

官方在 8.0.37 中修复了这个 bug,可升级到 8.0.37 解决。
作者:胡呈清,爱可生 DBA 团队成员,擅长故障分析、性能优化,个人博客:[简书 | 轻松的鱼],欢迎讨论。
爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
本文约 1500 字,预计阅读需要 8 分钟。
问题描述
MySQL 版本:8.0.26
跑批执行到 insert into t1 select * from t2 时,有一个定时任务运行 MySQL 巡检脚本,巡检脚本执行到 select * from performance_schema.data_locks、select * from performance_schema.data_lock_waits 会导致 MySQL hang,一开始只是某些 SQL 执行无响应,最终 MySQL 无法登录。
分析过程
1. 开始 hang 时的线程状态
下图标记的两个线程中:
- 第一个线程完整的 SQL 是
insert into t1 select * from t2 - 第二个线程完整的 SQL 是
select * from performance_schema.data_lock_waits,这是巡检脚本里的 SQL,上一句是select * from performance_schema.data_locks - 其余线程全部都卡住了

2. 分析堆栈
分析等锁和互斥量的线程持有和正在等待的锁情况如下:
- Thread 285 持有 LOCK_status,被 Thread 21 持有的
srv_innodb_monitor_mutex阻塞 - Thread 21 持有
srv_innodb_monitor_mutex,被未知线程持有的trx_sys_mutex_enter()即trx_sys->mutex阻塞 - 大量线程被 Thread 285 持有的 LOCK_status 阻塞
- 大量线程(包括
insert into..select和查询ps.data_lock_wait)阻塞在trx_sys_mutex_enter()
现在的问题是没有找到哪个线程持有了 trx_sys->mutex 互斥量。
< ,
, >
>
3. 本地复现
调用存储过程,当执行到 insert into ... select... 时,另外一个 session 执行 select * from performance_schema.data_locks。
反复测试了很多次,后面找到了复现的必要条件:
执行 select * from performance_schema.data_locks 报错内存分配异常:ERROR 3044 (HY000): Memory allocation error: while scanning data_locks table in function rnd_next.
然后才能观察到 insert into ... select 卡住,堆栈显示这个线程在等 trx_sys->mutex。
复现截图:
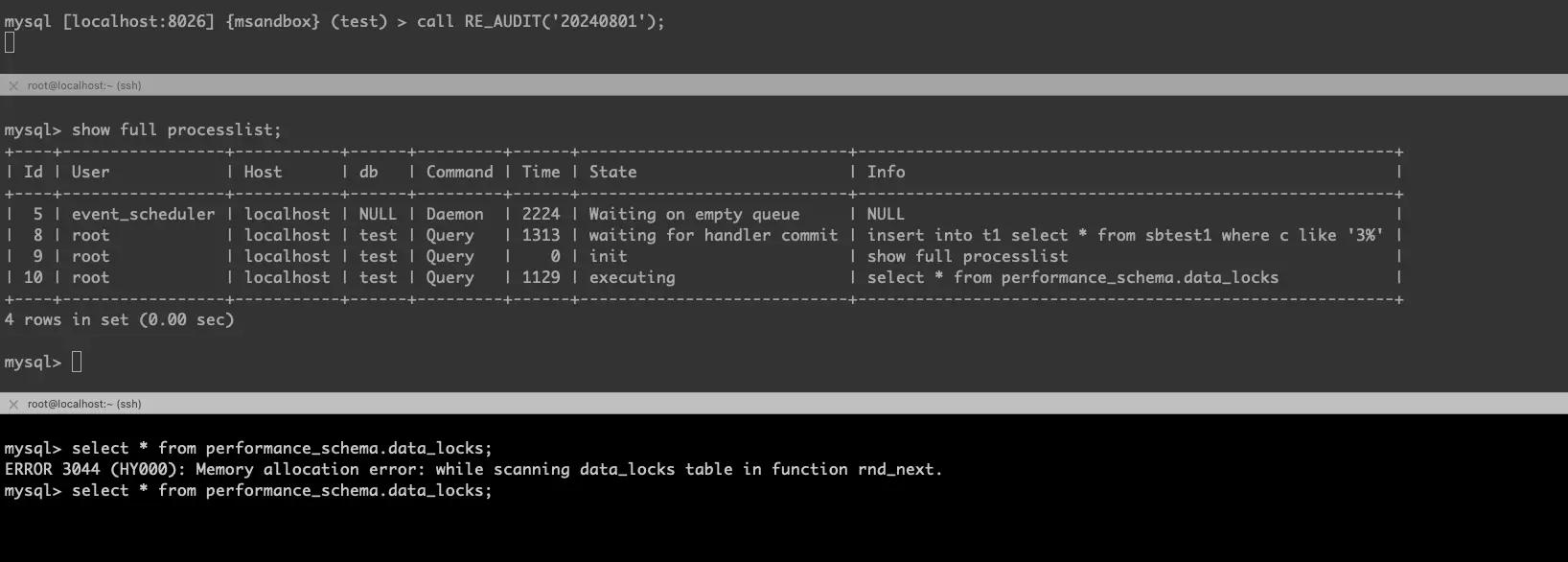
insert into ... select 线程堆栈如下,不过分析所有线程堆栈后仍然找不到谁持有了 trx_sys->mutex。

4. 代码分析 trx_sys->mutex 结构
由于堆栈信息里找不到 trx_sys->mutex 互斥锁的持有者,想到的另外一个方法是用 gdb 打印出 trx_sys->mutex 结构,看其中是否有线程 ID 信息。
发现只有 debug 模式下才有 线程 ID 信息,普通模式下没有,因此需要编译一个 debug 版本进行复现,然后用 gdb 打印出 trx_sys->mutex 互斥锁的持有者。


5. debug 版本复现
当查询 ps.data_locks 触发内存分配报错后,通过 gdb 打印 insert into 线程的堆栈,卡在了 mutex_enter_inline:

然后打印查询 ps.data_locks 的线程堆栈,堆栈是正常的,但是打印 trx_sys->mutex 时发现持有者竟是它自己:
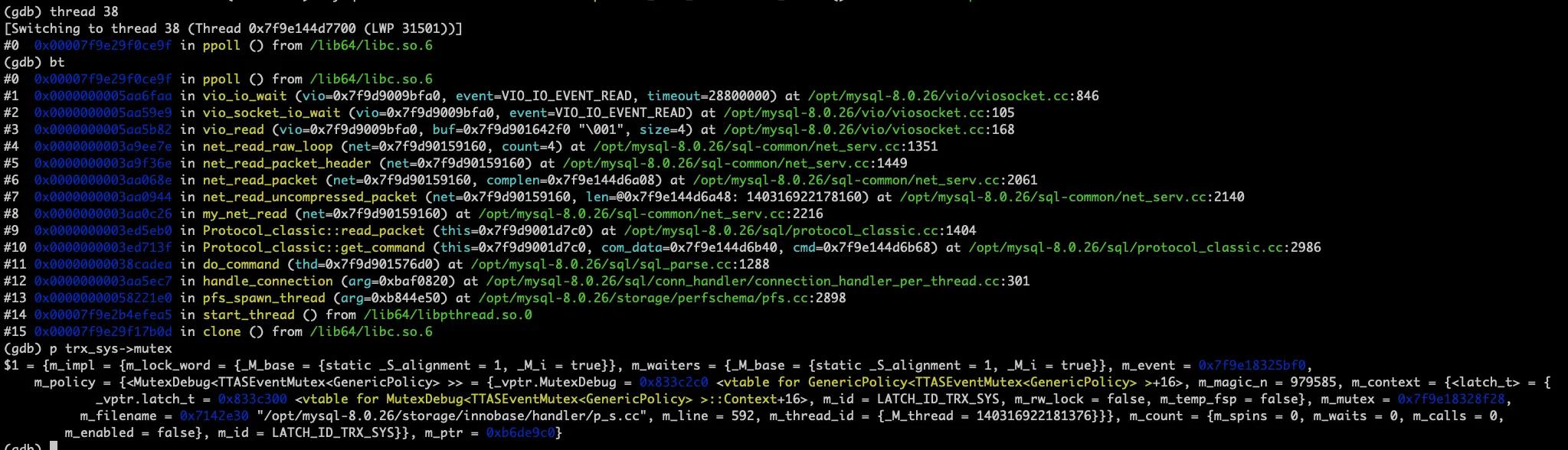
将 _M_thread 的值转换为 16 进制,就可以用来核对 gdb info thread 输出的的线程号:
gdb) p/x 140316922181376
$2 = 0x7f9e144d7700
6. 合理推测 & 找证据
经过 debug 版本上复现,发现查询 ps.data_locks 时触发内存分配错误,但是没有释放 trx_sys->mutex 互斥量。
于是合理推测:存在 bug,查询 ps.data_locks 时触发内存分配错误后,不会释放 trx_sys->mutex,导致内部死锁。
找到了这个 bug:https://github.com/mysql/mysql-server/commit/d6be2f8d23b1fe41f10c7147957faf68b117abb2
7. bug 解释
在 performance_schame.data_locks 的实现中,使用了 C++ try-catch 机制来处理读取 data_locks 记录时内存分配失败的异常情况。
在 table_data_locks.cc 文件的 table_data_locks::rnd_next 函数中:


代码解释: catch (const std::bad_alloc &) 用来捕获 std::bad_alloc 类型的异常,当 try 块中抛出 std::bad_alloc 异常时,调用 my_error 打印错误信息,并返回 ER_STD_BAD_ALLOC_ERROR,结束执行。
try 模块中的 iterator_done = it->scan(&m_container, true); 是实际执行的业务逻辑代码,it->scan 进行某种迭代扫描操作,结果存储在 iterator_done 变量中。catch 模块捕获的异常就是由这里抛出的。
it->scan 的定义在 p_s.cc 源码文件的 Innodb_data_lock_iterator::scan 函数中,执行逻辑很清晰:
trx_sys_mutex_enter()先加trx_sys->mutex互斥锁- 调用
scan_trx_list扫码rw_trx_list、mysql_trx_list两个事务列表 trx_sys_mutex_exit()释放trx_sys->mutex互斥锁
很显然,调用 scan_trx_list 扫描时如果发生 std::bad_alloc 内存异常,会直接被 catch 模块获取,抛出异常结束执行,无法执行到 trx_sys_mutex_exit() 释放互斥锁,导致了 trx_sys->mutex 互斥锁的残留。

这一点可以在 debug 版本复现时打印的 trx_sys->mutex 信息中得到证实:是在 p_s.cc 文件的第 592 行加上的。

复现步骤
简化的复现步骤如下:
- 准备一个小内存的虚拟机,比如 2-4G,方便触发内存分配异常
- 造一张 500 万行的表 t1
- 执行
begin;select * from t1 for update; - 执行
select * from performance_schema.data_locks;触发报错ERROR 3044 (HY000): Memory allocation error: while scanning data_locks table in function rnd_next. - 继续查询
performance_schema.data_lock_waits会被阻塞。
结论
该故障成因如下:
- 跑批中
INSERT INTO t1 SELECT * FROM t2;会对t2表所有行加 S Lock(原因:RR 隔离级别,并且无法走索引)。t2表很大,有几亿行,会导致performance_schema.data_locks中有几亿个锁记录; - 查询 ps.data_locks 时,由于记录数太多,消耗大量内存,触发内存分配异常。在 ps.data_locks 的实现中,内存分配异常是由 C++ try-catch 机制处理的,但是这个异常处理发生在 mutex lock 和 mutex unlock 之间,导致 mutex 不释放。本次故障就是执行
trx_sys_mutex_enter()后迭代扫描锁记录时发生了内存分配异常,trx_sys_mutex_exit()释放互斥锁的操作未执行,残留了下来; - 由于
trx_sys->mutex互斥锁在 InnoDB 中被大量使用,接下来巡检脚本查询 data_lock_waits 被阻塞,后台 purge 线程、innodb monitor 线程、元数据刷新进程、用户线程执行的业务 SQL 都被阻塞,最终会导致死锁。
解决方案
-
官方在 8.0.37 中修复了这个 bug,可升级到 8.0.37 解决。
修复方式是在
ps.data_locks、data_lock_waits的实现中去掉了try-catch这段代码,防止发生在 mutex lock 和 mutex unlock 之间处理异常,导致 mutex unlock 无法执行残留 mutex。 -
不要在行锁很多的情况下查询
ps.data_locks。
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
SQLE 是一款全方位的 SQL 质量管理平台,覆盖开发至生产环境的 SQL 审核和管理。支持主流的开源、商业、国产数据库,为开发和运维提供流程自动化能力,提升上线效率,提高数据质量。
✨ Github:https://github.com/actiontech/sqle
? 文档:https://actiontech.github.io/sqle-docs/
? 官网:https://opensource.actionsky.com/sqle/
? 微信群:请添加小助手加入 ActionOpenSource
评论记录:
回复评论: