
没有人能保证数据同步能在各种特征的流量中都平稳工作,所以......
作者:爱可生 ActionDB 技术团队。
爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
本文约 2800 字,预计阅读需要 10 分钟。
案例背景
某客户需要将 Oracle 的数据同步到 OceanBase(MySQL 模式)。涉及到 OceanBase 的数据同步 / 迁移的工作就需要用到 OMS 了。
OceanBase 数据迁移服务(OceanBase Migration Service,OMS)是 OceanBase 数据库一站式数据传输和同步的产品。它支持多种关系型数据库、消息队列与 OceanBase 数据库之间的数据复制,是集数据迁移、实时数据同步和增量数据订阅于一体的数据传输服务,OMS 帮助您低风险、低成本、高效率的实现 OceanBase 的数据流通,助力构建安全、稳定、高效的数据复制架构。
数据同步需要注意些什么呢?
- 首先,保证数据不丢失、两端一致。
- 其次,要提高数据同步的效率。
- 两端数据的延迟越低越好
- 迁移流量 RPS 越高越好
这样对于业务侧来说,目标端数据库的数据一直是最新的,数据同步的意义也就在这里。
数据同步问题诊断痛点
目前,OMS 在数据同步时如果出现性能波动或故障情况,只能展示同步的整体延迟和迁移流量、PRS 等指标值。如果要进一步定位延迟升高、数据同步阻塞等情况的具体原因,则需要用户在 OMS 服务器上手动执行诊断命令。
手动执行诊断的过程较为繁琐、展示效果不够直观,同时问题处理建议也常常缺乏足够精确度的数据支撑。
ActionOMS
ActionOMS 基于 OMS 本身的优秀能力,并依托于爱可生公司在数据库及周边工具的多年开发经验、对数据迁移 / 同步过程的深刻理解与运维经验,推出的定制化版本。
官方授权
ActionOMS 由 OceanBase 向爱可生进行了全部代码授权,可对 OMS 问题进行源码解释并修复,同时可以接受定制化开发的 OMS 版本。
版本介绍
2024 年 7 月中旬,ActionOMS 发布了 4.24.07.0 版本。该版本新增了智能性能诊断和智能故障诊断功能。结合 量化推导,自顶向下 (Top-Down) 的思路,从进程开始,逐层深入,细化到具体工作线程、缓存队列等内部机制,最终定位性能问题。
智能诊断:不需要通过手动介入的方式,自动化采集各项性能指标,系统层面分析指标异常值,最终展现给用户精准的延迟故障点以及对应的调整方案。
实践案例
客户要求在数据同步过程中对影响性能指标的原因进行排查,依靠全面细致的监控数据给出同步过程中出现的延迟问题处理方案。
为了满足客户需求,ActionOMS 重塑了延迟诊断逻辑,支持自动化采集各组件的性能指标,并结合 SRE 常用的诊断思路,提供系统性、精准的诊断结果和优化方案,使用户在页面上能以更直观的方式了解问题原因并进行调整。
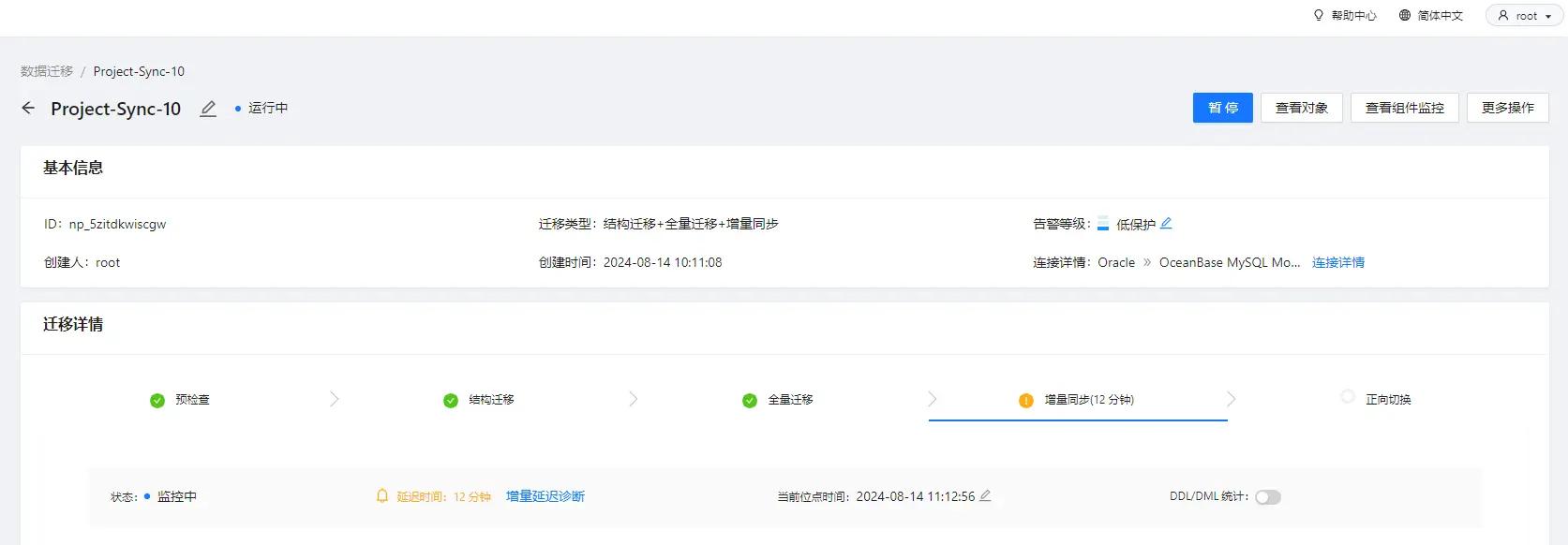
针对上图中出现的增量同步达到了 12 分钟,并且延迟时间还在一直上涨的情况,通过新增的增量延迟诊断功能,我们可以看到数据同步过程中关键节点的延迟情况、出现问题的节点以及对应的处理建议。

结构说明
第一层:两端同步关键节点
第一层展示的为两端数据同步中的比较关键的步骤,其对应的为组件或进程。
显示当前节点处理增量记录的两个时间:
- 延迟时间 = 当前时间 - 节点处理的最新增量记录的时间
- 最新的指标时间:当前诊断所依据的指标的生成时间
图中可知,日志采集 、日志格式转换 、日志缓存 等节点的状态都为正常(蓝色)且延迟时间较小,表示这些步骤处理的增量记录几乎都是最新的。
日志回放 的状态为阻塞(红色),其延迟时间为 11 分 52 秒,和增量同步延迟时间基本一致,表示增量记录都阻塞在回放阶段。导致最终目标端的数据延迟也为 12 分钟左右。
想要确定回放阶段具体出现了什么问题,我们就要看第二层节点。
第二层:红色节点问题分析

第二层展示的为第一层中状态为阻塞且标记为红色的子节点(第一层不同的步骤会包含不同的第二层节点)。
显示问题节点工作处理器信息:
- 当前处理器名称
- 作用
- 状态 :状态为阻塞时,显示阻塞信息:
- 原因
- 处理建议
- 依据的指标信息
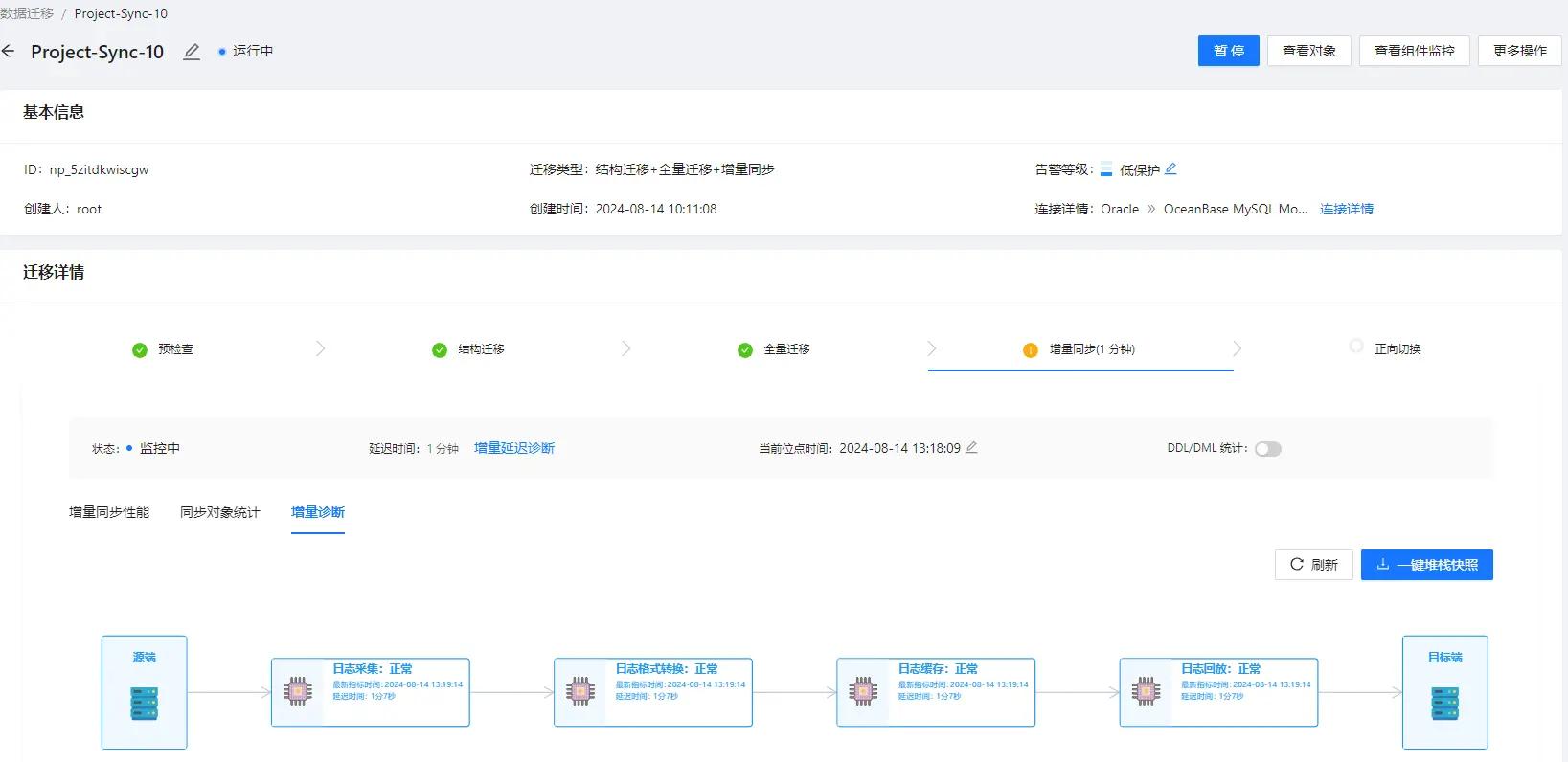
第一层日志回放出现了阻塞,那么第二层显示的为日志回放步骤中更为具体的流程,包含:store 接收 & 拼接事务 -> ETL 数据转换 -> 梳理事务顺序 -> 向目标端回放数据。
其中 梳理事务顺序节点 状态为阻塞(该节点负责梳理增量记录中的事务关系,对于不相关事务可以做到并行回放,相关事务由于之间的依赖性,目前只能顺序回放)。
诊断结论 显示为事务链可能出现了阻塞等未知问题,依据的指标为事务记录缓存的使用率超过 50%,对应的 处理建议 也具体到需要调整的参数和值。
处理效果
ActionOMS 针对系统给到的处理建议调整参数后,可以看到 迁移流量和 RPS 均得到 2-3 倍提升!
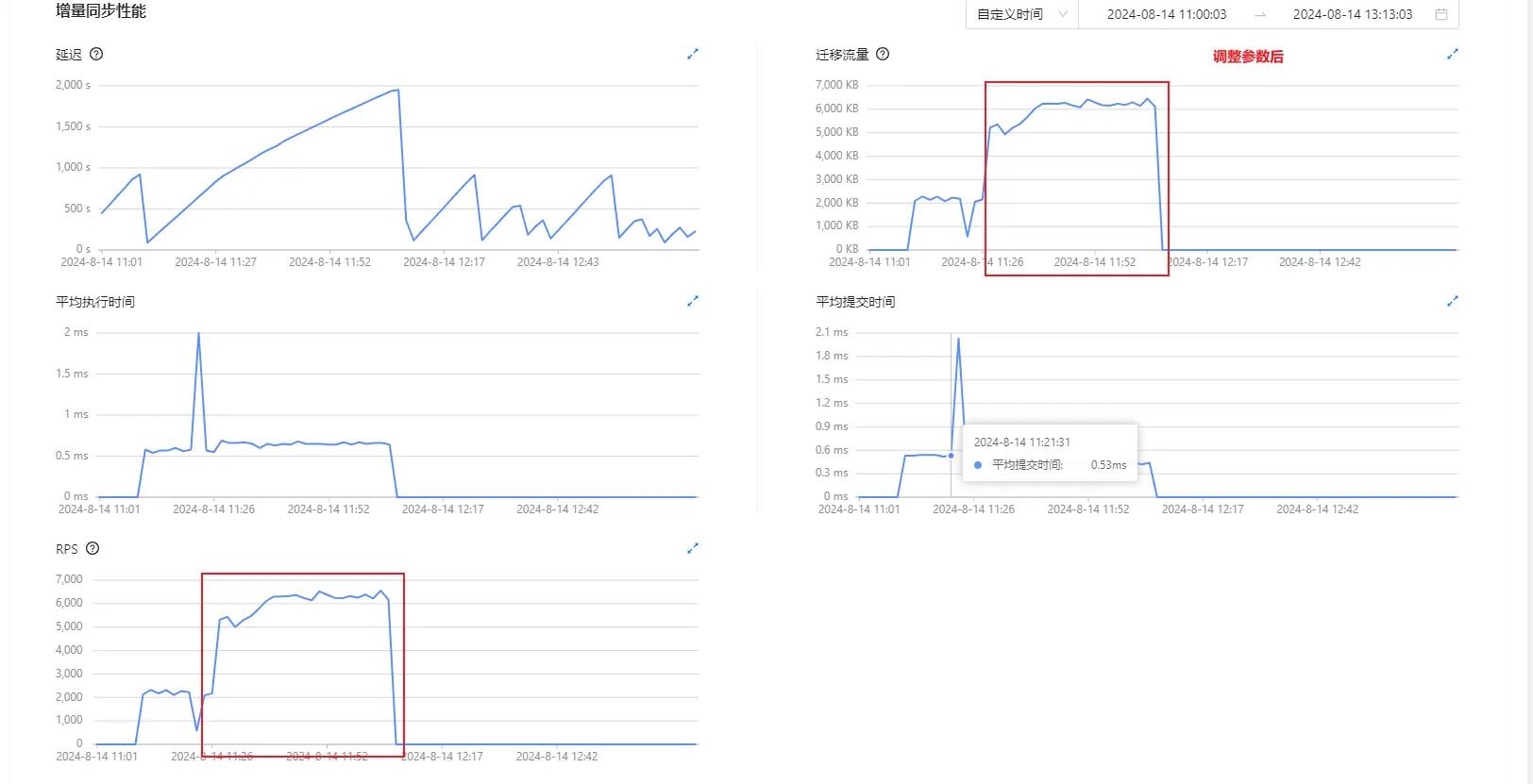
后续在 12 点左右,增量数据完成同步并且延迟回落。
功能详解
自动化采集各项性能指标
貌似端到端数据同步需求很简单,不就是从源端库把数据拿到,再回放到目标端库么?实际上实现还是相对繁琐的。其中包含的过程:
- 源端数据抽取
- 数据解析转换
- 数据缓存
- 目标端回放
每个过程可能又有不同的进程来负责,而每个进程又包含了大量的工作线程和缓存等。每个环节出现问题都有可能导致延迟升高、目标端数据不更新。
对于故障诊断来说,首先也是必须要实现的就是要采集同步过程中涉及的所有工作线程、缓存等各项性能指标,这一点也是后续诊断的基石,没有全部的性能指标,也就无法用全局视角看待问题。
系统层面分析指标异常值
在全面获取到各项性能指标后,往往需要一些对于故障的方法论才能得到更可靠的结论以及调整方案。
ActionOMS 依托爱可生公司多年在数据库及周边工具的一线运维工作得到的方法论,结合 自顶向下(Top-Down) 的诊断思路。从整体上衡量工作线程的利用率,通过分析如 _thread_used_1m(每分钟工作线程使用率)、_thread_rps_1min(每分钟工作线程吞吐量)、_queue_depth(队列深度)、_thread_idling_1min(每分钟线程空转率)等关键指标,识别是否存在性能问题。
对于特定场景下,比如:
- 线程调度是否均匀? 程序会自动计算同组内指标值的离散值用于反应调度问题。
- 线程是否存在卡住的情况? 通过线程使用率和吞吐量指标相结合分析的方式,另外对于线程使用率相较于 CPU 使用率计算方式做了扩展,可识别线程让出,但对于程序来说仍然卡住的情况。
- 在 ORACLE-RAC 中多实例中流量不均衡会导致延迟升高? 由于每个实例都会独立产生 REDO LOG,ActionOMS 为了保持增量变更的有序性,对 RAC 架构这种多日志流来源场景的事务结果会进行合并排序。通过合并排序的线程空转率来判定是否存在因流量不均匀带来的延迟高问题。
给用户展现精准的延迟故障点
数据同步过程中,一个节点出现了问题,可能会连锁的导致上游节点的指标值都出现异常,对于诊断系统来说,溯源同等重要。
ActionOMS 采用 自右到左 思路,往往最下游出现的问题才是关键问题,首先暴露下游问题,解决后再重新诊断,逐步解决。

补充说明
考虑到现场场景的复杂性,现有的诊断方法论可能覆盖不了的情况。能更方便的收集现场信息交由研发人工诊断,我们在页面提供 一键堆栈快照 按钮,可一键收集增量过程中全部进程堆栈、火焰图等信息。后续也会逐渐丰富诊断的方法论。
对于自动采集以及诊断的需求来说,除了满足自身需要,还需要保证不会对被采集和诊断的系统造成明显的性能损耗。这里我们在指标采集和指标诊断的过程中,默认选择每分钟的采集频率和采用异步处理整个过程。
总结
对于一个数据同步系统来说,随着业务的变化,业务的数据流量特征也会随之变化。没有人能保证数据同步能在各种特征的流量中都平稳工作。
提供自动的诊断功能是为了实时监控和分析系统的各项性能指标,及时识别和处理潜在问题,确保系统在面对复杂、多变的业务流量时仍能稳定运行。它不仅能帮助系统管理员快速定位问题源头,还能提供相应的调整建议,以便在问题发生时迅速采取措施,避免数据同步延迟对业务造成更大的影响。
ActionOMS 不仅提升了数据同步系统的健壮性和可靠性,还大大降低了运维人员的工作负担,避免了因为未知问题导致的长时间排查过程,使得整个数据同步过程更加高效、稳定。
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
SQLE 是一款全方位的 SQL 质量管理平台,覆盖开发至生产环境的 SQL 审核和管理。支持主流的开源、商业、国产数据库,为开发和运维提供流程自动化能力,提升上线效率,提高数据质量。
✨ Github:https://github.com/actiontech/sqle
? 文档:https://actiontech.github.io/sqle-docs/
? 官网:https://opensource.actionsky.com/sqle/
? 微信群:请添加小助手加入 ActionOpenSource
评论记录:
回复评论: