

一、前言
然而,在实际生产中,除了单表查询,更多的是多个表的联合查询,这样的查询通常是慢 SQL 的重灾区,查询速度慢,且使用服务器资源较多,如果能将这类 SQL 优化掉,那必将大大减轻数据库服务器压力。现在,咱就通过多表关联内部数据操作的角度,看看如何进行 SQL 优化。
# 创建两个表结构一模一样的表:t1、t2create table t1( id int not null auto_increment, a int, b int, c int, primary key(id), key idx_a(a));
create table t2 like t1;
delimiter //create procedure t1_proc()begin declare i int default 1; while (i<=3000) do if (i%3) = 0 then insert into t1(a,b,c) values(i, i, i); end if; set i=i+1; end while;end //delimiter ;
delimiter //create procedure t2_proc()begin declare i int default 1; while (i<=200000) do if (i%2) = 0 then insert into t2(a,b,c) values(i, i, i); end if; set i=i+1; end while;end //delimiter ;
call t1_proc();call t2_proc();
drop procedure t1_proc;drop procedure t2_proc;
[5.7.37-log localhost:mysql.sock]>select * from t1 limit 5;+----+------+------+------+| id | a | b | c |+----+------+------+------+| 1 | 3 | 3 | 3 || 2 | 6 | 6 | 6 || 3 | 9 | 9 | 9 || 4 | 12 | 12 | 12 || 5 | 15 | 15 | 15 |+----+------+------+------+5 rows in set (0.00 sec)
[5.7.37-log localhost:mysql.sock]>select * from t2 limit 5;+----+------+------+------+| id | a | b | c |+----+------+------+------+| 1 | 2 | 2 | 2 || 2 | 4 | 4 | 4 || 3 | 6 | 6 | 6 || 4 | 8 | 8 | 8 || 5 | 10 | 10 | 10 |+----+------+------+------+5 rows in set (0.00 sec)
三、MySQL JOIN 算法
MySQL 对两表关联,支持多种 Join 算法,咱就以下面这个 SQL 为例,深入探讨一下。
select * from t1 join t2 on t1.b=t2.b;
1、Simple Nested-Loop Join
for row_1 in t1: # 循环1000次 for row_2 in t2: # 对应每个外层循环10w次 if row_1.b == row_2.b: do something
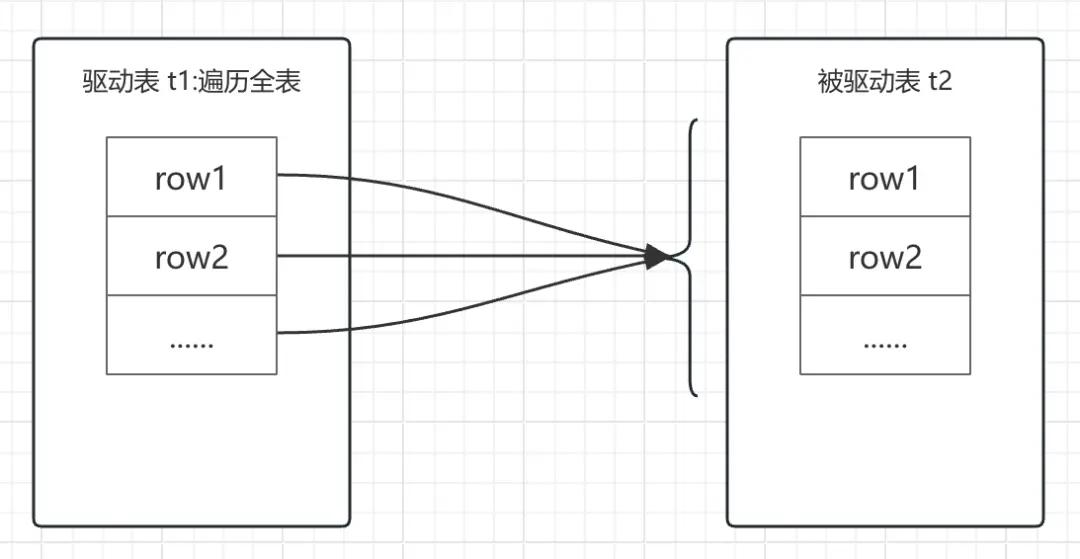
很显然,如果使用这种方式,当 t2 表足够大时,反复扫描数据的过程中,磁盘必然会被拉爆,服务器性能会急剧下降。像 MySQL 这样优秀的产品,必然会想方设法的避免这种情况的发生。
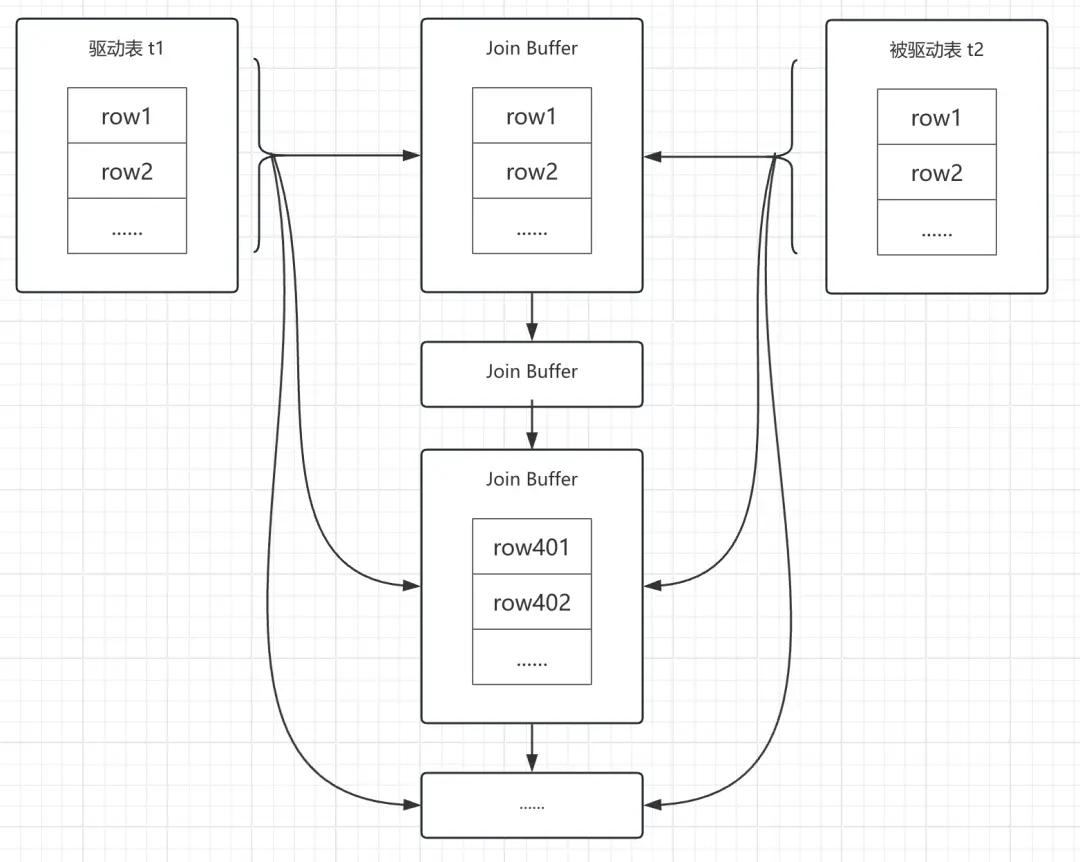
2、Block Nested-Loop Join
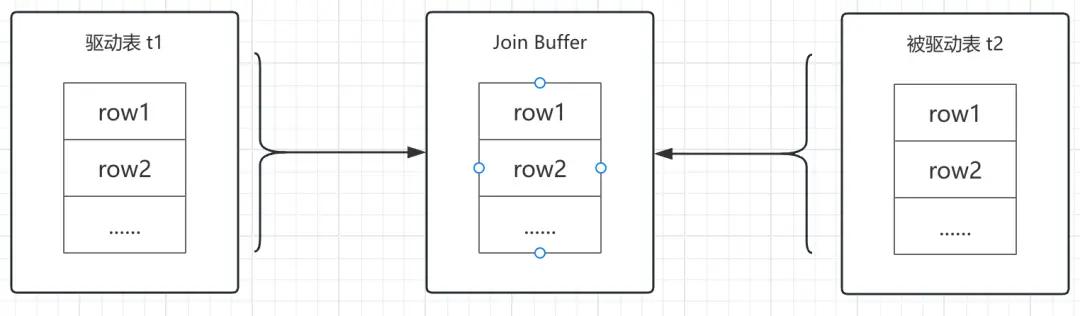
聪明的你,是不是在想:如果驱动表 t1 的结果集,无法一次性全部存放到 Join Buffer 内存中时,怎么办?
localhost:mysql.sock]>explain select * from t1 join t2 on t1.b=t2.b\G 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1000 filtered: 100.00 Extra: NULL 2. row *************************** id: 1 select_type: SIMPLE table: t2 partitions: NULL type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 100256 filtered: 10.00 Extra: Using where; Using join buffer (Block Nested Loop)2 rows in set, 1 warning (0.00 sec)
3、Hash Join
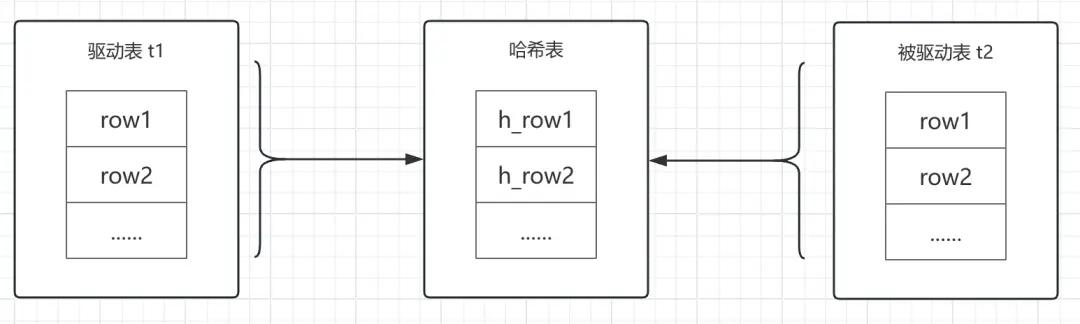
127.0.0.1:3380]>explain select * from t1 join t2 on t1.b=t2.b\G 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1000 filtered: 100.00 Extra: NULL 2. row *************************** id: 1 select_type: SIMPLE table: t2 partitions: NULL type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 100400 filtered: 10.00 Extra: Using where; Using join buffer (hash join)2 rows in set, 1 warning (0.00 sec)
[]>select * from t1 join t2 on t1.b=t2.b;......+------+------+------+------+------+------+500 rows in set (4.90 sec)
[8.0.27 127.0.0.1:3380]>select * from t1 join t2 on t1.b=t2.b;......+------+------+------+------+------+------+500 rows in set (0.02 sec)
4、Index Nested-Loop Join
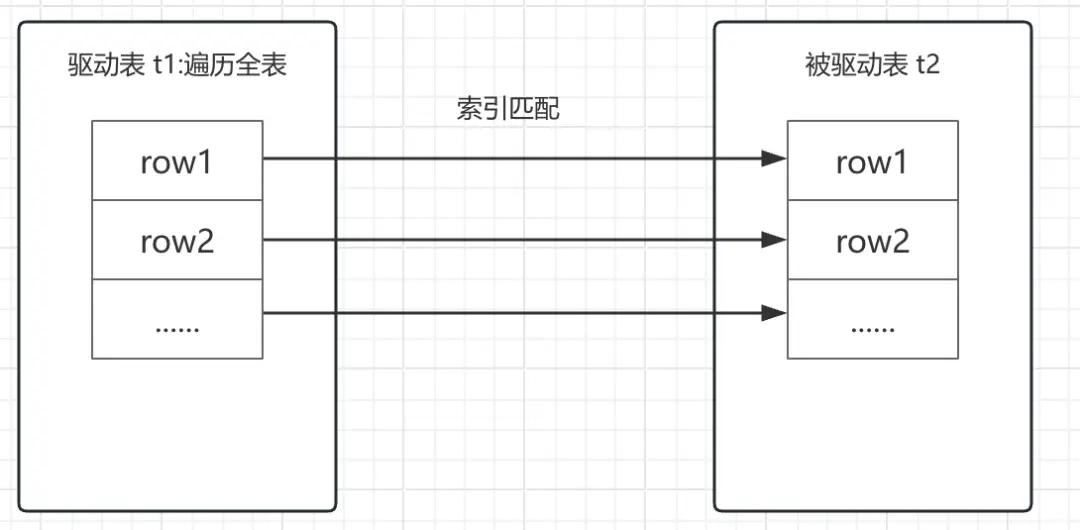
驱动表中的每一行记录,都可以通过被驱动表的索引列,进行索引查找(与关联列有关,可以是主键,也可以是二级索引),这瞬间就解决了被驱动表被扫描的问题。其本质,和单表查询中,通过建立合适索引的方式进行优化,是不是很相似。哪怕驱动表再大,如果索引列每个键值对应的数据量不大,那么索引查找速度依然可以快到起飞,这算法就叫 Index Nested-Loop Join。
select * from t1 join t2 on t1.b=t2.b;# 替换为select * from t1 join t2 on t1.b=t2.a;
localhost:mysql.sock]>explain select * from t1 join t2 on t1.b=t2.a\G 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1000 filtered: 100.00 Extra: Using where 2. row *************************** id: 1 select_type: SIMPLE table: t2 partitions: NULL type: refpossible_keys: idx_a key: idx_a key_len: 5 ref: db1.t1.b rows: 1 filtered: 100.00 Extra: NULL2 rows in set, 1 warning (0.00 sec)
[]>select * from t1 join t2 on t1.b=t2.a;......+------+------+------+------+------+------+500 rows in set (0.01 sec)
四、优化思路
1、初始 SQL
select *from t1 join t2 on t1.b = t2.bwhere t1.c in (6, 12, 18, 24, 30) and t2.c in (6, 12, 18, 24, 30);
localhost:mysql.sock]>explain select * from t1 join t2 on t1.b = t2.b where t1.c in (6, 12, 18, 24, 30) and t2.c in (6, 12, 18, 24, 30)\G 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1000 filtered: 50.00 Extra: Using where 2. row *************************** id: 1 select_type: SIMPLE table: t2 partitions: NULL type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 100345 filtered: 5.00 Extra: Using where; Using join buffer (Block Nested Loop)2 rows in set, 1 warning (0.00 sec)
从上面的执行计划可以看到,t1 表较小为驱动表,t2 表较大为被驱动表。咱一步一步分析,暂时剔除 t2 表,先看 t1 表是否有优化的空间,其现在是全表扫描,并通过 t1.c 列进行数据过滤。单表查询,如果查询条件列有索引,必然会加快查询速度对吧。
2、SQL 优化 1
select *from t1 join t2 on t1.b = t2.bwhere t1.a in (6, 12, 18, 24, 30) and t2.c in (6, 12, 18, 24, 30);
localhost:mysql.sock]>explain select * from t1 join t2 on t1.b = t2.b where t1.a in (6, 12, 18, 24, 30) and t2.c in (6, 12, 18, 24, 30)\G 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: rangepossible_keys: idx_a key: idx_a key_len: 5 ref: NULL rows: 5 filtered: 100.00 Extra: Using index condition 2. row *************************** id: 1 select_type: SIMPLE table: t2 partitions: NULL type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 100345 filtered: 5.00 Extra: Using where; Using join buffer (Block Nested Loop)2 rows in set, 1 warning (0.00 sec)
3、SQL 优化 2
select *from t1 join t2 on t1.b = t2.bwhere t1.a in (6, 12, 18, 24, 30) and t2.a in (6, 12, 18, 24, 30);
localhost:mysql.sock]>explain select * from t1 join t2 on t1.b = t2.b where t1.a in (6, 12, 18, 24, 30) and t2.a in (6, 12, 18, 24, 30)\G 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: rangepossible_keys: idx_a key: idx_a key_len: 5 ref: NULL rows: 5 filtered: 100.00 Extra: Using index condition 2. row *************************** id: 1 select_type: SIMPLE table: t2 partitions: NULL type: rangepossible_keys: idx_a key: idx_a key_len: 5 ref: NULL rows: 5 filtered: 10.00 Extra: Using index condition; Using where; Using join buffer (Block Nested Loop)2 rows in set, 1 warning (0.00 sec)
4、SQL 优化 3
select *from t1 join t2 on t1.b = t2.awhere t1.a in (6, 12, 18, 24, 30) and t2.c in (6, 12, 18, 24, 30);
localhost:mysql.sock]>explain select * from t1 join t2 on t1.b = t2.a where t1.a in (6, 12, 18, 24, 30) and t2.c in (6, 12, 18, 24, 30)\G 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: rangepossible_keys: idx_a key: idx_a key_len: 5 ref: NULL rows: 5 filtered: 100.00 Extra: Using index condition; Using where 2. row *************************** id: 1 select_type: SIMPLE table: t2 partitions: NULL type: refpossible_keys: idx_a key: idx_a key_len: 5 ref: db1.t1.b rows: 1 filtered: 50.00 Extra: Using where2 rows in set, 1 warning (0.00 sec)
5、疑问
# 添加c列索引alter table t2 add index idx_c(c);
# 调整t2表a列数据,a列查询条件中的值,每个值对应的数据量为4000update t2 set a=a%50;
# 消除表碎片,避免被其干扰alter table t2 engine=innodb;
# 驱动表传过来的键值,每个键值对应的数据为4000行[5.7.37-log localhost:mysql.sock]>select a,count(a) cnt -> from t2 -> where a in (6, 12, 18, 24, 30) -> group by a;+------+------+| a | cnt |+------+------+| 6 | 4000 || 12 | 4000 || 18 | 4000 || 24 | 4000 || 30 | 4000 |+------+------+5 rows in set (0.01 sec)
# 总共符合条件的数据,5行[5.7.37-log localhost:mysql.sock]>select * from t2 where c in (6, 12, 18, 24, 30);+----+------+------+------+| id | a | b | c |+----+------+------+------+| 3 | 6 | 6 | 6 || 6 | 12 | 12 | 12 || 9 | 18 | 18 | 18 || 12 | 24 | 24 | 24 || 15 | 30 | 30 | 30 |+----+------+------+------+5 rows in set (0.01 sec)重写测试 SQL:
select *from t1 join t2 on t1.b = t2.awhere t1.a in (6, 12, 18, 24, 30) and t2.c in (6, 12, 18, 24, 30);执行计划:
localhost:mysql.sock]>explain select * from t1 join t2 on t1.b = t2.a where t1.a in (6, 12, 18, 24, 30) and t2.c in (6, 12, 18, 24, 30)\G 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: rangepossible_keys: idx_a key: idx_a key_len: 5 ref: NULL rows: 5 filtered: 100.00 Extra: Using index condition 2. row *************************** id: 1 select_type: SIMPLE table: t2 partitions: NULL type: rangepossible_keys: idx_a,idx_c key: idx_c key_len: 5 ref: NULL rows: 5 filtered: 4.55 Extra: Using index condition; Using where; Using join buffer (Block Nested Loop)2 rows in set, 1 warning (0.00 sec)五、最后

扫一扫,加入技术交流群
本文分享自微信公众号 - 京东云开发者(JDT_Developers)。
如有侵权,请联系 [email protected] 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。
评论记录:
回复评论: