
相信大家,面对着一张张模糊不清、毫无表情的脸,肯定会感到无趣无生气。
如果你正在寻找一种简单而高效的方式,将静态照片转化为富有表现力的动态视频,那你可能会对 ComfyUI-IF_MemoAvatar 产生浓厚兴趣。
它是一款ComfyUI插件,依赖于ComfyUI,但能彻底改变你的体验,让任何人秒变表情帝!

项目介绍
ComfyUI-IF_MemoAvatar 是一种实现“MEMO”(Memory-Guided Diffusion)的强大工具,它基于记忆的扩散方法,将静态图像与音频相结合,生成富有表现力的讲话人角色视频。
简单来说,它通过分析你的面部特征和语音,构建一个虚拟的“表情库”,然后将这些表情与你的语音同步,最终生成一段逼真的说话视频。
无论你是 Windows 还是 Linux 用户,都可以轻松搭建和使用。
TTS、唱歌、说唱,它都可以胜任。

主要功能
1、从单张图片生成表情丰富的动态视频
只需一张静态图片,工具会通过分析面部特征,创建一个栩栩如生的角色模型。当音频输入时,这个角色会根据声音驱动,动态地进行嘴部和面部表情的同步。
2、音频驱动的面部动画
音频不仅仅是声音,还包含了情感。
MemoAvatar 可以识别音频中的情感线索,并将这些情感转化为角色的面部表情。
例如,当音频传递高兴、悲伤或愤怒的情绪时,角色的表情也会发生相应的变化。
3、情感表达转移
与传统的面部动画生成不同,MemoAvatar 支持将一种情感风格从音频转移到图像角色中。
这种情感转移使生成的内容更加贴合实际应用需求。
4、高质量视频输出
输出视频的质量直接影响用户体验。该模型不仅关注面部动画的流畅性,还保证生成的视频具有高清画质,并且避免了常见的边缘模糊或画面跳动问题。
快速使用
①克隆仓库
首先,可以直接使用ComfyUI管理器直接下载。

或手动将工具代码克隆到 ComfyUI 的 custom_nodes 文件夹中并安装依赖:
bash 代码解读复制代码git clone https://github.com/if-ai/ComfyUI-IF_MemoAvatar
cd ComfyUI-IF_MemoAvatar
pip install -r requirements.txt
②注意 xformers 的安装
Linux 用户直接运行以下命令安装 xformers:
代码解读复制代码pip install xformers
Windows 用户确保你的环境中支持 xformers,然后运行以下命令检查安装状态:
sql 代码解读复制代码pip show xformers
③模型文件准备
工具会自动将所需的模型文件下载到 ComfyUI 安装路径的 face_analisys/models 文件夹中。
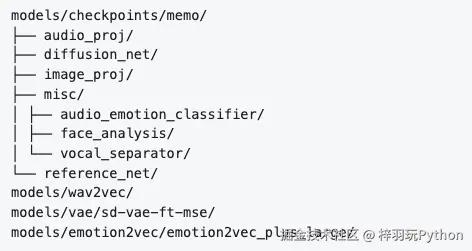
为避免错误,请将下载的模型文件直接复制到 face_analisys 文件夹中,不要移动它们,否则 HF 会重新检测并下载空文件。
适用场景
-
虚拟主播与短视频创作
-
教育与培训视频
-
面试模拟与语音交互
-
情感化社交内容
写在最后
ComfyUI-IF_MemoAvatar 它不仅是一款技术强大的工具,更是一座创意的桥梁。
通过照片和音频的结合,MemoAvatar 能把静态的形象赋予生命,为个人和企业提供了无限的可能性。
如果你对个性化视频生成感兴趣,不妨亲自尝试这款工具。
GitHub项目地址:github.com/if-ai/Comfy…
评论记录:
回复评论: