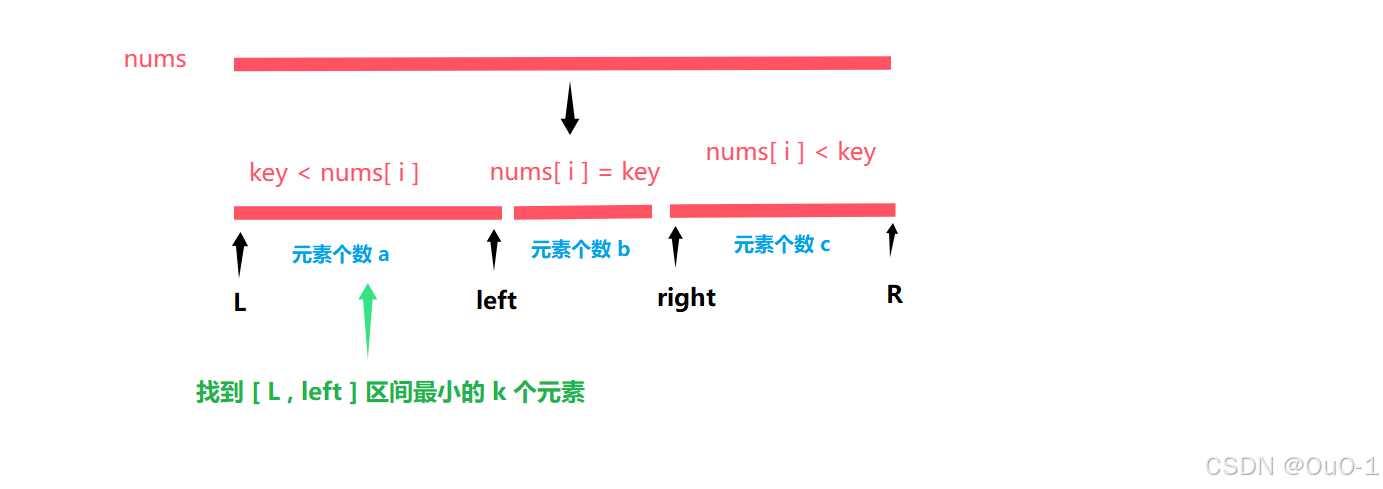
把数组分三块
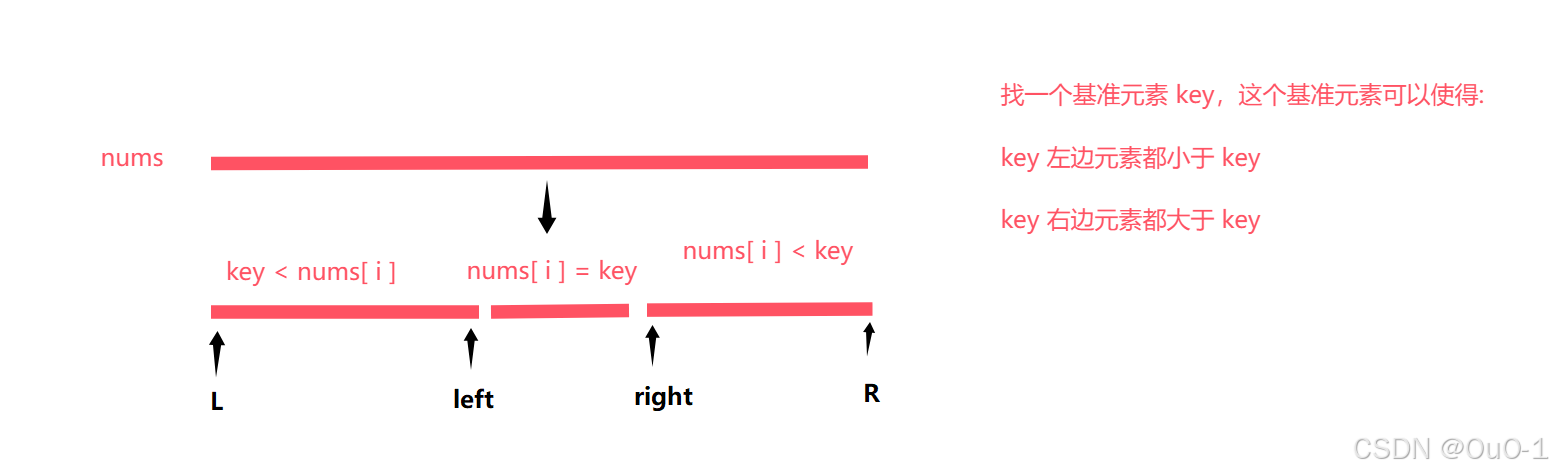
[ left + 1 , right - 1 ] 这块区域用于存与生成的随机基准元素值相同的元素 ,并且以这块区域为基准,把其他数组元素分到这三块区域对应的区域;

可以记一下这个 partation 的过程,这是快排的核心逻辑;
[ L , left ] & [ right , R ] 进行排序
根据 nums[ i ] 与 key 的大小关系,把所有元素放到 [ left + 1 , right - 1 ] 的两边(两边还是乱序的),再对两边区域进行递归排序即可;
快速选择算法
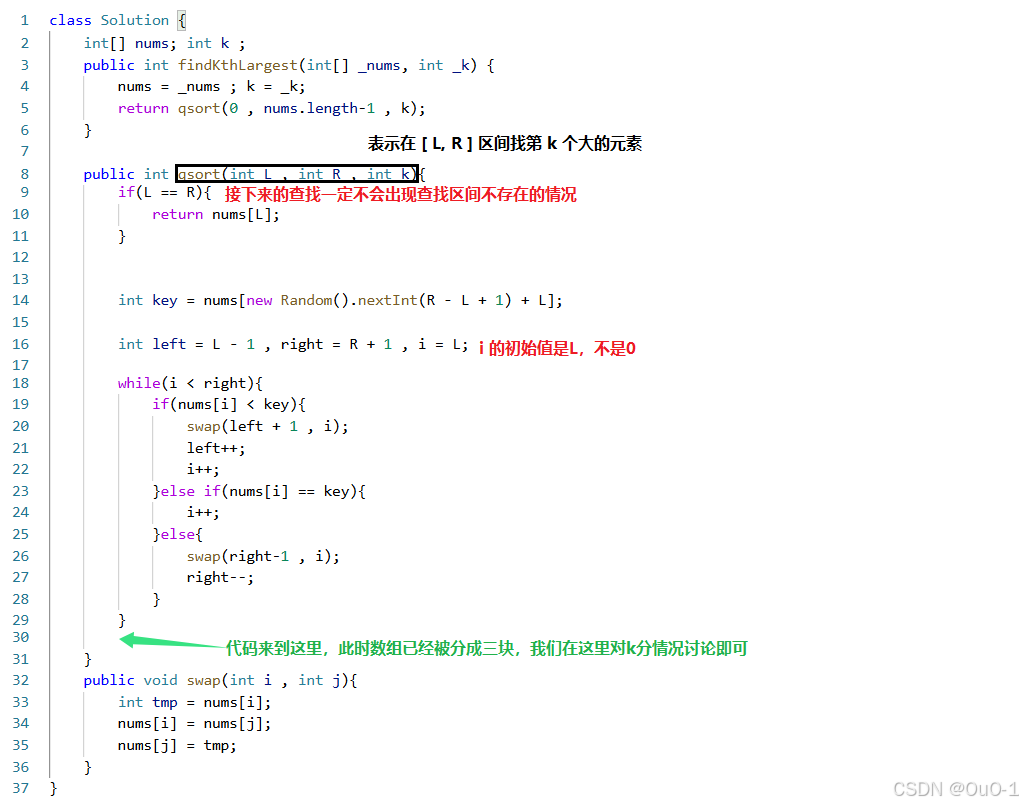
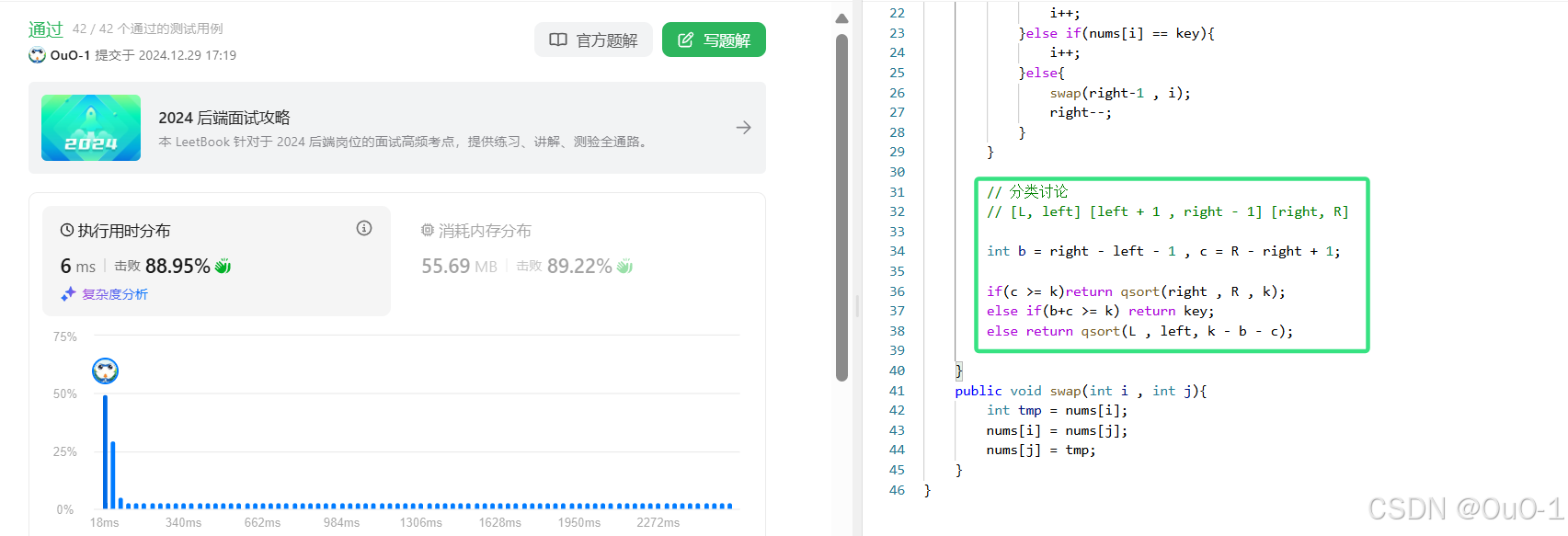
数组中的第K个最大元素
题目解析

算法原理
解法:基于快排实现快速选择算法
快速排序 Partation
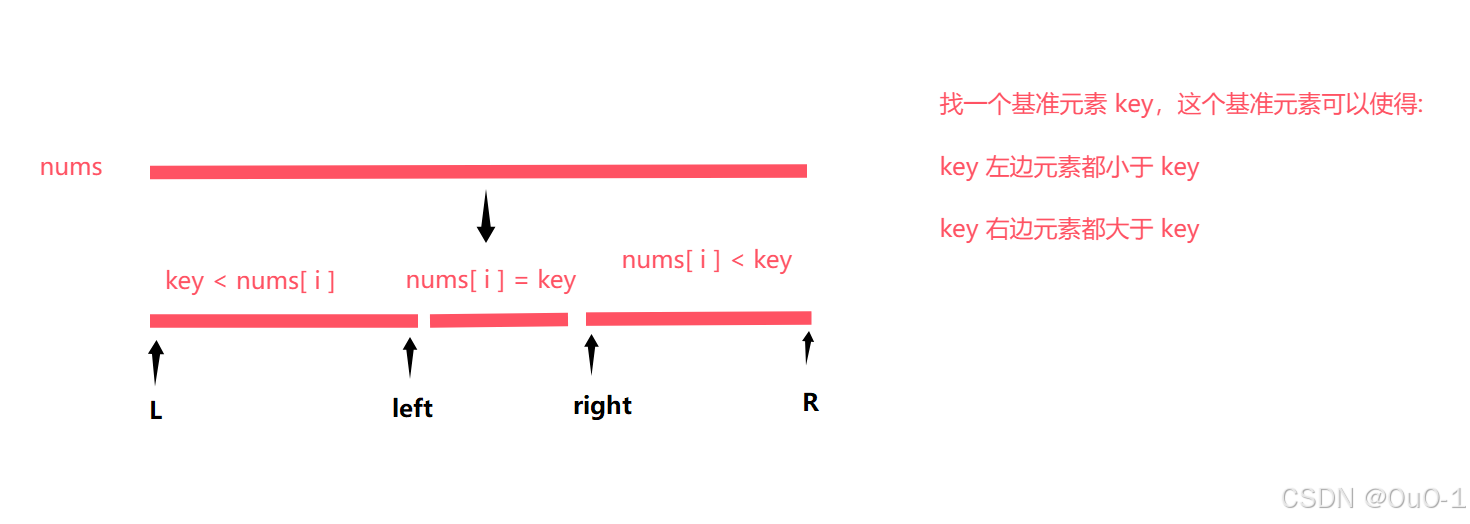 本题是要找出数组中第 K 大的元素 KthLarges,那么我们可以根据基准元素,来判断 KthLarges 是落在上面三个区域的哪一个区域,然后对这个区域进行继续进行 Partation,继续找 KthLarges;
本题是要找出数组中第 K 大的元素 KthLarges,那么我们可以根据基准元素,来判断 KthLarges 是落在上面三个区域的哪一个区域,然后对这个区域进行继续进行 Partation,继续找 KthLarges;
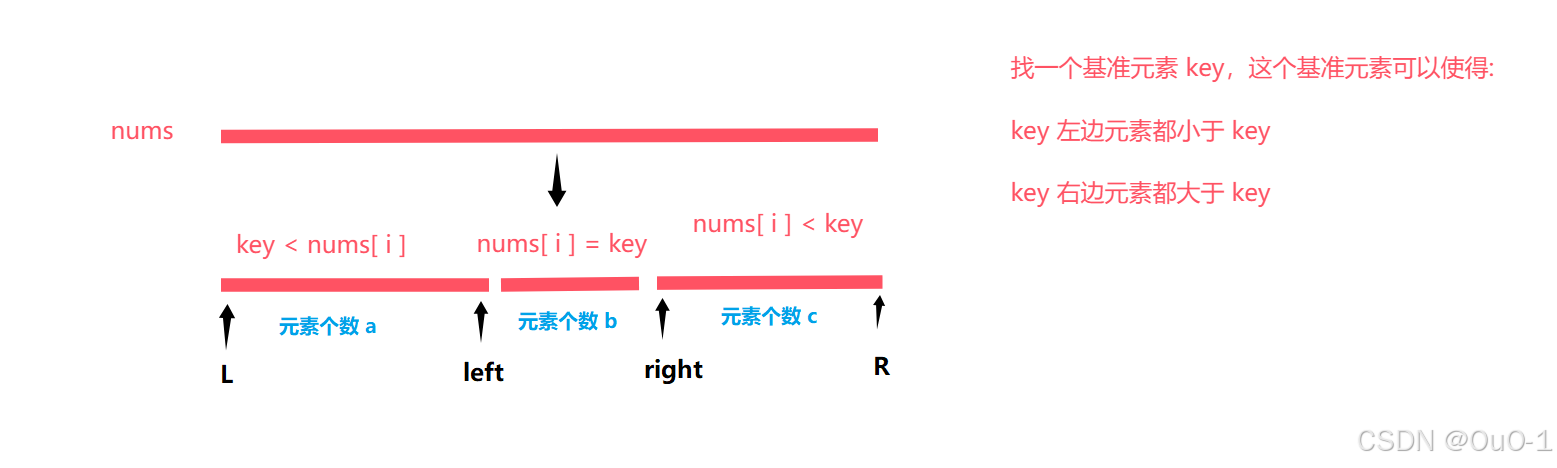
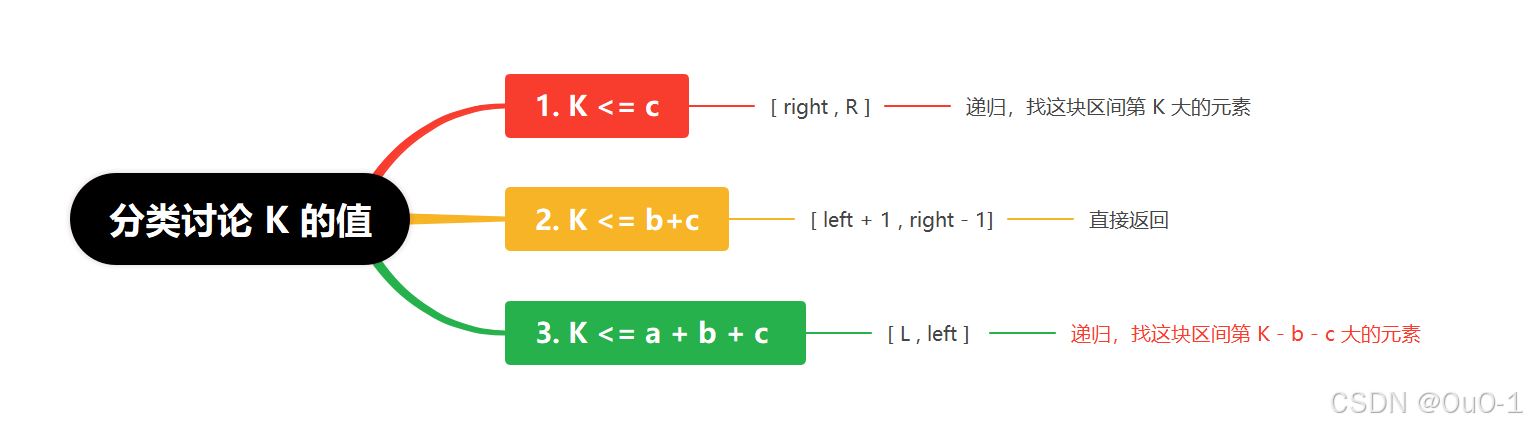
根据 K 的值分情况讨论,确定 KthLarges 的区间位置
我们先分别设三个区间的元素个数:
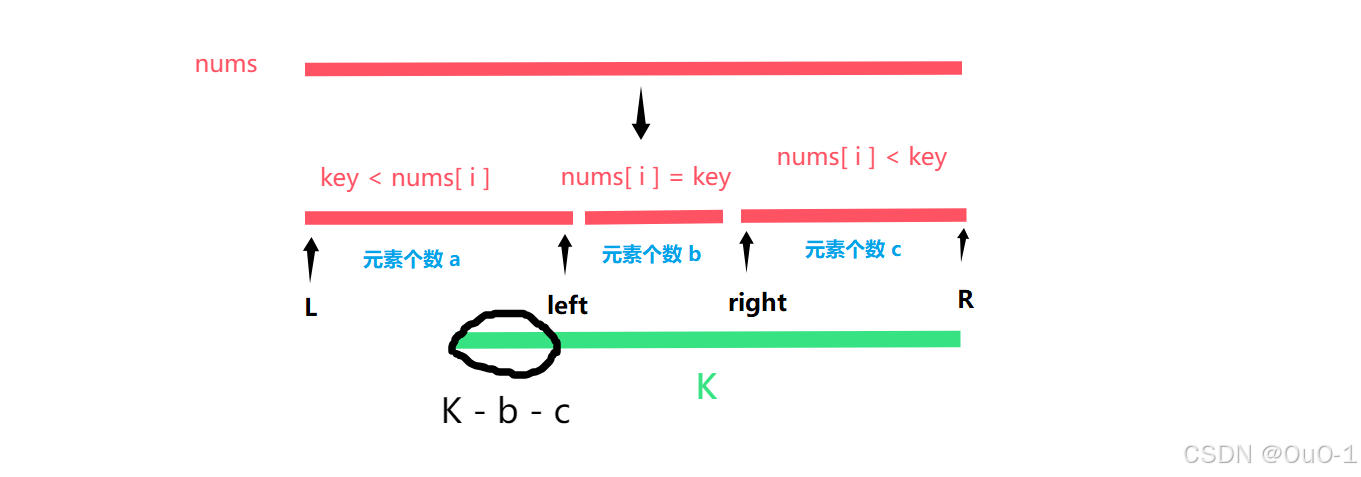
处理细节问题

我们解释一下这种情况:
编写代码
先根据快排 partation 原理,把数组分三块
根据 k 的值来决定递归三块中的哪一块区域
最小的k个数
题目解析

算法原理
解法一:直接排序
时间复杂度 O( N * logN)
解法二:使用大根堆( 求最小的前K个数)
时间复杂度 O( N * logK )
解法三:快速选择算法
时间复杂度趋于 O( N ) ,因为是随机选择基准元素,步骤如下:
对 K 的值分类讨论
(1) a > k
(2) b >= k
这种情况我们直接返回前面两个区域的前 k 个小的元素即可,不用关心 [ L , right ] 区间的顺序;
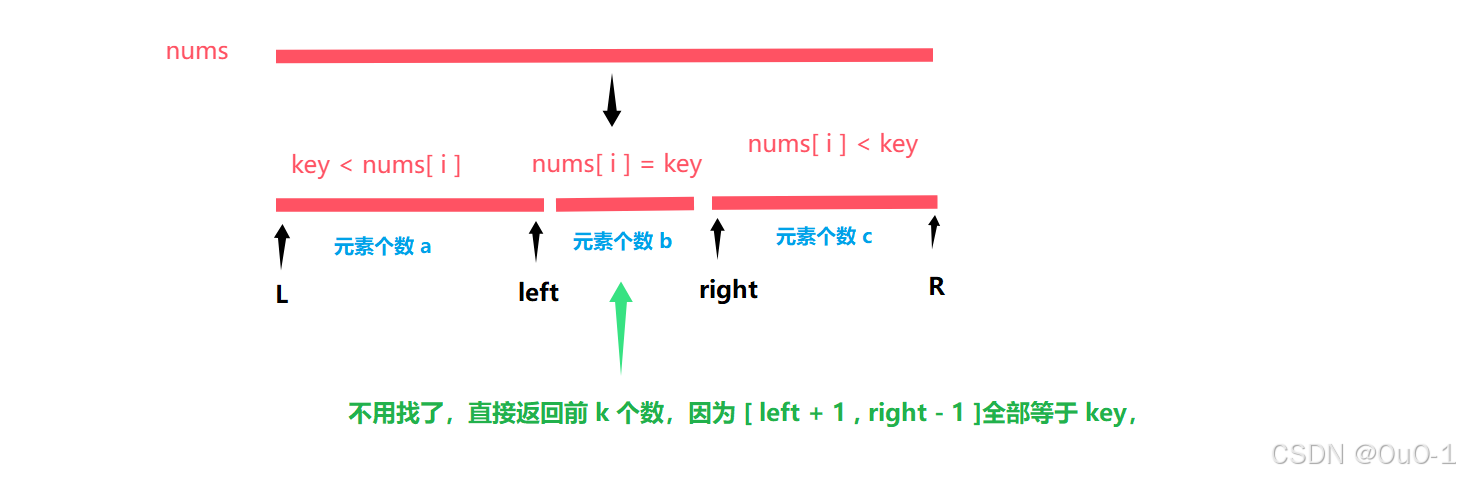
(3) k > b+c
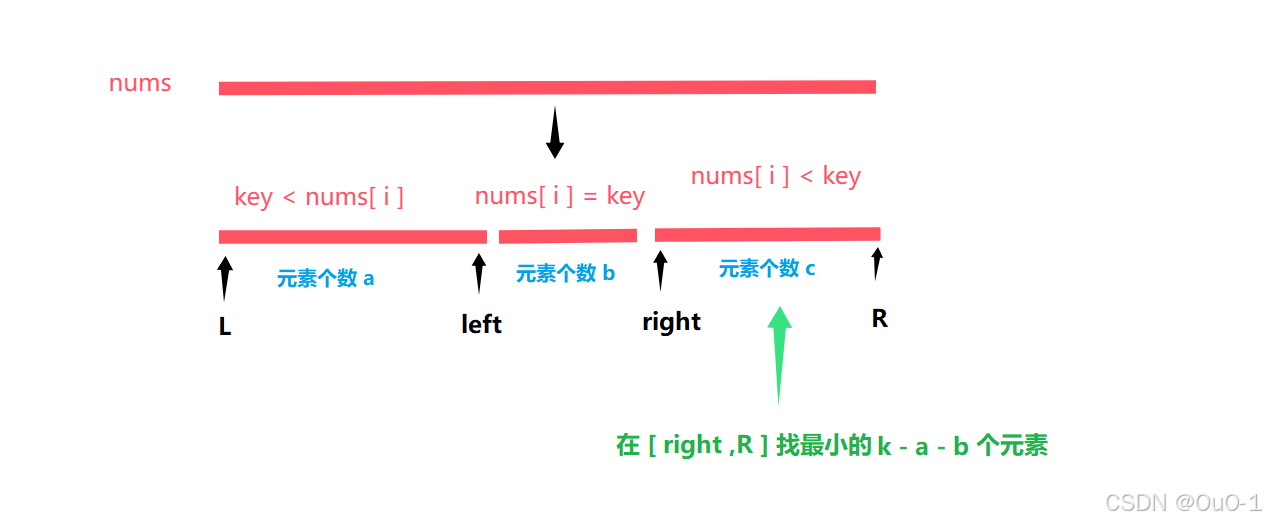
通过这三种情况,我们就能明显的感受到快速选择排序是最优的解法;
比如第三种情况,此时[ L ,right ] 区间是没有排序的,但是我们依旧已经找到了最小的 k 个元素的一部分;而其他两种情况都是要对数组的每一个元素进行排序;
编写代码
我们是对 nums 的前 k个元素进行排序,把然后把 nums 的前 k 个元素赋值个 ret,然后返回;

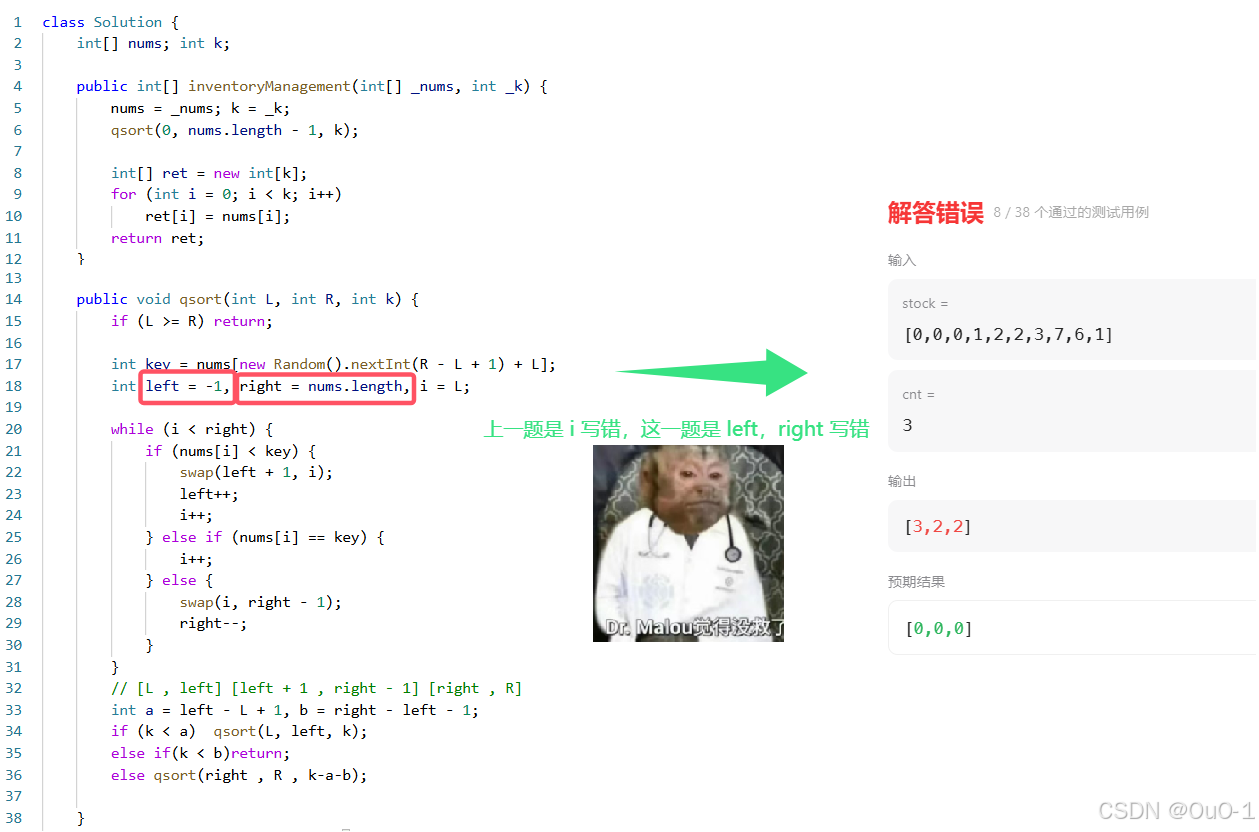
报错原因:粗心导致 left & right 指针的初始值写错了
归并排序
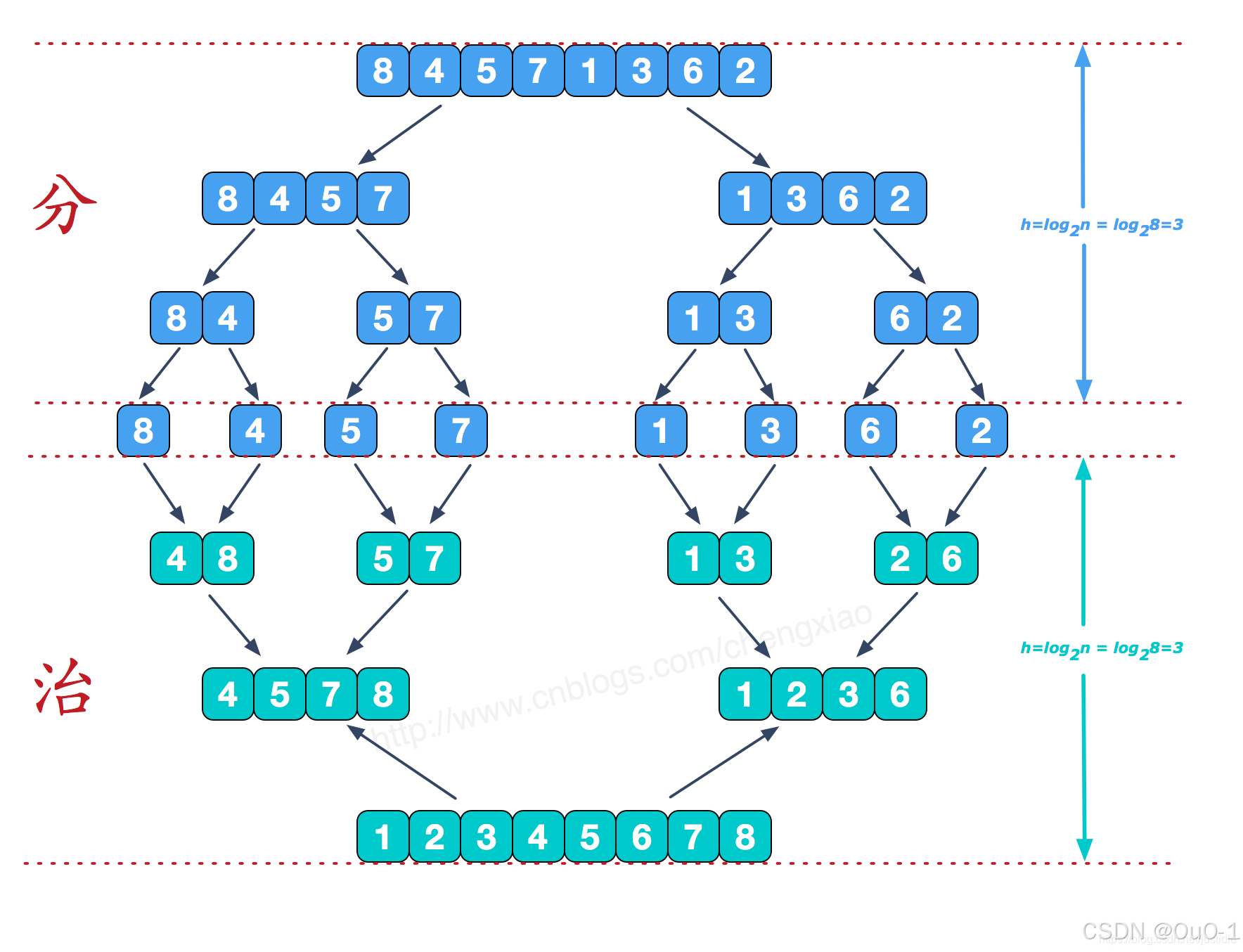
- 当数组块被分成每一块都只有一个元素,分块结束;
- 用双指针合并两个有序数组;
- 归并排序的决策树非常像二叉树的后续遍历( 左右根 ),而快排则类似前序遍历(先对数组整体粗糙分一遍,再去两边区域细分);
使用归并排序来排序数组
题目解析

编写代码

优化:辅助数组设置为全局变量
把 tmp 设置为全局,就不用在每次递归时,创建一个新的 tmp ,减少时间开销;
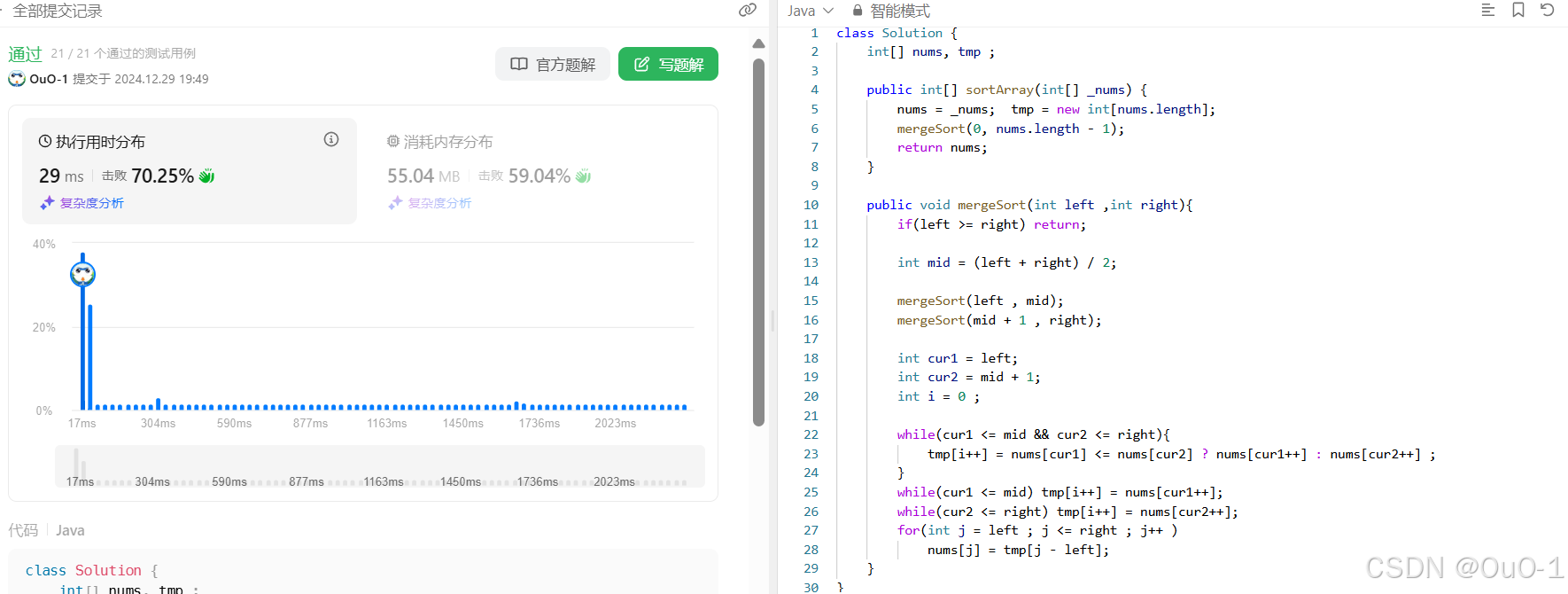
- int[] nums, tmp ;
-
- public int[] sortArray(int[] _nums) {
- nums = _nums;
- tmp = new int[nums.length];
- mergeSort(0, nums.length - 1);
- return nums;
- }
-
- public void mergeSort(int left ,int right){
- if(left >= right) return;
-
- int mid = (left + right) / 2;
-
- mergeSort(left , mid);
- mergeSort(mid + 1 , right);
-
- int cur1 = left;
- int cur2 = mid + 1;
- int i = 0 ;
-
- while(cur1 <= mid && cur2 <= right){
- tmp[i++] = nums[cur1] <= nums[cur2] ? nums[cur1++] : nums[cur2++] ;
- }
-
- while(cur1 <= mid) tmp[i++] = nums[cur1++];
- while(cur2 <= right) tmp[i++] = nums[cur2++];
-
- for(int j = left ; j <= right ; j++ )
- nums[j] = tmp[j - left];
- }

数组中的逆序对
题目解析

算法原理
解法一:暴力枚举
固定其中一个数,在这个数后面区间找比这个数小的数,来构成一个逆序对; 使用两层 for 循环即可,但是会超时;
解法二:归并排序
算法原理

(1) 左半部分 + 右半部分 + 一左一右

本质还是暴力枚举,逆序对个数 = a + b + c
(2) 左半部分 + 左排序 + 右半部分 + 右排序 + 一左一右 + 排序
对左右两边排好序,再一左一右挑数组成逆序对,并不影响结果:
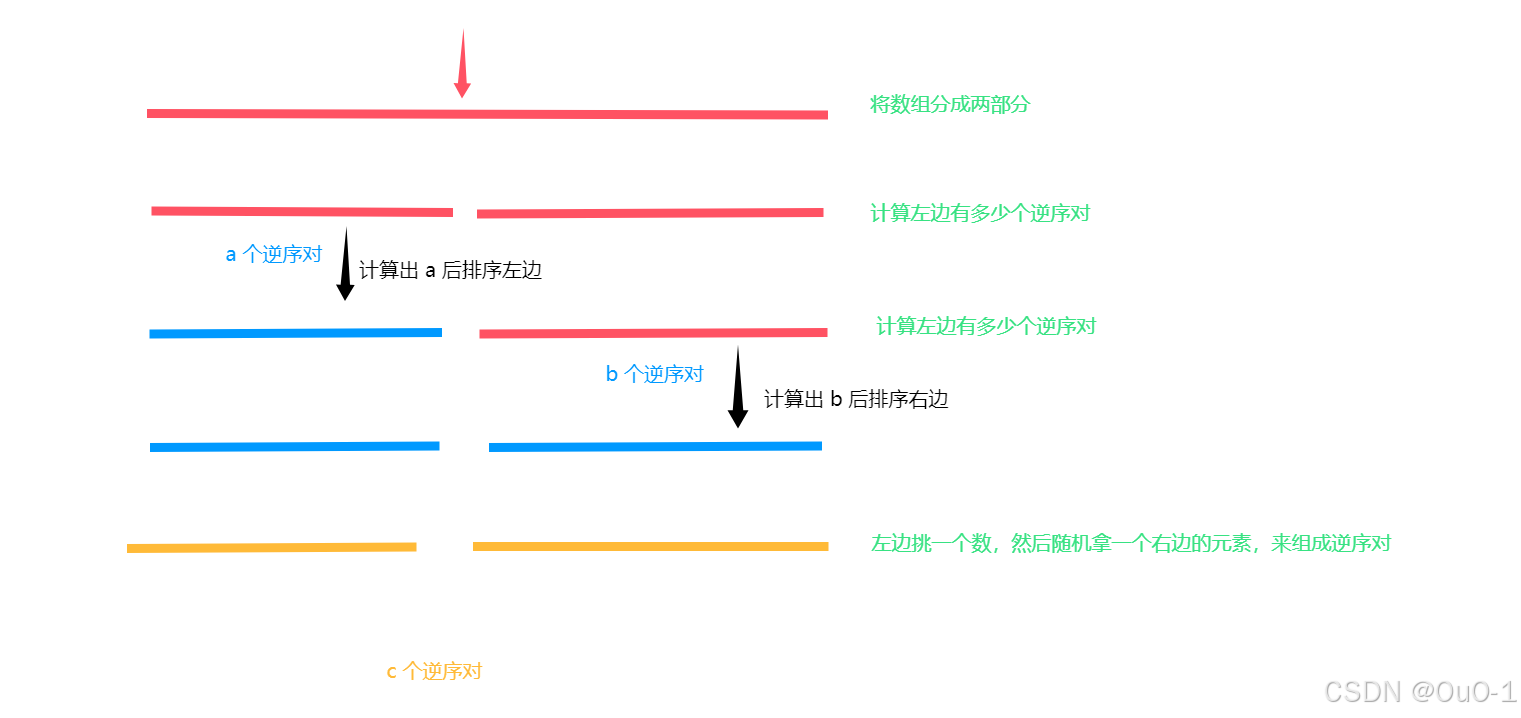
本题为什么可以利用归并排序解决问题?

并且通过这步操作,我们得出本题最终的解法,就是需要通过归并排序求逆序对个数;
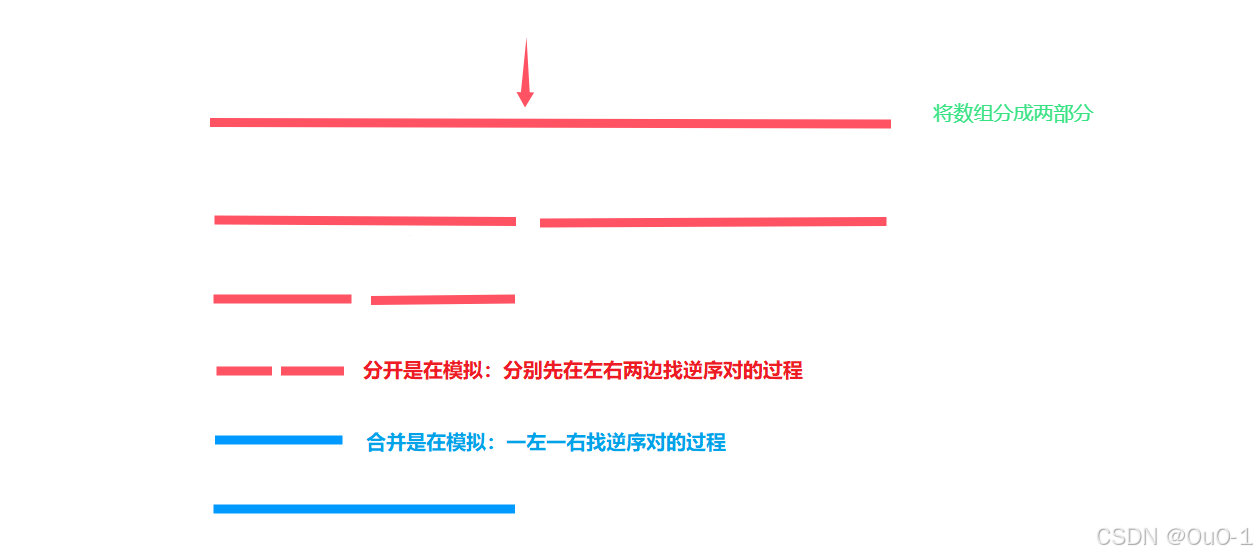
我们在找出左右两边的逆序对个数时,先对两边排序再一左一右,会非常快:
一左一右查找逆序对策略优化
我们在之前找左右两边区域的所有逆序对时,就刻意地对左右两边进行排序,找完左右两边的逆序对时,nums 的两边区域的顺序已经被排序成升序,此时我们需要一左一右寻找逆序对;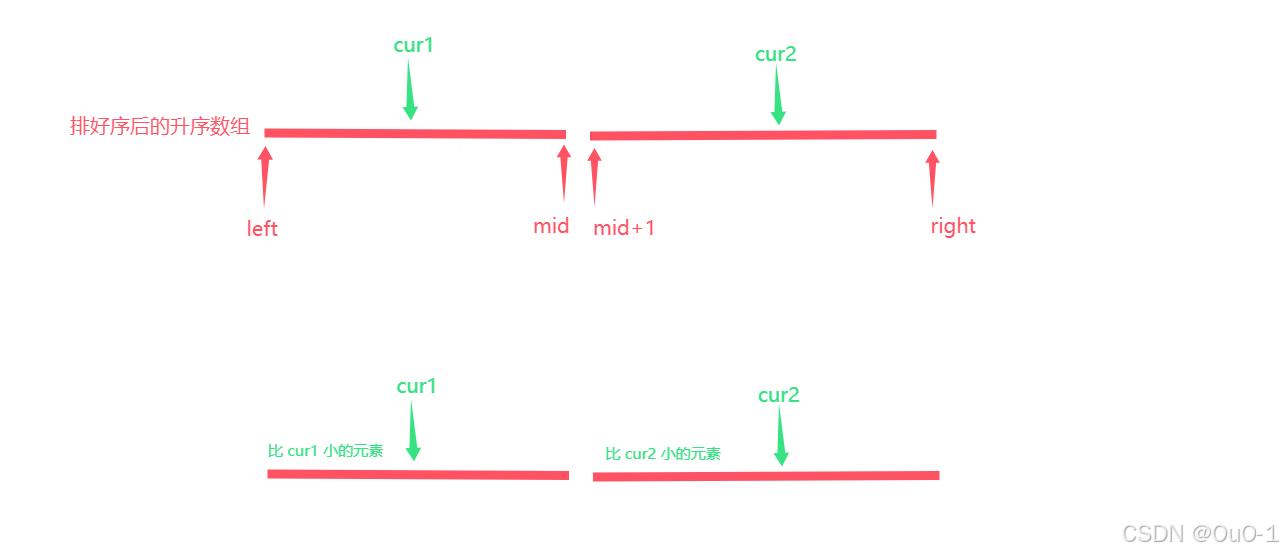
策略一 : 判断 nums[cur1]>nums[cur2] + 升序
统计一左一右逆序对的固定策略
固定 cur2, 只要 cur1 一移动到 nums[cur1]>nums[cur2]位置,就统计符合要求的区间的元素个数,cur2++;
假设我们固定 cur2,要在左边找有多少个比 nums[ cur2 ] 大的元素
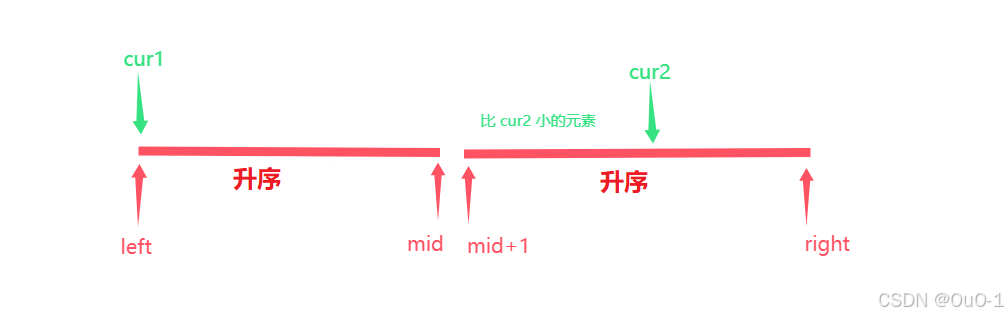
令 cur1 在左边区域中从左到右扫描,找出第一个 nums[ cur1 ] > nums[ cur2 ] 的 cur1
(1) nums[ cur1 ] <= nums[ cur2 ]
我们直接让 cur1++ ,并且为了让数组有序,我们要把 nums[cur1] 放入辅助数组中,方便后续排序,继续往后找即可:
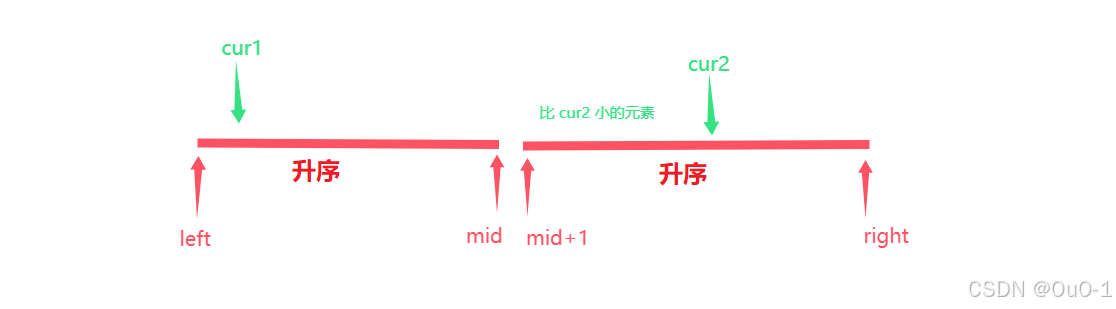
(2) nums[ cur1 ] > nums[ cur2 ]
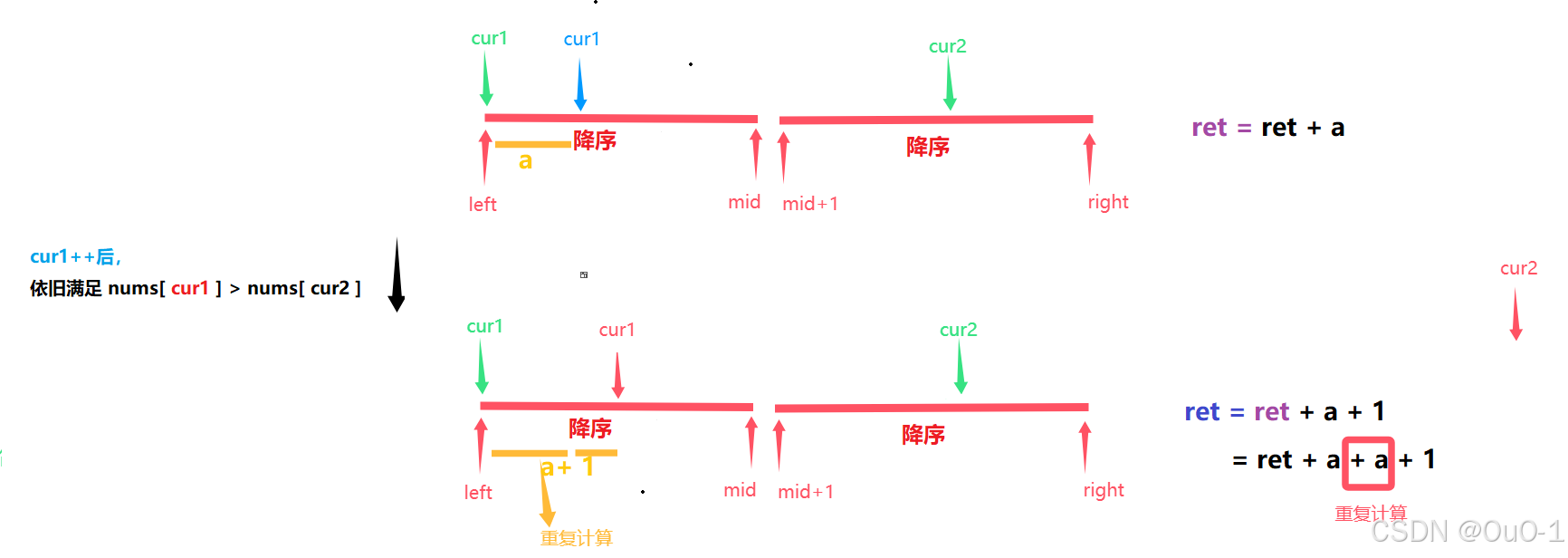
出现这种情况,对于两边升序区域,当 nums[ cur1 ] > nums[ cur2 ] ,说明此时 cur1 指向的元素,是左边区域第一个比 nums[ cur2 ] 大的元素;cur1 后面所有元素都比 nums[ cur2 ] 大
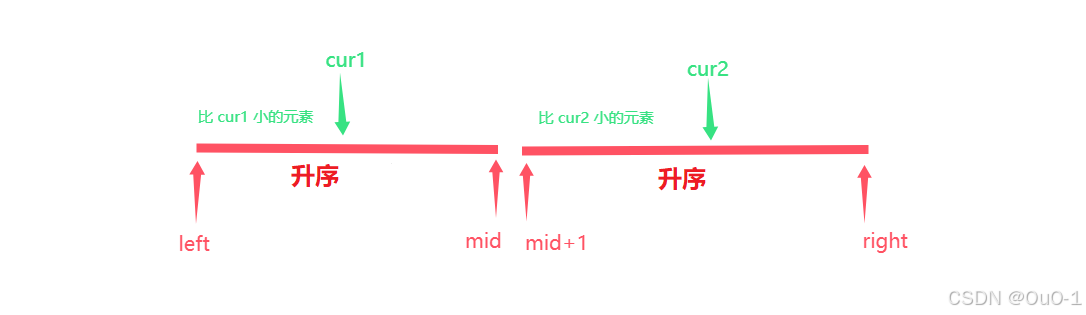
也因为是升序排序,在 cur1 一走到第一个合法位置时, ret += mid - cur1 + 1即可;
本轮 cur2 的所有能拿到的逆序对就已经统计好了,此时 cur2++ 即可;
如果策略一使用降序排列会出现的问题
对于降序排序,我们依旧是需要固定 cur2;
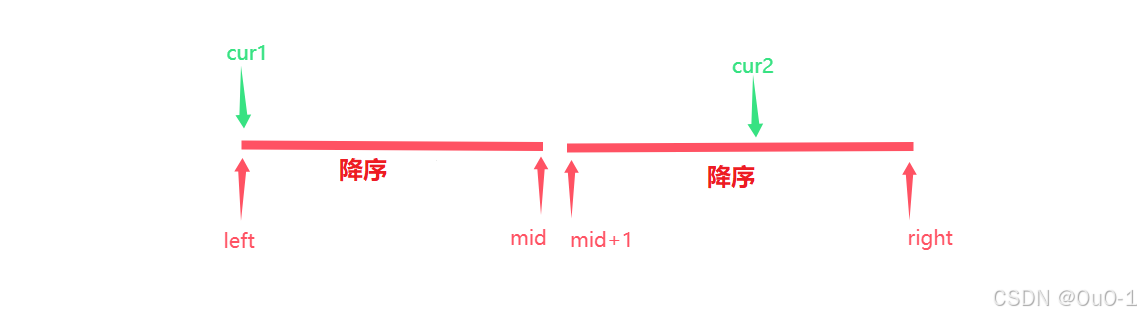
我们依旧需要采取【 只要 cur1 一移动到 nums[cur1]>nums[cur2] 的位置,就统计符合这个要求的区间的元素个数】的策略
如下图的情况:
因为是降序排序的,所以 cur2 不能因为 nums[cur1]>nums[cur2] 就马上++ ,还必须看下一个 cur1 能否满足 nums[cur1]>nums[cur2] :
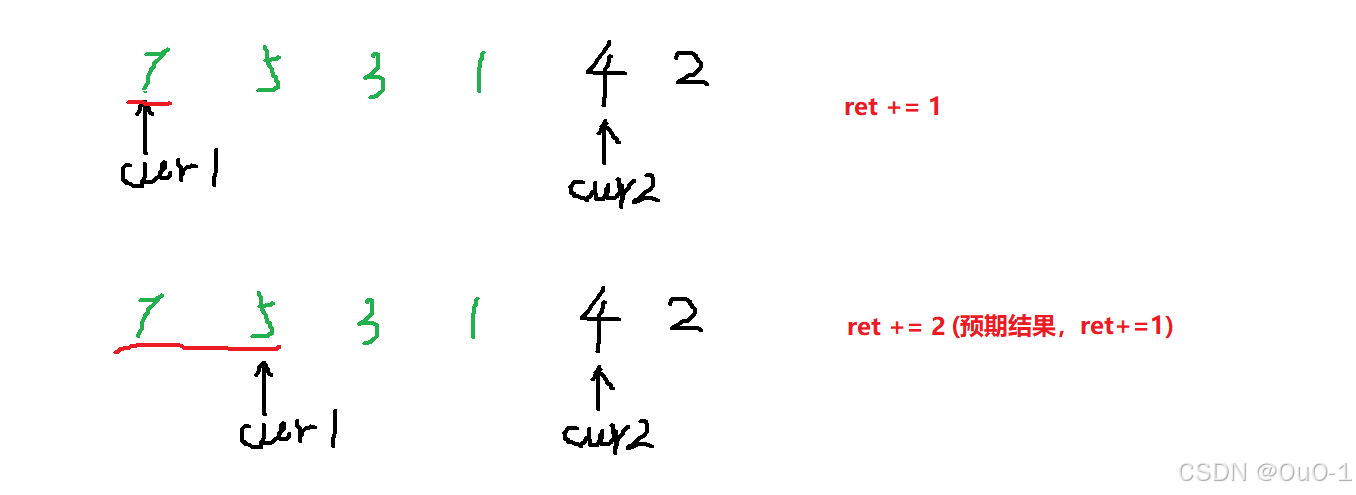
因为采取了【 只要 cur1 一移动到 nums[cur1]>nums[cur2] 的位置,就统计符合这个要求的区间的元素个数】的策略,因此就会造成大量的重复计算;
cur1 一移动,判断是否大于 cur2,如果判断成立,马上就让 ret += cur1 - left +1,所以会出现多次重复计算;
所以使用策略一,在排序数组时不能用降序,避免大量重复计数,所以只能用升序;
策略二 : nums[cur1]
统计一左一右逆序对的固定策略
固定 cur2, 只要 cur1 一移动到 nums[cur1]
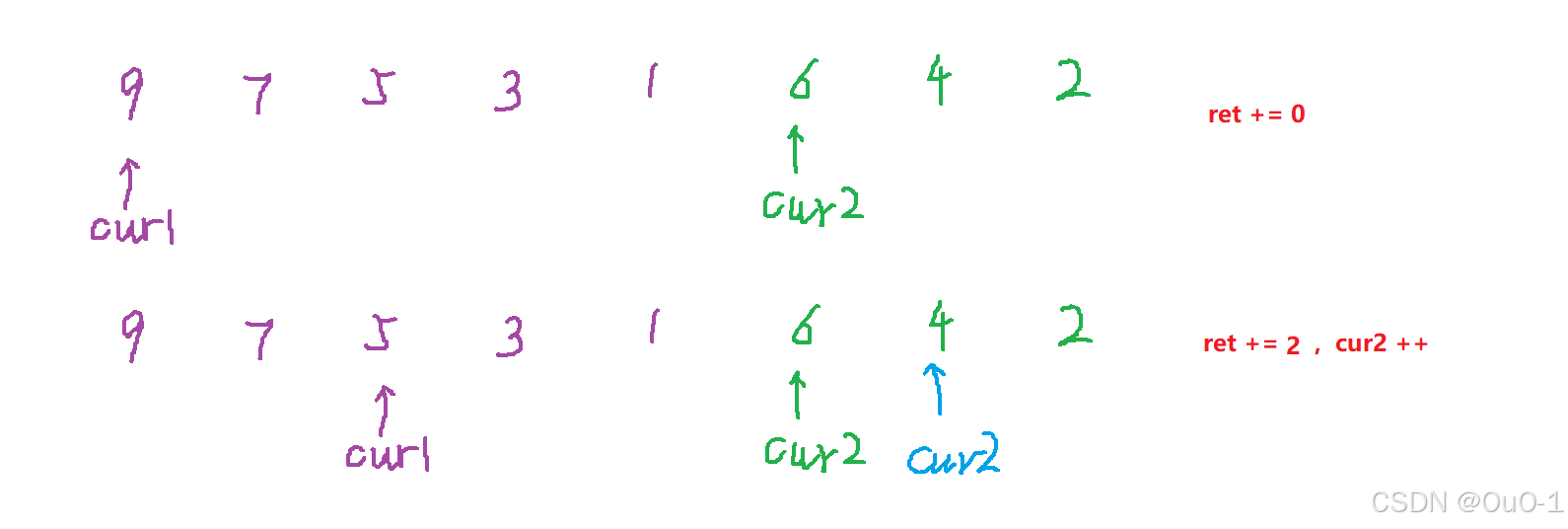
编写代码
策略一 + 升序
准备工作

主逻辑
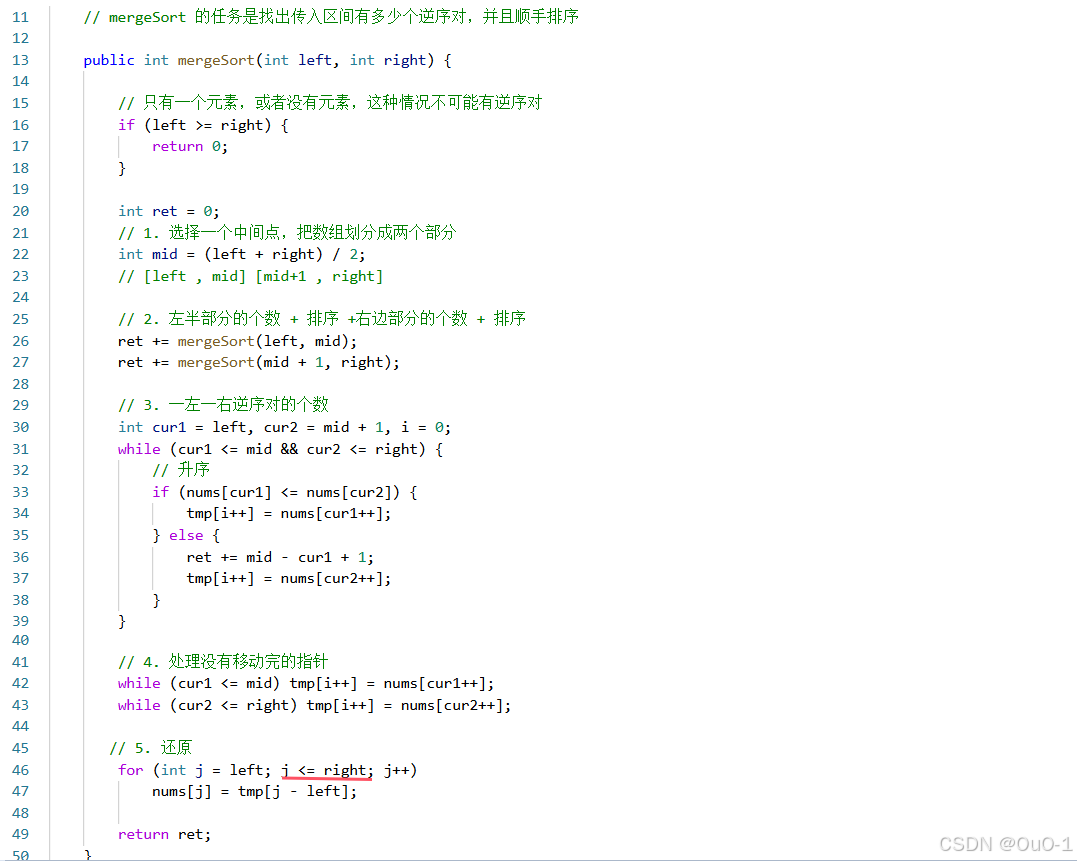
策略二 + 降序

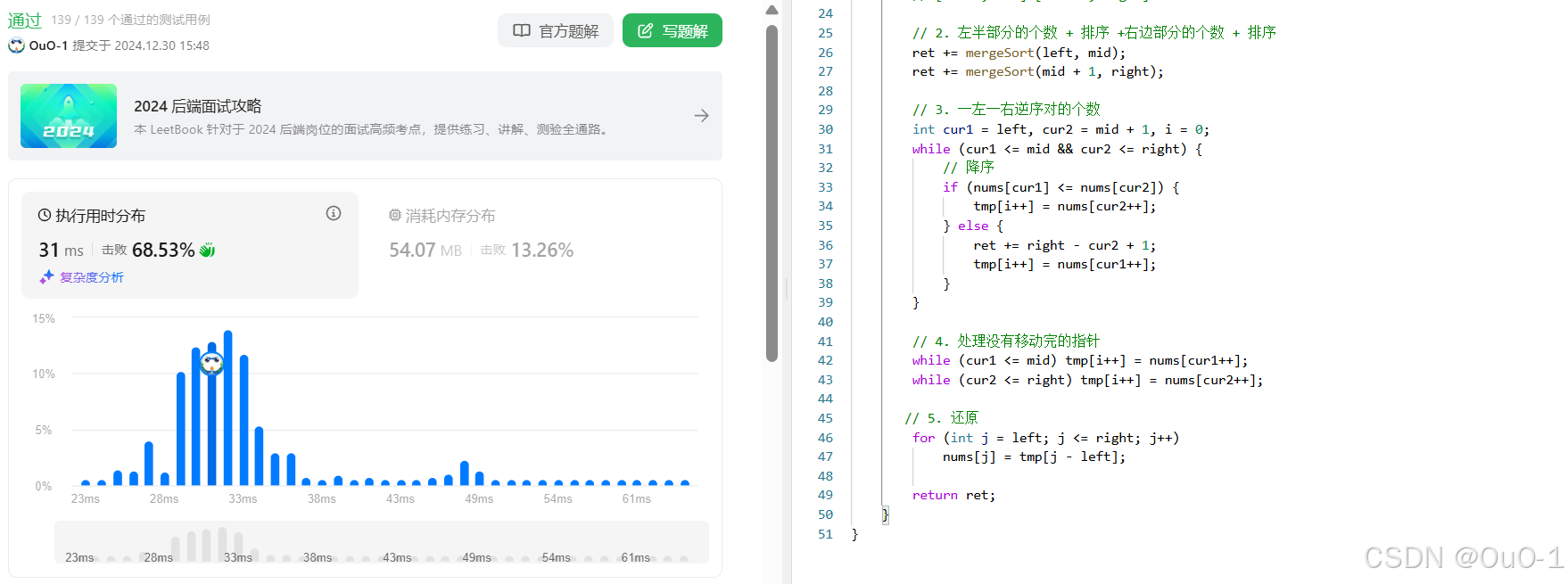
计算右侧小于当前元素的个数
题目解析

算法原理
这道题的本质,还是类似于求逆序对的个数;
解法:归并排序(左半部分 + 左排序 + 右半部分 + 右排序 + 一左一右 + 排序)
一左一右策略:nums[ cur1 ] < nums[ cur2 ] + 降序(上一题策略二)

- nums[ cur1] <= nums[ cur2 ] ,cur2++;修改对应的辅助数组;
- nums[ cur1 ] > nums[ cur2 ],把 nums[ cur1 ] 对应 ret[ ] 下标的元素加上 right - cur2 + 1; 修改对应的辅助数组;
处理细节问题
 我们要找到 nums[ cur1 ] 对应 ret[ ] 的对应下标 ,因为我们排序的时候,下标已经乱了;
我们要找到 nums[ cur1 ] 对应 ret[ ] 的对应下标 ,因为我们排序的时候,下标已经乱了;
如果我们使用哈希表来设置 < nums 元素 , ret 下标 > 的映射,如果 nums有重复元素,哈希表无法存储重复元素,就无法解决下标混乱的问题;
所以我们设置与 nums 同等规模的数组 index[ ],表示 nums 未排序时元素的原始下标,

不管 nums 因为排序,里面的元素怎么移动,index 对应的元素绑定移动:
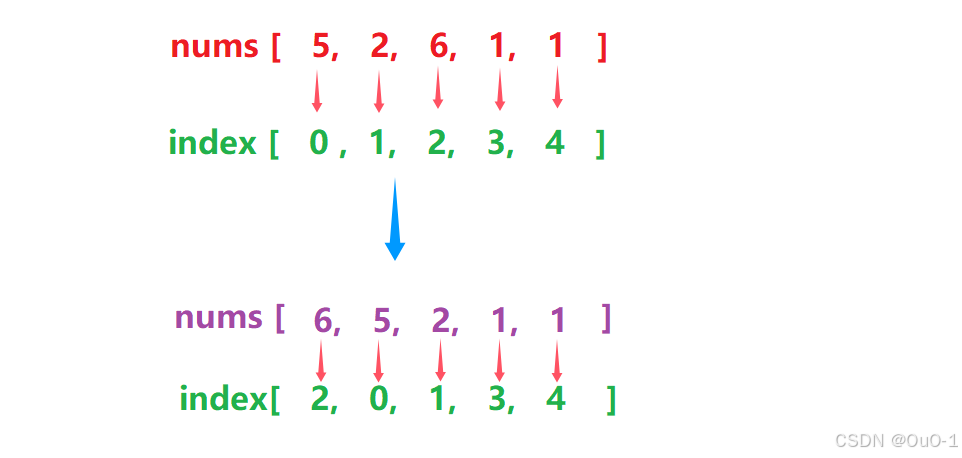
那如何让 nums[] 和 index[] 绑定移动呢?我们需要创建两个辅助数组 tmp,来让它们同步移动;
最后,让 ret [ index[ i ] ] += right - cur2 + 1 即可;
编写代码
准备工作
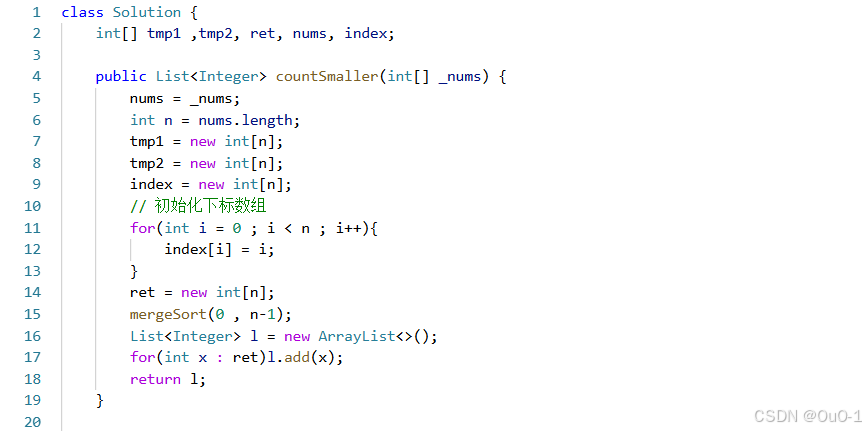
核心逻辑
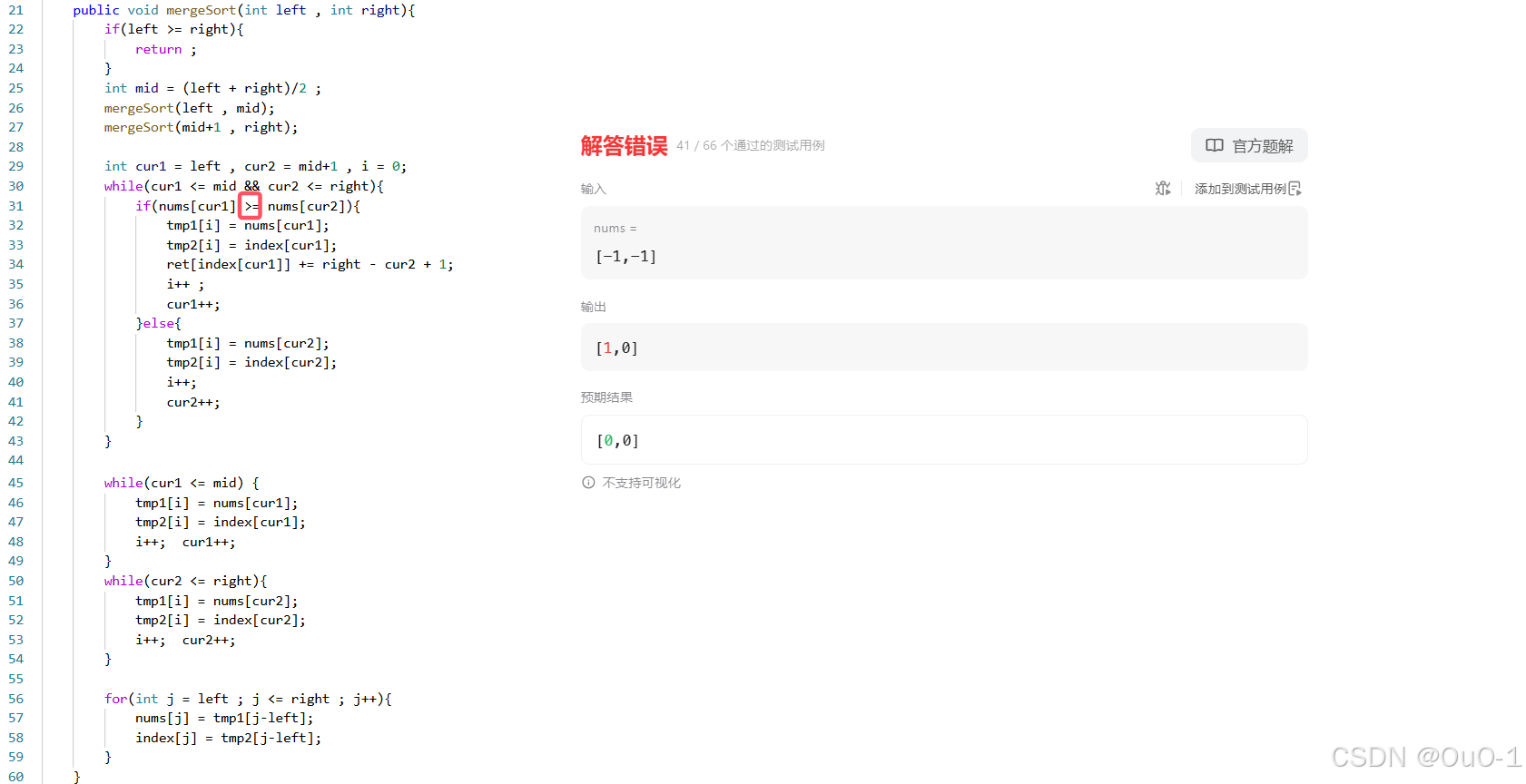
报错原因:对于降序排序的一左一右操作不熟练,判断条件写错了 ;
翻转对
拓展
直接插入排序
选择排序
冒泡排序
评论记录:
回复评论: