
前言

AI 图片生成像魔法一样,要完全理解里面的算法细节原理门槛挺高,但如果只是了解基本思路和相关概念,还是比较简单的。Stable Diffusion 是当前最流行的 AI 图片生成模型之一,本文基于 Stable Diffusion 介绍图片生成的基本原理,希望对大家有帮助。
扩散模型
所有的AI设计工具,安装包、模型和插件,都已经整理好了,?获取~

目前市面上文字生成图片基本上都基于 Diffusion 扩散模型,Stable Diffusion / Flux 都是,它最基本的原理是:根据文字指示,把一张随机生成的全是噪点的图片,一步步去掉噪点生成跟文字描述匹配的图片。
具体是怎样做到的?这里可以分步看两个问题:
-
生成:怎么从一张随机噪点的图生成一张正常的图
-
控制生成:怎么控制这个生成的图跟用户输入的 prompt 文字关联上
1. 生成
先看下第一个问题:从随机噪点图生成一张正常图片。
Denoising UNet
简化看下大概过程:
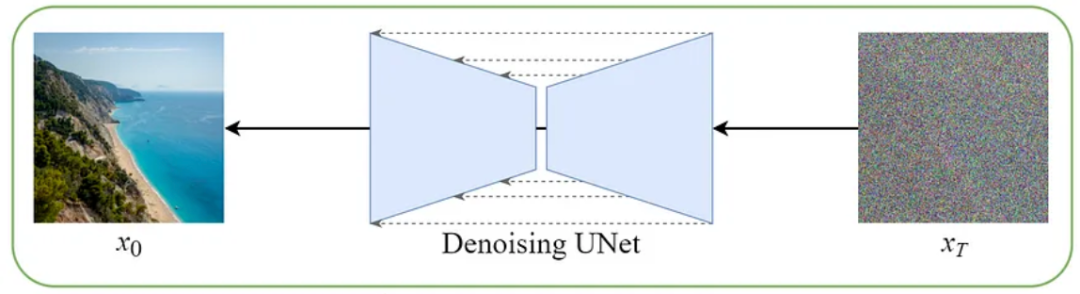
Denoising UNet 是一种基于 UNet 架构的深度学习模型,专门用于图像去噪任务。
可以粗略地理解为,Denoising UNet 这个模型在训练过程中记录了海量图片的内容(不是精确存储,可以理解为识别提取了图片特征,模糊地记忆图片的关键信息,跟人脑对一个画面的记忆类似)。在使用这个模型时,输入一个随机噪点图,经过模型处理能还原生成一张整张的图片。
如果你是用一张图片拼命训练它,那这个模型训练出来后,最终使用它时生成出来的就是这张图片本身,因为整个模型记录的都是这张图片的信息。如果你用一万张不同的图片训练这个模型,那使用它生成出来的会是这一万张图片内容随机组合的一张图片。
加噪降噪
上面说的这个生成过程,并不是一次性就从随机噪声图变成正常图了,而是一步步降噪的过程。
如下图所示,X0是正常的图片,XT是一个完全随机噪声,从X0到XT还有中间非常多加了不同程度噪点的图,模型学习记录的是怎么对一张有噪点的图逐步去噪点,还原出最终图。
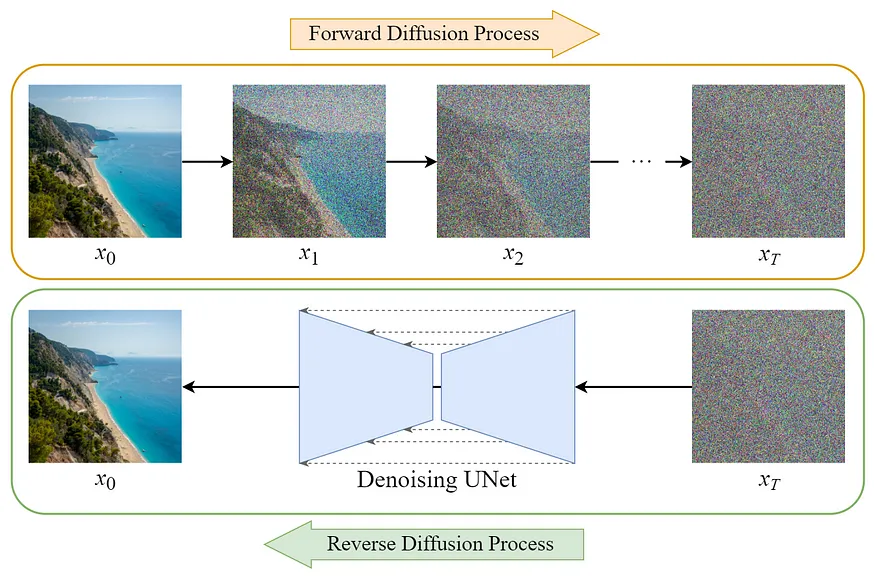
Denoisiong UNet 这个模型的能力是,给一张图片,它能预测出来这张图片上是加了多少噪声,这样就可以让这张图减掉这些噪声,得到更清晰一点的图,最终逐步降噪为一张正常图片。
预测降噪
下面稍微再展开看下预测噪声的的一步是怎么做的:
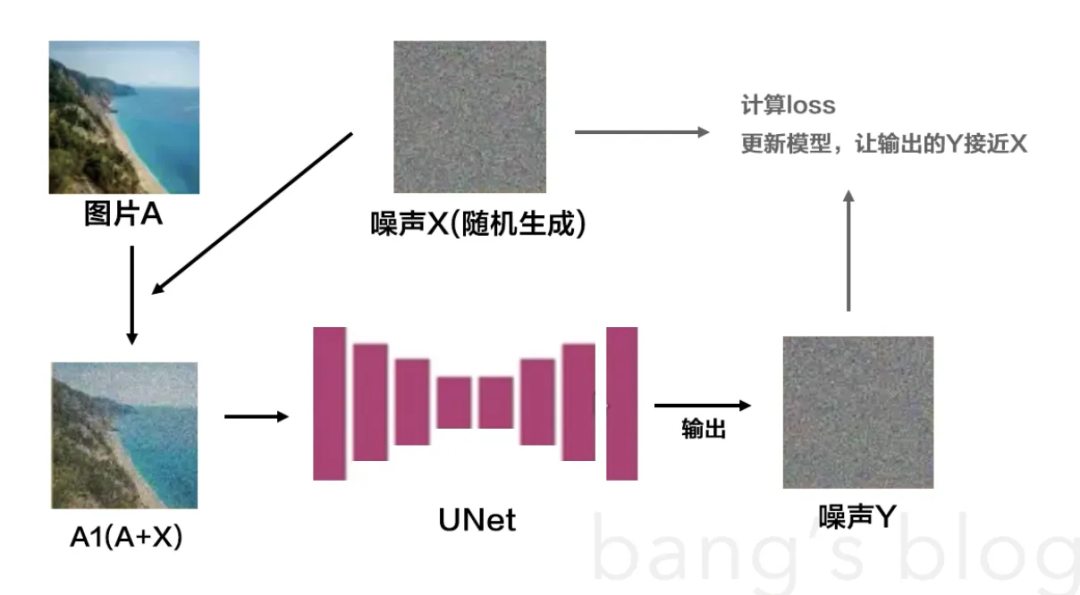
-
选一张正常图片A,随机生成一个噪声X,给A加上这个噪声。A+X=A1。
-
把A1输入到模型,我们希望做到的是,模型能在只有输入A1,没有输入噪声X的情况下,能自己推理知道噪声X是什么,如果能做到,那就可以通过A1 – X = A,把更清晰的图给反解出来了,也就是输入一张有噪点的图,输出一张去了噪点的图。
-
怎样做到?在训练过程中,我们是有A1和X这两个数据的,模型自己生成另一个噪声Y,跟噪声X对比,然后通过不断调节自己的参数,让自己生成的这个噪声接近X就行了。
-
这样模型记录了相关参数,下次拿A1过来,它就能推算出近似于上面加的噪声X,然后做A1 – X = A去噪,得到更清晰的图片A。
多步降噪
上面是简化的一步,只是把图片从稍微加了点噪声中还原出来,并不是直接从一个没有信息量充满噪声的图片中直接还原蹦出一张图来。要实现从纯噪声图生成一张图片,需要重复很多步上述步骤,所以它还有一个Time step的参数参与在训练过程中。
Time step 就是噪声强度,很好理解,表示的是加多少次噪声。回到上面的训练过程继续:
-
上面的训练,A 是完全没加过噪声的图片,A1是加了一次噪声X的图片,time step 就是1表示加了一次噪声,A1 和 t=1 输入到模型,训练出能推算 A1->A的能力
-
下一步针对A1再加一个噪声X2,A1+X2=A2,time step就是2,把加了两次噪声的图片A2和t=2输入到模型,训练出能推算A2->A1的能力
-
循环N次,加上多张图片重复这个步骤,模型的参数就学会了这里每一个步骤加的噪声数据。
-
实际训练过程中,t会是一个随机数,经过海量图片多轮训练,会覆盖所有t的值。下图epoch[回合],表示一轮一轮的训练,每次用不同的图片,不同的time step做训练
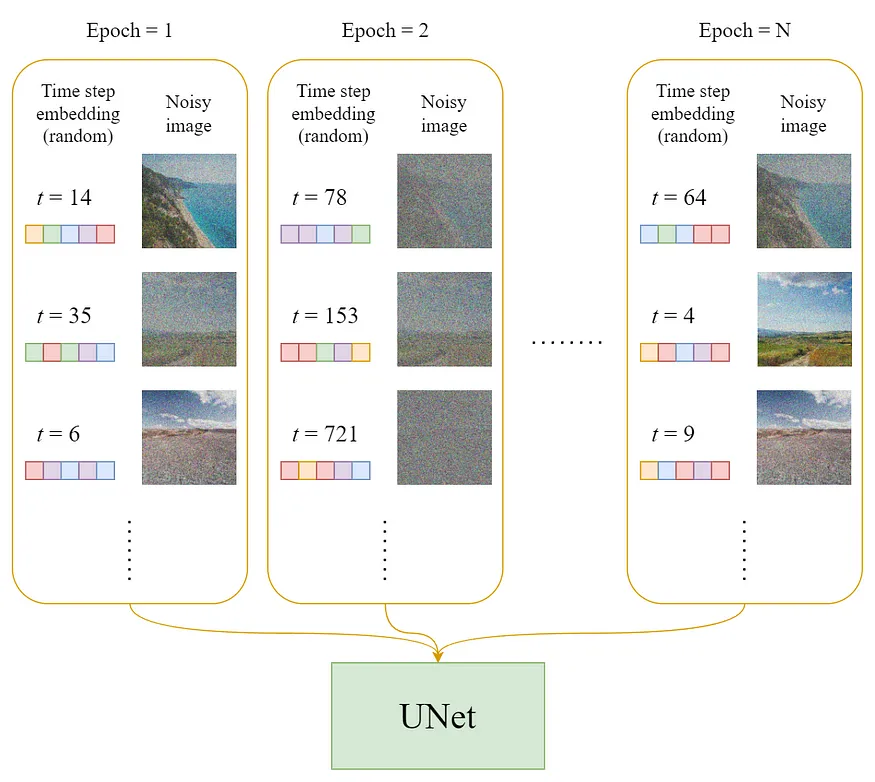
4. 最后就能从这个链路里把一个满是噪声(比如加了1000次噪声)的A1000逐渐去噪生成出清晰的图片A。A1000->A999 … ->A2->A1->A:
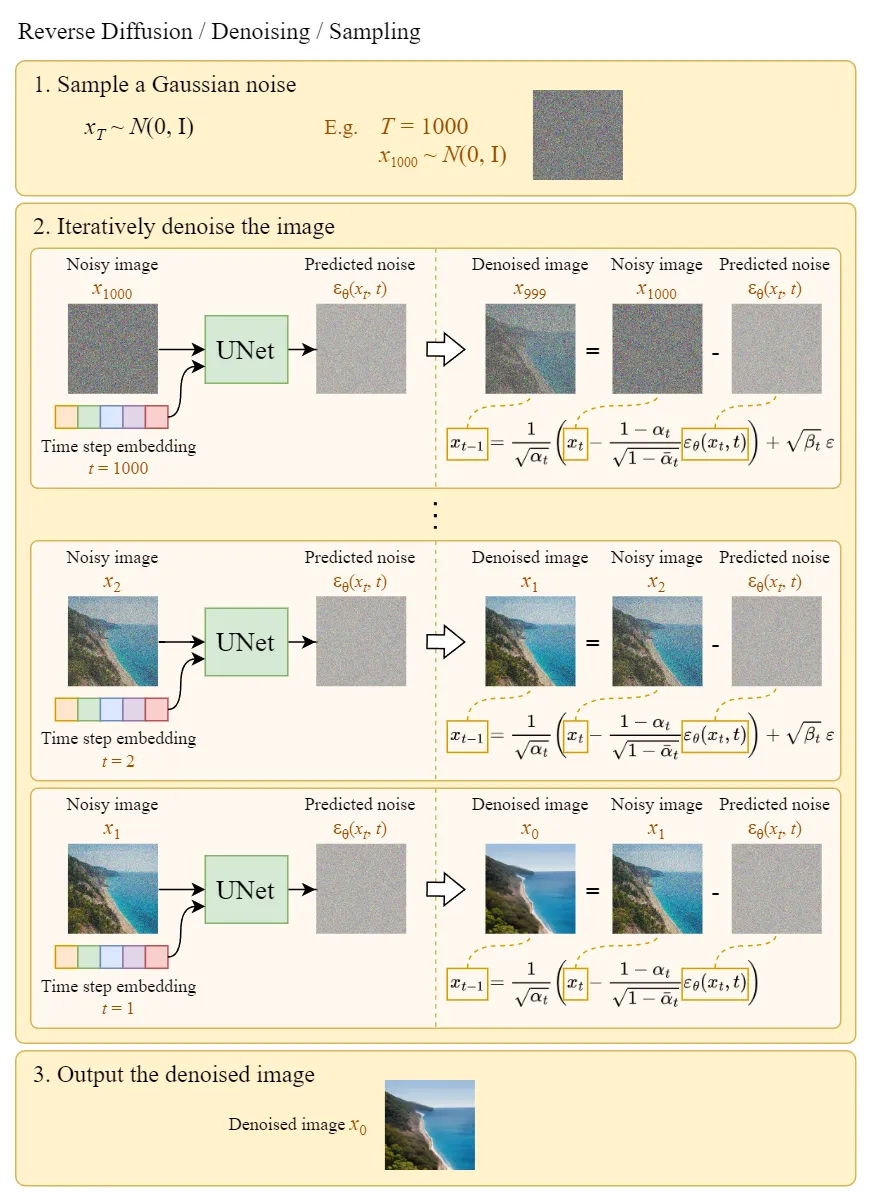
训练和生成过程简化后就是这样。如果训练集是一张图片反复训练,我猜测输入一张加满噪声的图,最终会把这张图片还原出来。如果训练集是海量的图片,那这里还原出来的图片,如果不加其他控制,就会是这些海量图片随机的组合结果。
2. 控制生成
接下来到下一个问题,就是怎样控制它去噪过程,让它生成的图片跟我们输入的文案描述匹配。
概念上很简单,就是在训练和生成过程中,把图片的描述文字也加进去。我们事先准备提供给模型训练的数据,除了图片本身,还需要包含对这张图片的文本描述,这样模型才能学到文本和图片内容的关系。
附:SD使用公开的 LAION-5B 数据集。通过CommonCrawl获取文本和图片,OpenAI的CLIP计算后获取图像和文本的相似性,并删除相似度低于设定阈值的图文对(英文阈值0.28,其余阈值0.26),500亿图片保留了不到60亿,最后形成58.5亿个图文对,包括23.2亿的英语,22.6亿的100+语言及12.7亿的未知语言。
[图片]
按刚才训练过程的示意图,实际上模型是三个输入,加了噪声的图片A1、图片对应的文本描述text,噪声强度time step,在这三者的作用下共同推理出对应的噪声。
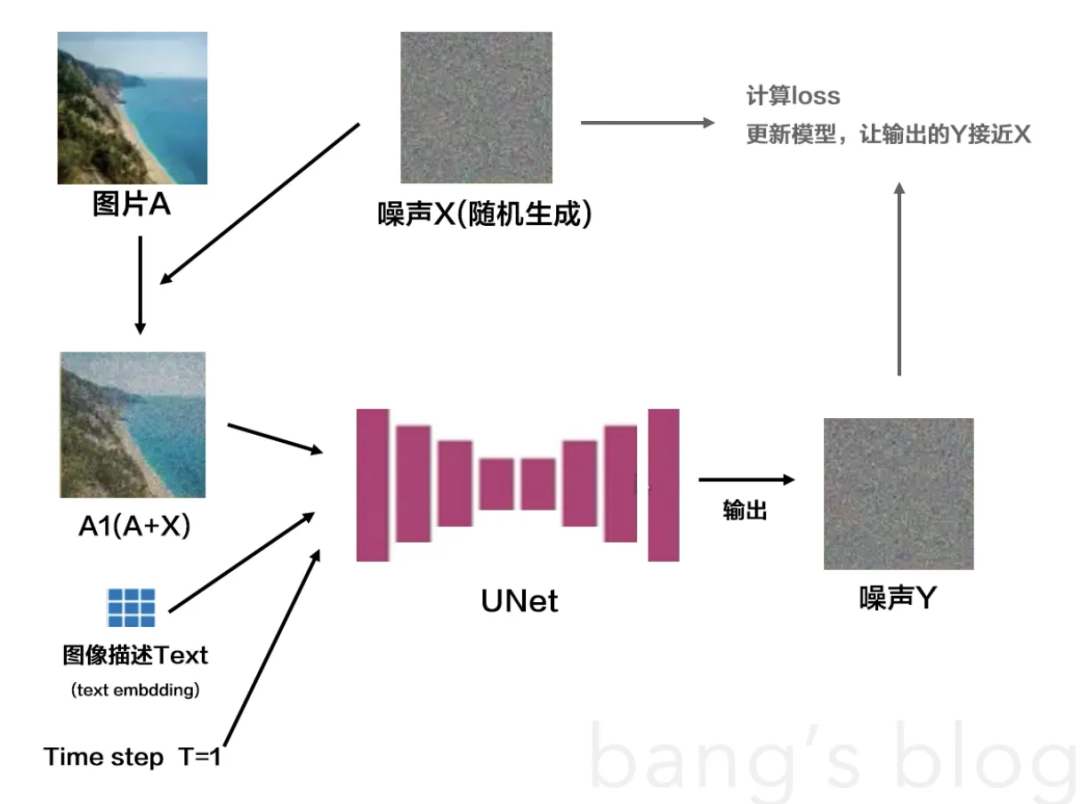
有text的训练输入后,后续在通过噪声生成图片的过程中,根据用户输入的prompt文本,就可以引导去噪的走向。
如果比较具象地想象这个过程,比如训练集有20张图片,5张的图片描述是girl,其他15张没有girl。训练过程中,girl这个词就跟这5张图片关联记录在网络参数里,在训练后使用这个模型时,输入的文本有girl,那去噪的过程的每一步就大概率会定位到这5张图片训练时的数据,会有更大概率去噪的过程走向这5张图片,而不是之前的随机走向。
到这里,扩散模型最基本的原理就差不多了。
重要概念
上述整个过程比较简化,过程中有几个重要的问题和概念还没提到,这里逐个说明。
Latent Space & VAE
上述的扩散模型的训练和使用,有个很明显要解决的问题,就是图片太大了,如果图片用像素数据表示,现在 iPhone 拍的一张照片有最小有 500w 像素,即使做常见的图片压缩(JPG/PNG),也有几百K的数据大小,如果用原图按上面的流程跑下来,计算量巨大,显然我们要针对图片做降维(或者理解为压缩),把一张图片的数据量降低,再进行后续的训练和使用。所以需要一个降维模型做这个事,这个模型需要满足:
-
有 encode 和 decode,需要能从 encode 和处理后的低维数据 decode 成高清图片。
-
要压缩得尽量小,方便低成本做上述海量的计算。
-
信息要能保留得足够多。
-
信息要有语义,不然训练过程中不同图片的信息无法交叉融合。
VAE (Variational Autoencoders 变分自编码器)能做到这些,VAE 提供了 encoder 和 decoder,一张图片经过 VAE encode,可以压缩成仅有 64x64x4 的矩阵,这里经过 encode 后的数据空间,就称为隐空间(Latent Space),在这个空间里进行上述扩散模型的训练和生成流程,成本就非常低,这也是目前Stable Diffusion能跑在我们普通电脑上的原因。最后在隐空间里生成的图片数据,经过 VAE decoder,就能转换成高清图。
那 VAE 为什么能做到这样?一张图片转成 64x64x4 这么小的数据量,为什么能保存图片的信息?通俗理解是 VAE 把图片内容转成了语义概率表示,相当于变成了这张图片的描述,比如描述这张图片有猫的概率、有猫爪子的概率,猫在左边的概率,绿色的概率,类似这样,更深入就不了解了。
CLIP
VAE 解决图片编码问题,再来看看文本的编码。在控制生成里,文本实际上是怎样参与到模型训练和生成的过程?如果文本只是随便编码进入模型,模型可能只认得一些特定字符,不认识语义,也就在后续的图片生成中没法比较好地通过自由的prompt文案控制。
SD 使用 OpenAI 训练的 CLIP 模型,把文本转为对应的向量,为什么用它,因为 CLIP 模型本身是一个文本到图片的映射模型,它对文本转出来的向量,更贴近图片的特征空间。
稍微展开说下原理:
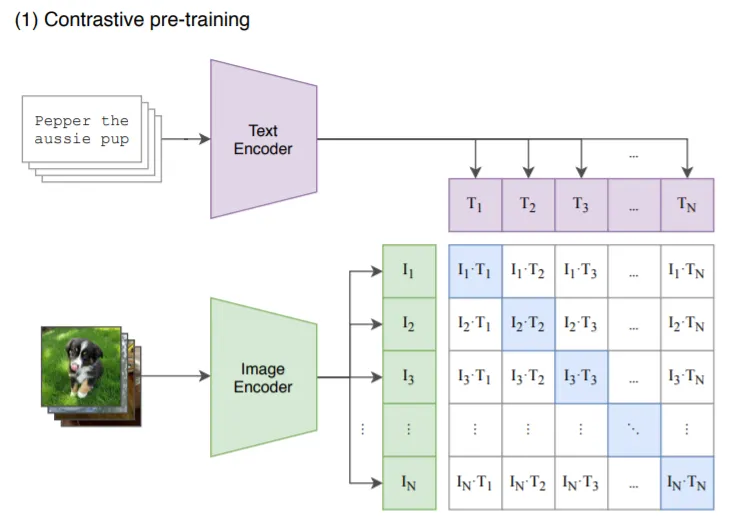
-
有N张图片、以及它们对应的 N 个对图片的描述文本
-
对图像进行编码,得到I,下图中,I1/I2/…/IN 表示从第 1 到 N 张图片的编码表示。
-
对文本片段进行编码,得到T,下图中,T1/T2…TN 表示从第 1 到 N 张图片对应的文本描述。
-
模型的任务是训练 TextEncoder 和 ImageEncoder的 参数:
-
让图中蓝色部分Ti和Ii相似度变高,它们原本就是一一对应的文本-图片,属于正样本。(数学上是计算余弦相似度,越大表示相似度越高,最大化这个值)
-
让白色部分相似度最低,它们的文本和图片是没有关系的,属于负样本。(数学上是余弦相似度值最小化)
这样训练后,最终使用这个模型时,TextEncoder出来的向量表示,就跟图片内容有很强的关系。比如下图第四行,猫的文字描述通过 TextEncode 出来的值,跟猫的图片的ImageEncode出来的值,相似度更高,跟其图片的encode相似度就低。
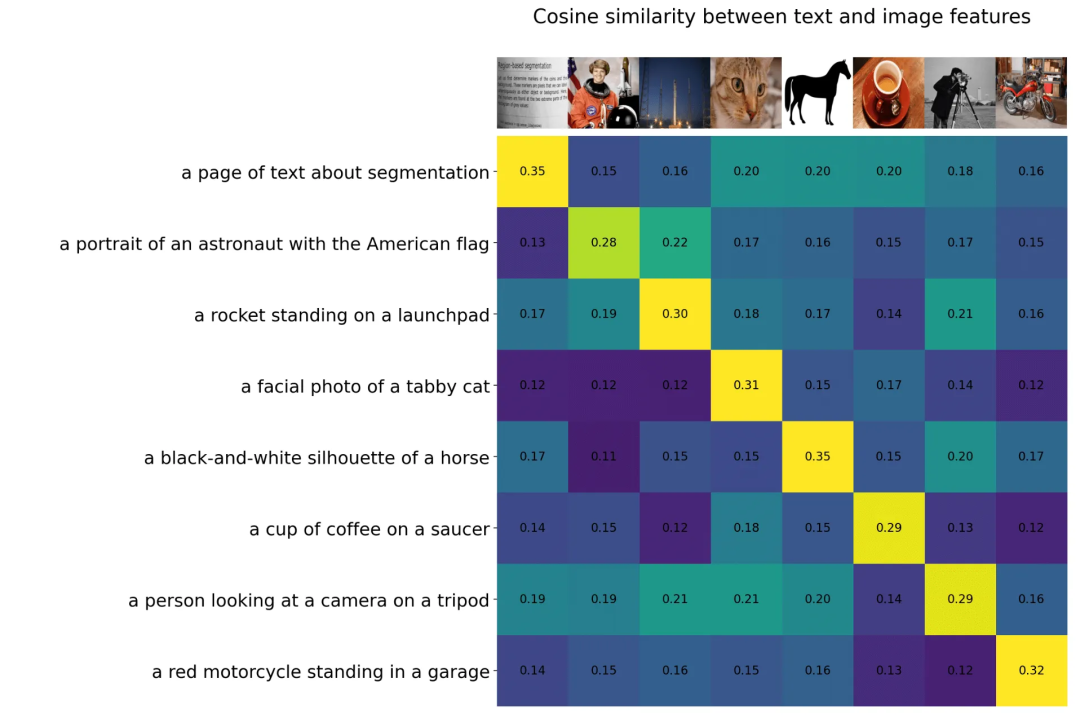
PS. 更细节的 CLIP 怎么跟 SD 生成过程结合,还没弄得很清楚,实际上SD 没有用 CLIP 里的 Image encoder,扩展模型训练过程中是用别的 Image Encoder,那就并没有用到文本和实际图片的对应映射关系,但可能CLIP出来的文本编码,语义和表现形式上已经是图片的模式,比如文字 cat,它能跟图片空间里猫所表示的形态(形状/位置)、视觉(眼睛/颜色/形状)、语义(宠物/动物)能比较接近地对应上,也能存储到相关信息,所以跟其他图片编码结合,也能起到很大作用?
采样器
编码和数据量的问题解决了,还有个问题没提到,就是上面流程里的步数太长了,最开始提出的扩散模型训练方案 DDPM(Denoising Diffusion Probabilistic Models 去噪扩散概率模型),正常需要 1000 步降噪过程(称为采样),才能生成一张不错的图片,即使上述隐空间已经降低了计算量,但生成一张图要1000步,还是达不到大规模可用。
为什么 DDPM 一定要这么多次采样?可以到"阅读原文"处点开参考链接,有篇文章说得比较清楚,因为不能直接减小步数(每次噪声加得很少,避免一步就破坏掉原图),不能跳步降噪(每一步状态都依赖前一步,号称马尔科夫性质)。
随后很快有人提出 DDIM(Denoising Diffusion Implicit Models 去噪扩散隐式模型) 方案,训练时还是 DDPM 一步步来,但生成时是可以做到跳步,同时还能让在步数变少的情况下保持生成的稳定。DDIM不是从头开始逐步去噪,而是选择几个关键的时间点,只在这些时间点上进行去噪操作,并且中间的步骤,比如从降噪100次的图片,下一步直接生成降噪90次的图片,跳10步,生成速度就快了10倍。为什么它能做到跳步?具体原因都是数学公式,就不展开了。
Stable Diffusion 的 WebUI 上有很多采样器,Eular a,Karras,DPM 等,在去噪过程中通过不同的方法,有不同的多样化程度、图像质量、速度、收敛性的区别。
Stable Diffusion
最后总结说下 Stable Diffusion。上面整个过程和概念,是一个个解决问题的方法,把它们组合起来,逐渐建立起基于扩散模型生成图片的方法大厦,谁都可以用这些公开的理论方法建一套自己的生图模型。
Stable Diffusion 就在这些基础上做一些改进,建立一套稳定的框架、训练出基础模型,开源让所有人可以用,整个 SD 就是多种能力的组合,这些能力可以分别不断升级替换,模型本身还有很多方式去做更强的控制干预(ControlNet / LORA等),使得它可定制性可玩性很强,生态越来越繁荣。
最后让我们用一个图串起整个流程和讲解到的概念:
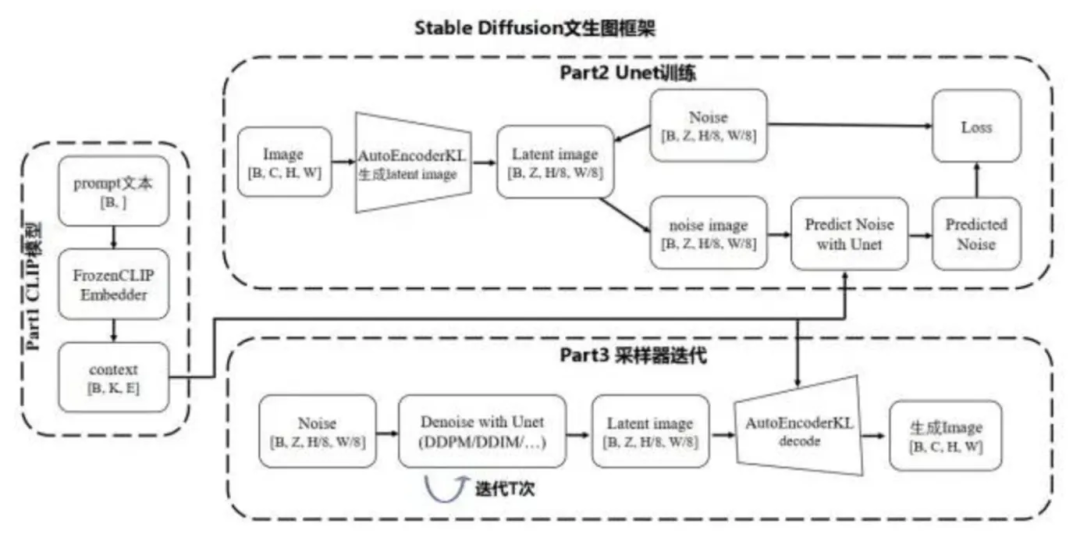
-
Part1 是用 CLIP 模型对文本做编码。
-
Part2 在模型训练过程中,图片经过 AutoencoderKL(VAE编码器的实现)生成隐空间下图片的表示,随机生成一个 noise 噪声,加到这个图片里,同时把通过 CLIP 模型编码的图片对应描述文本加入进来,一起进入 UNet 模型,训练预测加了多少 noise 噪声的能力。
-
Part3 在模型推理过程中,输入一个完全随机噪点,在隐空间里通过不同的采样器,结合prompt 文本输入(图上没表示出来,文本数据会参与到降噪过程),在 UNet 模型里迭代多步做降噪预测,生成隐空间里的图片,再通过 VAE AutoencoderKL 解码出图片。
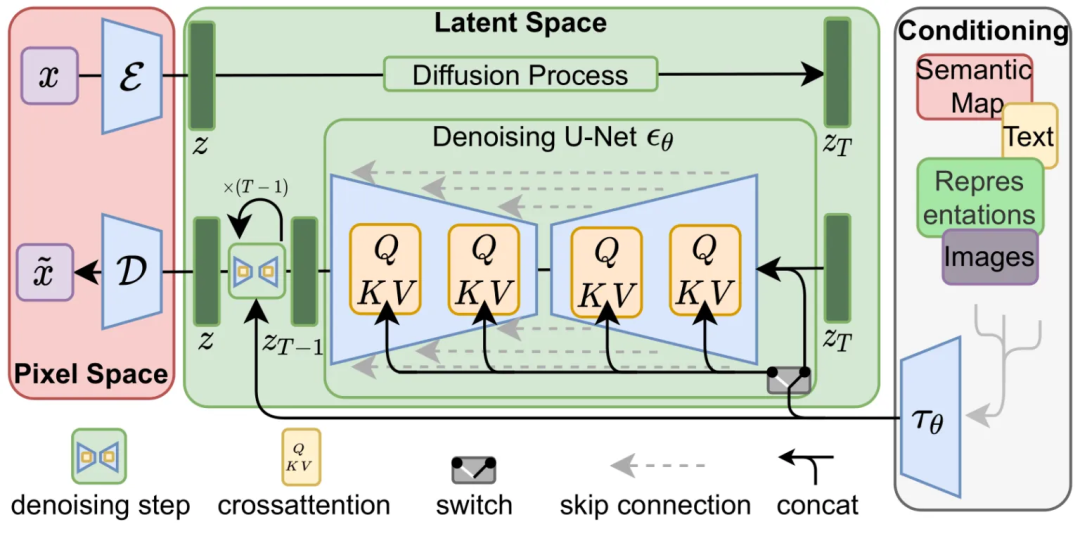
了解整个基础流程和概念后,现在看 Stable Diffusion 论文中的这张架构图,应该也大致能理解是什么意思了。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
?stable diffusion新手0基础入门PDF?

?AI绘画必备工具?
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
?AI绘画基础+速成+进阶使用教程?
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
?12000+AI关键词大合集?

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
评论记录:
回复评论: