
一、目的与要求
1、通过实验掌握Spark Streaming的基本编程方法;
2、熟悉利用Spark Streaming处理来自不同数据源的数据。
3、熟悉DStream的各种转换操作。
4、熟悉把DStream的数据输出保存到文本文件或MySQL数据库中。
1.参照教材示例,利用Spark Streaming对三种类型的基本数据源的数据进行处理。
2.参照教材示例,完成kafka集群的配置,利用Spark Streaming对Kafka高级数据源的数据进行处理,注意topic为你的姓名全拼。
3.参照教材示例,完成DStream的两种有状态转换操作。
4.参照教材示例,完成把DStream的数据输出保存到文本文件或MySQL数据库中。
三、实验步骤(实验过程)
1. 文件流:
>>> from pyspark import SparkContext
>>> from pyspark.streaming import StreamingContext
>>> ssc=StreamingContext(sc,10)
>>> lines=ssc.\
... textFileStream('file:///usr/local/spark/mycode/streaming/logfile')
>>> words=lines.flatMap(lambda line:line.split())
>>> wordCounts=words.map(lambda x:(x,1)).reduceByKey(lambda a,b:a+b)
>>> wordCounts.pprint()
>>> ssc.start()
套接字流:
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: NetworkWordCount.py
exit(-1)
sc = SparkContext(appName="PythonStreamingNetworkWordCount")
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
RDD队列流:
import time
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
sc = SparkContext(appName="PythonStreamingQueueStream")
ssc = StreamingContext(sc, 2)
#创建一个队列,通过该队列可以把RDD推给一个RDD队列流
rddQueue = []
for i in range(5):
rddQueue += [ssc.sparkContext.parallelize([j for j in range(1, 1001)], 10)]
time.sleep(1)
#创建一个RDD队列流
inputStream = ssc.queueStream(rddQueue)
mappedStream = inputStream.map(lambda x: (x % 10, 1))
reducedStream = mappedStream.reduceByKey(lambda a, b: a + b)
reducedStream.pprint()
ssc.start()
ssc.stop(stopSparkContext=True, stopGraceFully=True)
2. from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
if __name__=="__main__":
if len(sys.argv)!= 3:
print("Usage:KafkaWordCount.py
exit(-1)
sc=SparkContext(appName="PythonStreamingKafkaWordCount")
ssc=StreamingContext(sc,1)
zkQuorum,topic=sys.argv[1:]
kvs=KafkaUtils.createStream(ssc,zkQuorum,"spark-streaming-consumer",{topic:1})
lines=kvs.map(lambda x:x[1])
counts=lines.flatMap(lambda line:line.split(" ")).map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
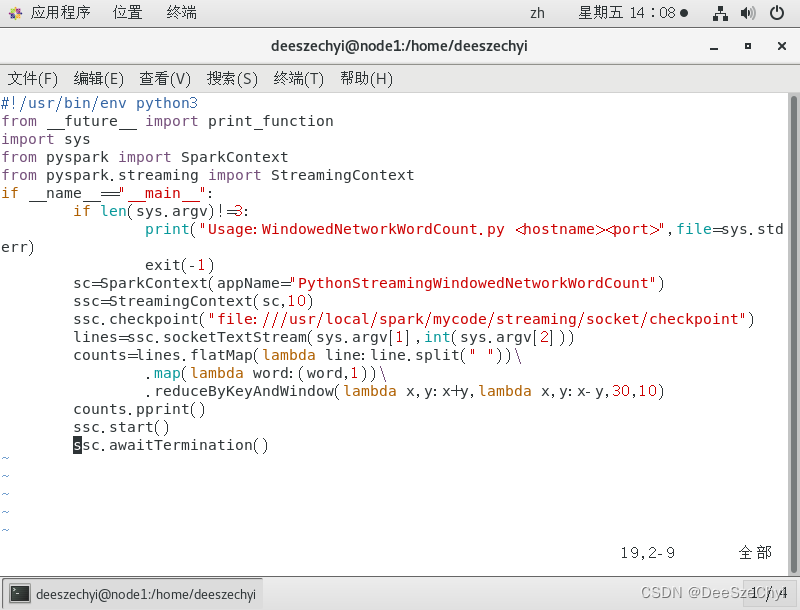
3.无状态转换:第一问套接字流词频统计程序NetworkWordCount程序
有状态转换:#!/usr/bin/env python3
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__=="__main__":
if len(sys.argv)!=3:
print("Usage:WindowedNetworkWordCount.py
exit(-1)
sc=SparkContext(appName="PythonStreamingWindowedNetworkWordCount")
ssc=StreamingContext(sc,10)
ssc.checkpoint("file:///usr/local/spark/mycode/streaming/socket/checkpoint")
lines=ssc.socketTextStream(sys.argv[1],int(sys.argv[2]))
counts=lines.flatMap(lambda line:line.split(" "))\
.map(lambda word:(word,1))\
.reduceByKeyAndWindow(lambda x,y:x+y,lambda x,y:x-y,30,10)
counts.pprint()
ssc.start()
ssc.awaitTermination()
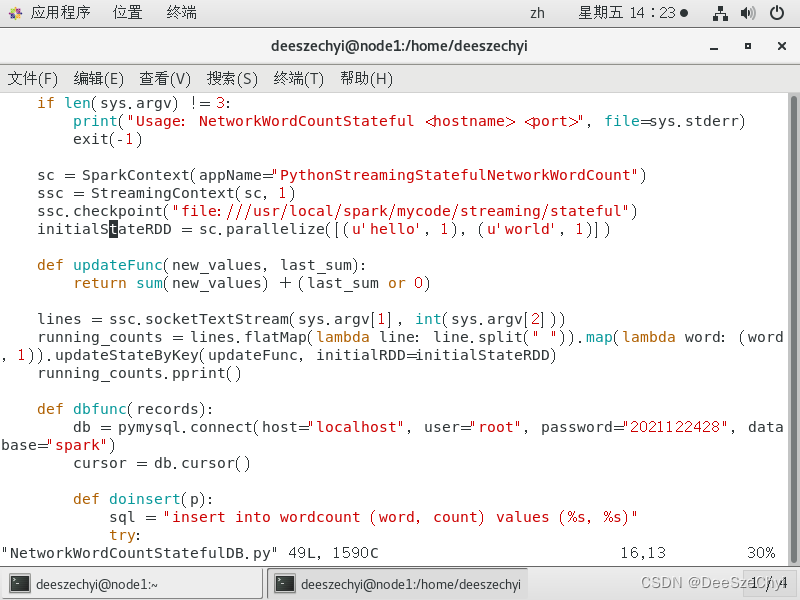
4. from __future__ import print_function
import sys
import pymysql
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: NetworkWordCountStateful
exit(-1)
sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")
ssc = StreamingContext(sc, 1)
ssc.checkpoint("file:///usr/local/spark/mycode/streaming/stateful")
# RDD with initial state (key, value) pairs
initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
running_counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.updateStateByKey(updateFunc, initialRDD=initialStateRDD)
running_counts.pprint()
def dbfunc(records):
db = pymysql.connect("localhost","root","123456","spark")
cursor = db.cursor()
def doinsert(p):
sql = "insert into wordcount(word,count) values ('%s', '%s')" % (str(p[0]), str(p[1]))
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
for item in records:
doinsert(item)
def func(rdd):
repartitionedRDD = rdd.repartition(3)
repartitionedRDD.foreachPartition(dbfunc)
running_counts.foreachRDD(func)
ssc.start()
ssc.awaitTermination()
四、实验结果
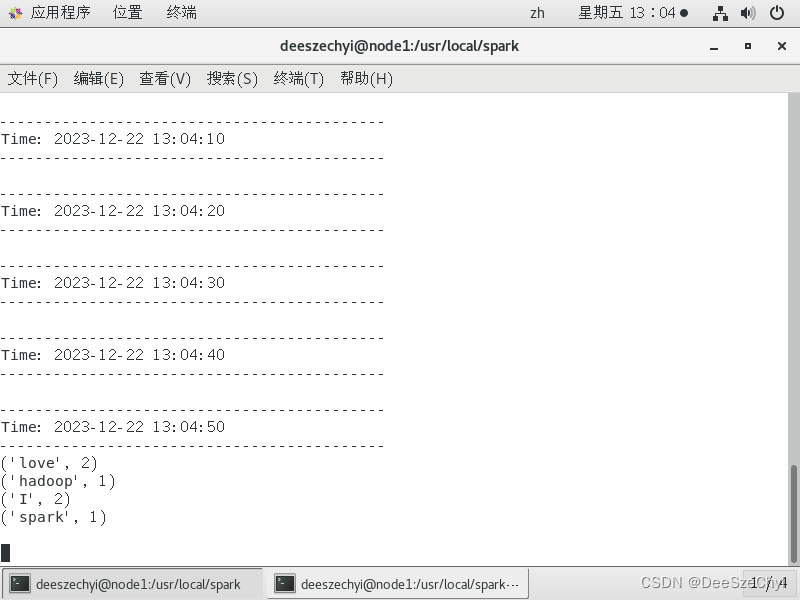
1.文件流:在pyspark交互式环境中输入:

在/usr/local/spark/mycode/streaming/logfile目录下创建一个log1.txt文件,输入:I love spark I love hadoop,则流计算终端显示:
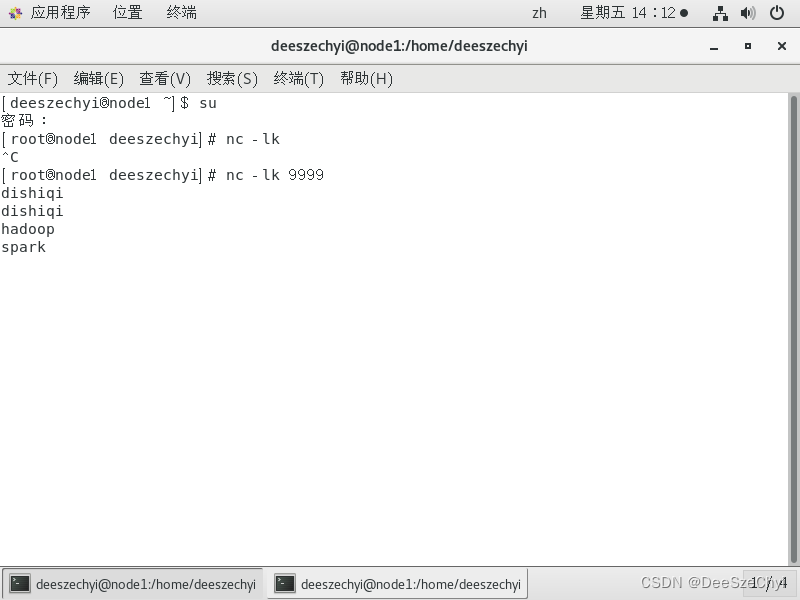
套接字流:创建NetworkWordCount.py

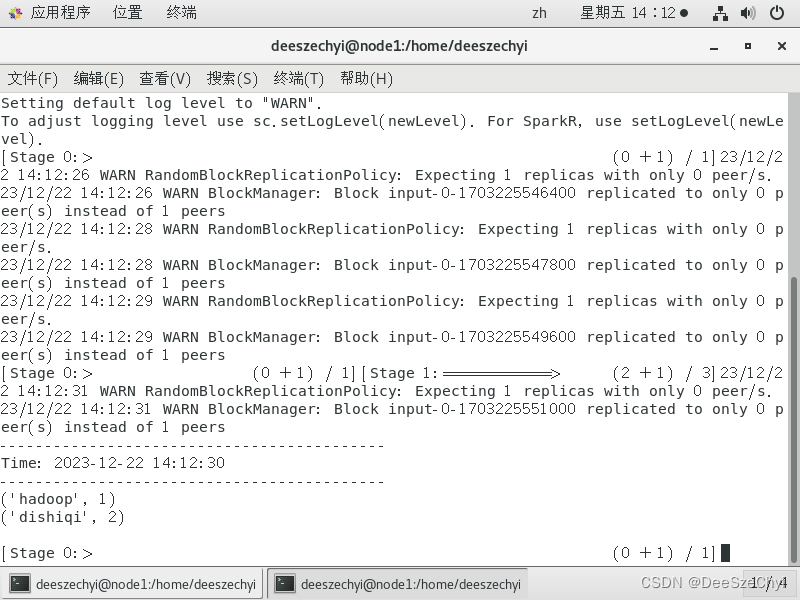
在数据流终端启动服务器,端口号设置为9999,在里面输入一些单词,则在流计算终端显示:

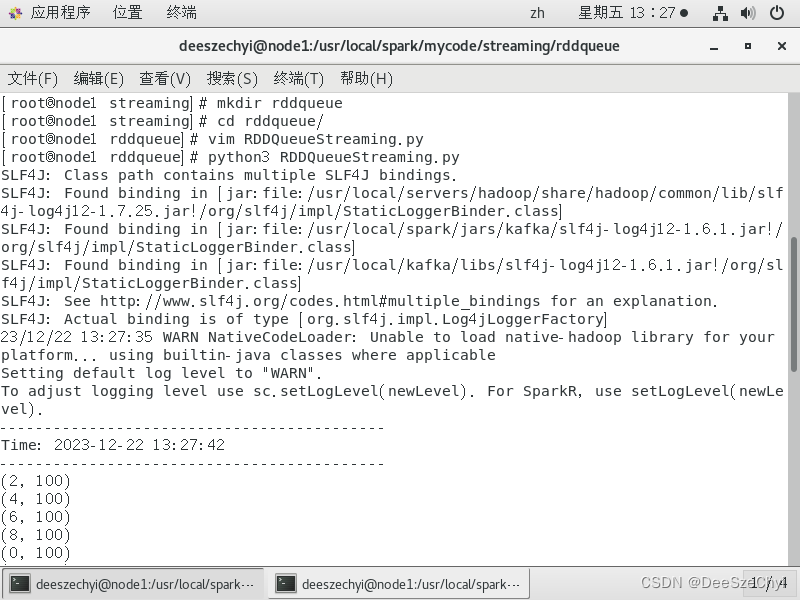
RDD队列流:

2.kafka配置:
启动zookeeper:

启动Kafka:

创建自己名字拼音的主题:

通过spark streaming程序使用kafka数据源:

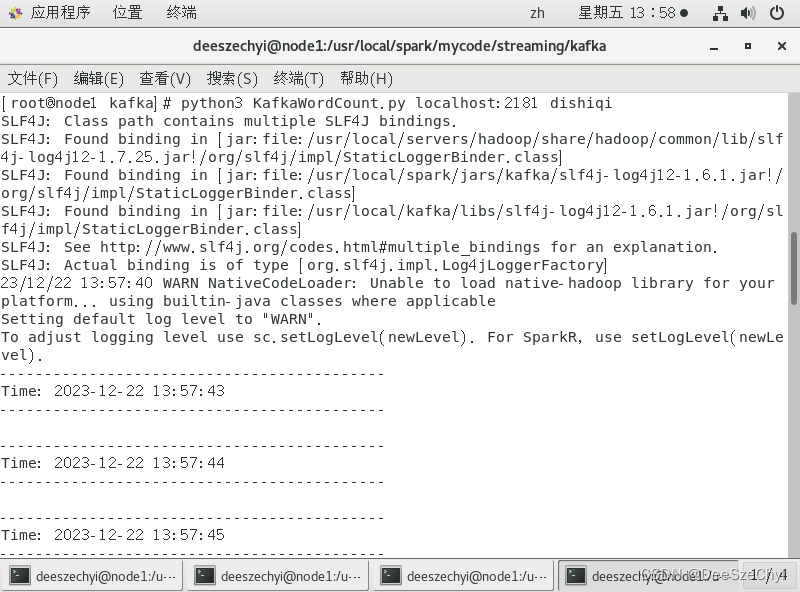
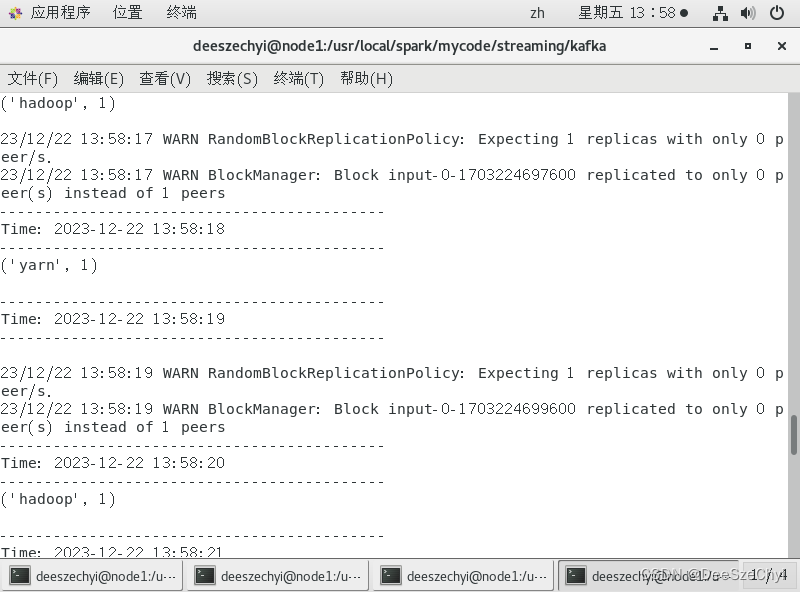
3.无状态转换见套接字流NetworkWordCount词频统计程序
有状态转换:
4. 在终端安装python连接MySQL的模块:

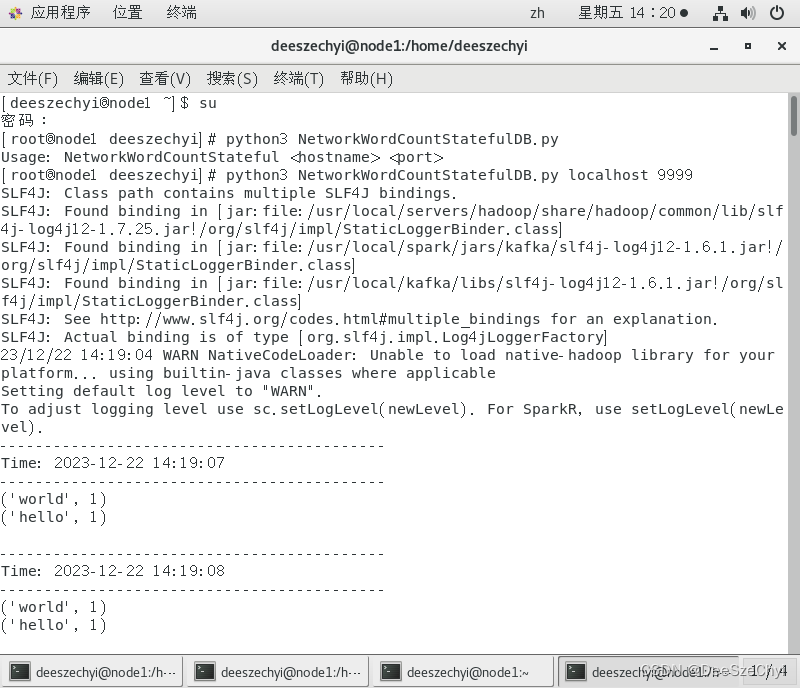
查看数据库:

评论记录:
回复评论: