
太久没用基本都忘光了,发现记的笔记也没有很好的梳理,虽然网上已经有了不少详细的文档了,但自己梳理一遍记忆比较深刻。
本文转载自我的博客:https://blog.abyssdawn.com/archives/515.html
已同步公众号
环境准备
$ python --version
Python 3.10.10
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:41:10_Pacific_Daylight_Time_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
安装 Stable Diffusion WebUI
nvidia显卡用户输入以下指令,下载Stable Diffusion WebUI的代码仓库。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
- 1
这里我clone的版本为1.10.0,目前的时间是2025-01-15
运行webui-user.bat
此时会开始下载pytorch,但是因为是官方的源很慢,可以先关闭终端
进入venv虚拟环境,使用国内镜像安装
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 -f https://mirrors.aliyun.com/pytorch-wheels/cu118
- 1
再次运行webui-user.bat
安装完毕
如果想要开启api功能,可以编辑web-user.bat,在set COMMANDLINE_ARGS的最后加上 -api
关于启动命令的详细说明:
| 参数指令 | 数值 | 默认值 | 说明 |
|---|---|---|---|
| 设置值 | |||
| -h, --help | None | False | 显示此帮助消息并退出。 |
| –exit | 安装后终止程序。 | ||
| –data-dir | DATA_DIR | ./ | 用户数据保存的路径。 |
| –config | CONFIG | configs/stable-diffusion/v1-inference.yaml | 建构模型设置档的路径。 |
| –ckpt | CKPT | model.ckpt | Stable Diffusion模型的存盘点模型路径。一旦指定,该模型会加入至存盘点模型列表并加载。 |
| –ckpt-dir | CKPT_DIR | None | 存放Stable Diffusion模型存盘点模型的路径。 |
| –no-download-sd-model | None | False | 即使找不到模型,也不自动下载SD1.5模型。 |
| –vae-dir | VAE_PATH | None | VAE的路径。 |
| –gfpgan-dir | GFPGAN_DIR | GFPGAN/ | GFPGAN路径 |
| –gfpgan-model | GFPGAN_MODEL | GFPGAN模型文件名 | |
| –codeformer-models-path | CODEFORMER_MODELS_PATH | models/Codeformer/ | Codeformer模型档的路径。 |
| –gfpgan-models-path | GFPGAN_MODELS_PATH | models/GFPGAN | GFPGAN模型档的路径。 |
| –esrgan-models-path | ESRGAN_MODELS_PATH | models/ESRGAN | ESRGAN模型档的路径。 |
| –bsrgan-models-path | BSRGAN_MODELS_PATH | models/BSRGAN | BSRGAN模型档的路径。 |
| –realesrgan-models-path | REALESRGAN_MODELS_PATH | models/RealESRGAN | RealESRGAN模型档的路径。 |
| –scunet-models-path | SCUNET_MODELS_PATH | models/ScuNET | ScuNET模型档的路径。 |
| –swinir-models-path | SWINIR_MODELS_PATH | models/SwinIR | SwinIR和SwinIR v2模型档的路径。 |
| –ldsr-models-path | LDSR_MODELS_PATH | models/LDSR | 含有LDSR模型档的路径。 |
| –lora-dir | LORA_DIR | models/Lora | 含有LoRA模型档的路径。 |
| –clip-models-path | CLIP_MODELS_PATH | None | 含有CLIP模型档的路径。 |
| –embeddings-dir | EMBEDDINGS_DIR | embeddings/ | Textual inversion的embeddings路径 (缺省: embeddings) |
| –textual-inversion-templates-dir | TEXTUAL_INVERSION_TEMPLATES_DIR | textual_inversion_templates | Textual inversion范本的路径 |
| –hypernetwork-dir | HYPERNETWORK_DIR | models/hypernetworks/ | Hypernetwork路径 |
| –localizations-dir | LOCALIZATIONS_DIR | localizations/ | 在地化翻译路径 |
| –styles-file | STYLES_FILE | styles.csv | 风格文件名 |
| –ui-config-file | UI_CONFIG_FILE | ui-config.json | UI设置档文件名 |
| –no-progressbar-hiding | None | False | 取消隐藏Gradio UI的进度条 (我们之所以将其隐藏,是因为在浏览器启动硬件加速的状况下,进度条会降低机器学习的性能) |
| –max-batch-count | MAX_BATCH_COUNT | 16 | UI的最大批量数值 |
| –ui-settings-file | UI_SETTINGS_FILE | config.json | UI设置值画面的文件名 |
| –allow-code | None | False | 允许在WebUI运行自订指令稿 |
| –share | None | False | 使用此参数在启动后会产生Gradio网址,使WebUI能从外部网络访问 |
| –listen | None | False | 以0.0.0.0主机名称启动Gradio,使其能回应连接请求 |
| –port | PORT | 7860 | 以给定的通信端口启动Gradio。1024以下的通信端口需要root权限。如果可用的话,缺省使用7860通信端口。 |
| –hide-ui-dir-config | None | False | 在WebUI隐藏设置档目录。 |
| –freeze-settings | None | False | 禁用编辑设置。 |
| –enable-insecure-extension-access | None | False | 无视其他选项,强制激活扩充功能页签。 |
| –gradio-debug | None | False | 使用 --debug选项启动Gradio |
| –gradio-auth | GRADIO_AUTH | None | 设置Gardio授权,例如"username:password",或是逗号分隔值形式"u1:p1,u2:p2,u3:p3" |
| –gradio-auth-path | GRADIO_AUTH_PATH | None | 设置Gardio授权文件路径。 例如 “/路径/” 再加上--gradio-auth的格式。 |
| –disable-console-progressbars | None | False | 不在终端机显示进度条。 |
| –enable-console-prompts | None | False | 在使用文生图和图生图的时候,于终端机印出提示词 |
| –api | None | False | 以API模式启动WebUI |
| –api-auth | API_AUTH | None | 设置API授权,例如"username:password",或是逗号分隔值形式"u1:p1,u2:p2,u3:p3" |
| –api-log | None | False | 激活所有API请求的纪录档 |
| –nowebui | None | False | 仅启动API, 不启动WebUI |
| –ui-debug-mode | None | False | 不加载模型,以更快启动WebUI |
| –device-id | DEVICE_ID | None | 选择要使用的CUDA设备 (例如在启动指令稿使用export CUDA_VISIBLE_DEVICES=0或1) |
| –administrator | None | False | 使用系统管理员权限 |
| –cors-allow-origins | CORS_ALLOW_ORIGINS | None | 允许跨来源资源共用,列表以逗号分隔,不可有空格 |
| –cors-allow-origins-regex | CORS_ALLOW_ORIGINS_REGEX | None | 允许跨来源资源共用,后面加上单一正规表达式 |
| –tls-keyfile | TLS_KEYFILE | None | 部份激活TLS,,需要配合–tls-certfile才能正常运作 |
| –tls-certfile | TLS_CERTFILE | None | 部份激活TLS,需要配合–tls-keyfile才能正常运作 |
| –server-name | SERVER_NAME | None | 设置服务器主机名称 |
| –skip-version-check | None | False | 不检查torch和xformers的版本 |
| –no-hashing | None | False | 禁用计算存盘点模型的sha256哈希值,加快加载速度 |
| –skip-version-check | None | False | 不检查torch与xformers版本。 |
| –skip-version-check | None | False | 不检查Python版本。 |
| –skip-torch-cuda-test | None | False | 不检查CUDA是否正常运作。 |
| –skip-install | None | False | 跳过安装套件。 |
| –loglevel | None | None | 日志纪录等级,有效值为CRITICAL, ERROR, WARNING, INFO, DEBUG |
| –log-startup | None | False | 在启动程序时输出launch.py的详细运行内容。 |
| –api-server-stop | None | False | 允许通过API通信停止/重启/强制停止主程序。 |
| –timeout-keep-alive | int | 30 | 设置uvicorn的timeout_keep_alive数值。 |
| 性能相关 | |||
| –xformers | None | False | 给cross attention layers激活xformers |
| –reinstall-xformers | None | False | 强制重装xformers,升级时很有用。但为避免不断重装,升级后将会移除。 |
| –force-enable-xformers | None | False | 强制给cross attention layers激活xformers 此选项无法运作的话请勿回报bug |
| –xformers-flash-attention | None | False | 给xformers激活Flash Attention,提升再现能力 (仅支持SD2.x或以此为基础的模型) |
| –opt-split-attention | None | False | 强制激活Doggettx的cross-attention layer优化。有CUDA的系统缺省激活此选项。 |
| –opt-split-attention-invokeai | None | False | 强制激活InvokeAI的cross-attention layer优化。无CUDA的系统缺省激活此选项。 |
| –opt-split-attention-v1 | None | False | 激活旧版的split attention优化,防止占用全部可用的VRAM, |
| –opt-sub-quad-attention | None | False | 激活增进内存效率的sub-quadratic cross-attention layer优化 |
| –sub-quad-q-chunk-size | SUB_QUAD_Q_CHUNK_SIZE | 1024 | sub-quadratic cross-attention layer优化使用的串行化区块大小 |
| –sub-quad-kv-chunk-size | SUB_QUAD_KV_CHUNK_SIZE | None | sub-quadratic cross-attention layer优化使用的kv区块大小 |
| –sub-quad-chunk-threshold | SUB_QUAD_CHUNK_THRESHOLD | None | sub-quadratic cross-attention layer优化过程中,区块化使用的VRAM阈值 |
| –opt-channelslast | None | False | 激活4d tensors使用的alternative layout,或许可以加快推理速度 仅适用搭载Tensor内核的Nvidia显卡(16xx系列以上) |
| –disable-opt-split-attention | None | False | 强制禁用cross-attention layer的优化 |
| –disable-nan-check | None | False | 不检查生成图像/潜在空间是否有nan。在CI模式无使用存盘点模型的时候很有用。 |
| –use-cpu | {all, sd, interrogate, gfpgan, bsrgan, esrgan, scunet, codeformer} | None | 让部份模块使用CPU作为PyTorch的设备 |
| –no-half | None | False | 不将模型转换为半精度浮点数 |
| –precision | {full,autocast} | autocast | 使用此精度评估 |
| –no-half-vae | None | False | 不将VAE模型转换为半精度浮点数 |
| –upcast-sampling | None | False | 向上采样。搭配 --no-half使用则无效。生成的结果与使用–no-half参数相近,效率更高,使用更少内存。 |
| –medvram | None | False | 激活Stable Diffusion模型优化,牺牲速度,换取较小的VRAM占用。 |
| –lowvram | None | False | 激活Stable Diffusion模型优化,大幅牺牲速度,换取更小的VRAM占用。 |
| –lowram | None | False | 将Stable Diffusion存盘点模型的权重加载至VRAM,而非RAM |
| –disable-model-loading-ram-optimization | None | False | 禁用模型加载时降低RAM占用的优化。 |
| 功能 | |||
| –autolaunch | None | False | 启动WebUI后自动打开系统缺省的浏览器 |
| –theme | None | Unset | 使用指定主题启动WebUI (light或dark),无指定则使用浏览器缺省主题。 |
| –use-textbox-seed | None | False | 在WebUI的种子字段使用textbox (没有上下,但可以输入长的种子码) |
| –disable-safe-unpickle | None | False | 不检查PyTorch模型是否有恶意代码 |
| –ngrok | NGROK | None | Ngrok授权权杖, --share参数的替代品。 |
| –ngrok-region | NGROK_REGION | us | 选择启动Ngrok的区域 |
| –update-check | None | None | 启动时检查有无新版本。 |
| –update-all-extensions | None | None | 在启动WebUI的时候自动更新所有扩充功能。 |
| –reinstall-xformers | None | False | 强制重新安装xformers,适用于更新程序之后运行。更新完之后记得移除此参数。 |
| –reinstall-torch | None | False | 强制重新安装touch,适用于更新程序之后运行。更新完之后记得移除此参数。 |
| –tests | TESTS | False | 运行功能测试,确认WebUI正常运作。 |
| –no-tests | None | False | 即使有--test参数也不要运行功能测试。 |
| –dump-sysinfo | None | False | 倾印系统消息并退出程序(不包括扩充功能) |
| –disable-all-extensions | None | False | 禁用所有扩充功能,包含内置的扩充功能。 |
| –disable-extra-extensions | None | False | 禁用所有扩充功能。 |
| 已经无效的选项 | |||
| –show-negative-prompt | None | False | 无作用 |
| –deepdanbooru | None | False | 无作用 |
| –unload-gfpgan | None | False | 无作用 |
| –gradio-img2img-tool | GRADIO_IMG2IMG_TOOL | None | 无作用 |
| –gradio-inpaint-tool | GRADIO_INPAINT_TOOL | None | 无作用 |
| –gradio-queue | None | False | 无作用 |
| –add-stop-route | None | False | 无作用 |
| –always-batch-cond-uncond | None | False | 无作用 |
下载模型
目前找Stable Diffusion与其衍生模型的网站主要就二个。
第一个是 HuggingFace,中文俗称抱脸笑,可以说是人工智能界的Github。Stable Diffusion背后用到的很多AI工具,如Transformer、Tokenizers、Datasets都他们开发的,网站上也有丰富的教学文档。
另一个是 Civitai,专门用来分享Stable Diffusion相关的资源,特色是模型都有示范缩略图,用户也可以分享彼此使用的提示词,以及分享作品。
这里我先下载一个动漫模型:https://civitai.com/models/4437/abyssorangemix2-sfwsoft-nsfw
將下载后的模型放到models\Stable-diffusion
文生图
文生图(txt2image)即为让AI按照文本叙述生图。
生图流程为在左上角填入提示词,勾选左下角的生图参数,再点击右上角生成图片。其余SD WebUI的功能用法大抵都按照此逻辑设计,有些参数是通用的。
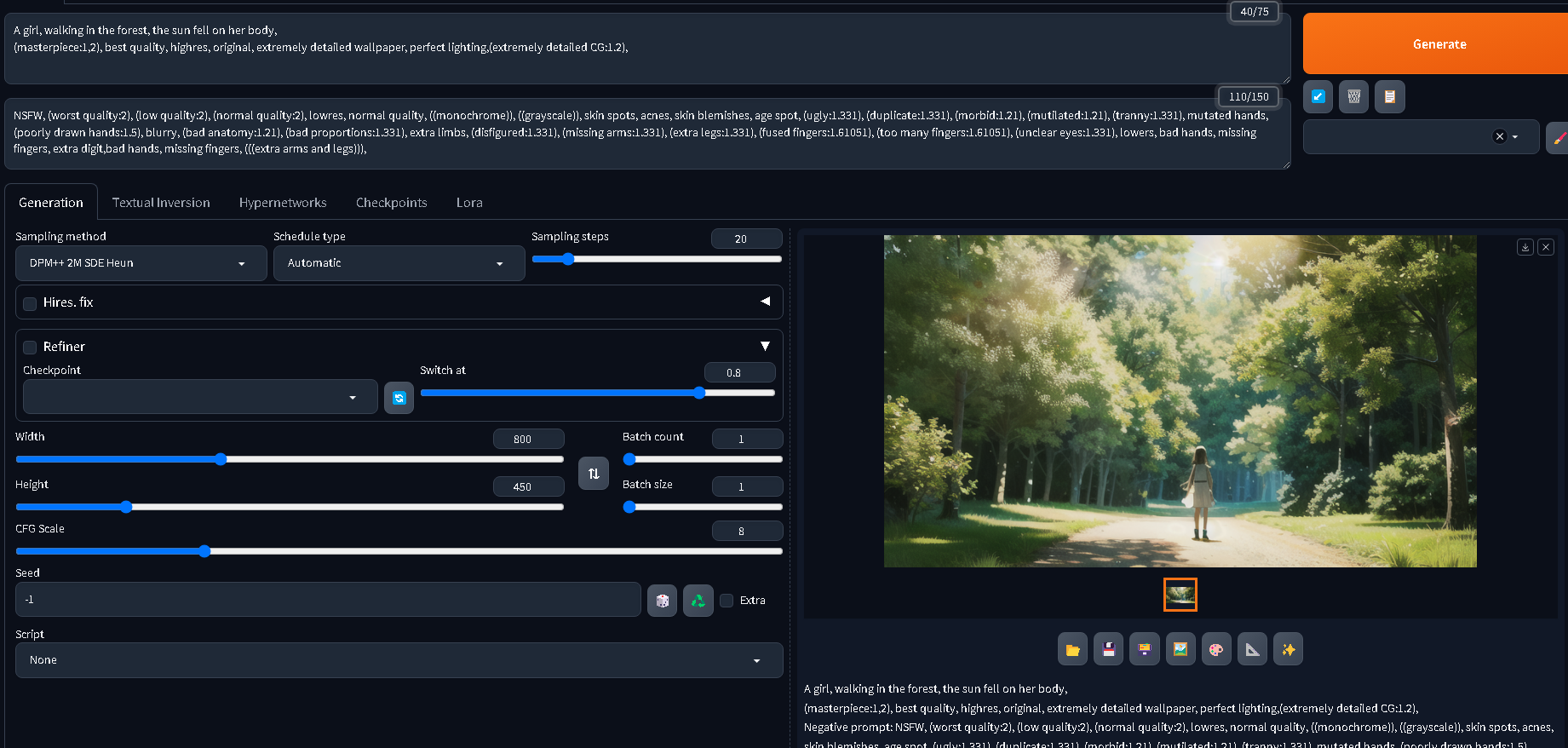
文生图 案例1
在prompt输入
A girl, walking in the forest, the sun fell on her body,
(masterpiece:1,2), best quality, highres, original, extremely detailed wallpaper, perfect lighting,(extremely detailed CG:1.2),
- 1
- 2
在nagative prompt输入
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
- 1
通用参数:
- Sampling method 采样方法选择:DPM++ 2M SDE Heun
- Sampling Steps 采样步数:20
- Width 宽度:800
- Height 高度:450
- Batch count 生成几次:1
- Batch size 一次生成几张:1
- CFG Scale 提示词的相关度:8
- Seed 种子码:-1 表示随机,也可以填别人画好的seed
其它参数先不用管,点击生成
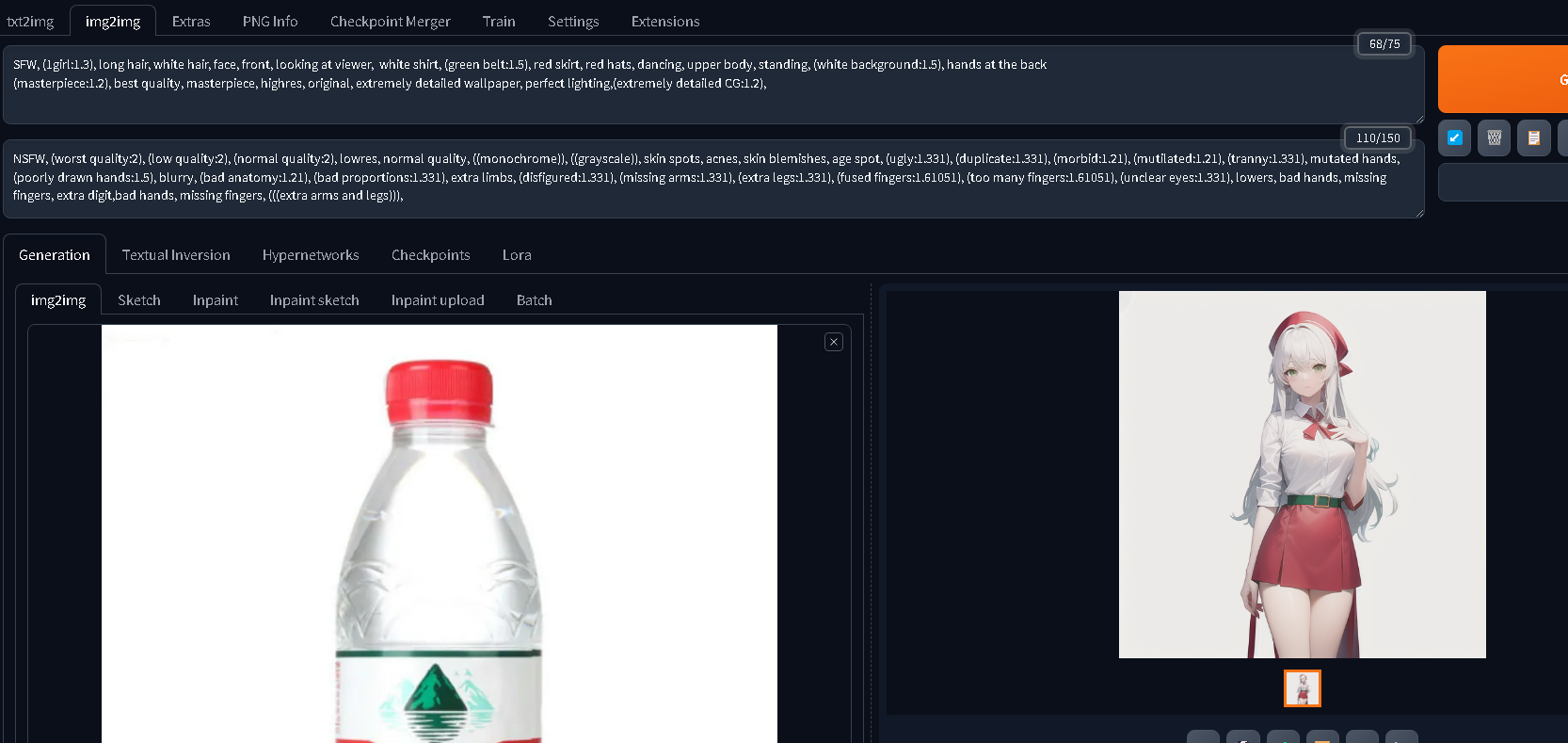
图生图
图生图(img2img)是让AI参照现有的图片生图,源自InstructPix2Pix技术。
例如:上传一张真人照片,让AI把他改绘成动漫人物;上传画作线稿,让AI自动上色;上传一张黑白照,让AI把它修复成彩色相片。
这个功能位于「Img2img」的页签。
随便在网上找一张非二次元的图片,例如我这里使用矿泉水瓶的图片
参考步骤:
- 上传参考图。图片比例最好跟设置生成的宽高一致
- 调整通用参数。特别注意Denoising strength,该参数调低的情况下可以用来微调原图
- 点击生成
提示词(注意看格式)
SFW, (1girl:1.3), long hair, white hair, face, front, looking at viewer, white shirt, (green belt:1.5), red skirt, red hats, dancing, upper body, standing, (white background:1.5), hands at the back
(masterpiece:1.2), best quality, masterpiece, highres, original, extremely detailed wallpaper, perfect lighting,(extremely detailed CG:1.2),
Negative prompt: NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 4072734573, Size: 600x600, Model hash: 038ba203d8, Model: AbyssOrangeMix2_SFW, Denoising strength: 0.7, Clip skip: 2, ENSD: 31337, Mask blur: 4
- 1
- 2
- 3
- 4
图生图的生成结果按钮下的最后两个按钮可以从图片中提取提示词,有兴趣的也可以试一下。
内补绘制
内补绘制(inpaint)。这是用AI填充涂黑(遮罩)区域的技术,例如给图片的角色换衣服。或是反过来:让AI把图片空白的地方绘制完成(outpaint)。
可以想像成让AI帮您修图,用于在图中添加或去除对象。
此功能位于Img2img下的Inpaint页面。
参数说明:
- Mask blur:图片上的笔刷毛边柔和程度。
- Mask mode:选择要让AI填满涂黑区域(Inpaint masked),或是填满未涂黑区域(Inpaint not masked)。
- Masked content:要填充的内容。
- Fill:让AI参考涂黑附近的颜色填满区域。
- Original:在填满区域的时候参考原图底下的内容。
- latent noise:使用潜在空间填满,可能会生出跟原图完全不相关的内容。
- latent nothing:使用潜在空间填满,不加入噪声。
- Inpaint area:选择要填满整张图片(Whole picture)或是只填满涂黑的区域(Only masked)
- Only masked padding, pixels是像素内距。
- Only masked即外补绘制模式。
参考流程:
- 上传参考图
- 绘制要重绘的区域
- 填写提示词
- 调整参数
- 生成
若要切换为外补绘制:点击左下角的Mask mode,将Inpaint masked改成Inpaint not masked,这样AI就会改为填满没有涂黑的地方。
batch页面可以批量处理图片,大家自行尝试。
这里我没做出效果比较好的示例,在网上找了张效果图,涂黑的部分就是重绘的部分,新版涂抹已经变成白色了

额外网络 进阶模型
大模型一般指Checkpoint,小模型则是除了大模型之外的其他模型,如LoRA、Embeddings、Hypernetwork对大模型起到“微调”作用
小模型主要用来改善画风,并改善生成特定对象、角色的准确度。例如使用Anything模型生图,再搭配"Taiwan-doll-likeness LoRA"就能转成真人风格而不用依赖许多提示词,并且可以一次叠很多个,就像套多层滤镜一般。
- LoRA:比较常用,一般用于还原角色、形象特征,也可以用于训练画风
- Embeddings:还原角色的形象特征
- Hypernetwork:用的不多
Civitai有很多小模型可以下载。下载时需注意模型是哪一种。
- Embedding请放stable-diffusion-webui文件夹下的embeddings
- HyperNetwork放到stable-diffusion-webui/models/hypernetworks。
- LoRA放到stable-diffusion-webui/models/Lora。
如果要显示小模型缩略图,将图片取跟该模型一样的文件名,并放到该模型的文件夹。例如在Taiwan-doll-likeness.safetensors所在的文件夹放一张Taiwan-doll-likeness.png。
使用方法:
- 在正常使用文生图的基础上。选择lora,点击小模型的卡片便会将其加到提示词字段,提示词字段会出现,表示要在绘图时使用LoRA。
- 如果生出来的图片太诡异,调整提示词字段每个LoRA后面的数字,控制权重。xxx:0.5
这里介绍一下VAE,之前生成的图片都会偏灰。VAE (variational autoencoder)可以让算出来的图片色彩更漂亮,改善图片颜色灰灰暗暗的问题。
这里下载模型对应的VAE:https://huggingface.co/WarriorMama777/OrangeMixs/tree/main/VAEs
下载orangemix.vae.pt
如果要使用VAE,下载VAE模型后,将其放到stable-diffusion-webui/models/VAE文件夹。
接着点击Settings → Stable Diffusion → SD VAE,选取要使用的VAE,再点击Apply Settings,此后生图就会一律使用指定的VAE。
lora案例1
到c站下载lora:https://civitai.com/models/9727?modelVersionId=11564
这里我下载的是d.va (overwatch) d.va 守望先锋
下载后放到models\Lora文件夹。
此时在Lora选项卡的右上角点击刷新就可以看到卡片
提示词
SFW, masterpiece, best quality, 1girl, brown hair, brown eyes, smile, standing, dynamic pose, outdoors, city background, , deeva \(overwatch 1 version\), d.va /(overwatch 1/),
facial_mark, whisker_markings, d.va_\(overwatch\), 1girl, blue bodysuit, long_hair, pilot_suit, solo, facepaint, headphones, gun, brown_hair, holding_gun, swept_bangs, clothes_writing, bangs, breasts, blue_background, hand_on_hip, animal_print, handgun, brown_eyes, medium_breasts, holding_weapon, bracer, ribbed_bodysuit, weapon, white_gloves, shoulder_pads, holding, high_collar, turtleneck, standing, white_footwear, full_body, charm_\(object\), pink_lips, gloves, hand_up, pistol, skin_tight, smile
Negative prompt: NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 3590206651, Size: 600x800, Model hash: a074b8864e, Model: 二次元:Counterfeit V2.5, Denoising strength: 0.4, Clip skip: 2, ENSD: 31337, Hires upscale: 1.5, Hires upscaler: R-ESRGAN 4x+ Anime6B
- 1
- 2
- 3
- 4
可以试一下加和不加的区别

放大图片分辨率
用默认的512x512分辨率就生出不错的图,可以将图片直接丢到Extras放大。
参数
- Scale by:按照此数字的倍数放大
- Scale to:放大至指定宽高
- Upscaler 1 & Upscaler 2:放大图片的时候可以只用一种放大器,也可以混合使用二种放大器。
- Upscaler 2 visibility:第二个放大器的权重。
- GFPGAN visibility:GFPGAN脸部修复模型的权重
- CodeFormer visibility:CodeFormer脸部修复模型的权重
Upscaler的选择
- ESRGAN_4x适合用于处理真人照片
- ESRGAN_4x适合用于绘画
- Anime6B适合用于动漫图片,它也可以用来将真人图片转动漫风格
切换至Extras页面,上传图片,选取放大2倍,点击下面的Upscaler 1中挑一个看起来顺眼的,其余维持缺省,按Generate即会得到放大过的图片。
参考
- https://docs.stablediffusion.cn/
- https://nenly.notion.site/017c3341c8b84a7ebb4c2cb16f36e28f

评论记录:
回复评论: