
以下参数中有sql字眼的一般只有spark-sql模块生效,如果你看过spark的源码,你会发现sql模块是在core模块上硬生生干了一层,所以反过来spark-sql可以复用core模块的配置,例外的时候会另行说明,此外由于总结这些参数是在不同时间段,当时使用的spark版本也不一样,因此要注意是否有效,验证的方法很简单,去下面官方文档搜一下就行。如果本博主已经踩了坑的会直接说明。看完之后如果有core模块优化参数不多的感觉,无需自扰,因为core模块的开发本身就是80%依赖代码级优化实现的,比如rdd集的分区拆分、加盐、转换等等都是在代码级别完成的,而不是任务提交参数。
这里附带官网的配置文档–》https://spark.apache.org/docs/latest/configuration.html,把官方文档放在这里有两个目的,一是官方文档里面spark参数很全,就导致里面不止有可用来任务优化的参数,还有偏集群用的配置,比如是否开始任务ui,是否在ui中就能kill任务等等这种,二是我下面写的都是我在工作中会用到的,以及一些使用经验,并且官方文档里那么多参数工作都不可能都用,你想用也记不住,同时大家在看其他文献时,遇到不认识的参数可以去找找看,官方文档里有参数的开始生效版本(Since Version),找不到的话就说明,参数不正确或者apache最新版本的spark已经删除了相关配置,这是最难受的一点,spark官方文档里现在只显示最新版本的可用参数
1、任务使用资源限制,基本参数,注意的是这些资源配置有spark前缀是因为他们是标准的conf配置,也就是submit脚本,你调用--conf参数写的,和--driver.memory这种属于不同的优先级,--driver.memory这种优先级比它高
spark.driver.memory=20G #applicationmaster启动的driver进程占用内存
spark.driver.cores=4 #applicationmaster启动的driver进程占用核数
spark.executor.cores=4 #容器占用核数
spark.executor.memory=40G #容器占用的内存数
spark.num.executors=10 #任务用到的总容器数
- 1
- 2
- 3
- 4
- 5
对于spark来讲,数据量和计算量是两个不同的概念,计算任务本身不止有单一的MR架构那样一个map一个reduce的直白执行逻辑,还有很多复杂的任务task,所以随着执行计划的不同,往往计算量要大于数据量,而且这个差距是成正比的放大,要使用的计算资源也更多,除了计算任务本身,还有伴随计算产生的附加消耗,因此往往1G的数据要付出3G的计算资源,甚至更多,在具体计算的时候使用多少资源,就需要经验了,而且要注意并不是一味的加资源任务就能跑通,需要配合其他参数以及实际使用经验。不过刚接触可以参考几个公式
1、容器个数 = min( 计算数据大小 / 预期单容器内存 + 5~10%左右的资源预留,任务执行中配合其他参数可支持并行task最多时的容器个数 )
2、driver的内存(spark.driver.memory),除非涉及数据广播或数据回收(collect这种算子),否则一般情况下5G5C的资源就足够大多数任务,甚至都很富裕了,并且driver容器的资源永远大于driver可收集数据集大小(spark.driver.maxResultSize)
3、单容器的内存和核数的比例,小任务一般是5:1,随着任务越来越大这个比例也会随之缩小,虽然你可以用单边的牺牲,来换取另一个资源的节省,比如单容器2C/20G这种配置方式,但是如果差的太多任务的效率和成功率反而会事倍功半
在单边牺牲的时候也不要太离谱,比如内存很小,核数很多的时候容易爆org.apache.http.ConnectionClosedException: Premature end of Content-Length delimited message body这种类似的错误
在容器资源的估算上,除了上面提到的用数据量来估算,也有的地方使用总核数来估算,也就是用总量可用有多少,再除以其他的相关数据值,这种情况是因为拥有的集群资源不多,没有办法支撑任务完全自主扩张,虽然两种估算方法最后的目的是一样的,但是后者对于大任务所需资源来讲,肯定会影响任务的运行,具体使用的时候看情况而定即可
在具体配置的时候,容器个数最好交给动态延展去处理,这样不会造成在启动容器量和在计算数据量上的不协调,除非你容器设置的本身不够。当你的任务特别大,大到超过了容器读写性能的瓶颈,再考虑用num的方式直接指定定额的容器个数,因为随着不同集群性能的影响,过大的任务在容器动态延展上会很吃力,任务会不稳定。
至于一个集群的性能读写瓶颈,如果你能拿到当前集群的冒烟测试结果,那是最好的,但是越大的集群,冒烟测试越不好做,所以除非是私有云的小项目,否则一般很难拿到,此时最直观的观察点就是这个集群的shuffer额度,在保证任务跑通的情况下,一个集群能容纳的shuffer量越高他的读写瓶颈就越高,本作者最高操作过读写瓶颈在10Tshuffer下保证任务运行,10t以上就不太好说了
2、限制sql任务运行时拉取的分区数和拉去文件总大小的上限,不过这两个配置是kyuubi的,做一个参考而已,apache spark不限制你读取的分区数和数据大小
spark.sql.watchdog.maxPartitions=2000
spark.sql.watchdog.maxFileSize=3t
- 1
- 2
3、任务过程中计算文件的大小控制,也就是聚合、拆分相关,这点可以跳过,因为这点涉及的参数不是apache spark的参数,放在这里只是做一个对比,apache 版本的core模块需要通过关注rdd集的分区数控制,见下面的36点,或者大文件控制上限,见5点,sql模块需要通过AQE,见下面的9点
spark.sql.optimizer.insertRepartitionBeforeWriteIfNoShuffle.enabled=true #是否对不发生shuffer的stage做聚合
spark.sql.optimizer.insertRepartitionBeforeWrite.enabled=true #是否在写入文件之间聚合
spark.sql.optimizer.finalStageConfigIsolation.enabled=true #最后任务的最后阶段文件聚合,会有一个落盘前聚合的执行计划
- 1
- 2
- 3
上面这三个文件聚合是kyuubi的参数,apache spark开源团队对离线文件聚合与拆分这方面,由于被白嫖太多所以有些许摆烂
但是国内大厂有自己的开发做出了自己的东西,比如阿里基础架构计算引擎3.2.1升级点概要中提到的支持非动态分区支持合并小文件
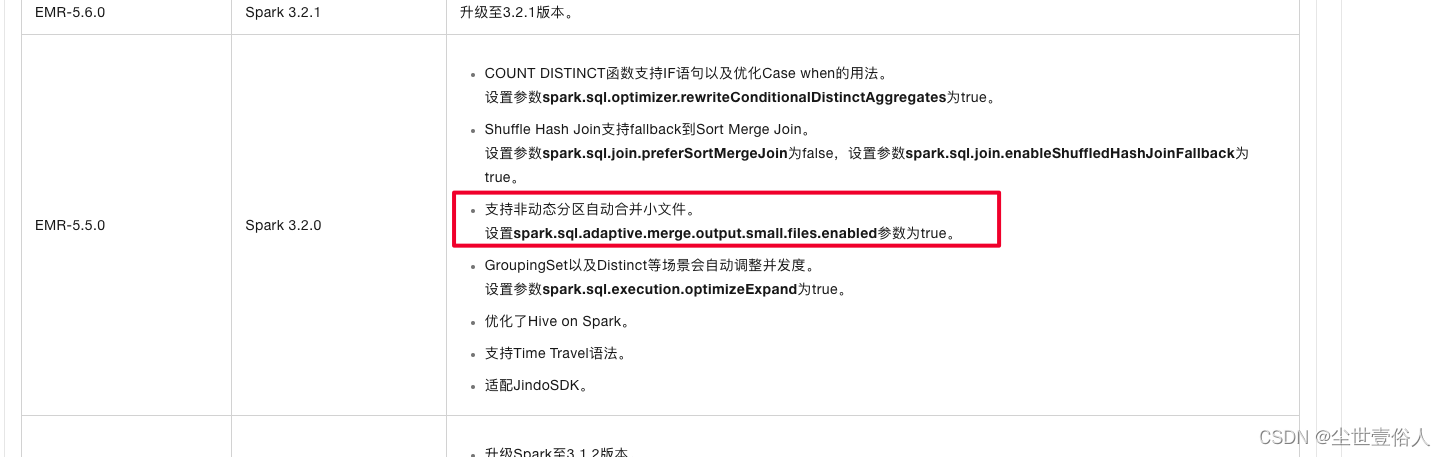
诸如此类的参数各家引擎提供商都不一样,因此如果你用的不是开源就问一下提供方是否有相关参数,同时这也更加突出了开发的重要,尤其是在这个AI满天飞的时代,很多公共的姿势资源差距被拉平了,所以大家努力共勉提升自己的技术水平还是很有必要的
4、任务最后阶段消耗资源多少,通常是配合压缩和自适应分区的相关配置来做任务优化,这两个参数同上也是kyuubi的,放在这里再次向告诉大家突出不同发行版本下的spark架构有着不同的特点,需要灵活应用
spark.sql.finalWriteStage.executorMemory=10g
spark.sql.finalWriteStage.executorCores=2
- 1
- 2
5、大文件拆分,从apache spark 2.1.0 版本开始core模块处理大文件时,可以不通过修改rdd集的分区数来控制计算过程中生成的文件大小,因为大文件的上限是一个未知数,直接通过分区数来控制,可能会发生需多次尝试的情况,最终本末倒置,因此,apache spark支持修改计算中生成文件的上限,来限制大文件对任务的影响,默认是128M(134217728字节)
spark.files.maxPartitionBytes=134217728 #一般情况用这个
- 1
不过当你使用的是sql模块,并且读取Parquet、JSON和ORC文件时,apache版本下的spark,提供了两个比较鸡肋的同类型配置,说是鸡肋是因为sql模块有AQE,因此了解知道就行
spark.sql.files.maxPartitionBytes=128MB #这个配置在你读取的数据文件类型是Parquet、JSON和ORC时使用,⭐️⭐️⭐️注意这个参数2.0.0开始起效
spark.sql.files.maxPartitionNum=null #当你的数据文件类型是Parquet、JSON和ORC时使用,用来调整最大分区数,⭐️⭐️⭐️注意这个参数3.5.0开始起效
- 1
- 2
配置的时候注意,spark.sql.files.maxPartitionNum的起效版本是3.5.0,而apache spark源码里面的默认值就是空的,官方文档中提到如果不配置时默认采用spark.sql.shuffle.partitions的值,并且需要开启AQE以及AQE的分区跟踪
6、数据文件压缩
如果你在使用sparksql能力处理hive数据,可以使用下面hive和mr的配置
mapreduce.output.fileoutputformat.compress=true #是否对任务的输出数据压缩
mapreduce.output.fileoutputformat.compress.type=BLOCK
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec #用到的压缩类
mapreduce.map.output.compress=true #是否对map阶段的输出进行压缩
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.GzipCodec #同上
hive.exec.compress.output=true #hive端数据压缩
mapred.output.compression.type=BLOCK
mapred.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
常用的格式如下
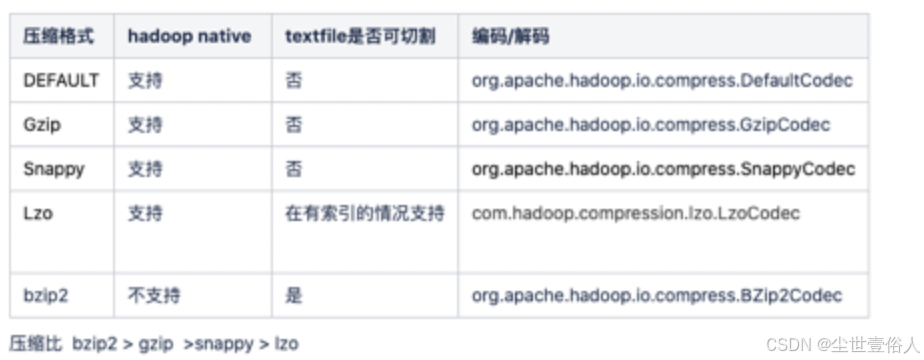
如果你不是只关注hive数仓中数据的处理,则可以使用其他的压缩配置,注意
spark.rdd.compress=true #是否对rdd集合的数据进行压缩
spark.checkpoint.compress=true #是否对任务检查点数据压缩,默认false
spark.broadcast.compress=true #spark任务的广播数据是否压缩,默认true,压缩格式复用 spark.io.compression.codec
spark.shuffle.compress=true #shuffle数据是否压缩
spark.shuffle.spill.compress=true #shuffer时溢出的数据是否压缩,默认true,压缩用到的类库采用spark.io.compression.codec的值
- 1
- 2
- 3
- 4
- 5
在sparksql模块处理parquet和orc数据时,压缩的格式可以另行制定,注意一般不用,因为这个配置的生效优先级是最后的,它只是压缩的格式支持的多一些
spark.sql.parquet.compression.codec=snappy #默认是snappy,可以选择none, uncompressed(这个是不压缩的意思), snappy, gzip, lzo, brotli, lz4, lz4raw, lz4_raw, zstd
spark.sql.orc.compression.codec=snappy # 可选 none, un- 1
评论记录:
回复评论: