
学习目标:
(1)理解掌握KNN算法的原理
(2)掌握以MapReducer编程实现KNN算法
(3)掌握以MapReducer编程实现KNN分类器评估
实现的Hadoop框架如下:
任务背景
XX网站是一个深受用户欢迎的电影网站,它提供了大量的电音介绍及评论,包括上影的影视查询及其购票服务。用户可以记录想看、看过的电影,顺便打分、写电影评。为了提高用户的使用体验和满意度,网站计划为广大的用户提供更精准‘更个性化的电影推荐服务。
什么是个性化的电影推荐服务?举一个简单的列子,不同性别的人偏爱的电影有所不同,如大部分的男生可能比较喜欢看警匪类型或者动作型的电影,而大部分的女生.喜欢看浪漫的爱情篇。那么网站就可以根据性别特点为用户推荐用户更加喜欢的电影。如某会员是女性,那么当该会员登录时,网站可以为她推荐最新上映的浪漫爱情片。相对于常规的针对整体对象的推荐方式,比如好评排行榜、热门电影等,这类个性化的推荐的方式更加适合用户的真实需求,,从而提高用户的体验及其与用户的粘性。当然,在实际业务服务中进行正真的个性化推荐时,不仅是依靠用户的性别信息,而是需要使用大量与用户相关的真实数据来建立推荐模型。
因为用户在访问网站的电影时产生了大量的历史浏览数据,从用户浏览过的电影类型记录来预测该用户的性别,这里可以作为一个解决思路来进行尝试,大致步骤如下:
(1)对用户看过的说有电影类型进行统计,再通过已知性别用户观看电影的类型数据建立一个分类器。
(2)向分类器输入未知用户性别用户观看电影的类型统计数据,获得该用户的性别分类。
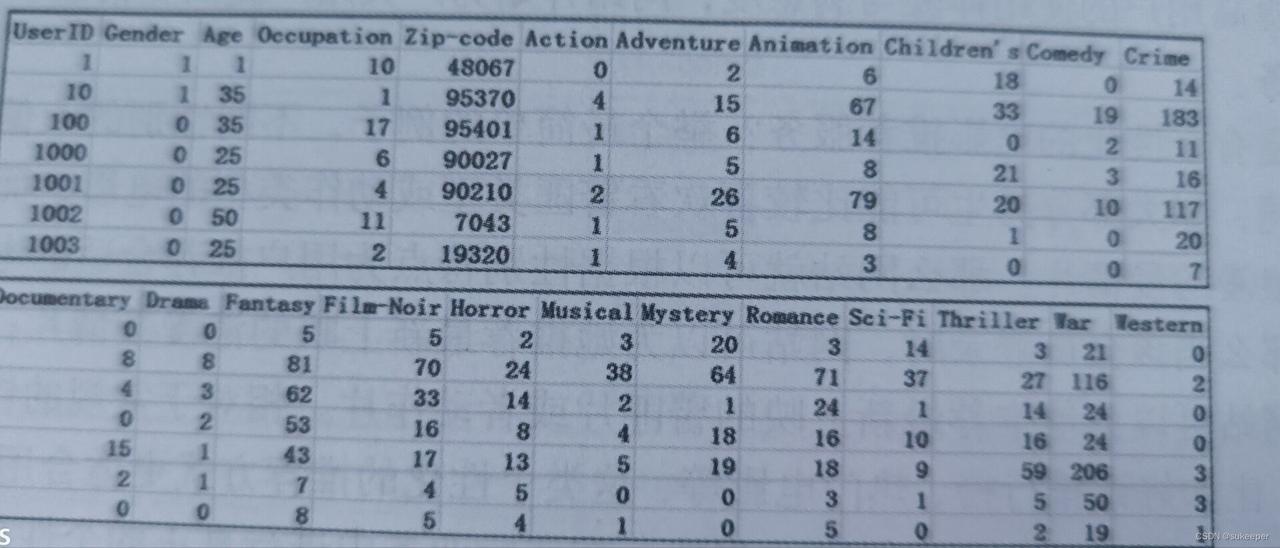
如下图所示,数据是根据每个用户的性别信息及该用户看过的电影类型的统计情况。其中,UserID代表的是用户ID;Gender代表的是用户性别,其中1代表的是女性,0代表的是男性;Age代表的是用户的年龄;Occupation代 代表的是用户的职业;Zip-code代表的是用户的地区编码;从Action到Western代表的是电影的不同类型。列如,某条记录中Action的字段值是4,则说明该用户看过4部动作电影。
这里使用MapReducer编程,利用KNN算法对已知性别的用户观看的电影类型统计和建立分类器,并且对这个分类器的分类结果进行评估,选出分类性能最好的一个分类器,用于对未知性别的用户进行分类。
认识KNN算法
KNN算法简介
KNN算法又称为K邻近分类算法,它是一个理论上比较成熟的算法,也是分类算法中最简单的算法之一。所谓K邻近,就是K个最近的邻居的意思,即每个样本都可以用它最接近的K个邻居来代表。该方法的思路:如果特征空间中的K个最相似的样本中的大多数属于一个类别,某样本也属于这个类别。在KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或多个样本的类别来决定待分类的所属类别。
更详细的讲解这里给大家推荐一篇写得比较好文章:KNN算法原理_一骑走烟尘的博客-CSDN博客_knn算法原理
本过程使用到三份数据,分别为用户对电影的评分数据ratings.dat、已知用户性别的用户数据users.dat、电影信息数据movies.dat。
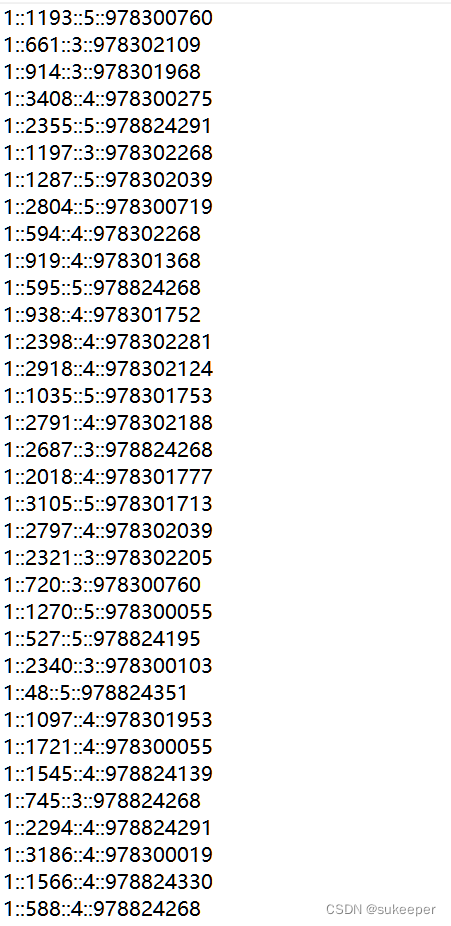
用户对电影的部分评分数据ratings.dat如下图所示。该数据包含四个字段,即UserID(用户ID)、MovieID(电影ID)、Rating(评分)及Timestamp(时间戳)。其中,UserID的范围是1~6040,MovieID的范围是1~3925,Rating采用的是五分好评制,即最高分为5分,最低分为1分。
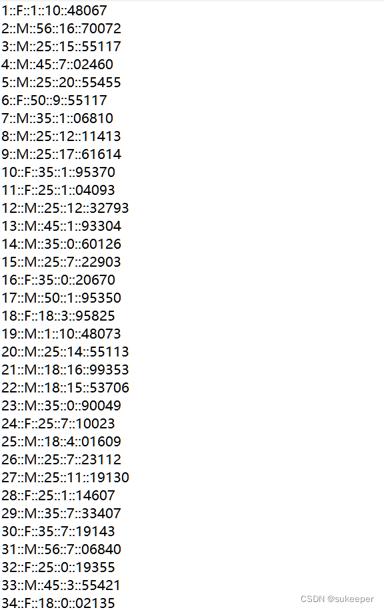
已知性别的用户信息部分数据users.dat如下图所示。该数据包括5个字段,分别为UserID(用户ID)、Gender(用户性别)、Age(年龄)、Occupation(职业)以及Zippy-code(地区编码) 。其中,Occupation字段代表21种不同的职业类型,Age记录的并不是用户的真实年龄,而是一个年龄段,例如,1代表的是18岁一下。
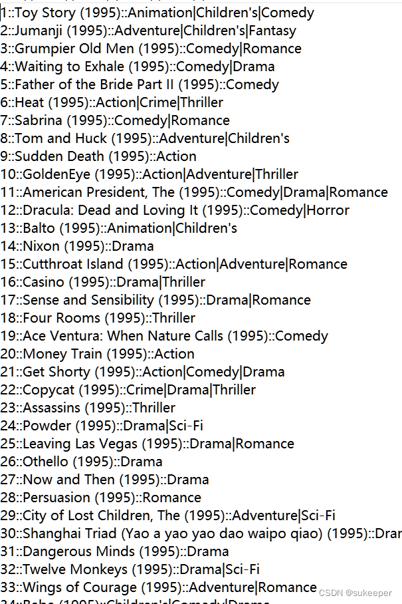
部分电影数据movies.dat数据如下图所示,该字段包括MovieID(电影ID),Title(电影名称)。Genres(电影类型)三个字段。其中,Title字段不仅记录电影名称,还记录了电影上映的时间。数据中总共记录了18种电影类型,包括喜剧片、动作片、警匪片、爱情片等。
step2:数据变换
我们的目的是根据电影类型来预测用户的性别,换句话说,预测用户的性别需要知道用户看过的那些类型的电影最多,所以对用户看过的电影数据类型进行统计,但是我们没有直接的数据,需要从三份数据里面提取的需要的信息。如下图:
数据转换是将数据从一种表现形式变为另一种表现形式的过程。数据转换主要是找到数据的特征表示。将网站用户的用户信息数据及其观影记录数据进行转换,得到用户观看电影的类型统计数据,思路如下:
(1)
根据UserID字段连接ratings.dat数据和users.dat数据,连接得到一份包含UserID(用户ID)、Gender(用户性别)、Age(用户年龄)、Occupation(用户职业)、Zip-code(用户地区编码)、MovieID(电影ID)的数据。
代码实现
GlobalUtility (自定义类型)
import org.apache.hadoop.conf.Configuration;
public class GlobalUtility
{
private static Configuration conf = null;
private static String DFS = "fs.defaultFS";
private static String DFS_INPL = "fs.hdfs.impl";
public static Configuration getConf()
{
if (conf == null)
{
conf = new Configuration();
conf.set(DFS,"hdfs://master:8020");
conf.set(DFS_INPL,"org.apache.hadoop.hdfs.DistributedFileSystem");
}
return conf;
}
}
UserAndRatingMapper
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class UserAndRatingMapper extends Mapper {
private FileSystem fs = null;
Map userInfoMap = null;
private String splitter =null;
private FSDataInputStream is = null;
private BufferedReader reader =null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
fs = FileSystem.get(context.getConfiguration());
URI[] uris = context.getCacheFiles();
splitter = conf.get("SPLITTER");
userInfoMap = new HashMap<>();
for (URI path:uris)
{
if (path.getPath().endsWith("users.dat"))
{
is = fs.open(new Path(path));
reader = new BufferedReader(new InputStreamReader(is,"utf-8"));
String line = null;
while ((line = reader.readLine())!= null)
{
String[] strs = line.split(splitter);
userInfoMap.put(strs[0],line);
}
}
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] strs = line.split(splitter);
Text key_out = new Text(userInfoMap.get(strs[0])+"::"+strs[1]);
context.write(key_out,NullWritable.get());
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
reader.close();
is.close();
}
}
UserAndRatingReducer
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.mockito.internal.matchers.Null;
import java.io.IOException;
public class UserAndRatingReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
UserAndRatingDriver
import MovieUserPredict.preTreat.mapper.UserAndRatingMapper;
import MovieUserPredict.preTreat.reducer.UserAndRatingReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import java.io.File;
import java.net.URI;
public class UserAndRatingDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.set("SPLITTER",args[4]);
Job job = Job.getInstance(conf,"user and rating link mission");
job.addCacheFile(new URI(args[2]));
job.setJarByClass(UserAndRatingDriver.class);
job.setMapperClass(UserAndRatingMapper.class);
job.setReducerClass(UserAndRatingReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
Path inputPath = new Path(args[1]);
FileInputFormat.addInputPath(job,inputPath);
Path outputPath = new Path(args[3]);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputPath))
{
fs.delete(outputPath,true);
}
FileOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:2;
}
}
MainEntrence(统一方法入口)
import MovieUserPredict.preTreat.drivers.UserAndRatingDriver;
import MovieUserPredict.preTreat.drivers.User_Rating_movies_Driver;
import org.apache.hadoop.util.ToolRunner;
import sccc.utilities.GlobUtility;
public class MainEntrence {
public static void main(String[] args) throws Exception {
if (args.length < 5)
{
System.err.println("Patameters are not correct.");
System.exit(1);
}
if (args[0].equals("PreTreat_one"))
{
ToolRunner.run(GlobUtility.getConf(),new UserAndRatingDriver(),args);
}else if (args[0].equals("PreTreat_two"))
{
ToolRunner.run(GlobUtility.getConf(),new User_Rating_movies_Driver(),args);
}
}
}
实现效果:
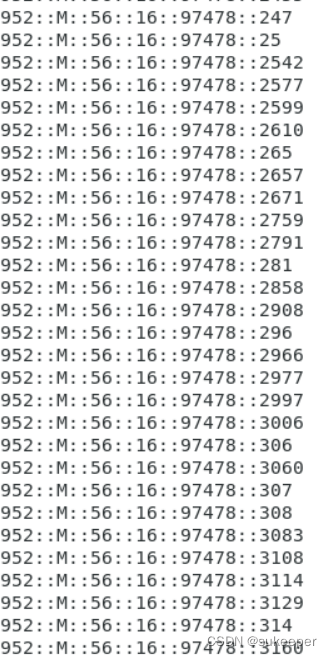
(2)
根据moviesID连接movies.dat数据和上一步跑出来的数据,连接结果是一份包含UserID(用户ID),Gender(性别),Age(年龄),Occupation(职业),Zip-code(地区邮编),MovieID(电影ID).Genres(电影类型)的数据。
代码实现
User_Rating_movies_Mapper
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class User_Rating_movies_Mapper extends Mapper
{
private String splitter = null;
private FileSystem fs = null;
private FSDataInputStream is = null;
private Map movieInfoMap = new HashMap<>();
@Override
protected void setup(Context context) throws IOException, InterruptedException
{
Configuration conf = context.getConfiguration();
fs = FileSystem.get(conf);
splitter = conf.get("SPLITTER");
URI[] uris = context.getCacheFiles();
for (URI uri :uris)
{
if (uri.getPath().endsWith("movies.dat"))
{
is = fs.open(new Path(uri));
BufferedReader reader = new BufferedReader(new InputStreamReader(is,"utf-8"));
String line = null;
while ((line = reader.readLine())!=null)
{
String[] strs = line.split(splitter);
movieInfoMap.put(strs[0],strs[2]);
}
}
}
}
@Override
protected void map(Text key, NullWritable value, Context context) throws IOException, InterruptedException
{
String line = key.toString();
String[] strs = line.split(splitter);
String movieId = strs[strs.length-1];
Text value_out = new Text(line+splitter+movieInfoMap.get(movieId));
context.write(NullWritable.get(),value_out);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException
{
is.close();
}
} User_Rating_movies_Reducer
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class User_Rating_movies_Reducer extends Reducer {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
}
@Override
protected void reduce(NullWritable key, Iterable values, Context context) throws IOException, InterruptedException {
for (Text text:values)
{
context.write(key,text);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
}
}
User_Rating_movies_Driver
import MovieUserPredict.preTreat.mapper.User_Rating_movies_Mapper;
import MovieUserPredict.preTreat.reducer.User_Rating_movies_Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import java.net.URI;
public class User_Rating_movies_Driver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.set("SPLITTER",args[4]);
Job job = Job.getInstance(conf,"User Ratings movies link mission");
job.addCacheFile(new URI(args[2]));
job.setJarByClass(User_Rating_movies_Driver.class);
job.setMapperClass(User_Rating_movies_Mapper.class);
job.setReducerClass(User_Rating_movies_Reducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
Path inputPath = new Path(args[1]);
FileInputFormat.addInputPath(job,inputPath);
Path outputPath = new Path(args[3]);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputPath))
{
fs.delete(outputPath,true);
}
FileOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:2;
}
}
MainEntrence
import MovieUserPredict.preTreat.drivers.UserAndRatingDriver;
import MovieUserPredict.preTreat.drivers.User_Rating_movies_Driver;
import org.apache.hadoop.util.ToolRunner;
import sccc.utilities.GlobUtility;
public class MainEntrence {
public static void main(String[] args) throws Exception {
if (args.length < 5)
{
System.err.println("Patameters are not correct.");
System.exit(1);
}
if (args[0].equals("PreTreat_one"))
{
ToolRunner.run(GlobUtility.getConf(),new UserAndRatingDriver(),args);
}else if (args[0].equals("PreTreat_two"))
{
ToolRunner.run(GlobUtility.getConf(),new User_Rating_movies_Driver(),args);
}
}
}
实现效果:
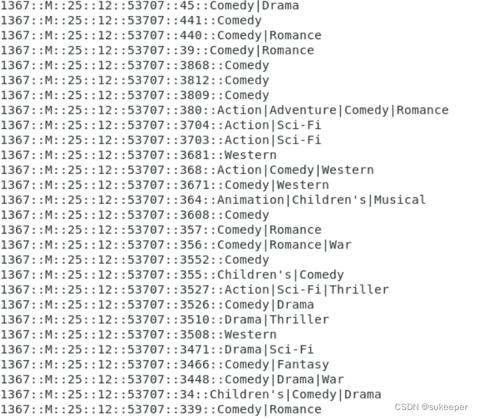
(3)
下面包括两个部分(Map、Reduce):
一、将基本信息里的数据M(男性)转换为数字0,F(女 性)转换为数字1
对每个用户看过的电影类型进行统计,得到一个特征向量矩阵,可以通过MapReduce编程实现。在Map阶段,对Gender(性别)做进一步转换,如果是女性(F)则用1标记,如果是男性(M)则用0标记,Map输入的键是UserID,Gender,Age,Occupation,Zip-code,输出的值是Genres(电影类型)。Map实现流程如图所示: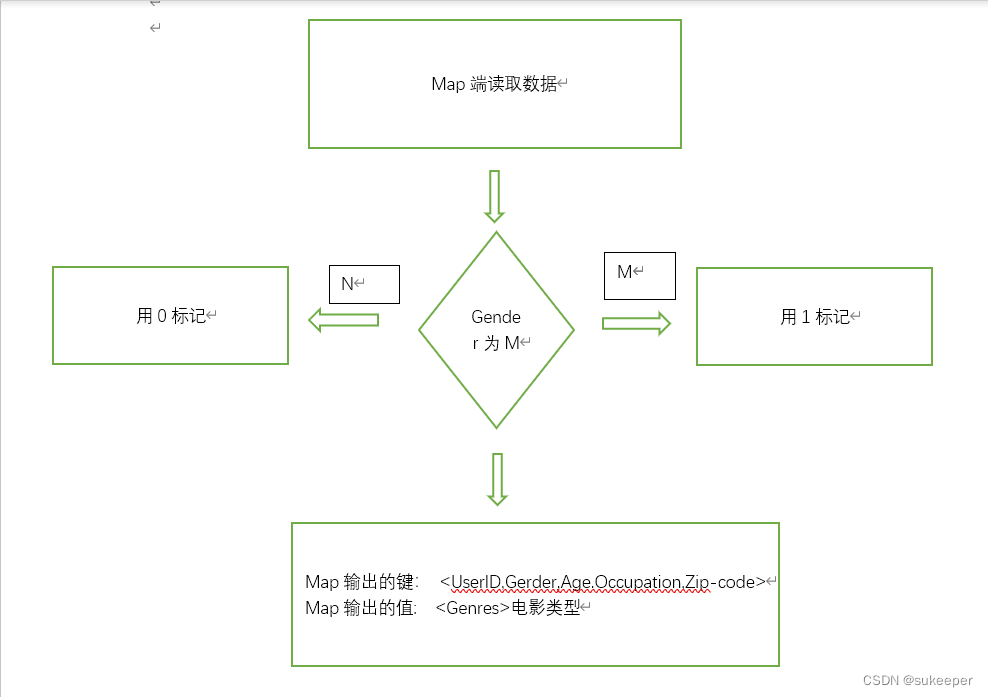
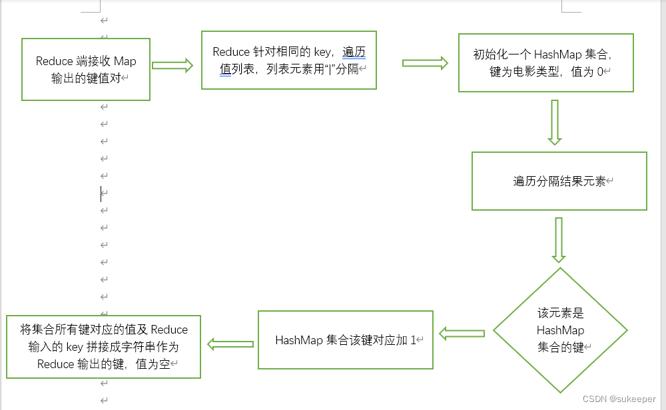
二、对每个用户看过的电影类型进行统计
在Reduce阶段,reduce函数先将每个用户初始化一个HashMap集合,集合中有18个键值对,键分别为1
18种电影类型,每个键对应的值为0。在Map输出的键值对中,相同的值被整合到一个列表中。reduce函数针对相同的键遍历其值列表,对列表中的每个元素根据分割符“|”进行分隔,遍历结果,如果HashMap所有集合中的键包括分隔结果中的元素,则该键对应值加1.最后将Hash Map所有键值对的值及Reduce输入的键用逗号分隔合并成一个字符串作为Reduce输出键,值为空。具体实现思路如下:
代码实现
MoviesGenresMapper
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MoviesGenresMapper extends Mapper {
private String splitter = null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
splitter = conf.get("SPLITTER_MAP");
}
@Override
protected void map(NullWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] strs = line.split(splitter);
StringBuffer userinfo = new StringBuffer();
for (int i = 0; i < 5; i++)
{
if (i == 1)
{
if (strs[i].equals("F"))
{
userinfo.append(1 + ",");
}
else {
userinfo.append(0 + ",");
}
}
else
{
userinfo.append(strs[i]+",");
}
}
Text key_out = new Text(userinfo.toString());
Text value_out = new Text(strs[strs.length - 1]);
context.write(key_out, value_out);
}
} MoviesGenresReducer
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class MoviesGenresReducer extends Reducer {
private String splitter = null;
private Map genersCountMap = new HashMap<>();
private String[] genersName = new String[]{
"Action","Comedy","Romance","Sci-Fi",
"Adventure","Musical","Crime",
"Children's","Thriller","War",
"Drama","Mystery","Horror","Documentary","Film-Noir","Fantasy","Western","Animation"
};
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
splitter = conf.get("SPLITTER_REDUCE");
}
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
for (int i = 0; i < genersName.length;i++)
{
genersCountMap.put(genersName[i],0);
}
for (Text geners:values)
{
String[] strs = geners.toString().split(splitter);
for (int i = 0; i1);
}
}
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(key.toString());
for (int i =0 ;i< genersName.length;i++)
{
if (i < genersName.length-1)
{
stringBuffer.append(genersCountMap.get(genersName[i])+",");
}else
{
stringBuffer.append(genersCountMap.get(genersName[i]));
}
}
Text key_out = new Text(stringBuffer.toString());
context.write(key_out,NullWritable.get());
}}
MoviesGenresDriver
import MovieUserPredict.preTreat.mapper.MoviesGenresMapper;
import MovieUserPredict.preTreat.reducer.MoviesGenresReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
public class MoviesGenresDriver extends Configured implements Tool
{
@Override
public int run(String[] args) throws Exception
{
Configuration conf = getConf();
conf.set("SPLITTER_MAP",args[3]);
conf.set("SPLITTER_REDUCE",args[4]);
Job job = Job.getInstance(conf,"User Ratings movies link mission");
job.setJarByClass(MoviesGenresDriver.class);
job.setMapperClass(MoviesGenresMapper.class);
job.setReducerClass(MoviesGenresReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
Path inputPath = new Path(args[1]);
FileInputFormat.addInputPath(job,inputPath);
Path outputPath = new Path(args[2]);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputPath))
{
fs.delete(outputPath,true);
}
FileOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:2;
}
}
MainEntrence
import MovieUserPredict.preTreat.drivers.MoviesGenresDriver;
import MovieUserPredict.preTreat.drivers.UserAndRatingDriver;
import MovieUserPredict.preTreat.drivers.User_Rating_movies_Driver;
import org.apache.hadoop.util.ToolRunner;
import sccc.utilities.GlobUtility;
public class MainEntrence {
public static void main(String[] args) throws Exception {
if (args.length < 5)
{
System.err.println("Patameters are not correct.");
System.exit(1);
}
if (args[0].equals("PreTreat_one"))
{
ToolRunner.run(GlobUtility.getConf(),new UserAndRatingDriver(),args);
}else if (args[0].equals("PreTreat_two"))
{
ToolRunner.run(GlobUtility.getConf(),new User_Rating_movies_Driver(),args);
}else if (args[0].equals("PreTreat_three"))
{
ToolRunner.run(GlobUtility.getConf(),new MoviesGenresDriver(),args);
}
}
}
实现效果:

step3:数据清洗
数据清洗是数据预处理里面的一个重要步骤,上面我们处理过的数据里面可能含有噪声数据,例如缺失值或者异常值,这类数据会影响分类器的建立,因此需要对这些数据进行处理。一般情况下,数据中的缺失值可以表示成空、“NULL”、“null”、“NAN”。而异常值则需要根据实际情况判断,比如前面统计过电影类型数量的统计,我们知道所统计的电影数据类型数据是大于或等于零的,一旦这结果出现负数就肯定是异常值 。
处理缺失值的方法有两种:
删除记录和数据插补
异常值的处理方法:
(1)删除含有的异常值
(2)视为缺失值
(3)平均值修正
常用的插补方法
均值/中位数/众数 根据数据类型来选择 使用固定值 将缺失值用一个常量替换 最近邻插补 在记录中找到缺失样本最接近的样本来插补该数据 回归方 建立自变量、因变量、常量之间的关系来找应该插入的值 插值法 采用数学函数方法
将缺失值和异常值替换成零可以用MapReduce编程实现。思路:我们可以在Mapper里面添加自定义计数器来实现异常值和缺失值的统计。在Map函数中读取数据时,判断读取进来的数据是否含有异常值和缺失值,若有则用零替换,同时计数器加一,这样我们既可以处理异常数据也可以看到数据里面到底有多少异常值和缺失值。
具体代码实现如下:
DataCleanDriver
import MovieUserPredict.preTreat.mapper.DataCleanMapper;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
public class DataCleanDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.set("SPLITTER",args[3]);
Job job = Job.getInstance(conf,"Data clearn mission");
job.setJarByClass(DataCleanDriver.class);
job.setMapperClass(DataCleanMapper.class);
job.setNumReduceTasks(0);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
Path inputPath = new Path(args[1]);
FileInputFormat.addInputPath(job,inputPath);
Path outputPath = new Path(args[2]);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputPath))
{
fs.delete(outputPath,true);
}
FileOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:2;
}
}
DataCleanMapper
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class DataCleanMapper extends Mapper {
private String splitter = null;
enum DataCleanCount{
NULLDATA,
ABNORMALDATA
}
@Override
protected void setup(Context context) throws IOException, InterruptedException {
splitter = context.getConfiguration().get("SPLITTER");
}
@Override
protected void map(Text key, NullWritable value, Context context) throws IOException, InterruptedException {
StringBuffer stringBuffer = new StringBuffer();
String line = key.toString();
String[] strs = line.split(splitter);
for (int i = 0; i < strs.length;i++)
{
if (strs[i].equals("") || strs[i].equals("null") || strs[i].equals("NAN"))
{
context.getCounter(DataCleanCount.NULLDATA).increment(1l);
strs[i] = "0";
}
if (i != 4 && Integer.parseInt(strs[i])<0)
{
context.getCounter(DataCleanCount.ABNORMALDATA).increment(1l);
strs[i] = "0";
}
if (i == strs.length-1)
{
stringBuffer.append(strs[i]);
}
else
{
stringBuffer.append(strs[i]+",");
}
}
context.write(new Text(stringBuffer.toString()),NullWritable.get());
}
}
MainEntrence
import MovieUserPredict.preTreat.drivers.DataCleanDriver;
import MovieUserPredict.preTreat.drivers.MoviesGenresDriver;
import MovieUserPredict.preTreat.drivers.UserAndRatingDriver;
import MovieUserPredict.preTreat.drivers.User_Rating_movies_Driver;
import org.apache.hadoop.util.ToolRunner;
import sccc.utilities.GlobUtility;
public class MainEntrence {
public static void main(String[] args) throws Exception {
if (args.length < 4)
{
System.err.println("Patameters are not correct.");
System.exit(1);
}
if (args[0].equals("PreTreat_one"))
{
ToolRunner.run(GlobUtility.getConf(),new UserAndRatingDriver(),args);
}else if (args[0].equals("PreTreat_two"))
{
ToolRunner.run(GlobUtility.getConf(),new User_Rating_movies_Driver(),args);
}else if (args[0].equals("PreTreat_three"))
{
ToolRunner.run(GlobUtility.getConf(),new MoviesGenresDriver(),args);
}
else if (args[0].equals("PreTreat_clear"))
{
ToolRunner.run(GlobUtility.getConf(),new DataCleanDriver(),args);
}
}
}
代码实现效果:

step4:数据划分
一般来说,分类算法有三个步骤:
一:训练集
通过归纳分析训练样本集来建立分类器
二:验证集
用验证数据集来选择最优的模型参数
三:测试集
用已知类别的测试样本集评估分类器的准确性
在建立电影用户分类器之前,先要将预处理好的数据分化成训练数据集、验证数据集、测试数据集。一般采用8:1:1的比例随机划分数据集,其中训练数据集占80%,测试数据集与验证数据集个占10%。要注意的是数据集的数据划分的唯一性的,也就是说一份数据集只会进入一个集里面进行处理。
具体编程代码如下:
import MovieUserGenderPrdict.preTreat.utities.GlobalUtility;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.*;
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
public class SplitDataSet
{
private static Configuration conf = GlobalUtility.getConf();
private static int getsize(SequenceFile.Reader reader, Path path) throws IOException
{
int count = 0;
Text key = new Text();
NullWritable value = NullWritable.get();
while (reader.next(key,value))
{
count++;
}
reader.close();
return count;
}
private static Set trainIndex(int datasize)
{
Set train_index = new HashSet();
int trainSplitNum = (int)(datasize*0.8);
Random random = new Random();
while (train_index.size()return train_index;
}
private static Set validateIndex(int datasize, Set train_index)
{
Set validate_index = new HashSet();
int validateSplitNum = datasize - (int)(datasize*0.9);
Random random = new Random();
while (validate_index.size()int a = random.nextInt(datasize);
while (a > datasize)
{
a = random.nextInt();
}
if (!train_index.contains(a))
{
validate_index.add(a);
}
}
return validate_index;
}
public static void main(String[] args) throws IOException {
conf.set("fs.defaultFS","master:8020");
FileSystem fs = FileSystem.get(conf);
Path moviedata = new Path("/demoData2132/clean_out/part-m-00000");
SequenceFile.Reader reader = new SequenceFile.Reader(fs,moviedata,conf);
int datasize = getsize(reader,moviedata);
Set train_index = trainIndex(datasize);
System.out.println(train_index.size());
Set validate_index = validateIndex(datasize,train_index);
System.out.println(validate_index.size());
Path train = new Path("hdfs://master:8020/demo/movies/trainData.seq");
if (fs.exists(train))
{
fs.delete(train,true);
}
SequenceFile.Writer os1 = SequenceFile.createWriter(fs,conf,train,Text.class,NullWritable.class);
Path test = new Path("hdfs://master:8020/demo/movies/testData.seq");
if (fs.exists(test))
{
fs.delete(test,true);
}
SequenceFile.Writer os2 = SequenceFile.createWriter(fs,conf,test,Text.class,NullWritable.class);
Path validate = new Path("hdfs://master:8020/demo/movies/validateData.seq");
if (fs.exists(validate))
{
fs.delete(validate,true);
}
SequenceFile.Writer os3 = SequenceFile.createWriter(fs,conf,validate,Text.class,NullWritable.class);
String line = "";
int sum = 0;
int trainsize = 0;
int testsize = 0;
int validatesize = 0;
Text key = new Text();
NullWritable value = NullWritable.get();
// reader.seek(0);
reader = new SequenceFile.Reader(fs,moviedata,conf);
while (reader.next(key,value))
{
sum++;
if (train_index.contains(sum))
{
trainsize ++;
os1.append(key,value);
}
else if (validate_index.contains(sum))
{
validatesize ++;
os2.append(key,value);
}
else
{
testsize ++;
os3.append(key,value);
}
}
os1.close();
os2.close();
os3.close();
reader.close();
fs.close();
System.out.println(train_index.size());
System.out.println(datasize);
System.out.println(validate_index.size());
}
}
注意:数据的读取路径与存储路径要根据自己的存储路径来
实现效果如下:

hdfs://master:8020/demo/movies/trainData.seq
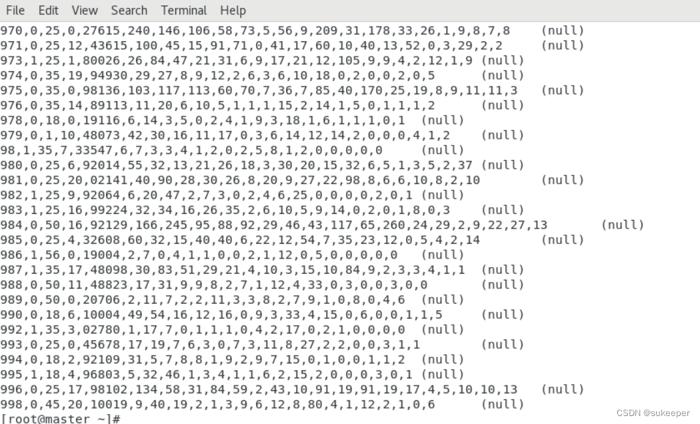
hdfs://master:8020/demo/movies/testData.seq

hdfs://master:8020/demo/movies/validataData.seq
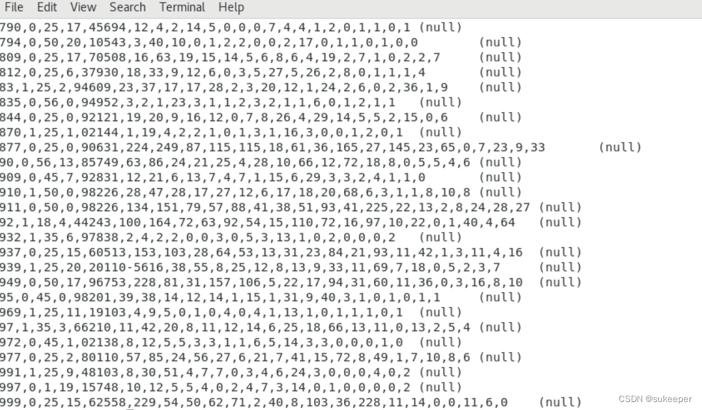
注意:这里显示的数据都是部分数据
step5:用户性别分类
实现思路:
(1)
自定义值类型表示距离和类型。由于KNN算法是计算的测试数据与已知数类别的训练数据之间的距离,找到距离测试数据最近的K个训练数据,再根据数据所属类型的众数来判断测试数据的类别。所以Map阶段需要将测试数据与训练数据的距离及其该训练集的类别作为值输出,程序可以使用Hadoop内置的数据类型Text作为值类型输出距离即类别。但是为了提高程序的执行效率,建议自定义类型表示距离和类别,我在这里就是使用的自定义的方法。
(2)
Map阶段,setup函数读取测试数据。在map函数黎曼读取每一条训练数据,遍历测试数据,计算读取进来的训练记录及其每条测试数据的距离,计算距离采用的是欧几里得的计算方法,map输出的键是每条测试数据,输出的值是该测试数据与读取的训练数据的距离和训练数据的类别。
(3)
Reduce阶段,setup函数初始化参数K值,reduce函数对相同键的值根据距离进行排序,去除前K个值,输出reduce函数取进来的键和这个K个值中的类别的众数。
实现代码:
KnnMapper
import MovieUserPredict.Knn.entities.DistanceAndLabel;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.net.URI;
import java.util.*;
public class KnnMapper extends Mapper
{
private String splitter = null;
private FileSystem fs = null;
private SequenceFile.Reader reader = null;
private Mapint[]> testData = new HashMap<>();
@Override
protected void setup(Context context) throws IOException, InterruptedException
{
Configuration conf = context.getConfiguration();
fs = FileSystem.get(conf);
splitter = conf.get("SPLITTER");
URI[] uris = context.getCacheFiles();
for (URI uri:uris)
{
if (uri.getPath().endsWith("testData.seq"))
{
reader = new SequenceFile.Reader(fs,new Path(uri),conf);
Text key = new Text();
NullWritable value = NullWritable.get();
while (reader.next(key,value))
{
String line = key.toString();
String[] strs = line.split(splitter);
int[] vector = new int[20];
int j = 0;
StringBuffer stringBuffer = new StringBuffer();
for (int i=0;iif (i > 1 && i != 4)
{
vector[j] = Integer.parseInt(strs[i]);
j++;
}
if (i < 4)
{
stringBuffer.append(strs[i]+splitter);
}
else if (i == 4)
{
stringBuffer.append(strs[i]);
}
}
testData.put(stringBuffer.toString(),vector);
}
}
}
}
@Override
protected void map(Text key, NullWritable value, Context context) throws IOException, InterruptedException
{
String line = key.toString();
String[] strs = line.split(splitter);
int label =Integer.parseInt(strs[1]);
int[] trainVector = new int[20];
int j = 0;
for (int i=2;iif (i!=4)
{
trainVector[j] = Integer.parseInt(strs[i]);
j++;
}
}
Iterator iterator = testData.keySet().iterator();
while (iterator.hasNext())
{
String key_out = iterator.next();
float distance = Distance(testData.get(key_out),trainVector);
DistanceAndLabel value_out = new DistanceAndLabel(distance,label);
context.write(new Text(key_out),value_out);
}
}
private float Distance(int[] testVector, int[] trainVector)
{
float distance = 0.0f;
int sum = 0;
for (int i=0;i2);
}
distance = (float) Math.sqrt(sum);
return distance;
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException
{
if (reader != null)
{
reader.close();
}
}
} KnnReducer
import MovieUserPredict.Knn.entities.DistanceAndLabel;
import MovieUserPredict.utities.SortedSingleLinkedList;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class KnnReducer extends Reducer {
private int K_VALUE = 0;
private SortedSingleLinkedList sortedwork = new SortedSingleLinkedList();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
K_VALUE = context.getConfiguration().getInt("K_VALUE",3);
}
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
for (DistanceAndLabel item:values)
{
if (sortedwork.length() < K_VALUE)
{
sortedwork.add(item);
}else{
if (item.getDistance() < sortedwork.get(0).getDistance())
{
sortedwork.remove(0);
sortedwork.add(item);
}
}
}
int female = 0;
int male = 0;
for (int i =0; i< sortedwork.length();i++)
{
if (sortedwork.get(i).getLabel() == 1)
{
female++;
}
else {
male++;
}
}
if (female >= male)
{
context.write(new IntWritable(1),key);
}
else {
context.write(new IntWritable(0),key);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
//FileSystem fs = FileSystem.get(context.getConfiguration());
// fs.close();
}
}
KnnDriver
import MovieUserPredict.Knn.KnnMapper.KnnMapper;
import MovieUserPredict.Knn.KnnReducer.KnnReducer;
import MovieUserPredict.Knn.entities.DistanceAndLabel;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import java.net.URI;
public class KnnDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.setInt("K_VALUE",Integer.parseInt(args[4]));
conf.set("SPLITTER",args[5]);
Job job = Job.getInstance(conf,"Knn Mission");
job.addCacheFile(new URI(args[2]));
job.setJarByClass(KnnDriver.class);
job.setMapperClass(KnnMapper.class);
job.setReducerClass(KnnReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DistanceAndLabel.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
Path inputPath = new Path(args[1]);
FileInputFormat.addInputPath(job,inputPath);
Path outputPath = new Path(args[3]);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputPath))
{
fs.delete(outputPath,true);
}
FileOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:2;
}
}
Maintrence
import MovieUserPredict.Knn.KnnDriver.EvaluateDriver;
import MovieUserPredict.Knn.KnnDriver.KnnDriver;
import MovieUserPredict.preTreat.drivers.DataCleanDriver;
import MovieUserPredict.preTreat.drivers.MoviesGenresDriver;
import MovieUserPredict.preTreat.drivers.UserAndRatingDriver;
import MovieUserPredict.preTreat.drivers.User_Rating_movies_Driver;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.MRBench;
import org.apache.hadoop.util.ToolRunner;
import sccc.utilities.GlobUtility;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class MainEntrence {
public static void main(String[] args) throws Exception {
if (args.length < 4)
{
System.err.println("Patameters are not correct.");
System.exit(1);
}
if (args[0].equals("PreTreat_one"))
{
ToolRunner.run(GlobUtility.getConf(),new UserAndRatingDriver(),args);
}else if (args[0].equals("PreTreat_two"))
{
ToolRunner.run(GlobUtility.getConf(),new User_Rating_movies_Driver(),args);
}else if (args[0].equals("PreTreat_three"))
{
ToolRunner.run(GlobUtility.getConf(),new MoviesGenresDriver(),args);
}
else if (args[0].equals("PreTreat_clear"))
{
ToolRunner.run(GlobUtility.getConf(),new DataCleanDriver(),args);
}
else if (args[0].equals("bestk_maxAccuray"))
{
float maxAccuracy = 0.0f;
int bestk = 0;
FSDataInputStream is = null;
BufferedReader reader = null;
FileSystem fs = FileSystem.get(GlobUtility.getConf());
Path evaluate_res = new Path("hdfs://master:8020/demo/evaluation_out/part-r-00000");
Map accray_res_map = new HashMap<>();
for (int k = 3; k <=21 ; k+= 2)
{
String[] args_knn = new String[]
{
args[0], args[1], args[2], args[3], k+"",args[5]
};
ToolRunner.run(GlobUtility.getConf(),new KnnDriver(),args_knn);
String[] args_evaluation = new String[]
{
args[0], args[3], args[6], args[5]
};
ToolRunner.run(GlobUtility.getConf(),new EvaluateDriver(),args_evaluation);
while (k <= 21 && !fs.exists(evaluate_res) )
{
Thread.sleep(3000);
}
is = fs.open(evaluate_res);
reader = new BufferedReader(new InputStreamReader(is,"utf-8"));
String accuray_str = null;
while ((accuray_str = reader.readLine()) != null)
{
float cacuracy = Float.parseFloat(accuray_str);
accray_res_map.put(k,cacuracy);
float accuray = Float.parseFloat(accuray_str);
if (accuray > maxAccuracy)
{
maxAccuracy = accuray;
bestk = k;
}
}
is.close();
reader.close();
}
Iterator iterator = accray_res_map.keySet().iterator();
while (iterator.hasNext())
{
Integer key = iterator.next();
System.out.println("K="+key+" Accuray"+accray_res_map.get(key));
}
System.out.println("Maxaccuary="+maxAccuracy);
System.out.println("Brestk="+bestk);
fs.close();
}
}
}
step5:效果评估
具体流程:
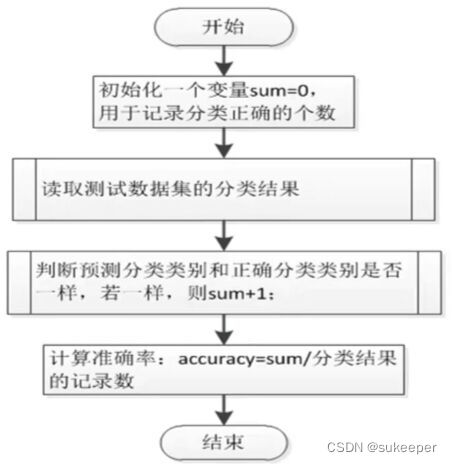
实现代码:
EvaluateMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class EvaluateMapper extends Mapper {
private String splitter = null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
splitter = context.getConfiguration().get("SPLITTER");
}
@Override
protected void map(IntWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(splitter);
String trueValue = strs[1];
String predictValue = key.get()+"";
context.write(NullWritable.get(),new Text(trueValue+ splitter+predictValue));
}
}
EvaluateReducer
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class EvaluateReducer extends Reducer {
private String splitter = null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
splitter = context.getConfiguration().get("SPLITTER");
}
@Override
protected void reduce(NullWritable key, Iterable values, Context context) throws IOException, InterruptedException {
int rightCount = 0;
int totalCount = 0;
for (Text v : values)
{
totalCount++;
String trueValue = v.toString().split(splitter)[0];
String predictValue = v.toString().split(splitter)[1];
if (trueValue.equals(predictValue))
{
rightCount++;
}
}
float accuracy = (float) rightCount/totalCount;
// String.format("%s.1",accuracy);
accuracy = Float.parseFloat(String.format("%.1f",accuracy));
context.write(new FloatWritable(accuracy),NullWritable.get());
}
}
EvaluateDriver
import MovieUserPredict.Knn.KnnMapper.EvaluateMapper;
import MovieUserPredict.Knn.KnnReducer.EvaluateReducer;
import MovieUserPredict.Knn.entities.DistanceAndLabel;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import java.net.URI;
public class EvaluateDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.set("SPLITTER",args[3]);
Job job = Job.getInstance(conf,"Knn Mission");
job.setJarByClass(EvaluateDriver.class);
job.setMapperClass(EvaluateMapper.class);
job.setReducerClass(EvaluateReducer.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(FloatWritable.class);
job.setOutputValueClass(NullWritable.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
Path inputPath = new Path(args[1]);
FileInputFormat.addInputPath(job,inputPath);
Path outputPath = new Path(args[2]);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputPath))
{
fs.delete(outputPath,true);
}
FileOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:2;
}
}
MainEntrence
import MovieUserPredict.Knn.KnnDriver.EvaluateDriver;
import MovieUserPredict.Knn.KnnDriver.KnnDriver;
import MovieUserPredict.preTreat.drivers.DataCleanDriver;
import MovieUserPredict.preTreat.drivers.MoviesGenresDriver;
import MovieUserPredict.preTreat.drivers.UserAndRatingDriver;
import MovieUserPredict.preTreat.drivers.User_Rating_movies_Driver;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.MRBench;
import org.apache.hadoop.util.ToolRunner;
import sccc.utilities.GlobUtility;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class MainEntrence {
public static void main(String[] args) throws Exception {
if (args.length < 4)
{
System.err.println("Patameters are not correct.");
System.exit(1);
}
if (args[0].equals("PreTreat_one"))
{
ToolRunner.run(GlobUtility.getConf(),new UserAndRatingDriver(),args);
}else if (args[0].equals("PreTreat_two"))
{
ToolRunner.run(GlobUtility.getConf(),new User_Rating_movies_Driver(),args);
}else if (args[0].equals("PreTreat_three"))
{
ToolRunner.run(GlobUtility.getConf(),new MoviesGenresDriver(),args);
}
else if (args[0].equals("PreTreat_clear"))
{
ToolRunner.run(GlobUtility.getConf(),new DataCleanDriver(),args);
}
else if (args[0].equals("bestk_maxAccuray"))
{
float maxAccuracy = 0.0f;
int bestk = 0;
FSDataInputStream is = null;
BufferedReader reader = null;
FileSystem fs = FileSystem.get(GlobUtility.getConf());
Path evaluate_res = new Path("hdfs://master:8020/demo/evaluation_out/part-r-00000");
Map accray_res_map = new HashMap<>();
for (int k = 3; k <=21 ; k+= 2)
{
String[] args_knn = new String[]
{
args[0], args[1], args[2], args[3], k+"",args[5]
};
ToolRunner.run(GlobUtility.getConf(),new KnnDriver(),args_knn);
String[] args_evaluation = new String[]
{
args[0], args[3], args[6], args[5]
};
ToolRunner.run(GlobUtility.getConf(),new EvaluateDriver(),args_evaluation);
while (k <= 21 && !fs.exists(evaluate_res) )
{
Thread.sleep(3000);
}
is = fs.open(evaluate_res);
reader = new BufferedReader(new InputStreamReader(is,"utf-8"));
String accuray_str = null;
while ((accuray_str = reader.readLine()) != null)
{
float cacuracy = Float.parseFloat(accuray_str);
accray_res_map.put(k,cacuracy);
float accuray = Float.parseFloat(accuray_str);
if (accuray > maxAccuracy)
{
maxAccuracy = accuray;
bestk = k;
}
}
is.close();
reader.close();
}
Iterator iterator = accray_res_map.keySet().iterator();
while (iterator.hasNext())
{
Integer key = iterator.next();
System.out.println("K="+key+" Accuray"+accray_res_map.get(key));
}
System.out.println("Maxaccuary="+maxAccuracy);
System.out.println("Brestk="+bestk);
fs.close();
}
}
}
计算结果为:
0.7
想必大家也明白这里的0.7是意思。
这个项目到这里就结束了,这算是我做的第一个项目,当然这不可能是我一个人完成的,是在老师的指导下完成的。其实中途也遇到了好多的报错和问题,有的问题是请教老师,其实更多的是和同学朋友一起解决的,可见团队的重要性。当然,这个项目里面还有很多不足的地方,希望大家踊跃的提出,一起来讨论,毕竟同一个的题实现的编程方式有很多。
我是sukeeper,关注我,大家一起学编程
。
评论记录:
回复评论: