
测试
从日志信息来看:
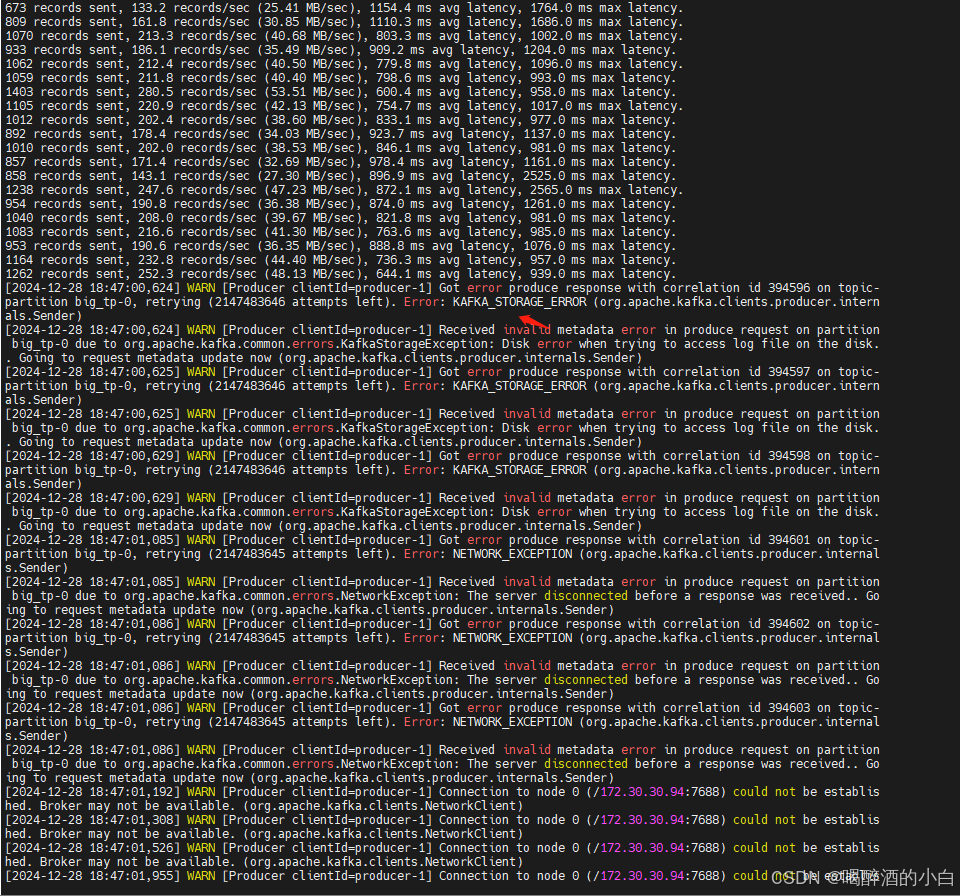
[2024-12-30 09:39:47,738] WARN [Producer clientId=producer-1] Error while fetching metadata with correlation id 3 : {big_tp=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
- 1
这是 Kafka Producer 在尝试获取元数据(Metadata)时发生了 LEADER_NOT_AVAILABLE 错误的警告。这表示生产者无法找到指定 Topic 的分区的 Leader。以下是可能的原因及分析:

1. Topic 配置问题
- 原因:
- Topic
big_tp未正确创建,或者分区的 Leader 尚未被正确分配。 - 如果 Topic 是动态创建的,Kafka Broker 可能需要时间分配 Leader 节点。
- Topic
- 解决方法:
- 使用 Kafka 命令行工具检查 Topic 是否存在:
kafka-topics.sh --bootstrap-server <broker-address> --topic big_tp --describe- 1
- 确认分区数和副本数正确,以及分区是否有 Leader。如果没有 Leader,需要进一步检查 Kafka 集群状态。
- 使用 Kafka 命令行工具检查 Topic 是否存在:
2. Kafka Broker 不健康
- 原因:
- Kafka 集群中某些 Broker 宕机或不可用,导致分区的 Leader 丢失。
- Zookeeper(或 Kafka 集群自身的控制器)可能未及时重新分配 Leader。
- 解决方法:
- 检查 Kafka Broker 状态是否正常:
kafka-broker-api-versions.sh --bootstrap-server <broker-address>- 1
- 检查 Kafka 的控制台日志是否存在错误信息(如网络问题或磁盘问题)。
- 检查 Zookeeper 状态(如果使用 Zookeeper):
zkCli.sh -server <zookeeper-address> status- 1
- 检查 Kafka Broker 状态是否正常:
3. 网络问题
- 原因:
- 生产者无法连接到 Kafka Broker,或者 Kafka Broker 间的通信存在问题。
- 可能是由于防火墙、网络延迟或网络分区(Partition)。
- 解决方法:
- 确认生产者的网络是否能正常连接 Kafka Broker:
telnet <broker-address> <broker-port>- 1
- 检查 Kafka 的
listeners和生产者的bootstrap.servers是否匹配。
- 确认生产者的网络是否能正常连接 Kafka Broker:
4. Broker 端配置问题
- 原因:
- Kafka Broker 的副本分配策略不当,导致 Leader 无法正常分配。
- Broker 启动时未能加载 Topic 的元数据(可能是磁盘损坏或数据丢失)。
- 解决方法:
- 检查 Broker 的日志,查看是否存在分区恢复失败或副本同步问题:
cat /opt/kafka/logs/server.log- 1
- 确保 Broker 参数配置正确,特别是以下关键配置:
unclean.leader.election.enable:设置为true,允许不完全同步的副本成为 Leader(可能导致数据丢失,但能快速恢复服务)。auto.leader.rebalance.enable:设置为true,启用自动 Leader 重新平衡。
- 检查 Broker 的日志,查看是否存在分区恢复失败或副本同步问题:
5. 副本同步问题
- 原因:
- 分区的 ISR(In-Sync Replicas,同步副本集)为空,导致没有可用的 Leader。
- 副本可能因为负载过高或延迟过大未能完成同步。
- 解决方法:
- 检查 ISR 集:
kafka-topics.sh --bootstrap-server <broker-address> --topic big_tp --describe- 1
- 如果 ISR 为空或不完整,可以通过调整以下 Broker 配置来优化副本同步:
replica.lag.time.max.ms:增加允许副本延迟的时间。num.replica.fetchers:增加副本的抓取线程数。
- 检查 ISR 集:
6. 生产者配置问题
- 原因:
- 生产者配置的
metadata.fetch.timeout.ms太短,导致元数据请求超时。 - 生产者可能未正确配置
acks或retries参数。
- 生产者配置的
- 解决方法:
- 增加
metadata.fetch.timeout.ms,例如:properties.put("metadata.fetch.timeout.ms", "30000");- 1
- 设置重试机制:
properties.put("retries", "5");- 1
- 增加
排查步骤总结
- 检查 Topic 是否存在,并查看分区 Leader 状态:
kafka-topics.sh --bootstrap-server <broker-address> --topic big_tp --describe- 1
- 检查 Kafka Broker 的健康状态和日志。
- 检查生产者与 Broker 的网络连通性。
- 如果 ISR 异常,优化副本同步相关配置。
通过以上步骤,逐步定位并解决问题。
终端1:模拟大量生产
./kafka-producer-perf-test.sh --producer-props bootstrap.servers=172.30.30.97:7212 --topic big_tp --num-records 5000000 --throughput -100 --record-size 20000
终端2:模拟小量生产
./kafka-producer-perf-test.sh --producer-props bootstrap.servers=172.30.30.97:7212 --topic small_tp --num-records 500 --throughput -100 --record-size 2000
终端3:统计大量生产
docker run --rm --name=kcat --network=host registry.woqutech.com/cicd/edenhill/kcat:1.7.1 -b 172.30.30.97:7212 -t big_tp -C -e | wc -l
终端4:统计小量生产
docker run --rm --name=kcat --network=host registry.woqutech.com/cicd/edenhill/kcat:1.7.1 -b 172.30.30.97:7212 -t small_tp -C -e | wc -l
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注意存储空间


目录空间解释
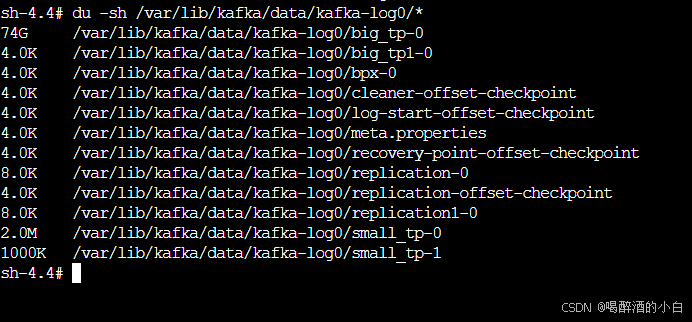
这些文件和目录是 Kafka 数据目录中的一部分,它们与 Kafka 的日志管理、副本同步和恢复机制有关。以下是每个文件和目录的详细解释:
-
cleaner-offset-checkpoint:- 这是一个检查点文件,用于记录日志清理器(Log Cleaner)的偏移量。日志清理器是 Kafka 后台运行的一个进程,负责删除旧的或过期的消息,以释放存储空间。这个文件记录了清理器处理日志文件时的最后一个偏移量。
- 文件大小为 4 字节,这可能表明文件内容非常简单,只包含一个偏移量值。
-
log-start-offset-checkpoint:- 这个文件记录了日志文件的起始偏移量。当 Kafka 启动时,它会使用这个偏移量来确定从哪个位置开始读取日志文件。
- 文件大小为 4 字节,类似于上面的清理器偏移量文件。
-
meta.properties:- 这是一个元数据文件,包含了分区的配置信息,如分区的副本数、最小和最大偏移量等。
- 文件大小为 88 字节,这个文件通常很小,因为它只包含一些基本的配置信息。
-
recovery-point-offset-checkpoint:- 这是一个检查点文件,用于记录消费者在分区中的恢复点偏移量。这个偏移量指示了消费者在分区中的位置,用于在消费者失败后恢复消费。
- 文件大小为 99 字节。
-
replication-0和replication1-0:- 这些是 Kafka 用于存储分区副本的目录。每个分区可能有多个副本,以提高数据的可靠性和可用性。这些目录包含了分区的副本数据。
- 目录权限设置为
drwxr-xr-x,意味着所有者可以读写执行,而组和其他用户只能读取和执行。 - 目录大小为 167 字节,这可能是指目录的元数据大小,而不是目录内容的大小。
-
replication-offset-checkpoint:- 这是一个检查点文件,用于记录副本同步的偏移量。这个文件帮助 Kafka 跟踪副本之间的同步状态,确保数据的一致性。
- 文件大小为 104 字节。
这些文件和目录是 Kafka 正常运行的关键部分,它们确保了数据的持久化、日志的清理、副本的同步以及消费者的正确恢复。
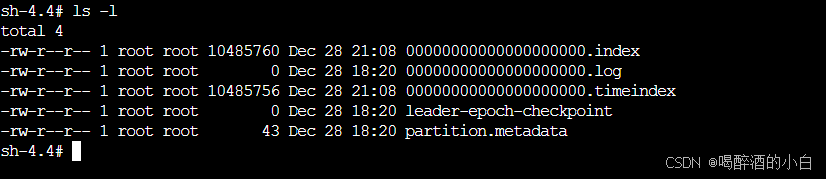
在 Kafka 中,每个分区(Partition)的数据存储由几个关键文件组成,这些文件共同维护了分区的数据和索引信息。以下是您提供的文件列表中各个文件的解释:
-
00000000000000085856.index:- 这是一个索引文件,用于存储分区中消息的索引信息。索引文件帮助 Kafka 快速定位消息,提高读取效率。
- 文件大小为 42920 字节。
- 最后修改时间是 12 月 28 日 18:26。
-
00000000000000085856.log:- 这是分区的日志文件,存储了分区中的所有消息数据。Kafka 的消息持久化就是通过这些日志文件实现的。
- 文件大小为 1073586352 字节(约 1GB)。
- 最后修改时间是 12 月 28 日 18:26。
-
00000000000000085856.snapshot:- 这是一个快照文件,用于存储分区中特定时刻的状态。在 Kafka 的日志压缩和消息删除功能中,快照文件被用来记录消息的删除点。
- 文件大小为 10 字节,这可能表明这是一个很小的快照,或者是一个空的快照文件。
- 最后修改时间是 12 月 28 日 18:25。
-
00000000000000085856.timeindex:- 这是一个时间索引文件,用于支持基于时间的消息检索。这个文件允许 Kafka 根据消息的时间戳快速定位消息。
- 文件大小为 62256 字节。
- 最后修改时间是 12 月 28 日 18:26。
这些文件共同构成了 Kafka 分区的数据存储结构。.log 文件是核心的数据文件,而 .index、.snapshot 和 .timeindex 文件则提供了索引和状态管理,使得 Kafka 能够高效地进行消息的存储、检索和维护。
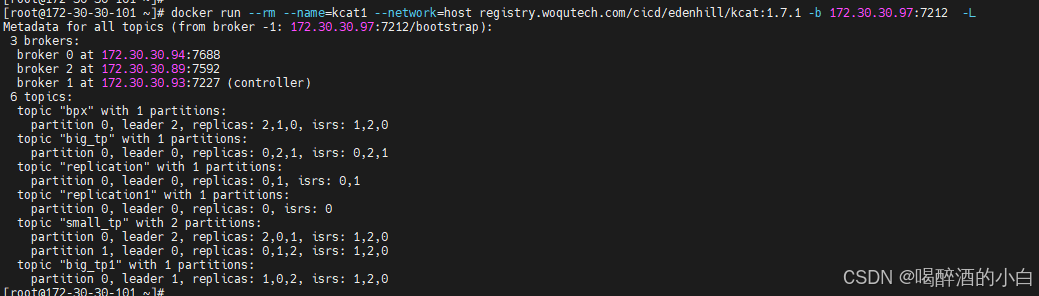
kcat
kcat 是 Kafka 的一个命令行工具,类似于 cat,用于生产和消费 Kafka 消息。根据您提供的命令:
kcat:1.7.1 -b 172.30.30.97:7212 -t big_tp -C -e
- 1
这个命令的各个参数含义如下:
kcat:1.7.1:指定了kcat的版本。-b 172.30.30.97:7212:指定 Kafka 代理(Broker)的地址和端口,这里是172.30.30.97机器上的7212端口。-t big_tp:指定要操作的 Kafka Topic 名称为big_tp。-C:表示以消费者(Consumer)模式运行。-e:表示消费到 Topic 结束,并输出最后一个偏移量。
根据这些参数,这个命令是在以消费者模式消费 big_tp Topic 中的数据,并且会一直消费到 Topic 的末尾。
至于您的问题“消费了数据就没有了吗”,这取决于 Kafka 的配置和 kcat 命令的使用方式:
-
数据持久性:Kafka 是一个持久化消息系统,消息被存储在磁盘上,直到它们被明确地删除。因此,即使消息被消费了,只要没有被删除,它们仍然存在于 Kafka 中。
-
消费偏移量:消费者消费消息后,会更新消费偏移量。偏移量是 Kafka 用来跟踪消费者在 Topic 分区中的位置的。一旦偏移量被更新,消费者就会认为那些消息已经被“消费”了,并且不会再次从那些偏移量的位置消费消息。
-
消息保留策略:Kafka 配置了消息的保留策略,可以是基于时间的(例如,保留7天),也可以是基于大小的(例如,保留到50GB)。如果消息超过了保留策略的限制,它们会被自动删除。
- 消费者组:Kafka 支持消费者组,同一个消费者组内的消费者可以共享消费任务。如果一个消费者消费了消息,其他消费者不会再次消费同一批消息。但是,如果另一个消费者组也订阅了同一个 Topic,它们可以独立地消费所有消息。
综上所述,使用 kcat 命令消费数据后,消息不会自动从 Kafka 中删除,除非达到了保留策略的限制或者被手动删除。消费操作只是更新了消费者的偏移量,表明那些消息已经被“处理”过了。
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 172.30.30.97:7212 --topic small_tp --time -1


基线
Kafka 的性能测试工具(kafka-producer-perf-test.sh 和 kafka-consumer-perf-test.sh)并没有固定的基线标准,因为性能受多种因素的影响,包括硬件配置、集群设置、网络条件、消息大小、分区数量等。不过,可以根据行业经验和典型场景,为性能测试设定一些参考基线指标。
影响 Kafka 性能的关键因素
-
硬件配置:
- 磁盘性能:SSD 优于 HDD,I/O 性能是瓶颈的常见来源。
- 网络带宽:10Gbps 或更高网络能够显著提升吞吐量。
- CPU 核心数:更多的核心数可以支持更高的并发线程。
- 内存大小:充足的内存可以提高 Kafka 缓存和数据传输效率。
-
Kafka 配置:
- 分区数量:更多分区可以提高并行处理能力,但会增加元数据管理开销。
- 副本数量:副本越多,吞吐量越低,但高可用性越好。
- 日志刷盘频率:
log.flush.interval.ms或log.flush.interval.messages的配置会影响写性能。
-
测试参数:
- 消息大小:小消息会增加网络和处理的开销,而大消息更容易受到网络吞吐限制。
- 生产者配置:
acks、batch.size、linger.ms等参数会显著影响测试结果。 - 消费者配置:
fetch.min.bytes和max.partition.fetch.bytes影响吞吐量。
参考性能基线
以下是典型 Kafka 集群的性能基线指标,仅供参考:
| 指标 | 基线参考值 | 说明 |
|---|---|---|
| 吞吐量 (Throughput) | 100MB/s - 1GB/s(每个 Broker) | 受消息大小和分区数量影响较大。 |
| 延迟 (Latency) | < 10ms(写入延迟) | 高负载下可能会增加,但通常保持低于 50ms。 |
| 每秒消息数 (Msg/s) | 5万 - 100万+(每个分区) | 消息大小为 1KB 的情况下。 |
| IOPS | 数千到数十万 | 磁盘性能直接影响 Kafka 的写性能。 |
测试基线案例
假设以下硬件和集群配置:
- 3 个 Kafka Broker,副本因子为 3,分区数量为 12。
- 硬件:NVMe SSD,10Gbps 网络,16 核 CPU,64GB 内存。
- 消息大小:200 字节。
生产者测试命令:
kafka-producer-perf-test.sh \
--topic test-topic \
--num-records 1000000 \
--record-size 200 \
--throughput -1 \
--producer-props bootstrap.servers=<broker-address>:9092
- 1
- 2
- 3
- 4
- 5
- 6
结果预期:
- 吞吐量:50MB/s ~ 300MB/s(取决于集群配置)。
- 消息数:每秒 25万 ~ 150万条消息(200 字节大小)。
- 延迟:平均 5ms - 15ms。
如何定义自己的基线标准
-
根据硬件和业务需求:
- 计算消息生产的峰值速率和消息大小,推算出需要的吞吐量。
- 根据分区数量和分布设置合理的硬件资源(如磁盘和 CPU 核心)。
-
逐步测试:
- 从小规模测试(1 分区、1 Producer 开始)逐步扩大到全负载测试。
- 测试不同消息大小、分区数量和副本设置的影响。
-
关注延迟:
- 高吞吐量通常伴随高延迟,找到合适的吞吐量和延迟平衡点。
-
记录基线结果:
- 针对生产环境,记录 Kafka 的吞吐量、延迟和硬件使用率,作为后续优化的参考。
性能优化建议
-
生产者优化:
- 增大批量大小(
batch.size)和等待时间(linger.ms)以提高吞吐量。 - 使用异步
acks=1或acks=all,视数据可靠性需求调整。
- 增大批量大小(
-
Broker 优化:
- 增加分区数量,提升并行能力。
- 优化磁盘使用(如启用压缩、使用快速存储)。
- 提高线程数(
num.network.threads、num.io.threads)。
-
消费者优化:
- 增大拉取大小(
fetch.max.bytes)和最大等待时间(fetch.max.wait.ms)。
- 增大拉取大小(
通过以上方式,你可以在自己的环境中建立合理的 Kafka 性能基线,进行有效的测试和优化。
官方文档和资源
是的,您可以参考以下官方文档和资源,了解如何使用 kafka-producer-perf-test.sh 进行性能测试,以及影响 Kafka 性能的因素:
- Apache Kafka 官方文档:提供了关于性能测试的详细信息,包括生产者和消费者的吞吐量测试、影响性能的配置参数等。
https://cwiki.apache.org/confluence/display/KAFKA/Performance%2Btesting
- Confluent 文档:详细介绍了 Kafka 的命令行工具,包括
kafka-producer-perf-test.sh的使用方法,以及如何测试和优化生产者性能。
https://docs.confluent.io/kafka/operations-tools/kafka-tools.html
- Confluent 开发者教程:提供了关于如何调优 Kafka 生产者客户端的教程,涵盖了不同配置设置对事件吞吐量和延迟的影响,以及如何使用性能测试脚本进行测试。
https://developer.confluent.io/courses/architecture/producer-hands-on
这些资源将帮助您深入了解 Kafka 性能测试工具的使用方法,以及如何根据您的特定环境和需求定义性能基线。
评论记录:
回复评论: